
CAD-ALZ: A Blockwise Fine-Tuning Strategy on Convolutional Model and Random Forest Classifier for Recognition of Multistage Alzheimer’s Disease



Abstract
:1. Introduction
- (1)
- This study proposes the CAD-ALZ model for joint deep and robust feature extraction, which are critical to diagnose Alzheimer’s disease (ALZ).
- (2)
- This paper integrates a blockwise fine-tune strategy into ConvMixer to extract deep features. This strategy unit is proposed in place of the attention module that promotes the flow of information with more efficient computation.
- (3)
- The CAD-ALZ model offers a cutting-edge diagnosis for the identification of stages of ALZ disease in an efficient manner compared to other approaches.
- (4)
- Multiple classes of ALZ are greatly imbalanced. To balance and increase this dataset, a data augmentation technique is applied.
- (5)
- Extensive experiments are performed on two publicly available benchmarks such as Kaggle-ALZ and ADNI. A detailed comparative study was presented to compare the proposed strategy to other existing DL approaches.
2. Literature Review
3. Materials and Methods
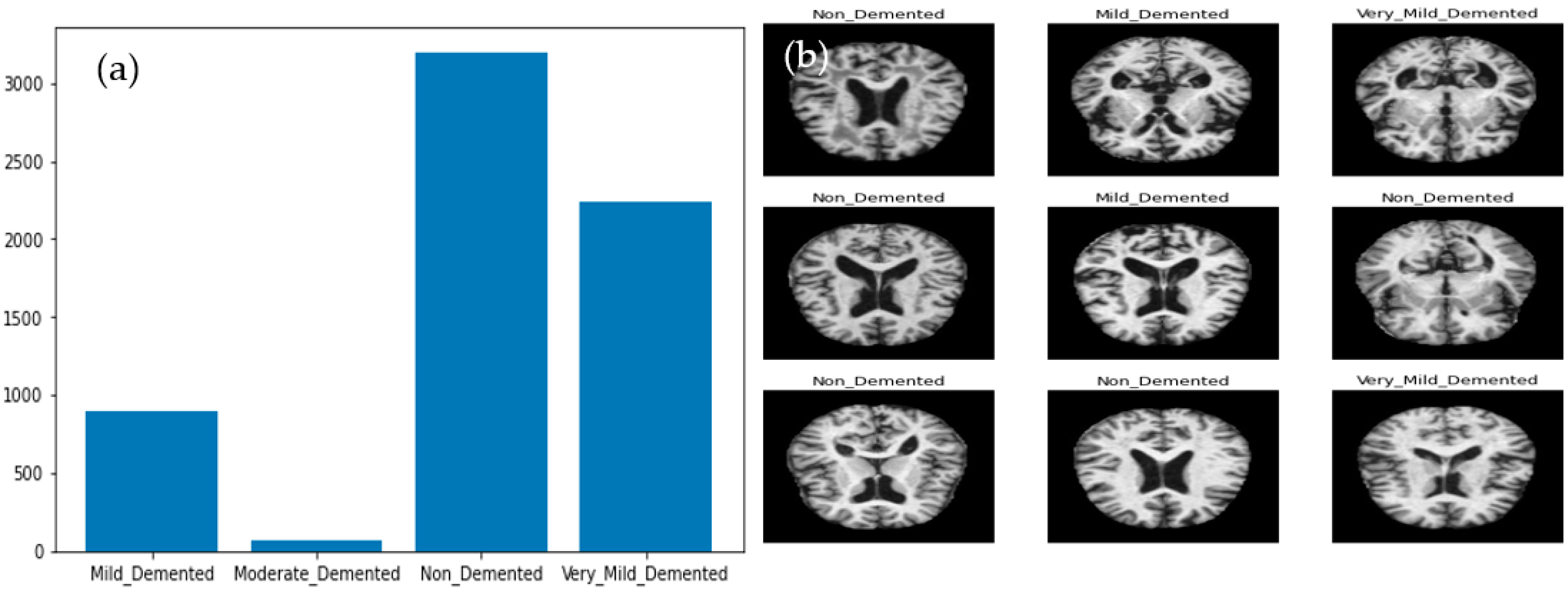
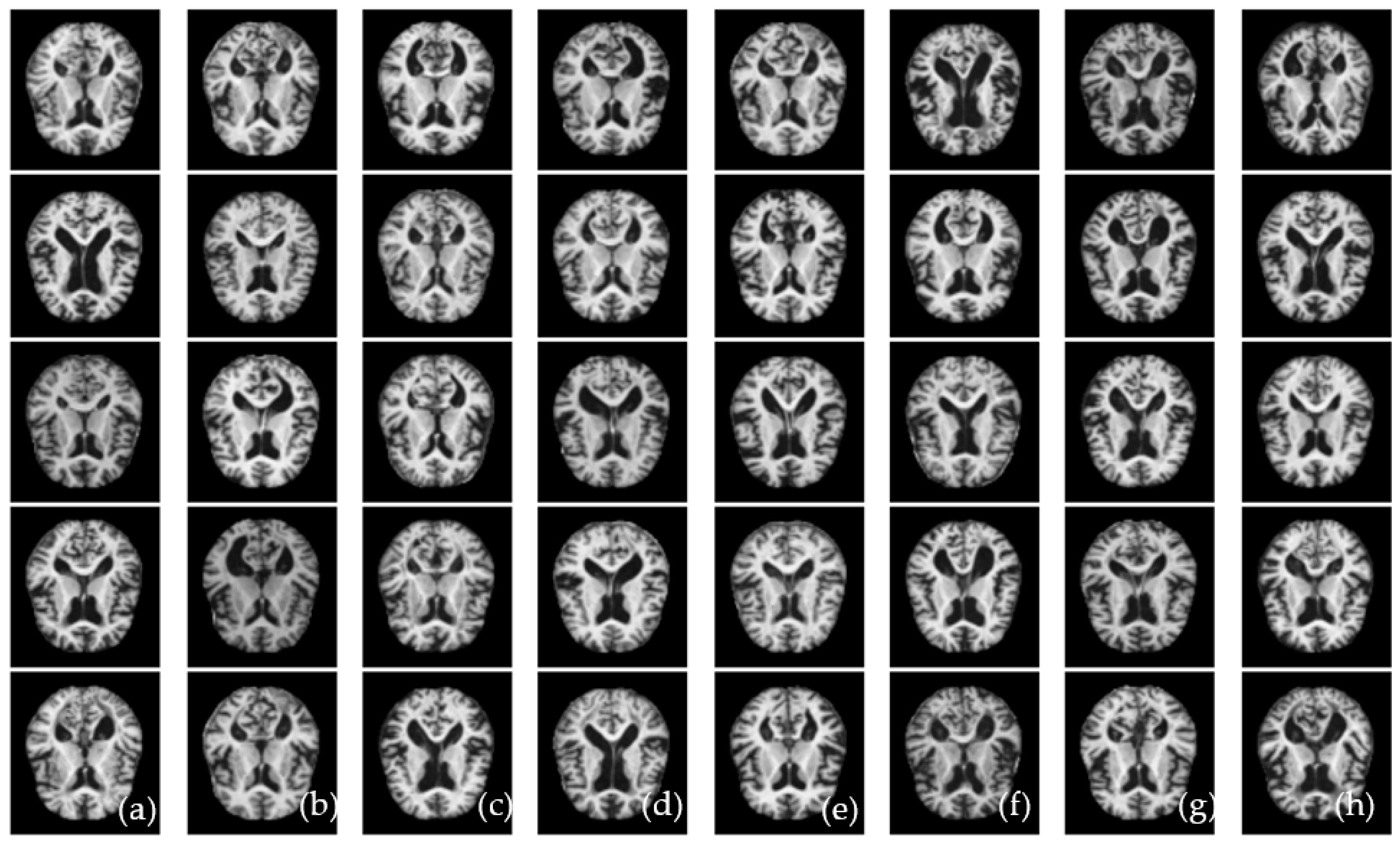
3.1. Data Acquisition
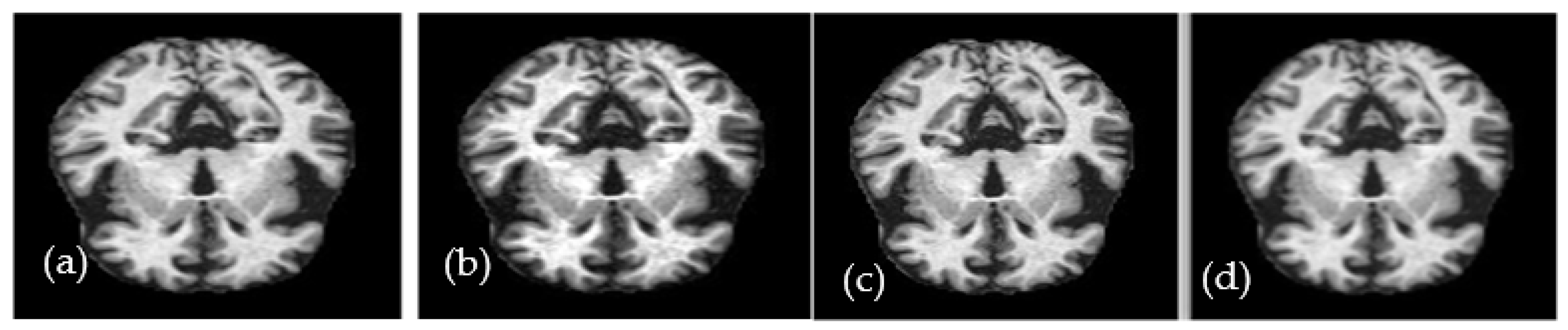
3.2. Preprocessing and Data Augmentation
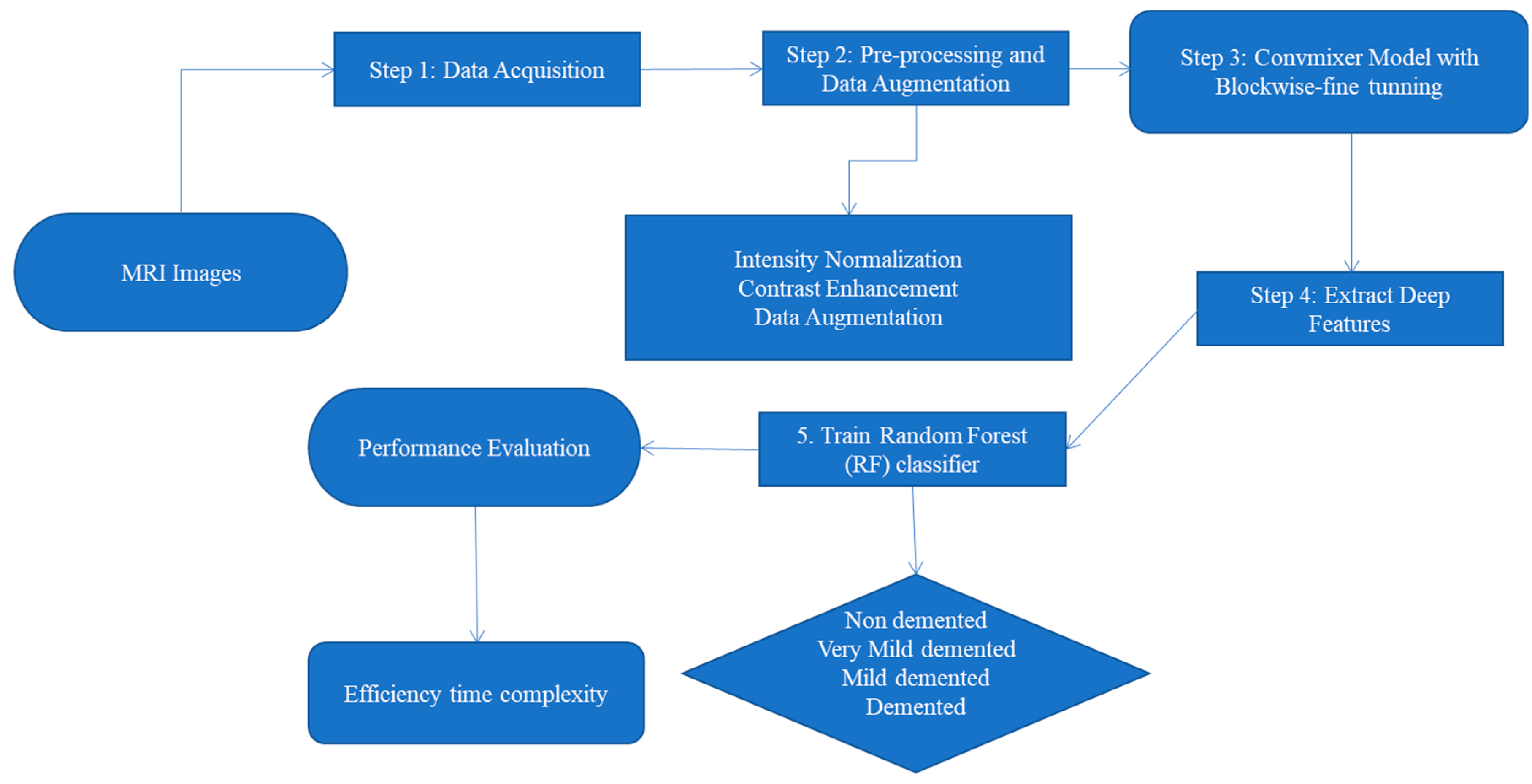
3.3. Proposed System Overview
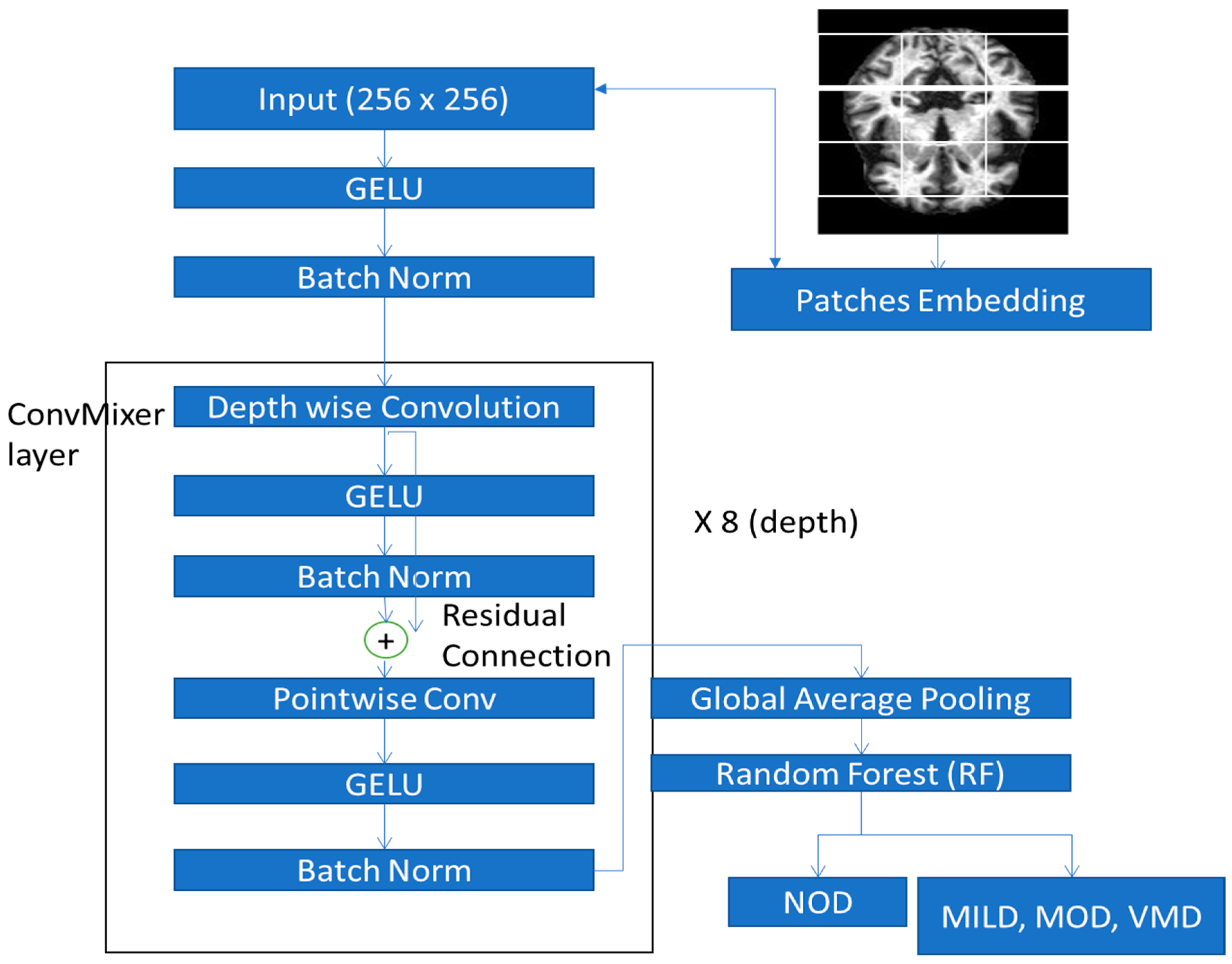
3.3.1. Deep Feature Extraction Using ConvMixer
| Algorithm 1: Proposed ConvMixer model with fine-tuning for robust feature extraction | |
| 1. | Input: Input Training Data, Tensor (), Image patches. |
| 2. | Output: Extracted feature map |
| 3. | Main Process: Function Depthwise_CNN and Pointwise_CNN for depthwise separable convolution. |
| 4. | block (b1) = Depthwise_CNN and Pointwise_CNN function block takes as inputs tensor (). |
| 5. | - For each ConvMixer block do |
| 6. | - Depthwise_CNN function includes (3 × 3) size is applied to inside Depthwise_CNN function. The BN function is performed. ReLU() activation function is applied and Pointwise_CNN() function including (1 × 1) size is applied to inside Pointwise_CNN function. BN() function is performed. ReLU() activation function is applied. [Blockwise fine-tune strategy for pre-trained model] |
| 7. | - (a) Remove last FC and Softmax layer from Inception v3 and Add Dense layer and dropout layer |
| 8. | - (b) Remove last FC and Softmax layer from Inception v3 and Add dense layer to network - [End for loop] |
| 9. | Structure of Model
|
| 10. | Afterward, the feature map F is generated by using average pool layer. |
3.3.2. Proposed ConvMixer Model Architecture
3.3.3. Blockwise Fine-Tuning Strategy
3.4. Feature Classification by Random Forest (RF) Classifier
| Algorithm 2: Random Forest (RF) classifier and final decision with majority voting scheme | |
| 1. | Input: Input A training set , features F number of trees in forest (m). |
| 2. | Output: Predict class for Alzheimer’s disease. Main Process: |
