1. Introduction
In February 2020, the World Health Organization (WHO) named the cause of the Coronavirus Disease 2019 (COVID-19) as SARS-CoV-2 [
1], which is a novel coronavirus that firstly been found in the human body. This virus shares a structural similarity of 87.1% [
2] to the SARS-related virus found in bats, and 79.5% [
3] to the SARS virus, which means novel coronavirus and SARS coronavirus belong to the same family of viruses but are not the same.
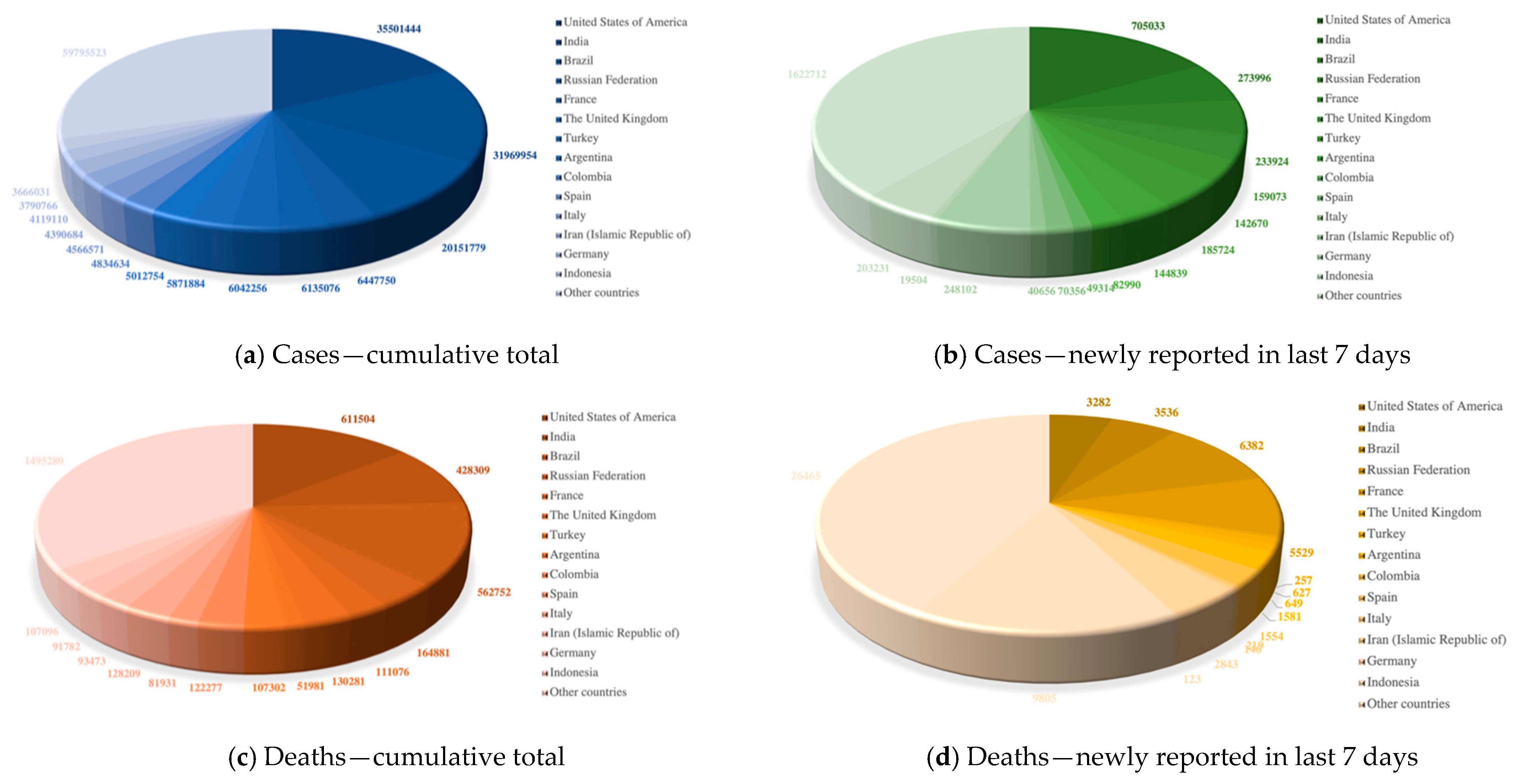
According to the latest real-time statistics reported by the WHO in
Figure 1, as of 10:37 a.m. Central European Summer Time (CEST) on 9 August 2021, there have been 202,296,216 confirmed cases of COVID-19 and 4,288,134 confirmed deaths over 225 countries, areas, or territories. Although vaccine doses have been administered in significant numbers, newly reported confirmed cases and deaths are still emerging every day.
From the current epidemiological investigation for COVID-19 [
4], the patient of latent period and some confirmed patients has no difference in appearance with the normal person but still has infectivity. Therefore, it is urgent to expand the coverage of COVID-19 inspection, accelerate the speed of detection, improve the accuracy of detecting infected persons including the asymptomatic infected persons as early as possible to avoid secondary transmission [
5]. However, at present, based on a variety of practical considerations, several countries around the world are trying to relax social restrictions, which poses great challenges to COVID-19 detection level, especially in places with high traffic density such as customs, airports, and stations. Thus, to quickly improve the COVID-19 diagnostic level, scientists and medical institutions worldwide are actively engaged in in-depth research into the COVID-19 diagnosis.
At present, the commonly used standard method of COVID-19 detection is the reverse transcription-polymerase chain reaction (RT-PCR) test. Nevertheless, RT-PCR usually takes up two days to complete and sometimes needs repetition or some other auxiliary detection approach in test to exclude potential false negatives [
6]. Care also needs to be taken during testing to prevent environmental contamination of the samples. Therefore, to improve the efficiency of COVID-19 detection, many medical institutions consider chest computed tomography (CT) scan as an early diagnostic tool for suspected coronavirus infection. Chest CT is a common basic diagnostic technique for pneumonia, which uses X-ray CT to examine the chest [
7]. Fang, Zhang [
6] compared the sensitivity of chest CT and RT-PCR in COVID-19 detection. The results indicate that chest CT is an effective method for screening COVID-19 patients, especially those who are tested negative for RT-PCR.
However, manual labelling and diagnosing of CT images may be time-consuming and labour-intensive. Human experts may also misdiagnose due to some external interference or subjective factors, especially when the lesion degree is mild. Hence, using computer-aided technologies to assist expert diagnosis has become a good choice [
8,
9]. Deep learning technology has also far achieved many contributions in dealing with CT images. Onishi, Teramoto [
10] proposed a novel deep learning system that combined a deep convolutional neural network and generative adversarial networks for pulmonary-nodule classification. Wang, Shen [
11] presented a raw patch-based convolutional neural network for the detection of lung nodules. Peng, Kang [
12] used a residual convolutional neural network for predicting the response of transarterial chemoembolization in hepatocellular carcinoma. As displayed in
Table 1, three pieces of the latest research from Wang and Wong [
13], Dey, Rajinikant [
14], and Abbas, Abdelsamea [
15] provide systematic reviews of deep learning techniques in detecting COVID-19. These all prove that deep learning methods can well approximate expert skills, and at the same time find novel relationships not already apparent to humans.
