




Histopathological Gastric Cancer Detection on GasHisSDB Dataset Using Deep Ensemble Learning
 , , and
, , and
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
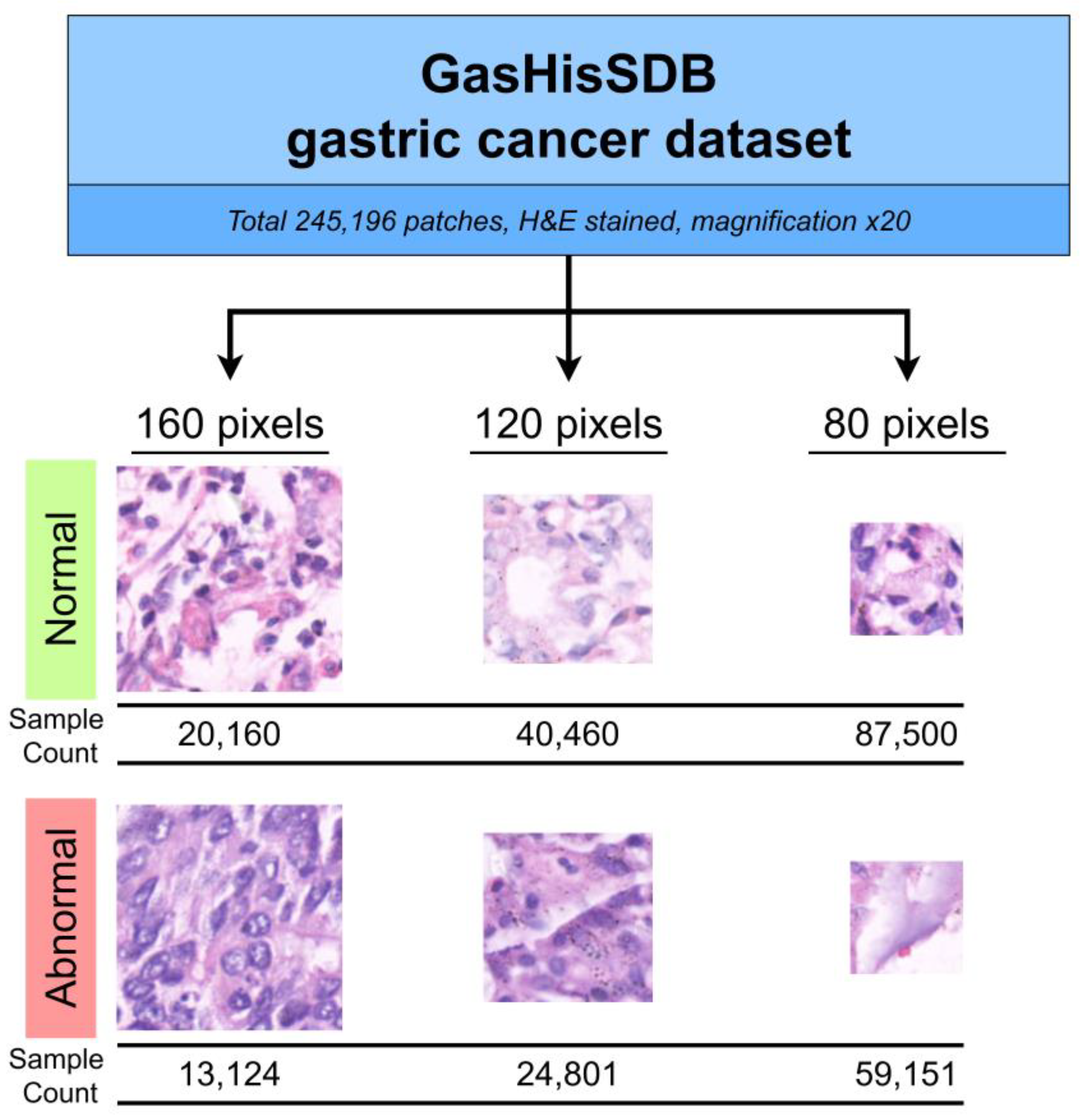
3.1. Dataset
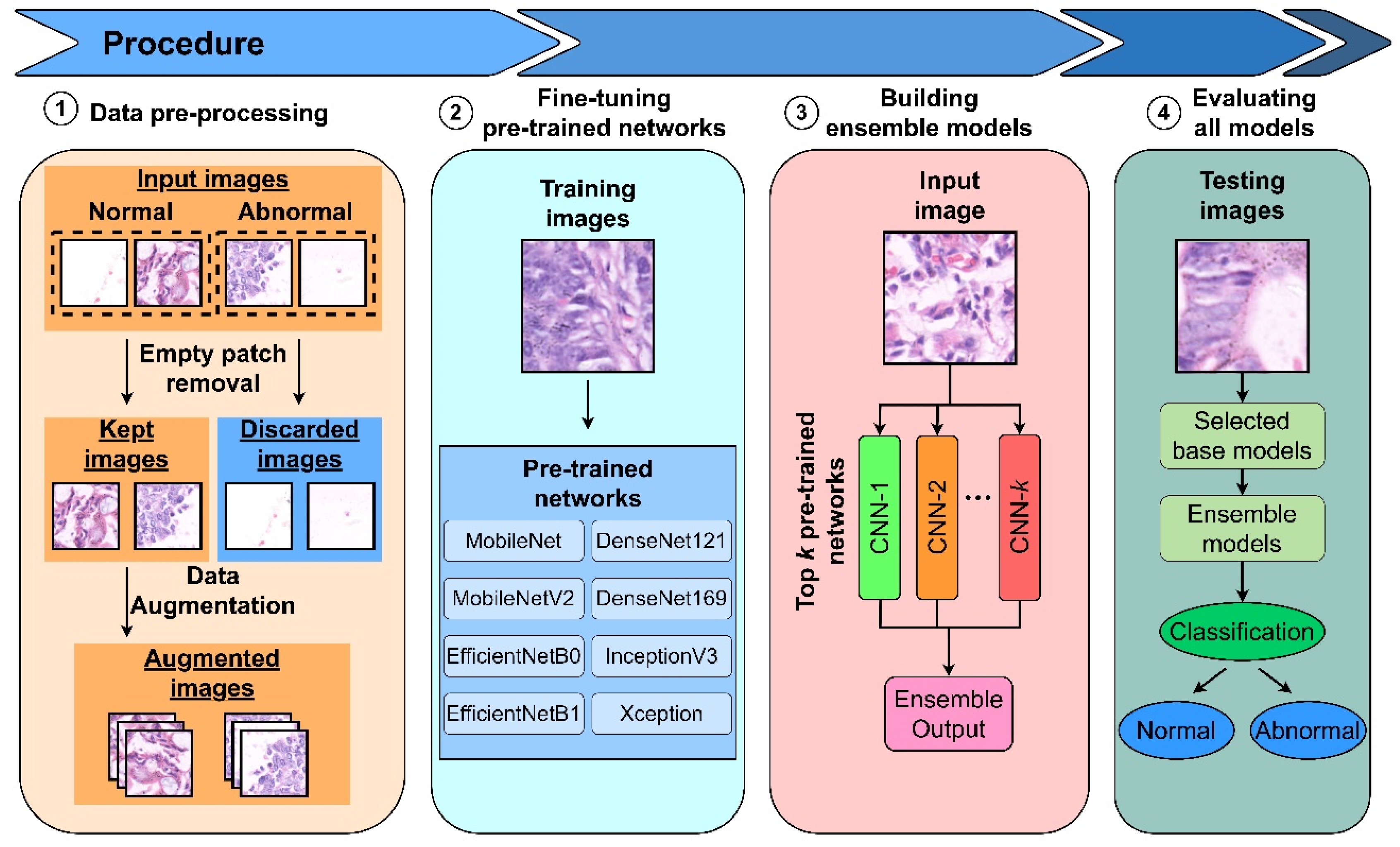
3.2. Methodology Overview
3.3. Dataset Pre-Processing
3.3.1. Empty Patch Removal Process
3.3.2. Data Augmentation
3.4. Pre-Trained Networks as the Base Models
3.4.1. InceptionV3
3.4.2. Xception
3.4.3. DenseNet Family
3.4.4. EfficientNet Family
3.4.5. MobileNet Family
3.5. Transfer Learning
3.6. Ensemble Models Architecture
3.7. Experiment Setting
3.8. Model Evaluation and Visualization
3.8.1. Evaluation Metrics
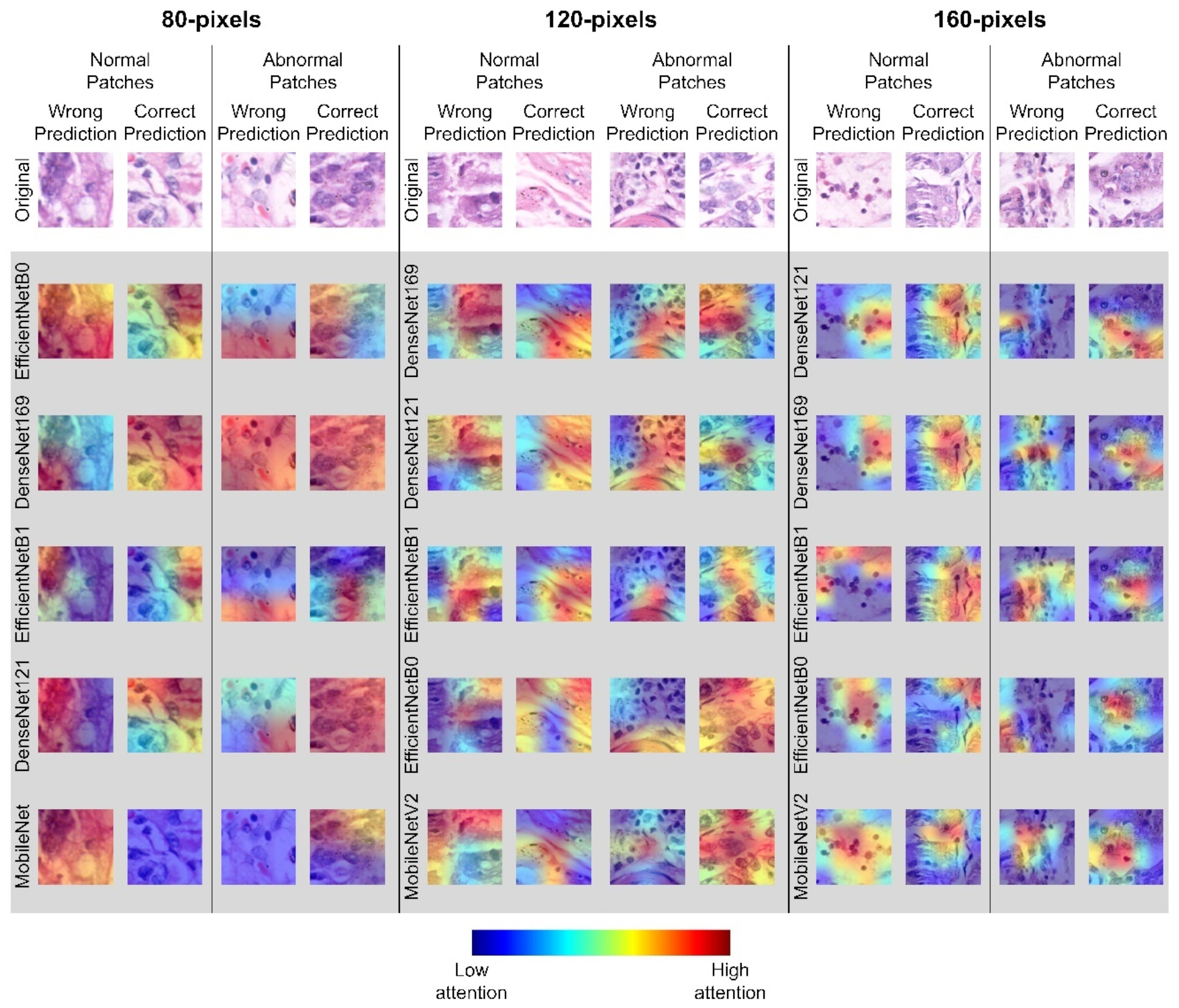
3.8.2. Prediction Visualization
4. Results
5. Discussion
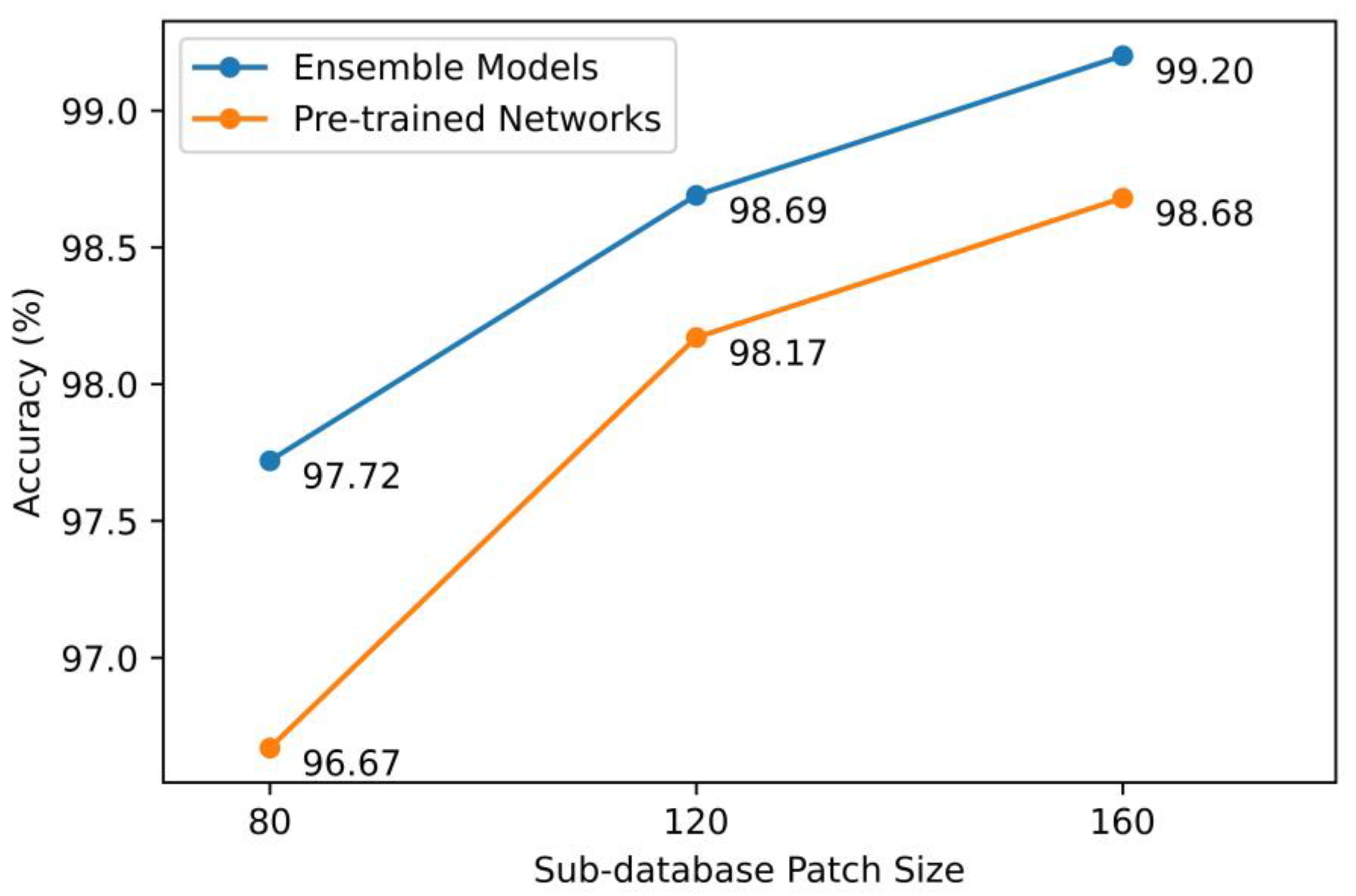
5.1. Performance Analysis of the Base and Ensemble Models
5.2. Performance Analysis of the Proposed Models and the State-of-the-Art Studies on the GasHisSDB Dataset
5.3. Extended Experiments
5.4. Limitations of Our Proposed Study
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Shah, M.A.; Khanin, R.; Tang, L.; Janjigian, Y.Y.; Klimstra, D.S.; Gerdes, H.; Kelsen, D.P. Molecular Classification of Gastric Cancer: A New Paradigm. Clin. Cancer Res. 2011, 17, 2693–2701. [Google Scholar] [CrossRef] [PubMed]
- Yasui, W.; Oue, N.; Kuniyasu, H.; Ito, R.; Tahara, E.; Yokozaki, H. Molecular Diagnosis of Gastric Cancer: Present and Future. Gastric Cancer 2001, 4, 113–121. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Liu, S.; Li, C.; Sun, J. MCLNet: An Multidimensional Convolutional Lightweight Network for Gastric Histopathology Image Classification. Biomed. Signal Process. Control 2023, 80, 104319. [Google Scholar] [CrossRef]
- Song, Z.; Zou, S.; Zhou, W.; Huang, Y.; Shao, L.; Yuan, J.; Gou, X.; Jin, W.; Wang, Z.; Chen, X.; et al. Clinically Applicable Histopathological Diagnosis System for Gastric Cancer Detection Using Deep Learning. Nat. Commun. 2020, 11, 4294. [Google Scholar] [CrossRef]
- Kato, M.; Nishida, T.; Yamamoto, K.; Hayashi, S.; Kitamura, S.; Yabuta, T.; Yoshio, T.; Nakamura, T.; Komori, M.; Kawai, N.; et al. Scheduled Endoscopic Surveillance Controls Secondary Cancer after Curative Endoscopic Resection for Early Gastric Cancer: A Multicentre Retrospective Cohort Study by Osaka University ESD Study Group. Gut 2013, 62, 1425–1432. [Google Scholar] [CrossRef]
- Satolli, M.A. Gastric Cancer: The Times They Are a-Changin’. World J. Gastrointest. Oncol. 2015, 7, 303. [Google Scholar] [CrossRef]