| 3. | function RandomForest (tn, Fn) |
| 4. | Initialize and For i = 1 to m do |
| 5. | |
| 6. | and [end for loop] [Function end] Function RandomizeTreeLearn () |
| 7. | If node contains only one class, then return else |
| 8. | At each node of tree: and split on best information gain features in f. |
| 9. | Return RandomizeTreeLearn () |
| 10. | [End function] |
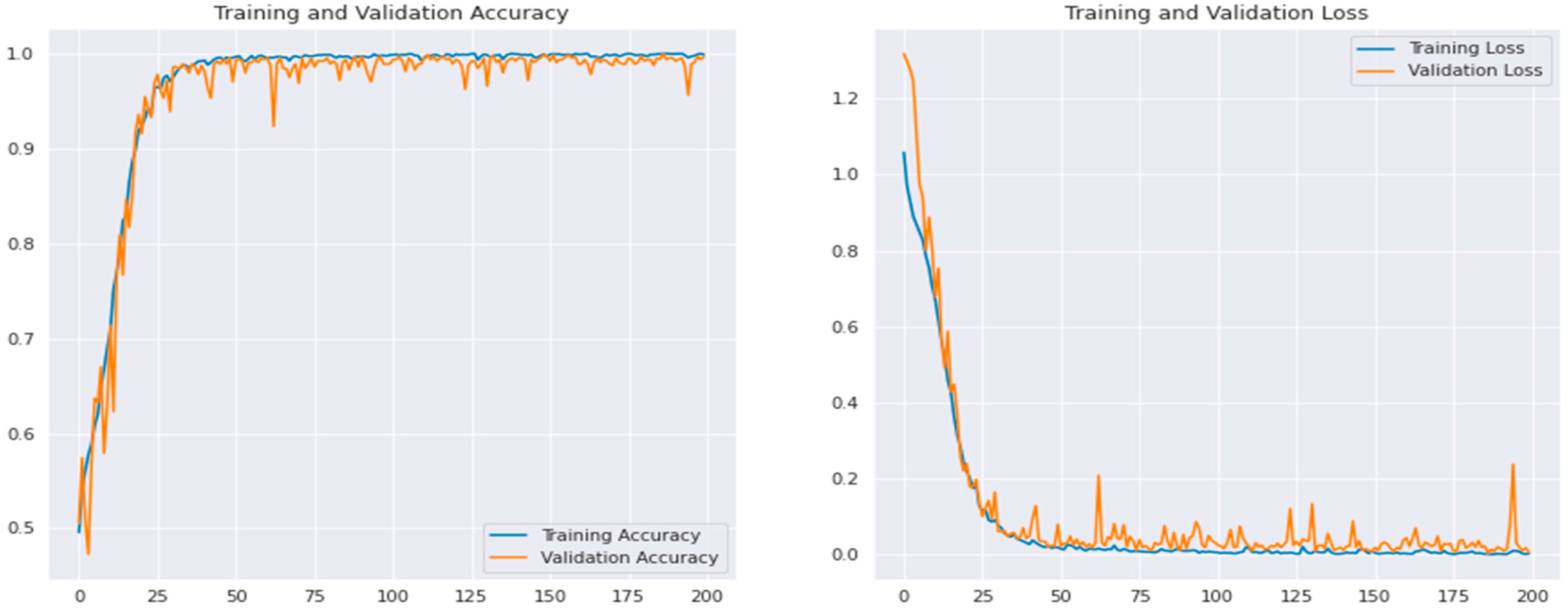
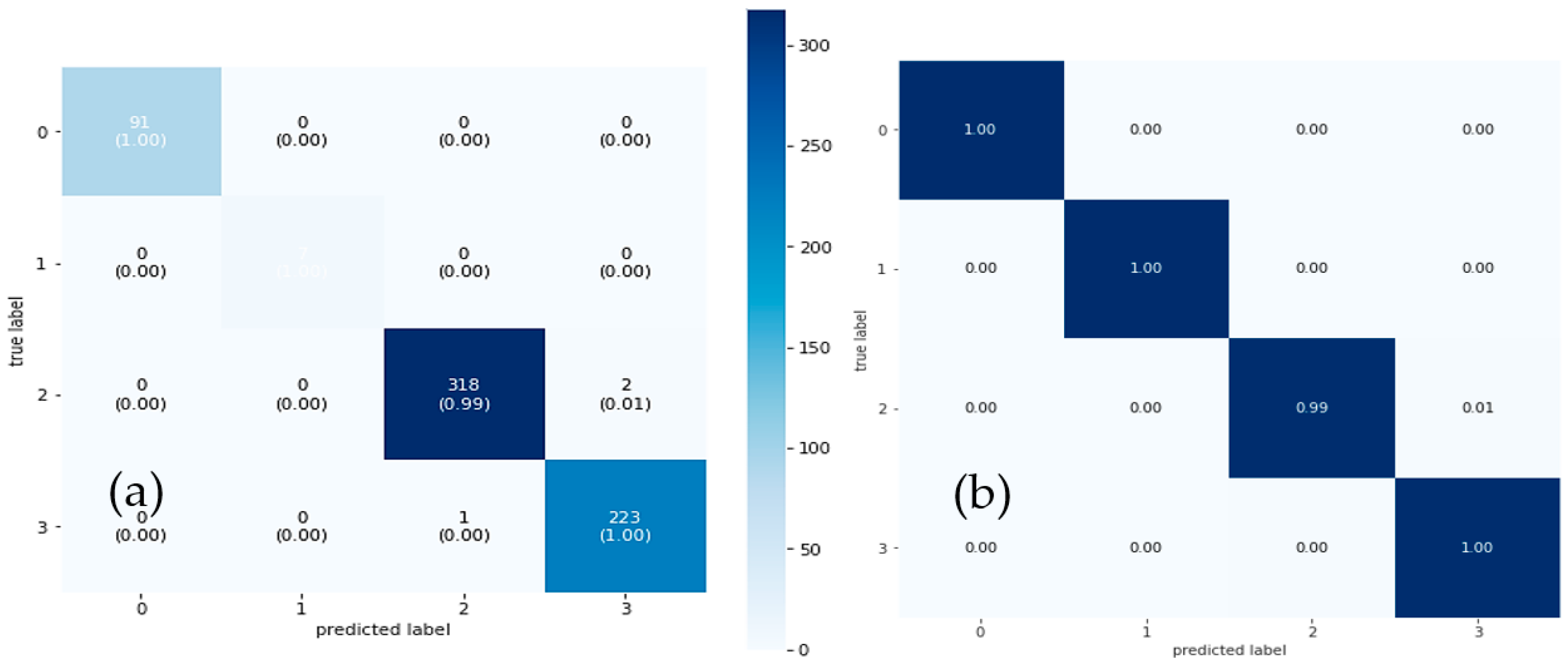
4. Experimental Results
4.1. Environment Setup
4.2. Statistical Performance Metrics
4.3. Results Analysis
4.4. Computational Cost
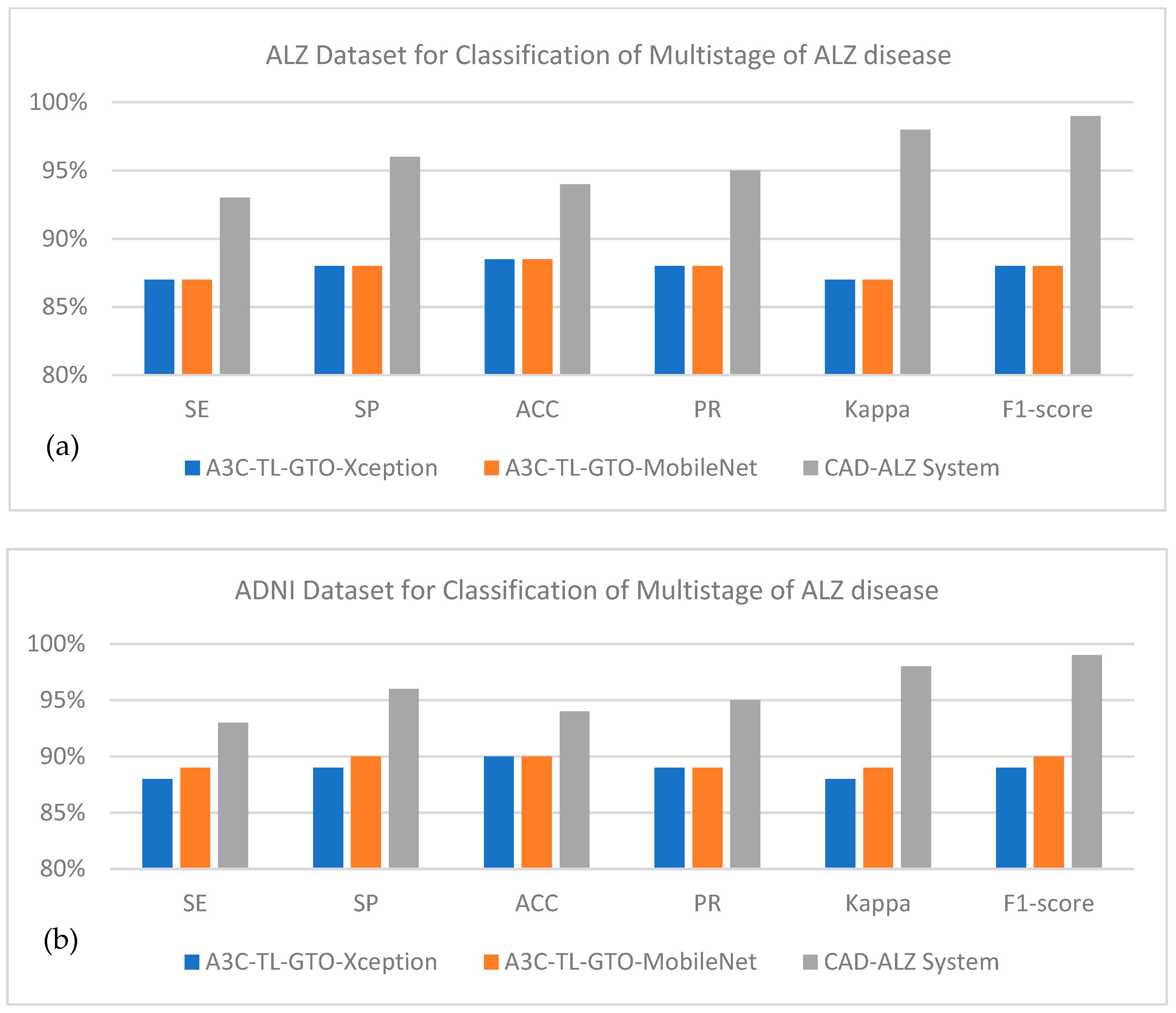
4.5. State-of-the-Art Comparisons
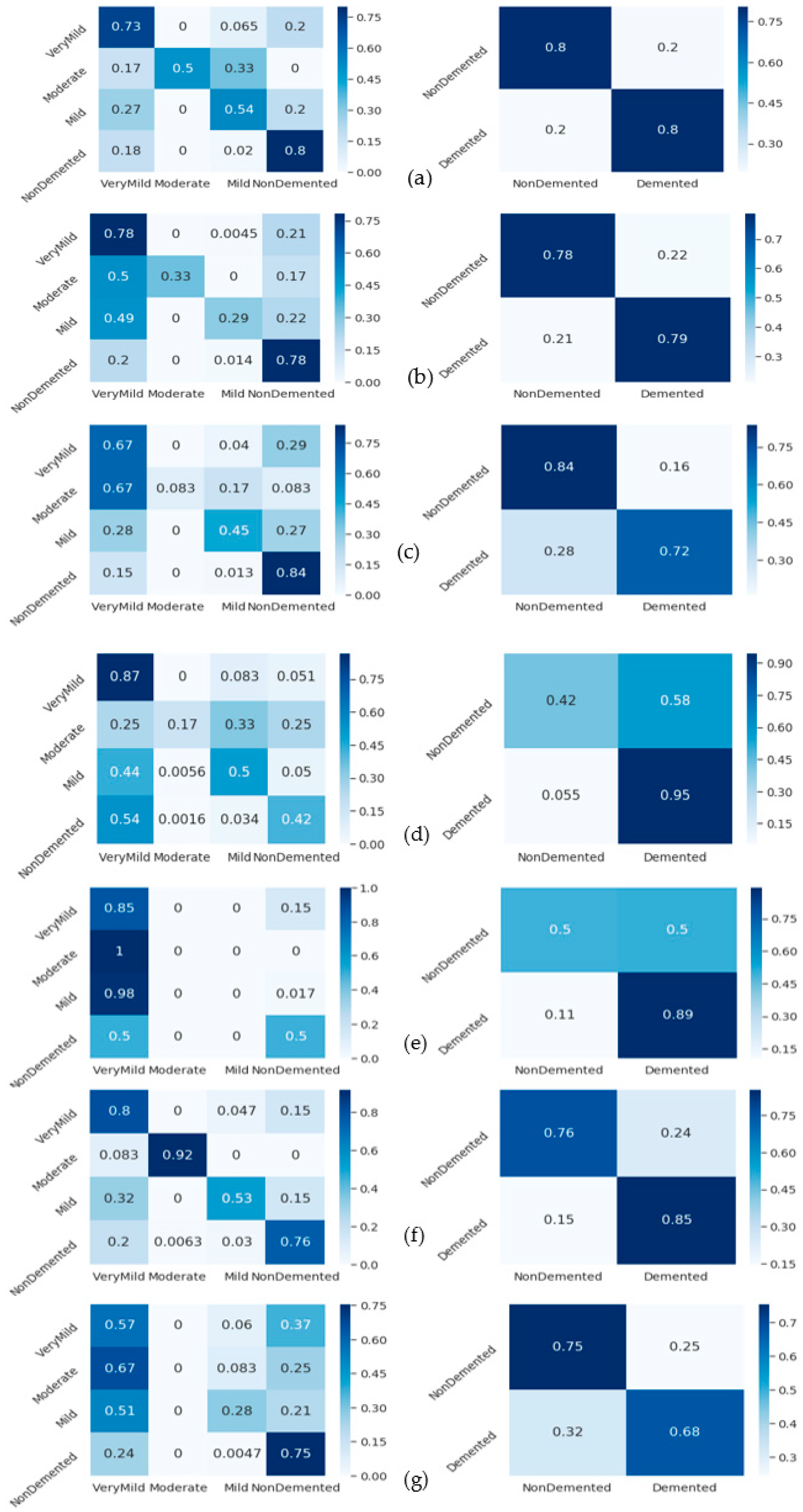
4.6. Analyze Generalizability of CAD-ALZ System
5. Discussion
5.1. Limitations of CAD-ALZ System
- Lack of changes in a patient’s state of health between a pair of trips. Out of the total MRI images gathered during patient visits, there are only few transitions. Instead of generalizing the crucial differences between the various phases of ALZ disease, it is simple for the model to overfit and memorize the status of a patient at each visit.
- The time complexity of the CAD-ALZ model can be calculated further on the cloud platform.
- Our goal is to make models that can accurately classify brain MRIs based on their true stage in the progression of Alzheimer’s disease. These models should be able to do this regardless of the number of visits, the lack of patient transitions, or small differences in scan quality. We hope to keep these difficulties in mind when designing future experiments.
- We can test our proposed transfer learning model to other datasets, which would make it easier to increase these models’ capacity to generalize across datasets.
- The preprocessing step is applied to increase the contrast and reduce the noise. We should test different methodologies compared to what has been used in this paper.
5.2. Future Directions of CAD-ALZ System
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | Explain Term |
| ALZ | Alzheimer |
| CAD | Computer-aided diagnosis |
| MD | Mental deterioration |
| AD | Alzheimer’s disease |
| MCI | Mild cognitive impairment |
| NC | Normal control |
| MRI | Magnetic resonance imaging |
| ROIs | Region-of-interests |
| ML | Machine learning |
| 2D/3D | Two dimensions or three dimensions |
| DL | Deep learning |
| CNNs | Convolutional neural networks |
| ADNI | Alzheimer’s disease neuroimaging initiative |
| TL | Transfer learning |
| wiseDNN | Weakly supervised densely connected neural network |
| FWPNN | FCM-based weighted probabilistic neural network |
| GLCM | Gray level co-occurrence matrix |
| DSAE | Stacked denoising sparse auto-encoder |
| DenseNet | Densely Connected Convolutional Networks |
| AUC | Area under the ROC Curve |
| VGG19 | Visual geometry group of 19 layers |
| BiLSTM | Bidirectional long short-term memory |
| DTE | Deep transfer ensemble |
| ISDL | Iterative sparse and deep learning |
