
Application of Deep Learning to IVC Filter Detection from CT Scans

 ,
,  , and
, and
Abstract
:1. Introduction
2. Artificial Intelligence and Medical Imaging
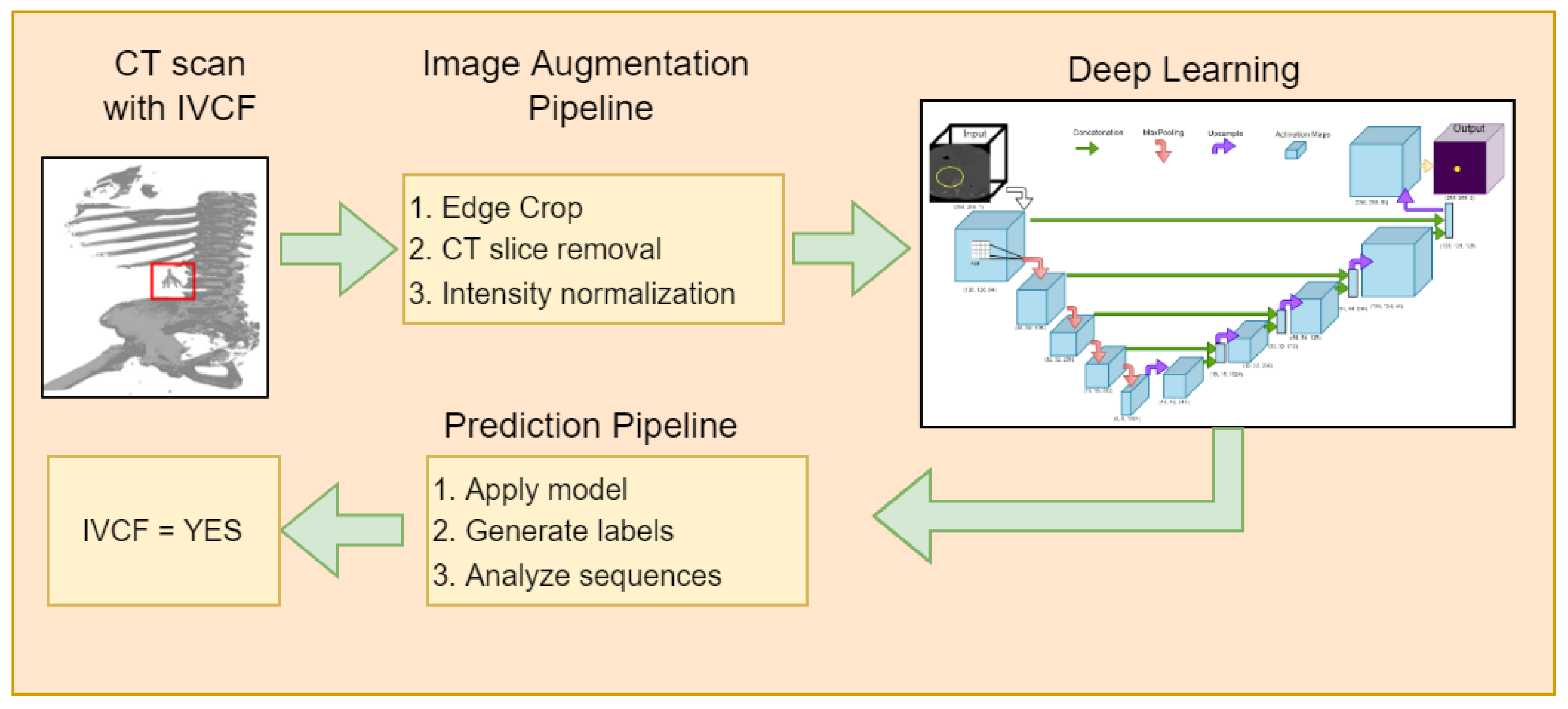
3. Materials and Methods
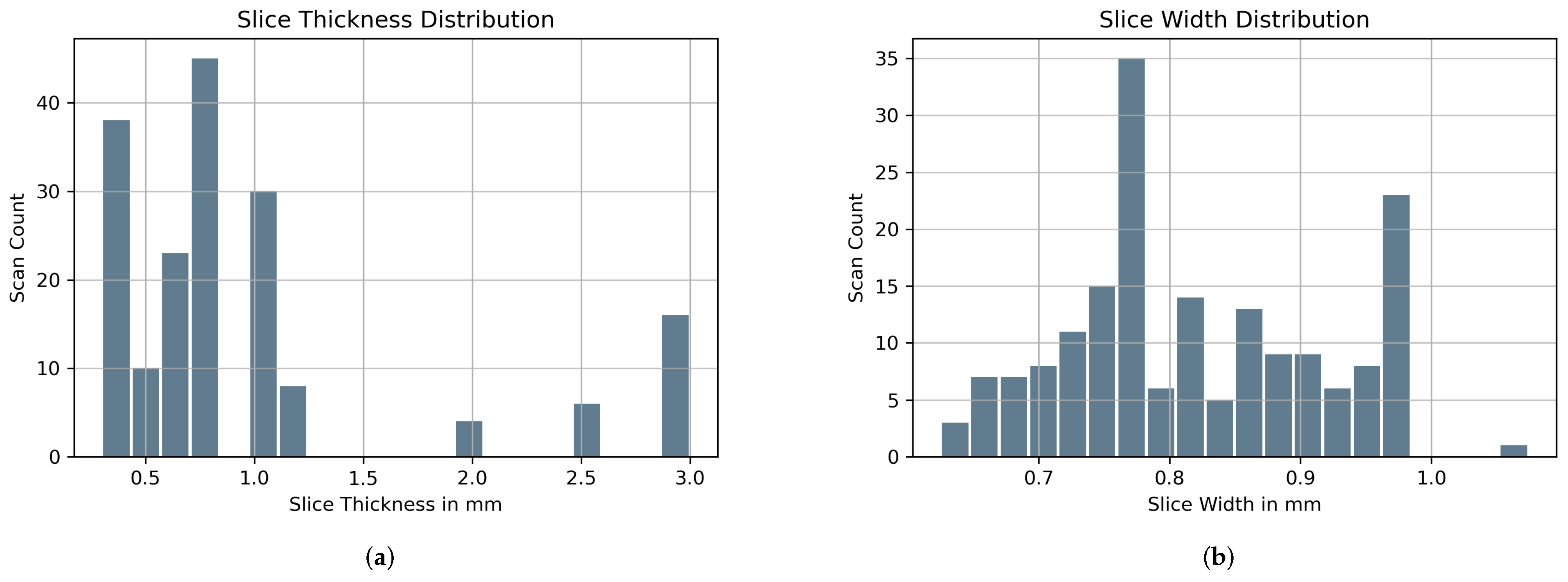
3.1. Dataset
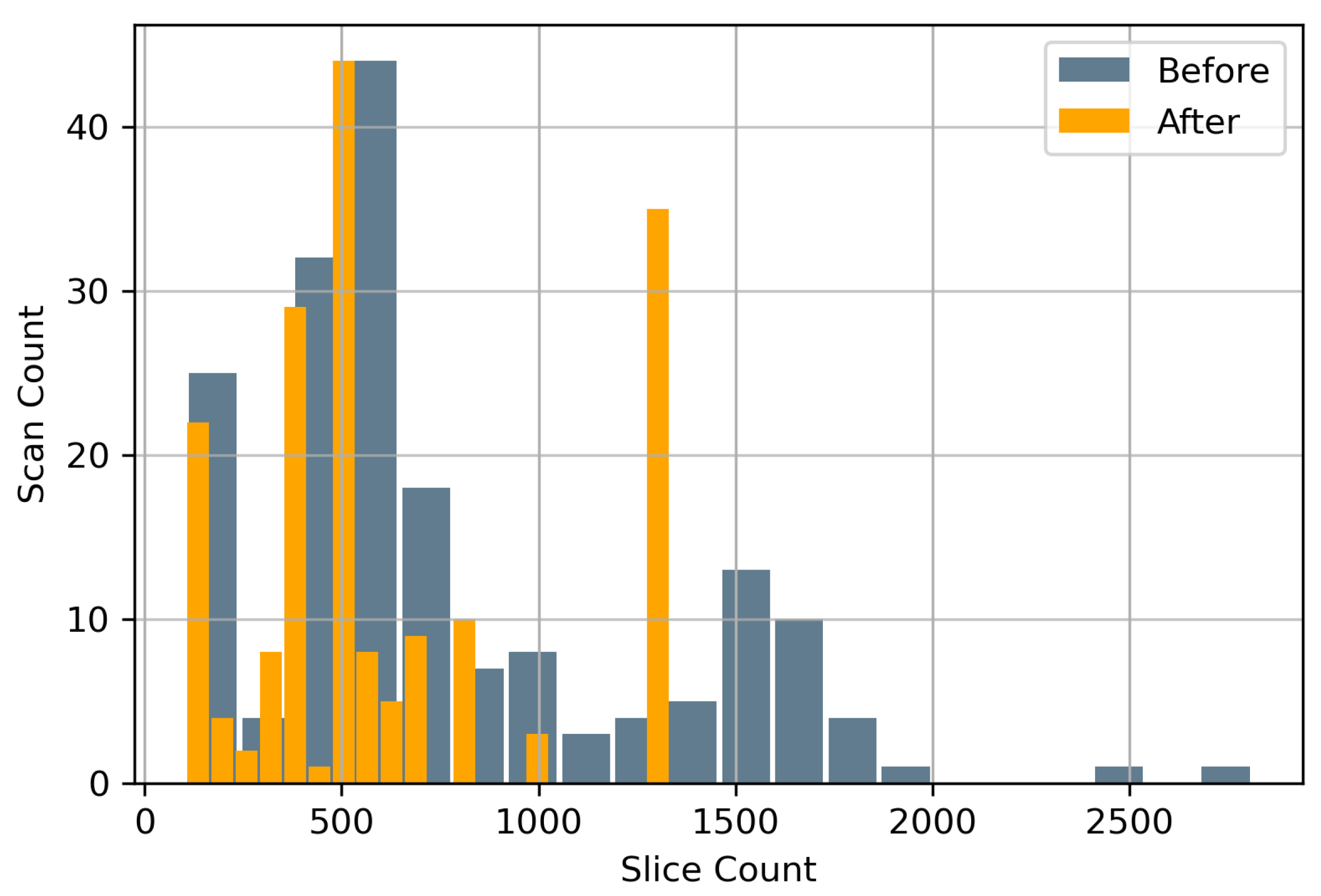
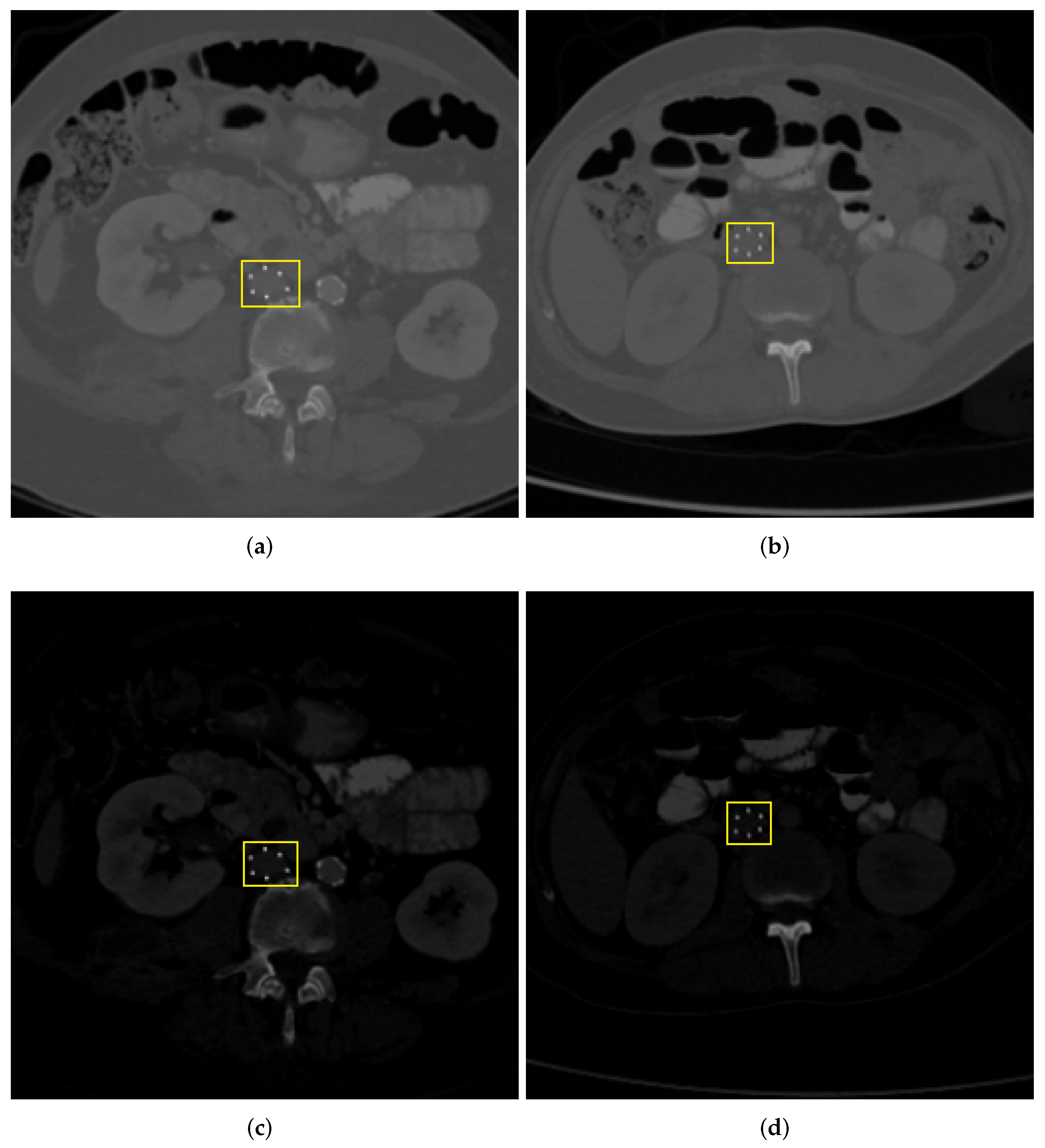
3.2. Spatial Cropping
3.3. Normalization
3.4. Image Augmentation
3.5. Network Architecture
3.6. Training Parameters
3.7. IVCF Prediction Pipeline
| Algorithm 1: IVCF prediction pipeline using the deep learning model |
 |
4. Results
4.1. Segmentation Evaluation
4.2. IVCF Prediction Pipeline Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| IVCF | Inferior Vena Cana Filters |
