
Big Data in Laboratory Medicine—FAIR Quality for AI?

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Definitions Surrounding Big Data
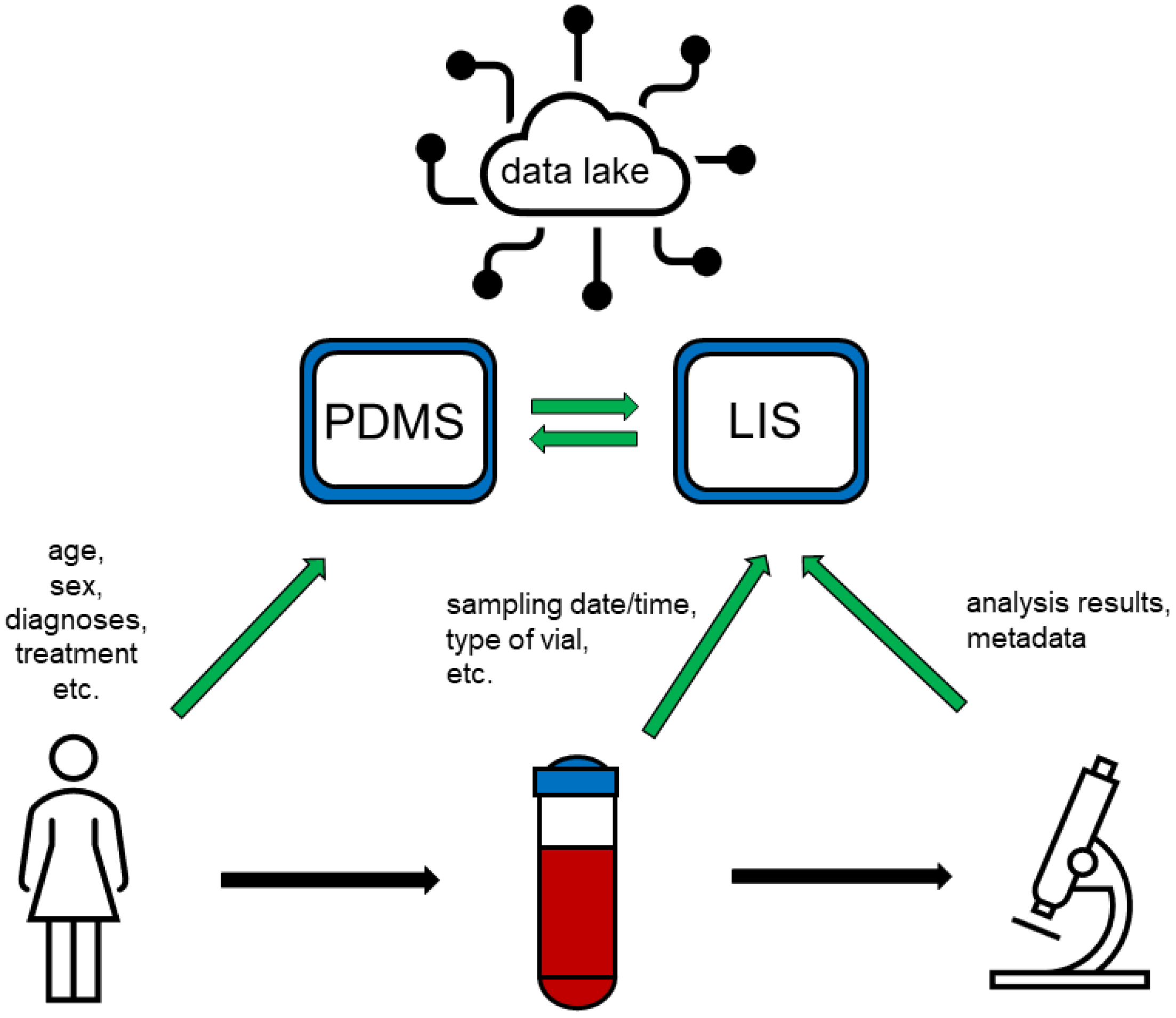
3. Transforming Laboratory Medicine into Big Data Science
3.1. Requirements
3.2. Risks
3.3. Chances
3.4. Fields of Application
4. Conclusions and Outlook
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cadamuro, J. Rise of the Machines: The Inevitable Evolution of Medicine and Medical Laboratories Intertwining with Artificial Intelligence—A Narrative Review. Diagnostics 2021, 11, 1399. [Google Scholar] [CrossRef] [PubMed]
- Gruson, D.; Helleputte, T.; Rousseau, P.; Gruson, D. Data Science, Artificial Intelligence, and Machine Learning: Opportunities for Laboratory Medicine and the Value of Positive Regulation. Clin. Biochem. 2019, 69, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, F.; Banfi, G. Machine Learning in Laboratory Medicine: Waiting for the Flood? Clin. Chem. Lab. Med. 2018, 56, 516–524. [Google Scholar] [CrossRef] [PubMed]
- Ronzio, L.; Cabitza, F.; Barbaro, A.; Banfi, G. Has the Flood Entered the Basement? A Systematic Literature Review about Machine Learning in Laboratory Medicine. Diagnostics 2021, 11, 372. [Google Scholar] [CrossRef]
- Mannello, F.; Plebani, M. Current Issues, Challenges, and Future Perspectives in Clinical Laboratory Medicine. J. Clin. Med. 2022, 11, 634. [Google Scholar] [CrossRef]
- Hitzler, P.; Janowicz, K. Linked Data, Big Data, and the 4th Paradigm. Semant. Web 2013, 4, 233–235. [Google Scholar] [CrossRef] [Green Version]
- Diebold, F.X. On the Origin(s) and Development of the Term “Big Data.”, PIER Working Paper No. 12-037. SSRN Electron. J. 2012, 421. [Google Scholar] [CrossRef]
- De Mauro, A.; Greco, M.; Grimaldi, M. A Formal Definition of Big Data Based on Its Essential Features. Libr. Rev. 2016, 65, 122–135. [Google Scholar] [CrossRef]
