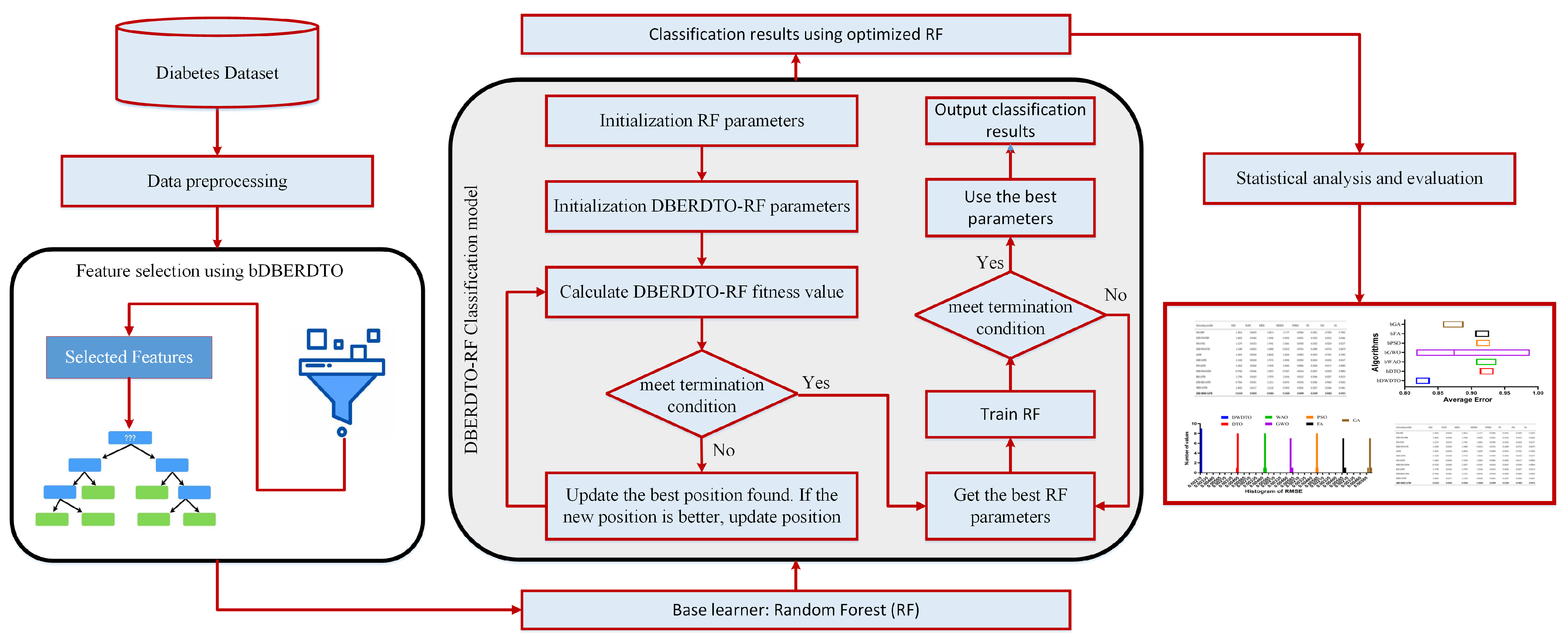
4.5. Results of Feature Selection
Using seven alternative metaheuristic optimization algorithms (bDBERDTO, bBER, bDTO, bPSO, bWAO, bGWO, and bFA), the authors report their findings about feature selection from diabetic features. The findings for each algorithm are summarized by their average select size. The average error results show the average error rate of each method, and they show that bDBERDTO has the lowest average error rate of 0.460, implying that the features selected by bDBERDTO can classify diabetes occurrences with a high degree of accuracy.
According to the results presented in
Table 6, bWAO has the largest average select size (0.776), indicating that it has selected the most features on average. This suggests that bWAO is less efficient at reducing the dimensionality of the dataset, which may result in overfitting. The average fitness results show how each algorithm generally performs. Based on the results, bDBERDTO can be considered a powerful feature selection algorithm for diabetes classification, with an average fitness value of 0.523, which is significantly higher than the other algorithms. The highest fitness values show the greatest results for each algorithm. Based on the findings, bDBERDTO’s feature selection yields superior classification results to the other algorithms, with a best fitness value of 0.425. The lowest fitness values show the worst possible outcomes for each algorithm. Finally, the standard deviation fitness results show the variation in fitness values obtained by each algorithm, revealing that bFA has the worst fitness value of 0.606, indicating that bFA could not select a good subset of features that can perform well in diabetes classification. This suggests that the features chosen by bDBERDTO are more stable and can lead to consistent performance in diabetes classification, as evidenced by the lowest standard deviation of fitness values produced by bDBERDTO (0.346). As a whole, these findings are very suggestive of bDBERDTO’s potential as a feature selection method for diabetes classification.
The analysis of variance (ANOVA) is a statistical technique used to compare the means of two or more groups to establish statistical significance. The analysis was performed on a dataset of 69 samples from 7 groups, as presented in
Table 7. With an F-value of 136.1 and a
p-value of less than 0.0001, the results demonstrate that the Treatment factor significantly affected the data. This indicates a statistically significant change in the response variable due to the treatment and a difference in means between the groups. The error variance is estimated using the residual findings, which show the variation within each group. For this situation, 63 degrees of freedom (DF) were available, and the residual mean square was 0.00179. This suggests a tiny amount of diversity inside each group, but the variation across groups is much more significant. The results in the total column reflect the sum of all possible differences in the data, both between and within groups. The total number of degrees of freedom was 69, and the sum of squares (SS) was 0.02502. The analysis of variance test results indicates that the differences between the treatment groups are statistically significant and not coincidental. The relationship between therapies and the response variable can be better understood, and judgments regarding which treatment is most effective can be made with the help of this data.
A non-parametric alternative is the Wilcoxon signed-rank test to compare two related samples. For each of the seven feature selection techniques (bDBERDTO, bBER, bDTO, bPSO, bWAO, bGWO, and bFA), the test is used to compare the theoretical median values (assumed to be zero) with the actual median values presented in
Table 8. Ten examples of each technique are used in the test. Each observation is given a rank, with higher ranks going to observations above the median and lower ranks going to observations below the median. These ranks are the “sum of signed ranks” (W). In this situation, the median values are continuously greater than the theoretical median of zero, as the sum of signed rankings is 55 across all 7 approaches. The total rankings for all “positive” and “negative” observations are summed to get the “sum of positive ranks” and “sum of negative ranks”, respectively. In this situation, all methods have median values greater than the theoretical median of zero, as seen by the total of the positive ranks being 55. No actual median values are below the theoretical median, as the sum of negative ranks is 0 for all techniques. Suppose that the null hypothesis (which here states that the observed median values are not significantly different from the theoretical median of zero) is correct. In that case, the “
p-value” (two-tailed) is the probability of obtaining a test statistic as extreme as or more extreme than the observed test statistic. For all seven approaches, the P value is less than 0.002, suggesting sufficient evidence to reject the null hypothesis and infer that the observed median values differ substantially from the theoretical median. If the
p-value was calculated exactly or estimated, as the information in the “Exact or estimate?” field. Here, the calculated P values are accurate. If you want to know if your results are statistically significant at the 0.05 level, enter that number into the “Significant (alpha = 0.05)?” column. Given that the P value is less than 0.05, these findings are statistically significant at the 5% level of confidence. Finally, the discrepancy between the observed median values and the ideal zero median is displayed in the “Discrepancy” section. In this category, the numbers represent the reported medians for each technique. The results show that, similar to every other feature selection approach evaluated, the suggested method (bDBERDTO) deviates significantly from the expected zero medians.
