
Auditory Brainstem Response Data Preprocessing Method for the Automatic Classification of Hearing Loss Patients
 , , , ,
, , , ,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Medical Data for Deep Learning
2.2. Auditory Brainstem Responses
2.3. Data Processing and Cleansing
2.4. ABR Data Preprocessing Process
Data Normalization and Preprocessing
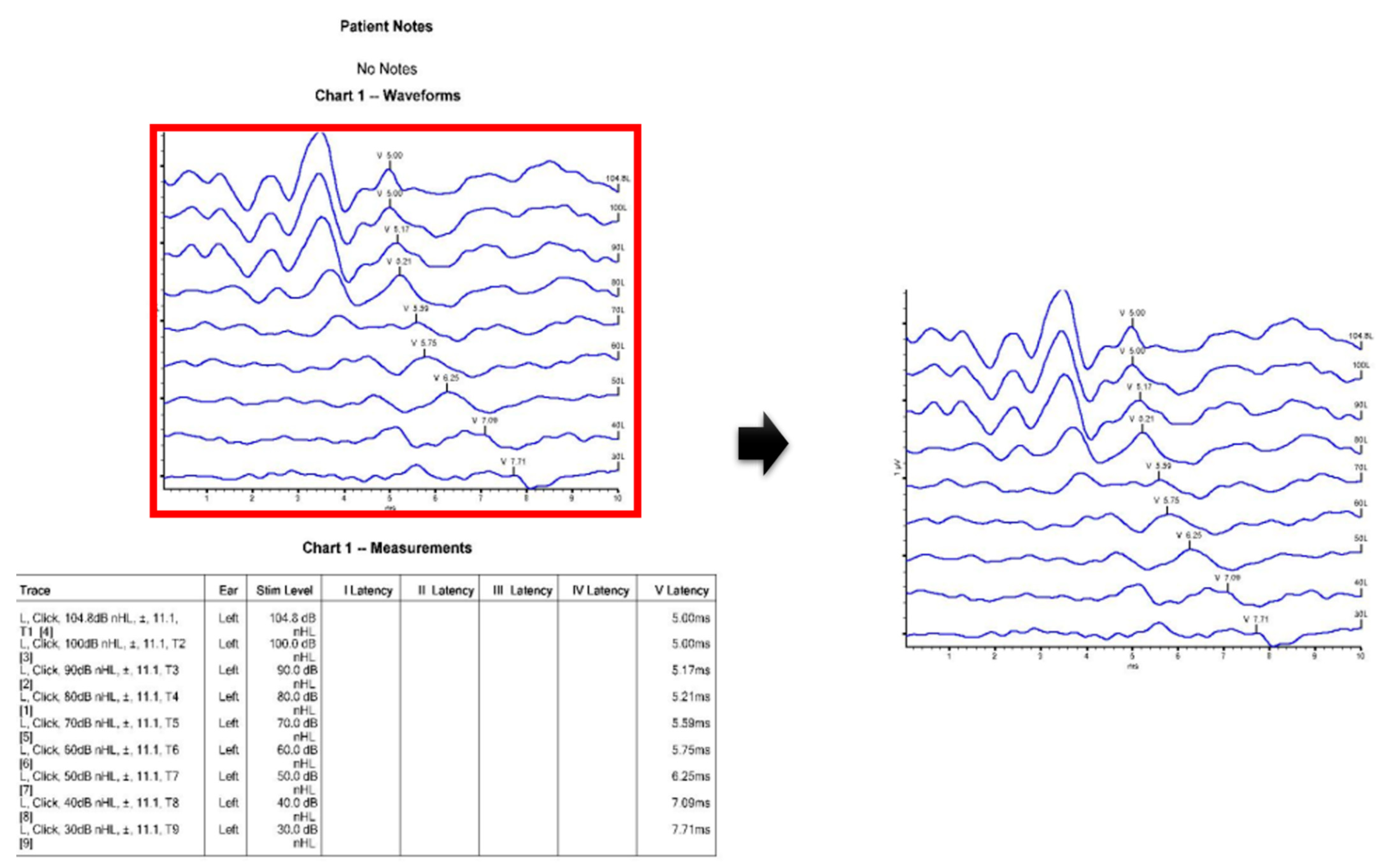
- Extraction of graph image
- 2.