| DNN | Deep neural network |
| SVM | Support vector machine |
| KNN | K-nearest neighbor |
| RF | Random forest |
| DBN | Deep belief network |
| GELU | Gaussian error linear unit |
| NVIDIA GPU | Nvidia graphics processing unit |
| FLOPS | Floating point operations per second |
References
- Sheng, J.; Xin, Y.; Zhang, Q.; Wang, L.; Yang, Z.; Yin, J. Predictive classification of Alzheimer’s disease using brain imaging and genetic data. Sci. Rep. 2022, 12, 2405. [Google Scholar] [CrossRef] [PubMed]
- Jo, T.; Nho, K.; Saykin, A.J. Deep learning in Alzheimer’s disease: Diagnostic classification and prognostic prediction using neuroimaging data. Front. Aging Neurosci. 2019, 11, 220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ebrahimighahnavieh, M.A.; Luo, S.; Chiong, R. Deep learning to detect Mental deterioration from neuroimaging: A systematic literature review. Comput. Methods Programs Biomed. 2020, 187, 105–122. [Google Scholar] [CrossRef]
- Noor, M.B.T.; Zenia, N.Z.; Kaiser, M.S.; Al Mamun, S.; Mahmud, M. Application of deep learning in detecting neurological disorders from magnetic resonance images: A survey on the detection of Alzheimer’s disease, Parkinson’s disease and schizophrenia. Brain Inform. 2020, 7, 11. [Google Scholar] [CrossRef] [PubMed]
- Acharya, U.R.; Fernandes, S.L.; WeiKoh, J.E.; Ciaccio, E.J.; Fabell, M.K.M.; Tanik, U.J.; Rajinikanth, V.; Yeong, C.H. Automated detection of Mental deterioration using brain MRI images–a study with various feature extraction techniques. J. Med. Syst. 2019, 43, 302. [Google Scholar] [CrossRef]
- Zhu, G.; Jiang, B.; Tong, L.; Xie, Y.; Zaharchuk, G.; Wintermark, M. Applications of deep learning to neuro-imaging techniques. Front. Neurol. 2019, 10, 869. [Google Scholar] [CrossRef] [PubMed]
- Pellegrini, E.; Ballerini, L.; Hernandez, M.D.C.V.; Chappell, F.M.; González-Castro, V.; Anblagan, D.; Danso, S.; Muñoz-Maniega, S.; Job, D.; Pernet, C.; et al. Machine learning of neuroimaging for assisted diagnosis of cognitive impairment and dementia: A systematic review. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 519–535. [Google Scholar] [CrossRef]
- Ramzan, F.; Khan, M.U.G.; Rehmat, A.; Iqbal, S.; Saba, T.; Rehman, A.; Mehmood, Z. A deep learning approach for automated diagnosis and multi-class classification of Mental deterioration stages using resting-state fMRI and residual neural networks. J. Med. Syst. 2020, 44, 37. [Google Scholar] [CrossRef]
- Bi, X.; Li, S.; Xiao, B.; Li, Y.; Wang, G.; Ma, X. Computer aided Mental deterioration diagnosis by an unsupervised deep learning technology. Neurocomputing 2020, 392, 296–304. [Google Scholar] [CrossRef]
- Goenka, N.; Tiwari, S. AlzVNet: A volumetric convolutional neural network for multiclass classification of Alzheimer’s disease through multiple neuroimaging computational approaches. Biomed. Signal Process. Control 2022, 74, 1–15. [Google Scholar] [CrossRef]