- Bria, E.; De Manzoni, G.; Beghelli, S.; Tomezzoli, A.; Barbi, S.; Di Gregorio, C.; Scardoni, M.; Amato, E.; Frizziero, M.; Sperduti, I.; et al. A Clinical–Biological Risk Stratification Model for Resected Gastric Cancer: Prognostic Impact of Her2, Fhit, and APC Expression Status. Ann. Oncol. 2013, 24, 693–701. [Google Scholar] [CrossRef]
- Ehteshami Bejnordi, B.; Veta, M.; Johannes van Diest, P.; van Ginneken, B.; Karssemeijer, N.; Litjens, G.; van der Laak, J.A.W.M.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women with Breast Cancer. JAMA 2017, 318, 2199. [Google Scholar] [CrossRef]
- Hameed, Z.; Zahia, S.; Garcia-Zapirain, B.; Javier Aguirre, J.; María Vanegas, A. Breast Cancer Histopathology Image Classification Using an Ensemble of Deep Learning Models. Sensors 2020, 20, 4373. [Google Scholar] [CrossRef]
- Sharma, H.; Zerbe, N.; Klempert, I.; Hellwich, O.; Hufnagl, P. Deep Convolutional Neural Networks for Automatic Classification of Gastric Carcinoma Using Whole Slide Images in Digital Histopathology. Comput. Med. Imaging Graph. 2017, 61, 2–13. [Google Scholar] [CrossRef]
- Korkmaz, S.A.; Akcicek, A.; Binol, H.; Korkmaz, M.F. Recognition of the Stomach Cancer Images with Probabilistic HOG Feature Vector Histograms by Using HOG Features. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; IEEE: Piscataway, NJ, USA; pp. 000339–000342. [Google Scholar]
- Korkmaz, S.A.; Binol, H.; Akcicek, A.; Korkmaz, M.F. A Expert System for Stomach Cancer Images with Artificial Neural Network by Using HOG Features and Linear Discriminant Analysis: HOG_LDA_ANN. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; IEEE: Piscataway, NJ, USA; pp. 000327–000332. [Google Scholar]
- Sharma, H.; Zerbe, N.; Heim, D.; Wienert, S.; Behrens, H.-M.; Hellwich, O.; Hufnagl, P. A Multi-Resolution Approach for Combining Visual Information Using Nuclei Segmentation and Classification in Histopathological Images. In Proceedings of the 10th International Conference on Computer Vision Theory and Applications, Berlin, Germany, 11–14 March 2015; SCITEPRESS—Science and Technology Publications: Setúbal, Portugal, 2015; pp. 37–46. [Google Scholar]
- Sharma, H.; Zerbe, N.; Boger, C.; Wienert, S.; Hellwich, O.; Hufnagl, P. A Comparative Study of Cell Nuclei Attributed Relational Graphs for Knowledge Description and Categorization in Histopathological Gastric Cancer Whole Slide Images. In Proceedings of the 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; IEEE: Piscataway, NJ, USA; pp. 61–66. [Google Scholar]