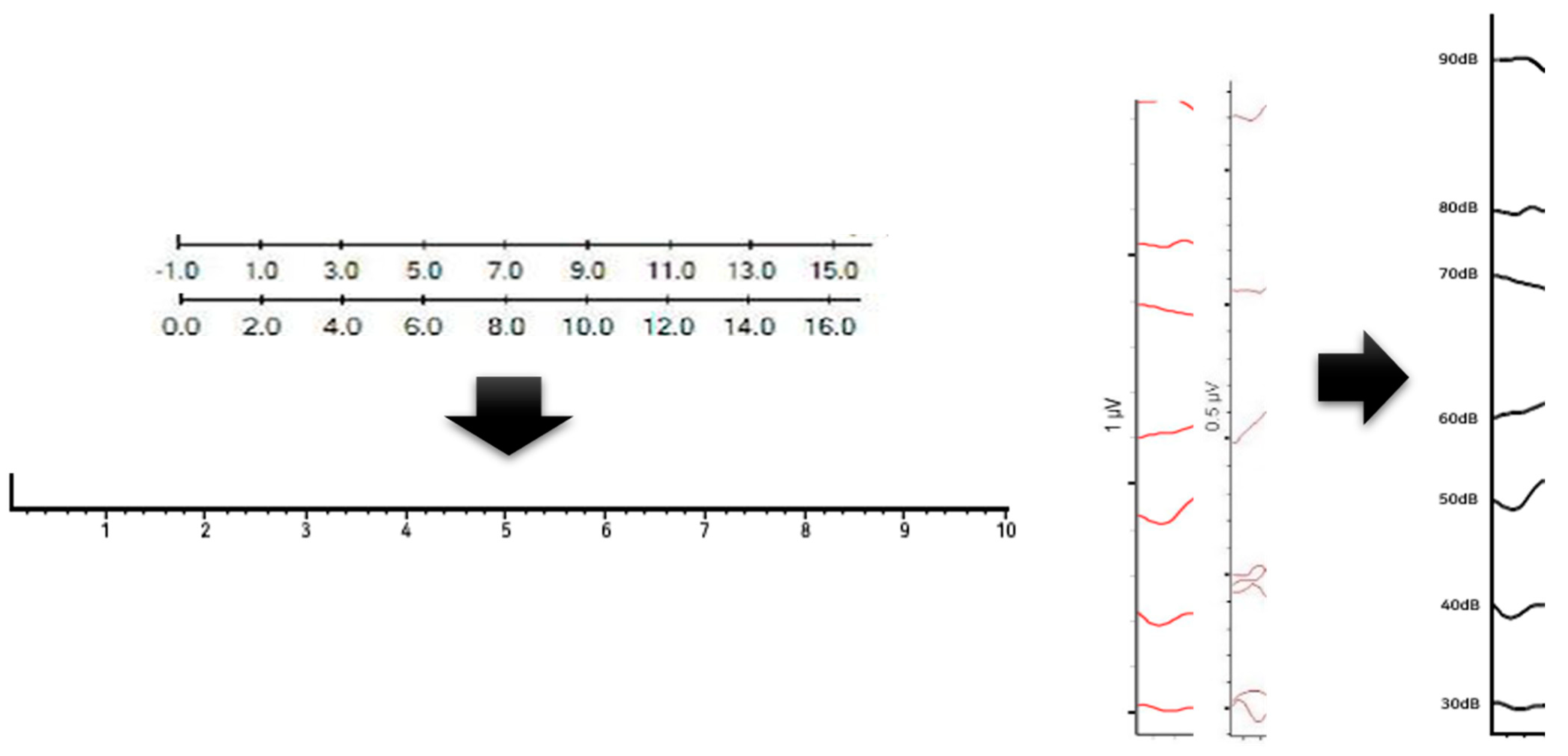
- Normalization of the X and Y axes of the graph
- 3.