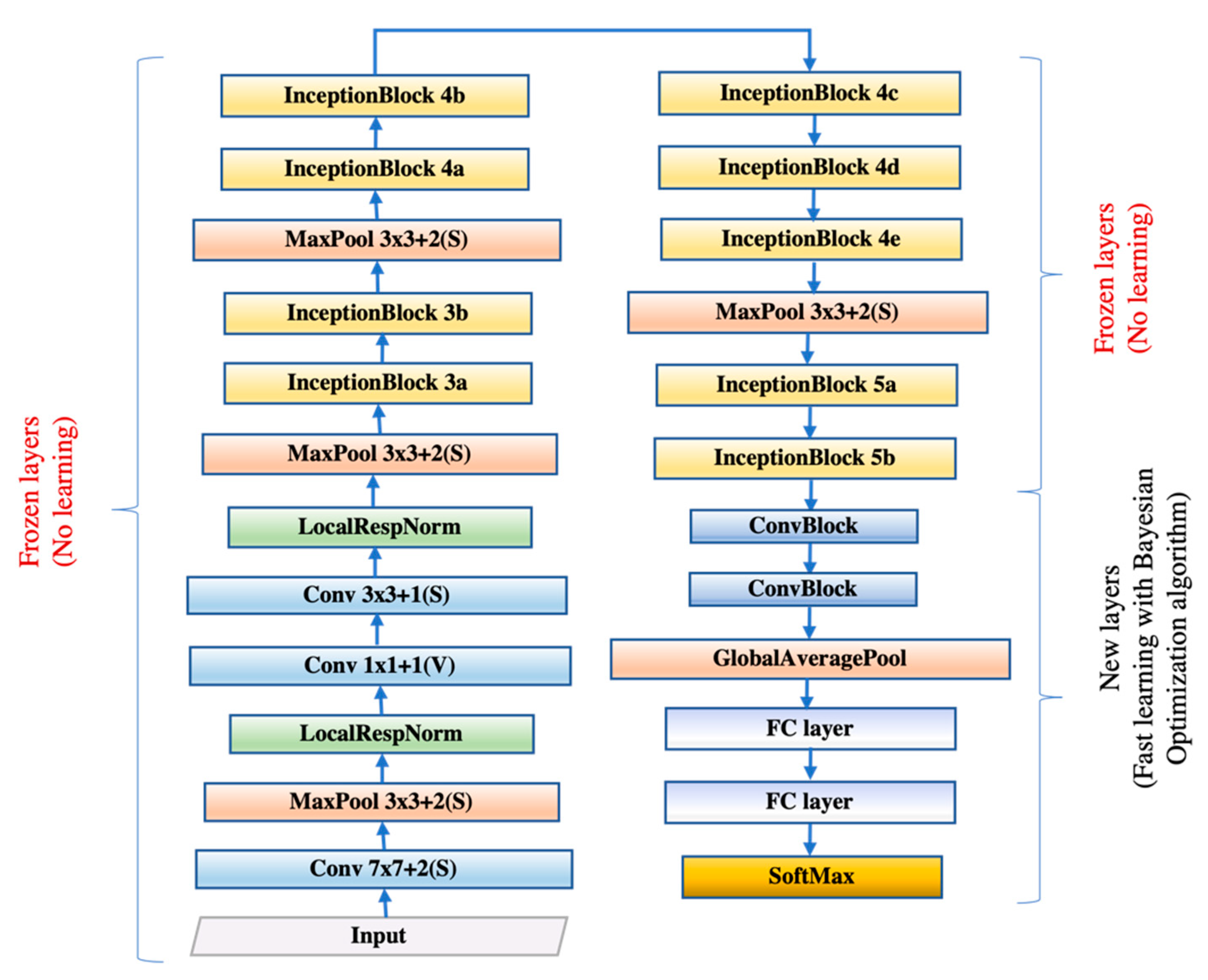
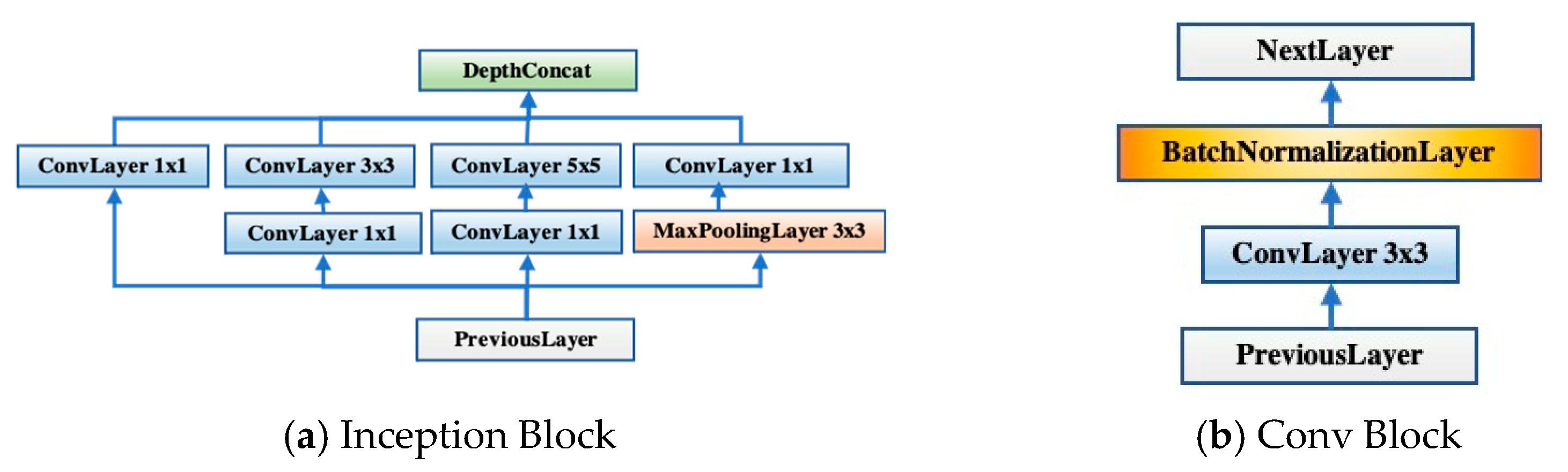
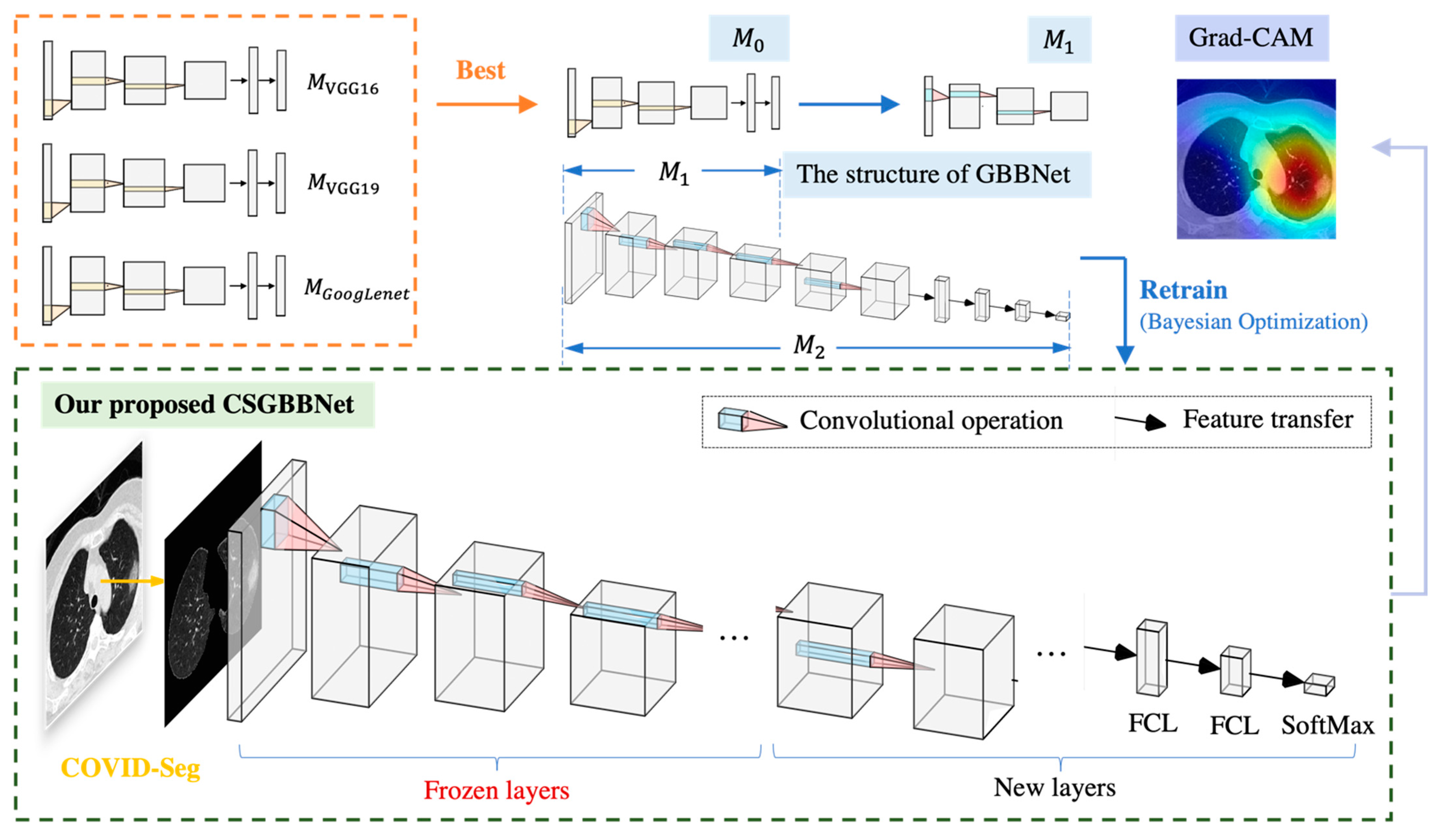
GoogLeNet is a classic deep learning structure proposed by Szegedy, Ioffe [
16]. Our novel model was proposed based on transfer learning from GoogLeNet. In addition, to prevent gradient explosion or dispersion and keep most activation functions away from their saturated region, more batch normalization relevant blocks were added into the newly designed layers. In this way, the robustness of the model to different hyperparameters during training will be improved and the optimization process will become smoother. This smoothness makes the behavior of the gradient more predictable and stable, allowing for faster training [
17].