- Sivaranjini, S.; Sujatha, C.M. Deep learning based diagnosis of Parkinson’s disease using convolutional neural network. Multimed. Tools Appl. 2020, 79, 15467–15479. [Google Scholar] [CrossRef]
- Gao, X.W.; Hui, R.; Tian, Z. Classification of CT brain images based on deep learning networks. Comput. Methods Programs Biomed. 2017, 138, 49–56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kam, T.E.; Zhang, H.; Jiao, Z.; Shen, D. Deep learning of static and dynamic brain functional networks for early MCI detection. IEEE Trans. Med. Imaging 2019, 39, 478–487. [Google Scholar] [CrossRef] [PubMed]
- Ju, R.; Hu, C.; Li, Q. Early diagnosis of Mental deterioration based on resting-state brain networks and deep learning. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 16, 244–257. [Google Scholar] [CrossRef]
- Murugan, S.; Venkatesan, C.; Sumithra, M.G.; Gao, X.Z.; Elakkiya, B.; Akila, M.; Manoharan, S. DEMNET: A deep learning model for early diagnosis of Alzheimer diseases and dementia from MR images. IEEE Access 2021, 9, 90319–90329. [Google Scholar] [CrossRef]
- Mehmood, A.; Maqsood, M.; Bashir, M.; Shuyuan, Y. A deep Siamese convolution neural network for multi-class classification of Alzheimer disease. Brain Sci. 2020, 10, 84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, J.; Zhang, Y. Brain MRI analysis for Mental deterioration diagnosis using an ensemble system of deep convolutional neural networks. Brain Inform. 2018, 5, 2. [Google Scholar] [CrossRef] [Green Version]
- Esmaeilzadeh, S.; Belivanis, D.I.; Pohl, K.M.; Adeli, E. End-to-End Mental Deterioration Diagnosis and Biomarker Identification. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2018; pp. 337–345. [Google Scholar]
- Janghel, R.R.; Rathore, Y.K. Deep Convolution Neural Network Based System for Early Diagnosis of Alzheimer’s Disease. IRBM 2021, 42, 258–267. [Google Scholar] [CrossRef]
- Basaia, S.; Agosta, F.; Wagner, L.; Canu, E.; Magnani, G.; Santangelo, R.; Filippi, M.; The Alzheimer’s Disease Neuroimaging Initiative. Automated classification of Mental deterioration and mild cognitive impairment using a single MRI and deep neural networks. NeuroImage Clin. 2019, 21, 10–26. [Google Scholar] [CrossRef]
- Talo, M.; Yildirim, O.; Baloglu, U.B.; Aydin, G.; Acharya, U.R. Convolutional neural networks for multi-class brain disease detection using MRI images. Comput. Med. Imaging Graph. 2019, 78, 101673. [Google Scholar] [CrossRef]
- Spasov, S.; Passamonti, L.; Duggento, A.; Lio, P.; Toschi, N.; The Alzheimer’s Disease Neuroimaging Initiative. A parameter-efficient deep learning approach to predict conversion from mild cognitive impairment to Alzheimer’s disease. NeuroImage 2019, 189, 276–287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gunawardena, K.A.N.N.P.; Rajapakse, R.N.; Kodikara, N.D. Applying convolutional neural networks for pre-detection of Mental deterioration from structural MRI data. In Proceedings of the 2017 24th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Auckland, New Zealand, 21–23 November 2017; pp. 1–7. [Google Scholar]