- Conversion of image to gray-scale
- 4.
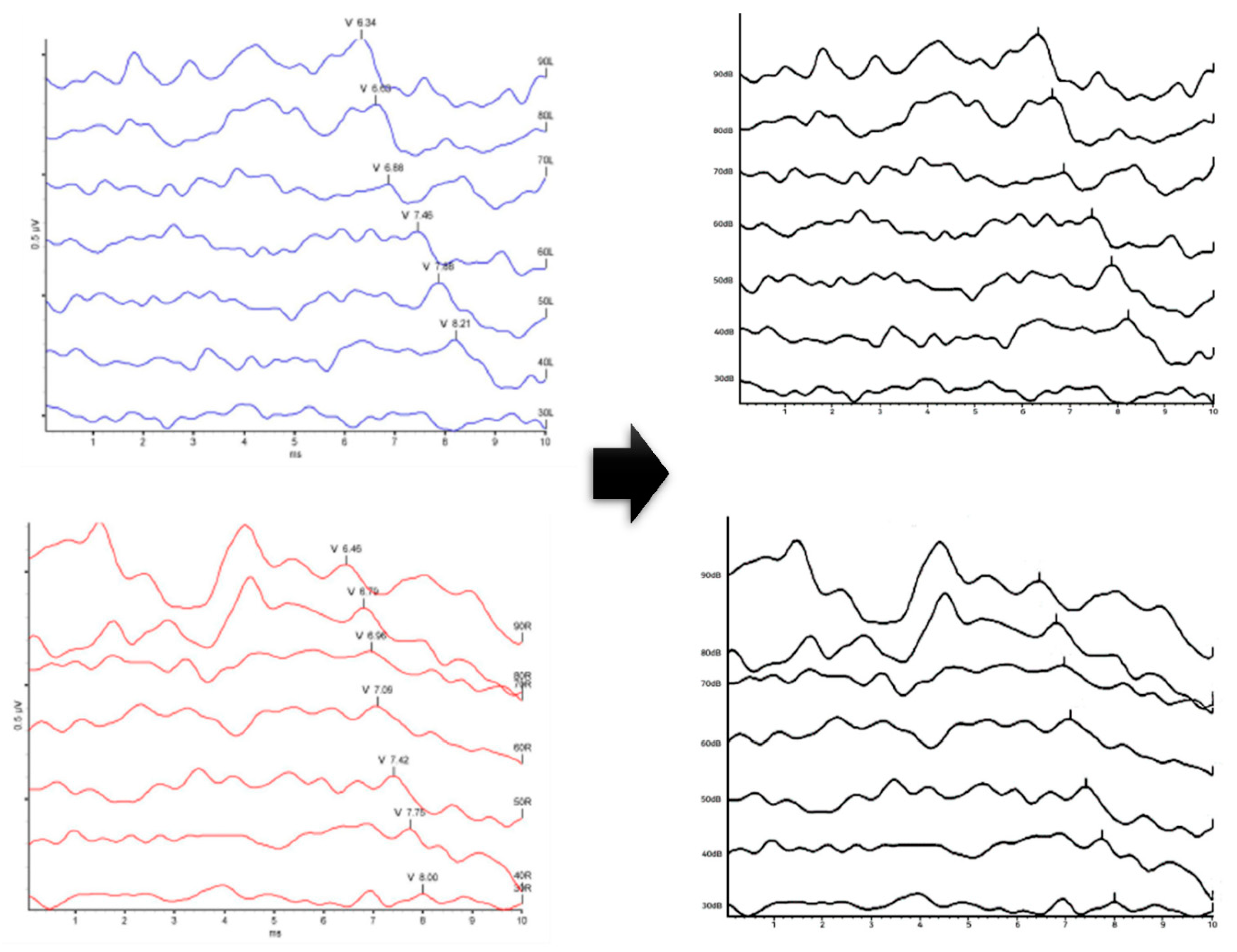
- Removing V Marks
- 5.
