1. Introduction
Diabetes is caused by an accumulation of glucose in the bloodstream [
1]. Diabetes puts a person at risk for various ailments, such as renal failure, loss of eyesight, teeth bleeding, nerve failure, lower limb seizure, stroke, heart failure, and so on [
2]. Diabetic neuropathy is caused by the destruction of kidney nephrons, while diabetic retinopathy is caused by the injury in the brain neurons, which leads to retinal infection and can progressively impair eyesight at an early stage [
3]. As a result, diabetic individuals must have comprehensive eye examinations during which the retina has to be examined by an ophthalmologist. Optical coherence tomography, fundus fluorescein angiography, slit lamp biomicroscopy, and fundus imaging are some of the methods used to identify the afflicted eye [
4].
In accordance with the survey conducted by the World Health Organization (WHO), diabetes [
5] is the seventh most deadly disease. Furthermore, with the supplementary statistics, there has been a high increment of diabetic patients which climbed up to 422 million. According to data, the number of diabetes-afflicted people over the age of 18 has increased from 4.7 percent to 8.5 percent, while some of the poorest persons are more likely to get diabetes. The maximum increase in glucose level has a significant impact on blood vessels, causing seeping of blood from the eyes and weakening of the human visual system [
6]. Humans, on the other hand, are born with the power to cure the sickness. When the brain recognizes blood leaking, it stimulates the surrounding tissues to deal with the situation. As a result, it causes the sporadic formation of new blood vessels, but the resulting cells are anemic [
7].
Retinal fundus image analysis is a helpful medical processing operation. Ophthalmologists can employ retinal blood vessel segmentation to help them diagnose a variety of eye problems [
8]. As a result, diseases including diabetic retinopathy, hypertension, atherosclerosis, and macular degeneration can alter the morphology of the arteries, thereby producing alterations in their diameter, tortuosity, and branching angle. Manually segmenting retinal vascular diseases is a time-consuming and skillful operation.
The severity of the illness can be determined by the abnormal size of any afflicted body component. There are a few forecasting models that are regarded as important concepts, such as exudate, venous beading, microaneurysms, and hemorrhaging. Microaneurysms are blood clots that are 100–120 µm in diameter and have a round form [
9]. Hemorrhage [
10] is produced by a large quantity of blood leaking from a damaged blood vessel. Neovascularization is the term for the unequal expansion of blood vessels. Non-proliferative DR (NPDR) and proliferative DR (PDR) are the two types of DR. As a result, the DR sample indicates various levels, as illustrated in
Table 1.
Early prediction of DR can play a significant role in preventing vision loss. Further, the structural change as a result of the vascular system may provide physical signs for the disease; hence, medical specialists advise patients to receive annual retinal screening tests utilizing dilated eye exams [
11]. Interestingly, these retina scans might be used to detect diabetes, although this would necessitate ophthalmologists’ general judgment, which could take time.
Deep Learning techniques have demonstrated superior performance in the identification of DR, with a high level of accuracy which distinguishes them from other models. Undoubtedly, DL can uncover hidden elements in images that medical specialists would never see. Due to its capability in feature extraction and training in discriminating between multi-classes, the convolutional neural network (CNN) is the most commonly used DL approach in the medical system [
12]. On several medical datasets, the transfer learning (TL) approach has also made it easier to retrain deep neural networks quickly and reliably [
13,
14].
Several machine vision applications are so complex that they cannot be solved with just one algorithm, which has prompted the design of models that incorporate two or more of the methodologies investigated. The weighted fusion strategy involves more than one model to tackle this challenge, since models are selected based on the problem’s specifications and feature extraction. By combining the features derived from a single model in a weighted manner, this procedure was developed to help single models mitigate their defects and enhance their strengths. This technique decreases prediction variance while reducing generalization error. As a result, the purpose of this research is to evaluate the effectiveness of weight-fusing neural network models for identification of DR which aids in the reduction of vision loss caused by DR and reduces the stress and time-consumption of ophthalmologists.
The remaining sections of this article is outlined in the following manner:
Section 2 discusses the related work of DR algorithms;
Section 3 explains the method behind our suggested approach;
Section 4 presents the experimental findings and model evaluation.
Section 5 presents the discussion of our study; and lastly, a conclusion is written in
Section 6.
2. Literature Review
In hospitals, medical practitioners carry out a comprehensive dilated eye exam, where drops are put in a patient’s eyes, allowing the examiner to see inside the eyes more clearly and examine for abnormalities. Fluorescein angiography is another diagnosis method involving the injection of yellow dye called fluorescein into a vein in a patient’s arm. This dye passes through the blood vessels and into the body [
2]. As the dye flows through the retina’s blood vessels, a unique camera captures pictures of it. This determines whether any blood vessels are clogged or leaking fluid, along with the amount of edema in the macula. It also reveals whether or not any aberrant blood vessels are forming. OCT angiography is a modern technology that examines blood arteries without the use of dye. Optical coherence tomography (OCT) is a type of diagnosis method that uses light to create images (OCT). The images produced by this test provide cross-sectional images of the retina, which reveal the thickness of the retina. This will assist in identifying how much fluid has leaked into the retinal tissue, if any at all. OCT tests may then be used to track how well the therapy is functioning [
8].
Additionally, some research articles have presented DR diagnosis based on precise lesions or clinical indications, for example, Glucose, LDL-Cholesterol, and HbAIs [
11]. An analysis by the Ref. [
11] identified risk factors and ranked HbAIs, LDL-cholesterol, and glucose as the most influential risk factors. Utilising these factors, machine learning models were developed to identify the diabetic patient from non-diabetic patients. Aslan et al. [
15] proposed a preprocessing and filtering conversion strategy to achieve fundus scan segmentation by making the blood vessel more noticeable when extracting the features. The Top-Hat transform, Adaptive threshold, and Gabor filter were the specific preprocessing procedures adopted. According to the authors, their approach had a high accuracy rate of 94.59%.
