
Early Diagnosis and Classification of Fetal Health Status from a Fetal Cardiotocography Dataset Using Ensemble Learning


Abstract
:1. Introduction
- We utilize class weighting as a preprocessing step to avoid overfitting during the model training process.
- We propose an ensemble learning (EL) model that benefits from the use of ensembles, which can improve the average prediction performance over that of any contributing member in the ensemble.
- We propose a new multiclass fetal health classification.
- Our scheme obtains higher accuracy than others in the literature.
2. Materials and Methods
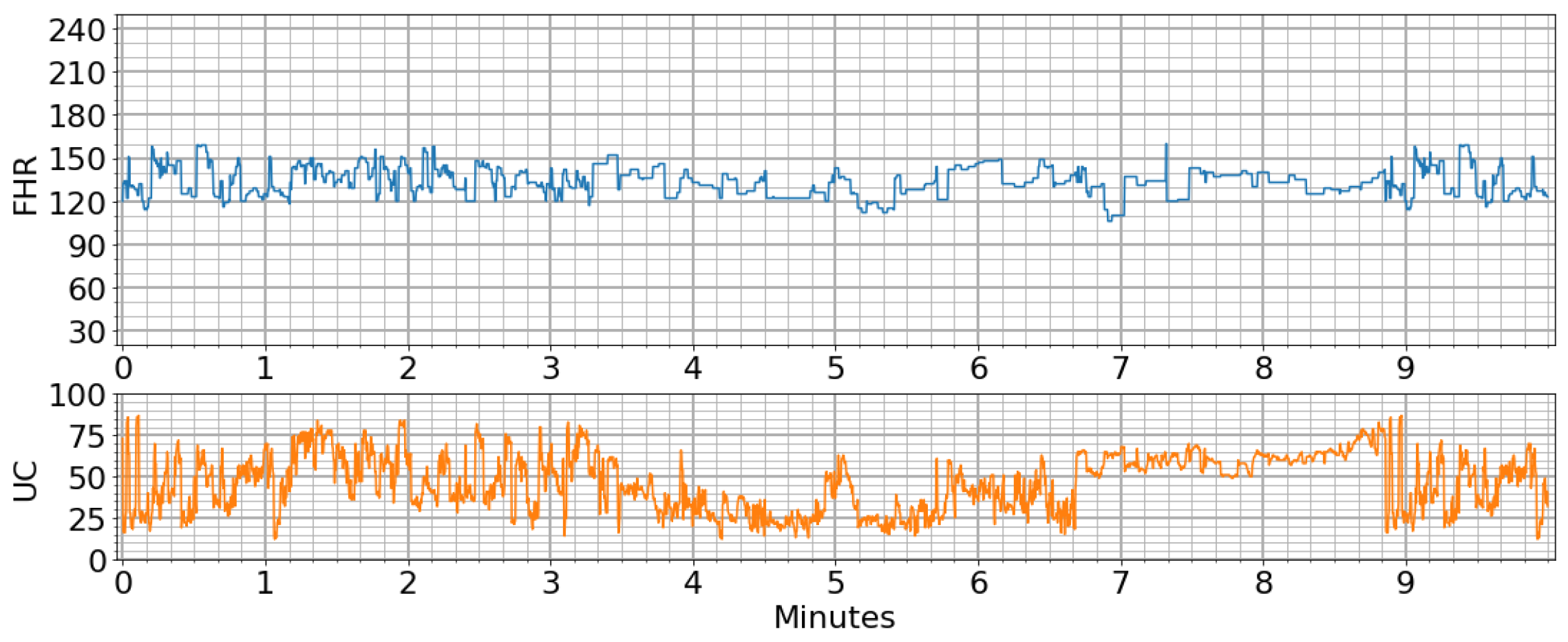
2.1. Dataset
