
PharmaKU: A Web-Based Tool Aimed at Improving Outreach and Clinical Utility of Pharmacogenomics

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Pharmacogenes
2.2. Calling Star Alleles
2.3. Diplotype–Phenotype Mapping
2.4. Implementation
3. Results
3.1. List of Genes Included in the Tool
3.2. Choice of Pharmacogenomic Tool for Calling Diplotypes
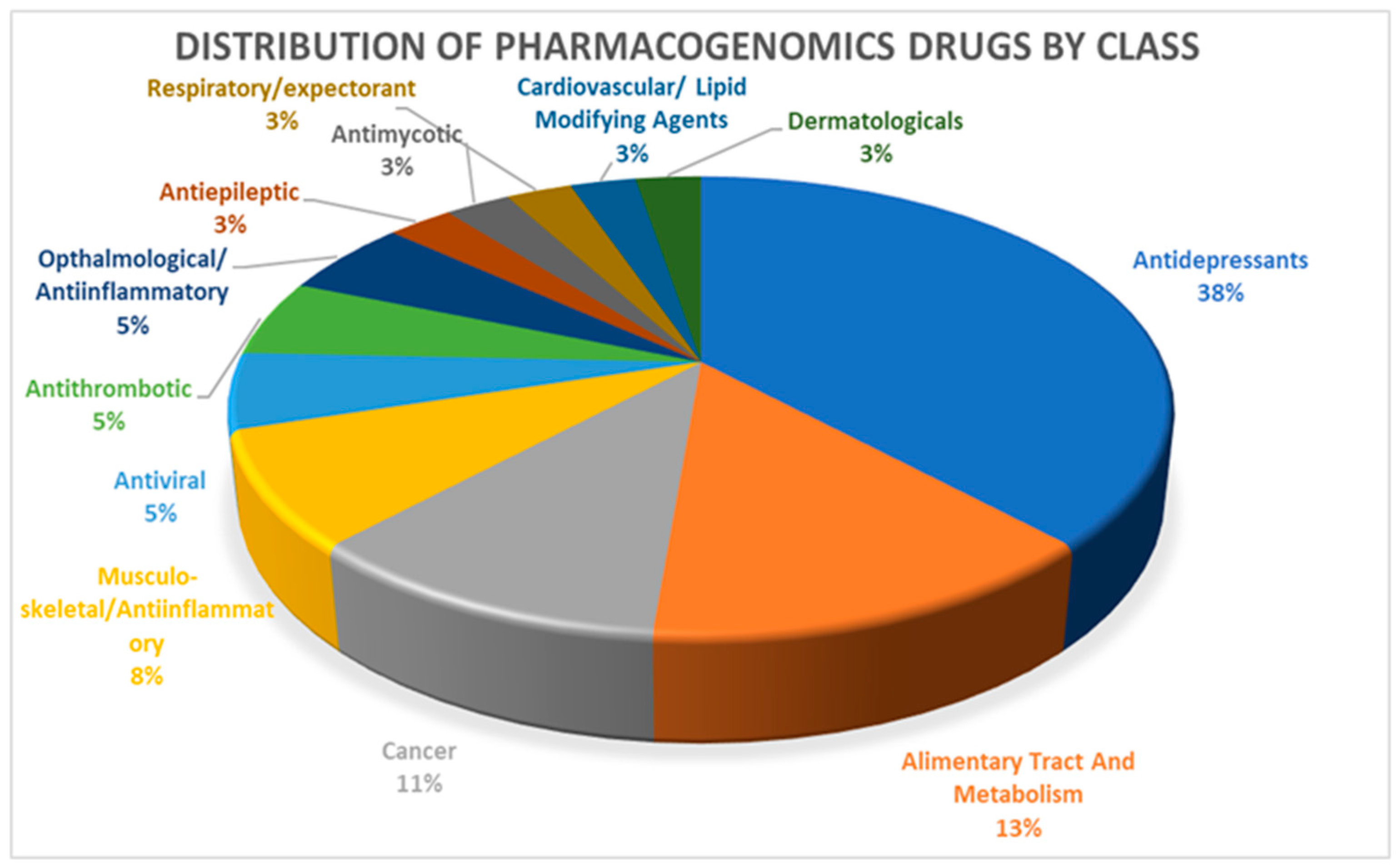
3.3. Drugs and Dosing Information
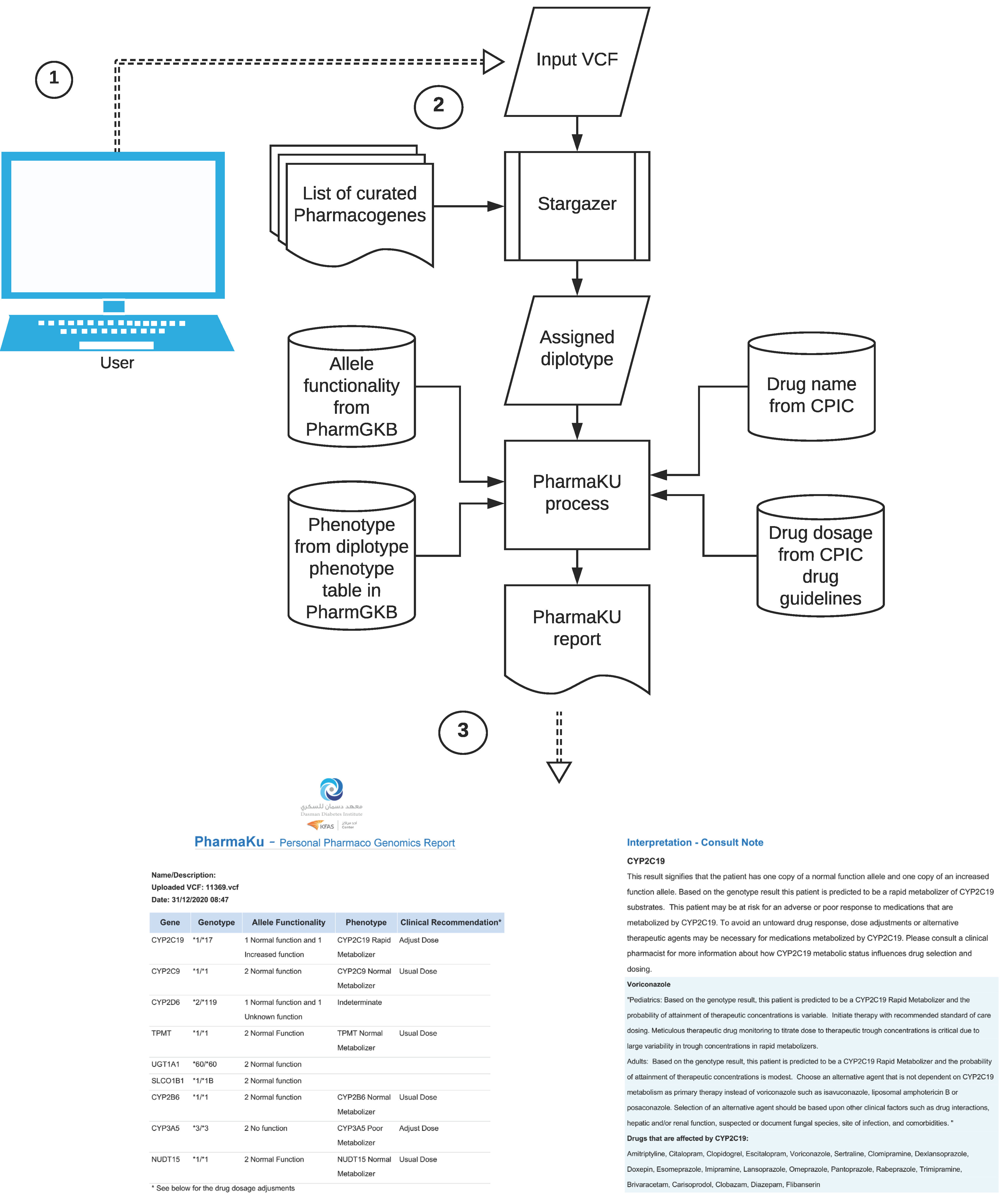
3.4. Using PharmaKU Software
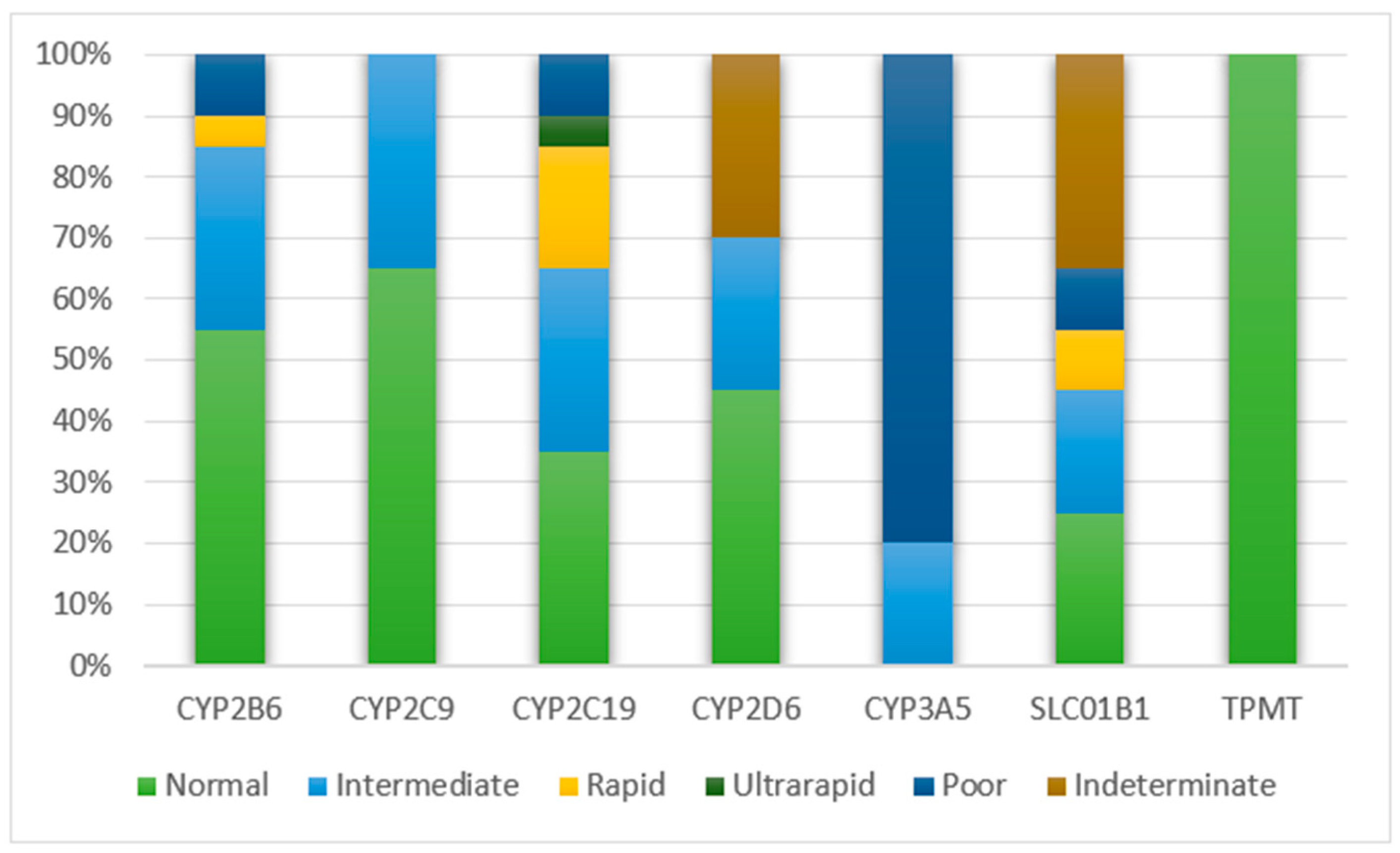
3.5. Report from 20 WGS Samples
3.6. Data Collaboration and Testing
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Urban, T.J.; Goldstein, D.B. Pharmacogenetics at 50: Genomic Personalization Comes of Age. Sci. Transl. Med. 2014, 6, 220ps1. [Google Scholar] [CrossRef] [PubMed]
- Primorac, D.; Bach-Rojecky, L.; Vađunec, D.; Juginović, A.; Žunić, K.; Matišić, V.; Skelin, A.; Arsov, B.; Boban, L.; Erceg, D.; et al. Pharmacogenomics at the center of precision medicine: Challenges and perspective in an era of Big Data. Pharmacogenomics 2020, 21, 141–156. [Google Scholar] [CrossRef] [PubMed]
- Spear, B.B.; Heath-Chiozzi, M.; Huff, J. Clinical application of pharmacogenetics. Trends Mol. Med. 2001, 7, 201–204. [Google Scholar] [CrossRef]
- Phillips, K.A.; Veenstra, D.L.; Oren, E.; Lee, J.K.; Sadee, W. Potential role of pharmacogenomics in reducing adverse drug reactions: A systematic review. JAMA 2001, 286, 2270–2279. [Google Scholar] [CrossRef] [PubMed]
- Pirmohamed, M.; James, S.; Meakin, S.; Green, C.; Scott, A.K.; Walley, T.J.; Farrar, K.; Park, B.K.; Breckenridge, A.M. Adverse drug reactions as cause of admission to hospital: Prospective analysis of 18 820 patients. BMJ 2004, 329, 15–19. [Google Scholar] [CrossRef] [Green Version]
- Van Driest, S.L.; Shi, Y.; Bowton, E.A.; Schildcrout, J.S.; Peterson, J.F.; Pulley, J.; Denny, J.C.; Roden, D.M. Clinically Actionable Genotypes Among 10,000 Patients With Preemptive Pharmacogenomic Testing. Clin. Pharmacol. Ther. 2014, 95, 423–431. [Google Scholar] [CrossRef] [Green Version]
- Dunnenberger, H.M.; Crews, K.R.; Hoffman, J.M.; Caudle, K.E.; Broeckel, U.; Howard, S.C.; Hunkler, R.J.; Klein, T.E.; Evans, W.E.; Relling, M.V. Preemptive Clinical Pharmacogenetics Implementation: Current Programs in Five US Medical Centers. Annu. Rev. Pharmacol. Toxicol. 2015, 55, 89–106. [Google Scholar] [CrossRef] [Green Version]
- Rost, S.; Fregin, A.; Ivaskevicius, V.; Conzelmann, E.; Hörtnagel, K.; Pelz, H.-J.; Lappegard, K.T.; Seifried, E.; Scharrer, I.; Tuddenham, E.G.D.; et al. Mutations in VKORC1 cause warfarin resistance and multiple coagulation factor deficiency type 2. Nat. Cell Biol. 2004, 427, 537–541. [Google Scholar] [CrossRef]