Further, some researchers have provided reports using the deep learning framework. Gulshan et al. [
16] suggested the utilization of Inception V3 to detect RDR trained on 128,000 images of fundus and obtained 99.1% and 97.5%, respectively. Shankar et al. [
5] introduced the HPTI-v4 diagnostic model for classifying DR, which achieved a very high accuracy level of 99.49%, specificity level of 99.68%, and sensitivity level of 98.83%. A strategy of the weighted fusion of pre-processed images for the classification of healthy and RDR was suggested by the authors in the Ref. [
17] by utilizing the mixture of a residual network and decision tree algorithm. The authors reported 93% sensitivity, 94% AUC, and 87% specificity.
Shanthi et al. [
18] reported an average accuracy level of 96.25% after making structural modifications to the AlexNet framework utilizing the Messidor dataset. DCNN was suggested by the authors of the Ref. [
19] for the segmentation and detection of DR lesions. New biomarkers were revealed when heatmaps were applied to the DR images. The authors reported a 95% ROC value on the Kaggle dataset. With the utilization of the Messidor dataset, a study in the Ref. [
20] suggested Inception-ResNet-V2 with the Moth optimization approach to extract features for classifying fundus images. The authors recorded 99.12% accuracy and 97.91% sensitivity.
A scheme that combines decision tree and bootstrap for the formulation of a double-channel process for segmenting fundus images was proposed in the Ref. [
21]. A combined scheme of visual captioning and accelerated efficient properties which is based on CNN was developed by authors of the Ref. [
22] to extract delicate local information. With the utilization of the Messidor dataset, the authors of the Ref. [
23] incorporated an attention algorithm into a pre-trained model to find patch locations, commonly for DR detection. A re-scaling scheme called SI2DRNet-v1 was suggested by the authors in the Ref. [
24], where the size of the kernel is scaled down. In the Ref. [
25], the authors created a technique for locating blood veins along with a pretreatment for bound component analysis. The dimensionality was then reduced using linear separation analysis. In their technique, SVM was utilized for classification.
Additionally, the LeNet model was suggested by the authors of the Ref. [
26] as a technique for EX detection. They disbanded the EX zones and transferred their training to the LeNet model. Before the training, they replicated the data. The Kaggle dataset was used to create the project. The authors of the Ref. [