| HU | Hounsfield Unit |
| IRB | Institutional Review Board |
| ReLU | Rectified Linear Unit |
| VTE | Venous thromboembolism |
Appendix A
| Algorithm A1: IVCF image augmentation algorithm for the deep learning model |
 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
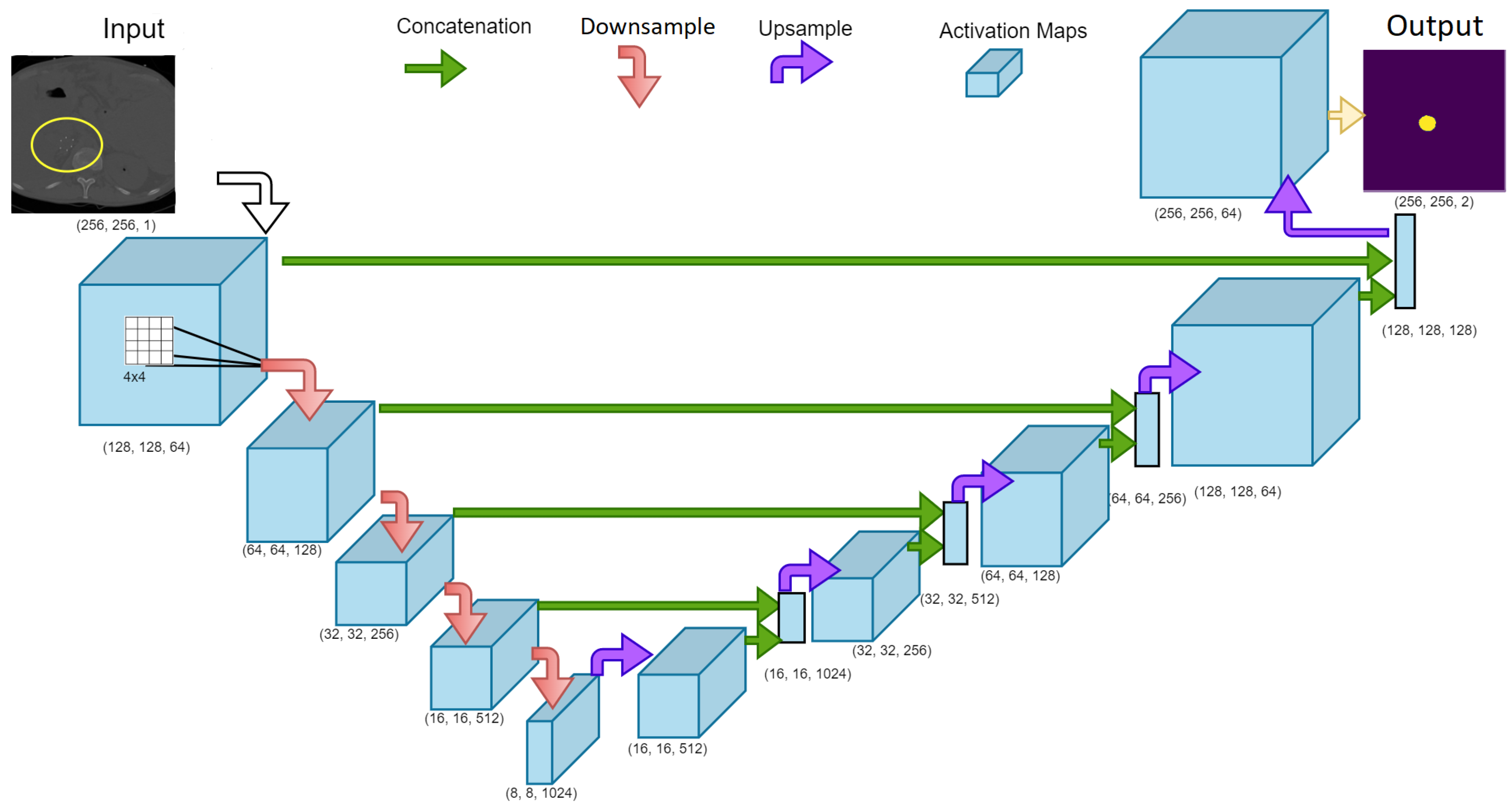{kind=link}
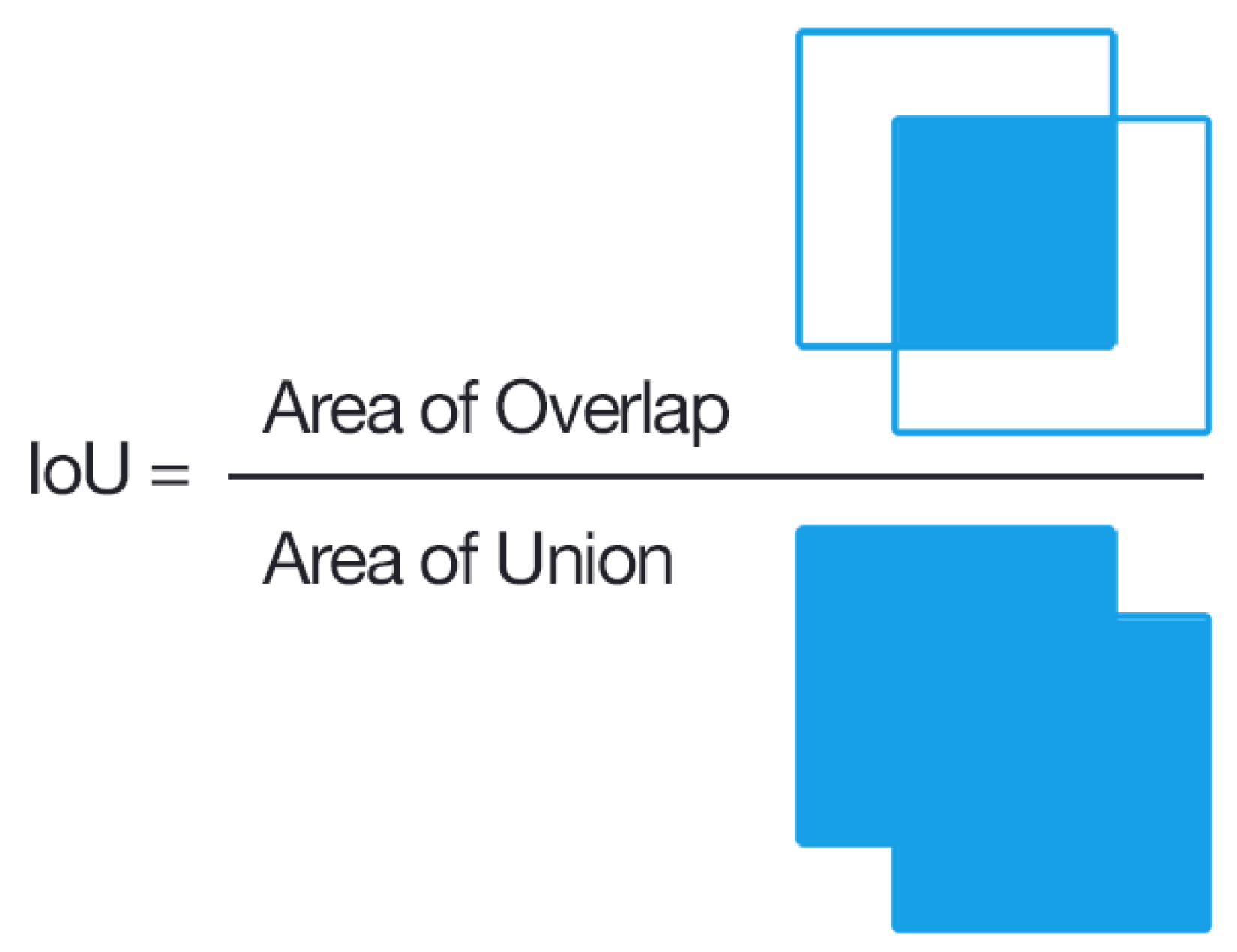{kind=link}
{kind=link}
{kind=link}
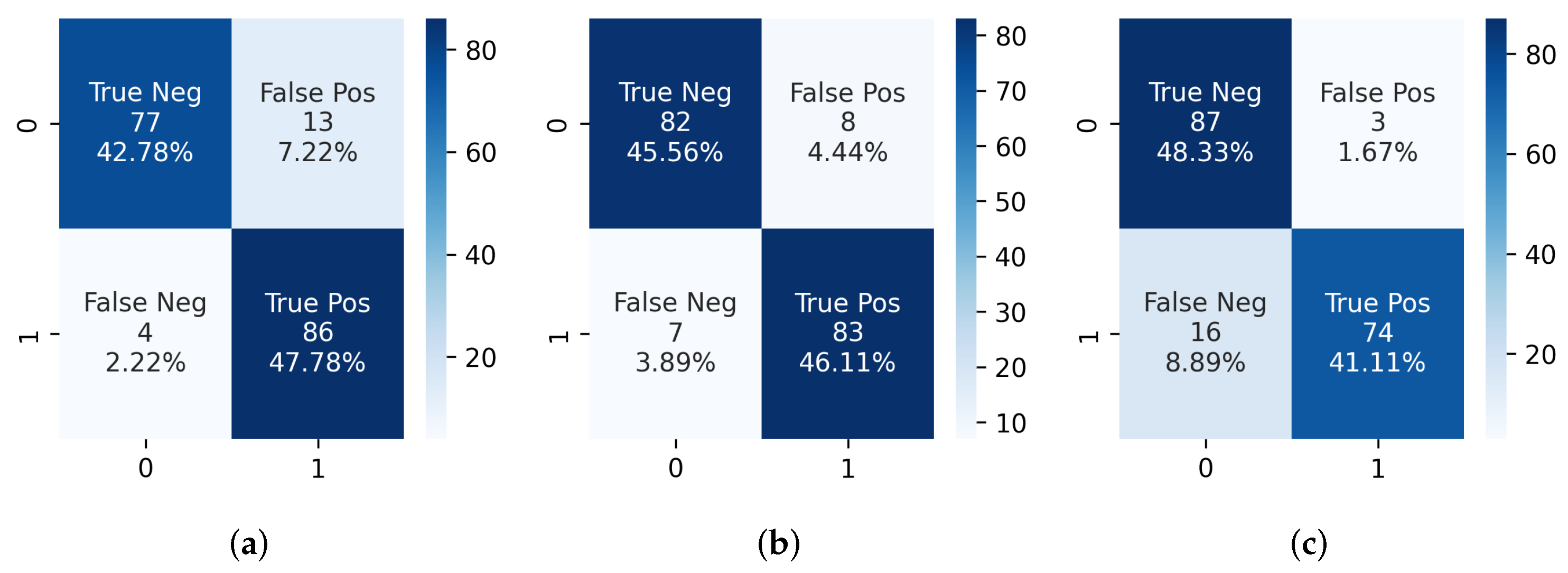{kind=link}
| Layer | Output Shape | Param # |
|---|---|---|
| input_1 | (20, 256, 256, 1) | 0 |
| downsample_1 | (20, 128, 128, 64) | 1024 |
| downsample_2 | (20, 64, 64, 128) | 131,584 |
| downsample_3 | (20, 32, 32, 256) | 525,312 |
| downsample_4 | (20, 16, 16, 512) | 2,099,200 |