- van der Zee, S.A.; Halperin, J.L. Anticoagulant therapy: Warfarin sensitivity genotyping closer to clinical practice. Nat. Rev. Cardiol. 2010, 7, 549–550. [Google Scholar] [CrossRef]
- Niu, X.; Mao, L.; Huang, Y.; Baral, S.; Li, J.-Y.; Gao, Y.; Xia, Y.-P.; He, Q.-W.; Wang, M.-D.; Li, M.; et al. CYP2C19 polymorphism and clinical outcomes among patients of different races treated with clopidogrel: A systematic review and meta-analysis. Acta Acad. Med. Wuhan 2015, 35, 147–156. [Google Scholar] [CrossRef]
- Riazi, S.; Kraeva, N.; Hopkins, P.M. Malignant Hyperthermia in the Post-Genomics Era: New Perspectives on an Old Concept. Anesthesiology 2018, 128, 168–180. [Google Scholar] [CrossRef] [PubMed]
- Amstutz, U.; Shear, N.H.; Rieder, M.J.; Hwang, S.; Fung, V.; Nakamura, H.; Connolly, M.B.; Ito, S.; Carleton, B.C.; the CPNDS Clinical Recommendation Group. Recommendations for HLA-B*15:02 and HLA-A*31:01 genetic testing to reduce the risk of carbamazepine-induced hypersensitivity reactions. Epilepsia 2014, 55, 496–506. [Google Scholar] [CrossRef] [PubMed]
- Black, A.J.; McLeod, H.L.; Capell, H.A.; Powrie, R.H.; Matowe, L.K.; Pritchard, S.C.; Collie-Duguid, E.S.; Reid, D.M. Thiopurine Methyltransferase Genotype Predicts Therapy-Limiting Severe Toxicity from Azathioprine. Ann. Intern. Med. 1998, 129, 716–718. [Google Scholar] [CrossRef] [PubMed]
- Lang, T.; Klein, K.; Fischer, J.; Nüssler, A.K.; Neuhaus, P.; Hofmann, U.; Eichelbaum, M.; Schwab, M.; Zanger, U.M. Extensive genetic polymorphism in the human CYP2B6 gene with impact on expression and function in human liver. Pharmacogenetics 2001, 11, 399–415. [Google Scholar] [CrossRef]
- Arbitrio, M.; Di Martino, M.T.; Scionti, F.; Agapito, G.; Guzzi, P.H.; Cannataro, M.; Tassone, P.; Tagliaferri, P. DMETTM (Drug Metabolism Enzymes and Transporters): A pharmacogenomic platform for precision medicine. Oncotarget 2016, 7, 54028–54050. [Google Scholar] [CrossRef]
- O’Donnell, P.H.; Bush, A.; Spitz, J.; Danahey, K.; Saner, D.; Das, S.; Cox, N.J.; Ratain, M.J. The 1200 Patients Project: Creating a New Medical Model System for Clinical Implementation of Pharmacogenomics. Clin. Pharmacol. Ther. 2012, 92, 446–449. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.M.; Haidar, C.E.; Wilkinson, M.R.; Crews, K.R.; Baker, D.K.; Kornegay, N.M.; Yang, W.; Pui, C.-H.; Reiss, U.M.; Gaur, A.H.; et al. PG4KDS: A model for the clinical implementation of pre-emptive pharmacogenetics. Am. J. Med. Genet. Part C Semin. Med. Genet. 2014, 166, 45–55. [Google Scholar] [CrossRef] [Green Version]