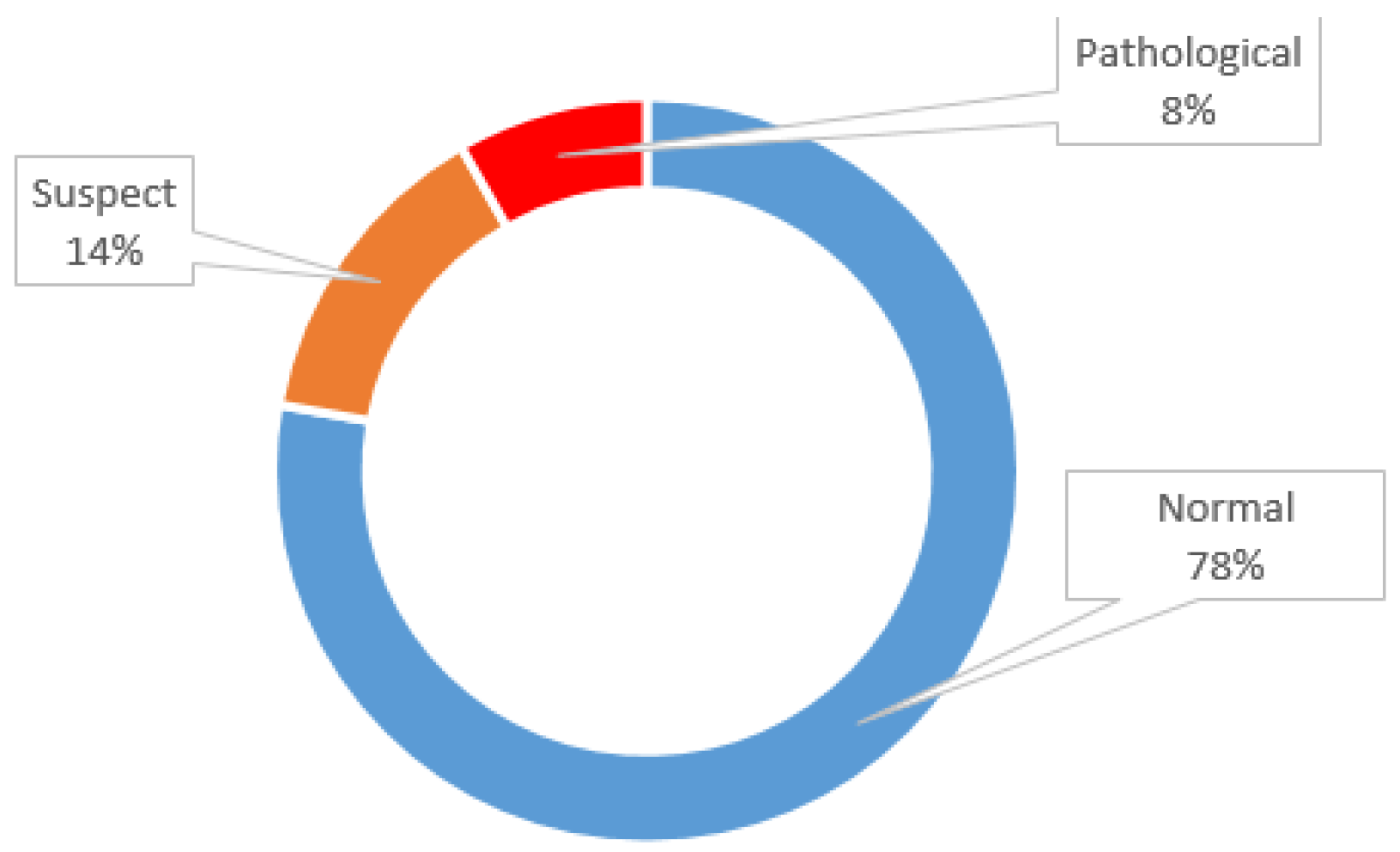
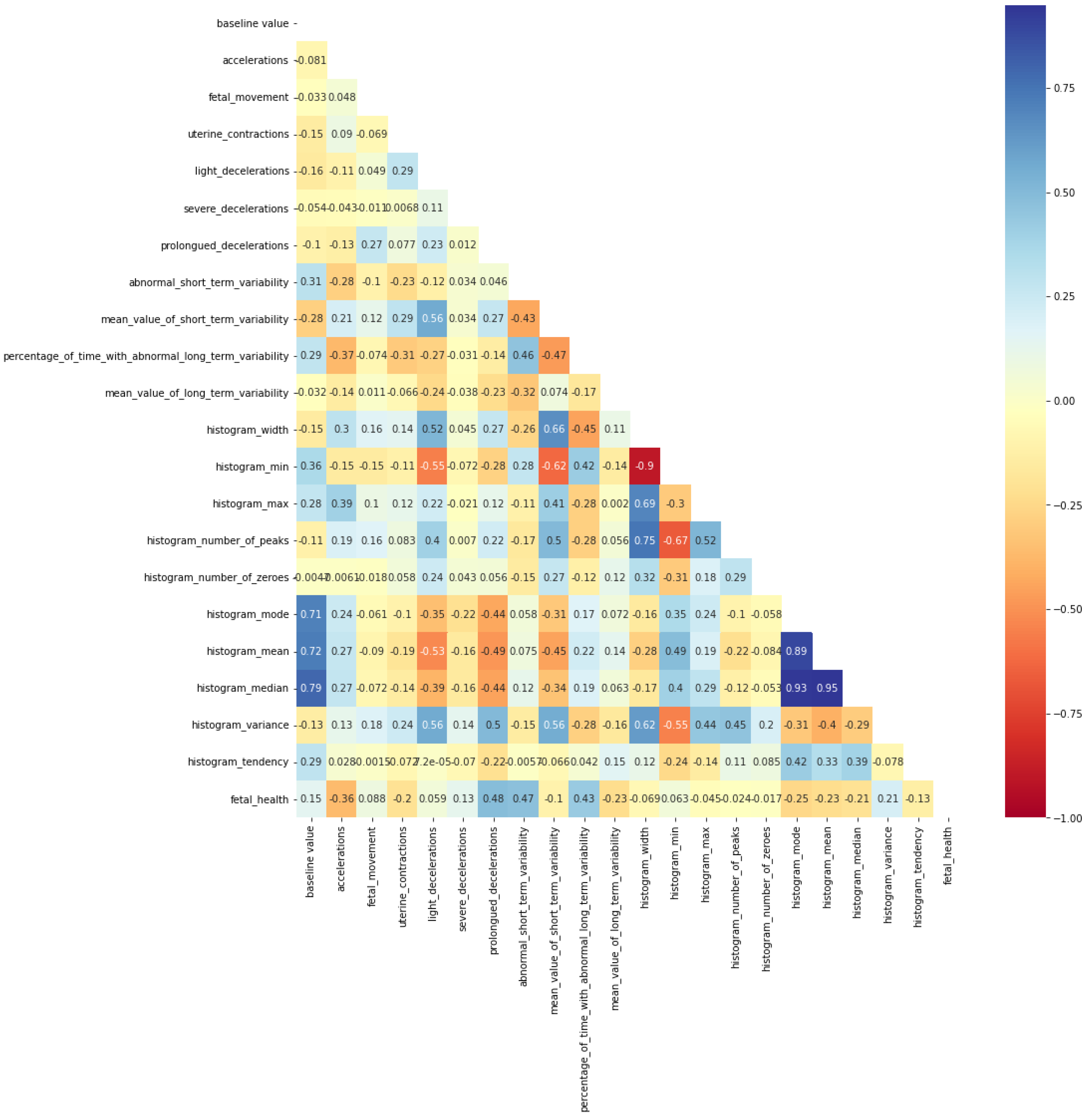
2.2. Exploratory Dataset
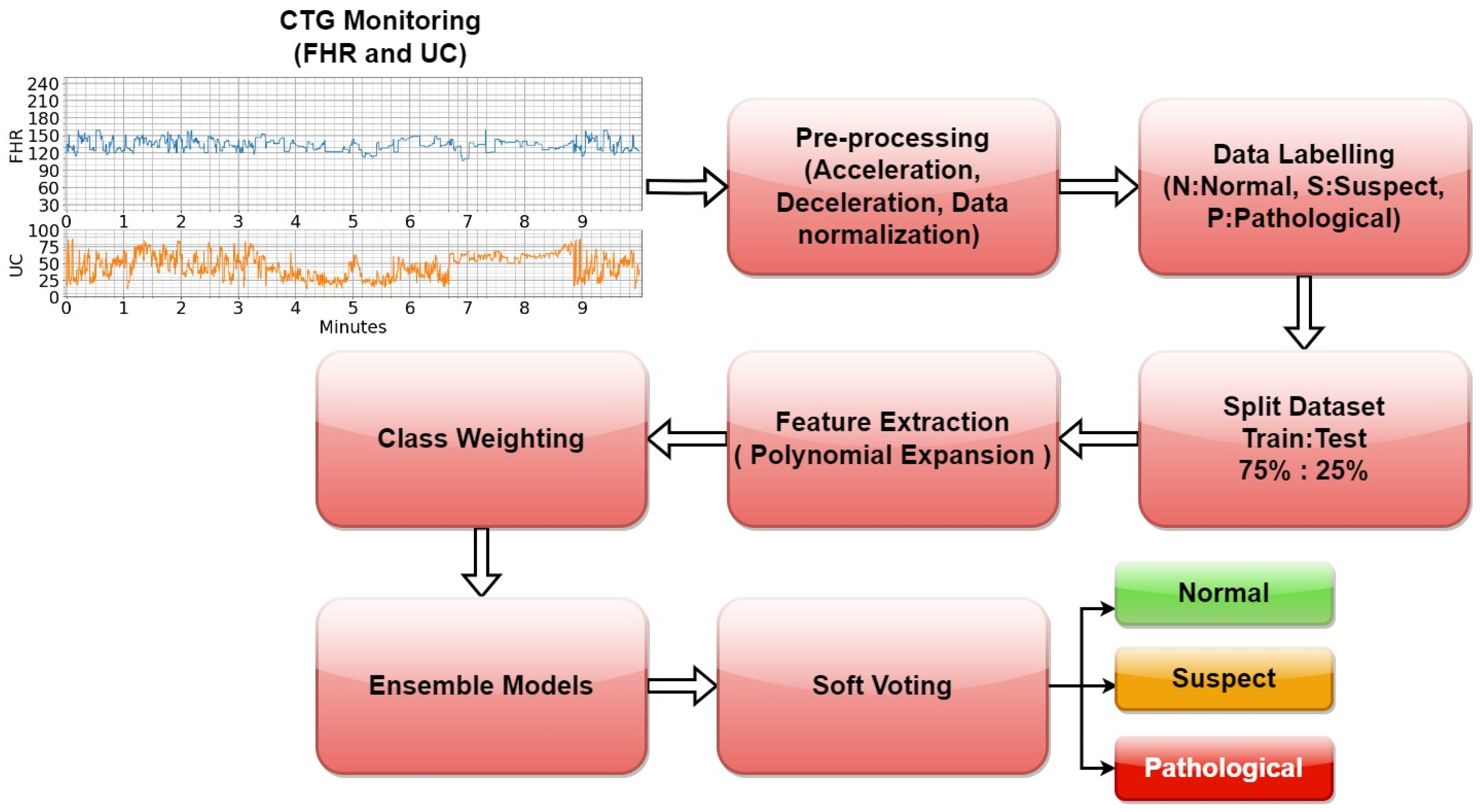
2.3. Proposed Method
2.4. Data Processing
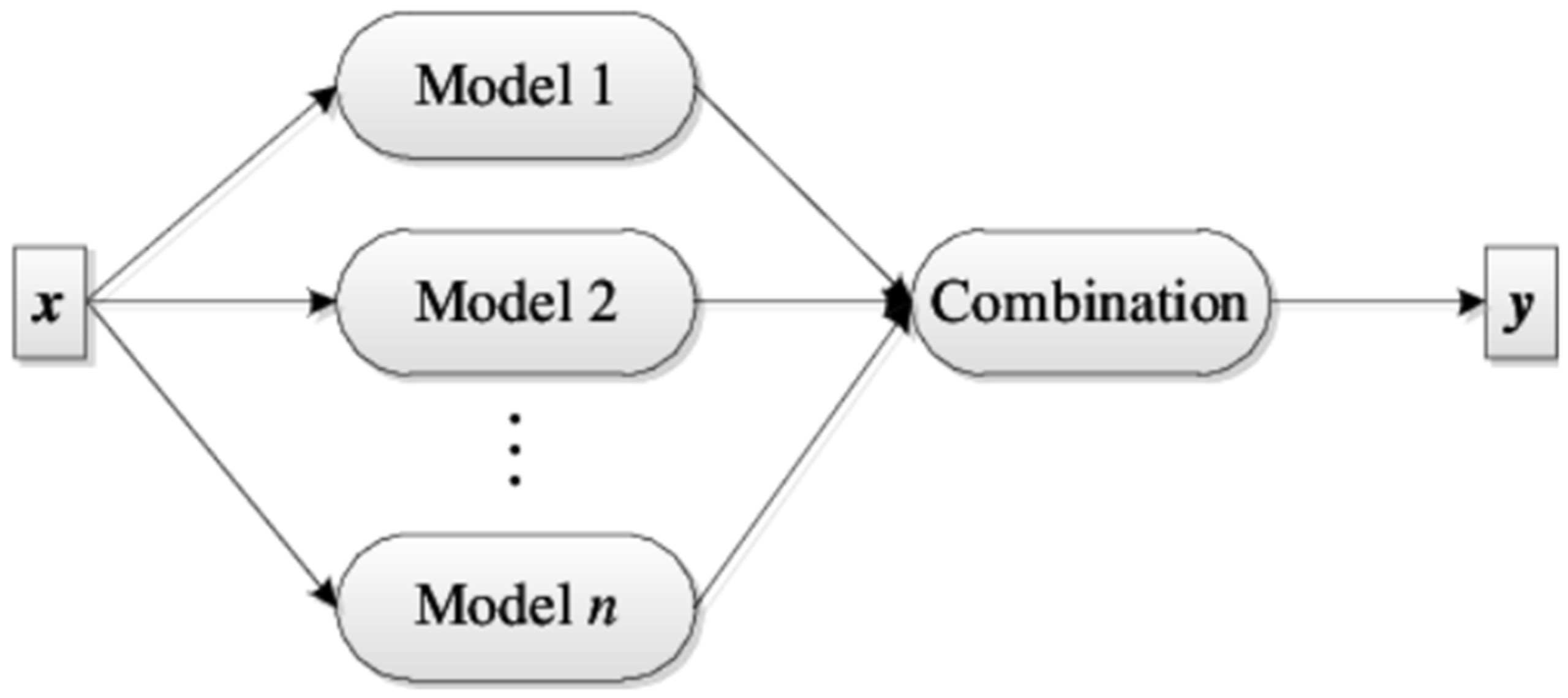
2.5. Ensemble Learning (EL)
2.5.1. LR
2.5.2. RF
2.5.3. Gradient Boosting (GB)
2.5.4. XGBoost
