
An Automated Method of 3D Facial Soft Tissue Landmark Prediction Based on Object Detection and Deep Learning
 ,
, 
Abstract
:1. Introduction
- High training and time cost for operators familiar with 3D software;
- High time cost for annotation of large amount of data;
- Poor consistency and repeatability of landmarks’ determination among different operators.
- Geometric information algorithm: it calculates the location of landmarks by mathematical methods based on geometric features, which is primarily used to determine landmarks with significant geometric features on the human face and can accurately locate the position of a small number of landmarks with significant features [14].
- Model matching algorithm: it calculates the location of landmarks by constructing candidate combinations of landmarks and utilizing topological relationships [15].
- Deep learning algorithm: it predicts the location of landmarks by building a deep neural network. Next, we will introduce the recent related work using deep learning methods in detail.
- We propose a deep learning architecture for predicting the facial soft tissue landmarks based on 3D face models instead of transforming 3D models into 2D images;
- We propose a prediction method for facial soft tissues landmarks based on 3D object detection, which is able to significantly increase the number of predicted landmarks to 32;
- Tested on real diagnostic data from hospitals, it achieves more landmarks of prediction and higher prediction accuracy than previous methods.
2. Materials and Methods
2.1. Datasets
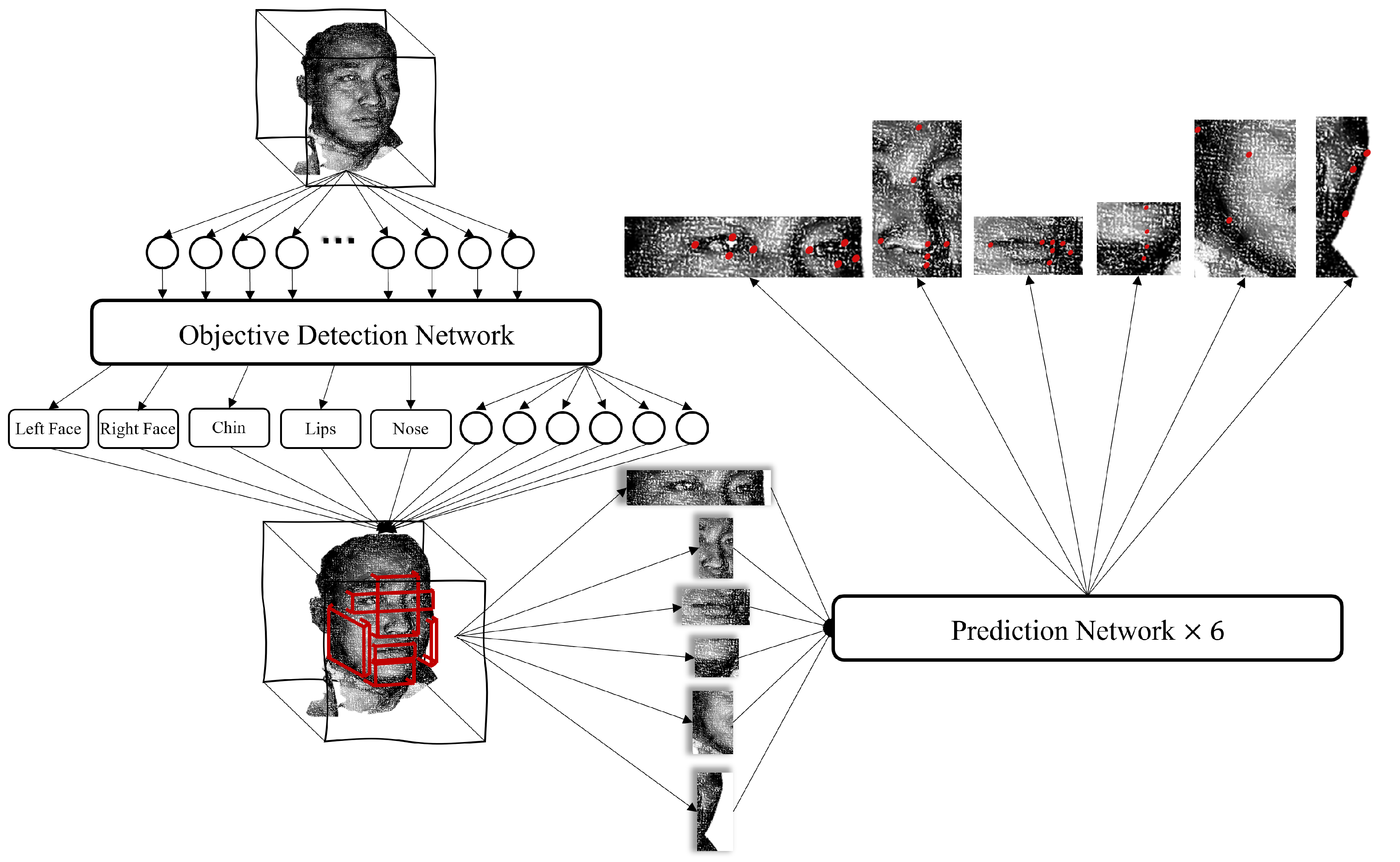
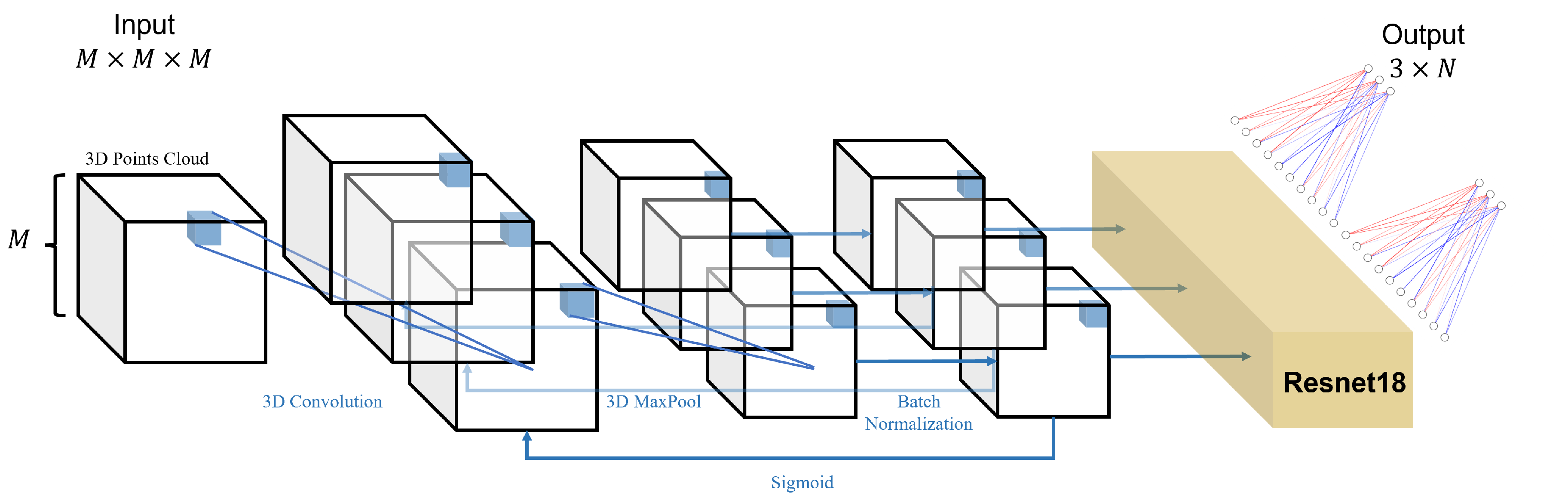
2.2. Architecture Overview
- Transform the 3D human facial soft tissue model into a 3D point cloud model;
- Input the point cloud into the object detection network to obtain the boxes of the six organs (eyes, nose, lips, chin, right face, and left face, each box is represented by a six-dimension vector);
- Extract the corresponding coordinate of each organ and put them into their prediction model to obtain the landmarks which need predicting.
