
The Role of Large Language Models (LLMs) in Providing Triage for Maxillofacial Trauma Cases: A Preliminary Study

 ,
,  , , ,
, , ,  ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patients and Triage System
2.2. Prompt Design
2.3. LLMs Answer Evaluation: QAMAI and AIPI
2.4. Statistical Analysis
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miragall, M.F.; Knoedler, S.; Kauke-Navarro, M.; Saadoun, R.; Grabenhorst, A.; Grill, F.D.; Ritschl, L.M.; Fichter, A.M.; Safi, A.-F.; Knoedler, L. Face the Future-Artificial Intelligence in Oral and Maxillofacial Surgery. J. Clin. Med. 2023, 12, 6843. [Google Scholar] [CrossRef] [PubMed]
- Baig, Z.; Lawrence, D.; Ganhewa, M.; Cirillo, N. Accuracy of Treatment Recommendations by Pragmatic Evidence Search and Artificial Intelligence: An Exploratory Study. Diagnostics 2024, 14, 527. [Google Scholar] [CrossRef] [PubMed]
- Cascino, F.; Pini, N.; Giovannoni, M.E.; Aboh, I.V.; Gabriele, G.; Niccolai, G.; Zerini, F.; Amadi, J.U.; Gennaro, P. Our Experience Managing Difficult Accidental Chainsaw Trauma. J. Craniofac. Surg. 2019, 30, 2207–2210. [Google Scholar] [CrossRef] [PubMed]
- Chu, Z.G.; Yang, Z.G.; Dong, Z.H.; Chen, T.W.; Zhu, Z.Y.; Deng, W.; Xiao, J.H. Features of cranio-maxillofacial trauma in the massive Sichuan earthquake: Analysis of 221 cases with multi-detector row CT. J. Craniomaxillofac. Surg. 2011, 39, 503–508. [Google Scholar] [CrossRef] [PubMed]
- Cascino, F.; Cerase, A.; Gennaro, P.; Latini, L.; Fantozzi, V.; Gabriele, G. Multidisciplinary evaluation of orbital floor fractures: Dynamic MRI outcomes. Orbit 2023, 42, 592–597. [Google Scholar] [CrossRef] [PubMed]
- Gabriele, G.; Nigri, A.; Pini, N.; Carangelo, B.R.; Cascino, F.; Fantozzi, V.; Funaioli, F.; Luglietto, D.; Gennaro, P. COVID-19 pandemic: The impact of Italian lockdown on maxillofacial trauma incidence in southern Tuscany. Ann. Ital. Chir. 2022, 92, 135–139. [Google Scholar]
- Wang, T.T.; Lee, C.C.; Luo, A.D.; Hajibandeh, J.T.; Peacock, Z.S. Using Telemedicine to Guide Interfacility Transfer for Facial Trauma. J. Oral Maxillofac. Surg. 2023, 81, 387–388. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Moon, J.T.; Purkayastha, S.; Celi, L.A.; Trivedi, H.; Gichoya, J.W. Ethics of large language models in medicine and medical research. Lancet Digit. Health 2023, 5, e333–e335. [Google Scholar] [CrossRef]
- Liu, H.Y.; Alessandri-Bonetti, M.; Arellano, J.A.; Egro, F.M. Can ChatGPT be the Plastic Surgeon’s New Digital Assistant? A Bibliometric Analysis and Scoping Review of ChatGPT in Plastic Surgery Literature. Aesthetic. Plast. Surg. 2023. [Google Scholar] [CrossRef] [PubMed]
- Frosolini, A.; Franz, L.; Benedetti, S.; Vaira, L.A.; de Filippis, C.; Gennaro, P.; Marioni, G.; Gabriele, G. Assessing the accuracy of ChatGPT references in head and neck and ENT disciplines. Eur. Arch. Otorhinolaryngol. 2023, 280, 5129–5133. [Google Scholar] [CrossRef]