- Pulley, J.M.; Denny, J.C.; Peterson, J.F.; Bernard, G.R.; Vnencak-Jones, C.L.; Ramirez, A.H.; Delaney, J.T.; Bowton, E.; Brothers, K.; Johnson, K.; et al. Operational Implementation of Prospective Genotyping for Personalized Medicine: The Design of the Vanderbilt PREDICT Project. Clin. Pharmacol. Ther. 2012, 92, 87–95. [Google Scholar] [CrossRef] [Green Version]
- Ingelman-Sundberg, M.; Mkrtchian, S.; Zhou, Y.; Lauschke, V.M. Integrating rare genetic variants into pharmacogenetic drug response predictions. Hum. Genom. 2018, 12, 1–12. [Google Scholar] [CrossRef]
- Pandi, M.-T.; Williams, M.S.; Van Der Spek, P.; Koromina, M.; Patrinos, G.P. Exome-Wide Analysis of the DiscovEHR Cohort Reveals Novel Candidate Pharmacogenomic Variants for Clinical Pharmacogenomics. Genes 2020, 11, 561. [Google Scholar] [CrossRef]
- Pratt, V.M.; Zehnbauer, B.; Wilson, J.A.; Baak, R.; Babic, N.; Bettinotti, M.; Buller, A.; Butz, K.; Campbell, M.; Civalier, C.; et al. Characterization of 107 genomic DNA reference materials for CYP2D6, CYP2C19, CYP2C9, VKORC1, and UGT1A1: A GeT-RM and Association for Molecular Pathology collaborative project. J. Mol. Diagn. 2010, 12, 835–846. [Google Scholar] [CrossRef] [PubMed]
- Krebs, K.; Milani, L. Translating pharmacogenomics into clinical decisions: Do not let the perfect be the enemy of the good. Hum. Genom. 2019, 13, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Price, M.J.; Carson, A.R.; Murray, S.S.; Phillips, T.; Janel, L.; Tisch, R.; Topol, E.; Levy, S. First pharmacogenomic analysis using whole exome sequencing to identify novel genetic determinants of clopidogrel response variability: Results of the genotype information and functional testing (GIFT) exome study. J. Am. Coll. Cardiol. 2012, 59, E9. [Google Scholar] [CrossRef] [Green Version]
- Meyerson, M.; Gabriel, S.B.; Getz, G. Advances in understanding cancer genomes through second-generation sequencing. Nat. Rev. Genet. 2010, 11, 685–696. [Google Scholar] [CrossRef] [PubMed]
- Mizzi, C.; Peters, B.; Mitropoulou, C.; Mitropoulos, K.; Katsila, T.; Agarwal, M.R.; Van Schaik, R.H.N.; Drmanac, R.; Borg, J.; Patrinos, G.P. Personalized pharmacogenomics profiling using whole-genome sequencing. Pharmacogenomics 2014, 15, 1223–1234. [Google Scholar] [CrossRef]
- Giannopoulou, E.; Katsila, T.; Mitropoulou, C.; Tsermpini, E.-E.; Patrinos, G.P. Integrating Next-Generation Sequencing in the Clinical Pharmacogenomics Workflow. Front. Pharmacol. 2019, 10, 384. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simon, R.; Roychowdhury, S. Implementing personalized cancer genomics in clinical trials. Nat. Rev. Drug Discov. 2013, 12, 358–369. [Google Scholar] [CrossRef]