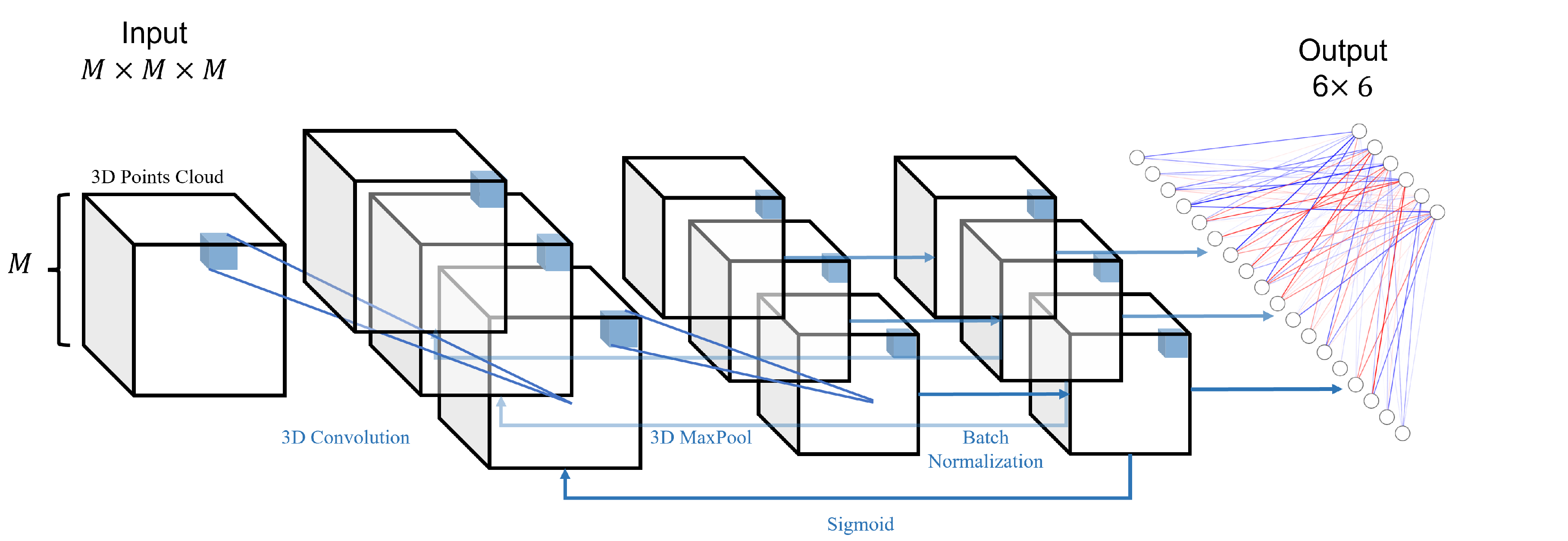
2.3. Object Detection Network
2.4. Prediction Network
2.5. Experiment
2.5.1. Data Preprocessing
- Cleaning the data by removing any obvious occlusions, such as the physician’s hand fixing the patient’s head, and any obviously incorrect markers;
- Normalizing all the data to the range [−1, 1], while preserving the scaling multiplier S of each data for error calculation.
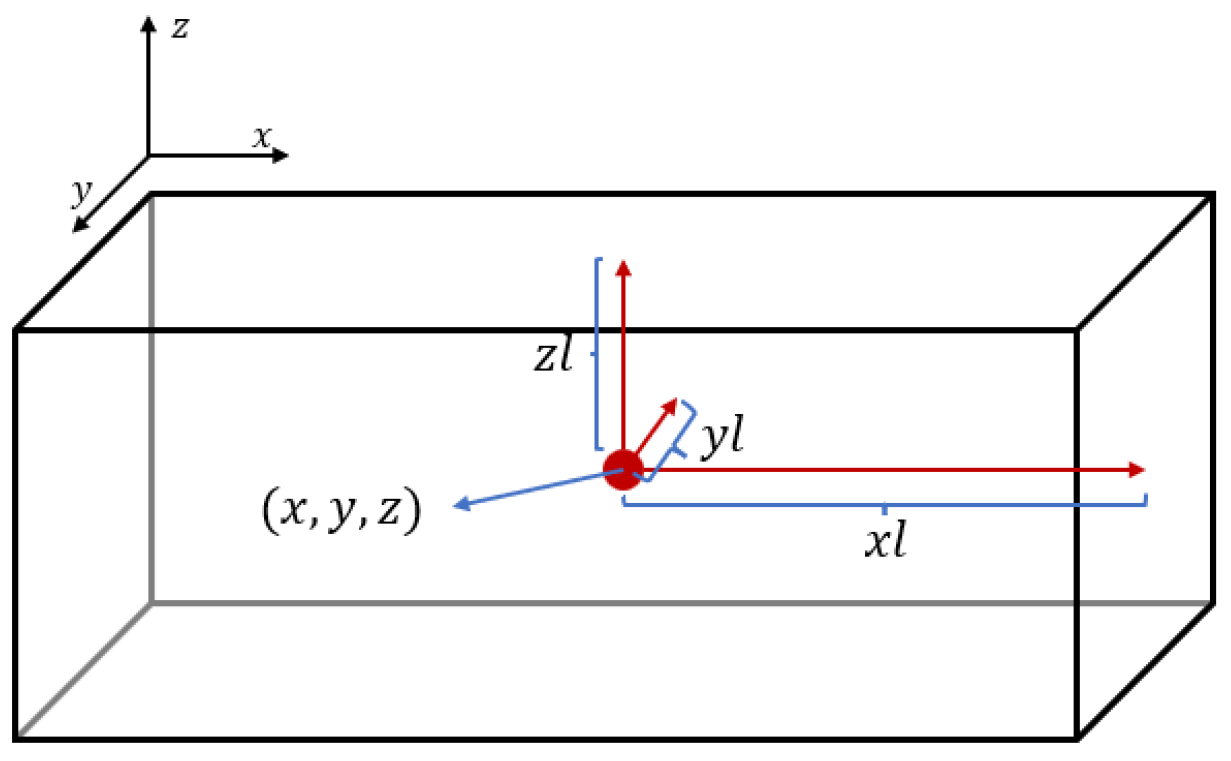
- Creating a three-dimensional uniform grid with a side length of M, which can accommodate points, and the data accuracy is ;
- After adjusting the valid numbers of the data, iteratively setting for the locations of the points present in the grid.
2.5.2. Loss Calculation
2.5.3. Experimental Setting
3. Results
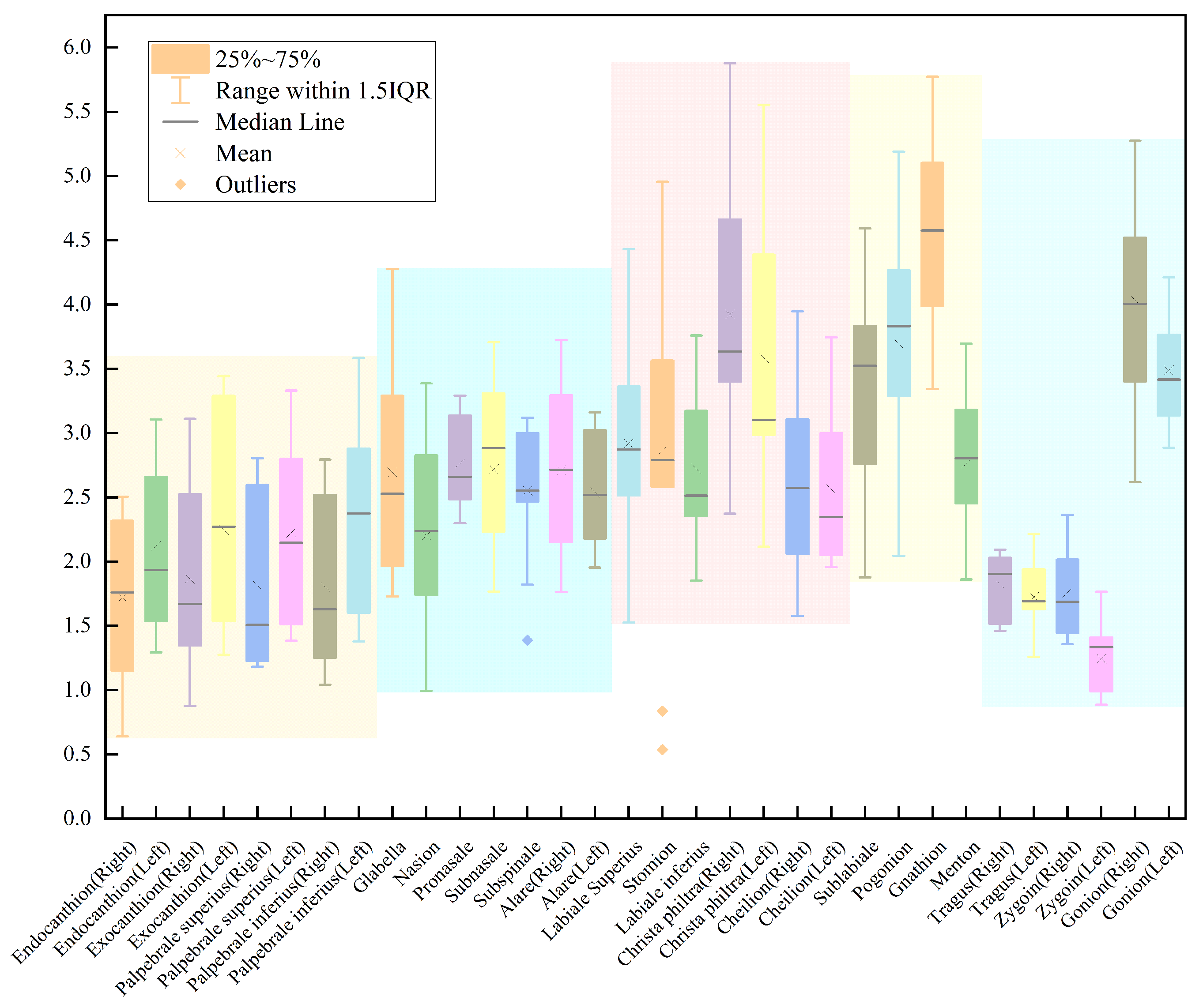
3.1. Comparison of Errors between Our Work and Manual Marking
3.2. Comparison of Errors between Our Work and Other Works
4. Discussion
- Existing algorithms do not fully extract the complex interrelationships between points in the 3D model;
- The data used in this study are insufficient for clinical practice. The further application of this method on a larger patient population is necessary to ensure reliable results. We plan to integrate the development of a 3D human facial soft tissue model database to expand the patient dataset;
- It is essential to conduct additional research to validate and establish the proposed method as a reliable tool in clinical practice. This entails conducting more comprehensive studies that evaluate its effectiveness, accuracy, and potential limitations in diverse clinical settings.
- The proximity of some landmarks is so close that, if the error in prediction is not sufficiently small compared to the distance to its nearest point, the prediction of a point becomes meaningless. However, this method of evaluation is not currently employed in corresponding works;
- There are numerous clinically significant landmarks present in both human facial soft tissue and CBCT images that existing methods are unable to predict due to limitations in algorithms and the corresponding databases.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Proffit, W.R.; Fields, H.W., Jr.; Sarver, D.M. Contemporary Orthodontics; Elsevier Health Sciences, 2006; p. 5. [Google Scholar]