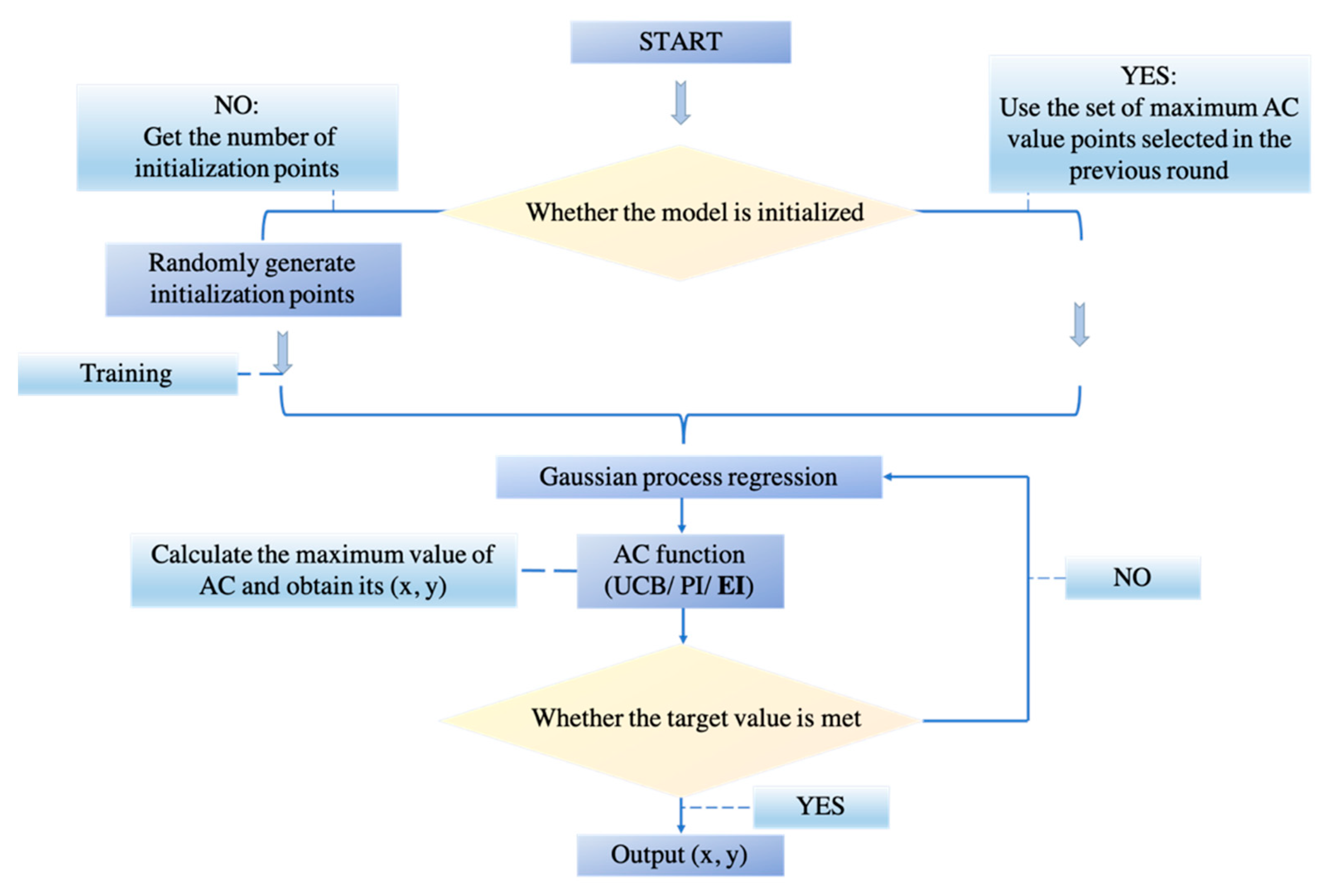
When dealing with deep neural networks, the selection of hyperparameters is always a problem. Manual parameter tuning is time-consuming and may not achieve optimal results. The advantage of Bayesian Optimization (BO) in parameter tuning is sample efficiency. In other words, if we consider one step as training the neural network with a set of hyperparameters, BO can find a better choice of hyperparameters with very few steps. In addition, BO does not ask for the gradient, which is difficult to be obtained from the hyperparameter of the neural network under general circumstances. These two benefits make BO become the algorithm we chose to tune the neural network in this experiment.
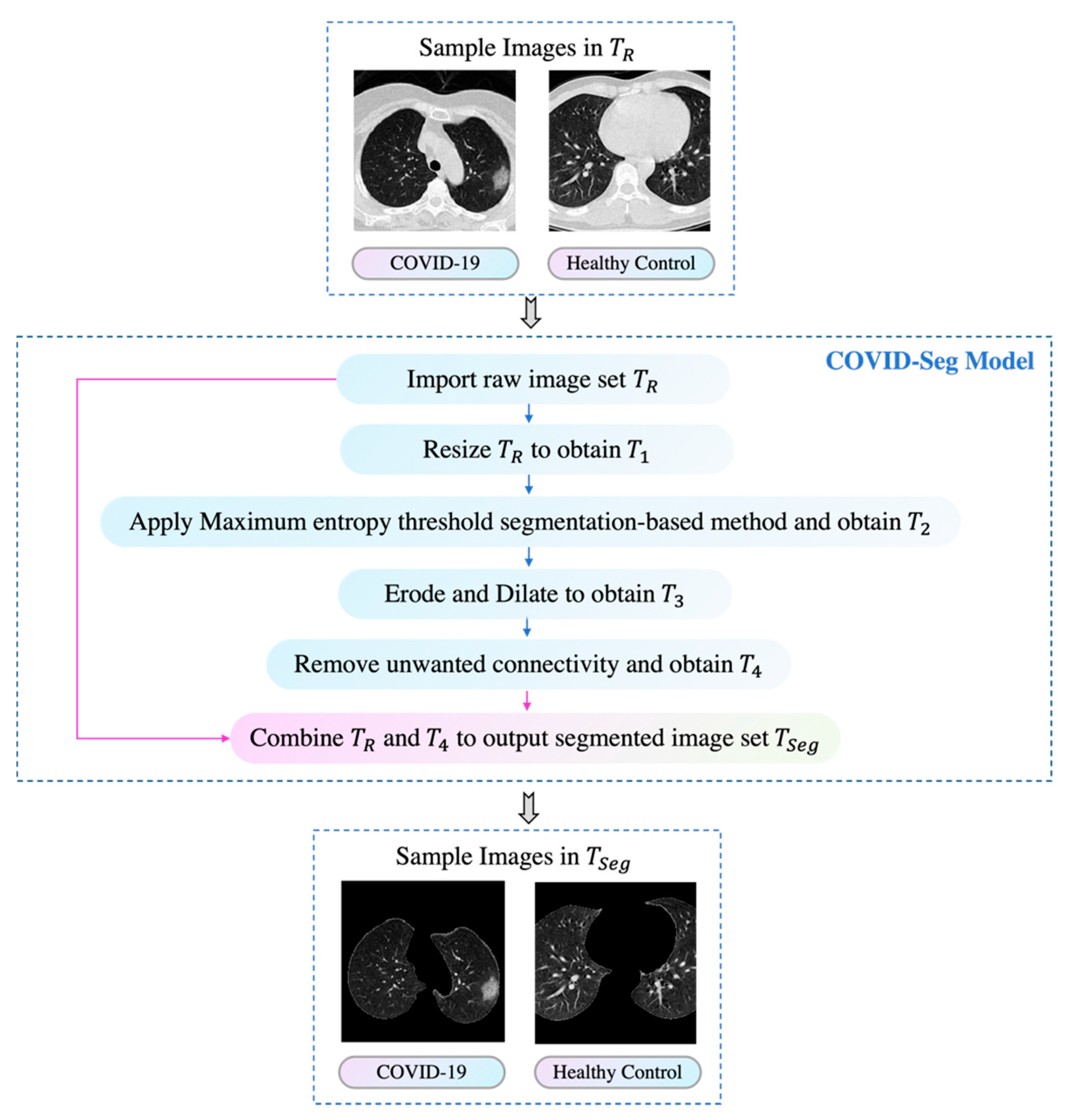
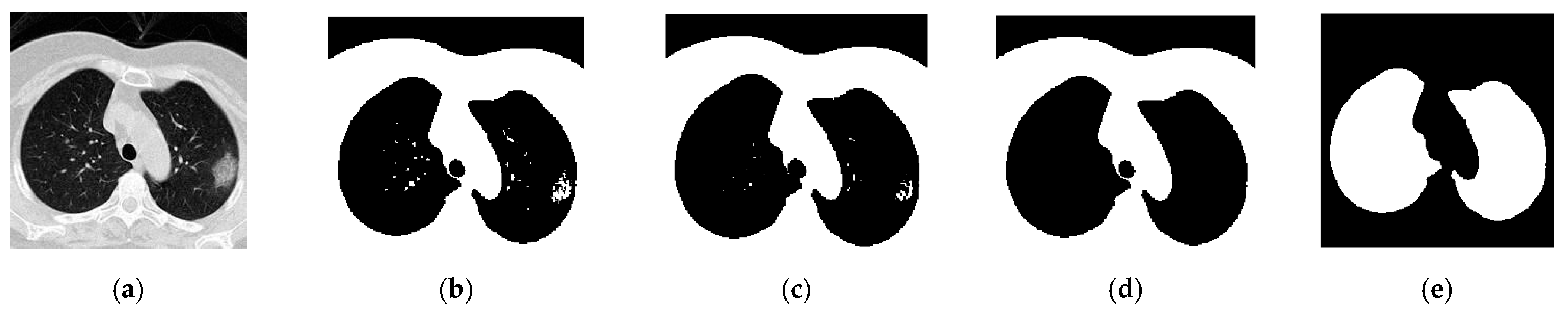
In this study, we linked biomedical research and artificial intelligence together to propose a novel, rapid, stable deep learning framework called CSGBBNet with excellent accuracy for distinguishing between COVID-19 patients and healthy people. There are four main improvements in our study. The first is we proposed a novel image pre-processing model—COVID-Seg based on the Maximum entropy threshold segmentation method, which can accurately outline the lung area. The ‘COVID’ here stands for ‘COVID-19 detection’, and the ‘Seg’ signifies ‘Segmentation process’. The second is, in this COVID-Seg model, we introduced an ‘erosion and dilation’ based process to refine the output segmented image. This is the first time this combination of techniques being applied to the COVID-19 detection field, and the results