| downsample_5 | (20, 8, 8, 1024) | 8,392,704 |
| upsample_1 | (20, 16, 16, 512) | 8,390,656 |
| concatenate_1 | (20, 16, 16, 1024) | 0 |
| upsample_2 | (20, 32, 32, 256) | 4,195,328 |
| concatenate_2 | (20, 32, 32, 512) | 0 |
| upsample_3 | (20, 64, 64, 128) | 1,049,088 |
| concatenate_3 | (20, 64, 64, 256) | 0 |
| upsample_4 | (20, 128, 128, 64) | 262,400 |
| concatenate_4 | (20, 128, 128, 128) | 0 |
| conv2d_ transpose_1 | (20, 256, 256, 64) | 131,136 |
| conv2d_1 | (20, 256, 256, 2) | 2050 |
| Total Parameters | 25,180,482 | |
| Sequence Number, Sig_Count | IVCF Scans | Normal Scans | ||
|---|---|---|---|---|
| Scans Flagged with IVCF (Best Is 90) | % Scans Flagged Correctly | Scans Not Flagged with IVCF (Best Is 90) | % Scans Flagged as Normal | |
| (5, 200) | 89 | 98.8 | 72 | 80 |
| (7, 200) | 89 | 98.8 | 78 | 86.67 |
| (9, 200) | 82 | 91.1 | 83 | 92.22 |
| (5, 300) | 86 | 95.56 | 77 | 85.56 |
| (7, 300) | 83 | 92.22 | 82 | 91.11 |
| (9, 300) | 74 | 82.22 | 87 | 96.67 |
| (5, 400) | 79 | 87.78 | 81 | 90 |
| (7, 400) | 69 | 76.67 | 87 | 96.67 |
| (9, 400) | 55 | 61.11 | 87 | 96.67 |
References
- Uberoi, R.; Tapping, C.R.; Chalmers, N.; Allgar, V. British Society of Interventional Radiology (BSIR) inferior vena cava (IVC) filter registry. Cardiovasc. Interv. Radiol. 2013, 36, 1548–1561. [Google Scholar] [CrossRef] [Green Version]
- Salei, A.; Raborn, J.; Manapragada, P.P.; Stoneburner, C.G.; Aal, A.K.A.; Gunn, A.J. Effect of a dedicated inferior vena cava filter retrieval program on retrieval rates and number of patients lost to follow-up. Diagn. Interv. Radiol. 