- Normalization of image size
2.5. VGG 16 Model
- Input layer: Basically, an image of size 224 × 224 is delivered to the convolution layer;
- Convolution layers: VGG16 has 13 convolution layers (conv 1–1~5–3). Each convolution layer consists of a small filter with a size of 3 × 3. Each filter is responsible for extracting features from the input image. After the convolutional layer, a rectified linear unit (ReLU) is used as the activation function;
- Pooling Layers: After each convolution layer, the max pooling layer is applied. Maximum pooling is responsible for reducing space by extracting only the largest values from each area;
2.6. Structure of the Proposed VGG16 Model by Tuning Hyperparameter
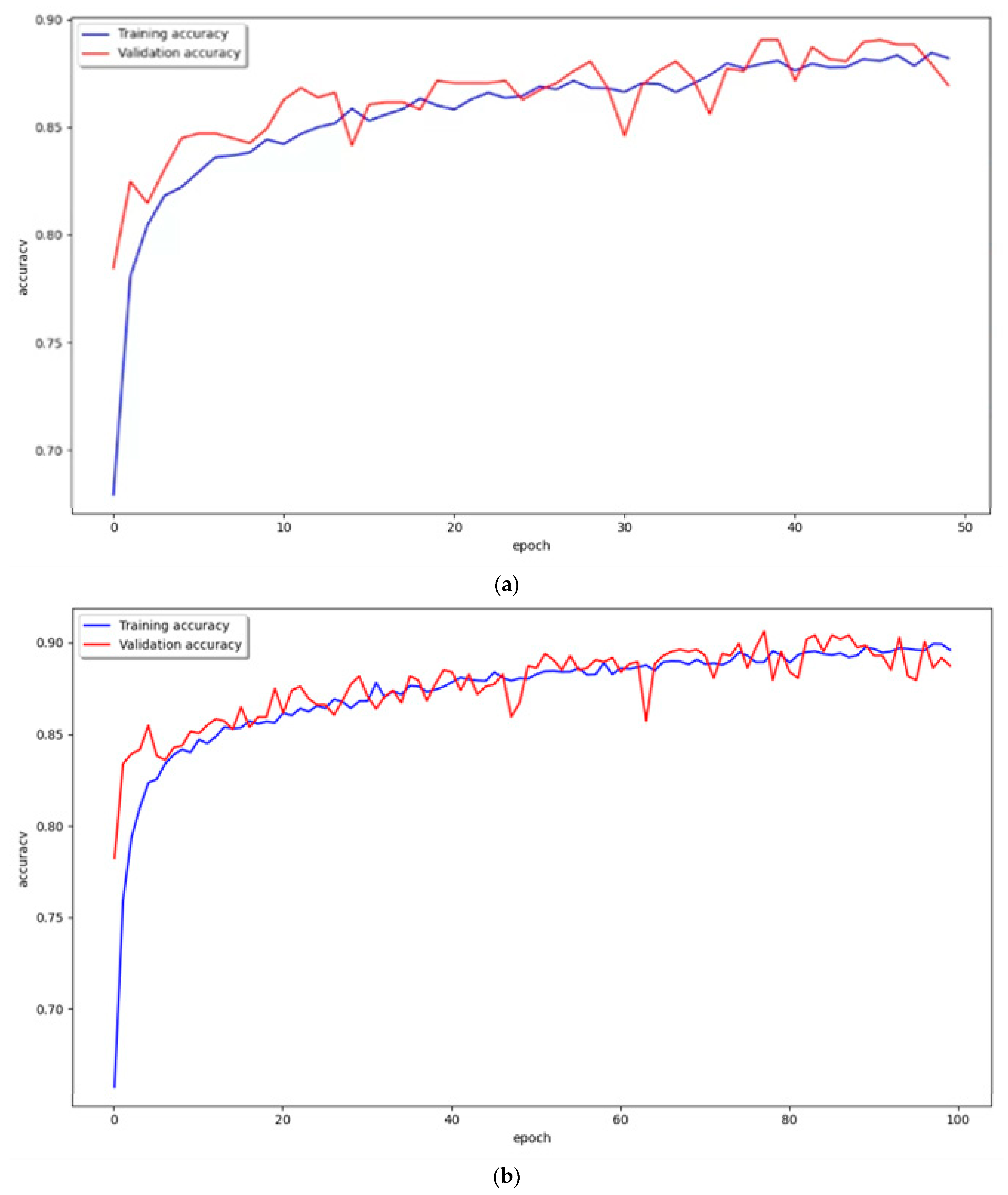
3. Results
VGG16 Model Learning and Classification Results
4. Discussion
Performance Evaluation of the VGG16 Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Burkard, R.F.; Eggermont, J.J.; Don, M. Auditory Evoked Potentials: Basic Principles and Clinical Application; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2007. [Google Scholar]
- Aldè, M.; Binda, S.; Primache, V.; Pellegrinelli, L.; Pariani, E.; Pregliasco, F.; Di Berardino, F.; Cantarella, G.; Ambrosetti, U. Congenital cytomegalovirus and hearing loss: The state of the art. J. Clin. Med. 2023, 12, 4465. [Google Scholar] [CrossRef] [PubMed]
- Eggermont, J.J. Auditory brainstem response. In Handbook of Clinical Neurology; North-Holland Publishing Company: Amsterdam, The Netherlands, 2019; Volume 160, pp. 451–464. [Google Scholar]
- Hood, L.J. Principles and applications in auditory evoked potentials. Ear Hear. 1996, 17, 178. [Google Scholar] [CrossRef]
- Abdala, C.; Folsom, R.C. The development of frequency resolution in humans as revealed by the auditory brain-stem response recorded with notched-noise masking. J. Acoust. Soc. Am. 1995, 98, 921–930. [Google Scholar] [CrossRef]
- Gorga, M.P.; Johnson, T.A.; Kaminski, J.R.; Beauchaine, K.L.; Garner, C.A.; Neely, S.T. Using a combination of click-and tone burst–evoked auditory brain stem response measurements to estimate pure-tone thresholds. Ear Hear. 2006, 27, 60–74. [Google Scholar] [CrossRef] [PubMed]