- Gamazon, E.R.; Skol, A.D.; Perera, M.A. The limits of genome-wide methods for pharmacogenomic testing. Pharmacogenetics Genom. 2012, 22, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Altman, R.B.; Whirl-Carrillo, M.; Klein, T.E. Challenges in the Pharmacogenomic Annotation of Whole Genomes. Clin. Pharmacol. Ther. 2013, 94, 211–213. [Google Scholar] [CrossRef] [Green Version]
- Reisberg, S.; Krebs, K.; Lepamets, M.; Kals, M.; Mägi, R.; Metsalu, K.; Lauschke, V.M.; Vilo, J.; Milani, L. Translating genotype data of 44,000 biobank participants into clinical pharmacogenetic recommendations: Challenges and solutions. Genet. Med. 2019, 21, 1345–1354. [Google Scholar] [CrossRef] [Green Version]
- Twist, G.P.; Gaedigk, A.; Miller, N.A.; Farrow, E.G.; Willig, L.K.; Dinwiddie, D.L.; Petrikin, J.E.; Soden, S.E.; Herd, S.; Gibson, M.; et al. Constellation: A tool for rapid, automated phenotype assignment of a highly polymorphic pharmacogene, CYP2D6, from whole-genome sequences. Npj Genom. Med. 2016, 1, 15007. [Google Scholar] [CrossRef]
- Numanagić, I.; Malikić, S.; Ford, M.; Qin, X.; Toji, L.; Radovich, M.; Skaar, T.C.; Pratt, V.M.; Berger, B.; Scherer, S.; et al. Allelic decomposition and exact genotyping of highly polymorphic and structurally variant genes. Nat. Commun. 2018, 9, 1–11. [Google Scholar] [CrossRef]
- Lee, S.; Wheeler, M.M.; Thummel, K.E.; Nickerson, D.A. Calling Star Alleles with Stargazer in 28 Pharmacogenes with Whole Genome Sequences. Clin. Pharmacol. Ther. 2019, 106, 1328–1337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klein, T.E.; Ritchie, M.D. PharmCAT: A Pharmacogenomics Clinical Annotation Tool. Clin. Pharmacol. Ther. 2018, 104, 19–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Twesigomwe, D.; Wright, G.E.B.; Drögemöller, B.I.; Da Rocha, J.; Lombard, Z.; Hazelhurst, S. A systematic comparison of pharmacogene star allele calling bioinformatics algorithms: A focus on CYP2D6 genotyping. Npj Genom. Med. 2020, 5, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Relling, M.V.; Klein, T.E. CPIC: Clinical Pharmacogenetics Implementation Consortium of the Pharmacogenomics Research Network. Clin. Pharmacol. Ther. 2011, 89, 464–467. [Google Scholar] [CrossRef]
- Swen, J.; Wilting, I.; De Goede, A.L.; Grandia, L.; Mulder, H.; Touw, D.; De Boer, A.; Conemans, J.; Egberts, T.; Klungel, O.; et al. Pharmacogenetics: From Bench to Byte. Clin. Pharmacol. Ther. 2008, 83, 781–787. [Google Scholar] [CrossRef]