2020, 26, 40. [Google Scholar] [CrossRef] [PubMed]
- Kaufman, J.A. Retrievable vena cava filters. Tech. Vasc. Interv. Radiol. 2004, 7, 96–104. [Google Scholar] [CrossRef] [PubMed]
- Jia, Z.; Fuller, T.A.; McKinney, J.M.; Paz-Fumagalli, R.; Frey, G.T.; Sella, D.M.; Van Ha, T.; Wang, W. Utility of retrievable inferior vena cava filters: A systematic literature review and analysis of the reasons for nonretrieval of filters with temporary indications. Cardiovasc. Interv. Radiol. 2018, 41, 675–682. [Google Scholar] [CrossRef] [PubMed]
- Durack, J.C.; Westphalen, A.C.; Kekulawela, S.; Bhanu, S.B.; Avrin, D.E.; Gordon, R.L.; Kerlan, R.K. Perforation of the IVC: Rule rather than exception after longer indwelling times for the Günther Tulip and Celect retrievable filters. Cardiovasc. Interv. Radiol. 2012, 35, 299–308. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhou, D.; Obuchowski, N.; Spain, J.; An, T.; Moon, E. Fracture and migration of Celect inferior vena cava filters: A retrospective review of 741 consecutive implantations. J. Vasc. Interv. Radiol. 2013, 24, 1719–1722. [Google Scholar] [CrossRef] [PubMed]
- Medwatch, F. Filters: Initial Communication: Risk of Adverse Events with Long Term Use. 2010. Available online: https://www.eeworldonline.com/inferior-vena-cava-ivc-filters-initial-communication-risk-of-adverse-events-with-long-term-use/ (accessed on 10 August 2022 ).
