
Ultrasound Image Analysis with Vision Transformers—Review


Abstract
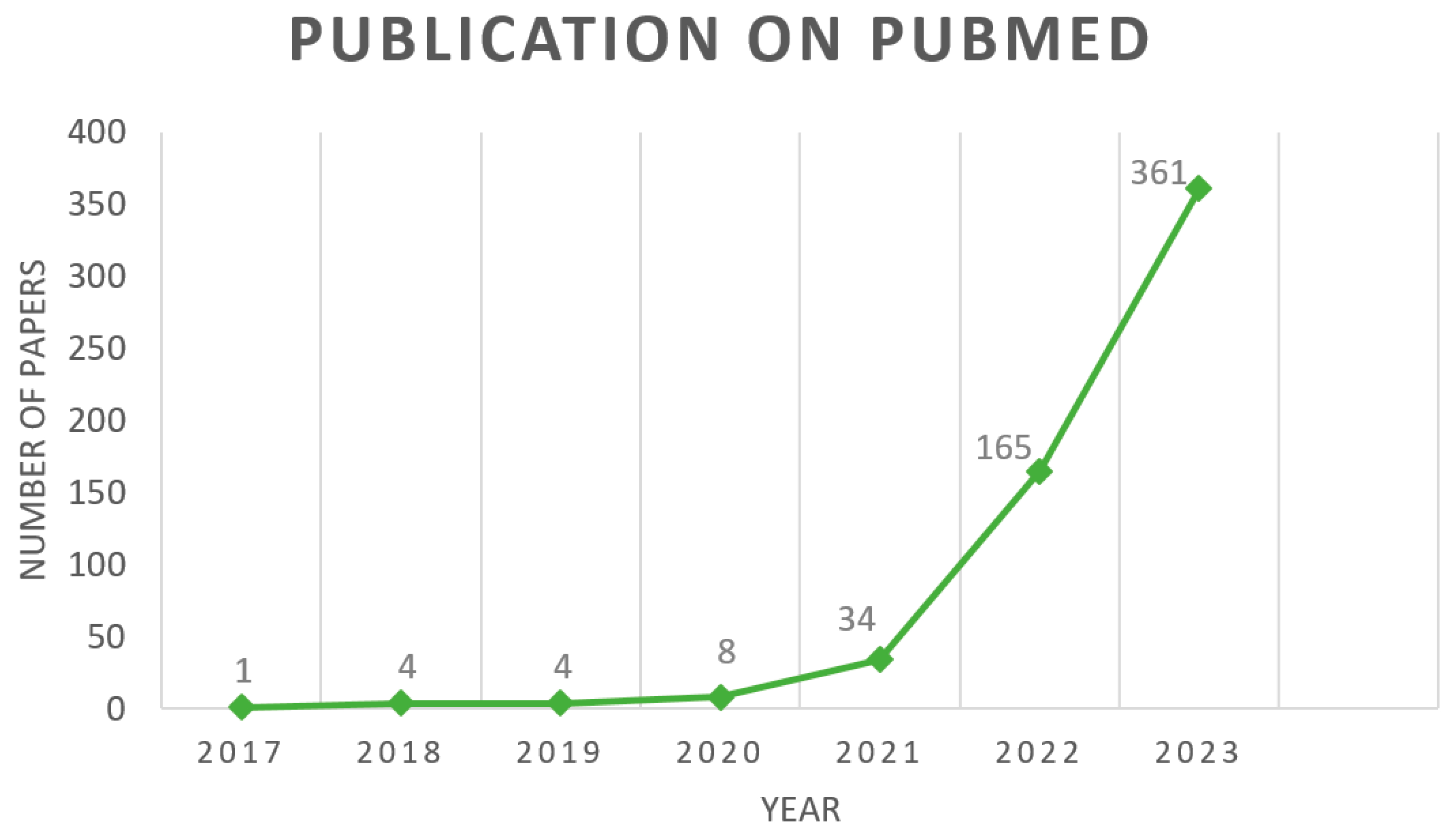
:1. Introduction
2. Background
2.1. Fundamentals of Transformers
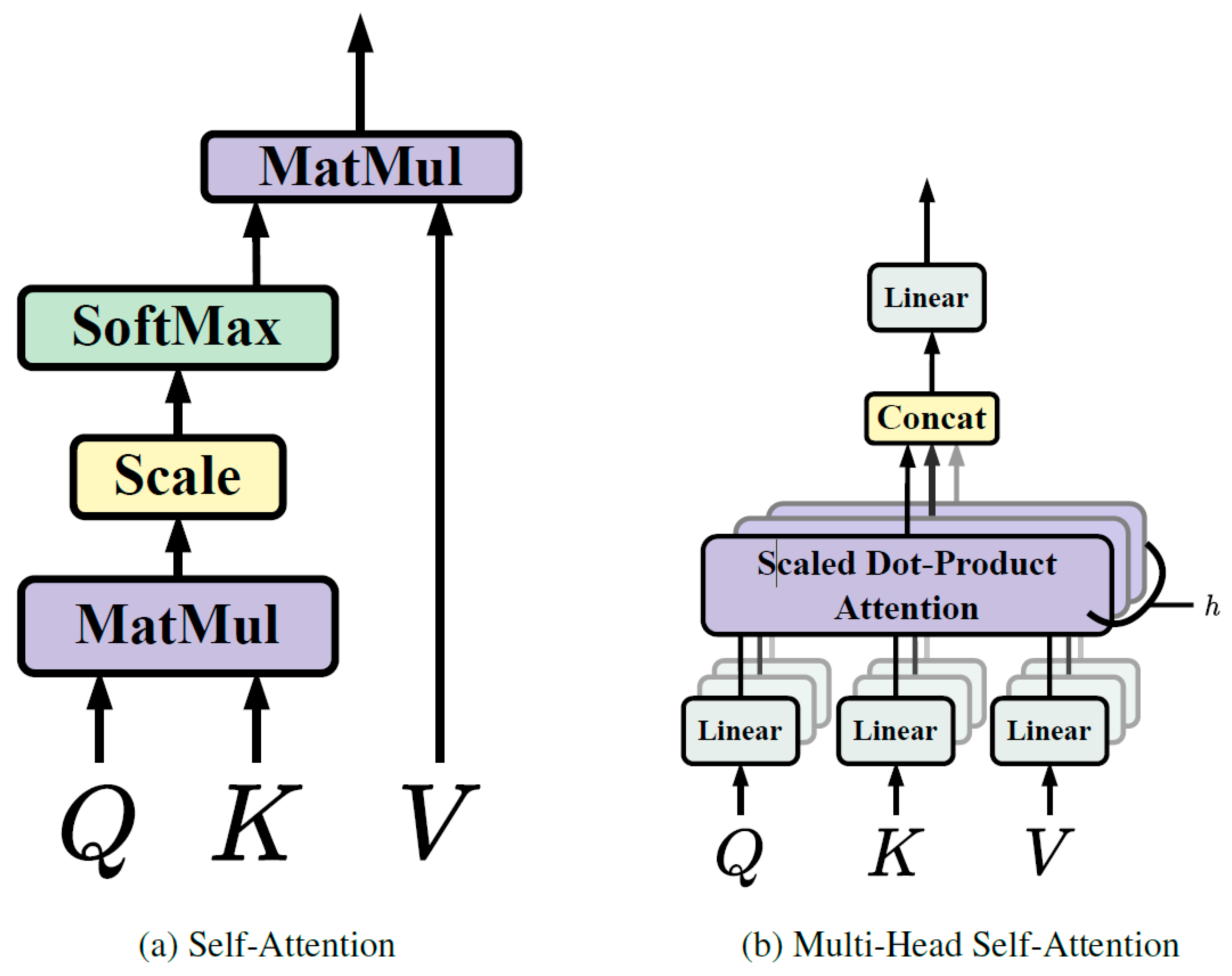
2.1.1. Self-Attention
2.1.2. Multi-Head Self-Attention
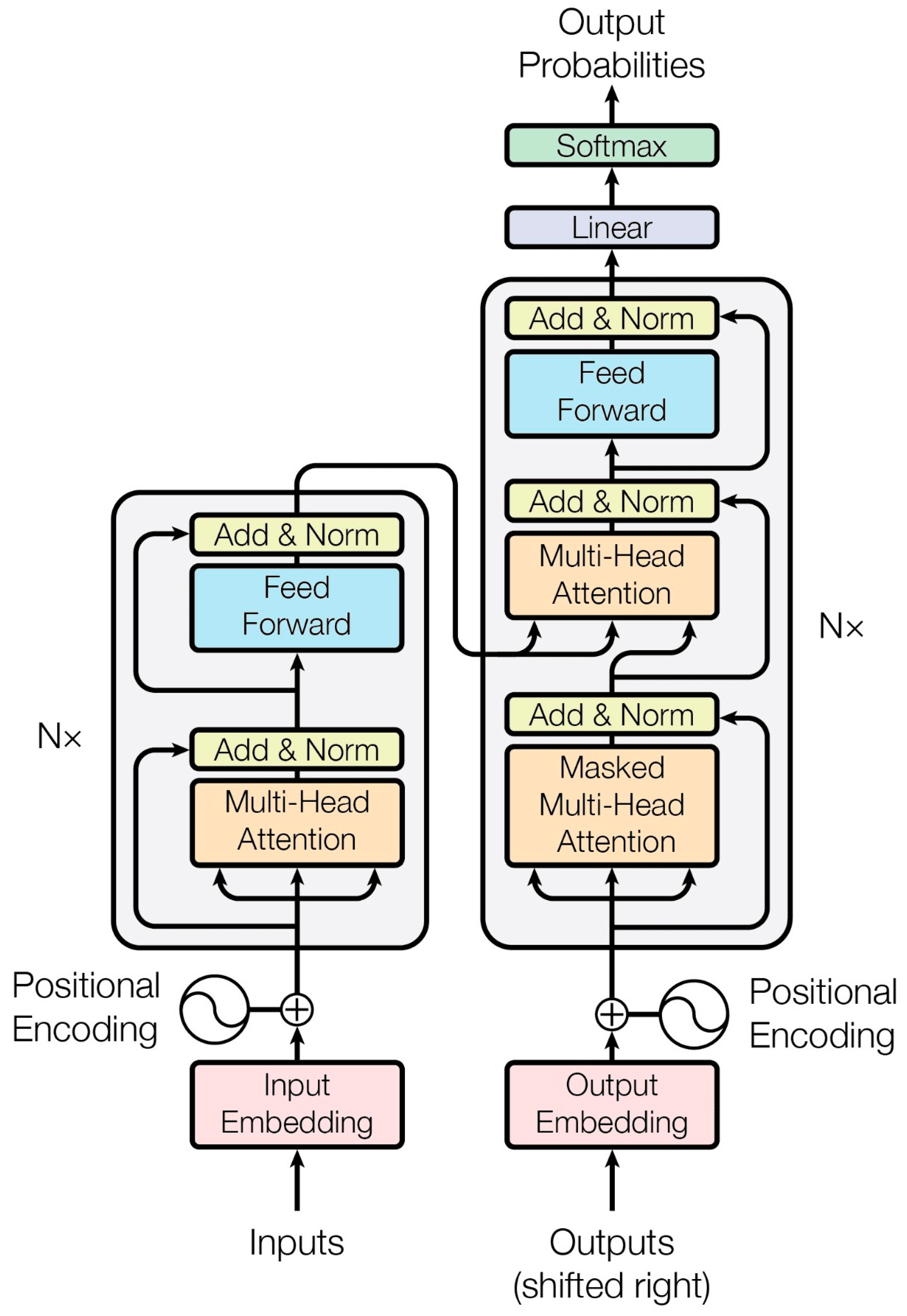
2.2. Transformer Architecture
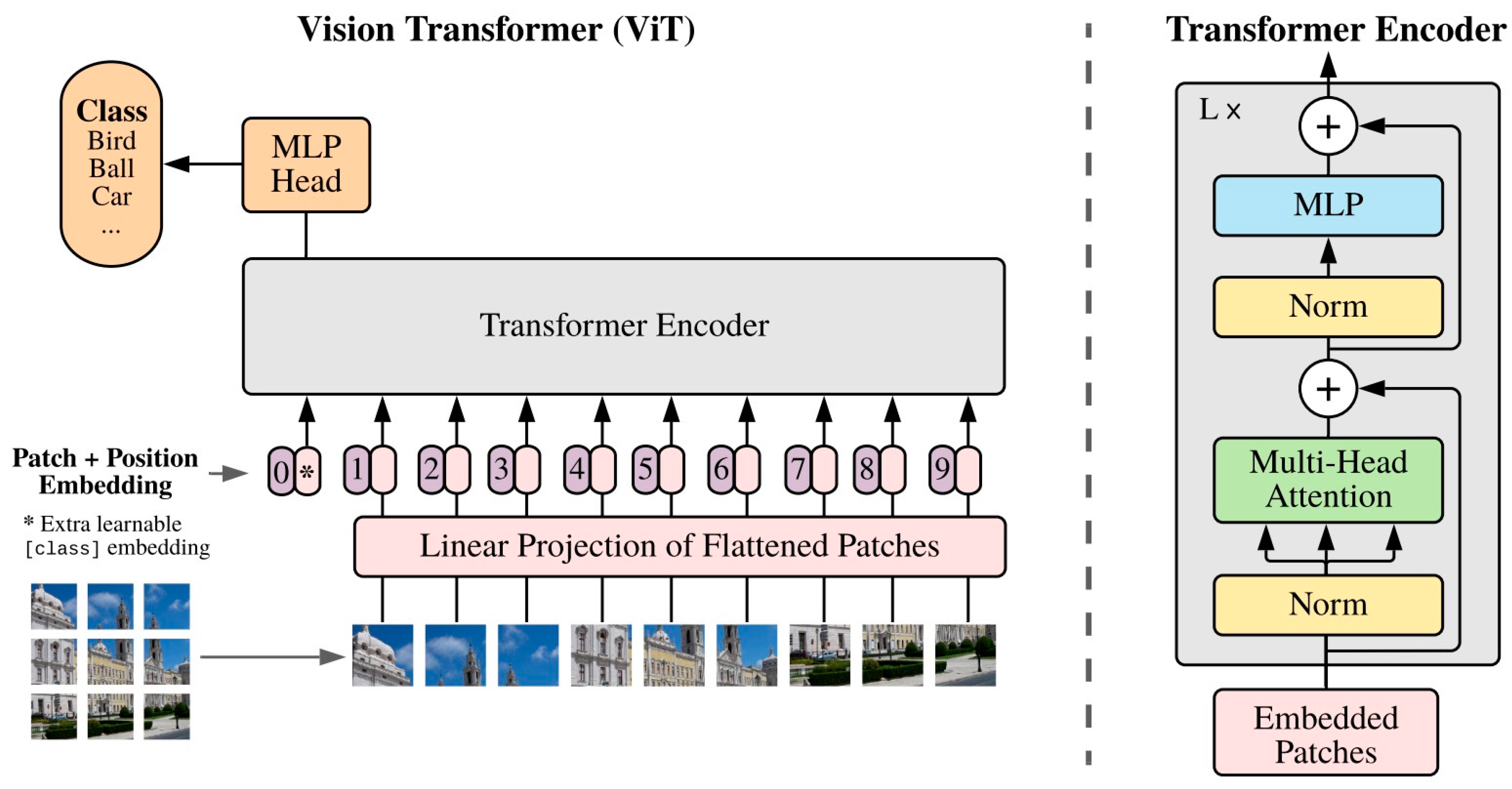
2.3. Vision Transformers
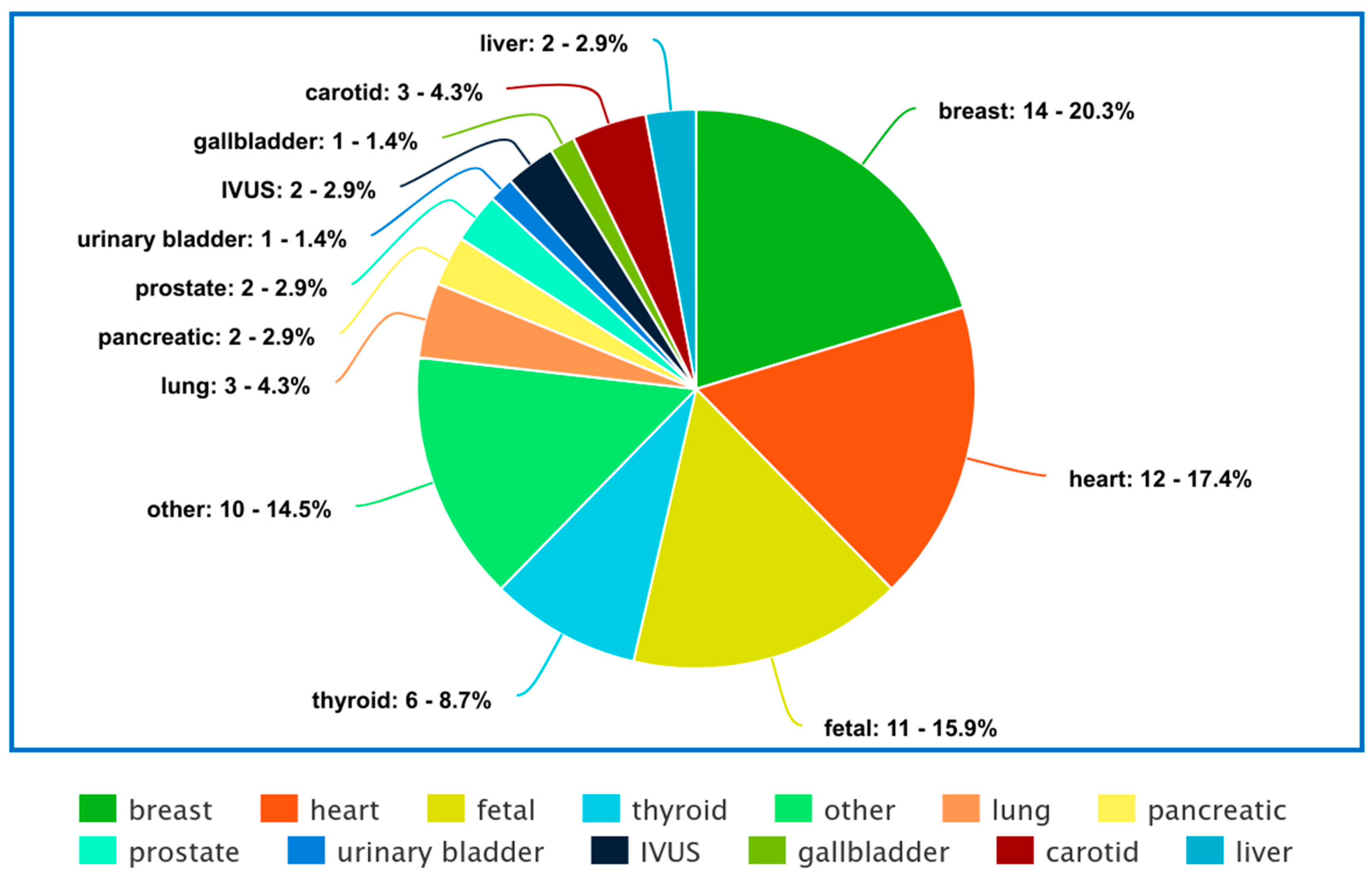
3. Organs
3.1. Breast
3.2. Urinary Bladder
3.3. Pancreatic
3.4. Prostate
3.5. Thyroid
3.6. Heart
3.7. Fetal
3.8. Carotid
3.9. Lung
3.10. Liver
3.11. IVUS
3.12. Gallbladder
3.13. Other-Synthetic
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Koutras, A.; Perros, P.; Prokopakis, I.; Ntounis, T.; Fasoulakis, Z.; Pittokopitou, S.; Samara, A.A.; Valsamaki, A.; Douligeris, A.; Mortaki, A. Advantages and Limitations of Ultrasound as a Screening Test for Ovarian Cancer. Diagnostics 2023, 13, 2078. [Google Scholar] [CrossRef]
- Leung, K.-Y. Applications of Advanced Ultrasound Technology in Obstetrics. Diagnostics 2021, 11, 1217. [Google Scholar] [CrossRef] [PubMed]
- Brunetti, N.; Calabrese, M.; Martinoli, C.; Tagliafico, A.S. Artificial intelligence in breast ultrasound: From diagnosis to prognosis—A rapid review. Diagnostics 2022, 13, 58. [Google Scholar] [CrossRef] [PubMed]
- Gifani, P.; Vafaeezadeh, M.; Ghorbani, M.; Mehri-Kakavand, G.; Pursamimi, M.; Shalbaf, A.; Davanloo, A.A. Automatic diagnosis of stage of COVID-19 patients using an ensemble of transfer learning with convolutional neural networks based on computed tomography images. J. Med. Signals Sens. 2023, 13, 101–109. [Google Scholar] [PubMed]
- Ait Nasser, A.; Akhloufi, M.A. A review of recent advances in deep learning models for chest disease detection using radiography. Diagnostics 2023, 13, 159. [Google Scholar] [CrossRef] [PubMed]
- Shalbaf, A.; Gifani, P.; Mehri-Kakavand, G.; Pursamimi, M.; Ghorbani, M.; Davanloo, A.A.; Vafaeezadeh, M. Automatic diagnosis of severity of COVID-19 patients using an ensemble of transfer learning models with convolutional neural networks in CT images. Pol. J. Med. Phys. Eng. 2022, 28, 117–126. [Google Scholar] [CrossRef]