- Swen, J.; Nijenhuis, M.; De Boer, A.; Grandia, L.; Der Zee, A.M.-V.; Mulder, H.; Rongen, G.; Van Schaik, R.; Schalekamp, T.; Touw, D.; et al. Pharmacogenetics: From Bench to Byte—An Update of Guidelines. Clin. Pharmacol. Ther. 2011, 89, 662–673. [Google Scholar] [CrossRef]
- Bank, P.C.D.; Caudle, K.E.; Swen, J.J.; Gammal, R.S.; Whirl-Carrillo, M.; Klein, T.E.; Relling, M.V.; Guchelaar, H. Comparison of the Guidelines of the Clinical Pharmacogenetics Implementation Consortium and the Dutch Pharmacogenetics Working Group. Clin. Pharmacol. Ther. 2018, 103, 599–618. [Google Scholar] [CrossRef]
- Bell, G.C.; Crews, K.R.; Wilkinson, M.R.; Haidar, C.E.; Hicks, J.K.; Baker, D.K.; Freimuth, R.R. Development and use of active clinical decision support for preemptive pharmacogenomics. J. Am. Med. Inform. Assn. 2014, 21, e93–e99. [Google Scholar] [CrossRef]
- Sangkuhl, K.; Whirl-Carrillo, M.; Whaley, R.M.; Woon, M.; Lavertu, A.; Altman, R.B.; Carter, L.; Verma, A.; Ritchie, M.D.; Klein, T.E. Pharmacogenomics Clinical Annotation Tool (PharmCAT). Clin. Pharmacol. Ther. 2020, 107, 203–210. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.B.; Wheeler, M.M.; Patterson, K.; McGee, S.; Dalton, R.; Woodahl, E.L.; Gaedigk, A.; Thummel, K.E.; Nickerson, D.A. Stargazer: A software tool for calling star alleles from next-generation sequencing data using CYP2D6 as a model. Genet. Med. 2019, 21, 361–372. [Google Scholar] [CrossRef] [PubMed]
- Birdwell, K.A.; Decker, B.; Barbarino, J.M.; Peterson, J.F.; Stein, C.M.; Sadee, W.; Wang, D.; Vinks, A.A.; He, Y.; Swen, J.J.; et al. Clinical Pharmacogenetics Implementation Consortium (CPIC) Guidelines forCYP3A5Genotype and Tacrolimus Dosing. Clin. Pharmacol. Ther. 2015, 98, 19–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thorn, C.F.; Lamba, J.K.; Lamba, V.; Klein, T.E.; Altman, R.B. PharmGKB summary: Very important pharmacogene information for CYP2B6. Pharm. Genom. 2010, 20, 520–523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schärfe, C.P.I.; Tremmel, R.; Schwab, M.; Kohlbacher, O.; Marks, D.S. Genetic variation in human drug-related genes. Genome Med. 2017, 9, 1–15. [Google Scholar] [CrossRef] [Green Version]
- O’Donnell, P.H.; Wadhwa, N.; Danahey, K.; Borden, B.A.; Lee, S.M.; Hall, J.P.; Klammer, C.; Hussain, S.; Siegler, M.; Sorrentino, M.J.; et al. Pharmacogenomics-Based Point-of-Care Clinical Decision Support Significantly Alters Drug Prescribing. Clin. Pharmacol. Ther. 2017, 102, 859–869. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Gene | Drug | PGx on FDA Label | CPIC Publications (PMID) |
|---|---|---|---|
| CYP2B6 | efavirenz | Actionable PGx | 31006110 |
| CYP2C19 | amitriptyline | 23486447; 27997040 | |
| citalopram | Actionable PGx | 25974703 | |