- Wu, J.; Qian, B.; Li, Y.; Gao, Z.; Ju, M.; Yang, Y.; Zheng, Y.; Gong, T.; Li, C.; Zhang, X. Leveraging multiple types of domain knowledge for safe and effective drug recommendation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 2169–2178. [Google Scholar]
- Wu, J.; Dong, Y.; Gao, Z.; Gong, T.; Li, C. Dual Attention and Patient Similarity Network for Drug Recommendation. Bioinformatics 2023, 39, btad003. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; He, W.; Chen, G.; Song, G.; Matthews, H.; Claes, P.; Jiang, R.; Xu, T. Facial asymmetry assessment in skeletal Class III patients with spatially-dense geometric morphometrics. Eur. J. Orthod. 2022, 44, 155–162. [Google Scholar] [CrossRef]
- Khambay, B.; Nebel, J.; Bowman, J.; Ayoub, A.; Walker, F.; Hadley, D. A pilot study: 3D stereo photogrammetric image superimposition on to 3D CT scan images–the future of orthognathic surgery. Int. J. Adult Orthod. Orthog. Surg. 2002, 17, 244–252. [Google Scholar]
- Wu, J.; Zhang, R.; Gong, T.; Bao, X.; Gao, Z.; Zhang, H.; Wang, C.; Li, C. A precision diagnostic framework of renal cell carcinoma on whole-slide images using deep learning. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; IEEE: Houston, TX, USA, 2021; pp. 2104–2111. [Google Scholar]
- Wu, J.; Zhang, R.; Gong, T.; Zhang, H.; Wang, C.; Li, C. A personalized diagnostic generation framework based on multi-source heterogeneous data. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 2096–2103. [Google Scholar]
- Waitzman, A.A.; Posnick, J.C.; Armstrong, D.C.; Pron, G.E. Craniofacial skeletal measurements based on computed tomography: Part I. Accuracy and reproducibility. Cleft-Palate-Craniofacial J. 1992, 29, 112–117. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Tang, K.; Zhang, H.; Wang, C.; Li, C. Structured information extraction of pathology reports with attention-based graph convolutional network. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 2395–2402. [Google Scholar]
