1. Introduction
The human body is made up of approximately 30 trillion cells. Cancer originates from abnormal cell growth, resulting in the formation of a primary tumor [
1]. Breast cancer predominantly affects women due to the excessive growth of breast cells. It is a highly invasive tumor and a leading cause of female fatalities [
2]. In Pakistan, breast cancer is prevalent, with one out of every nine women at risk of the disease, and it has the highest cancer-related mortality rate [
3]. According to the World Health Organization’s 2020 report, breast cancer is a significant cause of accidental death in women, with 8.2% of the Pakistani population dying from cancer.
Figure 1 shows that breast cancer is the most commonly diagnosed cancer type, with a 28.7% diagnosis rate in 2020 [
4]. Breast cancer has two types, including malignant and benign. Benign (non-invasive) cancer is a type of cancer that does not affect other organs. On the other hand, malignant (invasive) cancer spreads to neighboring tissues, making invasive cancer prognosis challenging due to varying clinical outcomes [
5]. Thus, early and precise diagnosis and prognosis are crucial for timely decision making by physicians to improve patients’ survivability. Survivability can be categorized as short-term (<5 years) or long-term (>5 years). Prognostications aid physicians who work with short-term survivable patients with a multi-featured disease [
6].
During the past few decades, the rapid growth of machine learning and deep learning techniques with high throughput has provided deep insights into micro-arrays, gene expression, and clinical data. Machine learning aids in efficiently diagnosing and treating life-threatening diseases, whereas deep learning helps extract highly informative features for disease prediction and prognosis [
7]. There are many sources of informative data for breast cancer prognosis, such as genetic data (gene expression and copy number variations) and clinical data (age, pregnancy timing, lifestyle factors, early menstruation, late menopause, etc.). Ensemble learning integrates the prediction of multiple neural networks to reduce the variability in prediction and decrease generalization errors [