- Liu, B.; Zhang, M.; Guo, T.; Cheng, Y. Classification of Gastric Slices Based on Deep Learning and Sparse Representation. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; IEEE: Piscataway, NJ, USA; pp. 1825–1829. [Google Scholar]
- Litjens, G.; Sánchez, C.I.; Timofeeva, N.; Hermsen, M.; Nagtegaal, I.; Kovacs, I.; Hulsbergen-van de Kaa, C.; Bult, P.; van Ginneken, B.; van der Laak, J. Deep Learning as a Tool for Increased Accuracy and Efficiency of Histopathological Diagnosis. Sci. Rep. 2016, 6, 26286. [Google Scholar] [CrossRef]
- Bayramoglu, N.; Kannala, J.; Heikkila, J. Deep Learning for Magnification Independent Breast Cancer Histopathology Image Classification. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA; pp. 2440–2445. [Google Scholar]
- Koo, J.C.; Ke, Q.; Hum, Y.C.; Goh, C.H.; Lai, K.W.; Yap, W.-S.; Tee, Y.K. Non-Annotated Renal Histopathological Image Analysis with Deep Ensemble Learning. Quant. Imaging Med. Surg. 2023, in press.
- Kong, B.; Wang, X.; Li, Z.; Song, Q.; Zhang, S. Cancer Metastasis Detection via Spatially Structured Deep Network. In Proceedings of the Information Processing in Medical Imaging: 25th International Conference, IPMI 2017, Boone, NC, USA, 25–30 June 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 236–248. [Google Scholar]
- BenTaieb, A.; Hamarneh, G. Predicting Cancer with a Recurrent Visual Attention Model for Histopathology Images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 129–137. [Google Scholar]
- Chen, M.; Zhang, B.; Topatana, W.; Cao, J.; Zhu, H.; Juengpanich, S.; Mao, Q.; Yu, H.; Cai, X. Classification and Mutation Prediction Based on Histopathology H&E Images in Liver Cancer Using Deep Learning. NPJ Precis. Oncol. 2020, 4, 14. [Google Scholar] [CrossRef]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyö, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and Mutation Prediction from Non–Small Cell Lung Cancer Histopathology Images Using Deep Learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef]
- Nagpal, K.; Foote, D.; Liu, Y.; Chen, P.-H.C.; Wulczyn, E.; Tan, F.; Olson, N.; Smith, J.L.; Mohtashamian, A.; Wren, J.H.; et al. Development and Validation of a Deep Learning Algorithm for Improving Gleason Scoring of Prostate Cancer. NPJ Digit. Med. 2019, 2, 48. [Google Scholar] [CrossRef]
- Bychkov, D.; Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep Learning Based Tissue Analysis Predicts Outcome in Colorectal Cancer. Sci. Rep. 2018, 8, 3395. [Google Scholar] [CrossRef]