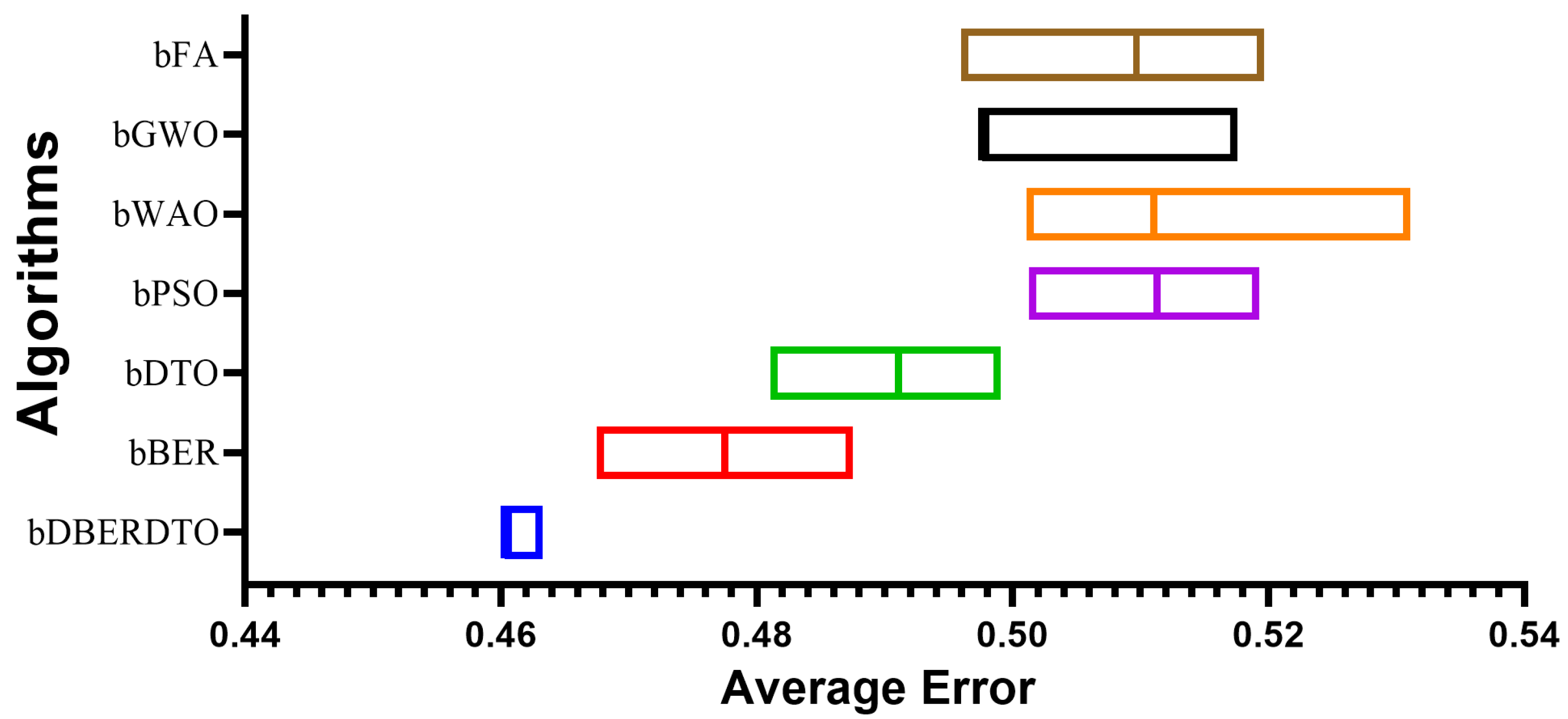
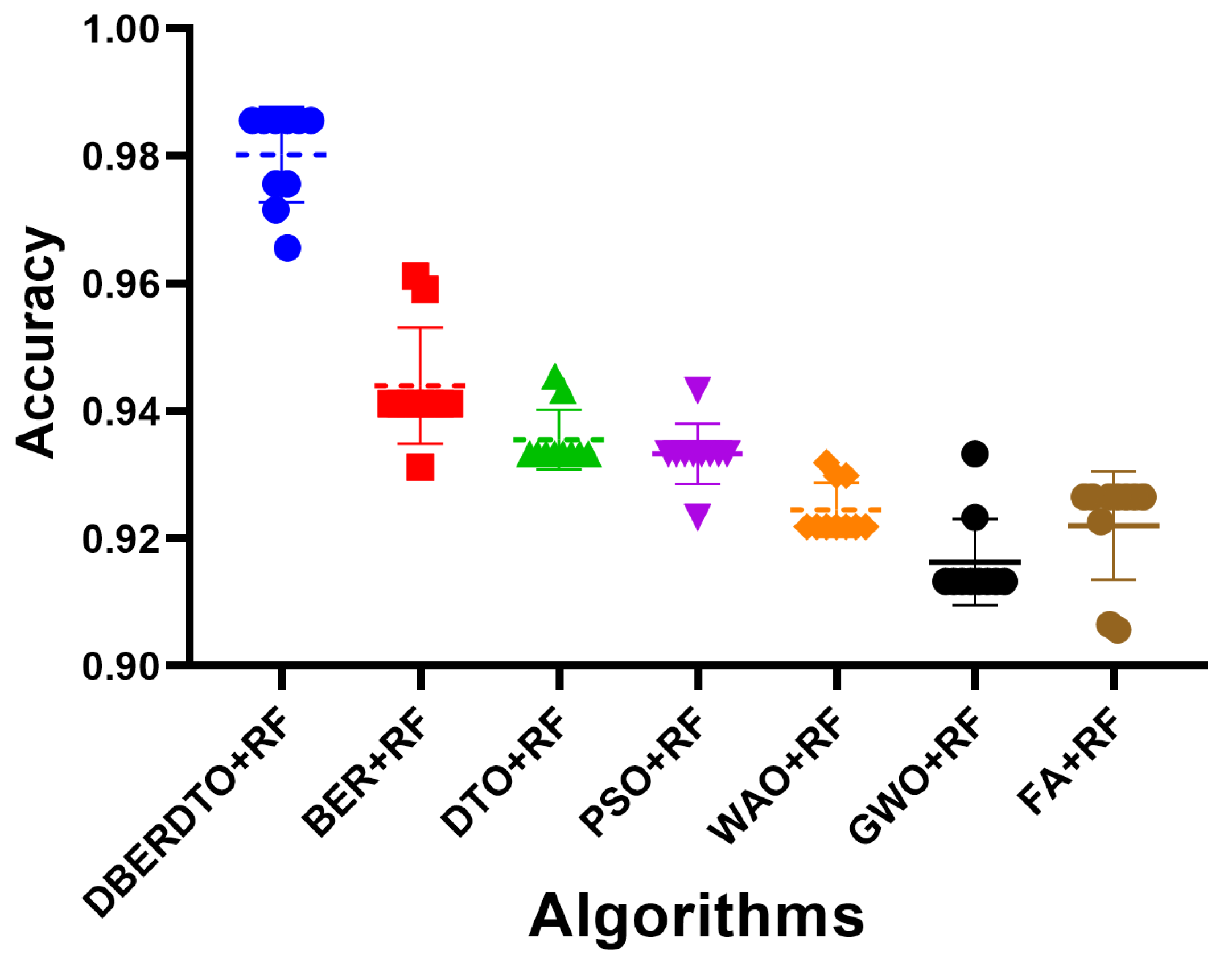
In
Figure 4, the proposed method, bDBERDTO, has the lowest average error in a plot comparing the average errors achieved by other feature selection techniques. The plot also included the other methods bFA, bGWO, bWOA, bPSO, bDTO, and bBER, but none of them could match the performance of bDBERDTO. The plot shows that the proposed method is quite good at picking out the most important features in a dataset, which improves the overall performance of the system. It’s important to remember that even the other methods managed to attain low average mistakes, showing that they are not without merit. However, the recommended strategy emerges as the undisputed victor in this comparison. The ramifications of these findings for professionals in domains that use feature selection techniques to boost model performance are substantial. Compared to popular feature selection approaches, bDBERDTO is expected to produce even better outcomes.