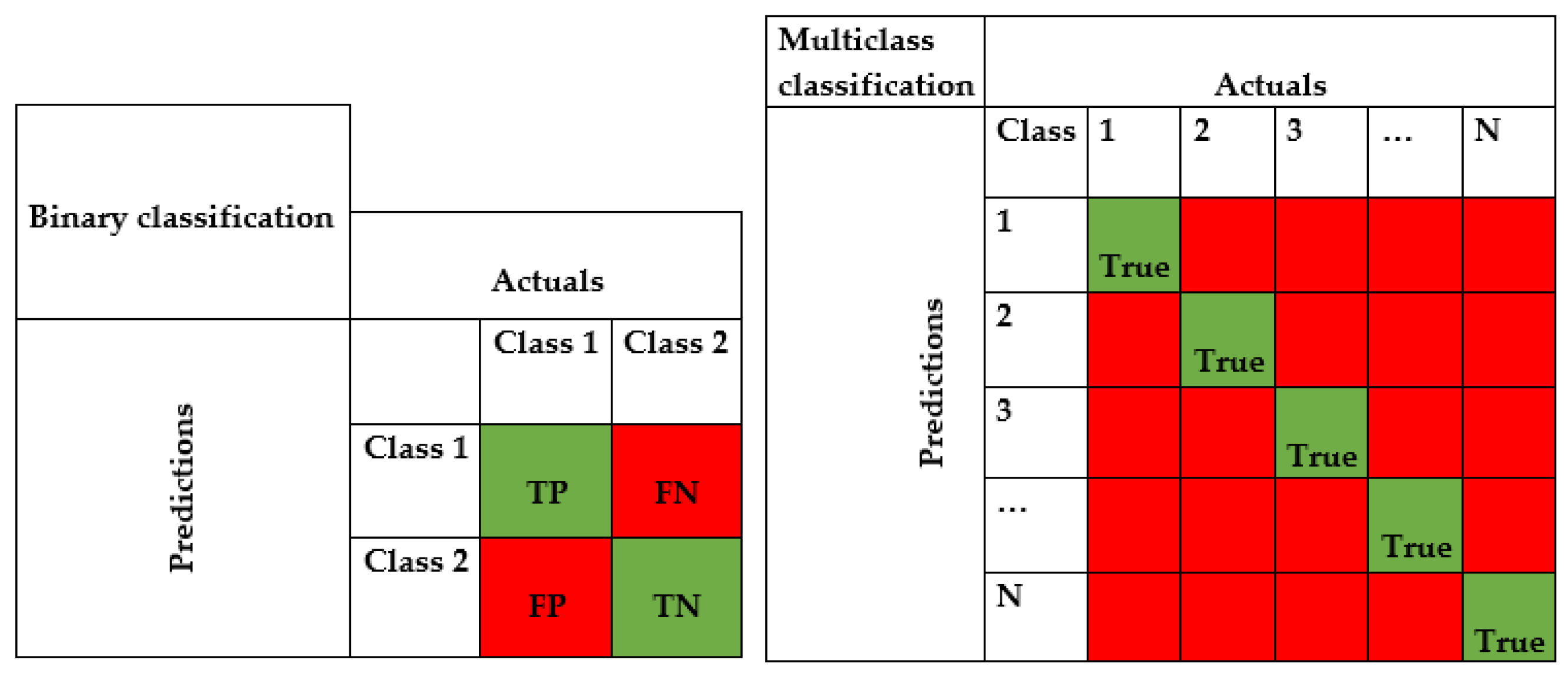
2.6. Model Evaluation
2.7. Weighted Majority Voting
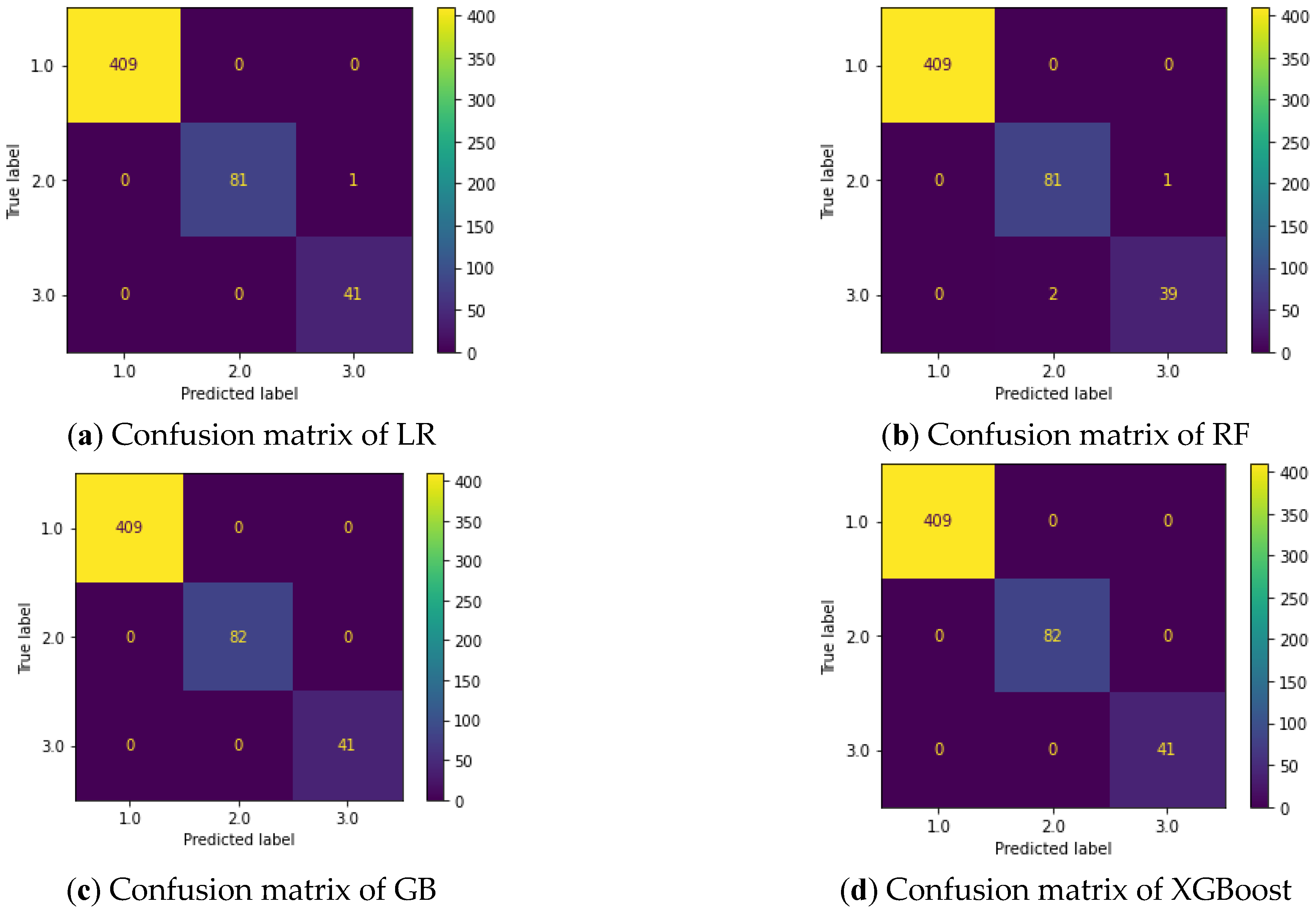
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huntley, B.J.; Huntley, E.S.; Di Mascio, D.; Chen, T.; Berghella, V.; Chauhan, S.P. Rates of maternal and perinatal mortality and vertical transmission in pregnancies complicated by severe acute respiratory syndrome coronavirus 2 (SARS-Co-V-2) infection: A systematic review. Obstet. Gynecol. 2020, 136, 303–312. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. 2022. Available online: http://whqlibdoc.who.int/publications/2006/9241563206_eng.pdf (accessed on 1 December 2022).