- Lukoianova, T.; Rubin, V.L. Veracity Roadmap: Is Big Data Objective, Truthful and Credible? Adv. Classif. Res. Online 2014, 24, 4. [Google Scholar] [CrossRef] [Green Version]
- Reimer, A.P.; Madigan, E.A. Veracity in Big Data: How Good Is Good Enough. Health Inform. J. 2019, 25, 1290–1298. [Google Scholar] [CrossRef]
- Kitchin, R. The Data Revolution: Big Data, Open Data, Data Infrastructures & Their Consequences; SAGE Publications Ltd.: London, UK, 2014; ISBN 9781446287484. [Google Scholar]
- Kitchin, R.; McArdle, G. What Makes Big Data, Big Data? Exploring the Ontological Characteristics of 26 Datasets. Big Data Soc. 2016, 3, 205395171663113. [Google Scholar] [CrossRef]
- Tolan, N.V.; Parnas, M.L.; Baudhuin, L.M.; Cervinski, M.A.; Chan, A.S.; Holmes, D.T.; Horowitz, G.; Klee, E.W.; Kumar, R.B.; Master, S.R. “Big Data” in Laboratory Medicine. Clin. Chem. 2015, 61, 1433–1440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big Data in Healthcare: Management, Analysis and Future Prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- Cowie, M.R.; Blomster, J.I.; Curtis, L.H.; Duclaux, S.; Ford, I.; Fritz, F.; Goldman, S.; Janmohamed, S.; Kreuzer, J.; Leenay, M.; et al. Electronic Health Records to Facilitate Clinical Research. Clin. Res. Cardiol. 2017, 106, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. Comment: The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space. Synth. Lect. Semant. Web: Theory Technol. 2011, 1, 1–136. [Google Scholar] [CrossRef] [Green Version]
- Euzenat, J.; Shvaiko, P. Ontology Matching; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 978-3-642-38720-3. [Google Scholar]
- Hugo, W.; Le Franc, Y.; Coen, G.; Parland-von Essen, J.; Bonino, L. FAIR Semantics Recommendations—Second Iteration. 2020. Available online: https://zenodo.org/record/4314321/files/D2.5_FAIR_Semantics_Recommendations_Second_Iteration_VDRAFT.pdf (accessed on 13 July 2022).