- Qian, J.; Li, H.; Wang, J.; He, L. Recent Advances in Explainable Artificial Intelligence for Magnetic Resonance Imaging. Diagnostics 2023, 13, 1571. [Google Scholar] [CrossRef] [PubMed]
- Vafaeezadeh, M.; Behnam, H.; Hosseinsabet, A.; Gifani, P. A deep learning approach for the automatic recognition of prosthetic mitral valve in echocardiographic images. Comput. Biol. Med. 2021, 133, 104388. [Google Scholar] [CrossRef]
- Gifani, P.; Shalbaf, A.; Vafaeezadeh, M. Automated detection of COVID-19 using ensemble of transfer learning with deep convolutional neural network based on CT scans. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 115–123. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Reynaud, H.; Vlontzos, A.; Hou, B.; Beqiri, A.; Leeson, P.; Kainz, B. Ultrasound video transformers for cardiac ejection fraction estimation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part VI 24, 2021. pp. 495–505. [Google Scholar]
- Gilany, M.; Wilson, P.; Perera-Ortega, A.; Jamzad, A.; To, M.N.N.; Fooladgar, F.; Wodlinger, B.; Abolmaesumi, P.; Mousavi, P. TRUSformer: Improving prostate cancer detection from micro-ultrasound using attention and self-supervision. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 1193–1200. [Google Scholar] [CrossRef]
- Dadoun, H.; Rousseau, A.-L.; de Kerviler, E.; Correas, J.-M.; Tissier, A.-M.; Joujou, F.; Bodard, S.; Khezzane, K.; de Margerie-Mellon, C.; Delingette, H. Deep learning for the detection, localization, and characterization of focal liver lesions on abdominal US images. Radiol. Artif. Intell. 2022, 4, e210110. [Google Scholar] [CrossRef]
- Wang, W.; Jiang, R.; Cui, N.; Li, Q.; Yuan, F.; Xiao, Z. Semi-supervised vision transformer with adaptive token sampling for breast cancer classification. Front. Pharmacol. 2022, 13, 929755. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Almekkawy, M. Ultrasound Localization Microscopy Using Deep Neural Network. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2023, 70, 625–635. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, J.; Luo, Q.; Shen, C.; Wang, R.; Ding, X. Automated classification of cervical lymph-node-level from ultrasound using Depthwise Separable Convolutional Swin Transformer. Comput. Biol. Med. 2022, 148, 105821. [Google Scholar] [CrossRef] [PubMed]
