1. Introduction
According to the global cancer statistics (GLOBOCAN 2018) nearly 93,000 new cases of oropharyngeal squamous cell carcinoma (OPSCC) were reported worldwide in 2018 [
1]. Lately, the incidence of OPSCC is significantly increasing in many countries worldwide, particularly due to positive human papillomavirus (HPV)-related OPSCC [
2]. HPV, primarily type 16, is recognized as a risk factor and important prognostic factor alongside tobacco and alcohol consumption [
3]. Nevertheless, the actual therapeutic decision for OPSCC is currently not differentiated according to HPV status. Instead, it is essentially based on the individual situation of the patient and his or her anatomical and biomedical conditions. While early-stage OPSCCs are usually treated by surgery or radiation therapy, more advanced stages require multimodal therapeutic concepts depending on the pathological indication. These may include invasive surgical procedures as well as adjuvant radiation or combined radiochemotherapy [
4,
5]. In cases of unresectable tumors, definitive radiochemotherapy is indicated. For recurrent or metastatic disease, new therapeutic options in the field of checkpoint immunotherapy have been approved. These represent a valuable addition to established conventional chemotherapies by blocking inhibitory immune checkpoint signaling pathways to reactivate immune response against cancer [
6]. Activation of the PD-1 protein, which can be expressed by T cells, in response to PD-L1, leads to inhibition of the immunological response of T cells and serves as a mechanism to bypass the tumor immune system. Anti-PD-1/PD-L1 immune checkpoint inhibitors (ICIs) can inhibit suppressive signaling through the PD-1/PD-L1 pathway and enhance antitumor immune activity [
7,
8]. Due to individual tumor characteristics, differences in resectability and comorbidities that may conflict with radio- or even more chemotherapy, a personalized view of the diagnostic and therapeutic process becomes necessary. This includes adjusted diagnostics and individualized decision-making to provide optimal outcomes and a valuable quality of life for the individual patient.
To consider all personal patient-related factors, the evaluation of ideal treatment strategies for OPSCCs is currently being discussed in interdisciplinary tumor boards. In these meetings, specialists from different disciplines evaluate the available options in order to find the best possible therapy for a specific patient case. The following disciplines are usually represented: otorhinolaryngology, head and neck surgery, maxillofacial surgery, pathology, radiology, radiation therapy, as well as medical oncology [
9]. Making such complex clinical decisions involves a set of individual considerations. The particular knowledge required to act in the patient’s favor comes from various sources of information such as learned expertise, specialist publications, and individual experience [
10]. Verifiable results from significant medical studies or clinical trials are considered a level of safety as they represent the current state of clinical evidence [
11]. This evidence also serves as a foundation for the preparation of clinical practice guidelines (CPG), which are provided by several medical associations. This overall process, also defined as evidence-based medicine (EBM), represents one current baseline for making medical decisions [
12,
13].
Although the concept of EBM integrates medical science and research, it provides general practice recommendations. So, it is therefore not an individual “instruction manual”, but must be applied to the individual patient according to the specific circumstances. Therefore, the clinical experience that a clinician accumulates during his or her professional career should not be underestimated in the diagnostic and decision-making process. Most judgments concerning specific criteria of the patient are made based on the clinician’s individual knowledge, training, and experience.
According to Lakoff et al., experience does not refer to memory, i.e., the result of interaction with the environment, but characterizes the immediate encounter, i.e., the process of repeated sensorimotor interaction with the environment in the sense of a repetitive action [
14]. This progressively shapes and links the functional neuron groups involved in this process more effectively. Experience thus changes the neuronal connection patterns of the brain. This implies that the diagnosis and therapy finding of current patient cases are cognitively compared with similar patient and diagnostic profiles of the past. For very unusual, rare, and complex cases, for which even highly trained clinicians may lack the experience, this described process of decision-making reaches its limit and can no longer guarantee the optimal strategy for an individual patient [
15]. Similarity analysis and comparison with previous cases could therefore form a valuable part of selecting an optimal diagnostic and therapeutic strategy. By means of an IT-supported process, it should be possible to access a broad knowledge base of patient cases. Based on the human cognitive process, an automatic search function can be used to evaluate specific diagnostic results of comparable patient cases and their courses for the current research question.