- Gan, R.K.; Ogbodo, J.C.; Wee, Y.Z.; Gan, A.Z.; González, P.A. Performance of Google bard and ChatGPT in mass casualty incidents triage. Am. J. Emerg. Med. 2024, 75, 72–78. [Google Scholar] [CrossRef] [PubMed]
- Thompson, L.; Hill, M.; Lecky, F.; Shaw, G. Defining major trauma: A Delphi study. Scand. J. Trauma. Resusc. Emerg. Med. 2021, 29, 63. [Google Scholar] [CrossRef] [PubMed]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Bolzoni, A.; Committeri, U.; Crimi, S.; et al. Accuracy of ChatGPT-Generated Information on Head and Neck and Oromaxillofacial Surgery: A Multicenter Collaborative Analysis. Otolaryngol. Head Neck Surg. 2023. [Google Scholar] [CrossRef] [PubMed]
- Jacob, J. ChatGPT: Friend or Foe?-Utility in Trauma Triage. Indian J. Crit. Care Med. 2023, 27, 563–566. [Google Scholar] [CrossRef] [PubMed]
- Fraser, H.; Crossland, D.; Bacher, I.; Ranney, M.; Madsen, T.; Hilliard, R. Comparison of Diagnostic and Triage Accuracy of Ada Health and WebMD Symptom Checkers, ChatGPT, and Physicians for Patients in an Emergency Department: Clinical Data Analysis Study. JMIR Mhealth Uhealth 2023, 11, e49995. [Google Scholar] [CrossRef] [PubMed]
- Gebrael, G.; Sahu, K.K.; Chigarira, B.; Tripathi, N.; Thomas, V.M.; Sayegh, N.; Maughan, B.L.; Agarwal, N.; Swami, U.; Li, H. Enhancing Triage Efficiency and Accuracy in Emergency Rooms for Patients with Metastatic Prostate Cancer: A Retrospective Analysis of Artificial Intelligence-Assisted Triage Using ChatGPT 4.0. Cancers 2023, 15, 3717. [Google Scholar] [CrossRef] [PubMed]
- Masalkhi, M.; Ong, J.; Waisberg, E.; Lee, A.G. Google DeepMind’s gemini AI versus ChatGPT: A comparative analysis in ophthalmology. Eye 2024. [Google Scholar] [CrossRef] [PubMed]
- Carlà, M.M.; Gambini, G.; Baldascino, A.; Giannuzzi, F.; Boselli, F.; Crincoli, E.; D’onofrio, N.C.; Rizzo, S. Exploring AI-chatbots’ capability to suggest surgical planning in ophthalmology: ChatGPT versus Google Gemini analysis of retinal detachment cases. Br. J. Ophthalmol. 2024. [Google Scholar] [CrossRef] [PubMed]
- Sorin, V.; Glicksberg, B.S.; Artsi, Y.; Barash, Y.; Konen, E.; Nadkarni, G.N.; Klang, E. Utilizing large language models in breast cancer management: Systematic review. J. Cancer Res. Clin. Oncol. 2024, 150, 140. [Google Scholar] [CrossRef] [PubMed]
- Lechien, J.R.; Briganti, G.; Vaira, L.A. Accuracy of ChatGPT-3.5 and -4 in providing scientific references in otolaryngology-head and neck surgery. Eur. Arch. Otorhinolaryngol. 2024, 281, 2159–2165. [Google Scholar] [CrossRef] [PubMed]
- Suárez, A.; Jiménez, J.; de Pedro, M.L.; Andreu-Vázquez, C.; García, V.D.-F.; Sánchez, M.G.; Freire, Y. Beyond the Scalpel: Assessing ChatGPT’s potential as an auxiliary intelligent virtual assistant in oral surgery. Comput. Struct. Biotechnol. J. 2023, 24, 46–52. [Google Scholar] [CrossRef] [PubMed]