- Perera, S.; Adhikari, S.; Yilmaz, A. Pocformer: A lightweight transformer architecture for detection of COVID-19 using point of care ultrasound. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 195–199. [Google Scholar]
- Li, J.; Zhang, P.; Wang, T.; Zhu, L.; Liu, R.; Yang, X.; Wang, K.; Shen, D.; Sheng, B. DSMT-Net: Dual Self-supervised Multi-operator Transformation for Multi-source Endoscopic Ultrasound Diagnosis. IEEE Trans. Med. Imaging 2023, 43, 64–75. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Cao, Y.; Hu, W.; Zhang, W.; Li, J.; Wang, C.; Mukhopadhyay, S.C.; Li, Y.; Liu, Z.; Li, S. Refined feature-based Multi-frame and Multi-scale Fusing Gate network for accurate segmentation of plaques in ultrasound videos. Comput. Biol. Med. 2023, 163, 107091. [Google Scholar] [CrossRef] [PubMed]
- Xia, M.; Yang, H.; Qu, Y.; Guo, Y.; Zhou, G.; Zhang, F.; Wang, Y. Multilevel structure-preserved GAN for domain adaptation in intravascular ultrasound analysis. Med. Image Anal. 2022, 82, 102614. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Liao, S.; Yang, Z.; Guo, J.; Zhang, Z.; Yang, Y.; Guo, Y.; Yin, S.; Liu, C.; Kang, Y. RDHCformer: Fusing ResDCN and Transformers for Fetal Head Circumference Automatic Measurement in 2D Ultrasound Images. Front. Med. 2022, 9, 848904. [Google Scholar] [CrossRef]
- Sankari, V.R.; Raykar, D.A.; Snekhalatha, U.; Karthik, V.; Shetty, V. Automated detection of cystitis in ultrasound images using deep learning techniques. IEEE Access 2023, 11, 104179–104190. [Google Scholar] [CrossRef]
- Basu, S.; Gupta, M.; Rana, P.; Gupta, P.; Arora, C. RadFormer: Transformers with global–local attention for interpretable and accurate Gallbladder Cancer detection. Med. Image Anal. 2023, 83, 102676. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. Med. Image Anal. 2023, 88, 102802. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; Montreal, BC, Canada, 10–17 October 2021, pp. 10012–10022.