8]. Integrating the available multi-dimensional data can lead to an efficient breast cancer prognosis [
9]. In recent years, researchers have proposed multiple homogeneous prognosis methods based on neural network models using ensemble techniques.
This works relies on developing heterogeneous models based on a prognostic model with stacking. The primary concern is to ensure the heterogeneity of the models for multi-modal data concerning the nature of the data. Different from prior works, we aim to design an LSTM module for the feature extraction of gene expression data. The proposed framework operates through three stages, specifically feature extraction, stacking, and classification. The following are the novel contributions of the proposed framework:
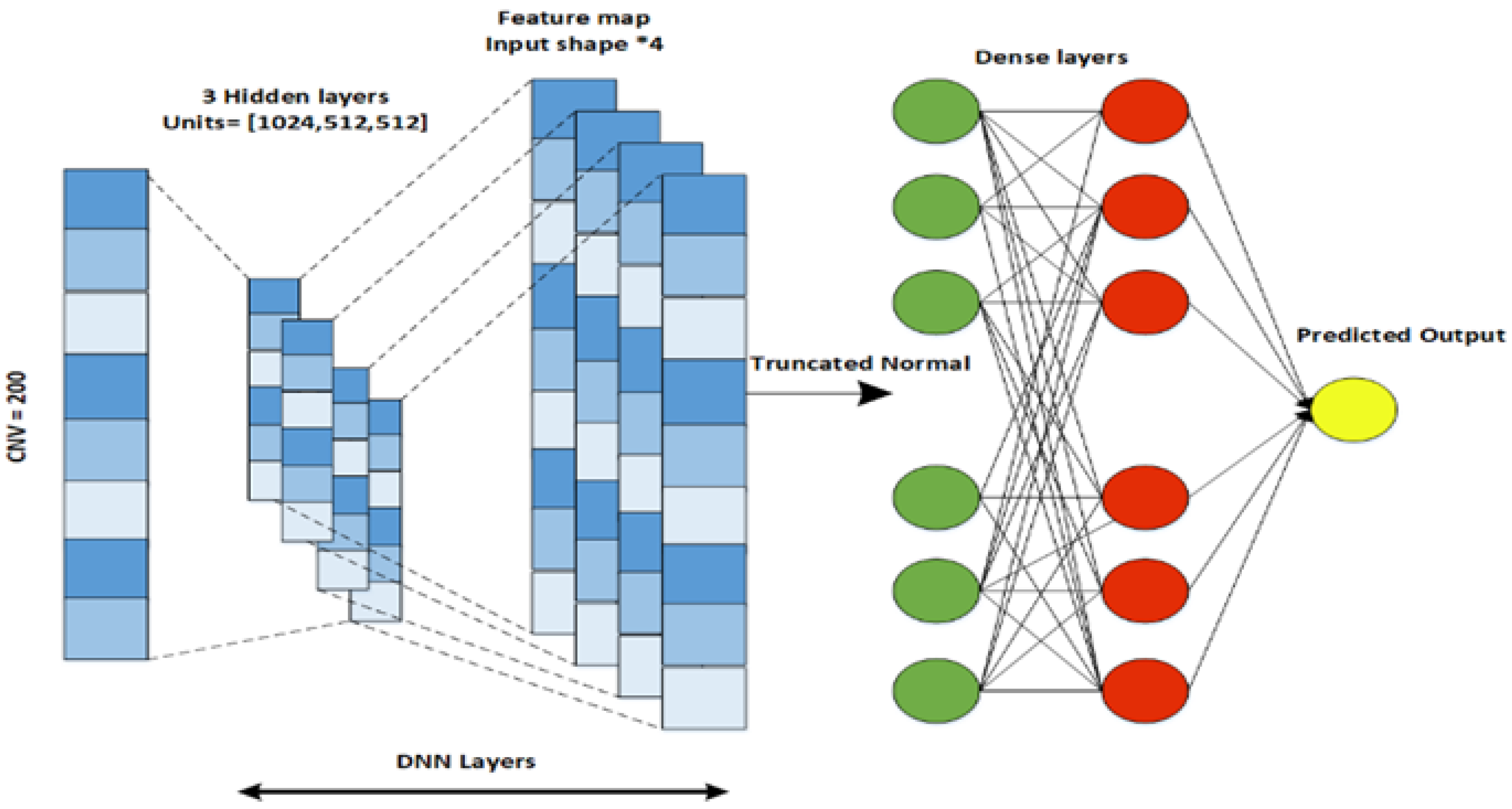
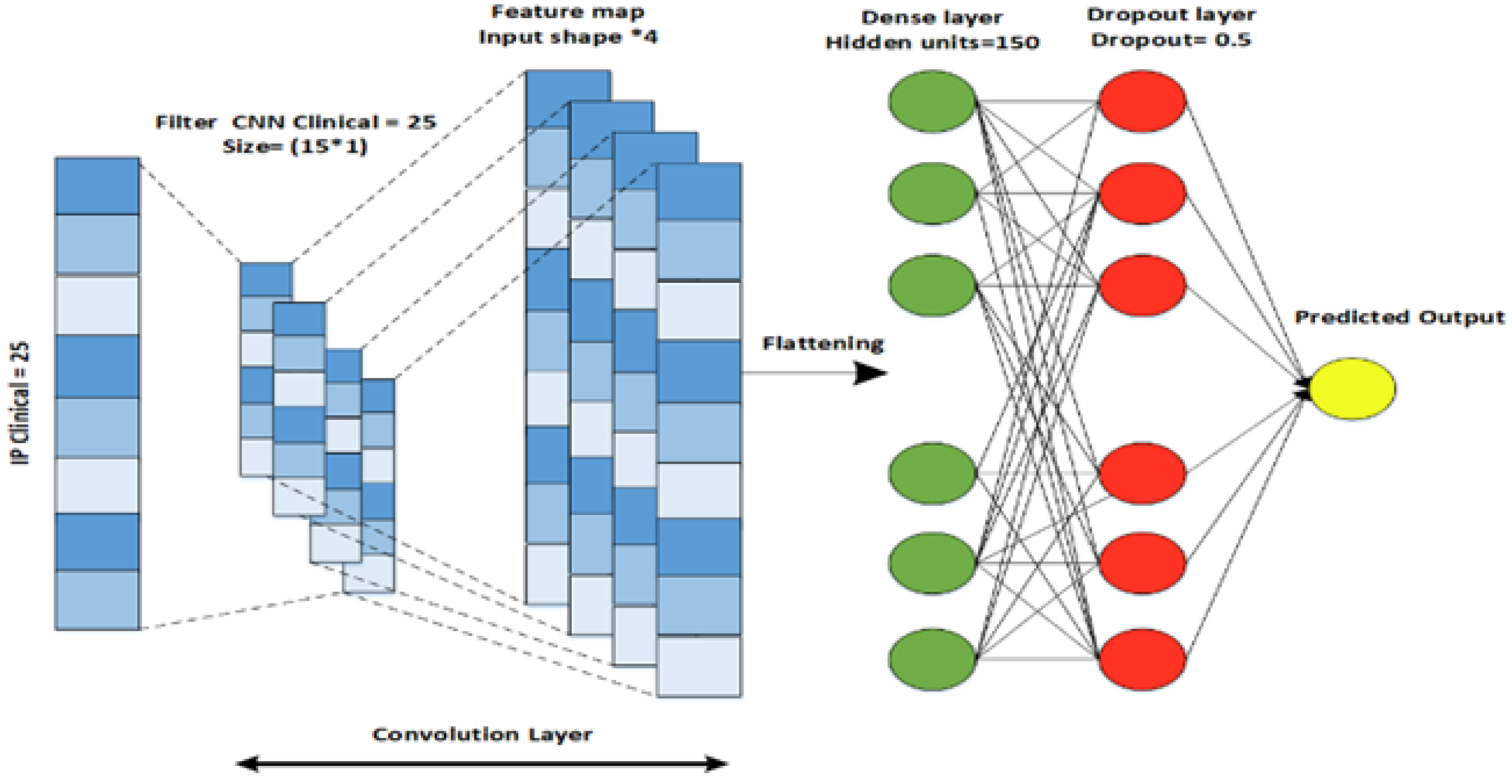
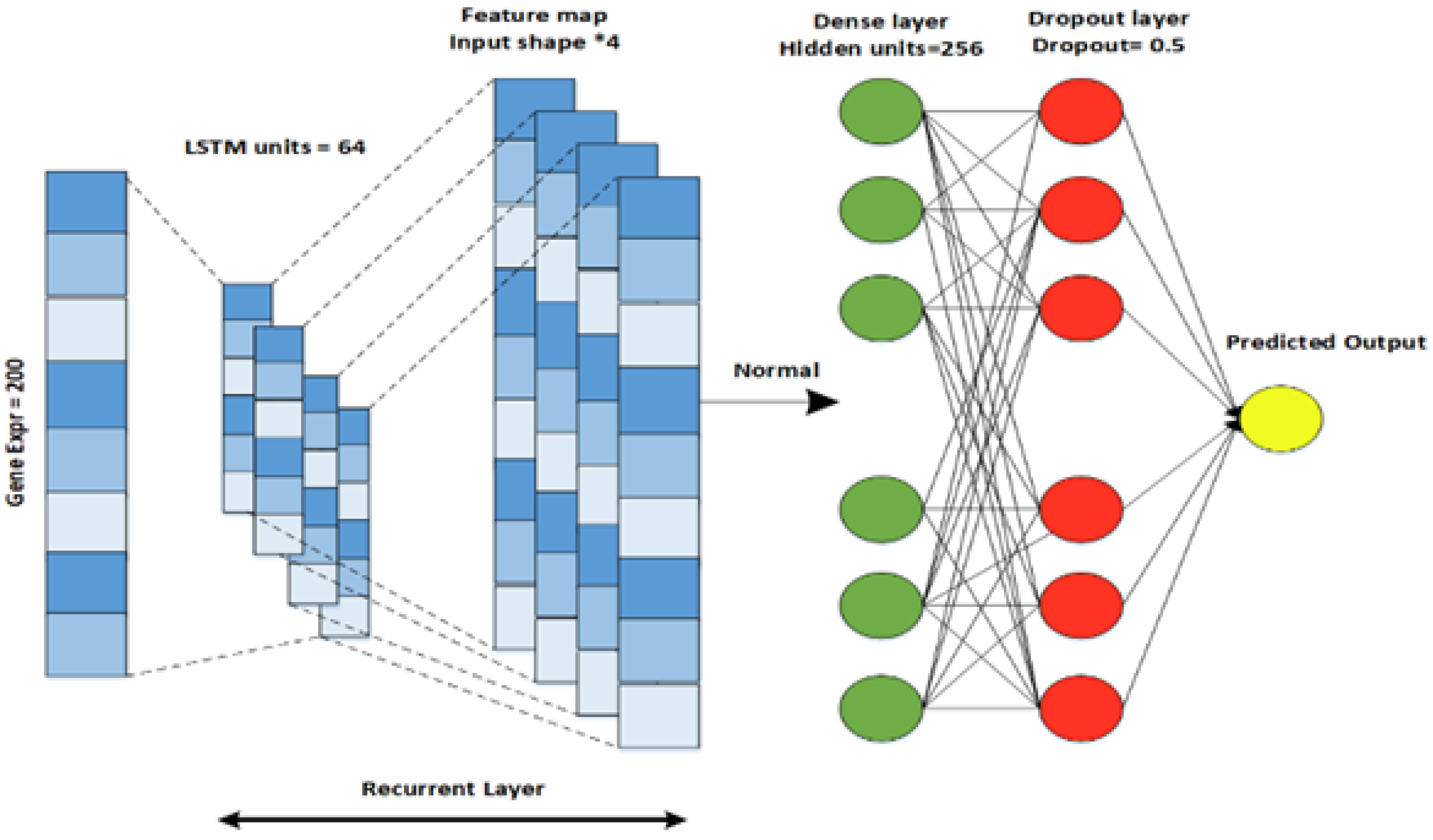
To obtain highly informative features, we implement an individual neural network for each data modality, including clinical data, gene expression data (Gene-Exp), and copy number variations (CNV).