27] dealt with overfitting and skewed datasets in the context of DR detection. The CNN model, which has 13 layers, was trained using data amplification using the Kaggle dataset. Another paper used an ensemble method of CNN models [
28] to identify all phases of DR using balanced and unbalanced classes. To begin with, they divided the Kaggle dataset into three sections and generated three sub-datasets. In the first model, they used DenseNet-121 to train three datasets independently and then combined the results. In the second model, they used ResNet50, DenseNet-121, and Inception-V3 to train three datasets independently and then combined their findings. The models were then compared to one another. It is worth mentioning that DL models have achieved significant results in medical imaging applications in recent times [
29,
30,
31,
32].
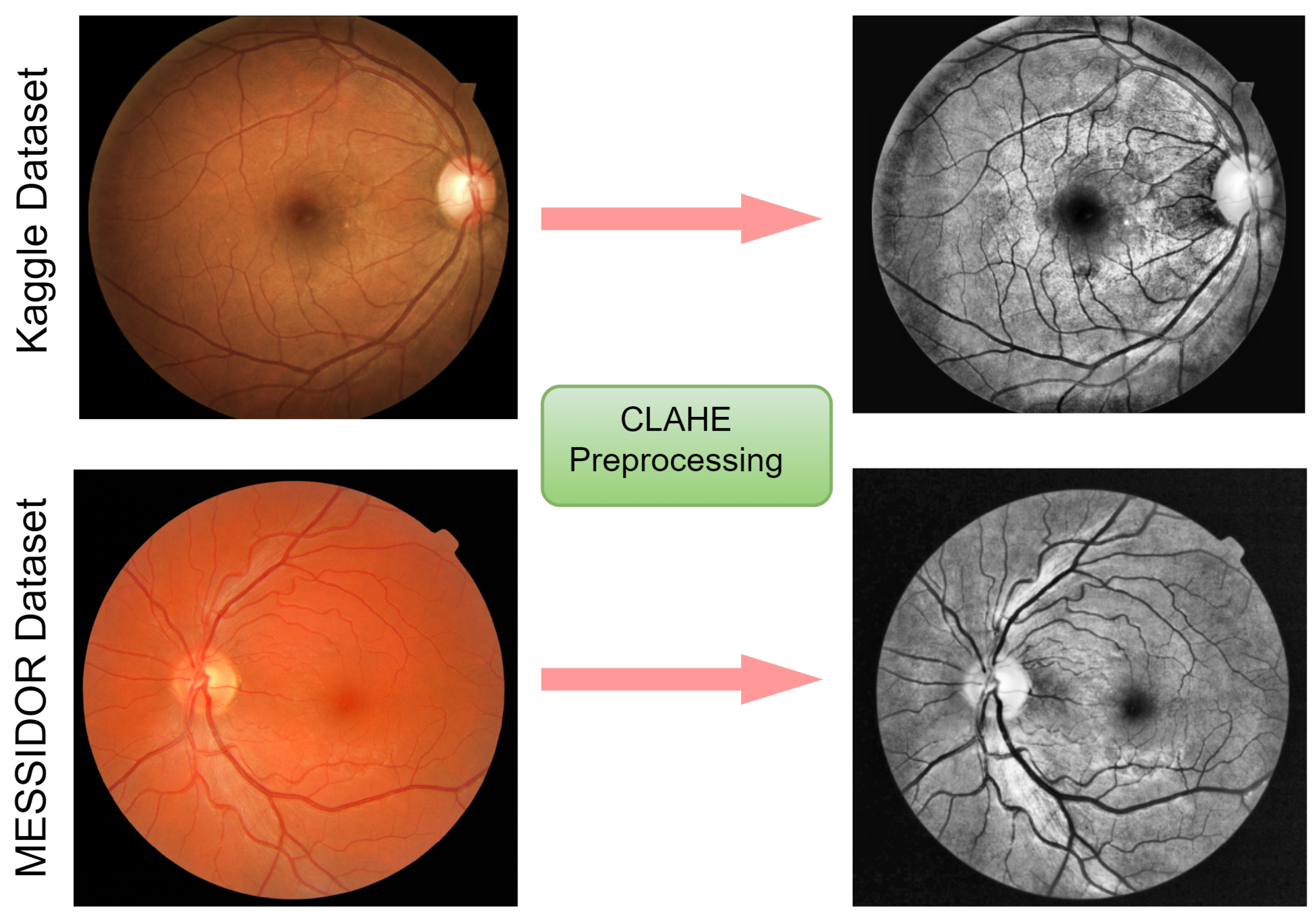
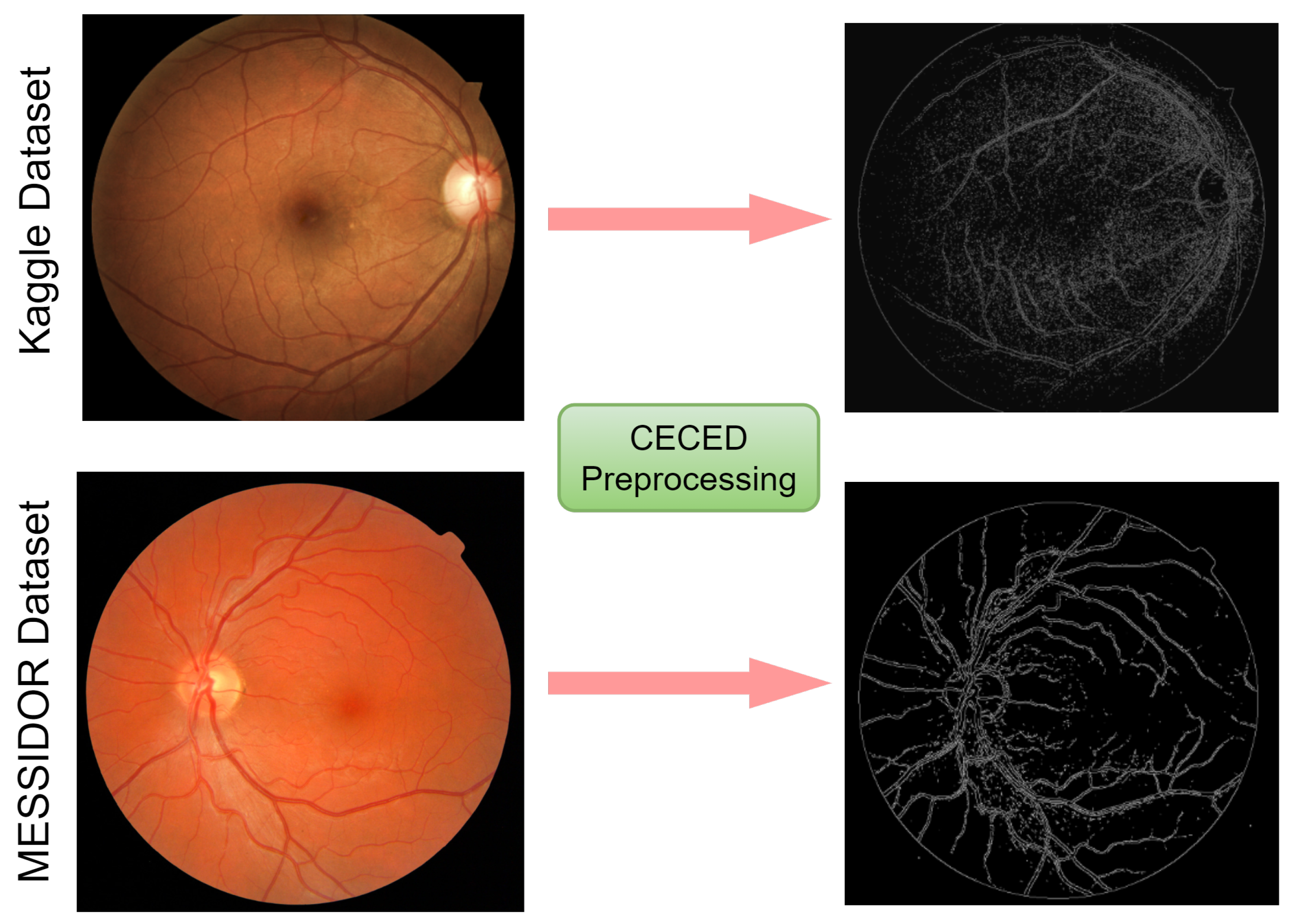
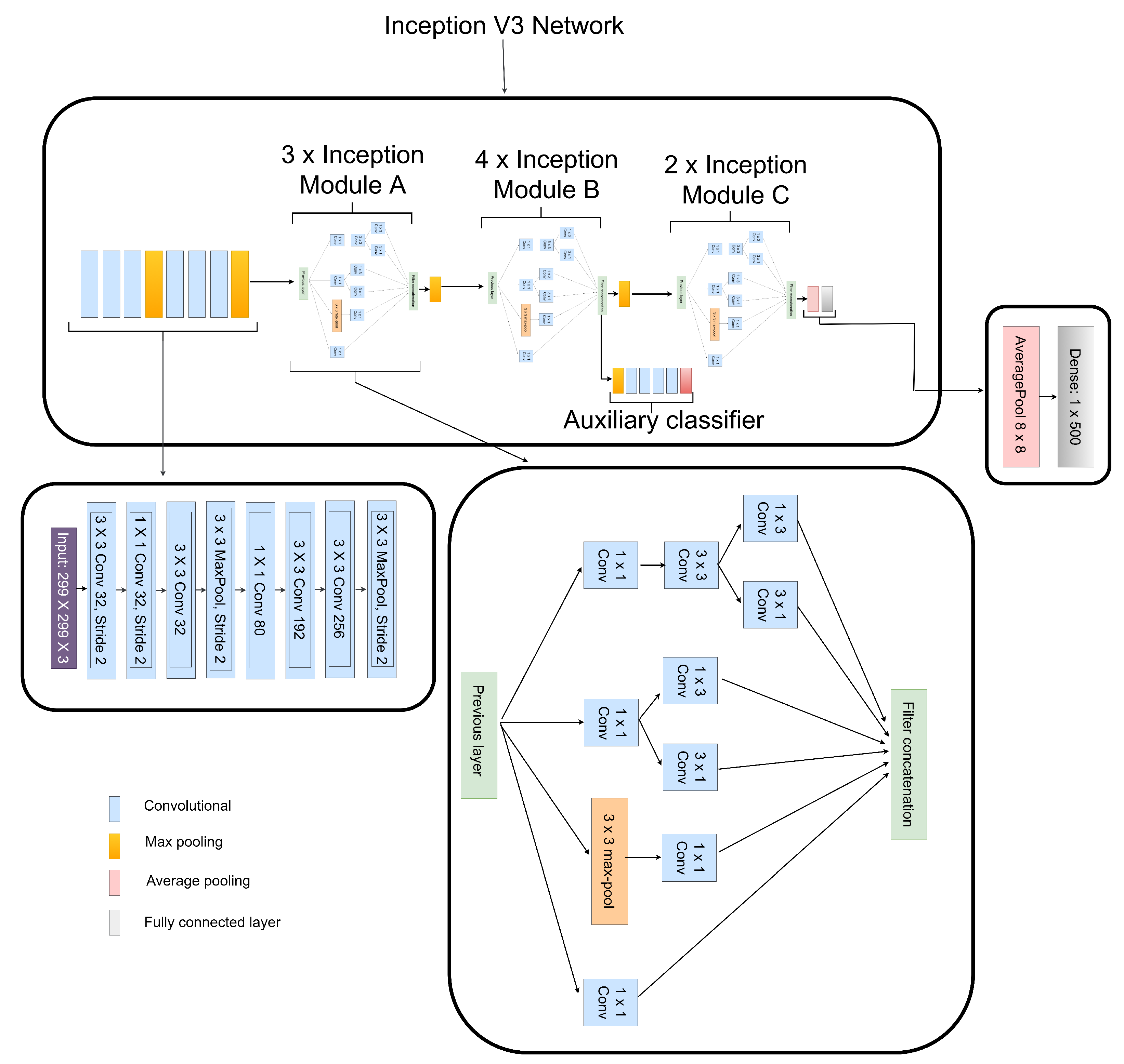
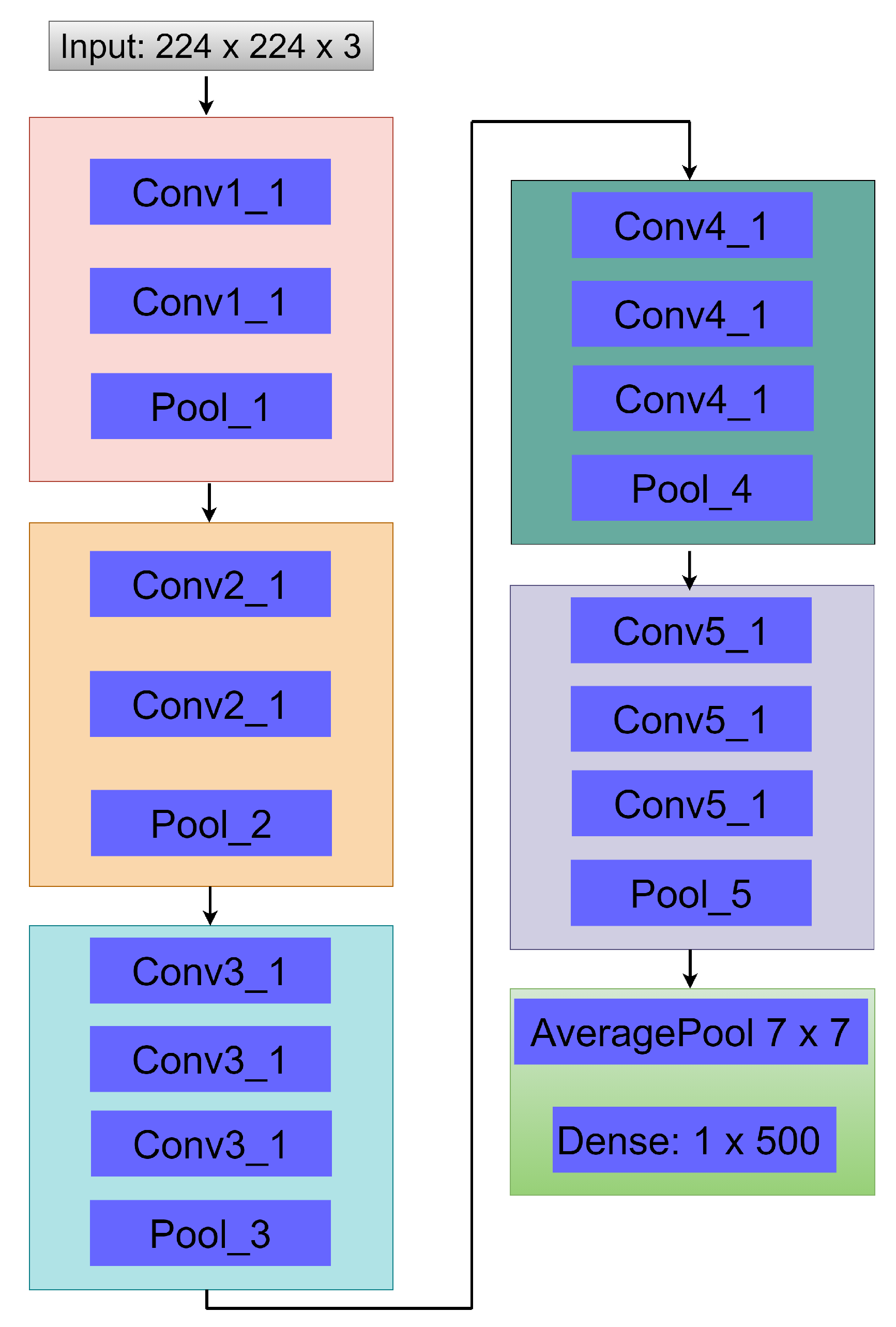
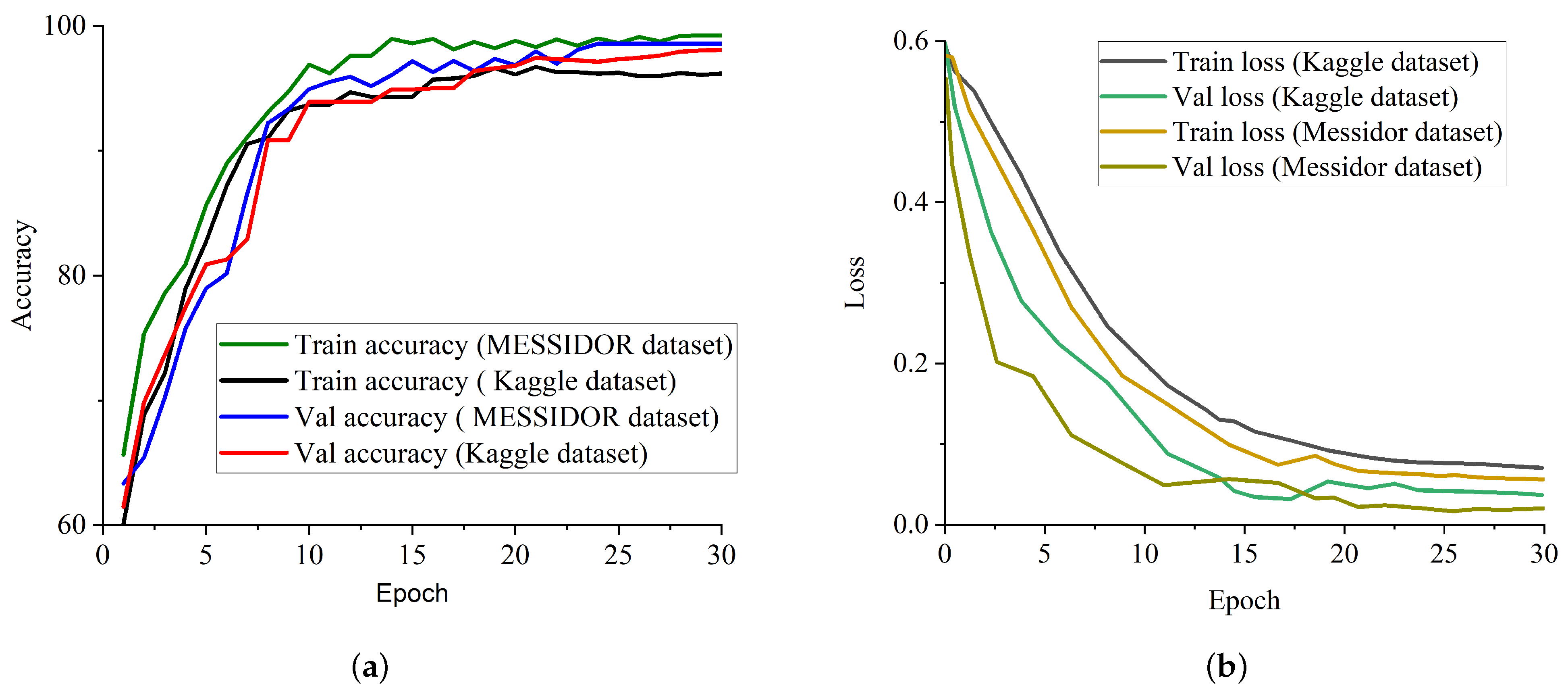
Though various DL models have been established for the classification of DR, enough emphasis has not been placed on the low resolution and quality which may influence the performance of DR classification. To this view, a weighted fusion deep learning network (WFDLN) is proposed for DR identification. Since the deep learning network has good performance in identifying images, two kinds of images are analyzed—one is CLAHE images, and the other is CECED images. We considered CECED and CLAHE because CECED provides and represents vital shape features in image classification and the CLAHE method limits histogram amplification and enhances the inverse of an intensity image. A pre-trained VGG-16 was built for the extraction of features from the CECED images, whereas Inception v3 was used for the extraction of features from CLAHE fundus images. Output from the dual channel fundus scans were then fused in a weighted pattern, and a Softmax classifier was used for the prediction of results.
Our paper focuses on the problem of low-quality DR images. The novelties of our proposed model is in threefold. First, the dual channels of fundus images which are CLAHE and CECED images are utilized for DR identification because of their interconnected properties. Secondly, the fine-tuning techniques are utilised for better extraction of features. Lastly, the output weights of each channel are merged for a robust prediction result. Two public datasets belonging to Kaggle and Messidor are used to evaluate the performance of our research.