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12179–12188. [Google Scholar]
- Available online: https://www.who.int/news-room/fact-sheets/detail/breast-cancer (accessed on 12 July 2023).
- Li, G.; Jin, D.; Yu, Q.; Zheng, Y.; Qi, M. MultiIB-TransUNet: Transformer with multiple information bottleneck blocks for CT and ultrasound image segmentation. Med. Phys. 2023, 51, 1178–1189. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wu, H.; Huang, X.; Guo, X.; Wen, Z.; Qin, J. Cross-image Dependency Modelling for Breast Ultrasound Segmentation. IEEE Trans. Med. Imaging 2023, 42, 1619–1631. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Lian, J.; Yi, Z.; Wu, R.; Lu, X.; Ma, P.; Ma, Y. HAU-Net: Hybrid CNN-transformer for breast ultrasound image segmentation. Biomed. Signal Process. Control 2024, 87, 105427. [Google Scholar] [CrossRef]
- Li, G.; Jin, D.; Yu, Q.; Qi, M. IB-TransUNet: Combining Information Bottleneck and Transformer for Medical Image Segmentation. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 249–258. [Google Scholar] [CrossRef]
- Zhou, J.; Hou, Z.; Lu, H.; Wang, W.; Zhao, W.; Wang, Z.; Zheng, D.; Wang, S.; Tang, W.; Qu, X. A deep supervised transformer U-shaped full-resolution residual network for the segmentation of breast ultrasound image. Med. Phys. 2023, 50, 7513–7524. [Google Scholar] [CrossRef]
- He, Q.; Yang, Q.; Xie, M. HCTNet: A hybrid CNN-transformer network for breast ultrasound image segmentation. Comput. Biol. Med. 2023, 155, 106629. [Google Scholar] [CrossRef] [PubMed]
- Song, M.; Kim, Y. Optimizing proportional balance between supervised and unsupervised features for ultrasound breast lesion classification. Biomed. Signal Process. Control 2024, 87, 105443. [Google Scholar] [CrossRef]
- Yang, H.; Yang, D. CSwin-PNet: A CNN-Swin Transformer combined pyramid network for breast lesion segmentation in ultrasound images. Expert Syst. Appl. 2023, 213, 119024. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, Y.; Jiang, W.; Wang, T.; Lei, B. 3d deep attentive u-net with transformer for breast tumor segmentation from automated breast volume scanner. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual, 1–5 November 2021; pp. 4011–4014. [Google Scholar]
- Gheflati, B.; Rivaz, H. Vision transformers for classification of breast ultrasound images. In Proceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, UK, 11–15 July 2022; pp. 480–483. [Google Scholar]
- Ayana, G.; Choe, S.-W. BUVITNET: Breast ultrasound detection via vision transformers. Diagnostics 2022, 12, 2654. [Google Scholar] [CrossRef] [PubMed]
- Mo, Y.; Han, C.; Liu, Y.; Liu, M.; Shi, Z.; Lin, J.; Zhao, B.; Huang, C.; Qiu, B.; Cui, Y. Hover-trans: Anatomy-aware hover-transformer for roi-free breast cancer diagnosis in ultrasound images. IEEE Trans. Med. Imaging 2023, 42, 1696–1706. [Google Scholar] [CrossRef]
- Ji, H.; Zhu, Q.; Ma, T.; Cheng, Y.; Zhou, S.; Ren, W.; Huang, H.; He, W.; Ran, H.; Ruan, L. Development and validation of a transformer-based CAD model for improving the consistency of BI-RADS category 3–5 nodule classification among radiologists: A multiple center study. Quant. Imaging Med. Surg. 2023, 13, 3671. [Google Scholar] [CrossRef]
- Available online: https://zenodo.org/records/8041285 (accessed on 15 June 2023).
- Available online: https://www.kaggle.com/datasets/aryashah2k/breast-ultrasound-images-dataset (accessed on 1 February 2020).
- Lu, X.; Liu, X.; Xiao, Z.; Zhang, S.; Huang, J.; Yang, C.; Liu, S. Self-supervised dual-head attentional bootstrap learning network for prostate cancer screening in transrectal ultrasound images. Comput. Biol. Med. 2023, 165, 107337. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Du, R.; Luo, Q.; Wang, R.; Ding, X. A novel model of thyroid nodule segmentation for ultrasound images. Ultrasound Med. Biol. 2023, 49, 489–496. [Google Scholar] [CrossRef] [PubMed]
- Jerbi, F.; Aboudi, N.; Khlifa, N. Automatic classification of ultrasound thyroids images using vision transformers and generative adversarial networks. Sci. Afr. 2023, 20, e01679. [Google Scholar] [CrossRef]
- Chen, F.; Han, H.; Wan, P.; Liao, H.; Liu, C.; Zhang, D. Joint Segmentation and Differential Diagnosis of Thyroid Nodule in Contrast-Enhanced Ultrasound Images. IEEE Trans. Biomed. Eng. 2023, 70, 2722–2732. [Google Scholar] [CrossRef]
- Zhang, N.; Liu, J.; Jin, Y.; Duan, W.; Wu, Z.; Cai, Z.; Wu, M. An adaptive multi-modal hybrid model for classifying thyroid nodules by combining ultrasound and infrared thermal images. BMC Bioinform. 2023, 24, 315. [Google Scholar] [CrossRef]
- Liu, Q.; Ding, F.; Li, J.; Ji, S.; Liu, K.; Geng, C.; Lyu, L. DCA-Net: Dual-branch contextual-aware network for auxiliary localization and segmentation of parathyroid glands. Biomed. Signal Process. Control 2023, 84, 104856. [Google Scholar] [CrossRef]
- Zhao, X.; Li, H.; Xu, J.; Wu, J. Ultrasonic Thyroid Nodule Benign-Malignant Classification with Multi-level Features Fusions. In Proceedings of the 2023 8th International Conference on Image, Vision and Computing (ICIVC), Dalian, China, 27–29 July 2023; pp. 907–912. [Google Scholar]
- Vafaeezadeh, M.; Behnam, H.; Hosseinsabet, A.; Gifani, P. Automatic morphological classification of mitral valve diseases in echocardiographic images based on explainable deep learning methods. Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 413–425. [Google Scholar] [CrossRef]
- Al Qurri, A.; Almekkawy, M. Improved UNet with Attention for Medical Image Segmentation. Sensors 2023, 23, 8589. [Google Scholar] [CrossRef]
- Zhao, C.; Chen, W.; Qin, J.; Yang, P.; Xiang, Z.; Frangi, A.F.; Chen, M.; Fan, S.; Yu, W.; Chen, X. IFT-net: Interactive fusion transformer network for quantitative analysis of pediatric echocardiography. Med. Image Anal. 2022, 82, 102648. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Wang, Q.; Zou, R.; Wang, Y.; Liu, F.; Zheng, H.; Du, S.; Yuan, C. A Heart Image Segmentation Method Based on Position Attention Mechanism and Inverted Pyramid. Sensors 2023, 23, 9366. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Lian, Y.; Yao, Y.; Chen, L.; Gao, F.; Xu, L.; Huang, X.; Feng, X.; Guo, S. Left Ventricle Segmentation in Echocardiography with Transformer. Diagnostics 2023, 13, 2365. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Tsui, P.-H.; Wu, W.; Zhou, Z.; Wu, S. MAEF-Net: Multi-attention efficient feature fusion network for deep learning segmentation. In Proceedings of the 2021 IEEE International Ultrasonics Symposium (IUS), Xi’an, China, 12–16 September 2021; pp. 1–4. [Google Scholar]
- Tang, Z.; Duan, J.; Sun, Y.; Zeng, Y.; Zhang, Y.; Yao, X. A combined deformable model and medical transformer algorithm for medical image segmentation. Med. Biol. Eng. Comput. 2023, 61, 129–137. [Google Scholar] [CrossRef]
- Ahmadi, N.; Tsang, M.; Gu, A.; Tsang, T.; Abolmaesumi, P. Transformer-based spatio-temporal analysis for classification of aortic stenosis severity from echocardiography cine series. IEEE Trans. Med. Imaging 2023, 43, 366–376. [Google Scholar] [CrossRef] [PubMed]
- Vafaeezadeh, M.; Behnam, H.; Hosseinsabet, A.; Gifani, P. CarpNet: Transformer for mitral valve disease classification in echocardiographic videos. Int. J. Imaging Syst. Technol. 2023, 33, 1505–1514. [Google Scholar] [CrossRef]
- Hagberg, E.; Hagerman, D.; Johansson, R.; Hosseini, N.; Liu, J.; Björnsson, E.; Alvén, J.; Hjelmgren, O. Semi-supervised learning with natural language processing for right ventricle classification in echocardiography—A scalable approach. Comput. Biol. Med. 2022, 143, 105282. [Google Scholar] [CrossRef] [PubMed]
- Fazry, L.; Haryono, A.; Nissa, N.K.; Hirzi, N.M.; Rachmadi, M.F.; Jatmiko, W. Hierarchical Vision Transformers for Cardiac Ejection Fraction Estimation. In Proceedings of the 2022 7th International Workshop on Big Data and Information Security (IWBIS), Depok, Indonesia, 1–3 October 2022; pp. 39–44. [Google Scholar]