The idea of comparing a new problem with a similar previous situation found its beginnings in the 1980s and has been tried to establish since then [
16]. As a cognitive similarity to clinical decision-making based on expertise coupled with the duality of subjective and objective knowledge, the term case-based reasoning (CBR) was introduced with the main principle: “similar problems have similar solutions” [
16]. Considering the enormous potential of CBR for automated systems in clinics, the capability has yet to be achieved with suitable technologies, since other fields already utilize similar approaches. Similarity analysis is used in the medical context for DNS and protein analysis, for example, but is also used in many other domains [
17]. It already forms an omnipresent and indispensable part in the context of recommendation systems. Based on the analysis of user behavior, suggestions for online shopping (“customers who bought this item also bought...”), music and movie streaming, or e-learning applications already influence decisions in our everyday life. To make recommendations, many member profiles with similar preferences and tastes are matched with the current user profile and the most suitable objects are recommended in a personalized catalog according to the collaborative technique of recommendation systems [
18]. This already established concept should now also relieve medical staff in their everyday work.
The consideration of computational similarity analysis for patients is a well-known approach that has been thoroughly investigated throughout the years [
19]. Especially since the advent of algorithmic analysis and machine learning (ML), methods such as k-nearest neighbors (kNN) and associated solutions have been applied to this problem with large success [
20,
21,
22,
23]. However, while those similarity metrics are well suited for the identification of similar (vector-based) abstractions of patients, they do only account for differences at a variable level (i.e., two patients with the same gender or almost equally distributed expressions in the blood count) but they do not consider the distances between individual variable states (i.e., between two categorical variables that are not equidistant regarding their influential factors, e.g., general performance status (ECOG) or other medical staging systems). While multiple measures that address this modality (also known as overlap measure) exist, they do only account for categorical variables. Since medical data sets are often subject to mixed variable types, solutions that are able to process those diverse entities are required.
To overcome those current methodological limitations in similarity search among patients, we present a novel approach that considers the intra-variable similarity of clinical cases based on mixed-type variables by using the
ϕK correlation coefficient [
24]. Due to this procedure, we also introduce a novel real-world application for the stated