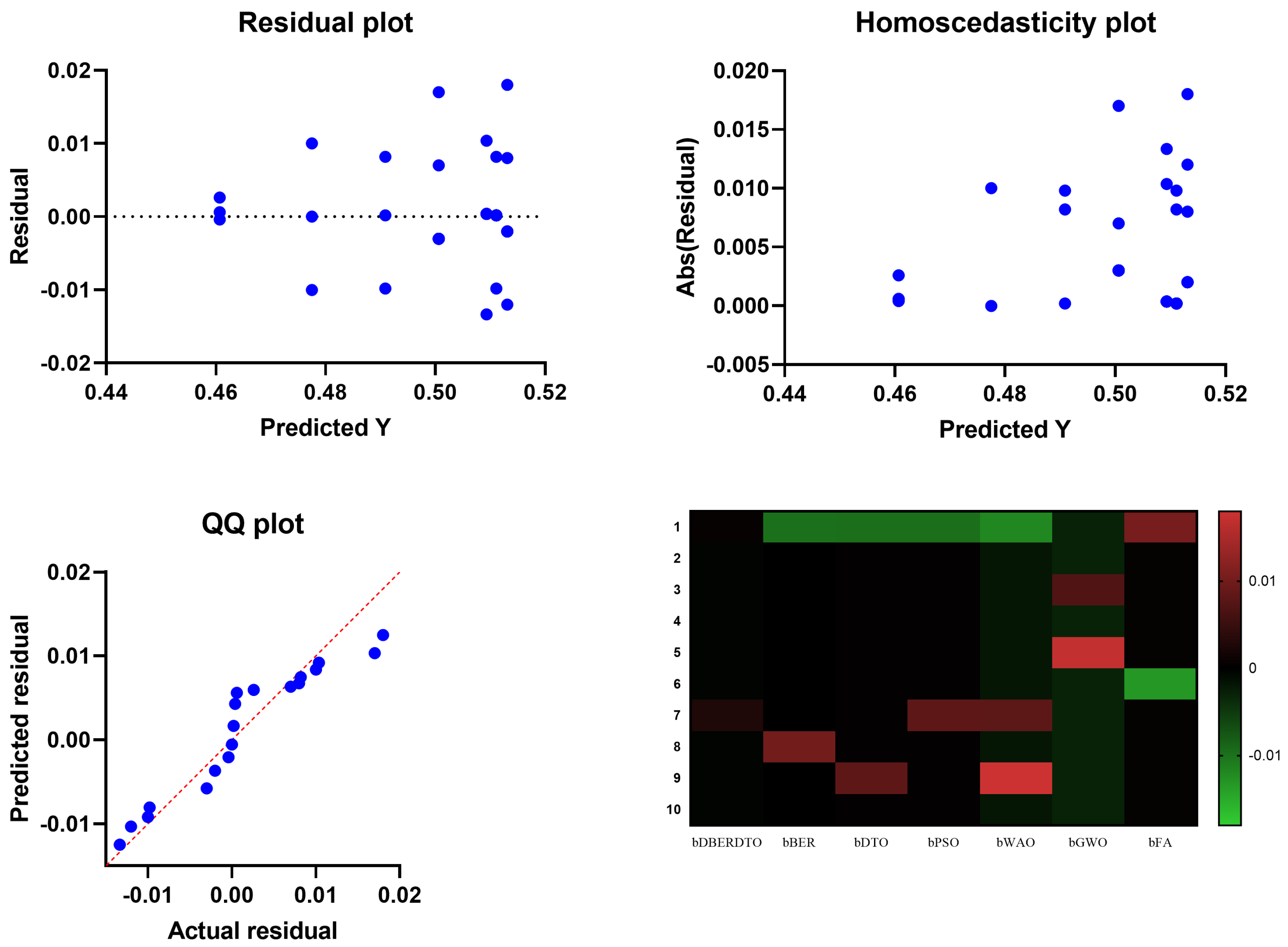
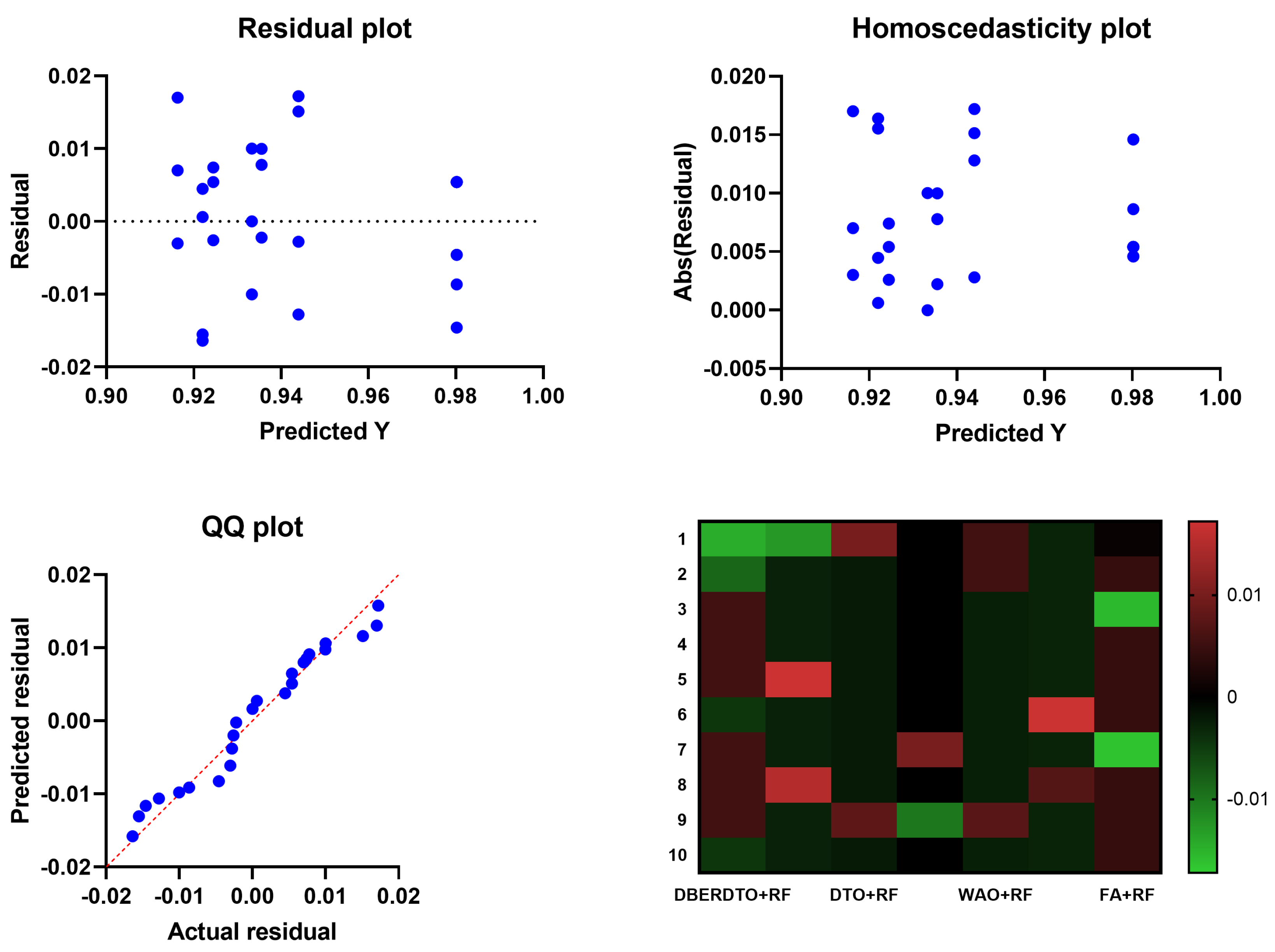
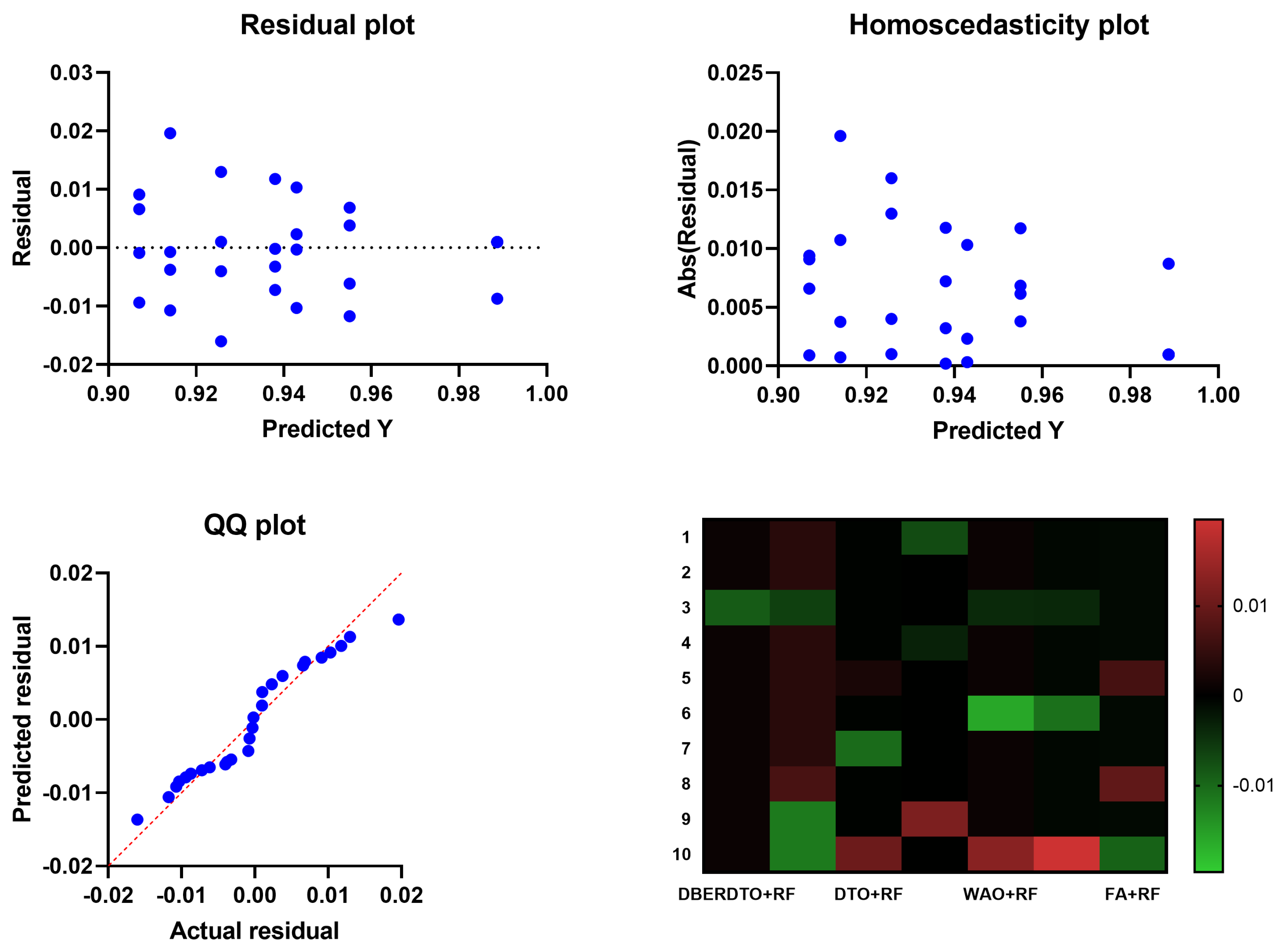
In
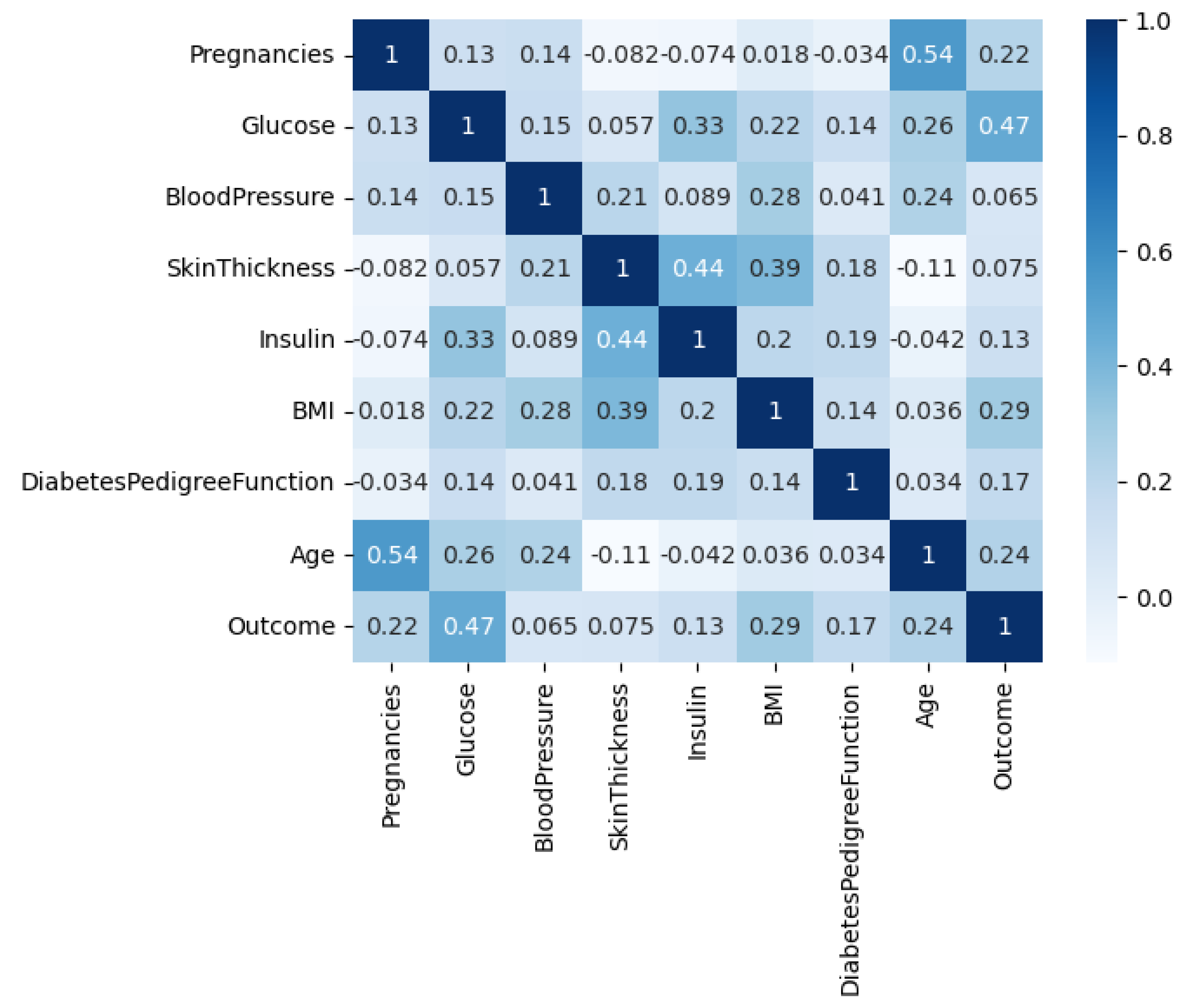
Figure 5, the residual, homoscedasticity, quartile-quartile (QQ), and heatmap plots are used to examine the ANOVA outcomes of the suggested feature selection technique. Residual and homoscedasticity plots are used to verify that the errors have the same variance and that the data is normally distributed. QQ plots are used to evaluate the normality of the residuals, while heatmap plots are used to see the connections between the chosen features. Providing that the assumptions are met, the residual plot, which displays the discrepancy between the observed and anticipated values, should exhibit no discernible pattern. The homoscedasticity plot’s residuals should be randomly dispersed around the horizontal line to ensure that the error variance is the same across all predictor variables levels. A straight line in the QQ plot indicates properly distributed residuals. We can gain insight into potential multicollinearity issues by displaying highly correlated features in a heatmap. These plots, when combined, give a thorough picture of the ANOVA results of the proposed feature selection approach, allowing practitioners to evaluate the assumptions and see any problems that may need fixing before interpreting the results.
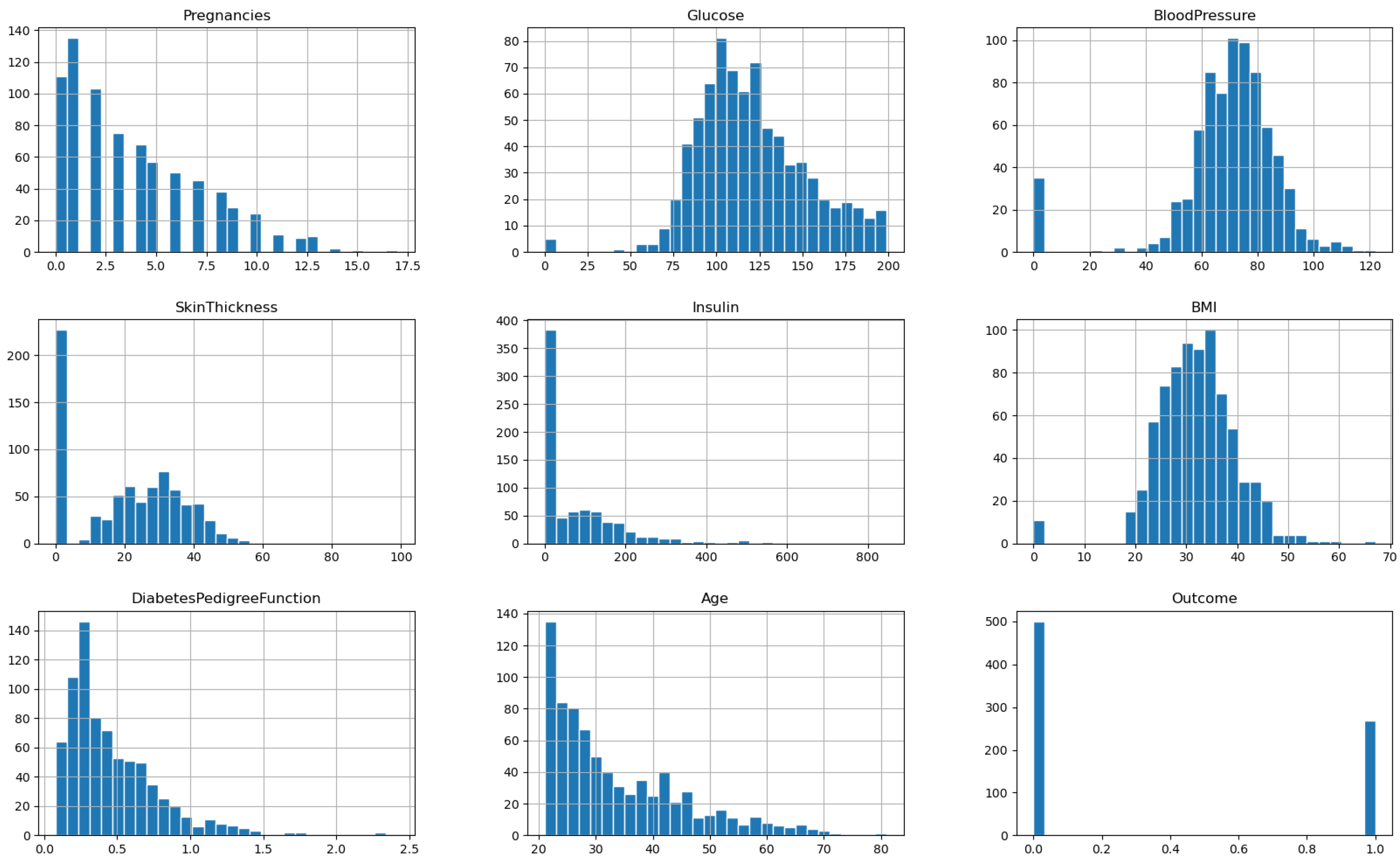
Different classification algorithms were evaluated on a diabetes dataset consisting of patient medical records and other parameters used to determine diabetes risk, and the findings are presented in