- Wu, J.; Zhang, R.; Gong, T.; Liu, Y.; Wang, C.; Li, C. Bioie: Biomedical information extraction with multi-head attention enhanced graph convolutional network. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 2080–2087. [Google Scholar]
- Littlefield, T.R.; Kelly, K.M.; Cherney, J.C.; Beals, S.P.; Pomatto, J.K. Development of a new three-dimensional cranial imaging system. J. Craniofacial Surg. 2004, 15, 175–181. [Google Scholar] [CrossRef] [PubMed]
- Maal, T.J.; van Loon, B.; Plooij, J.M.; Rangel, F.; Ettema, A.M.; Borstlap, W.A.; Bergé, S.J. Registration of 3-dimensional facial photographs for clinical use. J. Oral Maxillofac. Surg. 2010, 68, 2391–2401. [Google Scholar] [CrossRef] [PubMed]
- Vezzetti, E.; Marcolin, F.; Stola, V. 3D human face soft tissues landmarking method: An advanced approach. Comput. Ind. 2013, 64, 1326–1354. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F. Geometry-based 3D face morphology analysis: Soft-tissue landmark formalization. Multimed. Tools Appl. 2014, 68, 895–929. [Google Scholar] [CrossRef]
- Sukno, F.M.; Waddington, J.L.; Whelan, P.F. 3D facial landmark localization using combinatorial search and shape regression. In Proceedings of the Computer Vision–ECCV 2012, Workshops and Demonstrations, Florence, Italy, 7–13 October 2012; Proceedings, Part I 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 32–41. [Google Scholar]
- Yang, J.; Liu, Q.; Zhang, K. Stacked hourglass network for robust facial landmark localisation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 79–87. [Google Scholar]
- Paulsen, R.R.; Juhl, K.A.; Haspang, T.M.; Hansen, T.; Ganz, M.; Einarsson, G. Multi-view consensus CNN for 3D facial landmark placement. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part I. Springer: Berlin/Heidelberg, Germany, 2019; pp. 706–719. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, K.; Zhao, X.; Gao, W.; Zou, J. A coarse-to-fine approach for 3D facial landmarking by using deep feature fusion. Symmetry 2018, 10, 308. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus Database for 3D Face Analysis. In Proceedings of the Biometrics and Identity Management; Schouten, B., Juul, N.C., Drygajlo, A., Tistarelli, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Baksi, S.; Freezer, S.; Matsumoto, T.; Dreyer, C. Accuracy of an automated method of 3D soft tissue landmark detection. Eur. J. Orthod. 2021, 43, 622–630. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. CoRR 2015. Available online: http://xxx.lanl.gov/abs/1512.03385 (accessed on 10 December 2015).