show that this COVID-Seg model has a very significant effect on improving the model performance. Thirdly, we presented a novel GBBNet through restructuring, retraining the GoogLeNet model, and adding more batch normalization relevant blocks into it. The fourth is, in our GBBNet, we used Bayesian Optimization as the hyperparameter tuning algorithm to find a better choice of hyperparameters rapidly. In the name ‘GBBNet’, the ‘G’ represents ‘GoogLeNet’; the first ‘B’ stands for ‘Batch normalization relevant blocks’; the second ‘B’ stands for ‘Bayesian Optimization’. These four improvements can help enrich the performance of our model specially built for COVID-19 detection.
Section 2,
Section 3,
Section 4 and
Section 5 will introduce the dataset, methodology, experimental results, and conclusions of our study, respectively.
4. Experiments, Results, and Discussion
4.1. Data Splits
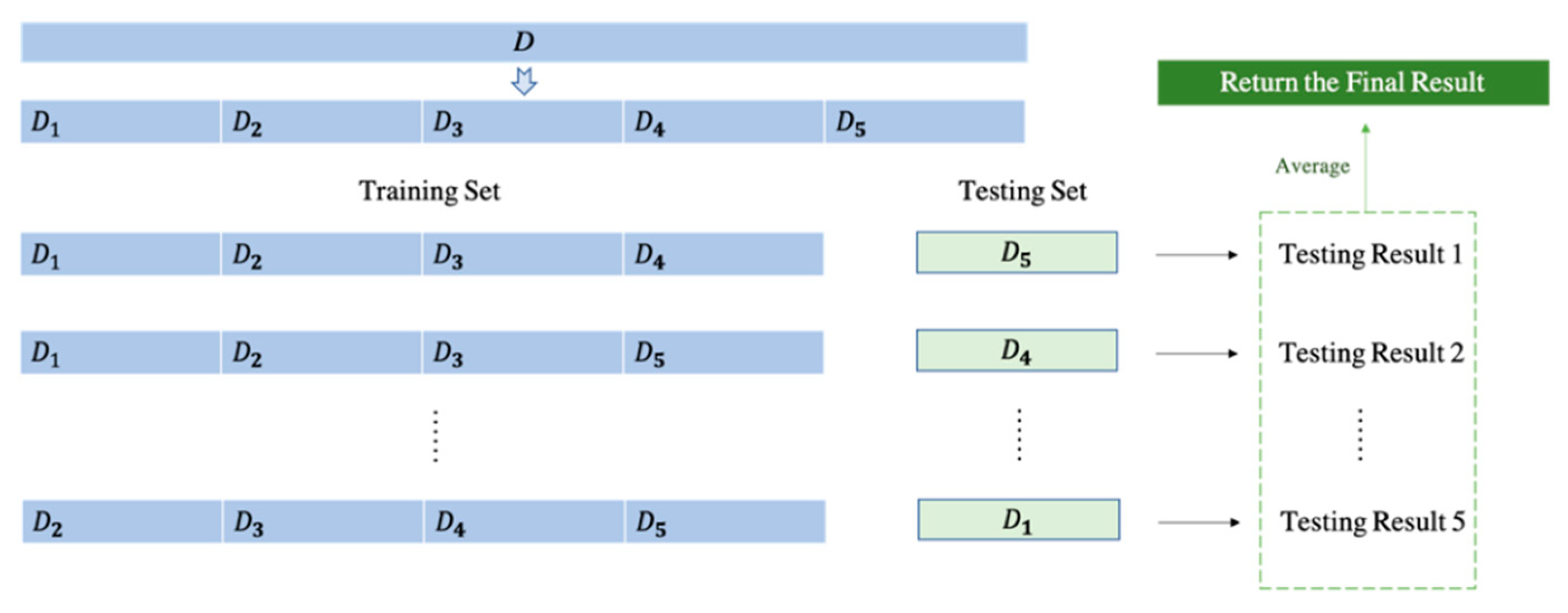
All the experiments were conducted on a laptop with GTX1060. The majority of experiments were written using MATLAB 2020a. To verify the robustness of our framework, we introduced a new benchmark dataset ‘COVID-CT’ with 539 CT scan images. In our experiment, we consider COVID-19 patient images as positive samples and healthy control images as negative samples on both datasets. Due to the reason that we utilized a fivefold cross-validation method, we would have five times of running, and in each running, images are divided into 80% for training, 20% for testing. A clear table for data splits for both the COVID Academic dataset and the new benchmark dataset can be found in
Table 5.