Table 9. Some performance indicators are
p-values, F-scores, precision, sensitivity, and specificity. The
p-value measures how likely it is to find a test statistic that is at least as outlandish as the one found in the dataset. The F-score examines how well true positive and false positive rates are balanced. F is the harmonic mean of precision and recall. The accuracy of a prediction system is measured by how many of those forecasts come true. An accurate positive rate is known as sensitivity, and an accurate negative rate is known as specificity. With an accuracy of 0.813, a sensitivity of 0.859, a specificity of 0.741, an F-score of 0.768, and a
p-value of 0.840, random forest (RF) outperformed the other classification algorithms. Logistic regression (LR) came in second, scoring an F-score of 0.760 and a
p-value of 0.800 with an accuracy of 0.787, sensitivity of 0.870, and specificity of 0.655. The support vector machine (SVM) results were similarly quite good: an F-score of 0.838, a
p-value of 0.761, a sensitivity of 0.935, and a specificity of 0.534. Regarding accuracy and F-scores, k-nearest neighbors (KNN) and decision tree (DT) were less effective than RF, LR, and SVM. Stochastic Gradient Descent (SGD) performed the worst in accuracy, sensitivity, and F-score compared to other classifiers. These findings indicate that RF, LR, and SVM are superior to KNN and DT when predicting diabetes from the provided information.