- Fanelli, G.; Dantone, M.; Van Gool, L. Real time 3D face alignment with Random Forests-based Active Appearance Models. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Zhao, X.; Dellandrea, E.; Chen, L.; Kakadiaris, I.A. Accurate Landmarking of Three-Dimensional Facial Data in the Presence of Facial Expressions and Occlusions Using a Three-Dimensional Statistical Facial Feature Model. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 41, 1417–1428. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Huang, D.; Wang, Y.; Chen, L. A coarse-to-fine approach to robust 3D facial landmarking via curvature analysis and Active Normal Model. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 18 April 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, M.; Fan, Z.; Peng, S. Learning to Detect 3D Facial Landmarks via Heatmap Regression with Graph Convolutional Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 2595–2603. [Google Scholar]
- Terada, T.; Chen, Y.W.; Kimura, R. 3D facial landmark detection using deep convolutional neural networks. In Proceedings of the 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Huangshan, China, 28–30 July 2018; pp. 390–393. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6897–6906. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
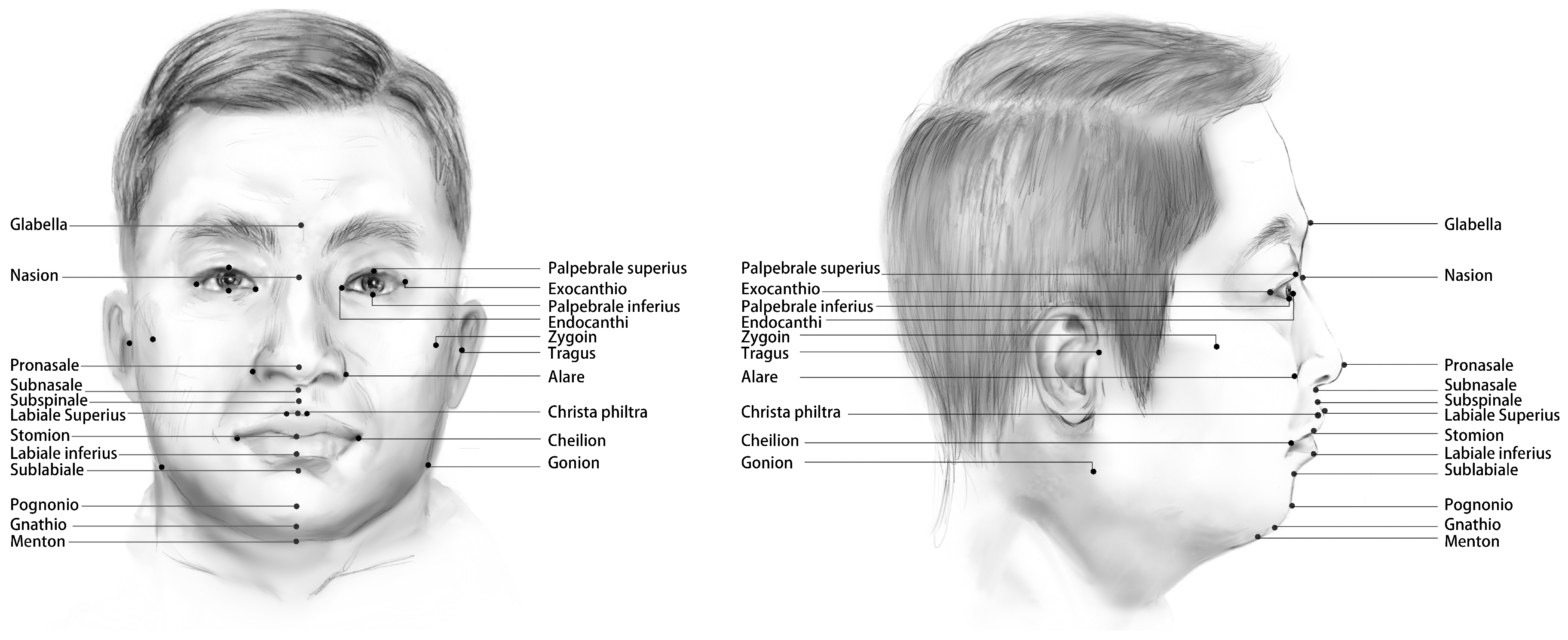
| Organ | Abbreviation | Landmarks | Definition |
|---|---|---|---|
| Eyes | En | Endocanthion (right and left) | The soft tissue point located at the inner commissure of the right eye fissure |
| Ex | Exocanthion (right and left) | The soft tissue point located at the outer commissure of the right eye fissure | |
| Ps | Palpebrale superius (right and left) | Most superior point on the margin of the upper eyelid | |
| Pi | Palpebrale inferius (right and left) | Most inferior point on the margin of the lower eyelid | |
| Nose | G | Glabella | Most anterior midpoint on the front-to-orbital soft tissue contour. |