- Abou-Abdallah, M.; Dar, T.; Mahmudzade, Y.; Michaels, J.; Talwar, R.; Tornari, C. The quality and readability of patient information provided by ChatGPT: Can AI reliably explain common ENT operations? Eur. Arch. Otorhinolaryngol. 2024. [Google Scholar] [CrossRef] [PubMed]
- Crook, B.S.; Park, C.N.; Hurley, E.T.; Richard, M.J.; Pidgeon, T.S. Evaluation of Online Artificial Intelligence-Generated Information on Common Hand Procedures. J. Hand. Surg. Am. 2023, 48, 1122–1127. [Google Scholar] [CrossRef] [PubMed]
- Funk, P.F.; Hoch, C.C.; Knoedler, S.; Knoedler, L.; Cotofana, S.; Sofo, G.; Dezfouli, A.B.; Wollenberg, B.; Guntinas-Lichius, O.; Alfertshofer, M. ChatGPT’s Response Consistency: A Study on Repeated Queries of Medical Examination Questions. Eur. J. Investig. Health Psychol. Educ. 2024, 14, 657–668. [Google Scholar] [CrossRef] [PubMed]
- Scherr, R.; Halaseh, F.F.; Spina, A.; Andalib, S.; Rivera, R. ChatGPT Interactive Medical Simulations for Early Clinical Education: Case Study. JMIR Med. Educ. 2023, 9, e49877. [Google Scholar] [CrossRef] [PubMed]
- Riestra-Ayora, J.; Vaduva, C.; Esteban-Sánchez, J.; Garrote-Garrote, M.; Fernández-Navarro, C.; Sánchez-Rodríguez, C.; Martin-Sanz, E. ChatGPT as an information tool in rhinology. Can we trust each other today? Eur. Arch. Otorhinolaryngol. 2024. [Google Scholar] [CrossRef] [PubMed]
- Navalesi, P.; Oddo, C.M.; Chisci, G.; Frosolini, A.; Gennaro, P.; Abbate, V.; Prattichizzo, D.; Gabriele, G. The Use of Tactile Sensors in Oral and Maxillofacial Surgery: An Overview. Bioengineering 2023, 10, 765. [Google Scholar] [CrossRef]
- Li, W.; Chen, J.; Chen, F.; Liang, J.; Yu, H. Exploring the Potential of ChatGPT-4 in Responding to Common Questions About Abdominoplasty: An AI-Based Case Study of a Plastic Surgery Consultation. Aesthetic. Plast. Surg. 2023. [Google Scholar] [CrossRef]
- Javadi, N.; Rostamnia, L.; Raznahan, R.; Ghanbari, V. Triage Training in Iran from 2010 to 2020: A Systematic Review on Educational Intervention Studies. Iran J. Nurs. Midwifery Res. 2021, 26, 189–195. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.Y.; Liu, X.C.; Pour Nejatian, N.; Nasir-Moin, M.; Wang, D.; Abidin, A.; Eaton, K.; Riina, H.A.; Laufer, I.; Punjabi, P.; et al. Health system-scale language models are all-purpose prediction engines. Nature 2023, 619, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Smith, A.L.; Greaves, F.; Panch, T. Hallucination or Confabulation? Neuroanatomy as metaphor in Large Language Models. PLOS Digit. Health 2023, 2, e0000388. [Google Scholar] [CrossRef] [PubMed]
- Azamfirei, R.; Kudchadkar, S.R.; Fackler, J. Large language models and the perils of their hallucinations. Crit. Care 2023, 27, 120. [Google Scholar] [CrossRef] [PubMed]