After applying feature selection, the classification outcomes for a diabetes dataset are presented in
Table 10.
p-values, F-scores, degrees of precision, and specificity are all reported. Stochastic Gradient Descent (SGD), Decision Trees (DT), K-Nearest Neighbors (KNN), Gaussian Naive Bayes (GNB), Support Vector Machines (SVM), Logistic Regression (LR), and Random Forest (RF) were all employed as classification methods. A small
p-value (0.588) indicates that the features used to train the SGD classifier are not very predictive of the outcome. Moderate F-score and accuracy (0.657) are accompanied by high sensitivity (0.909) and specificity (0.432) but low F-score (0.714) and accuracy (0.657). The
p-value for the DT classifier is somewhat higher (0.682) than the
p-value for SGD, but neither is statistically significant. Compared to SGD, the F-score and accuracy are better (0.779 and 0.73), although the sensitivity and specificity are the same (100). The KNN classifier’s greatest
p-value (0.769) indicates that the selected features are more important in predicting the outcome than any other classifiers. High levels of sensitivity (0.943) and specificity (0.545) are accompanied by a high F-score (0.847) and high levels of accuracy (0.791). The GNB classifier has a moderately low
p-value (0.806) and a high F-score (0.87) and accuracy (0.819). In contrast to the moderate specificity (0.6), the sensitivity is relatively high (0.943). With a
p-value of 0.857, SVM is the second most accurate classifier, suggesting that the features used to make the prediction are crucial. Very high sensitivity (0.909) and moderate specificity (0.762) are accompanied by a high F-score (0.882) and high accuracy (0.852). High
p-value (0.851), high F-score (0.889), and high accuracy (0.853) are all features of the LR classifier. Although the specificity is at 0.72, the sensitivity is very high at 0.93. Last but not least, the RF classifier excels in all three metrics studied here: F-score (0.909), accuracy (0.885), and sensitivity (0.909). The sensitivity (0.842) and the specificity (0.909) are pretty good. In conclusion, the KNN and RF classifiers achieved the highest F-scores, accuracy, sensitivity, and specificity following feature selection. It is important to highlight that the classifier selection is problem- and data-specific and that additional investigation may be required to identify the optimal model.
The analysis presented in
Table 11 provides multiple statistical indicators of diabetes categorization model performance. There is valuable insight to be gleaned from each metric concerning the precision and consistency of the model’s predictions. According to the first metric, “Number of values”, there were ten occurrences across all seven categories. Although their precise meanings aren’t specified, we can infer that they correspond to different aspects of the model’s performance or the data used to train and evaluate it. Both the minimum and maximum values for a given category are indicated by the respective “Minimum” and “Maximum” indicators. For instance, the first group ranges from 0.986 to 0.992 for its values. Outliers can be found, and the range of values for each category is determined with these metrics. In order to determine how far any number can go, we can use the “Range” metric. There was a wide disparity between the highest and lowest values, as seen by the range of 0.030 in the fifth group. Data on the distribution of values within each category is made available through the “Percentile” measurements. For example, the “Median” value divides the data in half, while the “25% Percentile” reflects the number below which 25% of the data falls. The “75% Percentile” indicates the figure below which 75% of the data falls. These metrics can help show where the data is most and least concentrated and whether or not it is biased. Similar information is provided by the “10% Percentile” and “90% Percentile” measures, but for the 10th and 90th percentiles of the data, instead of the median and interquartile ranges. Information about the results’ reliability is provided by using the “Actual confidence level”, “Lower confidence limit”, and “Upper confidence limit” metrics.
These estimates are based on a confidence interval, a range of numbers thought to contain the actual value of the population parameter under study. With a confidence level of 97.85%, the actual number is likely inside the estimated margin of error. Indicators of central tendency, dispersion, and variability in data are provided by the “Mean”, “Std. Deviation”, “Std. Error of Mean”, and “Coefficient of Variation” measurements. The mean is the value that is most often encountered, whereas the standard deviation and standard error of the mean tell us about the variation in the data and the precision with which we may estimate the mean. The coefficient of variation is a measure of variability independent of measurement units and can be used to assess similarities and differences in data distribution across distinct groups. If the data is highly skewed, “Geometric Mean” measure can be used as an alternate central tendency measure. The “Geometric SD Factor” measures the dispersion of the data. At the same time, the “Lower 95% CI of geo. means” and “Upper 95% CI of geo. mean” give the minimum and maximum values of the 95% confidence interval for the geometric mean, respectively. The “Harmonic Mean” measures offer a different kind of central tendency metric that might be helpful when working with severely skewed data. Lower and upper limits of the 95% confidence interval for the harmonic mean are provided under the headings “Lower 95% CI of harm. mean” and “Upper 95% CI of harm. mean”, respectively. In cases where the data is highly skewed, the “Quadratic Mean” measurements provide yet another alternative central tendency measure. The lower and upper bounds of the 95% confidence interval for the quadratic mean are provided by the “Lower 95% CI of the quad. mean” and “Upper 95% CI of the quad. mean” headings, respectively.
One way to compare and contrast many groups or treatments is via an analysis of variance (ANOVA) test, which is presented in
Table 12. The primary sections of the ANOVA table are labeled “Treatment”, “Residual”, and “Total”, respectively. The term “treatment” describes the differences in means between the various groups. The term “residual” is used to describe the ambiguous variation or inaccuracy that exists among the groups. What we mean by “total” here is the sum of the squares of all the observations or the entire amount of variability. The following is a breakdown of the metrics in each component of the ANOVA table:
Treatment = ( 0.02327 and 6 and 0.003878 and F (6, 63) = 211.8 and p < 0.0001):
SS (sum of squares) = 0.02327, representing the treatment groups’ variability;
DF (degrees of freedom) = 6, representing the number of groups being compared minus one;
MS (mean square) = 0.003878, representing the treatment group variance;
F (DFn, DFd) = 211.8, representing the F-statistic or the variance ratio between the treatment groups to the variance within the treatment groups;
p-value < 0.0001 represents the probability of observing such an extreme F-statistic or more powerful under the null hypothesis that no difference exists between the treatment groups.
Residual = ( 0.00115 and 63 and 0.000018):
SS = 0.00115 represents the unexplained variability or error within the groups;
DF = 63, representing the total number of observations minus the number of groups being compared;
MS = 0.000018, representing the treatment group variance.
Total = ( 0.02442 and 69):
SS = 0.02442 represents the total variability or sum of squares of all the observations;
DF = 69, representing the total number of observations minus one.