- Dowley, A.C.; Whitehouse, W.P.; Mason, S.M.; Cope, Y.; Grant, J.; Gibbin, K.P. Auditory neuropathy: Unexpectedly common in a screened newborn population. Dev. Med. Child Neurol. 2009, 51, 642–646. [Google Scholar] [CrossRef] [PubMed]
- Mason, S.; McCormick, B.; Wood, S. Auditory brainstem response in paediatric audiology. Arch. Dis. Child. 1988, 63, 465. [Google Scholar] [CrossRef]
- Elberling, C.; Parbo, J. Reference data for ABRs in retrocochlear diagnosis. Scand. Audiol. 1987, 16, 49–55. [Google Scholar] [CrossRef]
- Lim, T.; Oh, J.; Joo, J.B.; Cho, J.E.; Park, P.; Kim, J.Y. Difference in Thresholds between Auditory Brainstem Response Test and Pure Tone Audiometry by Frequency. Korean J. Otorhinolaryngol.—Head Neck Surg. 2023, 66, 7–14. [Google Scholar] [CrossRef]
- Norton, S.J.; Gorga, M.P.; Widen, J.E.; Folsom, R.C.; Sininger, Y.; Cone-Wesson, B.; Vohr, B.R.; Fletcher, K.A. Identification of neonatal hearing impairment: Summary and recommendations. Ear Hear. 2000, 21, 529–535. [Google Scholar] [CrossRef]
- Kim, L.S.; Jung, S.W.; Heo, S.D.; Hwang, C.H. Comparison of Auditory Brainstem Response and Auditory Steady-State Response Thresholds in Infants and Young Children. Korean J. Otorhinolaryngol.—Head Neck Surg. 2004, 47, 304–310. [Google Scholar]
- Stapells, D.R.; Gravel, J.S.; Martin, B.A. Thresholds for auditory brain stem responses to tones in notched noise from infants and young children with normal hearing or sensorineural hearing loss. Ear Hear. 1995, 16, 361–371. [Google Scholar] [CrossRef] [PubMed]
- Shen, D.; Wu, G.; Suk, H.-I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Lu, G. Skin Lesion Segmentation with Codec Structure Based Upper and Lower Layer Feature Fusion Mechanism. KSII Trans. Internet Inf. Syst. (TIIS) 2022, 16, 60–79. [Google Scholar]
- Jia, X.; Qian, C.; Yang, Z.; Xu, H.; Han, X.; Ren, H.; Wu, X.; Ma, B.; Yang, D.; Min, H. Boundary-aware dual attention guided liver segment segmentation model. KSII Trans. Internet Inf. Syst. (TIIS) 2022, 16, 16–37. [Google Scholar]