| Na | Nasion | Point directly anterior to the nasofrontal suture, in the midline | |
| Pn | Pronasale | The most anteriorly protruded point of the apex nasi | |
| Sn | Subnasale | Median point at the junction between the lower border of the nasal septum and the philtrum area | |
| A | Subspinale | The deepest point seen in the profile view below the anterior nasal spine | |
| Al | Alare (right and left) | The most lateral point on the nasal ala | |
| Lips | Ls | Labiale superius | Midpoint of the vermilion border of the upper lip |
| Sto | Stomion | Midline point of the labial fissure when the lips are naturally closed, with teeth shut in the natural position | |
| Li | Labiale inferius | Midpoint of the vermilion border of the lower lip | |
| Cph | Christa philtra (right and left) | Point on each elevated margin of the philtrum just before projection to the vermilion line | |
| Ch | Cheilion (right and left) | Outer corners of the mouth where the outer edges of the upper and lower vermilions meet | |
| Chin | B | Sublabiale | Most posterior midpoint of the philtrum |
| Pg | Pogonion | Most anterior median point on the mental eminence of the mandible | |
| Gn | Gnathion | Median point halfway between pg and me | |
| Me | Menton | Most inferior median point of the mental symphysis | |
| Face | Tra | Tragus (right and left) | The most convex point of the tragus at the external ear canal |
| Zv | Zygion (right and left) | Instrumentally determined as the most lateral point on the zygomatic arch | |
| Go | Gonion (right and left) | Point on the rounded margin of the angle of the mandible, bisecting two lines—one following the vertical margin of ramus and one following the horizontal margin of corpus of mandible |
| Organ | Output Dimension |
|---|---|
| Eyes | 8 |
| Nose | 7 |
| Lips | 7 |
| Chin | 4 |
| Right face | 3 |
| Left face | 3 |
| Landmark | Baksi1 [24] | Fanelli [26] | Zhao [27] | Sun [28] | Wang [19] | Our Method |
|---|---|---|---|---|---|---|
| Endocanthion (right) | ||||||
| Endocanthion (left) | ||||||
| Exocanthion (right) | ||||||
| Exocanthion (left) | ||||||
| Palpebrale superius (right) | - | - | - | - | - | |