- Li, S.F.; Zhao, Y.Y.; Li, G.F.; Wang, N.; Zhang, S.; Chen, L.; Wang, Y. Computerized analysis of fetal heart rate pattern in the third trimester of low-risk pregnancy by long-range electronic fetal monitoring. J. Matern.-Fetal Neonatal Med. 2021, 35, 5506–5512. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Zhu, Z.; Wang, C.; Zhang, F.; Zeng, H. Association between adverse perinatal outcomes and sleep disturbances during pregnancy: A systematic review and meta-analysis. J. Matern.-Fetal Neonatal Med. 2022, 35, 166–174. [Google Scholar] [CrossRef]
- Kucukali, G.K.; Keskin, M.; Erdeve, S.S.; Cetinkaya, S. Perinatal outcomes of high-dose vitamin D administration in the last trimester. Turk. J. Obstet. Gynecol. 2021, 18, 159–163. [Google Scholar] [CrossRef]
- Bafor, E.E.; Kalu, C.H.; Omoruyi, O.; Elvis-Offiah, U.B.; Edrada-Ebel, R. Thyme (Thymus vulgaris [Lamiaceae]) Leaves Inhibit Contraction of the Nonpregnant Mouse Uterus. J. Med. Food 2021, 24, 541–550. [Google Scholar] [CrossRef]
- Jia, Y.J.; Chen, X.; Cui, H.Y.; Whelehan, V.; Archer, A.; Chandraharan. Physiological CTG interpretation: The significance of baseline fetal heart rate changes after the onset of decelerations and associated perinatal outcomes. J. Matern.-Fetal Neonatal Med. 2021, 34, 2349–2354. [Google Scholar] [CrossRef]
- Singh, S.; Pai, S.; Sahu, B. Study of umbilical coiling index and perinatal outcome. Int. J. Reprod. Contracept. Obstet. Gynecol. 2020, 9, 3977–3983. [Google Scholar] [CrossRef]
- Subasi, A.; Kadasa, B.; Kremic, E. Classification of the cardiotocograph data for anticipation of fetal risks using bagging ensemble classifier. Procedia Comput. Sci. 2020, 168, 34–39. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Oprescu, A.M.; Miro-Amarante, G.; García-Díaz, L.; Beltrán, L.M.; Rey, V.E.; Romero-Ternero, M. Artificial intelligence in pregnancy: A scoping review. IEEE Access 2020, 8, 181450–181484. [Google Scholar] [CrossRef]
- Santur, Y.; Santur, S.G.; Karaköse, M. Architecture and implementation of a smart-pregnancy monitoring system using web-based application. Expert Syst. 2020, 37, e12379. [Google Scholar] [CrossRef]
- Chavez-Badiola, A.; Farias, A.F.S.; Mendizabal-Ruiz, G.; Garcia-Sanchez, R.; Drakeley, A.J.; Garcia-Sandoval, J.P. Predicting pregnancy test results after embryo transfer by image feature extraction and analysis using machine learning. Sci. Rep. 2020, 10, 4394. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, K.; Balyan, K.; Lamba, B.; Puri, M.; Sengupta, D.; Kumar, M. Ultrasound placental image texture analysis using artificial intelligence to predict hypertension in pregnancy. J. Matern.-Fetal Neonatal Med. 2021, 35, 5587–5594. [Google Scholar] [CrossRef]
- Maduwantha, M.C.; Vithana, V.N. “MumCare”: An Artificial Intelligence Based Assistant. Int. J. Electr. Comput. Eng. Res. 2021, 1, 21–28. [Google Scholar] [CrossRef]
- Dansharif, A.R.; Iyawa, G.E.; Owoseni, A.; Iyawa, R. mHealth for Self-Management in Pregnancy: Perceptions of Women in Low-Resource Settings. Procedia Comput. Sci. 2021, 181, 738–745. [Google Scholar] [CrossRef]
- Trolice, M.P.; Curchoe, C.; Quaas, A.M. Artificial intelligence—The future is now. J. Assist. Reprod. Genet. 2021, 38, 1607–1612. [Google Scholar] [CrossRef]
- UCI CTG Dataset. Available online: https://archive.ics.uci.edu/ml/datasets/cardiotocography (accessed on 1 July 2023).
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 July 2019. [Google Scholar]
- Zhou, K.; Yang, Y.; Qiao, Y.; Xiang, T. Domain adaptive ensemble learning. IEEE Trans. Image Process. 2021, 30, 8008–8018. [Google Scholar] [CrossRef] [PubMed]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons.: Hoboken, NJ, USA, 2021. [Google Scholar]
- Yeşilkanat, C.M. Spatio-temporal estimation of the daily cases of COVID-19 in worldwide using random forest machine learning algorithm. Chaos Solitons Fractals 2020, 140, 110210. [Google Scholar] [CrossRef]
- Qiu, Y.; Zhou, J.; Khandelwal, M.; Yang, H.; Yang, P.; Li, C. Performance evaluation of hybrid WOA-XGBoost, GWO-XGBoost and BO-XGBoost models to predict blast-induced ground vibration. Eng. Comput. 2021, 38, 4145–4162. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, Y.; Miao, D. Three-way confusion matrix for classification: A measure driven view. Inf. Sci. 2020, 507, 772–794. [Google Scholar] [CrossRef]
- Fasihi, M.; Nadimi-Shahraki, M.H.; Jannesari, A. A Shallow 1-D Convolution Neural Network for Fetal State Assessment Based on Cardiotocogram. SN Comput. Sci. 2021, 2, 287. [Google Scholar] [CrossRef]