- Griffiths, E.; Joseph, R.M.; Tilston, G.; Thew, S.; Kapacee, Z.; Dixon, W.; Peek, N. Findability of UK Health Datasets Available for Research: A Mixed Methods Study. BMJ Health Care Inf. 2022, 29, e100325. [Google Scholar] [CrossRef]
- Vines, T.H.; Albert, A.Y.K.; Andrew, R.L.; Débarre, F.; Bock, D.G.; Franklin, M.T.; Gilbert, K.J.; Moore, J.-S.; Renaut, S.; Rennison, D.J. The Availability of Research Data Declines Rapidly with Article Age. Curr Biol 2014, 24, 94–97. [Google Scholar] [CrossRef] [Green Version]
- Dahlweid, F.M.; Kämpf, M.; Leichtle, A. Interoperability of Laboratory Data in Switzerland—A Spotlight on Bern. J. Lab. Med. 2018, 42, 251–258. [Google Scholar] [CrossRef]
- FHIR Management Group Website for HL7 FHIR. 2022. Available online: https://www.hl7.org/fhir/ (accessed on 13 July 2022).
- Brickley, D.; Guha, R.V. RDF Schema 1.1.—W3C. 2004. Available online: https://www.w3.org/TR/rdf-schema/ (accessed on 13 July 2022).
- Boldi, P.; Vigna, S. The Webgraph Framework I. In Proceedings of the 13th Conference on World Wide Web—WWW ’04, New York, NY, USA, 17–22 May 2004; ACM Press: New York, NY, USA, 2004; p. 595. [Google Scholar]
- Coyle, K. Semantic Web and Linked Data. Libr. Technol. Rep. 2012, 48, 10–14. [Google Scholar]
- Hripcsak, G.; Duke, J.D.; Shah, N.H.; Reich, C.G.; Huser, V.; Schuemie, M.J.; Suchard, M.A.; Park, R.W.; Wong, I.C.K.; Rijnbeek, P.R.; et al. Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers. Stud. Health Technol Inf. 2015, 216, 574–578. [Google Scholar]
- Informatics, O.H.D.S. and The Book of OHDSI. 2021. Available online: https://ohdsi.github.io/TheBookOfOhdsi/ (accessed on 13 July 2022).
- tranSMART Foundation I2b2 Website. 2022. Available online: https://www.i2b2.org (accessed on 13 July 2022).
- Sweeney, L. K-Anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L -Diversity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Aggarwal, C.C. On K-Anonymity and the Curse of Dimensionality. In Proceedings of the VLDB, Trondheim, Norway, 30 August–2 September 2005; Volume 5, pp. 901–909. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. T-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Yin, C.; Zhang, S.; Xi, J.; Wang, J. An Improved Anonymity Model for Big Data Security Based on Clustering Algorithm. Concurr. Comput. Pract. Exp. 2017, 29, e3902. [Google Scholar] [CrossRef]
- McCord, K.A.; Hemkens, L.G. Using Electronic Health Records for Clinical Trials: Where Do We Stand and Where Can We Go? Cmaj 2019, 191, E128–E133. [Google Scholar] [CrossRef] [Green Version]
- Scheibner, J.; Ienca, M.; Kechagia, S.; Troncoso-Pastoriza, J.R.; Raisaro, J.L.; Hubaux, J.P.; Fellay, J.; Vayena, E. Data Protection and Ethics Requirements for Multisite Research with Health Data: A Comparative Examination of Legislative Governance Frameworks and the Role of Data Protection Technologies. J. Law Biosci. 2020, 7, lsaa010. [Google Scholar] [CrossRef]
- Price, W.N.; Cohen, I.G. Privacy in the Age of Medical Big Data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef]
- Samuel, G.; Chubb, J.; Derrick, G. Boundaries Between Research Ethics and Ethical Research Use in Artificial Intelligence Health Research. J. Empir. Res. Hum. Res. Ethics 2021, 16, 325–337. [Google Scholar] [CrossRef]