- Razzak, M.I.; Naz, S.; Zaib, A. Deep learning for medical image processing: Overview, challenges and the future. In Classification in BioApps: Automation of Decision Making; Springer: Cham, Switzerland, 2018; pp. 323–350. [Google Scholar]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef]
- Katz, J. Handbook of Clinical Audiology, International ed.; Williams & Wikins: Philadelphia, PA, USA, 2014. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Wu, Y.; Cai, C. An ensemble of convolutional neural networks for image classification based on LSTM. In Proceedings of the 2017 International Conference on Green Informatics (ICGI), Fuzhou, China, 15–17 August 2017; pp. 217–222. [Google Scholar]
- Lan, Y.; Xie, L.; Cai, X.; Wang, L. A many-objective evolutionary algorithm based on integrated strategy for skin cancer detection. KSII Trans. Internet Inf. Syst. (TIIS) 2022, 16, 80–96. [Google Scholar]
- Saini, R.; Semwal, P.; Jaware, T.H. Brain Tumor Classification Using VGG-16 and MobileNetV2 Deep Learning Techniques on Magnetic Resonance Images (MRI). In International Conference on Soft Computing and its Engineering Applications; Springer Nature: Cham, Switzerland, 2022; pp. 300–313. [Google Scholar]
- Koo, J.H.; Hwang, L.M.; Kim, H.H.; Kim, T.H.; Kim, J.H.; Song, H.S. Machine learning-based nutrient classification recommendation algorithm and nutrient suitability assessment questionnaire. KSII Trans. Internet Inf. Syst. 2023, 17, 16–29. [Google Scholar]
- Cone-Wesson, B.; Ramirez, G.M. Hearing sensitivity in newborns estimated from ABRs to bone-conducted sounds. J. Am. Acad. Audiol. 1997, 8, 5. [Google Scholar]
- Sininger, Y.S. Auditory brain stem response for objective measures of hearing. Ear Hear. 1993, 14, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Goh, E.K. Diagnosis of hearing loss. J. Clin. Otolaryngol. Head Neck Surg. 2003, 14, 161–167. [Google Scholar] [CrossRef]
- Cueva, R.A. Auditory brainstem response versus magnetic resonance imaging for the evaluation of asymmetric sensorineural hearing loss. Laryngoscope 2004, 114, 1686–1692. [Google Scholar] [CrossRef]