- Yoo, Y.; Tang, L.Y.; Brosch, T.; Li, D.K.; Kolind, S.; Vavasour, I.; Rauscher, A.; MacKay, A.L.; Traboulsee, A.; Tam, R.C. Deep learning of joint myelin and T1w MRI features in normal-appearing brain tissue to distinguish between multiple sclerosis patients and healthy controls. NeuroImage Clin. 2018, 17, 169–178. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Elazab, A.; Yang, P.; Wang, T.; Zhou, F.; Hu, H.; Xiao, X.; Lei, B. Deep learning framework for Mental deterioration diagnosis via 3D-CNN and FSBi-LSTM. IEEE Access 2019, 7, 63605–63618. [Google Scholar] [CrossRef]
- Wang, S.H.; Phillips, P.; Sui, Y.; Liu, B.; Yang, M.; Cheng, H. Classification of Mental deterioration based on eight-layer convolutional neural network with leaky rectified linear unit and max pooling. J. Med. Syst. 2018, 42, 85. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.; Popuri, K.; Ding, G.W.; Balachandar, R.; Beg, M.F. Multiscale deep neural network based analysis of FDG-PET images for the early diagnosis of Alzheimer’s disease. Med. Image Anal. 2018, 46, 26–34. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Zhang, Y.; Hou, X.X.; Chen, H.; Wang, S.H. Seven-layer deep neural network based on sparse autoencoder for voxelwise detection of cerebral microbleed. Multimed. Tools Appl. 2018, 77, 10521–10538. [Google Scholar] [CrossRef]
- Karim, R.; Shahrior, A.; Rahman, M.M. Machine learning-based tri-stage classification of Alzheimer’s progressive neurodegenerative disease using PCA and mRMR administered textural, orientational, and spatial features. Int. J. Imaging Syst. Technol. 2021, 4, 2060–2074. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, J.; Lian, C.; Shen, D. Weakly supervised deep learning for brain disease prognosis using MRI and incomplete clinical scores. IEEE Trans. Cybern. 2019, 50, 3381–3392. [Google Scholar] [CrossRef] [Green Version]
- Long, X.; Chen, L.; Jiang, C.; Zhang, L. Prediction and classification of Alzheimer disease based on quantification of MRI deformation. PLoS ONE 2017, 12, e0173372. [Google Scholar] [CrossRef] [Green Version]
- Duraisamy, B.; Shanmugam, J.V.; Annamalai, J. Alzheimer disease detection from structural MR images using FCM based weighted probabilistic neural network. Brain Imaging Behav. 2019, 13, 87–110. [Google Scholar] [CrossRef]
- Wu, C.; Guo, S.; Hong, Y.; Xiao, B.; Wu, Y.; Zhang, Q.; The Alzheimer’s Disease Neuroimaging Initiative. Discrimination and conversion prediction of mild cognitive impairment using convolutional neural networks. Quant. Imaging Med. Surg. 2018, 8, 992. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Dong, Z.; Phillips, P.; Wang, S.; Ji, G.; Yang, J.; Yuan, T.-F. Detection of subjects and brain regions related to Mental deterioration using 3D MRI scans based on eigenbrain and machine learning. Front. Comput. Neurosci. 2015, 9, 66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, W.; Tong, T.; Gao, Q.; Guo, D.; Du, X.; Yang, Y. Convolutional neural networks-based MRI image analysis for the Mental deterioration prediction from mild cognitive impairment. Front. Neurosci. 2018, 12, 12–30. [Google Scholar] [CrossRef] [PubMed]