- Piri, J.; Mohapatra, P.; Dey, R. Multi-objective Ant Lion Optimization Based Feature Retrieval Methodology for Investigation of Fetal Wellbeing. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021. [Google Scholar]
- Amin, B.; Salama, A.A.; El-Henawy, I.M.; Mahfouz, K.; Gafar, M.G. Intelligent Neutrosophic Diagnostic System for Cardiotocography Data. Comput. Intell. Neurosci. 2021, 2021, 6656770. [Google Scholar] [CrossRef]
- Kasım, Ö. Multi-Classification of Fetal Health Status Using Extreme Learning Machine. Icontech Int. J. 2021, 5, 62–70. [Google Scholar] [CrossRef]
- Bhowmik, P.; Bhowmik, P.C.; Ali, U.M.E.; Sohrawordi, M. Cardiotocography Data Analysis to Predict Fetal Health Risks with Tree-Based Ensemble Learning. Inf. Technol. Comput. Sci. 2021, 5, 30–40. [Google Scholar] [CrossRef]
- Haweel, M.T.; Zahran, O.; Abd El-Samie, F.E. Polynomial FLANN Classifier for Fetal Cardiotocography Monitoring. In Proceedings of the 2021 38th National Radio Science Conference (NRSC), Mansoura, Egypt, 18–21 May 2021. [Google Scholar]
- Fei, Y.; Huang, X.; Chen, Q.; Chen, J.; Li, L.; Hong, J.; Wei, H. Automatic Classification of Antepartum Cardiotocography Using Fuzzy Clustering and Adaptive Neuro-Fuzzy Inference System. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2021. [Google Scholar]
- Nandipati, S.C.R.; XinYing, C. Classification and Feature Selection Approaches for Cardiotocography by Machine Learning Techniques. J. Telecommun. Electron. Comput. Eng. (JTEC) 2020, 12, 7–14. [Google Scholar]
- John, M.; Shaiba, H. Ensemble based foetal state diagnosis. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020. [Google Scholar]
- Piri, J.; Mohapatra, P.; Dey, R. Fetal Health Status Classification Using MOGA-CD Based Feature Selection Approach. In Proceedings of the 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020. [Google Scholar]
- Chen, J.Y.; Liu, X.C.; Wei, H.; Chen, Q.Q.; Hong, J.M.; Li, Q.N.; Hao, Z.F. Imbalanced Cardiotocography Multi-classification for Antenatal Fetal Monitoring Using Weighted Random Forest. In Proceedings of the International Conference on Smart Health, Shenzhen, China, 1–2 July 2019. [Google Scholar]
- Sevani, N.; Hermawan, I.; Jatmiko, W. Feature Selection based on F-score for Enhancing CTG Data Classification. In Proceedings of the 2019 IEEE International Conference on Cybernetics and Computational Intelligence, Banda Aceh, Indonesia, 22–24 August 2019. [Google Scholar]
- Katuwal, R.; Suganthan, P.N. Stacked autoencoder based deep random vector functional link neural network for classification. Appl. Soft Comput. 2019, 85, 105854. [Google Scholar] [CrossRef] [Green Version]
- Vani, R. Weighted deep neural network based clinical decision support system for the determination of fetal health. Int. J. Recent Technol. Eng. 2019, 8, 8564–8569. [Google Scholar] [CrossRef]
- Iraji, M.S. Prediction of fetal state from the cardiotocogram recordings using neural network models. Artif. Intell. Med. 2019, 96, 33–44. [Google Scholar] [CrossRef]
- Uzun, A.; Kızıltas, C.E.; Yılmaz, E. Cardiotocography data set classification with extreme learning machine. In Proceedings of the International Conference on Advanced Technologies, Safranbolu, Turkey, 11–13 May 2018. [Google Scholar]
- Deressa, T.D.; Kadam, K. Prediction of fetal health state during pregnancy: A survey. Int. J. Comput. Sci. Trends Technol. 2018, 6, 29–36. [Google Scholar]
- Mehbodniya, A.; Lazar, A.J.P.; Webber, J.; Sharma, D.K.; Jayagopalan, S.; Singh, P.; Sengan, S. Fetal health classification from cardiotocographic data using machine learning. Expert Syst. 2022, 39, e12899. [Google Scholar] [CrossRef]
- Kaliappan, J.; Bagepalli, A.R.; Almal, S.; Mishra, R.; Hu, Y.C.; Srinivasan, K. Impact of Cross-Validation on Machine Learning Models for Early Detection of Intrauterine Fetal Demise. Diagnostics 2023, 13, 1692. [Google Scholar] [CrossRef] [PubMed]
- Shruthi, K.; Poornima, A.S. A Method for Predicting and Classifying Fetus Health Using Machine Learning. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 752–762. [Google Scholar]
- Paul, R.K.; Yeasin, M.; Kumar, P.; Kumar, P.; Balasubramanian, M.; Roy, H.S.; Gupta, A. Machine learning techniques for forecasting agricultural prices: A case of brinjal in Odisha, India. PLoS ONE 2022, 17, e0270553. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description and Unit | Mean | Std | Min | Max |
|---|---|---|---|---|---|
| Baseline value | Beats per minute | 133.3039 | 9.840844 | 106 | 160 |
| Accelerations | Accelerations per second | 0.003178 | 0.003866 | 0 | 0.019 |