| clopidogrel | Actionable PGx | 21716271; 23698643 | |
| escitalopram | Actionable PGx | 25974703 | |
| lansoprazole | Informative PGx | 32770672 | |
| omeprazole | Actionable PGx | 32770672 | |
| pantoprazole | Actionable PGx | 32770672 | |
| voriconazole | Actionable PGx | 27981572 | |
| clomipramine | 23486447; 27997040 | ||
| dexlansoprazole | Actionable PGx | 32770672 | |
| doxepin | Actionable PGx | 23486447; 27997040 | |
| imipramine | 23486447; 27997040 | ||
| sertraline | 25974703 | ||
| trimipramine | 23486447; 27997040 | ||
| esomeprazole | Actionable PGx | 32770672 | |
| rabeprazole | Actionable PGx | 32770672 | |
| CYP2C9 | celecoxib | Actionable PGx | 32189324 |
| flurbiprofen | Actionable PGx | 32189324 | |
| fosphenytoin | 25099164; 32779747 | ||
| ibuprofen | 32189324 | ||
| lornoxicam | 32189324 | ||
| meloxicam | Actionable PGx | 32189324 | |
| phenytoin | Actionable PGx | 25099164; 32779747 | |
| piroxicam | Actionable PGx | 32189324 | |
| tenoxicam | 32189324 | ||
| warfarin | Actionable PGx | 21900891; 28198005 | |
| aceclofenac | 32189324 | ||
| aspirin | 32189324 | ||
| diclofenac | 32189324 | ||
| indomethacin | 32189324 | ||
| lumiracoxib | 32189324 | ||
| nabumetone | 32189324 | ||
| naproxen | 32189324 | ||
| CYP2D6 | amitriptyline | Actionable PGx | 23486447; 27997040 |
| atomoxetine | Actionable PGx | 30801677 | |
| codeine | Actionable PGx | 22205192; 24458010 | |
| nortriptyline | Actionable PGx | 23486447; 27997040 | |
| ondansetron | Informative PGx | 28002639 | |
| paroxetine | Informative PGx | 25974703 | |
| tamoxifen | Actionable PGx | 29385237 | |
| tropisetron | 28002639 | ||
| clomipramine | Actionable PGx | 23486447; 27997040 | |
| desipramine | Actionable PGx | 23486447; 27997040 | |
| doxepin | Actionable PGx | 23486447; 27997040 | |
| fluvoxamine | Actionable PGx | 25974703 | |
| imipramine | Actionable PGx | 23486447; 27997040 | |
| trimipramine | Actionable PGx | 23486447; 27997040 | |
| CYP3A5 | tacrolimus | 25801146 | |
| DPYD | capecitabine | Actionable PGx | 23988873; 29152729 |
| fluorouracil | Actionable PGx | 23988873; 29152729 | |
| tegafur | 23988873; 29152729 | ||
| SLCO1B1 | simvastatin | 22617227; 24918167 | |
| TPMT | azathioprine | Testing recommended | 21270794; 23422873; 30447069 |
| mercaptopurine | Testing recommended | 21270794; 23422873; 30447069 | |
| thioguanine | Testing recommended | 21270794; 23422873; 30447069 | |
| UGT1A1 | atazanavir | 26417955 |
| # | Sample_ID | Tool | Gene | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CYP2B6 | CYP2C9 | CYP2C19 | CYP2D6 | CYP3A5 | DPYD | SLC01B1 | TPMT | UGT1A1 | |||