- Guillen-Grima, F.; Guillen-Aguinaga, S.; Guillen-Aguinaga, L.; Alas-Brun, R.; Onambele, L.; Ortega, W.; Montejo, R.; Aguinaga-Ontoso, E.; Barach, P.; Aguinaga-Ontoso, I. Evaluating the Efficacy of ChatGPT in Navigating the Spanish Medical Residency Entrance Examination (MIR): Promising Horizons for AI in Clinical Medicine. Clin. Pract. 2023, 13, 1460–1487. [Google Scholar] [CrossRef]
- Sahin, M.C.; Sozer, A.; Kuzucu, P.; Turkmen, T.; Sahin, M.B.; Sozer, E.; Tufek, O.Y.; Nernekli, K.; Emmez, H.; Celtikci, E. Beyond human in neurosurgical exams: ChatGPT’s success in the Turkish neurosurgical society proficiency board exams. Comput. Biol. Med. 2024, 169, 107807. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Liu, C.; Yang, J.; Weng, C. Fine-tuning Large Language Models for Rare Disease Concept Normalization. bioRxiv 2023. [Google Scholar] [CrossRef]
- Frosolini, A.; Gennaro, P.; Cascino, F.; Gabriele, G. In Reference to “Role of Chat GPT in Public Health”, to Highlight the AI’s Incorrect Reference Generation. Ann. Biomed. Eng. 2023, 51, 2120–2122. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Date of Incident | Age, Sex | Comorbidities | Nature of Injury | Maxillofacial Fractures | Concomitant Injuries | |
|---|---|---|---|---|---|---|
| Case 1 | October 2023 | 9, Female | None | Car accident | Orbital floor, nasal, maxillary | None |
| Case 2 | April 2023 | 15, male | None | Car accident | Mandibular | Cerebral, arm-wrist |
| Case 3 | January 2023 | 40, male | AIDS | Aggression | Mandibular | None |
| Case 4 | November 2023 | 51, female | Cerebral Palsy | Domestic Fall | Mandibular | None |
| Case 5 | November 2023 | 35, male | None | Aggression | Frontal bone, Orbital roof and medial wall, nasal septum | None |
| Case 6 | May 2023 | 41, male | None | Car Accident | Maxillary, zygomatic, orbit, nasal bones | Cerebral |
| Case 7 | April 2023 | 28, male | None | Bike accident | Mandibular | Odontological |
| Case 8 | October 2023 | 64, female | None | Domestic fall | Zygomatic, orbital floor, | Cerebral |
| Case 9 | February 2023 | 52, male | None | Car Accident | Mandibular | Odontological |
| Case 10 | January 2023 | 54, male | None | Aggression | Zygomatic, orbital floor, | None |
| Multidisciplinary Evaluation | Treatment | |||||
|---|---|---|---|---|---|---|
| ChatGPT 4.0 | GEMINI | Tertiary Referral Center | ChatGPT 4.0 | GEMINI | Tertiary Referral Center | |
| Case 1 | Ophthalmologist | Ophthalmologist | Opthalmologist | Observation, Orbital floor repair | Orbital floor repair | Orbital floor repair |
| Case 2 | Neurologist, orthopedic | NA | Neurologist, orthopedic | ORIF | ORIF | ORIF, post-operative rehabilitation |
| Case 3 | Infectious diseases | Dentist | NA | ORIF, antibiotics | ORIF; antibiotics | ORIF; antibiotic |
| Case 4 | NA | NA | NA | ORIF | ORIF | ORIF, post-operative rehabilitation |