5. Discussion
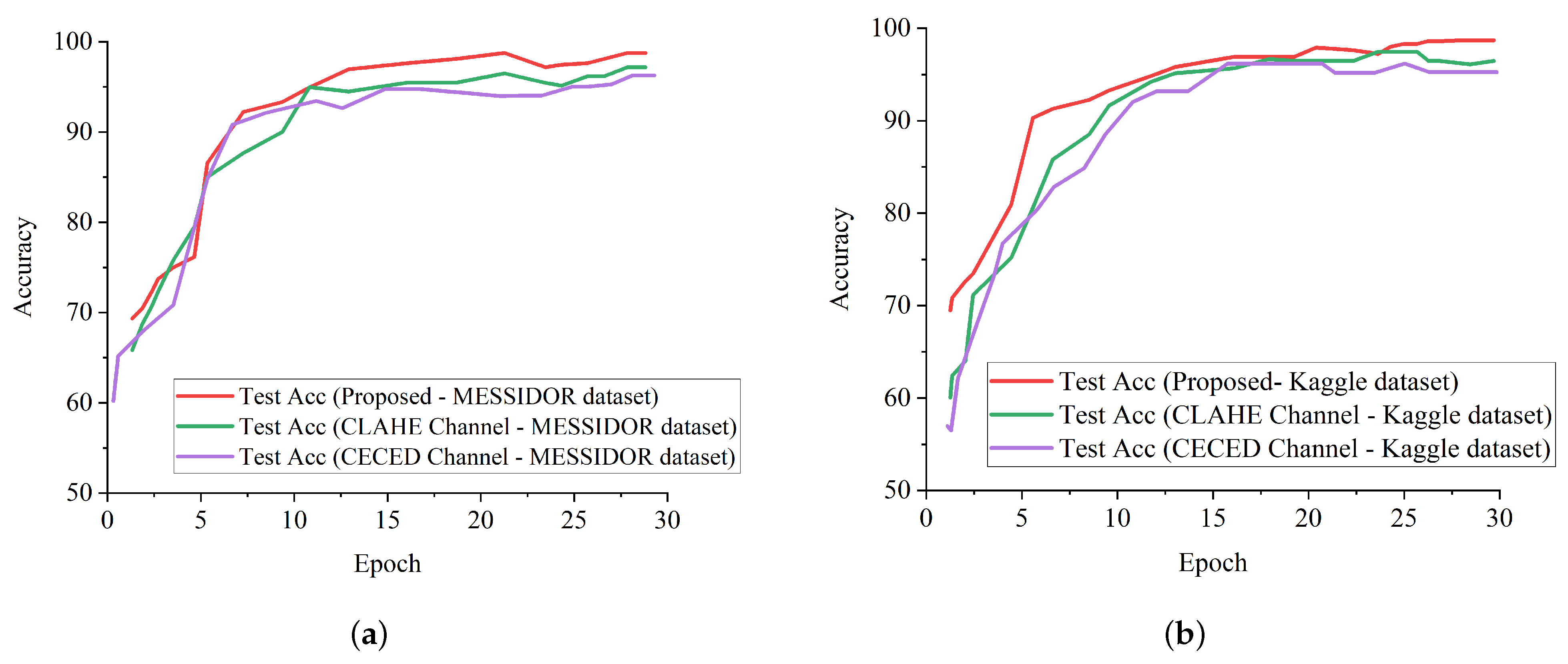
The performance of the proposed strategy in identifying DR in fundus images on different datasets has been presented, and the identification result for each dataset is presented in
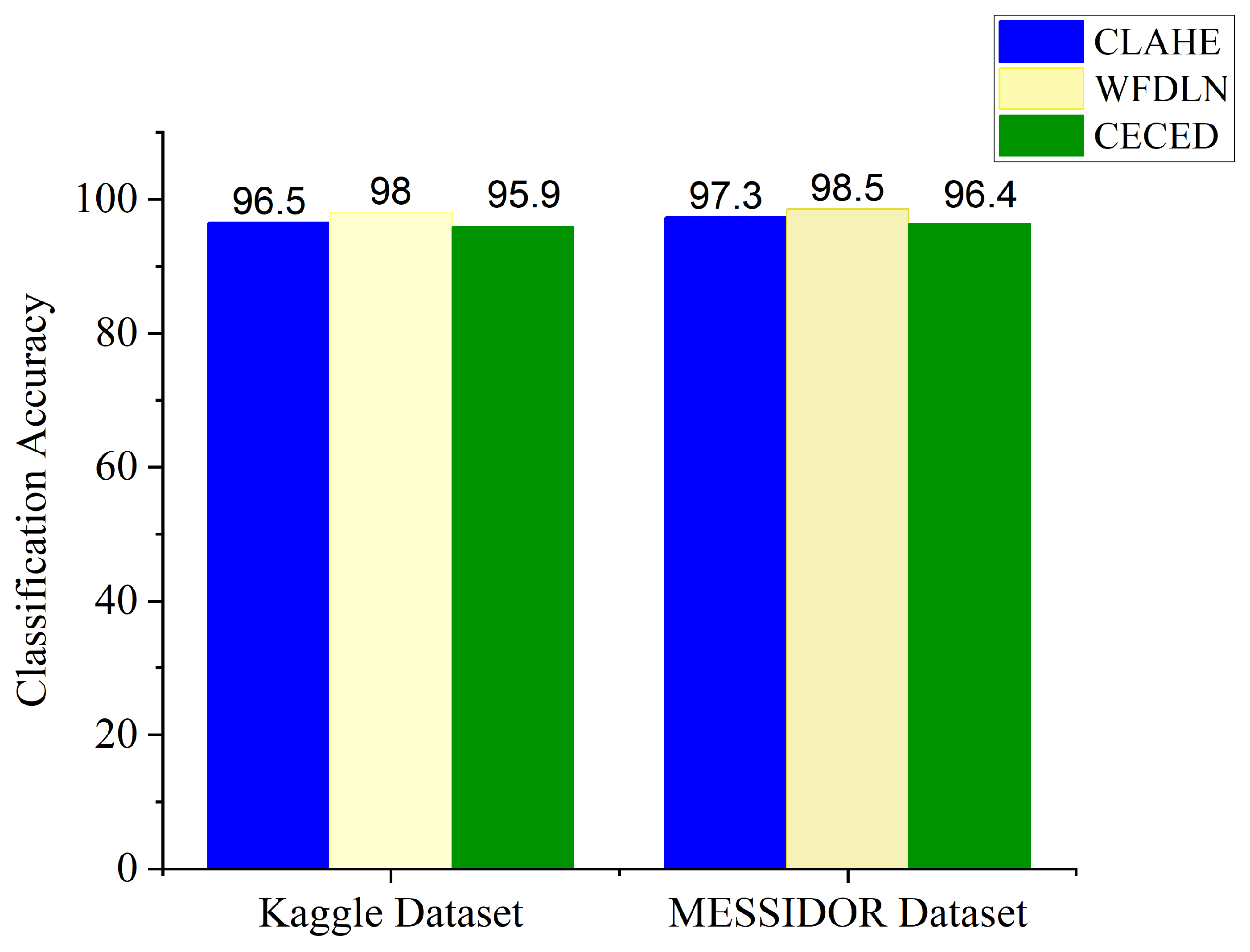
Table 3 in comparison with the single-based channels. As illustrated by the above-mentioned results, the proposed model can efficiently identify DR from non-DR fundus images. It is imperative to mention that our proposed strategy shows better generalization ability with the weighted fusion of CLAHE and CECED fundus images with a slight increase in computational time of 28.8 min.