| 1 | 1 | Astrolabe | *1/*2 | *1/*1 | *2/*4 | ||||||
| PharmCAT | *1/*2, *1/*35 | *5/*20, *5/*21 | *36, *60, *60 | ||||||||
| Stargazer | *1/*2 | *1/*2 | *1/*1 | *2/*4 | *3/*3 | *S12/*S12 | *1/*5 | *1/*1 | |||
| 2 | 2 | Astrolabe | *1/*1 | *1/*17 | *2/*41 | ||||||
| PharmCAT | *1/*4B, *1/*17 | *1A/*18 | *60/*60 | ||||||||
| Stargazer | *1/*1 | *1/*1 | *1/*17 | *2/*119 | *3/*3 | *6/*S12 | *1/*1B | *1/*1 | *60/*60 | ||
| 3 | 3 | Astrolabe | *1/*1 | *2/*2 | *41/*86 | ||||||
| PharmCAT | *2/*2 | *19/*20, *19/*21 | *36, *60 | ||||||||
| Stargazer | *1/*6 | *1/*1 | *2/*2 | *86/*119 | *3/*3 | *1/*9A | *1/*1B | *1/*1 | |||
| 4 | 4 | Astrolabe | *1/*1 | *1/*17 | *1/*41 | ||||||
| PharmCAT | *1/*4B, *1/*17 | *36, *60 | |||||||||
| Stargazer | *1/*1 | *1/*1 | *1/*17 | *1/*119 | *1/*3 | *S3/*5 | *1/*14 | *1/*1 | |||
| 5 | 5 | Astrolabe | *1/*1 | *1/*2 | *10/*4 | ||||||
| PharmCAT | *1/*2 | *1A/*20, *1A/*21 | |||||||||
| Stargazer | *1/*22 | *1/*1 | *1/*2 | *4/*10 | *1/*3 | *S3/*S12 | *1/*1B | *1/*1 | *79/*79 | ||
| 6 | 6 | Astrolabe | *1/*1 | *1/*2 | *1/*86 | ||||||
| PharmCAT | *1/*2 | *1A/*18 | *60/*60 | ||||||||
| Stargazer | *5/*6 | *1/*1 | *1/*2 | *1/*1 | *3/*3 | *S3/*S12 | *1/*1B | *1/*1 | |||
| 7 | 7 | Astrolabe | *2/*17 | *1/*1 | *1/*2 | ||||||
| PharmCAT | *2/*4B, *2/*17 | Multiple | |||||||||
| Stargazer | *1/*1 | *1/*1 | *2/*17 | *1/*2 | *3/*3 | *1/*S12 | *1/*S464F | *1/*1 | *79/*79 | ||
| 8 | 8 | Astrolabe | *1/*1 | *1/*1 | *1/*10 | ||||||
| PharmCAT | *18/*18, *18/*19, *19/*19 | *60 | |||||||||
| Stargazer | *6/*6 | *1/*1 | *1/*1 | *1/*10 | *1/*3 | *S12/*S38 | *1/*1 | *1/*1 | *60/*79 | ||
| 9 | 9 | Astrolabe | *1/*2 | *1/*1 | *1/*4 | ||||||
| PharmCAT | *1/*2 | *1A/*18, *1A/*19 | *36, *60 | ||||||||
| Stargazer | *1/*1 | *1/*1 | *1/*2 | *1/*4 | *3/*3 | *S12/*S12 | *1/*1 | *1/*1 | |||
| 10 | 10 | Astrolabe | *2/*2 | *1/*1 | *1/*4 | ||||||
| PharmCAT | *2/*2 | *20/*20, *20/*21, *21/*21 | *60/*60 | ||||||||
| Stargazer | *6/*6 | *1/*1 | *2/*2 | *1/*4 | *1/*3 | *1/*S12 | *1B/*1B | *1/*1 | |||
| 11 | 11 | Astrolabe | *2/*17 | *1/*1 | *1/*2 | ||||||
| PharmCAT | *2/*4B, *2/*17 | rs4149056T/rs4149056C | *36, *60 | ||||||||
| Stargazer | *1/*5 | *1/*1 | *2/*17 | *1/*2 | *3/*3 | *9A/*S12 | *1/*17 | *1/*1 | |||
| 12 | 12 | Astrolabe | *1/*1 | *1/*2 | *2/*4 | ||||||
| PharmCAT | *1/*2, *1/*35 | *5/*20, *5/*21 | *36, *60 | ||||||||
| Stargazer | *1/*1 | *1/*2 | *1/*1 | *2/*4 | *3/*3 | *6/*S12 | *1/*15 | *1/*1 | |||
| 13 | 13 | Astrolabe | *1/*1 | *1/*2 | *1/*1 | ||||||
| PharmCAT | *1/*2, *1/*35 | ||||||||||
| Stargazer | *1/*6 | *1/*2 | *1/*1 | *1/*122 | *3/*3 | *5/*9A | *1/*14 | *1/*1 | *1/*79 | ||