- Bulten, W.; Pinckaers, H.; van Boven, H.; Vink, R.; de Bel, T.; van Ginneken, B.; van der Laak, J.; Hulsbergen-van de Kaa, C.; Litjens, G. Automated Deep-Learning System for Gleason Grading of Prostate Cancer Using Biopsies: A Diagnostic Study. Lancet Oncol. 2020, 21, 233–241. [Google Scholar] [CrossRef]
- Koo, J.C.; Hum, Y.C.; Lai, K.W.; Yap, W.-S.; Manickam, S.; Tee, Y.K. Deep Machine Learning Histopathological Image Analysis for Renal Cancer Detection. In Proceedings of the 8th International Conference on Computing and Artificial Intelligence, Tianjin, China, 18–21 March 2022; ACM: New York, NY, USA, 2022; pp. 657–663. [Google Scholar]
- Voon, W.; Hum, Y.C.; Tee, Y.K.; Yap, W.-S.; Salim, M.I.M.; Tan, T.S.; Mokayed, H.; Lai, K.W. Performance Analysis of Seven Convolutional Neural Networks (CNNs) with Transfer Learning for Invasive Ductal Carcinoma (IDC) Grading in Breast Histopathological Images. Sci. Rep. 2022, 12, 19200. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Xie, X.; Shen, L. Deep Learning Based Gastric Cancer Identification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA; pp. 182–185. [Google Scholar]
- Iizuka, O.; Kanavati, F.; Kato, K.; Rambeau, M.; Arihiro, K.; Tsuneki, M. Deep Learning Models for Histopathological Classification of Gastric and Colonic Epithelial Tumours. Sci. Rep. 2020, 10, 1504. [Google Scholar] [CrossRef]
- Kloeckner, J.; Sansonowicz, T.K.; Rodrigues, Á.L.; Nunes, T.W.N. Multi-Categorical Classification Using Deep Learning Applied to the Diagnosis of Gastric Cancer. J. Bras. Patol. Med. Lab. 2020, 56, 1–8. [Google Scholar] [CrossRef]
- Hu, W.; Li, C.; Li, X.; Rahaman, M.M.; Ma, J.; Zhang, Y.; Chen, H.; Liu, W.; Sun, C.; Yao, Y.; et al. GasHisSDB: A New Gastric Histopathology Image Dataset for Computer Aided Diagnosis of Gastric Cancer. Comput. Biol. Med. 2022, 142, 105207. [Google Scholar] [CrossRef] [PubMed]
- Doyle, S.; Agner, S.; Madabhushi, A.; Feldman, M.; Tomaszewski, J. Automated Grading of Breast Cancer Histopathology Using Spectral Clusteringwith Textural and Architectural Image Features. In Proceedings of the 2008 5th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Paris, France, 14–17 May 2008; IEEE: Piscataway, NJ, USA; pp. 496–499. [Google Scholar]
- Kather, J.N.; Weis, C.-A.; Bianconi, F.; Melchers, S.M.; Schad, L.R.; Gaiser, T.; Marx, A.; Zöllner, F.G. Multi-Class Texture Analysis in Colorectal Cancer Histology. Sci. Rep. 2016, 6, 27988. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.; Mehra, R. Conventional Machine Learning and Deep Learning Approach for Multi-Classification of Breast Cancer Histopathology Images—A Comparative Insight. J. Digit. Imaging 2020, 33, 632–654. [Google Scholar] [CrossRef] [PubMed]