- Ahn, S.S.; Ta, K.; Thorn, S.L.; Onofrey, J.A.; Melvinsdottir, I.H.; Lee, S.; Langdon, J.; Sinusas, A.J.; Duncan, J.S. Co-attention spatial transformer network for unsupervised motion tracking and cardiac strain analysis in 3D echocardiography. Med. Image Anal. 2023, 84, 102711. [Google Scholar] [CrossRef]
- Zhao, L.; Tan, G.; Pu, B.; Wu, Q.; Ren, H.; Li, K. TransFSM: Fetal Anatomy Segmentation and Biometric Measurement in Ultrasound Images Using a Hybrid Transformer. IEEE J. Biomed. Health Inform. 2023, 28, 285–296. [Google Scholar] [CrossRef]
- Qiao, S.; Pang, S.; Luo, G.; Sun, Y.; Yin, W.; Pan, S.; Lv, Z. DPC-MSGATNet: Dual-path chain multi-scale gated axial-transformer network for four-chamber view segmentation in fetal echocardiography. Complex Intell. Syst. 2023, 9, 4503–4519. [Google Scholar] [CrossRef]
- Rahman, R.; Alam, M.G.R.; Reza, M.T.; Huq, A.; Jeon, G.; Uddin, M.Z.; Hassan, M.M. Demystifying evidential Dempster Shafer-based CNN architecture for fetal plane detection from 2D ultrasound images leveraging fuzzy-contrast enhancement and explainable AI. Ultrasonics 2023, 132, 107017. [Google Scholar] [CrossRef]
- Sarker, M.M.K.; Singh, V.K.; Alsharid, M.; Hernandez-Cruz, N.; Papageorghiou, A.T.; Noble, J.A. COMFormer: Classification of Maternal-Fetal and Brain Anatomy using a Residual Cross-Covariance Attention Guided Transformer in Ultrasound. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2023, 70, 1417–1427. [Google Scholar] [CrossRef]
- Arora, U.; Sengupta, D.; Kumar, M.; Tirupathi, K.; Sai, M.K.; Hareesh, A.; Chaithanya, E.S.S.; Nikhila, V.; Bhavana, N.; Vigneshwar, P. Perceiving placental ultrasound image texture evolution during pregnancy with normal and adverse outcome through machine learning prism. Placenta 2023, 140, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; You, G.; Chen, Q.; Zhang, X.; Wang, N.; He, X.; Zhu, L.; Li, Z.; Liu, C.; Yao, S. Development and evaluation of an artificial intelligence system for children intussusception diagnosis using ultrasound images. Iscience 2023, 26, 106456. [Google Scholar] [CrossRef] [PubMed]
- Płotka, S.; Grzeszczyk, M.K.; Brawura-Biskupski-Samaha, R.; Gutaj, P.; Lipa, M.; Trzciński, T.; Sitek, A. BabyNet: Residual transformer module for birth weight prediction on fetal ultrasound video. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 350–359. [Google Scholar]
- Płotka, S.S.; Grzeszczyk, M.K.; Szenejko, P.I.; Żebrowska, K.; Szymecka-Samaha, N.A.; Łęgowik, T.; Lipa, M.A.; Kosińska-Kaczyńska, K.; Brawura-Biskupski-Samaha, R.; Išgum, I. Deep learning for estimation of fetal weight throughout the pregnancy from fetal abdominal ultrasound. Am. J. Obstet. Gynecol. MFM 2023, 5, 101182. [Google Scholar] [CrossRef] [PubMed]
- Płotka, S.; Grzeszczyk, M.K.; Brawura-Biskupski-Samaha, R.; Gutaj, P.; Lipa, M.; Trzciński, T.; Išgum, I.; Sánchez, C.I.; Sitek, A. BabyNet++: Fetal birth weight prediction using biometry multimodal data acquired less than 24 hours before delivery. Comput. Biol. Med. 2023, 167, 107602. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Droste, R.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Visual-assisted probe movement guidance for obstetric ultrasound scanning using landmark retrieval. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part VIII 24, 2021. pp. 670–679. [Google Scholar]
- Carmen Prodan, N.; Hoopmann, M.; Jonaityte, G.; Oliver Kagan, K. How to do a second trimester anomaly scan. Arch. Gynecol. Obstet. 2023, 307, 1285–1290. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Huang, J.; Xu, W.; Cui, C.; Xu, W.; Li, Z. Method for carotid artery 3-D ultrasound image segmentation based on cswin transformer. Ultrasound Med. Biol. 2023, 49, 645–656. [Google Scholar] [CrossRef]
- Li, L.; Hu, Z.; Huang, Y.; Zhu, W.; Zhao, C.; Wang, Y.; Chen, M.; Yu, J. BP-Net: Boundary and perfusion feature guided dual-modality ultrasound video analysis network for fibrous cap integrity assessment. Comput. Med. Imaging Graph. 2023, 107, 102246. [Google Scholar] [CrossRef] [PubMed]
- Xing, W.; Liu, Y.; He, C.; Liu, X.; Li, Y.; Li, W.; Chen, J.; Ta, D. Frame-to-video-based Semi-supervised Lung Ultrasound Scoring Model. In Proceedings of the 2023 IEEE International Ultrasonics Symposium (IUS), Montreal, QC, Canada, 3–8 September 2023; pp. 1–4. [Google Scholar]
- Nehary, E.; Rajan, S.; Rossa, C. Lung Ultrasound Image Classification Using Deep Learning and Histogram of Oriented Gradients Features for COVID-19 Detection. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 1–6. [Google Scholar]
- Zhang, J.; Chen, Y.; Liu, P. Automatic Recognition of Standard Liver Sections Based on Vision-Transformer. In Proceedings of the 2022 IEEE 16th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 1–3 December 2022; pp. 1–4. [Google Scholar]
- Zhang, J.; Chen, Y.; Zeng, P.; Liu, Y.; Diao, Y.; Liu, P. Ultra-Attention: Automatic Recognition of Liver Ultrasound Standard Sections Based on Visual Attention Perception Structures. Ultrasound Med. Biol. 2023, 49, 1007–1017. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Bajaj, R.; Li, Y.; Ye, X.; Lin, J.; Pugliese, F.; Ramasamy, A.; Gu, Y.; Wang, Y.; Torii, R. POST-IVUS: A perceptual organisation-aware selective transformer framework for intravascular ultrasound segmentation. Med. Image Anal. 2023, 89, 102922. [Google Scholar] [CrossRef]
- Zhao, W.; Su, X.; Guo, Y.; Li, H.; Basnet, S.; Chen, J.; Yang, Z.; Zhong, R.; Liu, J.; Chui, E.C.-s. Deep learning based ultrasonic visualization of distal humeral cartilage for image-guided therapy: A pilot validation study. Quant. Imaging Med. Surg. 2023, 13, 5306. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Wang, Q.; Bao, Y.; Kong, L.; Jin, X.; Ou, W. Laednet: A lightweight attention encoder–decoder network for ultrasound medical image segmentation. Comput. Electr. Eng. 2022, 99, 107777. [Google Scholar] [CrossRef]
- Katakis, S.; Barotsis, N.; Kakotaritis, A.; Tsiganos, P.; Economou, G.; Panagiotopoulos, E.; Panayiotakis, G. Muscle Cross-Sectional Area Segmentation in Transverse Ultrasound Images Using Vision Transformers. Diagnostics 2023, 13, 217. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Zheng, C.; He, J.; Yi, S. PCT: Pyramid convolutional transformer for parotid gland tumor segmentation in ultrasound images. Biomed. Signal Process. Control 2023, 81, 104498. [Google Scholar] [CrossRef]
- Lo, C.-M.; Lai, K.-L. Deep learning-based assessment of knee septic arthritis using transformer features in sonographic modalities. Comput. Methods Programs Biomed. 2023, 237, 107575. [Google Scholar] [CrossRef]
- Manzari, O.N.; Ahmadabadi, H.; Kashiani, H.; Shokouhi, S.B.; Ayatollahi, A. MedViT: A robust vision transformer for generalized medical image classification. Comput. Biol. Med. 2023, 157, 106791. [Google Scholar] [CrossRef]
- Qu, X.; Ren, C.; Wang, Z.; Fan, S.; Zheng, D.; Wang, S.; Lin, H.; Jiang, J.; Xing, W. Complex transformer network for single-angle plane-wave imaging. Ultrasound Med. Biol. 2023, 49, 2234–2246. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.; Ding, Q.; Chen, J.; Yan, K.; Tang, R.S.-Y.; Cheng, S.S. Learning-based needle tip tracking in 2D ultrasound by fusing visual tracking and motion prediction. Med. Image Anal. 2023, 88, 102847. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef]
- Lai, T. Interpretable Medical Imagery Diagnosis with Self-Attentive Transformers: A Review of Explainable AI for Health Care. BioMedInformatics 2024, 4, 113–126. [Google Scholar] [CrossRef]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 782–791. [Google Scholar]
- Mondal, A.K.; Bhattacharjee, A.; Singla, P.; Prathosh, A. xViTCOS: Explainable vision transformer based COVID-19 screening using radiography. IEEE J. Transl. Eng. Health Med. 2021, 10, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Shao, Z.; Bian, H.; Chen, Y.; Wang, Y.; Zhang, J.; Ji, X. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. Adv. Neural Inf. Process. Syst. 2021, 34, 2136–2147. [Google Scholar]