Besides, to comprehensively evaluate the performance of the classifier, we added an evaluation criterion of harmonic average F1 score [
47,
48,
49,
50], which considers the value of both precision and recall according to the equation:
4.2. Statistical Results
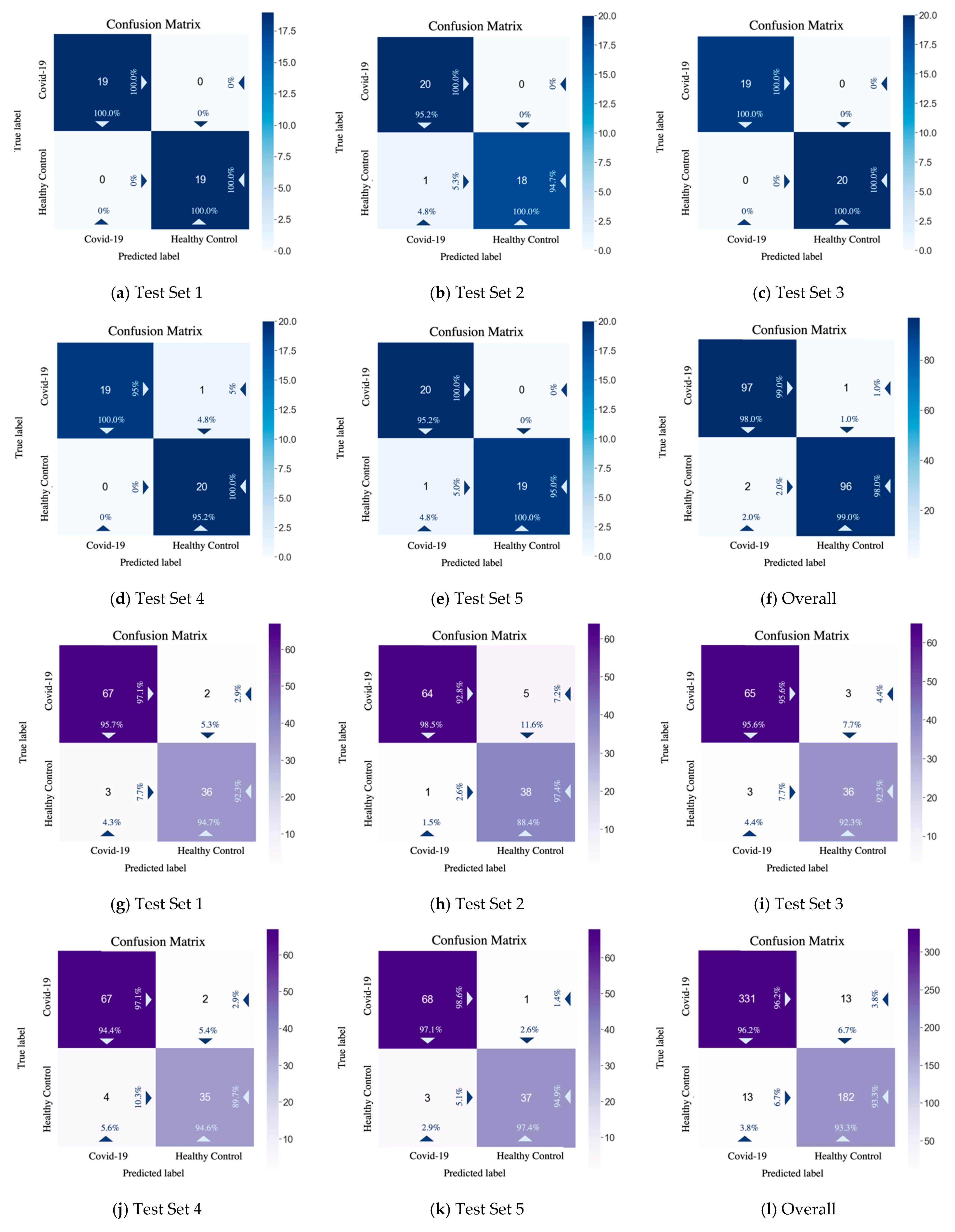
From the test performance and the confusion matrix results displayed in
Table 6 and
Figure 11, on the COVID Academic dataset, CSGBBNet predicted 193 correctly among all the 196 samples. While on the COVID-CT dataset, CSGBBNet achieves a mean accuracy of 95.17
1.22%, and a mean F1 score of 96.21
0.98%, which are higher than the best accuracy (89.1%) and the best F1 score (89.6%) reported in [
46]. This verifies that our framework has excellent robustness when encountered different datasets.
Taking the overall confusion matrix on the COVID Academic dataset as an illustration, the classifier correctly recognized 97 images of ‘COVID-19’ as ‘COVID-19’, 96 images of ‘Healthy Control’ as ‘Healthy Control’ but misidentified two images of ‘Healthy Control’ as ‘COVID-19’ 1 image of ‘COVID-19’ as ‘Healthy Control’. In the upper-left box of the confusion matrix, the value 98.0% means 98.0% of the ‘samples’ predicted as ‘COVID-19’ were classified right and the value 99.0% means 99.0% of the real ‘COVID-19’ samples were classified right. Meanwhile, in the lower-right box, the value 99.0% means 99.0% of the ‘samples’ predicted as ‘Healthy’ were classified right, and the value 98.0% represents 98.0% of the real ‘Healthy’ samples were classified right. In a medical sense, our approach has a very low misdiagnosis rate, especially when the target is a real COVID-19 patient. This is very helpful for practical applications because the high rate of diagnosis of COVID-19 patients can effectively prevent them from the second transmission of the epidemic.
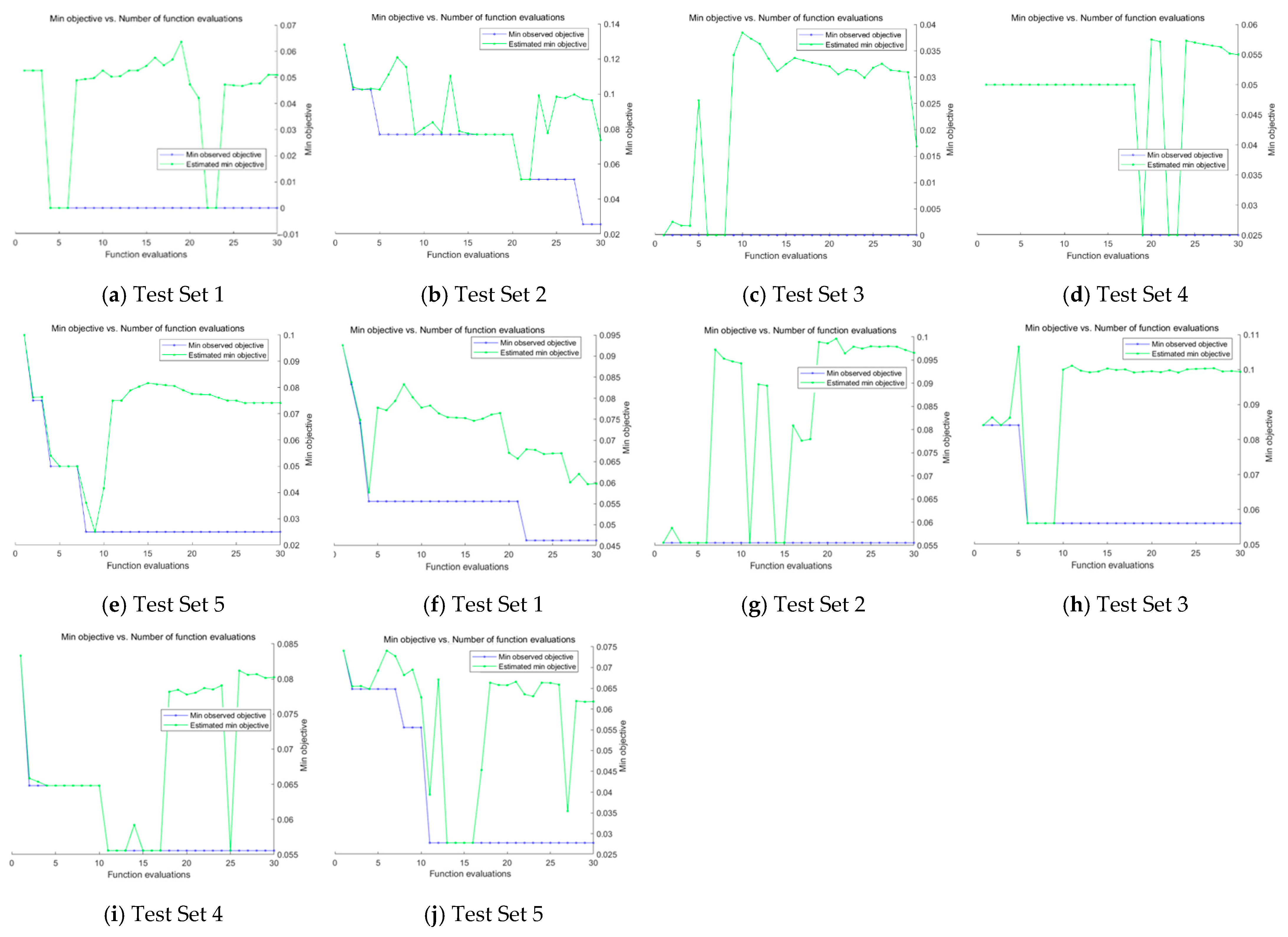
The graphs of minimum objective vs. number of function evaluations achieved during the Bayesian Optimization process on Test Sets in both datasets are shown in
Figure 12, where different combinations of hyperparameter such as ‘initial learning rate’, ‘momentum’, etc. were attempted in the training process to achieve an optimum result. In the next section, we will implement an ablation study to conduct a full analysis of our results.