- Han, Z.; Wei, B.; Zheng, Y.; Yin, Y.; Li, K.; Li, S. Breast Cancer Multi-Classification from Histopathological Images with Structured Deep Learning Model. Sci. Rep. 2017, 7, 4172. [Google Scholar] [CrossRef]
- Ameh Joseph, A.; Abdullahi, M.; Junaidu, S.B.; Hassan Ibrahim, H.; Chiroma, H. Improved Multi-Classification of Breast Cancer Histopathological Images Using Handcrafted Features and Deep Neural Network (Dense Layer). Intell. Syst. Appl. 2022, 14, 200066. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Adebanjo, A. Breast Cancer Diagnosis in Histopathological Images Using ResNet-50 Convolutional Neural Network. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; IEEE: Piscataway, NJ, USA; pp. 1–7. [Google Scholar]
- Shallu, S.; Mehra, R. Breast Cancer Histology Images Classification: Training from Scratch or Transfer Learning? ICT Express 2018, 4, 247–254. [Google Scholar] [CrossRef]
- Celik, Y.; Talo, M.; Yildirim, O.; Karabatak, M.; Acharya, U.R. Automated Invasive Ductal Carcinoma Detection Based Using Deep Transfer Learning with Whole-Slide Images. Pattern Recognit. Lett. 2020, 133, 232–239. [Google Scholar] [CrossRef]
- Ghosh, S.; Bandyopadhyay, A.; Sahay, S.; Ghosh, R.; Kundu, I.; Santosh, K.C. Colorectal Histology Tumor Detection Using Ensemble Deep Neural Network. Eng. Appl. Artif. Intell. 2021, 100, 104202. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, C.; Zhou, X.; Chen, H.; Xu, H.; Li, Y.; Zhang, H.; Li, X.; Sun, H.; Huang, X.; et al. Application of Transfer Learning and Ensemble Learning in Image-Level Classification for Breast Histopathology. Intell. Med. 2022. [Google Scholar] [CrossRef]
- Paladini, E.; Vantaggiato, E.; Bougourzi, F.; Distante, C.; Hadid, A.; Taleb-Ahmed, A. Two Ensemble-CNN Approaches for Colorectal Cancer Tissue Type Classification. J. Imaging 2021, 7, 51. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscataway, NJ, USA; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA; pp. 1800–1807. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA; pp. 2261–2269. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PLMR: La Jolla, CA, USA, 2019. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Springenberg, M.; Frommholz, A.; Wenzel, M.; Weicken, E.; Ma, J.; Strodthoff, N. From CNNs to Vision Transformers—A Comprehensive Evaluation of Deep Learning Models for Histopathology. arXiv 2022, arXiv:2204.05044. [Google Scholar]