- Playout, C.; Duval, R.; Boucher, M.C.; Cheriet, F. Focused attention in transformers for interpretable classification of retinal images. Med. Image Anal. 2022, 82, 102608. [Google Scholar] [CrossRef]
- Zhang, H.; Meng, Y.; Zhao, Y.; Qiao, Y.; Yang, X.; Coupland, S.E.; Zheng, Y. DTFD-MIL: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18802–18812. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. Transbts: Multimodal brain tumor segmentation using transformer. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part I 24, 2021. pp. 109–119. [Google Scholar]
- Xie, Y.; Zhang, J.; Shen, C.; Xia, Y. Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part III 24, 2021. pp. 171–180. [Google Scholar]
- Zhou, H.-Y.; Guo, J.; Zhang, Y.; Yu, L.; Wang, L.; Yu, Y. nnformer: Interleaved transformer for volumetric segmentation. arXiv 2021, arXiv:2109.03201. [Google Scholar]
- Hernandez-Torres, S.I.; Hennessey, R.P.; Snider, E.J. Performance Comparison of Object Detection Networks for Shrapnel Identification in Ultrasound Images. Bioengineering 2023, 10, 807. [Google Scholar] [CrossRef]
- Gharamaleki, S.K.; Helfield, B.; Rivaz, H. Deformable-Detection Transformer for Microbubble Localization in Ultrasound Localization Microscopy. In Proceedings of the 2023 IEEE International Ultrasonics Symposium (IUS), Montreal, QC, Canada, 3–8 September 2023; pp. 1–4. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| TransUNet [33] | Segmentation | Transformer and information bottlenecks | BUSI | F1: 0.8078 IoU: 0.6775 | Used one transformer layer |
| BUSSeg [34] | Segmentation | Cross-image dependency modeling | BUSI UDIAT | DSC: 0.8577 Jac: 0.7899 Acc: 0.9733 Sp: 0.9894 Se: 0.8584 | cross-image dependency module, cross-image contextual modeling, and cross-image dependency loss. |
| HAU-Net [35] | Segmentation | Hybrid CNN-transformer | BUSI UDIAT BLUI | DSC: 0.8311, 0.8873, 0.8948 | Developed a dual-module transformer architecture combining local and global transformer components. Implemented a cross-attention block to gather global context from multi-scale features across various layers. |
| IB-TransUNet [36] | Segmentation | Transformer and information bottlenecks | Synapse dataset BUSI | DSC: 0.8195 HD: 20.35 | Used multi-resolution fusion to skip connections. |
| DSTransUFRRN [37] | Segmentation | A full-resolution residual stream/TransU-Net/transformer | Open BUS dataset from the Sun Yat-sen University Cancer Center/UDIAT | DSC: 0.9104 | Used deep supervised transformer U-shaped full-resolution residual network. |
| HCTNet [38] | Segmentation | Transformer-based U-Net | BUSI BUS B total 1263 images | DSC: 0.82 Acc: 0.969 Jac: 0.718 Rec: 0.821 Prec: 0.832 | Created a Spatial-wise Cross-Attention (SCA) module that minimizes the semantic gap between the encoder and decoder subnetworks by merging the spatial attention maps. Introduced a TEBlock within the encoder to calculate pixel interaction, addressing the lack of global information obtained by CNNs. |
| [39] | Segmentation/Classification | Using both supervised and unsupervised learning | BUSI UDIAT | Acc: 0.99907 Sp: 0.9766 Se: 0.9977 | Tackled the problem of mask unavailability. |
| CSwin-PNet [40] | Segmentation | Pyramid Vision Transformer | UDIAT 780 Baheya Hospital ultrasound images | DSC: 0.8725 DSC: 0.8368 | Built a residual Swin transformer block (RSTB). Designed interactive channel attention (ICA) and supplementary feature fusion (SFF) modules. |
| 3D UNET [41] | Segmentation | 3D Deep Attentive U-Net with Transformer | Self collected dataset | DSC: 0.7636 Jac: 0.6214 HD: 15.47 Prec: 0.7895 Se: 0.7542 Sp: 0.9885 | Used 3D deep convolution NN |
| ViT-BUS [42] | Classification | Vision Transformers (ViTs) | BUSI+ Dataset B | Acc: 0.867 AUC: 0.95 | First application of ViTs to normal, malignant, and benign ultrasound image classification. |
| [14] | Classification | Semi-supervised vision transformer | DBUI BreakHis | Acc: 0.981 Prec: 0.981 Rec: 0.986 F1-core: 0.984 | Used a semi-supervised learning ViT. |
| BUVITNET [43] | Classification | Vision transformer/transfer learning | BUSI Mendeley breast ultrasound | Acc: 0.919 AUC: 0.937 F1-core: 0.919 MCC score:0.924 Kappa score:0.919 | Used transfer learning from cancer cell classification. |
| Hover-trans [44] | Classification | Horizontal and vertical transformers | UDIAT BUSI GDPH and SYSUCC | AUC: 0.92 Acc: 0.893 Spe: 0.836 Prec: 0.906 Rec: 0.926 F1-score:0.916 | Derived horizontal and vertical spatial information. |
| [45] | Localization/BI-RADS classifications | Vision transformer | Self collected dataset | Acc: 0.9489 Sp: 0.9509 Se: 0.941 | BI-RADS classification |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| [49] | Classification | Online-Net and Target-Net. | Self-collected data | Acc: 0.8046; Malignant: Prec: 0.8267; Rec: 0.8662; F1-score: 0.7907; Benign: Prec: 0.7500; Rec: 0.6364; F1-score: 0.6885; | A self-supervised dual-head attentional bootstrap learning network (SDABL), including Online-Net and Target-Net. |
| [12] | Classification | ROI-scale and core-scale feature extraction | Self-collected data | Prec: 0.787; Se: 0.880; Sp: 0.512 AUROC: 0.803; | A micro-ultrasound dataset with biopsy result |
| Methods/ References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| [50] | Segmentation | CNN, Vision Transformer, | Self-collected data, the DDTI dataset, the Breast Ultrasound Images Data Set (BUID) | IoU: 0.810, DSC: 0.892; | Used boundary attention transformer net. |
| [51] | Segmentation | CNN, Vision Transformer, | Self-collected data | DSC: 84.76; Jac: 74.39; Miou: 86.5; Rec: 83.9; Prec: 86.5; | Used residual bottlenecks, transformer bottlenecks, two branch down-sampling blocks, and the long-range feature extractor composed of the vision transformer. |
| [52] | Segmentation Classification | Swin Transformer | Self-collected data | DSC: 82.41; Acc: 86.59; | The dynamic Swin transformer encoder and multi-level feature collaborative learning are combined into U-net. |
| [53] | Classification | CNN, Vision Transformer, | Self-collected data | Acc: 0.9738; Prec: 0.9699; Sp: 0.9739; Se: 0.9736; F1-score: 0.9717; F2-score: 0.9738; | Used ultrasound images and infrared thermal images simultaneously. Used CNN and transformer for feature extraction and vision transformer for feature fusion. |
| [54] | Classification | Hybrid CNN and ViT | Public CIM@LAB | F1: 96.67, Rec: 95.01, Prec: 98.51, Acc: 97.63, | A hybrid ViT model with a backbone CNN. |
| [55] | Classification | Hybrid CNN and Swin Transformer | Public dataset DDTI provided by the National University of Colombia, | Acc: 0.954; Sp: 0.958; Se: 0.975; AUC: 0.974; | Shallow and deep features are fused for classification. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| Improved UNet [57] | Segmentation | CNNs (Squeeze-and-Excitation (SE)) and transformer | CAMUS Dataset | DSC (for ED): 0.9252 HD (for ED): 11.04 mm DSC (for ES): 0.9264 HD (for ES): 12.35 mm | The proposed network architecture includes the introduction of the Three-Level Attention (TLA) module, utilizing attention mechanisms. The TLA module boosts the feature embedding. A transformer is integrated at the bottleneck. |
| IFT-Net [58] | Segmentation | Interactive fusion transformer network (IFT-Net) | 4485 A4C and 1623 PSAX echocardiography of pediatric dataset + CAMUS | Acc: 0.954 DSC (LVEndo and LVEpi): 0.9049 and 0.8046 | The novel interaction established between the convolution branch and the transformer branch enables the bidirectional fusion of local features and global context information. A parallel network of Dual-Path Transformers (DPTs) and CNN is introduced, enabling the effective fusion of local and global features through full-process dual-branch feature interactive learning. This system is applied to perform an automatic quantitative analysis of pediatric echocardiography. |