4.3. Ablation Study
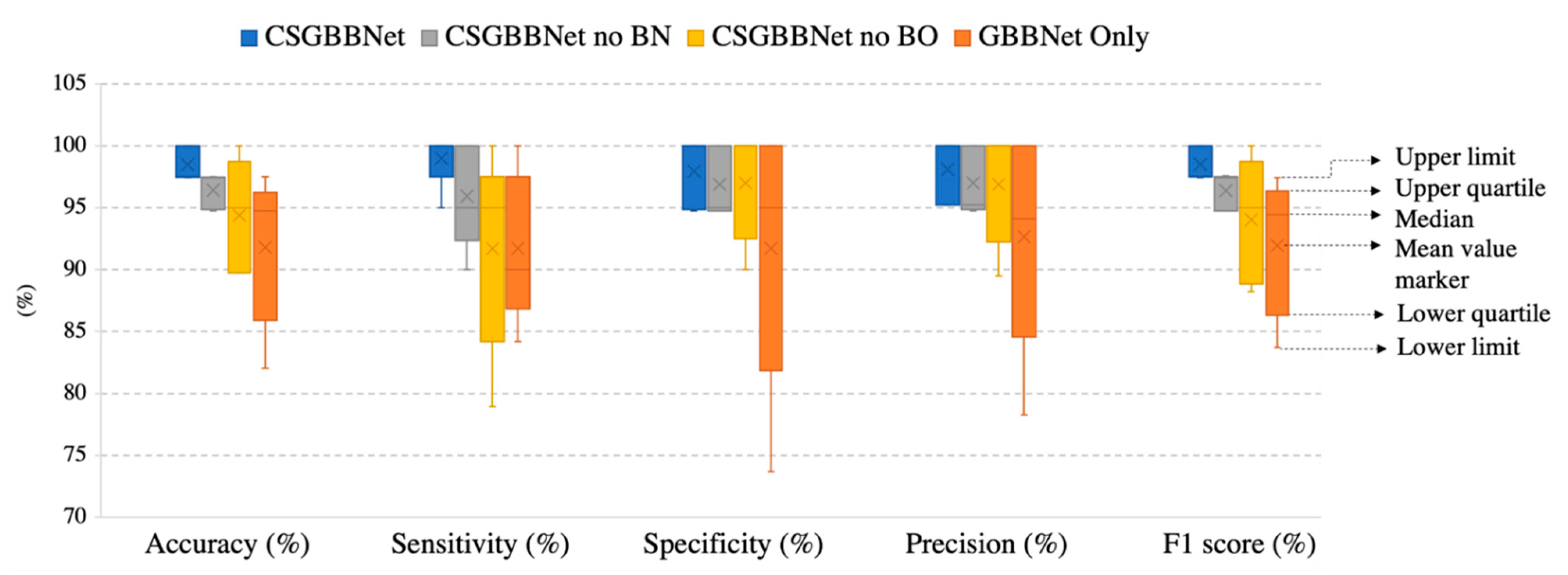
To more explicit verify the effectiveness of different proposed modules in our experiment, we named the framework without utilizing the COVID-Seg model as ‘GBBNet Only’, the model only without newly added designed layers as ‘CSGBBNet no BN’, the model only without Bayesian Optimization module as ‘CSGBBNet no BO’. In this section, all the experiments were conducted on ‘COVID Academic’.
As displayed in
Table 7 and
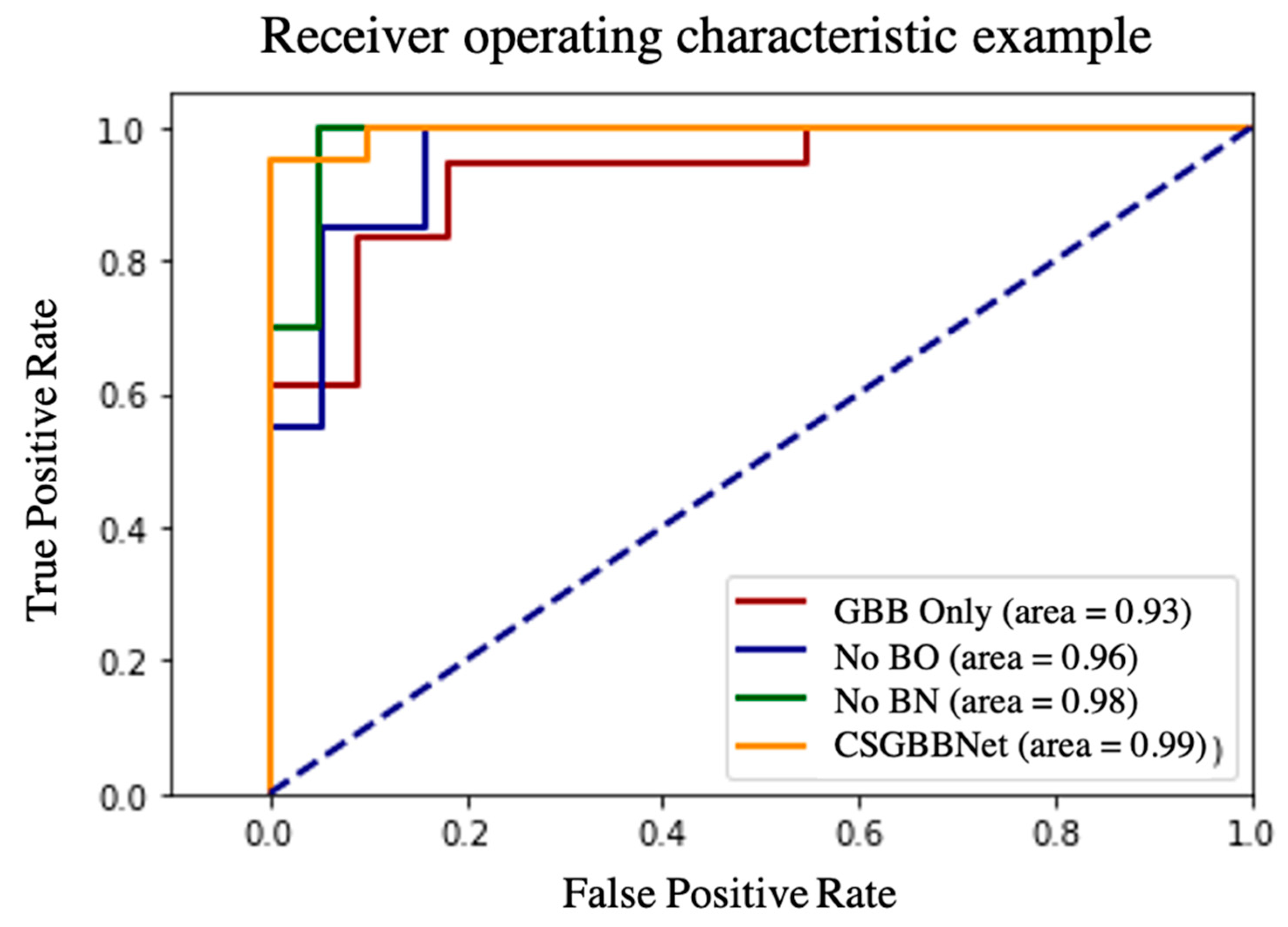
Figure 13, firstly, after introducing the COVID-Seg model, the results in the testing set were significantly improved with the accuracy of 6.68%, the sensitivity of 7.26%, the specificity of 6.21%, the precision of 5.44%, the F1 score of 6.56%, and the standard deviation in a range of 3.36–7.25%. This means our segmentation was very successful and effective. Second, after adding newly designed layers, the accuracy in the testing set improved 2.07%, the sensitivity improved 3.05%, the specificity improved 1.06%, the precision improved 1.10%, the F1 score improved 2.13%, and the stability of results also slightly improved. Third, utilizing Bayesian Optimization can help to find the optimum hyperparameters for the model because all the evaluated criteria have different degrees of improvements: the accuracy improved with 4.11%, the sensitivity improved with 7.32%, the specificity improved with 0.95%, the precision improved with 1.21%, the F1 score improved with 4.48% and the stability improved with 0.16–5.19% revealed by standard deviation. Finally, according to the Receiver operating characteristic (ROC) curve in
Figure 14, the illustrated diagnostic ability of the CSGBBNet classifier system is also superior to those without complete modules.