- Goceri, E. Diagnosis of Mental deterioration with Sobolev gradient-based optimization and 3D convolutional neural network. Int. J. Numer. Methods Biomed. Eng. 2019, 35, 32–50. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Sampath, R.; Mohamed Shakeel, P. Analysis of regional atrophy and prolong adaptive exclusive atlas to detect the alzheimers neuro disorder using medical images. Multimed. Tools Appl. 2020, 79, 10249–10265. [Google Scholar] [CrossRef]
- Oh, K.; Chung, Y.C.; Kim, K.W.; Kim, W.S.; Oh, I.S. Classification and visualization of Mental deterioration using volumetric convolutional neural network and transfer learning. Sci. Rep. 2019, 9, 5663. [Google Scholar] [CrossRef] [Green Version]
- Altaf, T.; Anwar, S.M.; Gul, N.; Majeed, M.N.; Majid, M. Multi-class Mental deterioration classification using image and clinical features. Biomed. Signal Process. Control 2018, 43, 64–74. [Google Scholar] [CrossRef]
- Shi, B.; Chen, Y.; Zhang, P.; Smith, C.D.; Liu, J. Nonlinear feature transformation and deep fusion for Mental deterioration staging analysis. Pattern Recognit. 2017, 63, 487–498. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Li, F.; Yan, H.; Wang, K.; Ma, Y.; Shen, L.; Xu, M.; Mental deterioration Neuroimaging Initiative. A multi-model deep convolutional neural network for automatic hippocampus segmentation and classification in Alzheimer’s disease. NeuroImage 2020, 208, 116459. [Google Scholar] [CrossRef]
- Qiu, S.; Joshi, P.S.; Miller, M.I.; Xue, C.; Zhou, X.; Karjadi, C.; Chang, G.H.; Joshi, A.S.; Dwyer, B.; Zhu, S.; et al. Development and validation of an interpretable deep learning framework for Mental deterioration classification. Brain 2020, 143, 1920–1933. [Google Scholar] [CrossRef]
- Talo, M.; Baloglu, U.B.; Yıldırım, Ö.; Acharya, U.R. Application of deep transfer learning for automated brain abnormality classification using MR images. Cogn. Syst. Res. 2019, 54, 176–188. [Google Scholar] [CrossRef]
- Jain, R.; Jain, N.; Aggarwal, A.; Hemanth, D.J. Convolutional neural network based Mental deterioration classification from magnetic resonance brain images. Cogn. Syst. Res. 2019, 57, 147–159. [Google Scholar] [CrossRef]
- Helaly, H.A.; Badawy, M.; Haikal, A.Y. Deep learning approach for early detection of Alzheimer’s disease. Cogn. Comput. 2022, 14, 1711–1727. [Google Scholar] [CrossRef] [PubMed]
- Tanveer, M.; Rashid, A.H.; Ganaie, M.A.; Reza, M.; Razzak, I.; Hua, K.-L. Classification of Alzheimer’s disease using ensemble of deep neural networks trained through transfer learning. IEEE J. Biomed. Health Inform. 2021, 26, 1453–1463. [Google Scholar] [CrossRef] [PubMed]