| Position Attention [59] | Segmentation | Position Attention Block + Atrous Spatial Pyramid Pooling (ASPP) | EchoNet-Dynamic dataset | DSC: 0.9145 Precision: 0.9079; Recall: 0.9278; F1-score: 0.9177 Jac: 0.8847 | Employs bicubic interpolation to produce high-resolution images. Integrates a position-aware attention to capture positional knowledge. |
| Segformer + Swin Transformer and K-Net [60] | Segmentation | Mixed Vision Transformer + Lightweight Segformer | EchoNet-Dynamic dataset | DSC (for Swin and Segformer): 0.9292 and 0.9279 | The technique employs basic post-processing by discarding segments with the largest pixel square, leading to more accurate segmentation outcomes. Two exclusive transformer automated deep-learning strategies are introduced for Left-Ventricle (LV) segmentation in echocardiography. These strategies aim to enhance missegmented outcomes via post-processing. |
| MAEF-Net [61] | Segmentation and Detection | Dual attention (DA) mechanism + atrous spatial pyramid pooling (EASPP) | EchoNet-Dynamic (10,030 videos) Private clinical dataset (2129 images) | DSC: 0.9310 MAE: 0.9281 | Captured heartbeat features, minimized noise, integrated a deep supervision mechanism, and employed spatial pyramid feature fusion. |
| [62] | Segmentation | gated axial attention | 480 transverse images | DSC: 0.919 | The network leveraged axial attention and dual-scale training to obtain detailed insights from long-range features, enabling the model to focus on important areas, ensuring its applicability across a wide range of medical imaging scenarios. |
| [63] | Aortic stenosis (AS) detection and severity classification | Temporal Deformable Attention (TDA) + MLP + Transformer | Private AS Dataset: 2247 patients and 9117 videos public dataset: TMED-2 577 patients | Acc (AS detection on private and dataset): 0.952 and 0.915 Acc (classification on private and dataset): 0.781 and 0.838% | Implemented a temporal loss method to boost sensitivity towards subtle movements in the Autonomic Vascular (AV) system. Applied temporal attention mechanisms to merge spatial data with temporal contextual information. Automatically identified key echo frames for classifier. |
| CarpNet [64] | Classification | Transformer network + Inception_Resnet_V2 | Private Dataset: 1773 case | Acc: 0. 71 | The first public unveiling of the application of the Carpentier functional classification in echocardiographic videos of the mitral valve. |
| Semi-supervised learning with NLP [65] | Right ventricular (RV) function and size classification | Text classification with 12-layer BERT model | 12,684 examinations with Swedish text dataset | Se and Sp (Text classifier for RV size): 0.98 and 0.98 Se and Sp (Text classifier for RV function): 0.99 and 0.98 Acc (A4C and view classification): 0.92 and 0.73 Se and Sp (The image classifier for RV size and function): 0.8 and 0.85 Se and Sp (The image classifier for RV function): 0.93 and 0.72 | Developed a pipeline for automatic image assessment using NLP models. Utilized model-annotated data from written echocardiography reports for training. Achieved significant improvement in sensitivity and specificity for identifying impaired RV function and enlarged RV. Demonstrated the potential of integrating auto-annotation within NLP applications. Showcased the capability for fast and cost-effective expansion of the training dataset. |
| UltraSwin [66] | Estimate the ejection fraction | hierarchical vision Transformers | EchoNet-Dynamic dataset | MAE: 5.59 | Calculated ejection fraction without requiring left-ventricle segmentation. |
| Ultrasound Video Transformers [11] | ES/ED detection and LVEF estimation | BERT model and Residual Auto-Encoder Network | Echonet-Dynamic dataset | Average Frame Distances of 3.36 Frames for ES and 7.17 Frames for ED, MAE(LVEF): 5.95 R2(LVEF): 0.52 | Developed an end-to-end learnable approach that allows for ejection fraction estimation without the need for segmentation. Introduced a modified transformer architecture capable of processing image sequences of varying lengths. |
| Co-attention spatial transformer [67] | Tracking | Co-Attention Spatial Transformer Network (STN) | Synthetic dataset + an in vivo 3D echocardiography dataset | MTE: 0.99 | Implementation of a spatial–temporal co-attention module within 3d echocardiography |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| RDHCformer [21] | Segmentation | Integrating transformer and CNN | HC18 dataset | MAE ± std (mm): 1.97 ± 1.89 | Rotating ellipse detection method was employed for skull edge detection, based on the anchor-free method. To address the challenge of angle regression, a Soft Stagewise Regression (SSR) strategy was introduced. Kullback–Leibler Divergence (KLD) loss was incorporated into the total loss function to enhance the regression accuracy. |
| TransFSM [68] | Segmentation | Hybrid transformer | HC18 dataset + seven clinical datasets | MAE (mm): 1.19 DSC: 0.9811 | Introduced a boundary-aware decoder for managing ambiguous boundaries. Designed a transformer auxiliary segment head for enhancing predicted masks. |
| DPC-MSGATNet [69] | Segmentation | Interactive dual-path chain gated axial-transformer (IDPCGAT) | 556 FC views | F1 score: 0.9687 IoU: 0.9399 | DPC-MSGATNet was developed with a global and a local branch network, allowing for the simultaneous handling of the full image and its smaller segments. |
| Fetal plane detection [70] | Classification | Swin Transformer + Evidential Dempster–Shafer Based CNN | BCNatal: 12,400 images | Acc: 0.889 | Utilized an evidentiary classifier, specifically the Dempster–Shafer Layer, in conjunction with a custom-designed CNN for fetal plane detection. Implemented an end-to-end learnable approach for sample classification, exploring the effects of the Swin transformer, which is infrequently used in ultrasound fetal planes analysis. |
| COMFormer [71] | Classification | Residual cross-variance attention (R-XCA) | BCNatal: 12,400 images | Acc (maternal-fetal): 0.9564 Acc (brain anatomy): 0.9633 | The COMFormer model employs a R-XCA block, leveraging residual connections to decrease gradients and boost the learning process. |
| placental ultrasound image texture evolution [72] | Classification | Vision transformer (ViT) | 1008 cases | Acc (T1 and T2 images): 0.6949 Acc (T2 and T3 images): 0.7083 Acc (T1 and T3 images): 0.8413 | Evaluated three deep learning models and found that the transfer learning model achieved the highest accuracy. |
| CIDNet [73] | Classification | MI-DTC (multi-stance deformable transformer classification) | 9999 images | balance Acc (BACC): 0.8464 AUC: 0.9716 | Utilized four CNN-based models as backbone networks for pre-processing. Implemented an effective cropping procedure in the pre-processing module. Multi-weighted new loss function led to improvement. Application of Gaussian blurring curriculum was confirmed to fix the texture bias. |
| BabyNet [74] | Regression | Residual Transformer Module in the 3D ResNet | 225 2D fetal ultrasound videos | MAPE: 7.5 + 0.66 | Presented a new methodology for predicting birth weight, which is derived directly from fetal ultrasound video scans. Leveraged a novel residual transformer module. |
| [75] | Regression | BabyNet | 900 routine fetal ultrasound examinations | MAPE: 3.75 + 2.00%. | There is no significant difference observed between fetal weight predictions made by human experts and those generated by a deep network |
| BabyNet++ [76] | Regression | Residual Transformer with Dynamic Affine Feature Transform Maps (DAFT) | 582 2D fetal ultrasound videos | MAPE: 5.1 + 0.6 | Demonstrated that BabyNet++ outperforms expert clinicians. Proved that BabyNet++ is less sensitive to clinical data. |