To sum up, the results above indicate the modules: COVID-Seg model, Bayesian Optimization training algorithm, and newly added layers are all effective in our framework.
4.4. Comparison between CSGBBNet and Other State-of-the-Art Approaches
We compared the proposed CSGBBNet with seven state-of-the-art approaches: WE-BO [
51], GLCM-SVM [
52], GoogLeNet [
29], ResNet18 [
53], DenseNet201 [
54], VGG16 [
40], VGG19 [
40].
In
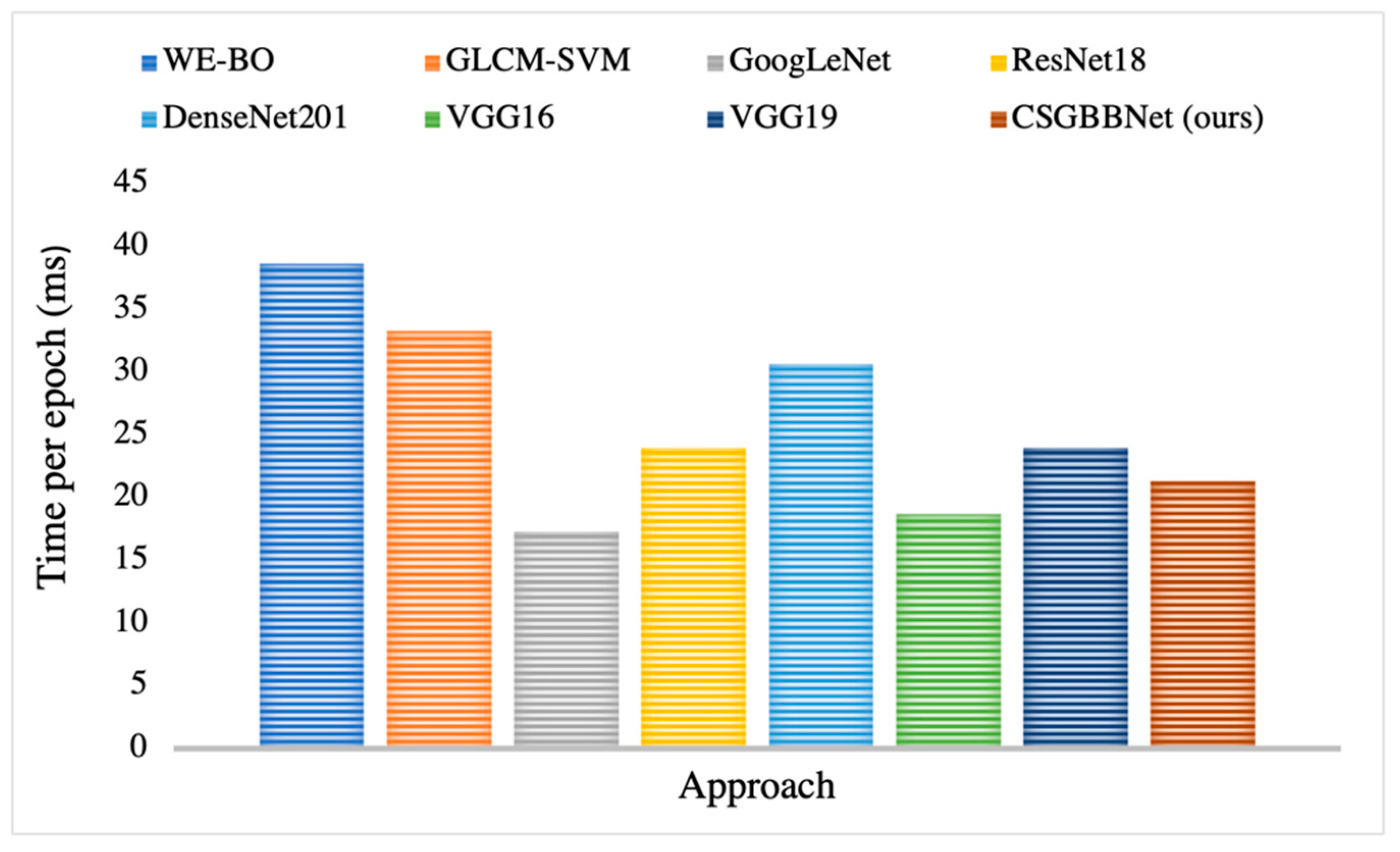
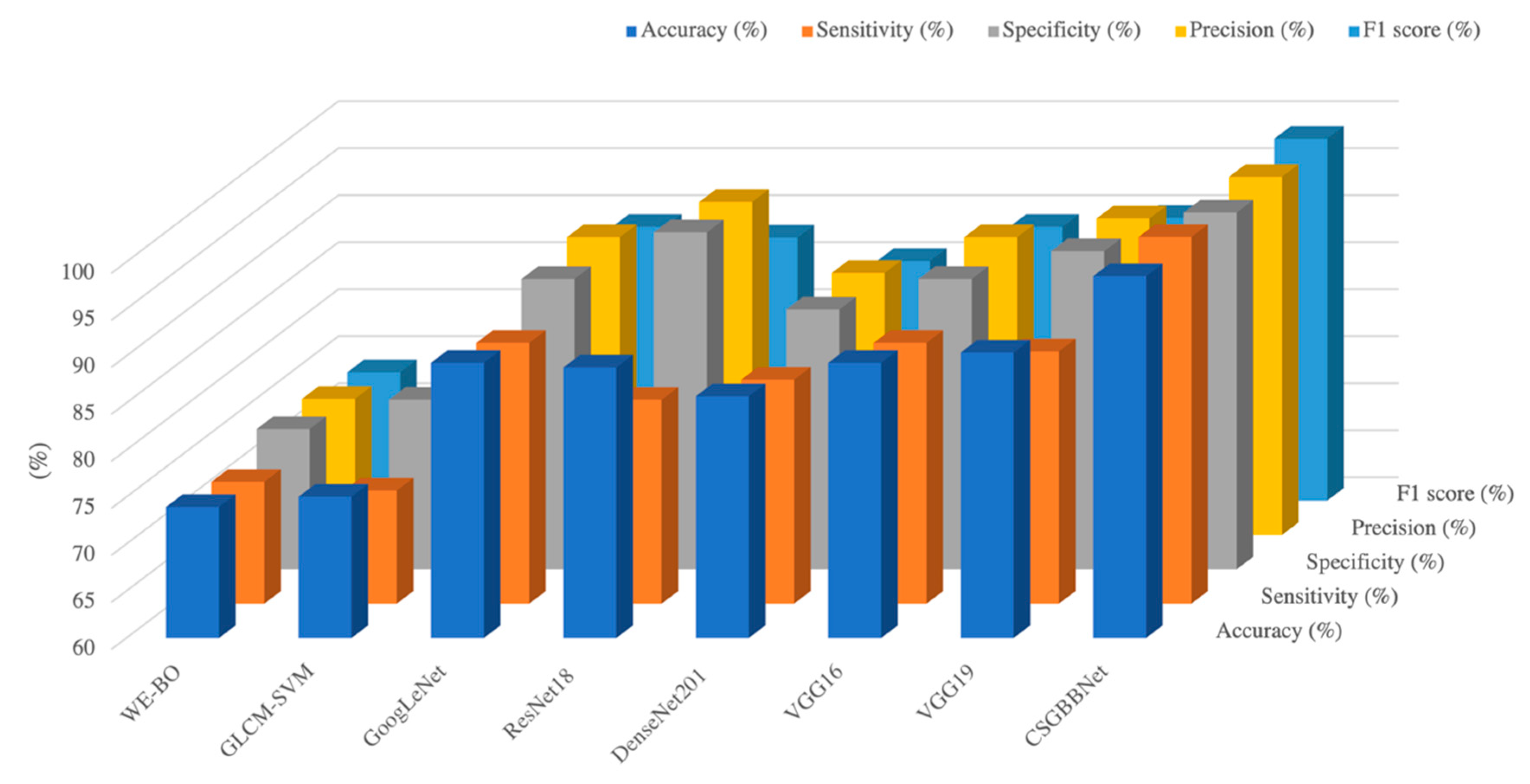
Table 8, when compared with seven state-of-the-art methods on the COVID Academic dataset, CSGBBNet has advantages in terms of most of the performance metrics. The results show excellent stability according to the values provided by standard deviation. And it is clear in
Figure 15 that CSGBBNet presents very good computational efficiency as it performs faster than most other approaches, except the comparative performance with GoogLeNet and VGG16. However, it can be easily observed that the speed difference among them is not significant, and our framework shows a much higher diagnostic rate when compared with GoogLeNet and VGG16.