| 14 | 14 | Astrolabe | *1/*1 | *1/*3 | *1/*1 | ||||||
| PharmCAT | *1/*3, *1/*18 | rs4149056C/rs4149056C | *36, *60 | ||||||||
| Stargazer | *2/*6 | *1/*3 | *1/*1 | *1/*1 | *3/*3 | *5/*S12 | *15/*15 | *1/*1 | |||
| 15 | 15 | Astrolabe | *1/*1 | *1/*1 | *1/*41 | ||||||
| PharmCAT | *1A/*18, *1A/*19 | *36, *60, *60 | |||||||||
| Stargazer | *1/*5 | *1/*1 | *1/*1 | *1/*119 | *3/*3 | *S12/*S12 | *1/*1 | *1/*1 | |||
| 16 | 16 | Astrolabe | *1/*2 | *1/*2 | *1/*41 | ||||||
| PharmCAT | *1/*2, *1/*35 | *1/*2 | rs4149056C/rs4149056C | *36, *60 | |||||||
| Stargazer | *1/*9 | *1/*2 | *1/*2 | *1/*119 | *3/*3 | *9A/*9A | *15/*15 | *1/*1 | |||
| 17 | 17 | Astrolabe | *17/*17 | *1/*1 | *1/*2 | ||||||
| PharmCAT | *4B/*4B, *4B/*17, *17/*17 | rs4149056T/rs4149056C | *60/*60 | ||||||||
| Stargazer | *1/*6 | *1/*1 | *17/*17 | *1/*2 | *3/*3 | *9A/*S12 | *1/*17 | *1/*1 | |||
| 18 | 18 | Astrolabe | *1/*17 | *1/*1 | *1/*1 | ||||||
| PharmCAT | *1/*4B, *1/*17 | *18/*18, *18/*19, *19/*19 | *36, *60 | ||||||||
| Stargazer | *1/*1 | *1/*1 | *1/*17 | *1/*1 | *3/*3 | *9A/*S12 | *1/*1 | *1/*1 | |||
| 19 | 19 | Astrolabe | *1/*1 | *1/*2 | *1/*2 | ||||||
| PharmCAT | *1/*2, *1/*35 | *1A/*18 | *36, *60 | ||||||||
| Stargazer | *1/*1 | *1/*2 | *1/*1 | *1/*2 | *3/*3 | *9A/*9A | *1/*1B | *1/*1 | |||
| 20 | 20 | Astrolabe | *1/*17 | *1/*2 | *2/*2 | ||||||
| PharmCAT | *1/*2, *1/*35 | *1/*4B, *1/*17 | *1A/*18 | ||||||||
| Stargazer | *1/*1 | *1/*2 | *1/*17 | *2/*2 | *3/*3 | *9A/*9A | *1/*1B | *1/*1 | *1/*1 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
John, S.E.; Channanath, A.M.; Hebbar, P.; Nizam, R.; Thanaraj, T.A.; Al-Mulla, F. PharmaKU: A Web-Based Tool Aimed at Improving Outreach and Clinical Utility of Pharmacogenomics. J. Pers. Med. 2021, 11, 210. https://doi.org/10.3390/jpm11030210
John SE, Channanath AM, Hebbar P, Nizam R, Thanaraj TA, Al-Mulla F. PharmaKU: A Web-Based Tool Aimed at Improving Outreach and Clinical Utility of Pharmacogenomics. Journal of Personalized Medicine. 2021; 11(3):210. https://doi.org/10.3390/jpm11030210
Chicago/Turabian StyleJohn, Sumi Elsa, Arshad Mohamed Channanath, Prashantha Hebbar, Rasheeba Nizam, Thangavel Alphonse Thanaraj, and Fahd Al-Mulla. 2021. "PharmaKU: A Web-Based Tool Aimed at Improving Outreach and Clinical Utility of Pharmacogenomics" Journal of Personalized Medicine 11, no. 3: 210. https://doi.org/10.3390/jpm11030210
APA StyleJohn, S. E., Channanath, A. M., Hebbar, P., Nizam, R., Thanaraj, T. A., & Al-Mulla, F. (2021). PharmaKU: A Web-Based Tool Aimed at Improving Outreach and Clinical Utility of Pharmacogenomics. Journal of Personalized Medicine, 11(3), 210. https://doi.org/10.3390/jpm11030210