- Lei, B.; Liang, E.; Yang, M.; Yang, P.; Zhou, F.; Tan, E.-L.; Lei, Y.; Liu, C.-M.; Wang, T.; Xiao, X.; et al. Predicting clinical scores for Alzheimer’s disease based on joint and deep learning. Expert Syst. Appl. 2022, 187, 115966. [Google Scholar] [CrossRef]
- Chen, Y.; Xia, Y. Iterative sparse and deep learning for accurate diagnosis of Alzheimer’s disease. Pattern Recognit. 2021, 116, 107944. [Google Scholar] [CrossRef]
- Bron, E.E.; Klein, S.; Papma, J.M.; Jiskoot, L.C.; Venkatraghavan, V.; Linders, J.; Aalten, P.; De Deyn, P.P.; Biessels, G.J.; Claassen, J.A.H.R.; et al. Cross-cohort generalizability of deep and conventional machine learning for MRI-based diagnosis and prediction of Alzheimer’s disease. NeuroImage Clin. 2021, 31, 102–124. [Google Scholar] [CrossRef] [PubMed]
- AbdulAzeem, Y.; Bahgat, W.M.; Badawy, M. A CNN based framework for classification of Alzheimer’s disease. Neural Comput. Appl. 2021, 33, 10415–10428. [Google Scholar] [CrossRef]
- Liu, S.; Masurkar, A.V.; Rusinek, H.; Chen, J.; Zhang, B.; Zhu, W.; Fernandez-Granda, C.; Razavin, N. Generalizable deep learning model for early Alzheimer’s disease detection from structural MRIs. Sci. Rep. 2022, 12, 17106. [Google Scholar] [CrossRef]
- Abuhmed, T.; El-Sappagh, S.; Alonso, J.M. Robust hybrid deep learning models for Alzheimer’s progression detection. Knowl.-Based Syst. 2021, 213, 106–128. [Google Scholar] [CrossRef]
- Hazarika, R.A.; Abraham, A.; Kandar, D.; Maji, A.K. An Improved LeNet-Deep Neural Network Model for Alzheimer’s Disease Classification Using Brain Magnetic Resonance Images. IEEE Access 2021, 9, 161194–161207. [Google Scholar] [CrossRef]
- Nawaz, H.; Maqsood, M.; Afzal, S.; Aadil, F.; Mehmood, I.; Rho, S. A deep feature-based real-time system for Alzheimer disease stage detection. Multimed. Tools Appl. 2021, 80, 35789–35807. [Google Scholar] [CrossRef]
- Herzog, N.J.; Magoulas, G.D. Brain asymmetry detection and machine learning classification for diagnosis of early dementia. Sensors 2021, 21, 778. [Google Scholar] [CrossRef]
- An, N.; Ding, H.; Yang, J.; Au, R.; Ang, T.F. Deep ensemble learning for Mental deterioration classification. J. Biomed. Inform. 2020, 105, 103–117. [Google Scholar] [CrossRef] [Green Version]
- Arafa, D.A.; Moustafa, H.E.D.; Ali-Eldin, A.M.; Ali, H.A. Early detection of Mental deterioration based on the state-of-the-art deep learning approach: A comprehensive survey. Multimed. Tools Appl. 2022, 81, 1–42. [Google Scholar] [CrossRef]
- Trockman, A.; Kolter, J.Z. Patches are all you need? arXiv 2022, arXiv:2201.09792. [Google Scholar]
- Lebedev, A.V.; Westman, E.; Van Westen, G.J.P.; Kramberger, M.G.; Lundervold, A.; Aarsland, D.; Soininen, H.; Kłoszewska, I.; Mecocci, P.; Tsolaki, M.; et al. Random Forest ensembles for detection and prediction of Alzheimer’s disease with a good between-cohort robustness. NeuroImage Clin. 2014, 6, 115–125. [Google Scholar] [CrossRef] [Green Version]
- Alzheimer’s Disease Dataset. Available online: https://www.kaggle.com/datasets/tourist55/alzheimers-dataset-4-class-of-images (accessed on 1 January 2022).