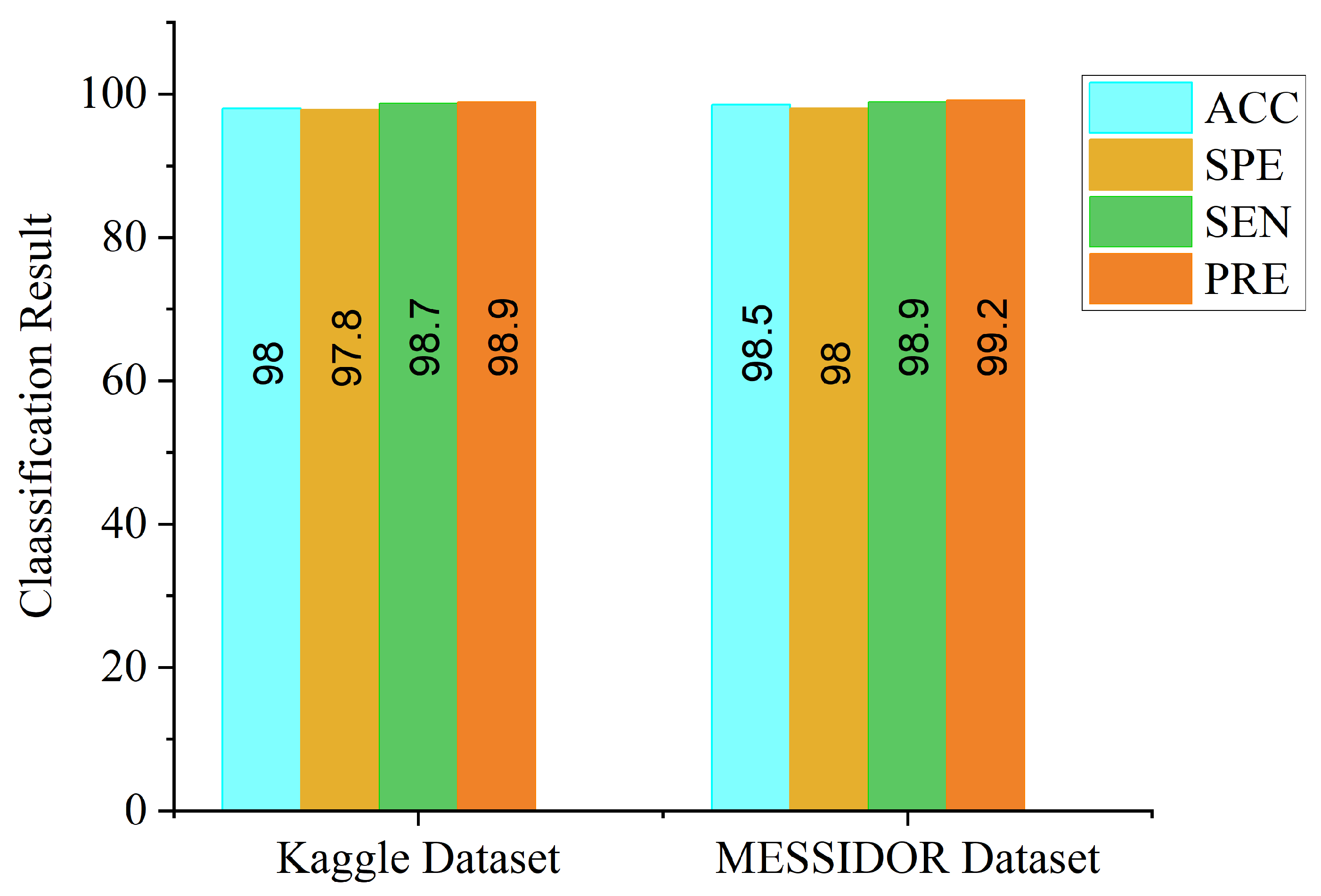
We denoted the channel as CLAHE-based for the approach that uses Inception V3 for CLAHE fundus images, and CECED-based for the approach that uses VGG-16 for CECED fundus images. The identification results for each dataset are presented in
Table 3. Our proposed model outperforms the single-based channels on all metrics, achieving 98.0% accuracy, 98.7% sensitivity, and 97.8% specificity on the Kaggle dataset, while on the Messidor dataset, the proposed model achieved 98.5% accuracy, 98.9% sensitivity, and 98.0% specificity.
We compared our proposed method with some up-to-date methods using the Messidor and Kaggle datasets.
Table 4 shows that the proposed model achieved a highest AUC score of 99.1%, followed by Gulshan et al. [
16] and Costa and Campilho [
22] with 99.0% on the Messidor dataset. On the Kaggle dataset, the proposed model achieved a highest accuracy score of 98.0%, as seen in
Table 5. Mansour et al. [
25] reported a higher sensitivity score of 100% than the proposed model; however, the proposed model achieved the same AUC value of 99.0% with Mansour et al. [
25].
In terms of accuracy, the proposed model achieved a highest score of 98.0%, indicating the superiority of our proposed model for DR identification. The competitive advantage of our proposed method is attributed to the complementary fusion of different channels of fundus images. It is worth mentioning that different deep learning models will perform differently under different conditions. In order to select the best-performing pre-trained model for our proposed weighted fusion deep learning framework, we conducted an ablation study using different transfer learning models, pre-trained on the ImageNet dataset.
Table 6 presents the results obtained from the experiments using our proposed framework with various pre-trained networks on the Messidor dataset. From the experimental result, the VGG-16 network shows better performance in extracting features from CECED fundus images compared to CLAHE fundus images, achieving 96.4% accuracy, 97.1% sensitivity, and 96.0% specificity. Inception V3 showed a significant improvement in performance in extracting features from CLAHE fundus images compared to CECED fundus images, achieving 97.3% accuracy, 97.8% sensitivity, and 97.0% specificity.
Table 7 shows the results of the experiments on the Kaggle dataset using our proposed framework with several pre-trained networks. According to the results of the experiments, the VGG-16 network performed better in extracting features from CECED fundus images than CLAHE fundus images, with 95.9% accuracy, 96.5% sensitivity, and 95.3% specificity. Inception V3 performed significantly better in extracting features from CLAHE fundus images than CECED fundus images, attaining 96.5% accuracy, 96.8% sensitivity, and 95.5% specificity.