- Ferretti, A.; Ienca, M.; Velarde, M.R.; Hurst, S.; Vayena, E. The Challenges of Big Data for Research Ethics Committees: A Qualitative Swiss Study. J. Empir. Res. Hum. Res. Ethics 2022, 17, 129–143. [Google Scholar] [CrossRef]
- Raisaro, J.L.; Troncoso-Pastoriza, J.R.; Misbach, M.; Sousa, J.S.; Pradervand, S.; Missiaglia, E.; Michielin, O.; Ford, B.; Hubaux, J.P. MEDCO: Enabling Secure and Privacy-Preserving Exploration of Distributed Clinical and Genomic Data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1328–1341. [Google Scholar] [CrossRef] [Green Version]
- Wirth, F.N.; Meurers, T.; Johns, M.; Prasser, F. Privacy-Preserving Data Sharing Infrastructures for Medical Research: Systematization and Comparison. BMC Med. Inform. Decis. Mak. 2021, 21, 242. [Google Scholar] [CrossRef] [PubMed]
- Medical Laboratories of Switzerland L4CHLAB Project. 2021. Available online: https://sphn.ch/wp-content/uploads/2021/04/2021-L4CHLAB-Process.pdf (accessed on 13 July 2022).
- FDA. Global Unique Device Identification Database Submission. Available online: https://www.fda.gov/medical-devices/unique-device-identification-system-udi-system/global-unique-device-identification-database-gudid (accessed on 13 July 2022).
- IDABC. IDABC—EUDAMED: European Database on Medical Devices. Available online: http://ec.europa.eu/idabc/en/document/2256/5637.html (accessed on 13 July 2022).
- GMDN Agency GMDN Agency. 2021. Available online: https://www.gmdnagency.org (accessed on 13 July 2022).
- Commission, E.; Emdn, T.; Commission, E. European Medical Device Nomenclature (EMDN). Available online: https://ec.europa.eu/health/system/files/2021-06/md_2021-12_en_0.pdf (accessed on 13 July 2022).
- SPHN. The SPHN Semantic Interoperability Framework. Available online: https://sphn.ch/network/data-coordination-center/the-sphn-semantic-interoperability-framework/ (accessed on 13 July 2022).
- Hernandez-Boussard, T.; Bozkurt, S.; Ioannidis, J.P.A.; Shah, N.H. MINIMAR (MINimum Information for Medical AI Reporting): Developing Reporting Standards for Artificial Intelligence in Health Care. J. Am. Med. Inf. Assoc. 2020, 27, 2011–2015. [Google Scholar] [CrossRef] [PubMed]
- Norgeot, B.; Quer, G.; Beaulieu-Jones, B.K.; Torkamani, A.; Dias, R.; Gianfrancesco, M.; Arnaout, R.; Kohane, I.S.; Saria, S.; Topol, E.; et al. Minimum Information about Clinical Artificial Intelligence Modeling: The MI-CLAIM Checklist. Nat. Med. 2020, 26, 1320–1324. [Google Scholar] [CrossRef]
- Gamble, M.; Goble, C.; Klyne, G.; Zhao, J. MIM: A Minimum Information Model Vocabulary and Framework for Scientific Linked Data. In Proceedings of the 2012 IEEE 8th International Conference on E-Science, Chicago, IL, USA, 8–12 October 2012; pp. 1–8. [Google Scholar]
- Hughes, G.; Mills, H.; De Roure, D.; Frey, J.G.; Moreau, L.; Schraefel, M.C.; Smith, G.; Zaluska, E. The Semantic Smart Laboratory: A System for Supporting the Chemical EScientist. Org. Biomol. Chem. 2004, 2, 3284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Knublauch, H.; Kontokostas, D. Shapes Constraint Language (SHACL) Website—W3C. 2017. Available online: https://www.w3.org/TR/shacl/ (accessed on 13 July 2022).