Specifically, we design a CNN for clinical data, a DNN for CNV, and an LSTM architecture for the gene expression modality. The output features generated by the individual neural networks are stacked to validate the generalization of the result.
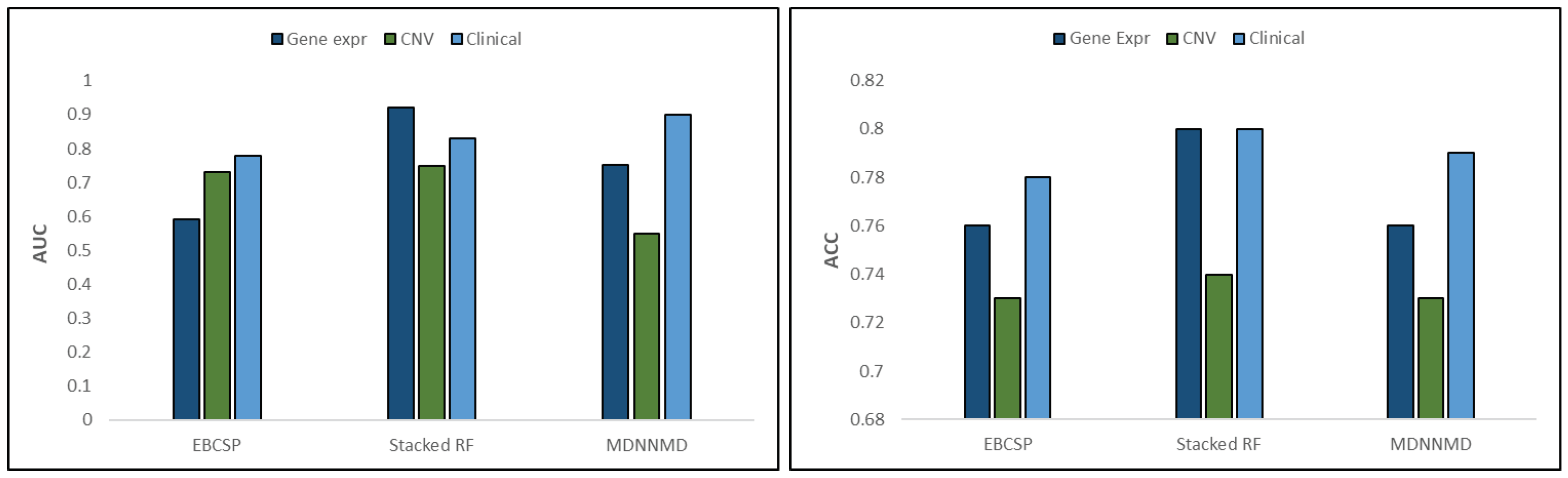
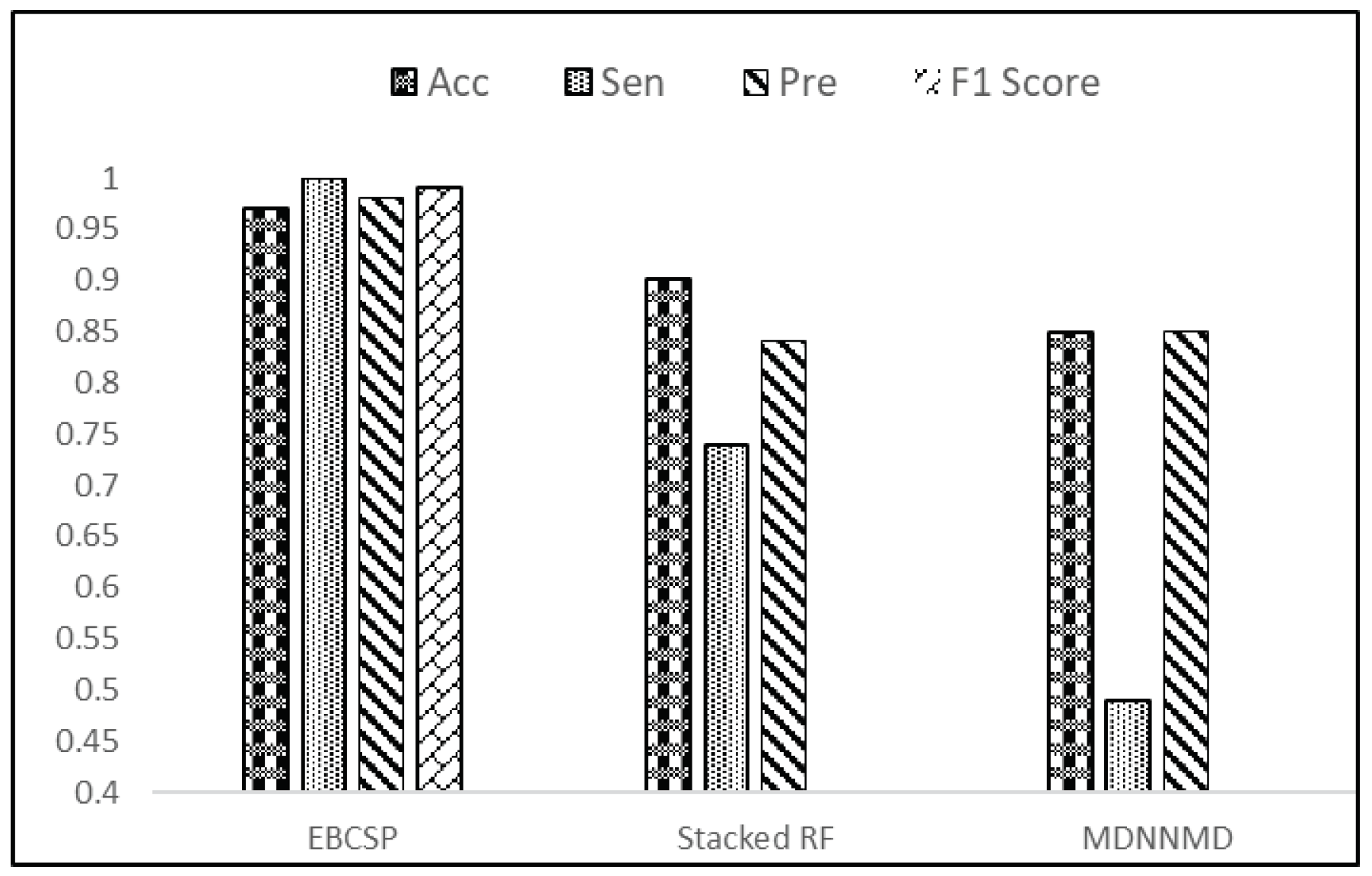
To confirm that integrating multi-modal data improves the prognostic power, we compare this technique with existing benchmarks. The results validate the effectiveness of the EBCSP in terms of accuracy.
2. Related Work
Machine learning has become a popular approach for predicting various diseases, including those affecting the lungs, breast, and oral cavities. In one study, the authors [
10] presented an overview of machine learning in primary lung cancer, highlighting both the strengths and weaknesses of these methods. Another study [
11] explored the performance of different machine learning models, such as logistic regression, random forest, K-nearest neighbors, and decision trees. The results showed that logistic regression outperformed the other models. In a separate study, Zhou et al. [
12] used the Bayesian approach to relate gene expression with class labels, utilizing the Markov chain Monte Carlo (MCMC) method to identify essential genes. The researchers implemented the Gibbs sampler and MCMC using the posterior distribution of the selected genes and validated their proposed method using large micro-array datasets.
