1. Introduction
The integration of Artificial Intelligence (AI) in healthcare, particularly through Automatic Speech Recognition (ASR) systems, has been a subject of increasing interest in recent years. These systems, demonstrating significant potential in various medical applications, have revolutionized the way patient–physician interactions are transcribed and clinical documentation is managed [
1]. Recent explorations into online therapy platforms underscore ASR’s expanding role in mental health, where nuanced language processing enhances therapeutic outcomes [
2]. In the field of radiology, where accuracy and efficiency in reporting are paramount, the application of ASR technology can be particularly transformative, offering a new paradigm in the way radiologists work and interact with diagnostic data [
3]. Similarly, advancements in ASR for cochlear implants illustrate the technology’s potential to improve communication for individuals with hearing impairments, showcasing its adaptability to diverse healthcare needs [
4].
Despite the global advancements in ASR technology, its application within the French medical context has been limited. This gap is further addressed by recent studies leveraging Large Language Models to refine the accuracy of ASR in medical transcription, promising more reliable patient records [
5]. This gap is primarily due to the linguistic and terminological specificity required in medical ASR systems, which are often not met by general-purpose ASR tools [
6]. The development of a French-language medical ASR system is thus a technological and linguistic challenge, requiring a deep understanding of medical terminologies and the nuances of spoken French in a clinical setting [
7]. The need for extensive and specialized datasets, encompassing a wide range of medical terminologies, accents, and speech patterns specific to the medical profession, poses a significant hurdle [
7]. While the broader application of ASR technology shows immense promise, the French radiological sector presents unique challenges such as the need for highly specialized terminologies and the accommodation of diverse French dialects and accents, which our research specifically aims to address. However, this also presents an opportunity to develop tailored solutions that can significantly benefit the medical community, particularly in non-English-speaking regions. Recent studies have shown promising results in cross-lingual applications of ASR, adapting systems to work with low-resource languages [
8]. Moreover, the development of specialized ASR systems for healthcare chatbots in schools demonstrates this technology’s potential in pediatric care, contributing to early health assessments [
9].
While ASR’s impact spans across multiple medical disciplines, the field of radiology in French healthcare settings remains largely untapped, marked by a critical need for customized ASR solutions. Our research directly responds to this gap by offering an ASR system that is not only linguistically and terminologically precise but also attuned to the operational workflows of French radiologists, thereby promising a significant leap towards streamlined radiological reporting and enhanced diagnostic efficiencies.
The use of advanced neural network models and language processing techniques has been explored to enhance the accuracy and reliability of medical ASR systems [
10,
11]. These advancements are not only technical but also encompass a broader understanding of the medical field, ensuring that the developed systems are finely tuned to the specific needs of healthcare professionals. Amidst these advancements, our study carves out a distinct niche by developing an ASR system that not only caters to the French-speaking medical community but is also intricately tailored to the nuanced demands of radiological terminology and practices in Francophone countries. Such nuanced applications of ASR, from enhancing mental health support to improving medical equipment interaction, underscore the technology’s evolving role in facilitating comprehensive and personalized care [
12].
The primary objective of this research was to develop a specialized French-language ASR system, tailored for radiological applications. This system aims to facilitate radiologists in efficiently generating medical image reports, thereby enhancing the overall workflow in diagnostic procedures [
13]. The novelty of this project lies in its focus on creating a dedicated ASR tool for radiology, addressing the scarcity of French-language audio datasets in the medical domain. By leveraging machine learning techniques, specifically tailored for medical jargon and radiological terms, this tool aims to provide accurate and efficient transcription services [
14]. The potential of ASR in medicine is vast, ranging from automated transcriptions of medical reports to assisting in the drafting process, indexing medical data, and enabling voice-based queries in medical databases [
15].
The implications of ASR technology extend beyond radiology to other medical fields. For instance, in emergency medical services, ASR has been assessed for its impact on stroke detection, showing potential for improving response times and diagnostic accuracy [
16]. In long-term care for older adults, ASR models have been used to facilitate interview data transcription, saving time and resources [
17]. Even in operating rooms, ASR techniques can be used to improve the dialogue between the surgeon and their human (e.g., surgical nurses) or digital (e.g., robotic arms) assistants [
18,
19]. Additionally, in pediatric care, ASR and voice interaction technologies have been explored for remote care management, demonstrating feasibility and effectiveness in tracking symptoms and health events [
20].