- Knublauch, H.; Allemang, D.; Steyskal, S. SHACL Advanced Features—W3C. 2017. Available online: https://www.w3.org/TR/shacl-af/ (accessed on 13 July 2022).
- Knublauch, H.; Maria, P. SHACL JavaScript Extensions—W3C. 2017. Available online: https://www.w3.org/TR/shacl-js/ (accessed on 13 July 2022).
- Bilke, A.; Naumann, F. Schema Matching Using Duplicates. In Proceedings of the Proceedings—International Conference on Data Engineering, Tokoyo, Japan, 5–8 April 2005; pp. 69–80. [Google Scholar]
- Nikolov, A.; Motta, E. Capturing Emerging Relations between Schema Ontologies on the Web of Data. CEUR Workshop Proc. 2011, 665, 1–12. [Google Scholar]
- Lehmann, S.; Guadagni, F.; Moore, H.; Ashton, G.; Barnes, M.; Benson, E.; Clements, J.; Koppandi, I.; Coppola, D.; Demiroglu, S.Y.; et al. Standard Preanalytical Coding for Biospecimens: Review and Implementation of the Sample PREanalytical Code (SPREC). Biopreservation Biobanking 2012, 10, 366–374. [Google Scholar] [CrossRef] [PubMed]
- Wagner, A.S.; Waite, L.K.; Wierzba, M.; Hoffstaedter, F.; Waite, A.Q.; Poldrack, B.; Eickhoff, S.B.; Hanke, M. FAIRly Big: A Framework for Computationally Reproducible Processing of Large-Scale Data. Sci Data 2022, 9, 80. [Google Scholar] [CrossRef]
- Perakakis, N.; Yazdani, A.; Karniadakis, G.E.; Mantzoros, C. Omics, Big Data and Machine Learning as Tools to Propel Understanding of Biological Mechanisms and to Discover Novel Diagnostics and Therapeutics. Metab. Clin. Exp. 2018, 87, A1–A9. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Li, L.; Xu, Y.; Yang, J. Machine Learning Meets Omics: Applications and Perspectives. Brief. Bioinform. 2022, 23, 460. [Google Scholar] [CrossRef]
- Wang, Z.; He, Y. Precision Omics Data Integration and Analysis with Interoperable Ontologies and Their Application for COVID-19 Research. Brief. Funct. Genom. 2021, 20, 235–248. [Google Scholar] [CrossRef]
- Kahn, M.G.; Mui, J.Y.; Ames, M.J.; Yamsani, A.K.; Pozdeyev, N.; Rafaels, N.; Brooks, I.M. Migrating a Research Data Warehouse to a Public Cloud: Challenges and Opportunities. J. Am. Med. Inform. Assoc. 2022, 29, 592–600. [Google Scholar] [CrossRef] [PubMed]
- Nydegger, U.; Lung, T.; Risch, L.; Risch, M.; Medina Escobar, P.; Bodmer, T. Inflammation Thread Runs across Medical Laboratory Specialities. Mediat. Inflamm. 2016, 2016, 4121837. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Pandis, I.; Wu, C.; He, S.; Johnson, D.; Emam, I.; Guitton, F.; Guo, Y. High Dimensional Biological Data Retrieval Optimization with NoSQL Technology. BMC Genom. 2014, 15, S3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ehrlich, M. Risks and Rewards of Big-Data in Epigenomics Research: An Interview with Melanie Ehrlich. Epigenomics 2022, 14, 351–358. [Google Scholar] [CrossRef] [PubMed]
- Halder, A.; Verma, A.; Biswas, D.; Srivastava, S. Recent Advances in Mass-Spectrometry Based Proteomics Software, Tools and Databases. Drug Discov. Today Technol. 2021, 39, 69–79. [Google Scholar] [CrossRef]
- Santos, A.; Colaço, A.R.; Nielsen, A.B.; Niu, L.; Strauss, M.; Geyer, P.E.; Coscia, F.; Albrechtsen, N.J.W.; Mundt, F.; Jensen, L.J.; et al. A Knowledge Graph to Interpret Clinical Proteomics Data. Nat. Biotechnol. 2022, 40, 692–702. [Google Scholar] [CrossRef]