In [
13], another overview was presented, which showcased recent advancements in radiomics utilizing deep learning. The authors investigated the effectiveness of deep learning in developing predictive and prognostic models. In [
14], the authors integrated a CNN and RNN to predict colorectal cancer using tumor tissue samples. The study aimed to directly use patient outcomes, eliminating the need for intermediate tissue classification. Furthermore, a comprehensive analysis of deep learning-based models, including Cox-net, Deep Surv, and Auto-Encoder with Cox regression networks (AECOX), was performed on the TCGA cancers dataset [
15]. The study’s findings emphasized the relationship between survival learnability on a pan-cancer level and patient characteristics.
Deep learning with ensemble models is gaining popularity for predicting various types of cancer. In [
16], the authors presented a pre-processing data approach that involved feature selection and aggregating random under-sampling. The results showed that an ensemble classifier with a BiLSTM or BiGRU model and a CNN model achieved the best classification performance, with accuracy and F1-score ranging between 91% and 96% for different types of heart disease. This proposed framework can potentially lead to highly accurate models suitable for real clinical data and diagnostic use.
In [
17], the authors proposed a novel methodology for classifying human cancer diseases based on gene expression profiles. The proposed system combined Information Gain and Standard Genetic Algorithm for feature selection and reduction, respectively, and Genetic Programming for cancer type classification. The methodology was evaluated on seven cancer datasets and compared with other machine learning approaches. Using a Genetic Algorithm improved the classification performance compared to other classifiers. In [
18], the researchers proposed a deep learning-based approach for detecting red lesions in fundus images, which is relevant for detecting early signs of diabetic retinopathy. The method combined deeply learned features with manually engineered features and used a random forest classifier to identify true lesion candidates. The proposed approach showed improved results and reported the highest performance on the DIARETDB1 and e-ophtha datasets.
Breast cancer prognosis is a critical need, alongside the prognosis of various other cancers. In pursuit of this objective, an ensemble approach that incorporates multiple machine learning models was investigated in [
19]. The authors considered five different classification models and applied gene expression analysis to these models to obtain informative gene data. The proposed model was validated in lung cancer, stomach adenocarcinoma, and invasive carcinoma samples. The results confirmed the effectiveness of the proposed ensemble model. Another ensemble model was proposed in [
20]. Here, the authors considered three classifiers, including support vector machines, logistics regression, and stochastic gradient descent optimization, for breast tumor classification. The proposed complex voting mechanism provided better results in comparison to existing benchmarks.
In [
21], a multi-modal ensemble classification approach was investigated for human breast cancer prognosis. The authors proposed a deep learning-based stacked ensemble model using three datasets: CNV, clinical, and gene expression. They proposed a novel two-phase framework where features were extracted using a convolutional neural network in the first phase and RF was implemented in the second phase for output prediction. The results validated the effectiveness of the proposed multi-modal classification. However, there is still a need for a model that can effectively predict breast cancer patient prognosis and survivability. Existing benchmark models only work for a limited number of gene signatures or use similar neural networks for multi-modal data. Therefore, this work aims to design a heterogeneous model for multi-modal data to test the effectiveness of the proposed model in terms of accuracy.
6. Conclusions
Breast cancer is a severe illness that often results in poor outcomes and is a leading cause of mortality. Physicians can make informed decisions about patient care by assessing patients’ survival rates. Therefore, there is a pressing need for a rapid and effective computational model to predict human breast cancer prognosis. This study aims to develop a prognostic model for human breast cancer by using independent neural networks for each relevant data modality. The EBCSP model, which stacks multi-dimensional data, is presented in this study for predicting the survival rate (long-term or short-term) of patients with human breast cancer. Clinical, gene expression, and copy number variation data are all informative sources for breast cancer prognosis. Individual neural network models were designed for each data modality, and the outputs were combined using RF for final classification. The predicted output can be validated or integrated with other sources of information before being used for clinical decision making. The EBCSP model outperforms existing benchmarks, including MDNNMD and stacked RF, and can be extended to similar critical diseases. However, it is important to note that the proposed work is limited to additional data modalities such as miRNA and gene methylation data, and future studies will explore these modalities using innovative methodologies.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}