- Li, S.; Liu, W. LGFFN-GHI: A Local-Global Feature Fuse Network for Gastric Histopathological Image Classification. J. Comput. Commun. 2022, 10, 91–106. [Google Scholar] [CrossRef]
- Ninos, K.; Kostopoulos, S.; Kalatzis, I.; Sidiropoulos, K.; Ravazoula, P.; Sakellaropoulos, G.; Panayiotakis, G.; Economou, G.; Cavouras, D. Microscopy Image Analysis of P63 Immunohistochemically Stained Laryngeal Cancer Lesions for Predicting Patient 5-Year Survival. Eur. Arch. Oto-Rhino-Laryngol. 2016, 273, 159–168. [Google Scholar] [CrossRef]
- Kostopoulos, S.; Ravazoula, P.; Asvestas, P.; Kalatzis, I.; Xenogiannopoulos, G.; Cavouras, D.; Glotsos, D. Development of a Reference Image Collection Library for Histopathology Image Processing, Analysis and Decision Support Systems Research. J. Digit. Imaging 2017, 30, 287–295. [Google Scholar] [CrossRef]
- Zhou, X.; Tang, C.; Huang, P.; Mercaldo, F.; Santone, A.; Shao, Y. LPCANet: Classification of Laryngeal Cancer Histopathological Images Using a CNN with Position Attention and Channel Attention Mechanisms. Interdiscip. Sci. 2021, 13, 666–682. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Number of Samples | ||
|---|---|---|---|
| Augmented Training Set | Validation Set | Testing Set | |
| 80-pixels | 111,532 | 27,883 | 55,766 |
| 120-pixels | 50,116 | 12,529 | 25,058 |
| 160-pixels | 25,866 | 6466 | 12,934 |
| Model | Accuracy (%) | ||
|---|---|---|---|
| 80-Pixels | 120-Pixels | 160-Pixels | |
| MobileNet | 96.06 | 97.20 | 97.99 |
| MobileNetV2 | 95.49 | 97.51 | 98.39 |
| EfficientNetB0 | 96.75 | 97.72 | 98.48 |
| EfficientNetB1 | 96.66 | 97.82 | 98.50 |
| DenseNet121 | 96.65 | 98.12 | 99.10 |
| DenseNet169 | 96.73 | 98.21 | 98.93 |
| InceptionV3 | 94.75 | 96.72 | 98.24 |
| Xception | 95.80 | 97.14 | 97.79 |
| Ranking | 80-Pixels | 120-Pixels | 160-Pixels |
|---|---|---|---|
| 1 | EfficientNetB0 | DenseNet169 | DenseNet121 |
| 2 | DenseNet169 | DenseNet121 | DenseNet169 |
| 3 | EfficientNetB1 | EfficientNetB1 | EfficientNetB1 |
| 4 | DenseNet121 | EfficientNetB0 | EfficientNetB0 |
| 5 | MobileNet | MobileNetV2 | MobileNetV2 |
| Model | Accuracy | AUC | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|---|
| MobileNet | 95.82 | 95.73 | 94.90 | 95.15 | 96.30 | 95.02 |
| MobileNetV2 | 95.29 | 94.87 | 96.36 | 92.26 | 97.48 | 94.27 |
| EfficientNetB0 | 96.47 | 96.46 | 95.26 | 96.39 | 96.53 | 95.82 |
| EfficientNetB1 | 96.50 | 96.41 | 95.83 | 95.83 | 96.99 | 95.83 |
| DenseNet121 | 96.61 | 96.30 | 97.42 | 94.41 | 98.20 | 95.89 |
| DenseNet169 | 96.67 | 96.70 | 95.26 | 96.88 | 96.52 | 96.07 |