ϕK metric and evaluate its suitability for the task of patient matching. Accordingly, the main aim of the presented method is to contribute to comprehensive and objective (unbiased) assistance in case-based reasoning and thus also to the therapy decision process in the long term. In conclusion, this methodology made it possible to identify an objective selection of decisive diagnostic features and their individual impact on primary and adjuvant treatment decisions in the head and neck tumor board.
2. Materials and Methods
2.1. Information Modeling Creating a Patient-Specific Vector
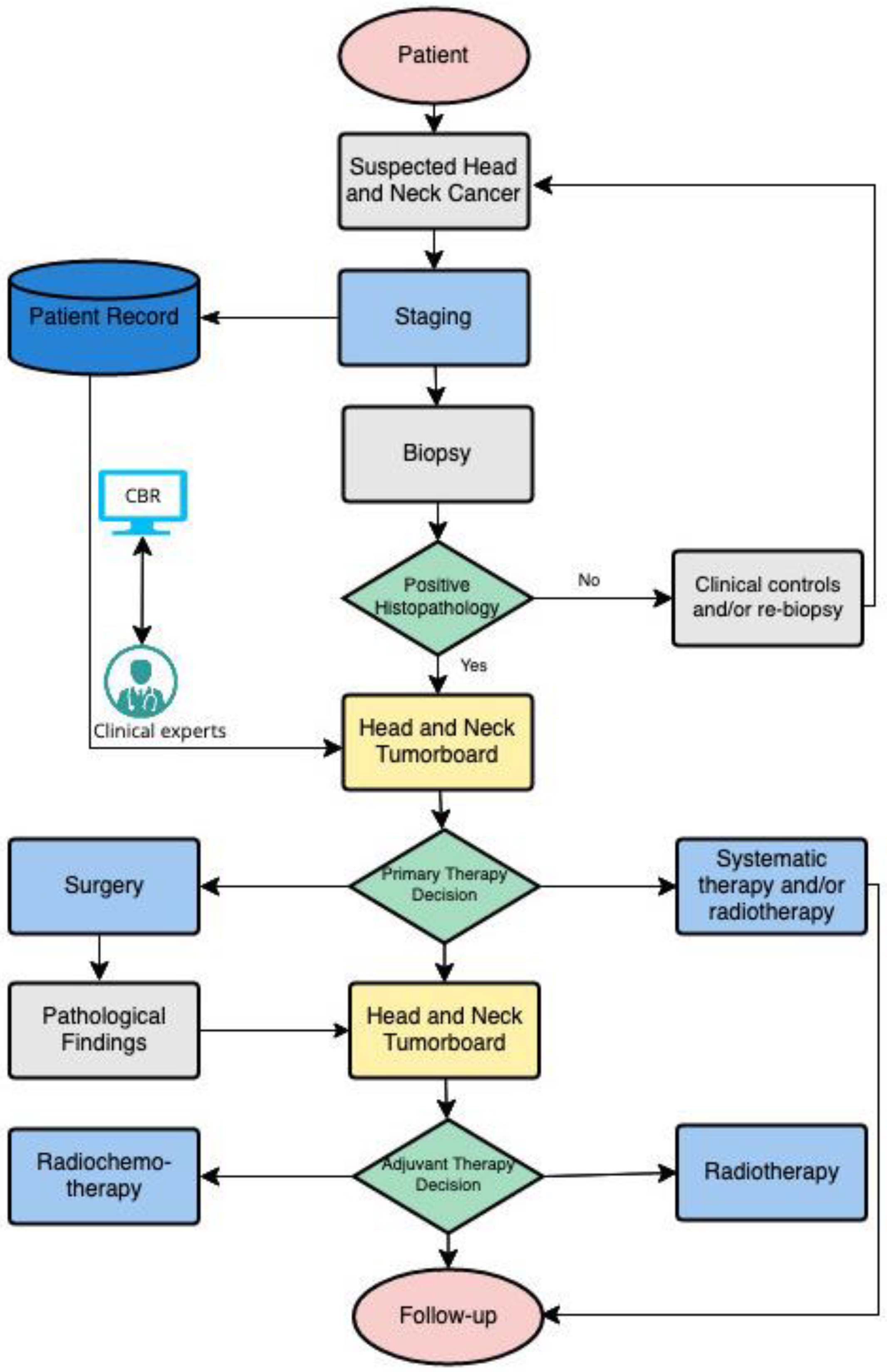
In order to adequately compare OPSCC patient cases, it is necessary to determine the context-specific variables (features) that are considered relevant to decision-making in relation to a corresponding endpoint (see
Figure 1). In the present case, this endpoint relates to the primary and adjuvant treatment decision. Thus, relevant and specific characteristics were initially identified from the diagnostic results using the hospital’s internal clinical information system and then transferred into patient- and diagnosis-related features. For primary treatment, in the patient category, age, severe pre-existing conditions, and the ECOG score, a general performance measure, are decisive factors for diagnostic and therapeutic management (see exemplary patient data in
supplement Table S1). While as diagnostic features, factors such as tumor size, infiltration of certain structures, possible metastases, as well as histo- and molecular-pathologic characteristics are important in assessing whether the tumor is resectable or chemotherapy is tolerable (see
Table S2). Provided that surgical therapy is successfully evaluated in terms of achieving complete tumor resection with clear margins and optimal quality life expected postoperatively, potential adjuvant treatment is discussed in a postoperative tumor board based on the definitive pathologic findings. The histopathological report of the surgical resection should include tumor localization, tumor size, histological tumor type and grading, lymph vessel invasion, blood vessel invasion and perineural invasion, locally infiltrated structures, number and size of affected lymph nodes, presence of extracapsular extension, and the resection status (see
Table S3). In addition, immunohistochemical scores such as the combined positive score (CPS) and the tumor proportion score (TPS) are also acquired to estimate PD-L1 expression. The CPS score evaluates the number of PD-L1 positive cells (tumor cells, lymphocytes, macrophages) relative to all viable tumor cells. TPS assesses the percentage of PD-L1 positive tumor cells in proportion to all viable tumor cells [
25]. The result of this process is a patient-specific vector of independent information entities, which shows the related medical factors influencing therapy decisions in a structured format. In this context,
Tables S1 and S2 each form the characteristic constellations for the primary decision scenario and
Tables S1 and S3 for the adjuvant therapy.
To establish the dataset, 102 patient cases with OPSCC from the University Hospital of Leipzig were retrospectively analyzed. All of them were previously discussed by a team of interdisciplinary experts in the head and neck tumor board. We were able to only capture complete patient data without any missing information during this process.