| Fetal movement | Fetal movements per second | 0.009481 | 0.046666 | 0 | 0.481 |
| Uterine contractions | Uterine contractions per second | 0.004366 | 0.002946 | 0 | 0.015 |
| Light decelerations | Light decelerations per second | 0.001889 | 0.00296 | 0 | 0.015 |
| Severe decelerations | Severe decelerations per second | 3.29 × 10−6 | 5.73 × 10−5 | 0 | 0.001 |
| Prolonged decelerations | Prolonged decelerations per second | 0.000159 | 0.00059 | 0 | 0.005 |
| Abnormal short-term variability | percentage of time with abnormal short term variability | 46.99012 | 17.19281 | 12 | 87 |
| Mean value of short-term variability | Mean value of short term variability | 1.332785 | 0.883241 | 0.2 | 7 |
| % abnormal long-term variability | Percentage of time with abnormal long term variability | 9.84666 | 18.39688 | 0 | 91 |
| Mean value of long-term variability | Mean value of long term variability | 8.187629 | 5.628247 | 0 | 50.7 |
| Histogram width | Width of FHR histogram | 70.44591 | 38.95569 | 3 | 180 |
| Histogram min | Minimum of FHR histogram | 93.57949 | 29.56021 | 50 | 159 |
| Histogram max | Maximum of FHR histogram | 164.0254 | 17.94418 | 122 | 238 |
| Histogram number of peaks | Histogram peaks | 4.068203 | 2.949386 | 0 | 18 |
| Histogram number of zeroes | Histogram zeros | 0.323612 | 0.706059 | 0 | 10 |
| Histogram mode | Histogram mode | 137.452 | 16.38129 | 60 | 187 |
| Histogram mean | Histogram mean | 134.6105 | 15.5936 | 73 | 182 |
| Histogram median | Histogram median | 138.0903 | 14.46659 | 77 | 186 |
| Histogram variance | Histogram variance | 18.80809 | 28.97764 | 0 | 269 |
| Histogram tendency | Histogram tendency | 0.32032 | 0.610829 | −1 | 1 |
| Fetal health | Fetal state class (0: normal (N); 1: suspect (S); 2: pathological (P)) | - | - | 0 | 2 |
| Attribute | Acc | F1 | Recall | Precision | G-Mean |
|---|---|---|---|---|---|
| LR | 0.99 | 0.99 | 1 | 0.99 | 0.99 |
| RF | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| GB | 1 | 1 | 1 | 1 | 1 |
| XGBoost | 1 | 1 | 1 | 1 | 1 |
| Author and Reference Work | Year | Methods | Classification | Accuracy (%) |
|---|---|---|---|---|
| Fasihi et al. [25] | 2021 | GA, Rprop, PNN, EL, LS-SVM, SF, XGBoost, | Multiclass | 97.46 |
| Piri et al. [26] | 2021 | SVM, RF, DT, KNN | Multiclass | 95.00 |
| Amin et al. [27] | 2021 | IN-RNNs, RNNs, NNs, nearest neighbor, DT | Multiclass | 95.10 |
| Kasım [28] | 2021 | ELM | Multiclass | 99.29 |
| Bhowmik et al. [29] | 2021 | DT, RF, ET, DF, EL | Multiclass | 96.05 |
| Haweel et al. [30] | 2021 | PNN, KNN, SVM, DT, RF, NB, B&B Model, ANN, LNN | Multiclass | 99.30 |
| Fei at al. [31] | 2020 | FCM | Multiclass | 96.39 |
| Nandipati et al. [32] | 2020 | KNN, SVM, RF, NB, NN, B&B, feature selection approaches | Multiclass | 95.07 |
| John et al. [33] | 2020 | NB, RF, J48 (C4.5), stacking model | Binary class | 98.90 |
| Piri et al. [34] | 2020 | LR, SVM, KNN, XGBoost, DT, RF, GNB | Multi Class | 94.00 |
| Chen et al. [35] | 2019 | WRF, DT, RF, BP, SVM, KNN, opportunity | Multiclass | 99.76 |
| Sevani et al. [36] | 2019 | SVM | Binary class | 94.35 |
| Katuwal et al. [37] | 2019 | RVFL, ELM, AE | Multiclass | 99.32 |
| Vani [38] | 2019 | SVM, RNN, NN, DT, KNN | Multiclass | 94.00 |
| Iraji [39] | 2019 | NN, DSSAEs, deep-ANFIS | Multiclass | 99.50 |
| Uzun et al. [40] | 2018 | ELM | Multiclass | 99.18 |
| Deressa et al. [41] | 2018 | RF, GA, OBFA | Multiclass | 93.61 |
| Mehbodniya et al. [42] | 2022 | SVM, RF, MLP, KNN | Multiclass | 94.5 |
| Kaliappan et al. [43] | 2023 | GB | Multiclass | 99. |
| Shrutki et al. [44] | 2023 | RF, GA | Multiclass | 96.62 |
| Our method | RF, GB, XGBoost | Multiclass | >99.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuzu, A.; Santur, Y. Early Diagnosis and Classification of Fetal Health Status from a Fetal Cardiotocography Dataset Using Ensemble Learning. Diagnostics 2023, 13, 2471. https://doi.org/10.3390/diagnostics13152471
Kuzu A, Santur Y. Early Diagnosis and Classification of Fetal Health Status from a Fetal Cardiotocography Dataset Using Ensemble Learning. Diagnostics. 2023; 13(15):2471. https://doi.org/10.3390/diagnostics13152471
Chicago/Turabian StyleKuzu, Adem, and Yunus Santur. 2023. "Early Diagnosis and Classification of Fetal Health Status from a Fetal Cardiotocography Dataset Using Ensemble Learning" Diagnostics 13, no. 15: 2471. https://doi.org/10.3390/diagnostics13152471
APA StyleKuzu, A., & Santur, Y. (2023). Early Diagnosis and Classification of Fetal Health Status from a Fetal Cardiotocography Dataset Using Ensemble Learning. Diagnostics, 13(15), 2471. https://doi.org/10.3390/diagnostics13152471