Recent reviews in the field of healthcare have highlighted significant advancements in Automatic Speech Recognition (ASR) technology and its diverse applications. These advancements underscore the transformative potential of ASR in healthcare, paving the way for more efficient, accurate, and patient-centered medical practices.
A comprehensive review of state-of-the-art approaches in ASR, speech synthesis, and health detection using speech signals has shed light on the current capabilities and future directions of speech technology in healthcare [
21]. This review emphasizes the growing importance of ASR in various healthcare settings, from clinical documentation to patient monitoring.
Another study explored the potential of real-time speech-to-text and text-to-speech converters, using Natural Language Grammar (NLG) and Abstract Meaning Representation (AMR) graphs, to enhance healthcare communication and documentation [
22]. This technology could revolutionize how medical professionals interact with electronic health records, making the process more intuitive and efficient.
The robustness of ASR systems in noisy environments, a common challenge in medical settings, has also been a focus of recent research [
23]. Enhancing the noise robustness of ASR systems is crucial for their effective deployment in diverse healthcare environments, from busy emergency rooms to outpatient clinics.
Furthermore, a systematic literature review on various techniques within the domain of speech recognition provides a comprehensive understanding of the advancements and challenges in this field [
24]. This review highlights the rapid evolution of ASR technology and its increasing relevance in healthcare.
In addition to these technical advancements, the integration of ASR with patient-reported outcomes and value-based healthcare has been explored [
25]. This integration signifies a shift towards more personalized and patient-centered healthcare models, where patient voices and experiences are directly captured and analyzed through advanced speech recognition technologies.
These reviews and studies collectively illustrate the significant strides made in ASR technology and its increasing applicability in healthcare. From enhancing clinical workflows to improving patient engagement, ASR technology is set to play a pivotal role in the future of healthcare delivery.
3. Results
The comprehensive fine-tuning process of the Whisper Large-v2 model revealed significant insights into the model’s performance under various training configurations. Initially, the training parameters were meticulously configured using the Seq2SeqTrainingArguments object from the Transformers library. Key parameters such as the batch size, learning rate, and warmup steps were strategically selected to optimize the model’s performance. Notably, a learning rate of was employed, which emerged as the most effective in enhancing the model’s accuracy, as evidenced by a notable decrease in both the Word Error Rate (WER) and Normalized Word Error Rate (Normalized WER).
In the evaluation metrics, both the Word Error Rate (WER) and Normalized Word Error Rate (Normalized WER) are reported. The inclusion of the Normalized WER offers insights into the transcription accuracy post the application of text normalization techniques. Such a metric serves as an adjusted measure, more reflective of the model’s ability to accurately decipher and transcribe medical radiology speech content. The Normalized WER evaluates the transcription’s core content fidelity, discounting variations due to punctuation, capitalization, and whitespace. This adjusted metric is crucial in a medical context where precise terminology is paramount. The observed consistent improvement in the Normalized WER over the standard WER underscores the model’s enhanced performance in transcribing detailed medical terminologies accurately.
The impact of different learning rates on the model’s performance was systematically evaluated (
Table 8). Our findings indicated that a learning rate of
led to promising results, particularly with a Normalized WER of 18.774% and a Normalized Character Error Rate (CER) of 12.103%. Additionally, the application of text normalization techniques significantly reduced the WER, underscoring the importance of this preprocessing step.
Further experiments were conducted to assess the influence of warmup steps on the model’s performance. The results showed that a warmup step of 1000 yielded the best performance, achieving a Normalized WER of 18.504% (
Table 9). This optimal configuration was thus subsequently adopted for further experimentation.
In addition to these parameters, this study delved into the optimization settings, particularly focusing on the Adam epsilon parameter. The optimizer’s configuration plays a crucial role in a model’s ability to converge to an optimal solution. Our experiments with different Adam epsilon values revealed significant variations in performance, as summarized in
Table 10. This table illustrates how subtle changes in the optimizer settings markedly influenced the model’s effectiveness, guiding us to select the most suitable configuration for our specific needs.
The exploration of the LORA model’s “R” parameter further demonstrated the impact of model configuration on performance. The configuration with R = 42 improved the model’s performance, indicating its effectiveness in enhancing the model’s transcription accuracy (
Table 11).