- Verhulst, S.; Jagadeesh, A.; Mauermann, M.; Ernst, F. Individual differences in auditory brainstem response wave characteristics: Relations to different aspects of peripheral hearing loss. Trends Hear. 2016, 20, 2331216516672186. [Google Scholar] [CrossRef]
- Mohan, R.; Ganapathy, K.; Rama, A. Brain tumour classification of magnetic resonance images using a novel CNN based medical image analysis and detection network in comparison with VGG16. J. Popul. Ther. Clin. Pharmacol. 2021, 28, 2. [Google Scholar]
- Qu, X.; Lu, H.; Tang, W.; Wang, S.; Zheng, D.; Hou, Y.; Jiang, J. A VGG attention vision transformer network for benign and malignant classification of breast ultrasound images. Med. Phys. 2022, 49, 5787–5798. [Google Scholar] [CrossRef]
- Al-Radaideh AA, H.; bin Mohd Rahim, M.S.; Ghaban, W.; Bsoul, M.; Kamal, S.; Abbas, N. Arabic Words Extraction and Character Recognition from Picturesque Image Macros with Enhanced VGG-16 Based Model Functionality Using Neural Networks. KSII Trans. Internet Inf. Syst. 2023, 17, 7. [Google Scholar]
- Yang, L.; He, H.; Liu, T. Road Damage Detection and Classification based on Multi-Level Feature Pyramids. KSII Trans. Internet Inf. Syst. 2021, 15, 2. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, X.; Zou, J.; He, K.; Sun, J. Accelerating very deep convolutional networks for classification and detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1943–1955. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
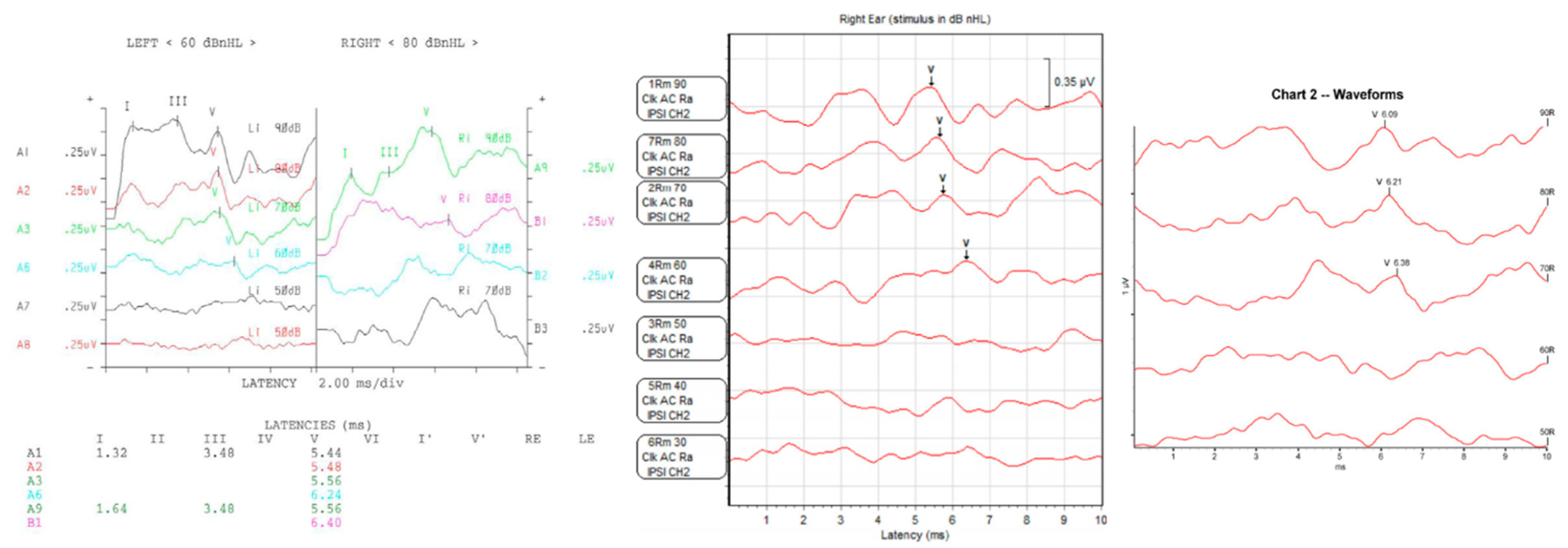
| Difference | Example of ABR Data Image |
|---|---|
| Different graph colors for each device |  |
| Inconsistency of X-axis starting point |  |
| Inconsistency of V waveform mark |  |
| Inconsistency of the presence of graph grid |  |
| Part | Specification |
|---|---|
| OS | Windows 10 Pro |
| CPU | Intel Core i7−12700 2.10 GHz |
| GPU | NVIDIA GeForce RTX 4090 24 GB |
| RAM | Samsung 21400—32.0 GB*2 |
| SSD | Samsung 970 1 TB |
| Epoch/Batch Size | 50/16 | 100/16 | 200/16 |
| Training accuracy | 87.52% | 88.20% | 92.13% |
| Epoch/Batch Size | 50/8 | 100/8 | 200/8 |
| Training accuracy | 88.12% | 89.40% | 91.96% |
| Epoch | 50 | 100 | 200 |