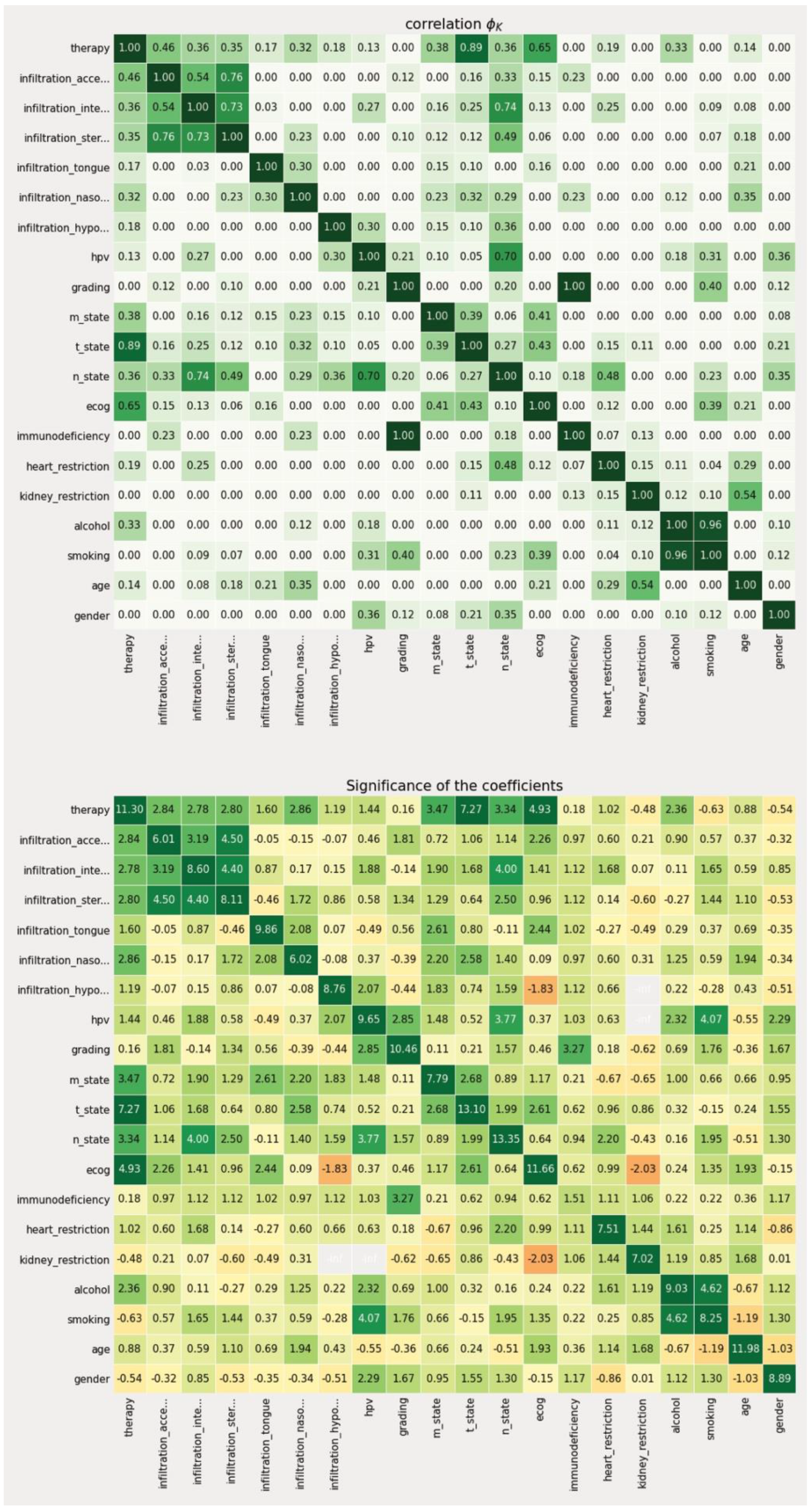
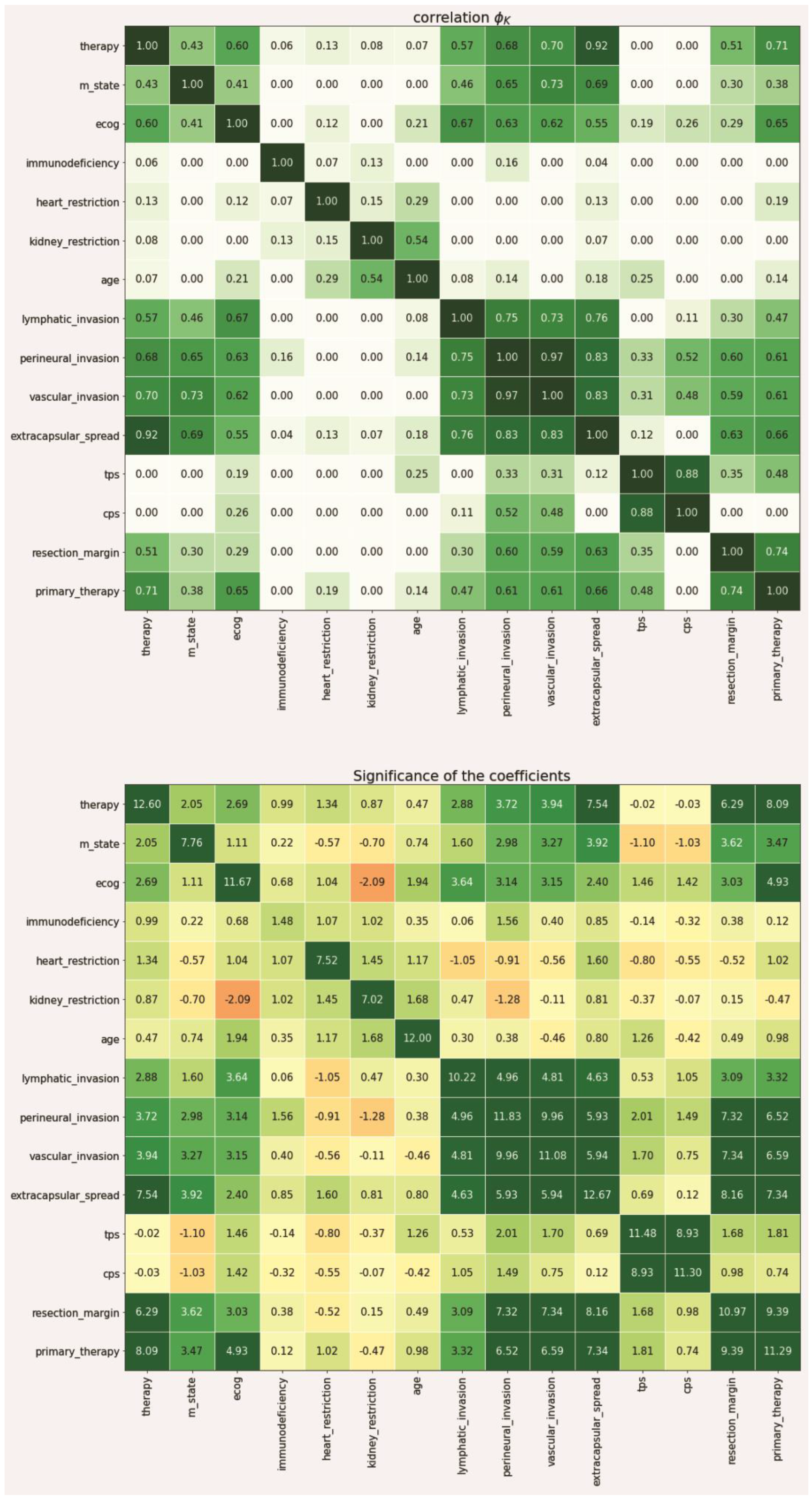
2.2. Data-Driven Reduction of the Feature Space Using the PhiK Correlation Coefficient
Since not every feature is equally important in the context of making a therapeutic decision, a data-driven metric for expressing the individual weight of that information needed to be derived from the data set. To achieve this, we first split the data into a training (81 patients) and test set (21 patients) to enable later verification of our approach with previously unseen data (patient data that was not used to derive feature space reduction and intra-variable analysis). Based on the training set, we then calculated the individual correlation of each feature in relation to the recorded treatment decision using the PhiK (
ϕK) package (version 0.9.12) in a Jupyter notebook python environment [
24]. The
ϕK coefficient is based on a refined version of Pearson’s χ
2 contingency test to evaluate the independence of two or more variables through an algorithmic calculation without restrictions to a single variable type. Thus, it enables the parallel consideration of categorical, ordinal, and interval variables, which is a crucial characteristic when dealing with medical data that is usually represented in mixed-type data columns, e.g., age (ordinal), ECOG (categorical). In contrast to more traditional metrics, such as
Pearson’s r, it also accounts for non-linear behavior between variables, which is another important characteristic regarding medical data including artificial scoring systems to express certain medical modalities (e.g., TNM-staging, ECOG). The PhiK package allows for the calculation of a correlation matrix using its own
ϕK coefficient as the associated metric. While there is currently no gold standard regarding the correlation threshold, we defined scores greater than 0.3 to be significant for our analysis. The coefficient itself ranges from 0 to 1.
In a second step, we then evaluated the resulting features in terms of their statistical significance using the integrated PhiK significance based on a modified
p-value calculation [
24]. The algorithm then calculates a Z-value for each possible feature constellation which can then be obtained in a matrix-based representation according to the previous correlation matrix. For the performed analyses, we have determined a Z-value greater than 2.5 to be significant.