| InceptionV3 | 94.56 | 94.55 | 92.71 | 94.47 | 94.63 | 93.58 |
| Xception | 95.48 | 95.40 | 94.34 | 94.92 | 95.88 | 94.63 |
| Ensemble-WA3 | 97.56 | 97.51 | 96.97 | 97.22 | 97.80 | 97.09 |
| Ensemble-WA5 | 97.69 | 97.59 | 97.54 | 96.95 | 98.23 | 97.24 |
| Ensemble-UA3 | 97.59 | 97.57 | 96.80 | 97.47 | 97.67 | 97.13 |
| Ensemble-UA5 | 97.72 | 97.65 | 97.39 | 97.18 | 98.12 | 97.28 |
| Ensemble-MV3 | 97.49 | 97.47 | 96.66 | 97.38 | 97.57 | 97.02 |
| Ensemble-MV5 | 97.66 | 97.59 | 97.32 | 97.10 | 98.07 | 97.21 |
| Model | Accuracy | AUC | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|---|
| MobileNet | 97.12 | 96.88 | 96.88 | 95.76 | 98.00 | 96.32 |
| MobileNetV2 | 97.54 | 97.59 | 96.00 | 97.82 | 97.35 | 96.90 |
| EfficientNetB0 | 97.66 | 97.66 | 96.42 | 97.68 | 97.64 | 97.04 |
| EfficientNetB1 | 97.76 | 97.67 | 97.09 | 97.23 | 98.10 | 97.16 |
| DenseNet121 | 97.87 | 97.70 | 97.72 | 96.86 | 98.53 | 97.29 |
| DenseNet169 | 98.17 | 98.02 | 98.04 | 97.30 | 98.74 | 97.67 |
| InceptionV3 | 96.63 | 96.45 | 95.80 | 95.63 | 97.27 | 95.71 |
| Xception | 97.03 | 96.86 | 96.43 | 96.03 | 97.69 | 96.23 |
| Ensemble-WA3 | 98.52 | 98.36 | 98.59 | 97.63 | 99.09 | 98.11 |
| Ensemble-WA5 | 98.69 | 98.59 | 98.54 | 98.13 | 99.06 | 98.33 |
| Ensemble-UA3 | 98.53 | 98.42 | 98.36 | 97.90 | 98.94 | 98.13 |
| Ensemble-UA5 | 98.68 | 98.61 | 98.38 | 98.27 | 98.95 | 98.32 |
| Ensemble-MV3 | 98.47 | 98.35 | 98.32 | 97.78 | 98.91 | 98.05 |
| Ensemble-MV5 | 98.64 | 98.57 | 98.32 | 98.23 | 98.91 | 98.27 |
| Model | Accuracy | AUC | Precision | Recall | Specificity | F1-Score |
|---|---|---|---|---|---|---|
| MobileNet | 98.00 | 97.72 | 98.75 | 96.28 | 99.17 | 97.50 |
| MobileNetV2 | 98.42 | 98.36 | 98.03 | 98.05 | 98.66 | 98.04 |
| EfficientNetB0 | 98.33 | 98.29 | 97.83 | 98.05 | 98.52 | 97.94 |
| EfficientNetB1 | 98.36 | 98.32 | 97.85 | 98.11 | 98.53 | 97.98 |
| DenseNet121 | 98.68 | 98.58 | 98.66 | 98.07 | 99.09 | 98.36 |
| DenseNet169 | 98.57 | 98.36 | 99.20 | 97.25 | 99.47 | 98.22 |
| InceptionV3 | 97.85 | 97.83 | 97.02 | 97.69 | 97.96 | 97.36 |
| Xception | 97.43 | 97.34 | 96.74 | 96.91 | 97.78 | 96.82 |
| Ensemble-WA3 | 98.94 | 98.78 | 99.44 | 97.94 | 99.62 | 98.68 |
| Ensemble-WA5 | 99.16 | 99.09 | 99.19 | 98.72 | 99.45 | 98.96 |
| Ensemble-UA3 | 99.03 | 98.93 | 99.13 | 98.45 | 99.42 | 98.79 |
| Ensemble-UA5 | 99.20 | 99.14 | 99.23 | 98.80 | 99.48 | 99.01 |
| Ensemble-MV3 | 98.97 | 98.88 | 99.06 | 98.40 | 99.36 | 98.73 |
| Ensemble-MV5 | 99.13 | 99.07 | 99.10 | 98.76 | 99.39 | 98.93 |
| Paper | Training /Validation/ Testing | Dataset Pre-Processing | Model Details | Accuracy (%) | ||