|---|---|---|---|
| Confusion matrix (tn;fp;fn;tp) | 386;114;68;432 | 402;98;89;411 | 384;116;43;457 |
| Test accuracy | 81.80% | 81.30% | 84.10% |
| Specificity | 77.20% | 80.40% | 76.80% |
| Sensitivity | 86.40% | 82.20% | 91.40% |
| FPR | 22.80% | 19.60% | 23.20% |
| FNR | 13.60% | 17.80% | 8.60% |
| Precision | 79.12% | 80.75% | 79.76% |
| F1 score | 82.60% | 81.47% | 85.18% |
| Epoch | 50 | 100 | 200 |
|---|---|---|---|
| Confusion matrix (tn;fp;fn;tp) | 405;95;106;394 | 430;70;95;405 | 398;102;49;451 |
| Test accuracy | 79.90% | 83.50% | 84.90% |
| Specificity | 81.00% | 86.00% | 79.60% |
| Sensitivity | 78.80% | 81.00% | 90.20% |
| FPR | 19.00% | 14.00% | 20.40% |
| FNR | 21.20% | 19.00% | 9.80% |
| Precision | 80.57% | 85.26% | 81.56% |
| F1 score | 79.68% | 83.08% | 85.66% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Seo, J.-H.; Moon, I.J.; Park, M.K.; Lee, J.B.; Kim, H.; Ahn, J.H.; Jang, J.H.; Lee, J.D.; Choi, S.J.; et al. Auditory Brainstem Response Data Preprocessing Method for the Automatic Classification of Hearing Loss Patients. Diagnostics 2023, 13, 3538. https://doi.org/10.3390/diagnostics13233538
Ma J, Seo J-H, Moon IJ, Park MK, Lee JB, Kim H, Ahn JH, Jang JH, Lee JD, Choi SJ, et al. Auditory Brainstem Response Data Preprocessing Method for the Automatic Classification of Hearing Loss Patients. Diagnostics. 2023; 13(23):3538. https://doi.org/10.3390/diagnostics13233538
Chicago/Turabian StyleMa, Jun, Jae-Hyun Seo, Il Joon Moon, Moo Kyun Park, Jong Bin Lee, Hantai Kim, Joong Ho Ahn, Jeong Hun Jang, Jong Dae Lee, Seong Jun Choi, and et al. 2023. "Auditory Brainstem Response Data Preprocessing Method for the Automatic Classification of Hearing Loss Patients" Diagnostics 13, no. 23: 3538. https://doi.org/10.3390/diagnostics13233538
APA StyleMa, J., Seo, J. -H., Moon, I. J., Park, M. K., Lee, J. B., Kim, H., Ahn, J. H., Jang, J. H., Lee, J. D., Choi, S. J., & Hong, M. (2023). Auditory Brainstem Response Data Preprocessing Method for the Automatic Classification of Hearing Loss Patients. Diagnostics, 13(23), 3538. https://doi.org/10.3390/diagnostics13233538