| Transformer-VLAD [77] | Image retrieval | Transformer-VLAD (vector of locally aggregated descriptors) | ScanTrainer Simulator (535,775 US images) | recall@top1: 0.834 | The task of directing the movement of the US probe was addressed as a landmark retrieval issue, utilizing a learned descriptor search method. A transformer–VLAD network was specifically developed to facilitate automatic landmark retrieval. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| U-CSWT [79] | Segmentation | U-shaped CSWin transformer | 213 3D ultrasound Images | DSC (MAB in the common carotid artery): 0.946 DSC (LIB in the common carotid artery): 0.908 | This method employs a novel approach to descriptor learning, which is accomplished through contrastive learning. This technique makes use of self-constructed anchor positive–negative pairs of ultrasound images. |
| RMFG_Net [19] | Segmentation | Transformer-based Cross-scale Spatial Location (TCSL) | DT dataset: 157 | DSC: 0.8598 IoU: 0.7922 HD (mm): 11.66 | A proposed Spatial–Temporal Feature Filter (STFF) learns more target information from low-level features. A multilayer gated fusion model is introduced for efficient information propagation, reducing noise during fusion. |
| BP-Net [80] | Classification | Boundary and perfusion network (BP-Net) + multi-modal fusion block | 245 US and CEUS videos | Acc: 0.9235 AUC: 0.935 | A multi-modal fusion block is incorporated to delve deeper into the internal/external characteristics of the plaque and highlight more influential features across US and contrast-enhanced ultrasound (CEUS) videos. It capitalizes on the sturdiness of CNN and the refined global modeling of transformers, leading to more precise classification results. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| DaViT [81] | Segmentation | A dual attention vision transformer (DaViT) | LUS dataset: 202 | Acc (FL scoring): 0.9508 Acc (VL scoring): 0.9259 | Used a long–short-term memory (LSTM) module for correlation analysis. |
| Nehary [82] | Classification | Vision transformer (ViT) | lung ultrasound images (LUS) dataset: 202 | Acc: 0.8666 | The advantages of ViT models include their ability to extract abstract features, leverage transfer learning, utilize transformer encoding for spatial context understanding, and perform accurate final classification. |
| POCFormer [17] | Classification | Vision transformer and a linear transformer | 212 US videos | Acc: 0.939 | Lightweight transformer architecture. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| [83] | Classification | Vision transformer (ViT) | 13,970 images | Acc: 0.929 | Standardized the medical examination of the liver in adults. |
| Ultra-Attention [84] | Classification | Transformer | 14,900 images | Acc: 0.932 | Accurately identified standard sections by considering the coupling of anatomic structures within the images. |
| DETR [13] | Detection | Vision transformer and a linear transformer | 1026 patients | Sp: 0.90 Se: 0.97 | Detecting, localized, and characterized focal liver lesions. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| POST-IVUS [85] | Segmentation | Selective transformer | IVUS-2011 | Jac: 0.92 | Segmentation by combining Fully Convolutional Networks (FCNs) with temporal context-based feature encoders. |
| MSP-GAN [20] | Classification | Vision transformer and a linear transformer | 212 US videos | Acc: 0.939 | Domain adaptation in IVUS. |
| Methods /References | Task | Architecture | Dataset | Evaluation Metrics | Highlights |
|---|---|---|---|---|---|
| [86] | Segmentation | Medical Transformer (MedT) | 5321 ultrasound images | DSC: 0.894 | Developed image-guided therapy (IGT) for visualization of distal humeral Cartilage. |
| LAEDNet [87] | Segmentation | Lightweight Attention Encoder–Decoder Network + Lightweight Residual Squeeze-and-Excitation (LRSE) | Brachial Plexus (BP) Dataset Breast Ultrasound Images Dataset (BUSI) Head Circumference Ultrasound (HCUS) Dataset | DSC (BP): 0.73 DSC (BUSI): 0.738 DSC (HCUS): 0.913 | The LAEDNet’s unique asymmetrical structure plays a crucial role in minimizing network parameters, thereby accelerating the inference process. A compact decoding block named LRSE has been developed, which employs an attention mechanism for smooth integration with the LAEDNet backbone. |
| TMUNet [88] | Segmentation | Vision transformer + The contextual attention network (TMUNet) | 2005 transverse ultrasound | DSC: 0.96 | Providing additional knowledge to ensure the execution of the previously mentioned tasks. |
| PCT [89] | Segmentation | Pyramid Convolutional Transformer (PCT) | PGTSeg (parotid gland tumor segmentation) dataset: 365 images | IoU: 0.8434 DSC: 0.9151 | The transformer branch incorporates an enhanced version of the multi-head attention mechanism, referred to as the multi-head fusion attention (MHFA) module. |
| Depthwise Swin Transformer [16] | Classification | Swin transformer | 2268 ultrasound images (1146 cases) | Acc: 0.8065 Se: 0.8068 Sp: 0.7873 F1 value: 0.7942 | Introduces a comprehensive approach for categorizing cervical lymph node levels in ultrasound images. Employs model that combines depthwise separable convolutions with transformer architecture, along with a novel loss function. |
| [90] | Feature extraction + Classification | Vision transformer (ViT) | 278 images | Acc: 0.92 AUC: 0.92 | Vision transformer is employed as a feature extractor, while a Support Vector Machine (SVM) acts as the classifier. |
| MedViT [91] | Classification | Medical Vision Transformer (MedViT) | BreastMNIST: 780 breast ultrasound | AUC: 0.938 Acc: 0.897 | To improve both the generalization performance and adversarial resilience, the authors aim to increase the model’s reliance on global structure features rather than texture information. They do this by calculating the mean and variance of the training examples along the channel dimensions in the feature space and mixing them together. This method enables the exploration of new regions in the feature space that are mainly associated with global structure features. |
| CTN [92] | Plane-wave Imaging (PWI) | CTN: complex transformer network | 1700 samples | Contrast ratio: 11.59 dB contrast-to-noise ratio: 1.16 generalized contrast-to-noise ratio: 0.68 | A CTN was developed using complex convolution to manage envelope information and extract complex reconstruction features from complex IQ data. This resulted in a higher spatial resolution and contrast at significantly reduced computational costs. The Complex Self-Attention (CSA) module was developed based on the principles of the self-attention mechanism. This module assists in eliminating irrelevant complex reconstruction features, thus enhancing image quality. |
| SR-MT [15] | Localization | Swin transformer | 11,000 realistic synthetic datasets | Lateral localization precision (LP) (MB = 1.6 MBs/mm2): 15.0 DSC: 0.8 IoU: 0.66 | The research confirmed the effectiveness of the proposed method in precisely locating Microbubbles (MB) in synthetic data and the in vivo visualization of brain structures. |
| tip tracking [93] | Tracking | Visual tracking network | 3000 US images | Tracking success rate: 78% | Implemented a motion prediction system, based on the Transformer network. Constructed a visual tracking module leveraging dual mask sets to pinpoint the needle tip and minimize background noise. Constructed a robust data fusion system that combines the results from the motion prediction and visual tracking systems. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vafaeezadeh, M.; Behnam, H.; Gifani, P. Ultrasound Image Analysis with Vision Transformers—Review. Diagnostics 2024, 14, 542. https://doi.org/10.3390/diagnostics14050542
Vafaeezadeh M, Behnam H, Gifani P. Ultrasound Image Analysis with Vision Transformers—Review. Diagnostics. 2024; 14(5):542. https://doi.org/10.3390/diagnostics14050542
Chicago/Turabian StyleVafaeezadeh, Majid, Hamid Behnam, and Parisa Gifani. 2024. "Ultrasound Image Analysis with Vision Transformers—Review" Diagnostics 14, no. 5: 542. https://doi.org/10.3390/diagnostics14050542
APA StyleVafaeezadeh, M., Behnam, H., & Gifani, P. (2024). Ultrasound Image Analysis with Vision Transformers—Review. Diagnostics, 14(5), 542. https://doi.org/10.3390/diagnostics14050542