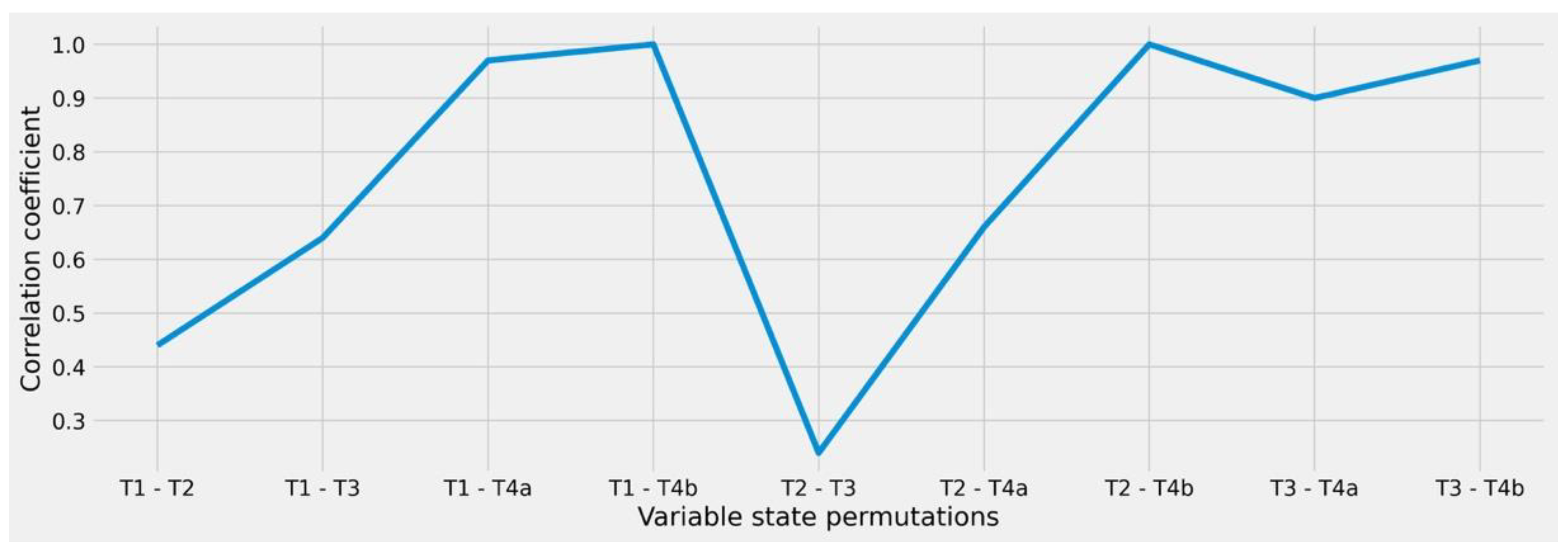
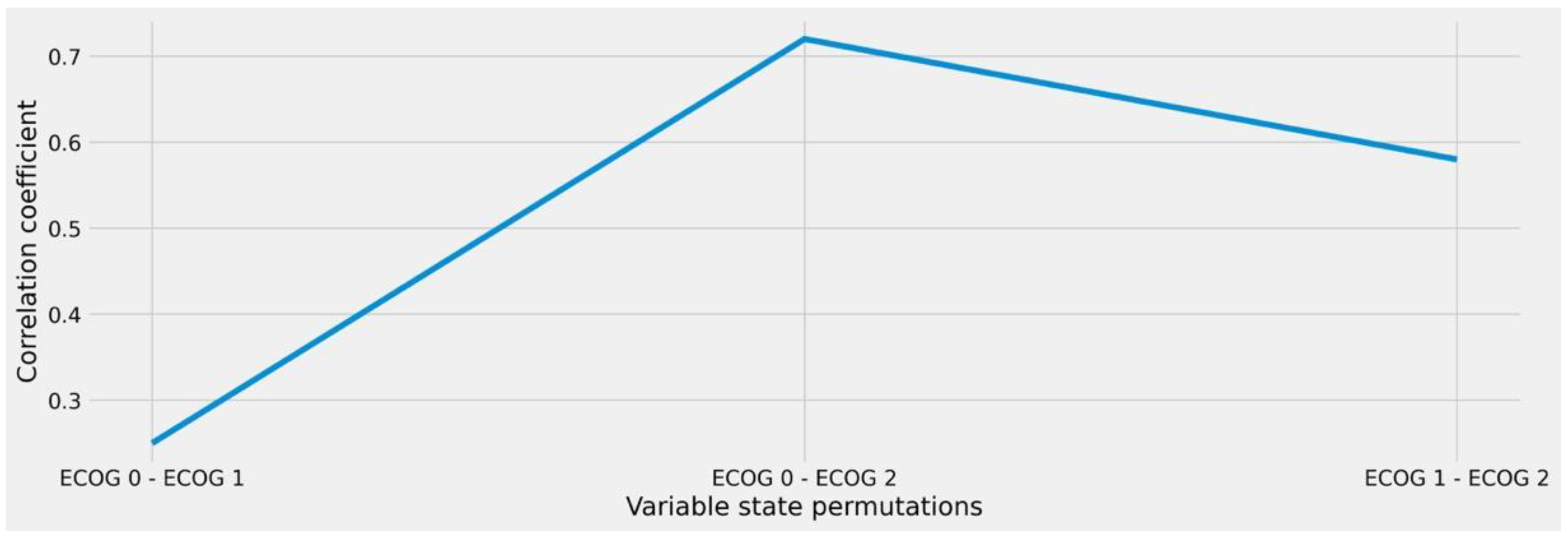
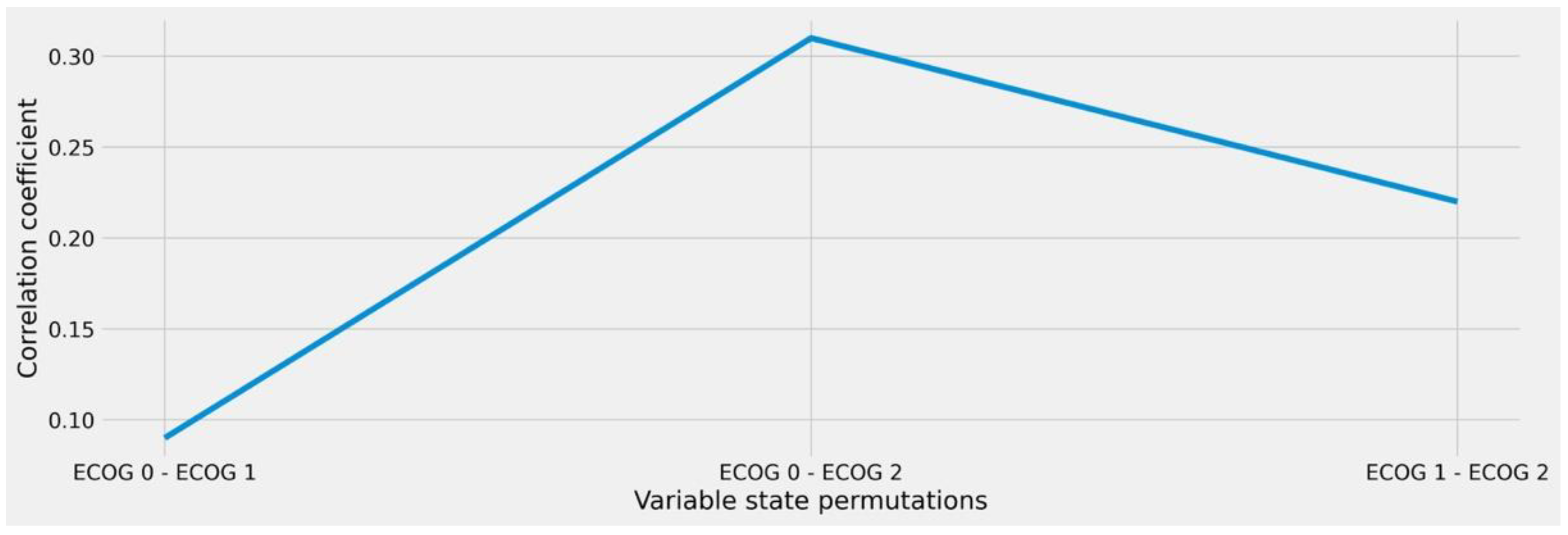
2.3. Analysis of Intra-Variable Behavior to Enable Granular Similarity Scoring
From a clinical point of view, there may be a difference in terms of treatment capacity whether a patient has ECOG = 1 or ECOG = 2, whereas no relevant distinction is usually made here between ECOG = 0 and ECOG = 1 states. Therefore, we further refined our analysis to account for intra-variable behavior in the remaining features (after reduction) with the goal to quantify the individual differences between the respective variable states. We therefore performed the same ϕK-based correlation and significance tests in relation to the therapy target variable while limiting the respective input feature states to every possible pairwise permutation schema, e.g., ECOG 0/ECOG 1, ECOG 0/ECOG 2, and ECOG 1/ECOG 2. In this way, we were able to calculate the numeric differences between the resulting clusters, allowing us to derive the amount of similarity or distance that results from looking at the individual states rather than the overall feature.
2.4. Consolidation of the Findings into a Similarity Metric
Based on the inter- and intra-variable analysis of the considered features, we were able to construct a weight-matrix that integrates the
ϕK correlation coefficients for all possible state permutations. Based on this, we suggest the implementation of the derived findings as additional factors to the calculation of similarity in the following way:
Thereby, represents the number of features in a patient vector that is considered for similarity analyses with a range of other same-type vectors in an iterative way. The weight factor represents the associated values from the weight-matrix that account for the respective correlation for each constellation of variable states. Due to , a relatively small ϕK correlation coefficient also results in a small distance as it has been shown that the derivation between both factors is of less importance for the respective decision scenario. Consequently, if the normalized sum of all feature correlation is small, it follows that the distance between two patient vectors is small, which then results in a high similarity value .