To conclude for this section, CSGBBNet achieves excellent performance with the mean accuracy of 98.49
1.23%, the sensitivity of 99.00
2.00%, the specificity of 97.95
2.51%, the precision of 98.10
2.61%, and the F1 score of 98.51
1.22%. It is worth mentioning that, as illustrated in
Figure 16, it performs better than seven other state-of-the-art methods in accuracy, specificity, precision, F1 score, and especially the sensitivity criterion of the model. The sensitivity of CSGBBNet is 12.64% higher than the approach ranked second in the table. The reason is we effectively removed the factors in the image that would affect the judgment of the model, such as the regions of the heart, ribs, and thoracic vertebrae. Moreover, our proposed model shows excellent stability, robustness, and very good computational efficiency when compared with other state-of-the-art machine learning approaches and the traditional RT-PCR test methods. In all, CSGBBNet has a low misdiagnosis rate, high stability, and can successfully diagnose multiple slice images within one second, which is of great significance in the practical application of COVID-19 detection.
To further verify if CSGBBNet provides an explainable and promising way to detect COVID-19, gradient-weighted class activation mapping (Grad-CAM) is employed in the next section.
4.5. Explainability of Proposed CSGBBNet
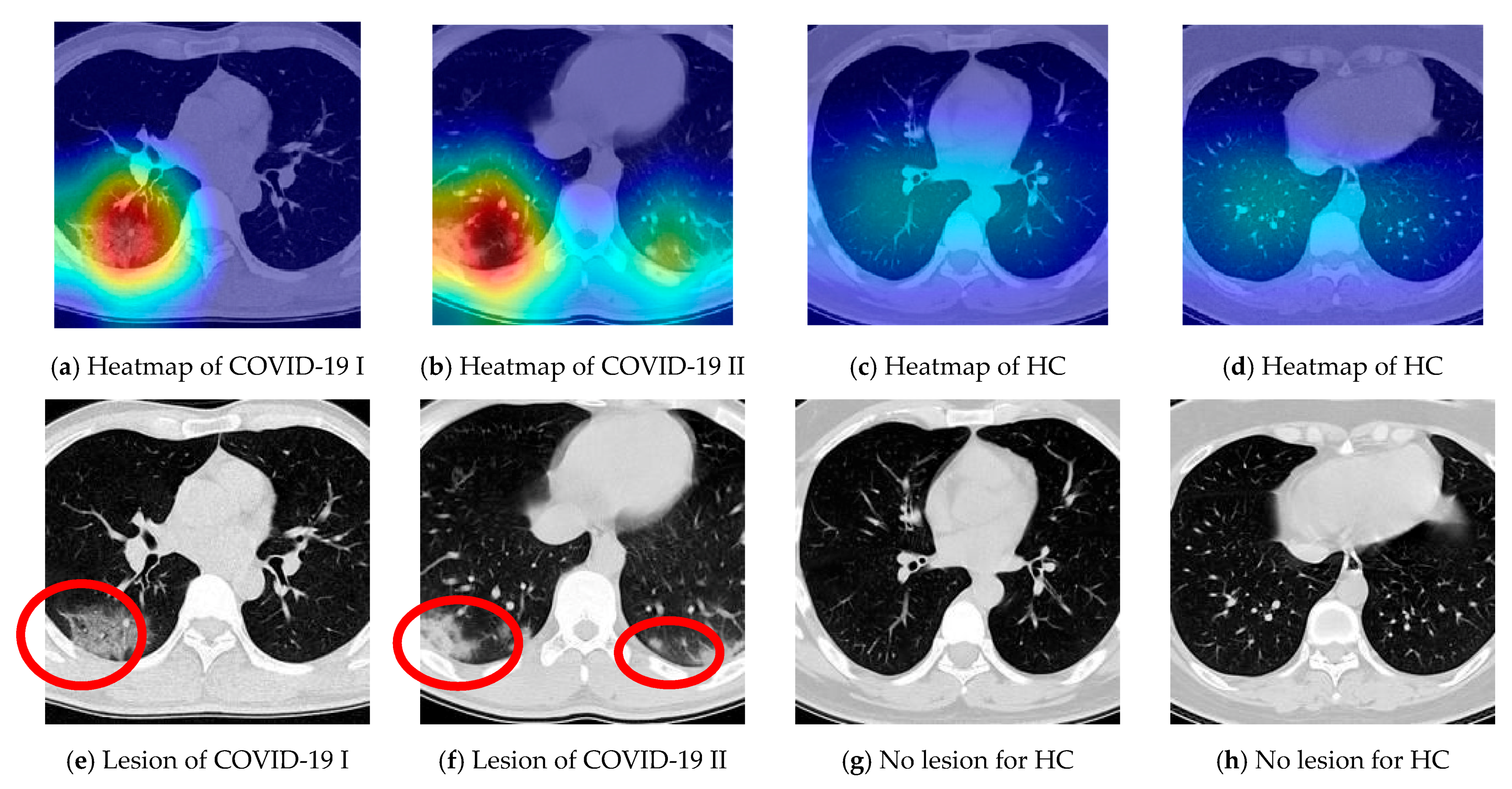
We take samples from the COVID-19 and HC class respectively and display the relevant heatmaps in
Figure 17a–d to verify the explainability of CSGBBNet. The manual delineations of lesion area for them are shown in
Figure 17e–h. These heatmaps were generated utilizing the ‘Inception 5b output’ feature map in GBBNet with the help of the Grad-CAM approach. The red area in the heatmap is the part with strong attention in the model, and the deep blue area is the part with little attention in the model. According to these heatmaps, we can confirm that, for the COVID-19 image (
Figure 17a,b), our framework is paying more attention to the lesion areas and meanwhile paying little attention to the non-lesion areas. While for the HC image (
Figure 17c,d), the attention of the model is not focused on any particular area because there is no lesion area in the healthy control category.
To sum up, the heatmaps provide a clear and understandable interpretation of how our CSGBBNet predicts COVID-19 images from healthy control images. In other words, the concerns of our model are very similar to the standard already approved in the medical community, which adds confidence that it is capable of assisting the diagnosis of doctors, radiologists, and inspectors at each epidemic prevention site in the real world.
5. Conclusions
Chest CT is a rapid, non-invasive method for screening COVID-19. Our proposed deep learning framework CSGBBNet using the COVID-Seg model as an image preprocessing method, GBBNet as a classification method is also an explainable framework to accomplish the classification task. CSGBBNet not only shows advantages in diagnostic rate, stability, and computational efficiency when compared with other state-of-the-art machine learning approaches and traditional RT-PCR tests, but also shares similar concerns with the standard approved in the medical community. Moreover, it shows excellent robustness when encountered with different datasets. To conclude, combining these two techniques can help to realize rapid, effective, stable, and safe detection of COVID-19, which is of great significance to clinical medicine and society.
In the future, we plan to incorporate or learn from more advanced deep learning techniques and revise the model to improve classification efficiency.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}