- Ahmed, O.; Jilani, S.; Heussner, D.; Khan, M. Trapped by controversy: Inferior vena cava filters and the law. J. Vasc. Interv. Radiol. 2017, 6, 886–888. [Google Scholar] [CrossRef] [PubMed]
- Gyang, E.; Zayed, M.; Harris, E.J.; Lee, J.T.; Dalman, R.L.; Mell, M.W. Factors impacting follow-up care after placement of temporary inferior vena cava filters. J. Vasc. Surg. 2013, 58, 440–445. [Google Scholar] [CrossRef] [Green Version]
- Grewal, S.; Chamarthy, M.R.; Kalva, S.P. Complications of inferior vena cava filters. Cardiovasc. Diagn. Ther. 2016, 6, 632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Nargesian, F.; Samulowitz, H.; Khurana, U.; Khalil, E.B.; Turaga, D.S. Learning Feature Engineering for Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2529–2535. [Google Scholar]
- Gomes, R.; Paul, N.; He, N.; Huber, A.F.; Jansen, R.J. Application of Feature Selection and Deep Learning for Cancer Prediction Using DNA Methylation Markers. Genes 2022, 13, 1557. [Google Scholar] [CrossRef]
- Ahsan, M.; Gomes, R.; Chowdhury, M.M.; Nygard, K.E. Enhancing Machine Learning Prediction in Cybersecurity Using Dynamic Feature Selector. J. Cybersecur. Priv. 2021, 1, 199–218. [Google Scholar] [CrossRef]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Jogin, M.; Madhulika, M.; Divya, G.; Meghana, R.; Apoorva, S. Feature extraction using convolution neural networks (CNN) and deep learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bengaluru, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Dara, S.; Tumma, P. Feature extraction by using deep learning: A survey. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 1795–1801. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Ahsan, M.; Gomes, R.; Denton, A. Application of a convolutional neural network using transfer learning for tuberculosis detection. In Proceedings of the 2019 IEEE International Conference on Electro Information Technology (EIT), Brookings, SD, USA, 20–22 May 2019; pp. 427–433. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Markham, B.L.; Barker, J.L. Spectral characterization of the Landsat Thematic Mapper sensors. Int. J. Remote Sens. 1985, 6, 697–716. [Google Scholar] [CrossRef] [Green Version]
- Shah, M.; Alnabelsi, T.; Patil, S.; Reddy, S.; Patel, B.; Lu, M.; Chandorkar, A.; Perelas, A.; Arora, S.; Patel, N.; et al. IVC filters—Trends in placement and indications, a study of 2 populations. Medicine 2017, 96, e6449. [Google Scholar] [CrossRef]
- Henry, J.; Pylypchuk, Y.; Searcy, T.; Patel, V. Adoption of electronic health record systems among US non-federal acute care hospitals: 2008–2015. ONC Data Brief 2016, 35, 2008–2015. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.J.; Kim, N. Deep learning in medical imaging. Neurospine 2019, 16, 657. [Google Scholar] [CrossRef] [Green Version]
- Setio, A.A.A.; Ciompi, F.; Litjens, G.; Gerke, P.; Jacobs, C.; Van Riel, S.J.; Wille, M.M.W.; Naqibullah, M.; Sánchez, C.I.; Van Ginneken, B. Pulmonary nodule detection in CT images: False positive reduction using multi-view convolutional networks. IEEE Trans. Med. Imaging 2016, 35, 1160–1169. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-net and its variants for medical image segmentation: A review of theory and applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Nisar, H.; Carnahan, P.K.; Fakim, D.; Akhuanzada, H.; Hocking, D.; Peters, T.M.; Chen, E.C. Towards ultrasound-based navigation: Deep learning based IVC lumen segmentation from intracardiac echocardiography. In Medical Imaging 2022: Image-Guided Procedures, Robotic Interventions, and Modeling; SPIE: Bellingham, WA, USA, 2022; Volume 12034, pp. 467–476. [Google Scholar]
- Alakwaa, W.; Nassef, M.; Badr, A. Lung cancer detection and classification with 3D convolutional neural network (3D-CNN). Lung Cancer 2017, 8, 409. [Google Scholar] [CrossRef] [Green Version]
- Liao, F.; Liang, M.; Li, Z.; Hu, X.; Song, S. Evaluate the malignancy of pulmonary nodules using the 3-d deep leaky noisy-or network. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3484–3495. [Google Scholar] [CrossRef] [PubMed]
- Hooda, R.; Sofat, S.; Kaur, S.; Mittal, A.; Meriaudeau, F. Deep-learning: A potential method for tuberculosis detection using chest radiography. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 497–502. [Google Scholar]
- Kant, S.; Srivastava, M.M. Towards automated tuberculosis detection using deep learning. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1250–1253. [Google Scholar]
- Liu, B.; Liu, Y.; Pan, X.; Li, M.; Yang, S.; Li, S.C. DNA methylation markers for pan-cancer prediction by deep learning. Genes 2019, 10, 778. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diamant, A.; Chatterjee, A.; Vallières, M.; Shenouda, G.; Seuntjens, J. Deep learning in head & neck cancer outcome prediction. Sci. Rep. 2019, 9, 2764. [Google Scholar]
- Tiwari, M.; Bharuka, R.; Shah, P.; Lokare, R. Breast Cancer Prediction Using Deep Learning and Machine Learning Techniques. 2020. Social Science Research Network. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3558786 (accessed on 1 August 2022).