An additional layer of optimization focused on the Low-Rank Adaptation (LORA) technique’s dropout parameter, Lora_dropout. A systematic comparison was undertaken to determine the most effective Lora_dropout value for the model, with the objective being to optimize the balance between reducing overfitting and preserving model performance. The comprehensive results of this comparison are presented in
Table 12, illustrating that a Lora_dropout value of 0.04 resulted in the most favorable performance, evidenced by a Normalized Word Error Rate (WER) of 17.121%. This optimal Lora_dropout setting contributed significantly to the model’s enhanced transcription accuracy.
The final chosen configuration, achieving a Normalized WER of 17.121%, represents the culmination of the fine-tuning efforts, incorporating the ideal Lora_dropout value. This refined configuration underscores the effectiveness of the fine-tuning strategy in enhancing the transcription accuracy for medical radiology terms.
The fine-tuning of the Whisper Large-v2 model yielded significant improvements in the transcription accuracy. This process culminated in a final Word Error Rate (WER) of 17.121%, accompanied by a training loss of 0.210 and a validation loss of 0.448.
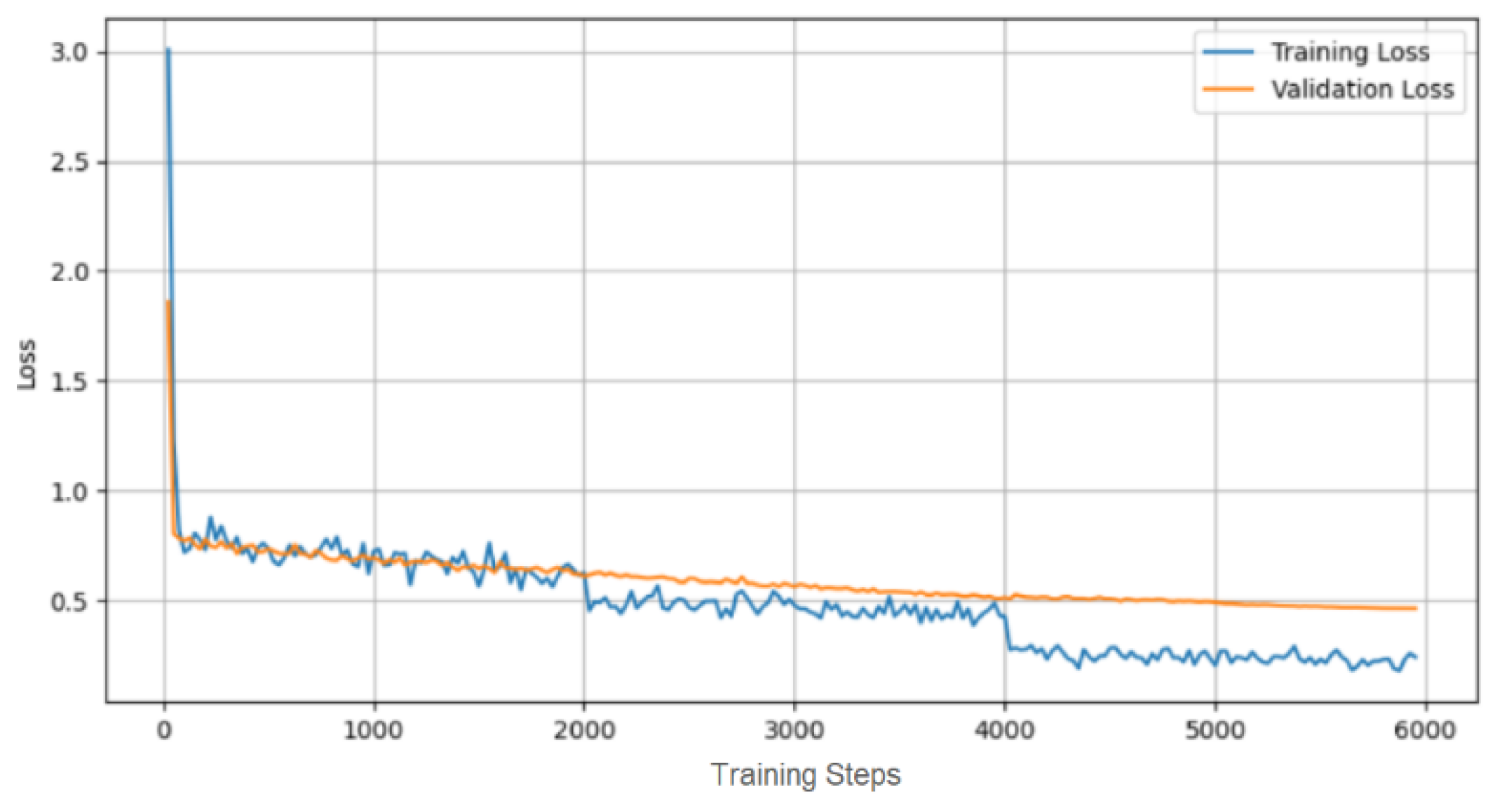
These metrics demonstrate the effectiveness of the fine-tuning strategy in enhancing the model’s performance for medical radiology term transcription. The progression of the training and validation loss over the fine-tuning period is illustrated in the loss curves shown in
Figure 5, providing a visual representation of the model’s learning trajectory.