| Palpebrale superius (left) | - | - | - | - | - | |
| Palpebrale inferius (right) | - | - | - | - | - | |
| Palpebrale inferius (left) | - | - | - | - | - | |
| Glabella | - | - | - | - | ||
| Nasion | - | - | - | - | - | |
| Pronasale | - | - | - | - | ||
| Subnasale | - | - | - | - | ||
| Subspinale | - | - | - | - | ||
| Alare (right) | ||||||
| Alare (left) | ||||||
| Labiale superius | ||||||
| Stomion | - | - | - | - | ||
| Labiale inferius | ||||||
| Christa philtra (right) | - | - | - | - | ||
| Christa philtra (left) | - | - | - | - | ||
| Cheilion (right) | ||||||
| Cheilion (left) | ||||||
| Sublabiale | - | - | - | - | ||
| Pogonion | - | - | - | - | ||
| Gnathion | - | - | - | - | ||
| Menton | - | - | - | - | - | |
| Tragus (right) | - | - | - | - | - | |
| Tragus (left) | - | - | - | - | - | |
| Zygoin (right) | - | - | - | - | - | |
| Zygoin (left) | - | - | - | - | - | |
| Gonion (right) | - | - | - | - | - | |
| Gonion (left) | - | - | - | - | - | |
| Mean results |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Xu, Y.; Zhao, J.; Du, T.; Li, D.; Zhao, X.; Wang, J.; Li, C.; Tu, J.; Qi, K. An Automated Method of 3D Facial Soft Tissue Landmark Prediction Based on Object Detection and Deep Learning. Diagnostics 2023, 13, 1853. https://doi.org/10.3390/diagnostics13111853
Zhang Y, Xu Y, Zhao J, Du T, Li D, Zhao X, Wang J, Li C, Tu J, Qi K. An Automated Method of 3D Facial Soft Tissue Landmark Prediction Based on Object Detection and Deep Learning. Diagnostics. 2023; 13(11):1853. https://doi.org/10.3390/diagnostics13111853
Chicago/Turabian StyleZhang, Yuchen, Yifei Xu, Jiamin Zhao, Tianjing Du, Dongning Li, Xinyan Zhao, Jinxiu Wang, Chen Li, Junbo Tu, and Kun Qi. 2023. "An Automated Method of 3D Facial Soft Tissue Landmark Prediction Based on Object Detection and Deep Learning" Diagnostics 13, no. 11: 1853. https://doi.org/10.3390/diagnostics13111853
APA StyleZhang, Y., Xu, Y., Zhao, J., Du, T., Li, D., Zhao, X., Wang, J., Li, C., Tu, J., & Qi, K. (2023). An Automated Method of 3D Facial Soft Tissue Landmark Prediction Based on Object Detection and Deep Learning. Diagnostics, 13(11), 1853. https://doi.org/10.3390/diagnostics13111853