- Baghdadi, N.A.; Malki, A.; Balaha, H.M.; Badawy, M.; Elhosseini, M. A3C-TL-GTO: Alzheimer Automatic Accurate Classification Using Transfer Learning and Artificial Gorilla Troops Optimizer. Sensors 2022, 22, 4250. [Google Scholar] [CrossRef]
- LONI Alzheimer’s Disease Neuroimaging Initiative. 2021. Available online: https://ida.loni.usc.edu (accessed on 10 December 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | * Dataset | Methodology | Results | Drawbacks |
|---|---|---|---|---|
| Liu et al. [30] | ADNI | Weakly supervised densely connected neural network (wiseDNN) | ACC: 93% | Evaluated on single dataset and classify two-classes |
| Long et al. [31] | ADNI | Deformation-based technique | ACC: 89.5% | Evaluated on single dataset and classify two-classes |
| Duraisamy et al. [32] | ADNI | FCM-based weighted probabilistic neural network (FWPNN) | ACC: 98.63% | Too much image processing, three classes and evaluate on signal dataset |
| Wu et al. [33] | ADNI | GoogleNet and CaffeNet | ACC: 95.42% to 97.01% | TL with limited dataset on two classes, detection accuracy is limited; computationally expensive |
| Zhang et al. [34] | ADNI | Image Processing and Machine learning | ACC: 92% | Image processing, handcrafted-based feature extraction approach, which limits the detection accuracy |
| Lin et al. [35] | ADNI | CNN | ACC: 91% | Two classes, CNN, used one dataset, and limited applicability |
| Goceri et al. [36] | ADNI | Sobolev-gradient-based optimization | ACC: 98% | Two classes, complicated approach compared to prior techniques |
| Kumar et al. [37] | ADNI | CNN and SVM | ACC: 95% | Two classes, computationally expensive and limited applicability |
| Oh et al. [38] | ADNI | Image features and CNN | ACC: 86.60% | Two classes, complex image processing |
| Altaf et al. [39] | ADNI | Gray level co-occurrence matrix (GLCM), scale-invariant feature transform, local binary pattern, and gradient histogram | ACC: 90% | Two classes, hand-crafted features limit the detection accuracy, and single dataset |
| Shi et al. [40] | ADNI | Stacked denoising sparse auto-encoder (DSAE) with feature fusion | -- | Two classes, feature fusion approach to make complexity expensive, and limited applicability |
| Liu et al. [41] | ADNI | multi-task CNN and DenseNet models | ACC: 89% | Three classes only and used only one dataset |
| Tanveer et al. [46] | ADNI | TL: VGG-16 | ACC: 95.73% | Three classes only and used only one limited dataset, classifier is not generalized |
| Chen et al. [48] | ADNI | Iterative sparse and deep learning (ISDL) | ACC: 94% | Two classes only and used only one limited dataset, classifier is not generalized |
| Bron et al. [49] | ADNI | SVM and CNN method | ACC: 92% | Two classes only and used only one limited dataset, classifier is not generalized |
| Abuhmed et al. [52] | ADNI | BiLSTM model | -- | Three classes only and used only one limited dataset, classifier is not generalized |
| Hazarika et al. [53] | ADNI | DNN with LeNet to replace max pooling layers | ACC: 93.5% | Two classes only and used only one limited dataset, classifier is not generalized |
| Herzoz et al. [55] | ADNI | CNN and SVM | ACC: 93.0% | Two classes only and used only one limited dataset, classifier is not generalized |
| An et al. [56] | ADNI | DBN+ NN | -- | Three classes only and used only one limited dataset, classifier is not generalized |
| Lebedev et al. [59] | ADNI | |||
| Baghdadi et al. [61] | ADNI | multi-task CNN and DenseNet models | ACC: 89% | Three classes only and used only one dataset. |
| Methods | Values Assigned |
|---|---|
| Affine transform | True |
| Pan | True |
| Spin-range | 0.12 |
| Crop | True |
| Horizontal-flip | True |
| Vertical-flip | False |
| Affine transform | True |
| Convolutional Layers | Parameters |
|---|---|
| Convolution-32 | (3 × 3 × 3 + 1) × 32 |
| Convolution-32 | (3 × 3 × 32 + 1) × 64 |
| Convolution-64 | (3 × 3 × 64) + (1 × 1 × 64 + 1) × 128 |
| Convolution-64 | (3 × 3 × 128) + (1 × 1 × 128 + 1) × 128 |
| Convolution-128 | (3 × 3 × 128) + (1 × 1 × 128 + 1) × 256 |
| Convolution-128 | (3 × 3 × 256) + (1 × 1 × 256 + 1) × 256 |
| Convolution-256 | (3 × 3 × 256) + (1 × 1 × 256 + 1) × 728 |
| Convolution-256 | (3 × 3 × 728) + (1 × 1 × 728 + 1) × 728 |
| Total | 87,488 |
| AD Type | 1 SE | 2 SP | 3 ACC | 4 PR | Kappa | F1-Score |
|---|---|---|---|---|---|---|
| Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% |
| Average Result | 94% | 96% | 95% | 0.96 | 0.96 | 99.5% |
| Methods | 1 SE | 2 SP | 3 ACC | 4 PR | Kappa | F1-Score |
|---|---|---|---|---|---|---|
| Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% |
| Moderate Dementia | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Very Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% |
| Developed CAD-ALZ System | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Feature Set | Methods | 1 SE | 2 SP | 3 ACC | 4 PR | 4 Kappa | 4 F1-Score |
|---|---|---|---|---|---|---|---|
| Kaggle-ALZ (4000) | Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| Moderate Dementia | 93% | 96% | 94% | 0.95 | 0.98 | 99% | |
| Very Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| ADNI (18,000) | Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| Moderate Dementia | 93% | 96% | 94% | 0.95 | 0.98 | 99% | |
| Very Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| Combined datasets | Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| Moderate Dementia | 93% | 96% | 94% | 0.95 | 0.98 | 99% | |
| Very Mild Dementia | 95% | 96% | 95% | 0.96 | 0.97 | 100% | |
| Normal | 93% | 96% | 94% | 0.95 | 0.98 | 99% |
| Architectures | Complexity (FLOPs) | # Parameters (M) | Model Size (MB) | GPU Speed (MS) |
|---|---|---|---|---|
| ConvMixer-V8 | 67.3 M | 1.9 | 9.3 | 0.6 |
| ConvMixer | 98.9 M | 2.5 | 14.5 | 1.7 |
| SqueezeNet | 94.4 M | 2.4 | 12.3 | 1.2 |
| ResNet18 | 275.8 M | 2.7 | 15.2 | 2.6 |
| MobileNet | 285.8 M | 3.4 | 16.3 | 2.7 |
| Inception V3 | 654.3 M | 3.9 | 17.5 | 2.9 |
| Xception | 66.9 M | 2.5 | 14.5 | 2.7 |
| AlexNet | 295.8 M | 2.5 | 12.3 | 3.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, Q.; Hussain, A.; Baig, A.R. CAD-ALZ: A Blockwise Fine-Tuning Strategy on Convolutional Model and Random Forest Classifier for Recognition of Multistage Alzheimer’s Disease. Diagnostics 2023, 13, 167. https://doi.org/10.3390/diagnostics13010167
Abbas Q, Hussain A, Baig AR. CAD-ALZ: A Blockwise Fine-Tuning Strategy on Convolutional Model and Random Forest Classifier for Recognition of Multistage Alzheimer’s Disease. Diagnostics. 2023; 13(1):167. https://doi.org/10.3390/diagnostics13010167
Chicago/Turabian StyleAbbas, Qaisar, Ayyaz Hussain, and Abdul Rauf Baig. 2023. "CAD-ALZ: A Blockwise Fine-Tuning Strategy on Convolutional Model and Random Forest Classifier for Recognition of Multistage Alzheimer’s Disease" Diagnostics 13, no. 1: 167. https://doi.org/10.3390/diagnostics13010167
APA StyleAbbas, Q., Hussain, A., & Baig, A. R. (2023). CAD-ALZ: A Blockwise Fine-Tuning Strategy on Convolutional Model and Random Forest Classifier for Recognition of Multistage Alzheimer’s Disease. Diagnostics, 13(1), 167. https://doi.org/10.3390/diagnostics13010167