| Case 5 | Neurologist, ophthalmologist | NA | Neurologist, ophthalmologist | ORIF, antibiotics | ORIF | ORIF, antibiotics, post-operative ICU |
| Case 6 | NA | Ophthalmologist, otolaryngologist | Neurologist, ophthalmologist | Orbital decompression, ORIF | ORIF, soft tissue reconstruction | ORIF, antibiotic |
| Case 7 | Dentist | Otolaryngologist | Dentist | ORIF, teeth splinting | ORIF, post-operative rehabilitation | ORIF, teeth splinting, post-operative rehabilitation |
| Case 8 | NA | NA | Ophthalmologist | ORIF | ORIF | ORIF |
| Case 9 | Dentist | NA | Dentist | ORIF, teeth splinting | Intermaxillary fixation | ORIF, teeth splinting, post-operative rehabilitation |
| Case 10 | NA | NA | Ophthalmologist | ORIF | ORIF | ORIF |
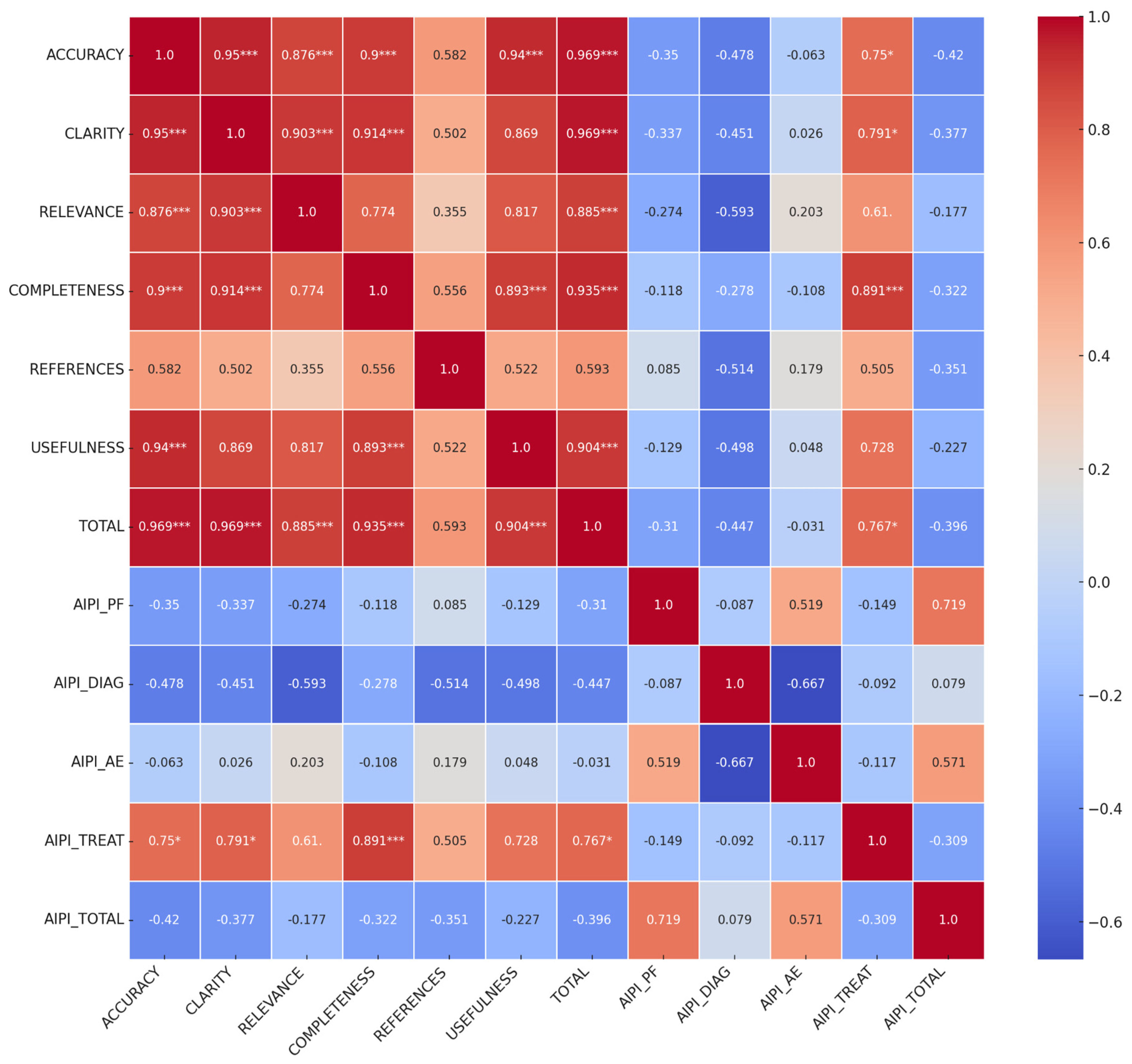
| Metric | GEMINI Mean (SD) | ChatGPT Mean (SD) | p-Value |
|---|---|---|---|
| AIPI: Patient Feature | 2.83 (0.89) | 2.75 (1.27) | 0.859 |
| AIPI: Diagnosis | 3.30 (0.66) | 2.30 (1.32) | 0.032 * |
| AIPI: Additional Examination | 1.50 (0.77) | 2.00 (1.33) | 0.327 |
| AIPI: Treatment | 1.86 (0.39) | 2.10 (0.57) | 0.150 |
| AIPI: Total | 9.50 (1.98) | 7.60 (2.59) | 0.052 |
| QAMAI: Accuracy | 3.03 (0.29) | 3.10 (0.99) | 0.802 |
| QAMAI: Clarity | 3.47 (0.36) | 3.50 (0.88) | 0.902 |
| QAMAI: Relevance | 2.90 (0.35) | 3.50 (0.88) | 0.021 * |
| QAMAI: Completeness | 3.00 (0.47) | 2.9 (1.12) | 0.802 |
| QAMAI: References | 3.07 (0.41) | 2.65 (1.11) | 0.214 |
| QAMAI: Usefulness | 2.93 (0.30) | 3.20 (1.01) | 0.396 |
| QAMAI: Total | 18.40 (1.64) | 18.85 (5.37) | 0.765 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frosolini, A.; Catarzi, L.; Benedetti, S.; Latini, L.; Chisci, G.; Franz, L.; Gennaro, P.; Gabriele, G. The Role of Large Language Models (LLMs) in Providing Triage for Maxillofacial Trauma Cases: A Preliminary Study. Diagnostics 2024, 14, 839. https://doi.org/10.3390/diagnostics14080839
Frosolini A, Catarzi L, Benedetti S, Latini L, Chisci G, Franz L, Gennaro P, Gabriele G. The Role of Large Language Models (LLMs) in Providing Triage for Maxillofacial Trauma Cases: A Preliminary Study. Diagnostics. 2024; 14(8):839. https://doi.org/10.3390/diagnostics14080839
Chicago/Turabian StyleFrosolini, Andrea, Lisa Catarzi, Simone Benedetti, Linda Latini, Glauco Chisci, Leonardo Franz, Paolo Gennaro, and Guido Gabriele. 2024. "The Role of Large Language Models (LLMs) in Providing Triage for Maxillofacial Trauma Cases: A Preliminary Study" Diagnostics 14, no. 8: 839. https://doi.org/10.3390/diagnostics14080839
APA StyleFrosolini, A., Catarzi, L., Benedetti, S., Latini, L., Chisci, G., Franz, L., Gennaro, P., & Gabriele, G. (2024). The Role of Large Language Models (LLMs) in Providing Triage for Maxillofacial Trauma Cases: A Preliminary Study. Diagnostics, 14(8), 839. https://doi.org/10.3390/diagnostics14080839