- Tolani, P.; Gupta, S.; Yadav, K.; Aggarwal, S.; Yadav, A.K. Big Data, Integrative Omics and Network Biology. In Advances in Protein Chemistry and Structural Biology; Elsevier: Amsterdam, The Netherlands, 2021; Volume 127, pp. 127–160. ISBN 9780323853194. [Google Scholar]
- Passi, A.; Tibocha-Bonilla, J.D.; Kumar, M.; Tec-Campos, D.; Zengler, K.; Zuniga, C. Genome-Scale Metabolic Modeling Enables in-Depth Understanding of Big Data. Metabolites 2022, 12, 14. [Google Scholar] [CrossRef]
- Sen, P.; Lamichhane, S.; Mathema, V.B.; McGlinchey, A.; Dickens, A.M.; Khoomrung, S.; Orešič, M. Deep Learning Meets Metabolomics: A Methodological Perspective. Brief. Bioinform. 2021, 22, 1531–1542. [Google Scholar] [CrossRef]
- Ferraro Petrillo, U.; Palini, F.; Cattaneo, G.; Giancarlo, R. FASTA/Q Data Compressors for MapReduce-Hadoop Genomics: Space and Time Savings Made Easy. BMC Bioinform. 2021, 22, 144. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Gu, J.; Genchev, G.Z.; Cai, X.; Wang, Y.; Guo, J.; Tian, G.; Lu, H. Improving the Diagnosis of Phenylketonuria by Using a Machine Learning–Based Screening Model of Neonatal MRM Data. Front. Mol. Biosci. 2020, 7, 115. [Google Scholar] [CrossRef]
- Marwaha, S.; Knowles, J.W.; Ashley, E.A. A Guide for the Diagnosis of Rare and Undiagnosed Disease: Beyond the Exome. Genome Med. 2022, 14, 23. [Google Scholar] [CrossRef] [PubMed]
- The European Parliament and Council Regulation on Medical Devices. Available online: http://data.europa.eu/eli/reg/2017/745/2020-04-24 (accessed on 13 July 2022).
- Goodall, A.; Bos, G. ISO 13485:2003 Medical Devices—Quality Management Systems—Requirements for Regulatory Purposes. Available online: https://www.iso.org/standard/59752.html (accessed on 13 July 2022).
- European Commission Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 (accessed on 13 July 2022).
- U.S. Food and Drug Administration. Good Machine Learning Practice for Medical Device Development: Guiding Principles. Available online: https://www.fda.gov/medical-devices/software-medical-device-samd/good-machine-learning-practice-medical-device-development-guiding-principles (accessed on 13 July 2022).
- The Medicines and Healthcare Products Regulatory Agency (MHRA). Transforming the Regulation of Software and Artificial Intelligence as a Medical Device. Available online: https://www.gov.uk/government/news/transforming-the-regulation-of-software-and-artificial-intelligence-as-a-medical-device (accessed on 13 July 2022).
- Abràmoff, M.D.; Lavin, P.T.; Birch, M.; Shah, N.; Folk, J.C. Pivotal Trial of an Autonomous AI-Based Diagnostic System for Detection of Diabetic Retinopathy in Primary Care Offices. npj Digit. Med. 2018, 1, 39. [Google Scholar] [CrossRef] [PubMed]
- FDA Permits Marketing of Artificial Intelligence-Based Device to Detect Certain Diabetes-Related Eye Problems. Available online: https://www.fda.gov/news-events/press-announcements/fda-permits-marketing-artificial-intelligence-based-device-detect-certain-diabetes-related-eye (accessed on 13 July 2022).