2.5. Evaluation of the Approach
To verify our approach, we further implemented an initial evaluation process by performing similarity searches among the test set (new and unseen patient data) with the training set. In this scenario, we considered a difference in variable states as relevant, if the calculated weight surpassed a score of 0.5. All other constellations were thus considered to be similar. If one or more matches (defined as patients to be the same or similar in all considered features) for a case in the test set were found according to this procedure, we then checked if their corresponding therapy selection was equal among all findings. For example, if our approach identified cases B and C as two similarity matches for case A, and all cases were treated equally, this would result in a perfect evaluation score of 1.0. If differences were found in the recorded treatments, the score would decrease accordingly. Finally, we have calculated a final evaluation score through summing up the individual results and dividing them by the sum of all found matches. To account for unrepresentative effects caused by only a one-time random selection of cases in the train-test-split, we implemented a 10-fold cross validation with randomly assigned cases to the respective test (n = 21) and training (n = 81) cohorts during each fold. The overall evaluation metric (evaluation score) is thus defined as the mean of the individual per-run outcomes.
4. Discussion
Based on our approach, an initial objective selection of crucial diagnostic features and their individual impact regarding primary and adjuvant therapy decisions in the head and neck tumor board could be established. Nevertheless, it should be noted that the determination of the introduced metrics is highly dependent on the underlying database. It must therefore be assumed that the results of our retrospective analysis of 102 patient cases are limited to some extent and would be more significant with the integration of more or other data sets. This research therefore serves as a proof-of-concept study. The outcomes presented in this paper should be considered as a starting point that needs to be further analyzed and verified by including additional case data. The precision of the decision is then proportional to the amount of case evidence provided. However, based on the trends and effects revealed by the utilized algorithms, we were able to agree with the results from the perspective of clinical professionals in the weighting of diagnosis-related factors. This indicates that the presented approach is likely to adapt to causal implications in the real-world setting (e.g., lowering the need for adjuvant treatment when an R0 resection with clear margins was achieved).
In this work, we exclusively focused on the utilization of the ϕK-correlation coefficient to perform feature-space reduction and similarity scoring. While this method was mainly based on the fact that the integrated data set inherited a mixed-type variable constellation, the resulting sets for both treatment decision scenarios were purely categorical. This would have allowed for benchmarking our approach with other methodological solutions that are also capable of considering state differences among variables (i.e., Goodall measure or probability-based methods). However, since the main goal of our work was to present a novel solution to the problem of case-based reasoning, an in-depth comparison of our approach to other potential solutions was out of scope but should be considered in future works, also using further data sets to evaluate the generalizability. While this might go along with different outcomes regarding the resulting feature set (e.g., by integrating numerical variables such as laboratory measures), the issue of unprocessable complexity in the analysis of state permutations among two variables would require pre-processing, e.g., by transforming the respective values to z-scores.
The analysis performed in this study considers only patients who were assessed and treated in a single hospital. Thus, the aspect of institutional bias cannot be completely dismissed. However, due to the generalized description and design of the methodological process, a simple transferability to a multicenter application is feasible. This could not only lead to a minimization of bias but could also make the process of identifying similar patient cases even more useful by extending the associated search area accordingly. However, this implementation is associated with a correspondingly high organizational and technical effort in practice as it would require the provision of a central repository for the structured input and storage of medical case data. It would also be necessary to ensure terminological consistency. This standardization also applies to the initial evaluation of the individual information entities for prior classification.
Furthermore, it should be noted that for certain patient cases, there may be more than one possible treatment option and that the patient’s will should not be disregarded. This may lead to deviations between the tumor board decision and the intervention that is performed and documented in the electronic health record. Consequently, it is possible that patients who might be identified as similar by our approach might have received another treatment option than the one initially suggested to the patient. In a future setting that integrates our approach towards similarity calculation for case-based reasoning, this very likely circumstance should be addressed.
Although the methodological approach was presented and evaluated using the example of OPSCC, it requires very little adaptation for further use cases in both oncological and non-oncological contexts. For this purpose, the presented processes only need to be mapped to the respective domain and the results need to be interpreted and evaluated accordingly.
This method may also be suitable for very rare and complex cases, where decision-making is further complicated when the available information and experience is limited. Therefore, misdiagnosis and incorrect treatment are more likely in rare and complex diseases due to insufficient knowledge and awareness [
29]. A concise identification of objective, decisive diagnostic features and an analysis of similarity to previous cases can answer individual questions with the aim of determining the best possible diagnosis and treatment strategy for the patient. This adds quality and granularity to the decision-making process and potentially improves patient outcomes. In addition, the analyses provided may contribute to the training and expertise of health professionals. Particularly, beginners may benefit from this, which also enhances objectivity and quality control in hospital diagnostic and treatment processes.
While the provided solution is intended to offer rational and intuitive assistance in clinical decision-making, it still needs to be considered that medical cases provide enormous diversity and should not be exclusively evaluated by a set of features. However, our primary aim is to provide proper assistance in identifying relevant cases as a further source of evidence in the therapy decision process and not the specification of the decision itself.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}