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A semi-supervised deep learning method based on stacked sparse auto-encoder for cancer prediction using RNA-seq data. Comput. Methods Programs Biomed. 2018, 166, 99–105. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A deep learning-based multi-model ensemble method for cancer prediction. Comput. Methods Programs Biomed. 2018, 153, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning applications for COVID-19. J. Big Data 2021, 8, 18. [Google Scholar] [CrossRef]
- Gomes, R.; Kamrowski, C.; Langlois, J.; Rozario, P.; Dircks, I.; Grottodden, K.; Martinez, M.; Tee, W.Z.; Sargeant, K.; LaFleur, C.; et al. A Comprehensive Review of Machine Learning Used to Combat COVID-19. Diagnostics 2022, 12, 1853. [Google Scholar] [CrossRef]
- El-Rashidy, N.; Abdelrazik, S.; Abuhmed, T.; Amer, E.; Ali, F.; Hu, J.W.; El-Sappagh, S. Comprehensive survey of using machine learning in the COVID-19 pandemic. Diagnostics 2021, 11, 1155. [Google Scholar] [CrossRef]
- Dairi, A.; Harrou, F.; Zeroual, A.; Hittawe, M.M.; Sun, Y. Comparative study of machine learning methods for COVID-19 transmission forecasting. J. Biomed. Inform. 2021, 118, 103791. [Google Scholar] [CrossRef]
- Hong, J.; Zhang, Y.D.; Chen, W. Source-free unsupervised domain adaptation for cross-modality abdominal multi-organ segmentation. Knowl.-Based Syst. 2022, 250, 109155. [Google Scholar] [CrossRef]
- Hong, J.; Yu, S.C.H.; Chen, W. Unsupervised domain adaptation for cross-modality liver segmentation via joint adversarial learning and self-learning. Appl. Soft Comput. 2022, 121, 108729. [Google Scholar] [CrossRef]
- Hong, J.; Cheng, H.; Wang, S.H.; Liu, J. Improvement of cerebral microbleeds detection based on discriminative feature learning. Fundam. Inform. 2019, 168, 231–248. [Google Scholar] [CrossRef]
- Ni, J.C.; Shpanskaya, K.; Han, M.; Lee, E.H.; Do, B.H.; Kuo, W.T.; Yeom, K.W.; Wang, D.S. Deep learning for automated classification of inferior vena cava filter types on radiographs. J. Vasc. Interv. Radiol. 2020, 31, 66–73. [Google Scholar] [CrossRef]
- Park, B.J.; Sotirchos, V.S.; Adleberg, J.; Stavropoulos, S.W.; Cook, T.S.; Hunt, S.J. Feasibility and visualization of deep learning detection and classification of inferior vena cava filters. medRxiv 2020. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Vesal, S.; Ravikumar, N.; Maier, A. SkinNet: A deep learning framework for skin lesion segmentation. In Proceedings of the 2018 IEEE Nuclear Science Symposium and Medical Imaging Conference Proceedings (NSS/MIC), Sydney, Australia, 10–17 November 2018; pp. 1–3. [Google Scholar]
- Gomes, R.; Rozario, P.; Adhikari, N. Deep learning optimization in remote sensing image segmentation using dilated convolutions and ShuffleNet. In Proceedings of the 2021 IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; pp. 244–249. [Google Scholar]
- Irwin, S.; Feldman, G. An isotropic 3 × 3 image gradient operator. Present. Stanf. Proj. 2014. Available online: https://www.researchgate.net/publication/281104656_An_Isotropic_3x3_Image_Gradient_Operator (accessed on 10 August 2022).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]










| UNet Model | Normalize | Dataset | Dice Scores | |
|---|---|---|---|---|
| Background | IVCF | |||
| 1 | Hard | Training | 0.9981 | 0.8168 |
| Validation | 0.9979 | 0.7981 | ||
| 2 | Soft | Training | 0.9969 | 0.7153 |
| Validation | 0.9970 | 0.7082 | ||
| Combination | Accuracy | Sensitivity | Specificity | Precision | F1 Score |
|---|---|---|---|---|---|
| 300, 5 | 90.56% | 0.9556 | 0.8556 | 0.8687 | 0.9101 |
| 300, 7 | 91.67% | 0.92 | 0.9111 | 0.9121 | 0.9171 |
| 300, 9 | 89.44% | 0.8222 | 0.9667 | 0.961 | 0.8862 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, R.; Kamrowski, C.; Mohan, P.D.; Senor, C.; Langlois, J.; Wildenberg, J. Application of Deep Learning to IVC Filter Detection from CT Scans. Diagnostics 2022, 12, 2475. https://doi.org/10.3390/diagnostics12102475
Gomes R, Kamrowski C, Mohan PD, Senor C, Langlois J, Wildenberg J. Application of Deep Learning to IVC Filter Detection from CT Scans. Diagnostics. 2022; 12(10):2475. https://doi.org/10.3390/diagnostics12102475
Chicago/Turabian StyleGomes, Rahul, Connor Kamrowski, Pavithra Devy Mohan, Cameron Senor, Jordan Langlois, and Joseph Wildenberg. 2022. "Application of Deep Learning to IVC Filter Detection from CT Scans" Diagnostics 12, no. 10: 2475. https://doi.org/10.3390/diagnostics12102475
APA StyleGomes, R., Kamrowski, C., Mohan, P. D., Senor, C., Langlois, J., & Wildenberg, J. (2022). Application of Deep Learning to IVC Filter Detection from CT Scans. Diagnostics, 12(10), 2475. https://doi.org/10.3390/diagnostics12102475