Concurrently, we deployed the “WhisperMed Radiology Transcriber”, a speech recognition application, on an Amazon Web Services (AWS) server. This application utilizes the fine-tuned Whisper Large-v2 model to provide high-accuracy transcriptions of medical radiology terms. Key features of this application include real-time transcription capabilities and an intuitive user interface, designed to meet the specific needs of medical professionals.
4. Discussion
This study’s integration of the Whisper Large-v2 model into radiological applications marks a significant advancement in medical Automatic Speech Recognition (ASR) systems. Demonstrating high accuracy in transcribing complex medical terminology, the model’s effectiveness across diverse audio environments is a testament to its adaptability in various medical settings. This adaptability is crucial considering the acoustic complexities inherent in different medical fields. The success of AI-driven speech recognition systems in both general healthcare communication and specialized areas like radiation oncology ([
28,
29]) underscores their potential to revolutionize medical data processing across a spectrum of clinical contexts [
30].
In clinical practices, the application of the proposed ASR system holds immense promise. The traditional process of transcribing diagnostic reports is often fraught with human error and inefficiency. By enhancing the accuracy and efficiency of medical documentation, this system stands to significantly improve the quality of patient care, as accurate records are vital for effective treatment planning [
31]. Within the context of real-world application, the “WhisperMed Radiology Transcriber” stands as a Minimum Viable Product (MVP) designed specifically for radiologists. The development of this application is a direct response to the need for efficient, accurate medical transcription in radiology, aiming to minimize the time spent on generating reports while maximizing the accuracy of reports. Although the application is in its early stages, preliminary feedback from a selected group of radiologists has been promising, indicating a strong potential for integration into daily clinical practices. Future iterations of this application will focus on extensive testing with a larger cohort of medical professionals to fine-tune its functionalities and ensure seamless integration with existing hospital information systems.
Recognizing the need for a deeper analysis of our model’s performance, we acknowledge that a comprehensive error analysis, particularly focusing on different types of data within the radiological domain, would provide valuable insights into the model’s specific strengths and areas in need of improvement. Additionally, while our study highlights the model’s effectiveness in transcribing complex medical terminology, a direct comparison with established French ASR baseline models, especially those previously applied in medical contexts, remains an area for future exploration. These comparisons would not only benchmark the Whisper Large-v2 model’s performance but also pave the way for more targeted improvements, especially in handling the unique challenges presented by French medical terminology and diverse accents. Future research will aim to fill these gaps, offering a more detailed understanding of the model’s performance nuances and its standing relative to existing French ASR solutions in healthcare. Additionally, integrating ASR systems with electronic health records (EHRs) could transform healthcare data management, reducing the administrative load on medical professionals and enabling a greater focus on patient care [
32].
However, the implementation of ASR in healthcare is challenging. The system must navigate a vast array of medical terminologies, accents, and speech nuances. This research represents progress in this area, but ongoing refinement is essential to meet the stringent accuracy requirements of medical data transcription [
33]. Addressing these challenges, particularly in non-English languages, remains a key area for future development. Studies on language-specific medical ASR solutions, such as those in Korean and French, highlight both the challenges and opportunities in creating effective multilingual medical ASR system [
28,
29,
30].