- Polish Center for Testing and Certification EC Certificate No. 1434-MDD-228/2019. Available online: https://uploads-ssl.webflow.com/5c118f855cb29ab026a90802/5dc09f28b316f423d17ce52b_CertyfikatyPCBC.pdf (accessed on 13 July 2022).
- Chauhan, K.P.; Trivedi, A.P.; Patel, D.; Gami, B.; Haridas, N. Monitoring and Root Cause Analysis of Clinical Biochemistry Turn Around Time at an Academic Hospital. Indian J. Clin. Biochem. 2014, 29, 505–509. [Google Scholar] [CrossRef] [Green Version]
- Mejía-Salazar, J.R.; Cruz, K.R.; Vásques, E.M.M.; de Oliveira, O.N. Microfluidic Point-of-Care Devices: New Trends and Future Prospects for Ehealth Diagnostics. Sensors 2020, 20, 1951. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.; Seidenberg, R.; Schuh, S.K.; Exadaktylos, A.K.; Schechter, C.B.; Leichtle, A.B.; Hautz, W.E. The Development and Validation of Different Decision-Making Tools to Predict Urine Culture Growth out of Urine Flow Cytometry Parameter. PLoS ONE 2018, 13, e0193255. [Google Scholar] [CrossRef]
- Schütz, N.; Leichtle, A.B.; Riesen, K. A Comparative Study of Pattern Recognition Algorithms for Predicting the Inpatient Mortality Risk Using Routine Laboratory Measurements. Artif. Intell. Rev. 2019, 52, 2559–2573. [Google Scholar] [CrossRef]
- Nakas, C.T.; Schütz, N.; Werners, M.; Leichtle, A.B.L. Accuracy and Calibration of Computational Approaches for Inpatient Mortality Predictive Modeling. PLoS ONE 2016, 11, e0159046. [Google Scholar] [CrossRef] [Green Version]
- Witte, H.; Nakas, C.T.; Bally, L.; Leichtle, A.B. Machine-Learning Prediction of Hypo- and Hyperglycemia from Electronic Health Records: Algorithm Development and Validation. JMIR Form. Res. 2022, 6, e36176. [Google Scholar] [CrossRef]
- Cadamuro, J.; Hillarp, A.; Unger, A.; von Meyer, A.; Bauçà, J.M.; Plekhanova, O.; Linko-Parvinen, A.; Watine, J.; Leichtle, A.; Buchta, C.; et al. Presentation and Formatting of Laboratory Results: A Narrative Review on Behalf of the European Federation of Clinical Chemistry and Laboratory Medicine (EFLM) Working Group “Postanalytical Phase” (WG-POST). Crit. Rev. Clin. Lab. Sci. 2021, 58, 329–353. [Google Scholar] [CrossRef]
- Perakslis, E.; Coravos, A. Is Health-Care Data the New Blood? Lancet Digit. Health 2019, 1, e8–e9. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
| Requirements | Implementation |
|---|---|
| Findability |
|
| Accessibility |
|
| Interoperability |
|
| Reusability |
|
| + |
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blatter, T.U.; Witte, H.; Nakas, C.T.; Leichtle, A.B. Big Data in Laboratory Medicine—FAIR Quality for AI? Diagnostics 2022, 12, 1923. https://doi.org/10.3390/diagnostics12081923
Blatter TU, Witte H, Nakas CT, Leichtle AB. Big Data in Laboratory Medicine—FAIR Quality for AI? Diagnostics. 2022; 12(8):1923. https://doi.org/10.3390/diagnostics12081923
Chicago/Turabian StyleBlatter, Tobias Ueli, Harald Witte, Christos Theodoros Nakas, and Alexander Benedikt Leichtle. 2022. "Big Data in Laboratory Medicine—FAIR Quality for AI?" Diagnostics 12, no. 8: 1923. https://doi.org/10.3390/diagnostics12081923
APA StyleBlatter, T. U., Witte, H., Nakas, C. T., & Leichtle, A. B. (2022). Big Data in Laboratory Medicine—FAIR Quality for AI? Diagnostics, 12(8), 1923. https://doi.org/10.3390/diagnostics12081923