With an F-statistic of 211.8 and a p-value of 0.0001, the variance analysis shows a statistically significant difference between the treatment groups. The ANOVA table’s Treatment column indicates more variation between treatment groups than within them. In contrast, the Residual column suggests some variation or error within the groups that cannot be accounted for by the other two columns.
The Wilcoxon signed-rank test is a useful non-parametric option when comparing two groups with some features. The evaluation in this scenario aims to assess the relative merits of several machine learning approaches as presented in
Table 13. If there is no difference between the two approaches, then the theoretical median is a vector of zeros. The empirical median equals the mean of the performance gaps between the various approaches and the theoretical median. Values equal the total number of test observations. In this scenario, there are 10 data points for each approach under consideration. Differences between the true and theoretical median can be quantified by adding up the signed rankings (W). When the rank is higher than zero, the real median exceeds the theoretical median; when the rank is lower than zero, the actual median falls short of the theoretical median. Considering that 55 is the sum of positive and negative ranks, we may conclude that all deviations from the theoretical median are positive. A test’s statistical significance is shown by its
p-value. Evidence exists to reject the null hypothesis if the
p-value is smaller than the significance level (alpha). All of the
p-values shown are smaller than 0.05, indicating that there is indeed a statistically significant difference between the two approaches. The
p-values are determined precisely, rather than being approximated, thanks to the accurate nature of the test. Positive signed ranks and a smaller difference between the actual and theoretical medians show that the proposed approach (DBERDTO + RF) outperforms the other methods by a wide margin.
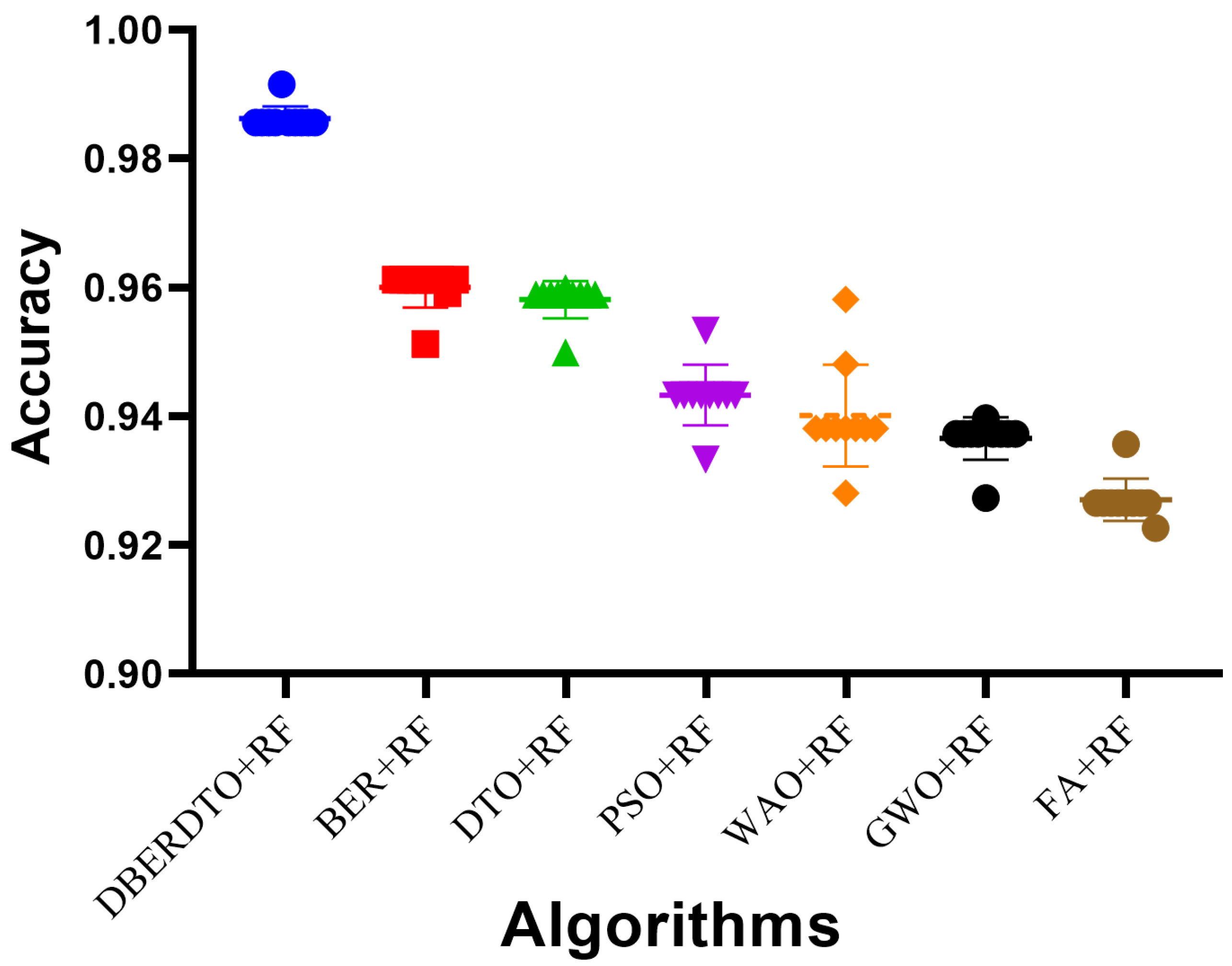
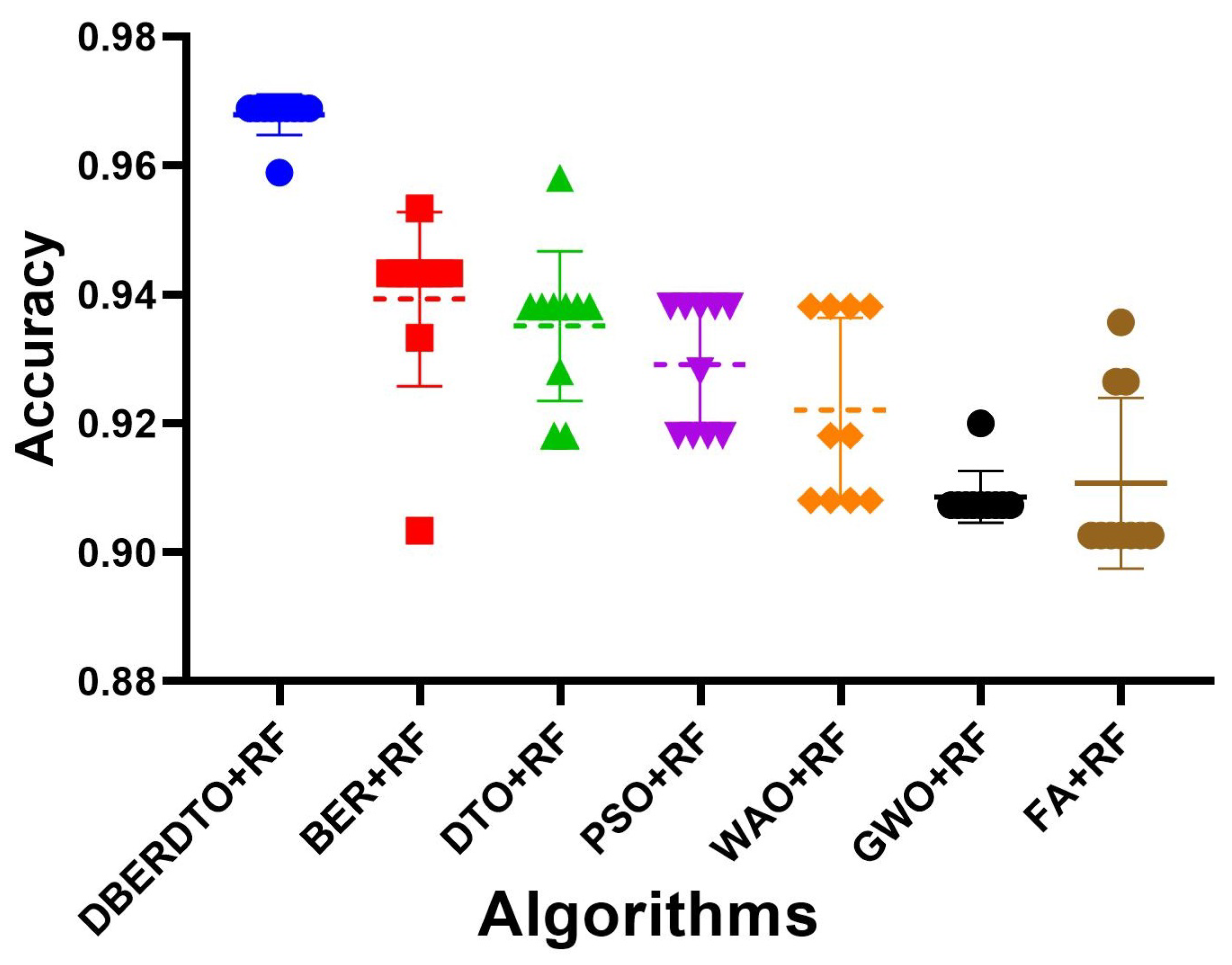
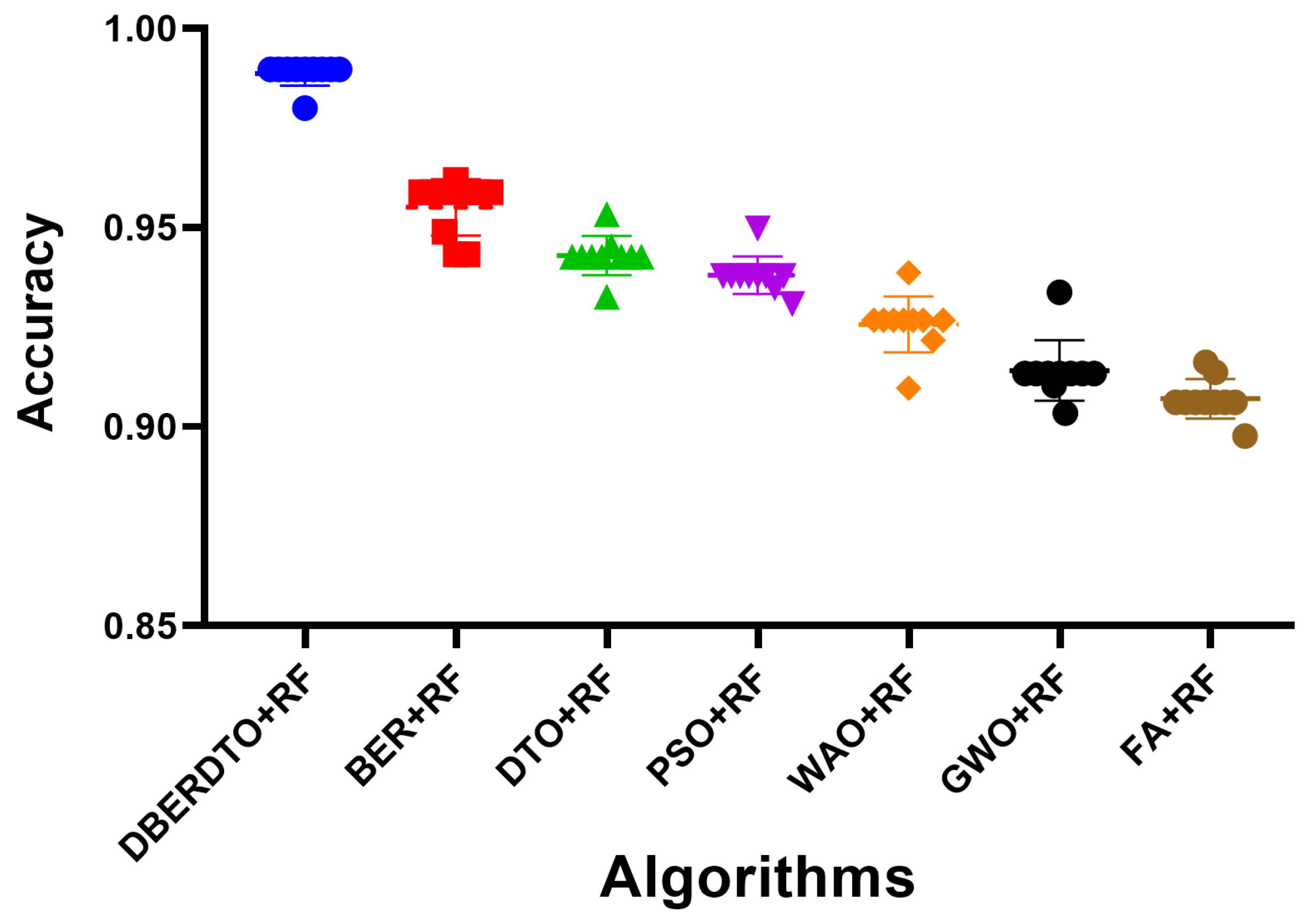
The plot shown in
Figure 6 comparing the classification accuracy attained by several strategies for diabetes case classification reveals that the proposed DBERDTO + RF strategy delivers the maximum accuracy. In addition to BER + RF, DTO + RF, PSO + RF, WOA + RF, GWO + RF, and FA + RF, we plotted these and other categorization approaches to see how they stacked up. The scatter plot shows that the proposed technique is very good at correctly categorizing instances of diabetes. Classification accuracy was still rather good for the remaining approaches, indicating that they had merit in their own right. Although the offered solution is not the only viable option, it is the most advantageous in this scenario. As correct diabetes case classification is crucial for both diagnosis and treatment, these findings have