The “WhisperMed Radiology Transcriber” serves as the tangible outcome of this research, specifically addressing the requirements of the radiological sector. As a Minimum Viable Product (MVP), this tool seeks to enhance report generation efficiency by providing accurate medical transcriptions tailored for radiology. Initial evaluations by a select cohort of radiologists have indicated positive reception, suggesting its potential for broader applications in clinical routines. Future developments will concentrate on comprehensive real-world evaluations to refine the application, ensuring its seamless integration with existing hospital information infrastructures and compliance with stringent medical documentation standards.
Beyond its clinical applications, this ASR system offers significant benefits in medical education. By facilitating the transcription of educational materials, it enhances accessibility and inclusivity, particularly for non-native speakers. This aligns with the digitalization trend in medical education, where technology is becoming increasingly pivotal in enriching learning experiences [
33].
Future research avenues are abundant. Tailoring ASR systems to specific medical specialties or languages could greatly expand their utility. Exploring their integration with voice-activated medical devices and telemedicine platforms presents opportunities to further leverage ASR technology in healthcare [
34].
The current study, despite its successes, encountered limitations due to resource constraints, which restricted the dataset size and prolonged the training period. Future studies should aim to utilize larger datasets and more robust computational resources to improve accuracy and efficiency. Real-world testing in clinical settings is also crucial to assess the system’s practicality and identify areas for improvement.
The findings of this research contribute significantly to the medical ASR field, particularly in radiology transcription. The potential impact of this work on clinical practices, healthcare efficiency, and medical education underscores the vital role of technology in advancing healthcare solutions. Addressing the identified limitations, such as dataset diversity and practical application, will be essential in future research to fully realize the potential of ASR systems in healthcare.
5. Conclusions
This study’s development of an Automatic Speech Recognition (ASR) system specifically designed for radiological applications represents a significant advancement in the application of technology within the healthcare sector. Our successful integration of the Whisper Large-v2 model into the ASR system has led to a notable achievement: a Word Error Rate (WER) of 17.121%. This achievement underscores the system’s proficiency in accurately transcribing complex medical terminology and adapting to diverse accents, which are critical in radiological contexts.
The practical implications of this research are particularly significant in clinical settings. By automating the transcription of diagnostic reports, this ASR system addresses a key challenge in radiology—the need for accurate and efficient documentation. In light of our findings and the development of the “WhisperMed Radiology Transcriber”, this research contributes significantly to the field of medical Automatic Speech Recognition (ASR) systems. The proposed application, although currently a prototype, embodies the practical application of our research findings. It is designed to be a foundational step towards creating a more robust and comprehensive tool that can be integrated into radiology departments worldwide. Moving forward, the focus will be on expanding the application’s testing in real-world clinical environments. This will involve a series of pilot studies aimed at evaluating the application’s effectiveness in live radiological settings, thereby ensuring that the final product is both user-friendly and highly accurate, meeting the exacting standards of medical documentation.
This improvement is not just a matter of convenience; it plays a vital role in enhancing patient care by supporting informed decision making based on precise and reliable medical records.
Moreover, the potential integration of the ASR system with electronic health records (EHRs) could be a game changer in healthcare administration. Such integration promises to streamline data entry processes, reduce the administrative burden on healthcare professionals, and improve the accuracy of patient records. This aligns with the broader goal of effective healthcare delivery, where accuracy and efficiency are paramount.
While this study has achieved its primary objectives, it also highlights areas for future exploration. The potential of tailoring ASR systems to specific medical specialties or languages, and integrating them with voice-activated medical devices and telemedicine platforms [
35], presents exciting avenues for expanding the utility and impact of ASR in healthcare.
Despite its successes, this study faced limitations, primarily due to resource constraints. These limitations necessitated a training dataset of 20,000 examples and extended the training period to 14 days. Future research could benefit from larger datasets and more advanced computational resources to further enhance the accuracy and efficiency of ASR systems. Real-world testing in clinical environments is also crucial to validate the practical applicability of the system and to identify areas for improvement.
In summary, this research makes a significant contribution to the field of medical ASR systems, particularly in radiology. It offers a robust and efficient tool for medical transcription, with the potential to significantly impact clinical practices and the efficiency of healthcare services. Our findings pave the way for future innovations in technology-enhanced healthcare solutions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}