|---|---|---|---|---|---|---|
| 80-Pixels | 120-Pixels | 160-Pixels | ||||
| [32] | 40%/40%/20% | - | VGG16 | 96.12 | 96.47 | 95.90 |
| ResNet50 | 96.09 | 95.94 | 96.09 | |||
| [51] | 40%/20%/40% | - | InceptionV3 trained from scratch | - | - | 98.83 ± 0.05 |
| InceptionV3 + ResNet50 (feature concatenation) | - | - | 98.80 ± 0.12 | |||
| [52] | 60%/20%/20% | - | Local-global feature fuse network | - | - | 96.81 |
| [4] | 80%/-/20% | - | MCLNet based on ShuffleNetV2 | 96.28 | 97.95 | 97.85 |
| Our study (only the best model is listed) | 40%/20%/40% | Data augmentation, empty patch removal | EfficientNetB0 + EfficientNetB1+ DenseNet121 + DenseNet169 + MobileNet (unweighted averaging) | 97.72 | 98.68 | 99.20 |
| EfficientNetB0 + EfficientNetB1+ DenseNet121 + DenseNet169 + MobileNetV2 (weighted averaging) | 97.69 | 98.69 | 99.16 | |||
| 534 × 400 Pixels Dataset | 1067 × 800 Pixels Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Paper | Model | Single Class Accuracy (%) | Accuracy (%) | Single Class Accuracy (%) | Accuracy (%) | ||||
| G1 | G2 | G3 | G1 | G2 | G3 | ||||
| [55] | LPCANet | 81.18 | 74.46 | 60.42 | 73.18 | 81.30 | 89.40 | 78.50 | 83.15 |
| Our models | Ensemble-WA5 | 98.48 | 89.09 | 95.92 | 94.71 | 98.28 | 97.94 | 97.67 | 97.99 |
| Ensemble-UA5 | 98.48 | 89.09 | 95.92 | 94.71 | 98.28 | 97.94 | 97.67 | 97.99 | |
| Ensemble-MV5 | 98.48 | 92.73 | 97.96 | 96.47 | 97.99 | 97.94 | 97.67 | 97.88 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yong, M.P.; Hum, Y.C.; Lai, K.W.; Lee, Y.L.; Goh, C.-H.; Yap, W.-S.; Tee, Y.K. Histopathological Gastric Cancer Detection on GasHisSDB Dataset Using Deep Ensemble Learning. Diagnostics 2023, 13, 1793. https://doi.org/10.3390/diagnostics13101793
Yong MP, Hum YC, Lai KW, Lee YL, Goh C-H, Yap W-S, Tee YK. Histopathological Gastric Cancer Detection on GasHisSDB Dataset Using Deep Ensemble Learning. Diagnostics. 2023; 13(10):1793. https://doi.org/10.3390/diagnostics13101793
Chicago/Turabian StyleYong, Ming Ping, Yan Chai Hum, Khin Wee Lai, Ying Loong Lee, Choon-Hian Goh, Wun-She Yap, and Yee Kai Tee. 2023. "Histopathological Gastric Cancer Detection on GasHisSDB Dataset Using Deep Ensemble Learning" Diagnostics 13, no. 10: 1793. https://doi.org/10.3390/diagnostics13101793
APA StyleYong, M. P., Hum, Y. C., Lai, K. W., Lee, Y. L., Goh, C. -H., Yap, W. -S., & Tee, Y. K. (2023). Histopathological Gastric Cancer Detection on GasHisSDB Dataset Using Deep Ensemble Learning. Diagnostics, 13(10), 1793. https://doi.org/10.3390/diagnostics13101793