substantial implications for medical professionals. To get even better results than with other standard classification approaches, users can try the DBERDTO + RF strategy. The high accuracy of the proposed method has the potential to improve the diagnosis and treatment of diabetes, which in turn will enhance the lives of those who suffer from the disease.
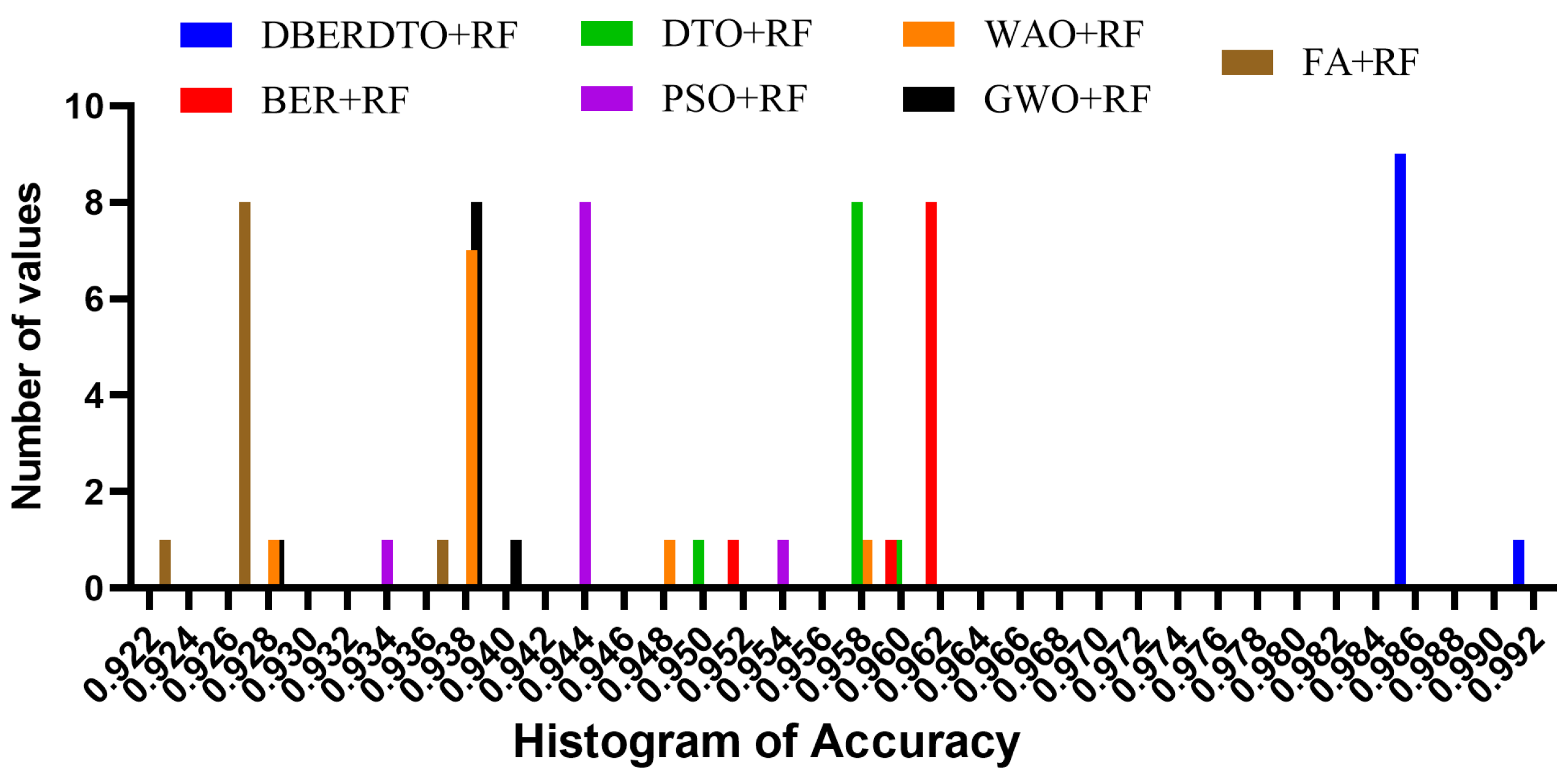
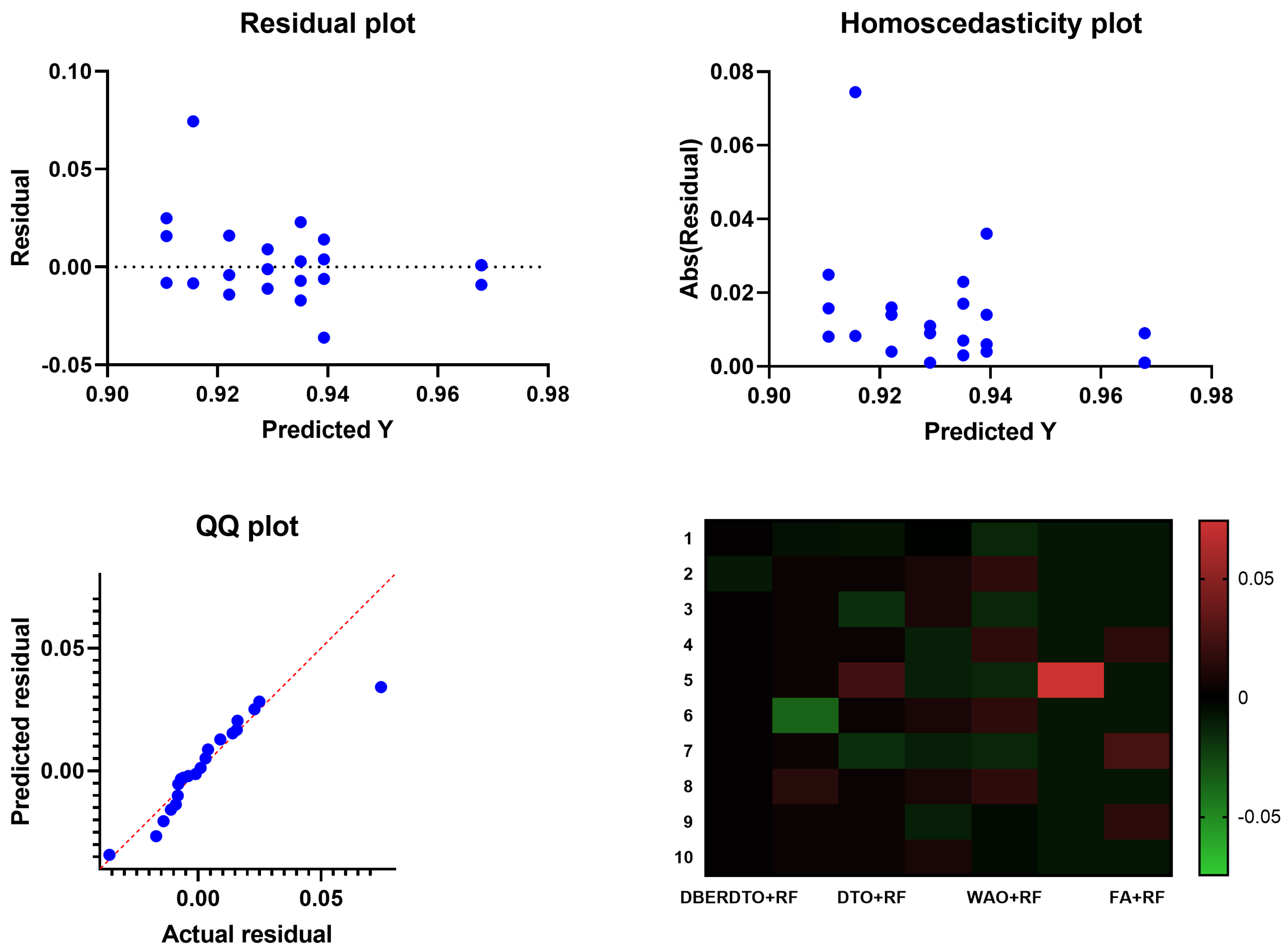
As shown in
Figure 7, the proposed DBERDTO + RF strategy achieves the highest accuracy compared to other methods in a histogram plot, comparing the classification accuracy attained by various approaches in classifying diabetes cases. Each method’s classification accuracy is displayed as a histogram, with the height of each bar indicating the frequency with which that accuracy number was obtained. The histogram shows that the most frequent accuracy values are concentrated at the maximum accuracy attained by the DBERDTO + RF method, confirming the superiority of the suggested method. This visualization helps practitioners select the most efficient way for their specific use case and further demonstrates the proposed strategy’s superiority in accurately identifying diabetes patients. On the other hand, the plots shown in
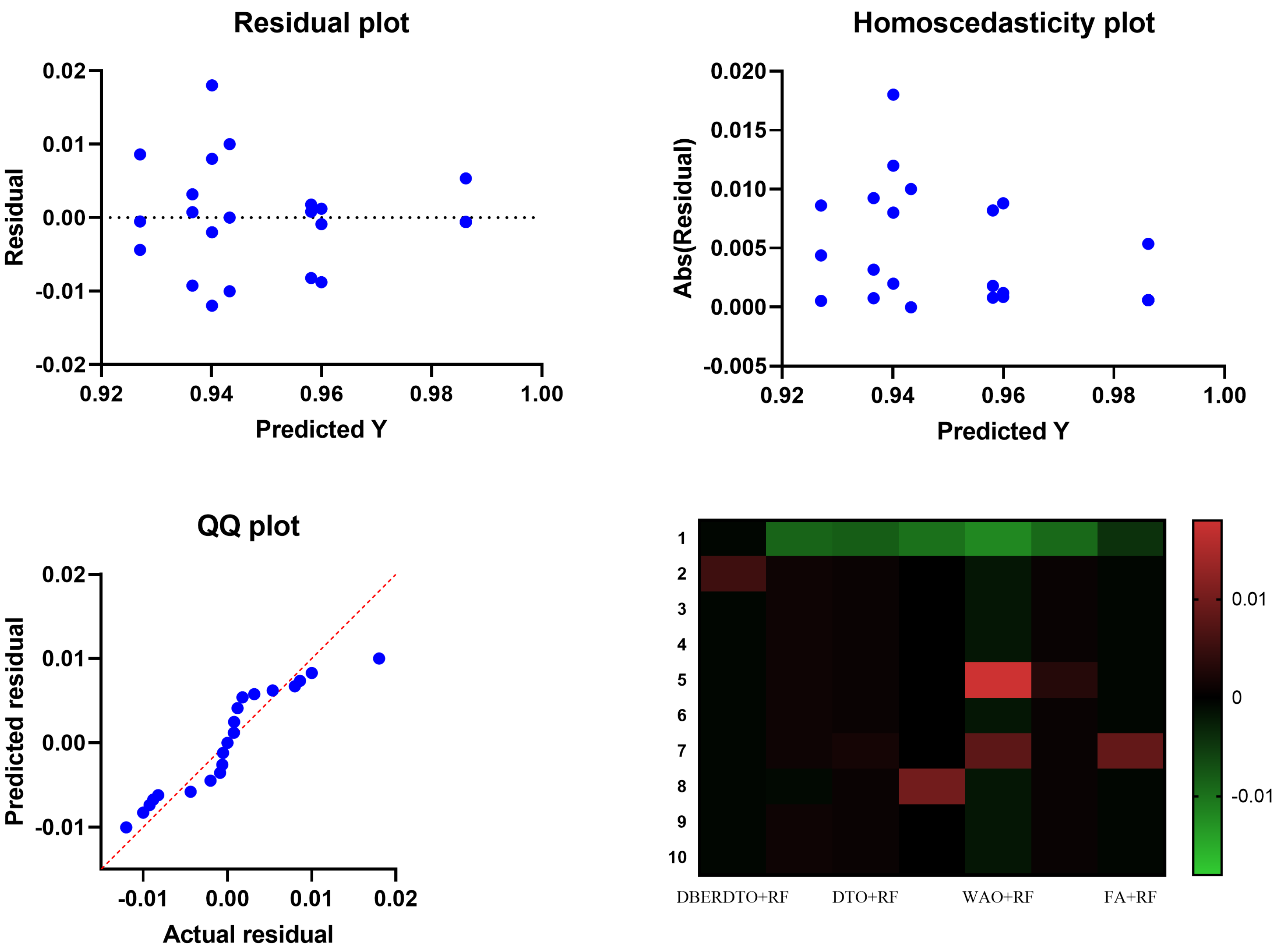
Figure 8 show the significance of the proposed approach in classifying diabetes cases compared to the other methods.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