In general, AlexNet showed the worst performance in all the metrics, followed by MobileNet in extracting features from CECED and CLAHE fundus images on both the Messidor and Kaggle datasets. For diagnosing sensitive conditions like diabetic retinopathy, it is important that we adopt a precision-recall curve to measure the mean average precision of the proposed model and the ROC curve as a method to measure the overall accuracy.
Figure 12a shows the precision-recall curve and
Figure 12b shows the ROC curve for the single channels and the proposed WFDLN model on the Messidor dataset. Similarly, the precision-recall curve and the ROC curve for the single channels and the proposed WFDLN model on the Kaggle dataset are presented in
Figure 13a,b, respectively.
Additionally, some of the fundus images were blurred with missing details, which could have impeded the proposed model from extracting and training meaningful features. Fortunately, the benefit of improving the low quality of fundus images using CLAHE and CECED pre-processing techniques characterizes high representation details of the fundus images with observable trainable features. The proposed WFDLN achieved a satisfactory performance in identifying DR, as we went a step further to compare our proposed model with some selected up-to-date frameworks in terms of precision-recall and ROC.
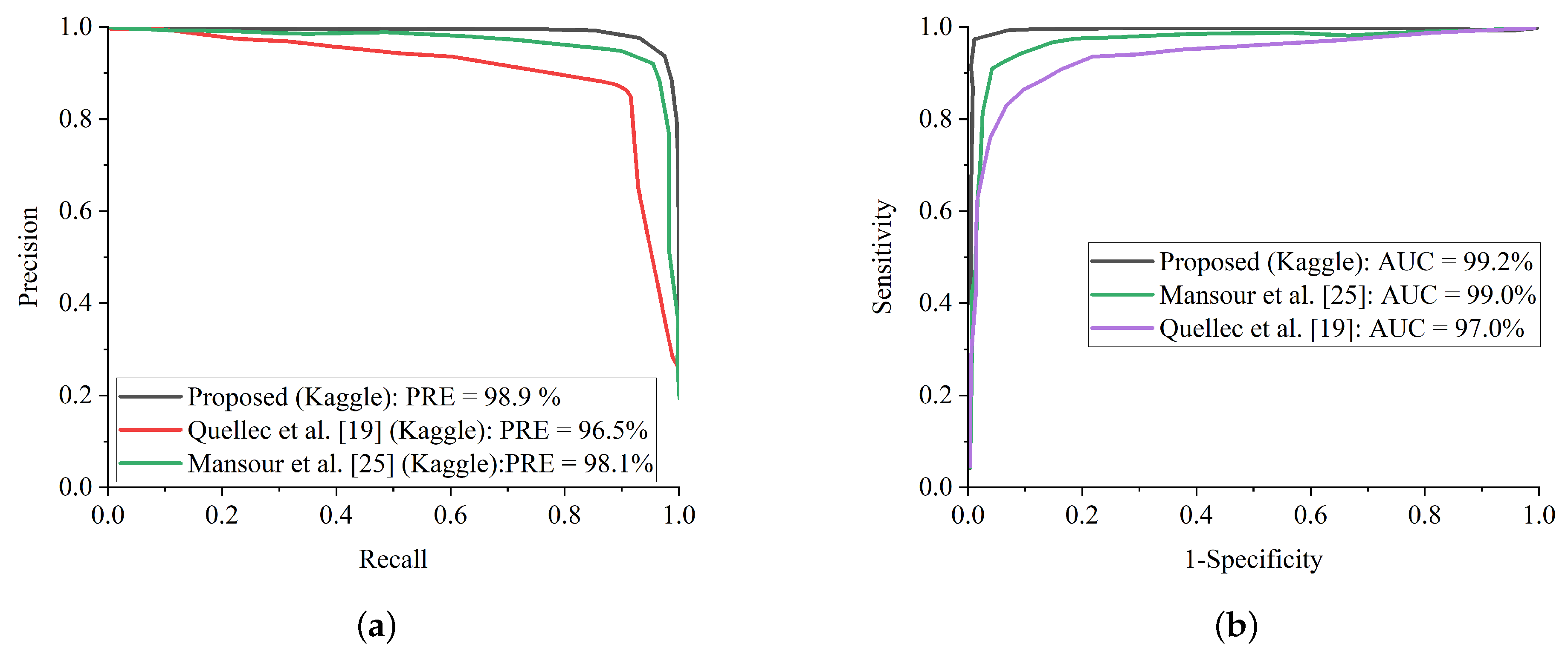
Figure 14a presents the precision-recall curve for the selected up-to-date models and the proposed WFDLN model on the Messidor dataset, while the ROC curve is presented in
Figure 14b. Similarly, the precision-recall curve on for the selected up-to-date models and our WFDLN model on the Kaggle dataset was presented in
Figure 15a, while the ROC curve was depicted in
Figure 15b. It is worth mentioning that all the models were trained on the same dataset for fair comparison.
From all indications, the proposed WFDLN surpasses other frameworks in the aspect of precision-recall and ROC curves, especially in handling low-quality fundus images. The precision-recall graphs reveal that our proposed model’s curves are closest to the graph’s upper right corner with the largest area, implying that it has higher precision and sensitivity. Similarly, the ROC graphs show that our proposed model’s curve was closest to the top-left corner of the graph and had the highest AUC, indicating that it has higher sensitivity and specificity. More importantly, the stated result in terms of ROC and precision-recall can assist expert ophthalmologists in striking a balance between accuracy and precision, as described above.
Even though this study achieved a high level of accuracy in diagnosing DR, it does have certain drawbacks. This suggested strategy, which has high classification accuracy in both Messidor and Kaggle DR datasets, might not obtain exactly the same classification accuracy in another medical dataset. The reason is because the images of various datasets differ owing to differences in labeling, noise, and other factors. To solve this challenge, the AI should be taught to utilize images acquired at various times and locations. Aside from the diversity of data, the allocation of the data classes is also significant. A disparity in class sizes has a detrimental impact on training. The accuracy of categorization was also affected by the different data augmentation strategies employed to correct the imbalance. Another disadvantage is that using the weighted fusion technique requires more processing time as compared to single-channel models while improving the classification accuracy. In light of these constraints, tests will be conducted in the future employing a wider range of images and possibly employing various optimization strategies that are more efficient in terms of computational time.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}