
Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques

 ,
,  , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Statistical Analysis
- The RPARTs are classification models based on a top-down methodology in which, starting from a root node, binary splits of data are generated until a certain criterion (i.e., the minimization of the node impurity) is encountered [17]. This method is prone to overfitting on training data. The cross-validation or bootstrapping procedure is a useful method to limit the overfitting, leading to defining the proper tuning of the Decision Tree (DT) parameters and optimizing the model accuracy [18].
- Random Forest is a tree-based algorithm, which involves the computation of hundreds to thousands of RPART trees; the method merges the DT output to increase the model’s generalizability [19].
- The GBM is based on a sequential boosting improvement of weak RPART classifiers (high bias and low variance). The GBM idea is to add a classifier sequentially so that the next classifier is trained to improve the already trained RPART. A random forest algorithm, instead, trains each classifier independently from the others [19].
- The SVM algorithm’s main objective is to find an optimal hyperplane of the feature’s N-dimensional space (N—the number of variables) that distinctly classify the data points into a binary partition [20]. Several hyperplanes may separate the classes of data points. The SVM algorithm considers the hyperplanes, which maximize the margin (the distance between data points of classes).
3. Results
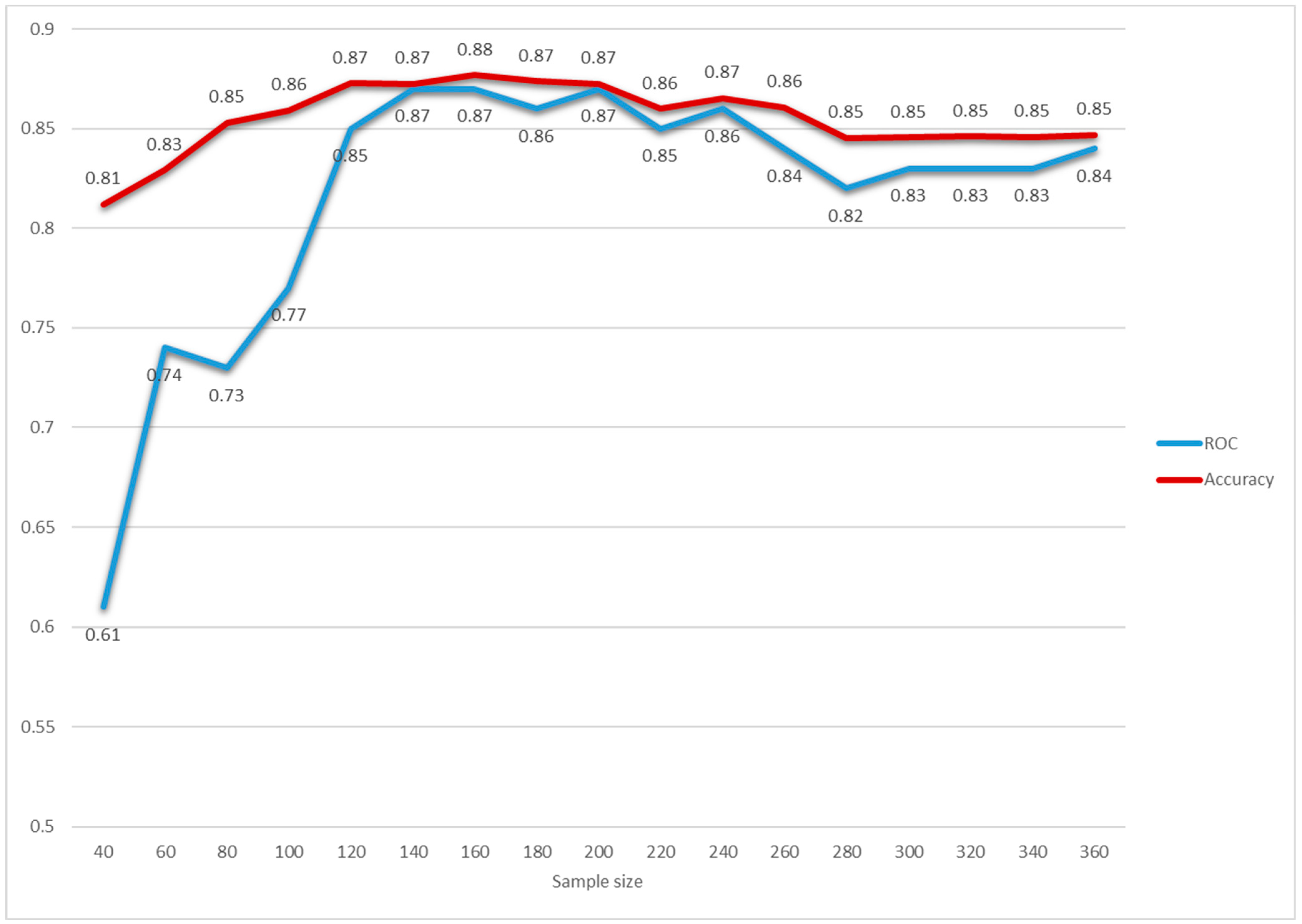
3.1. MLTs Performance
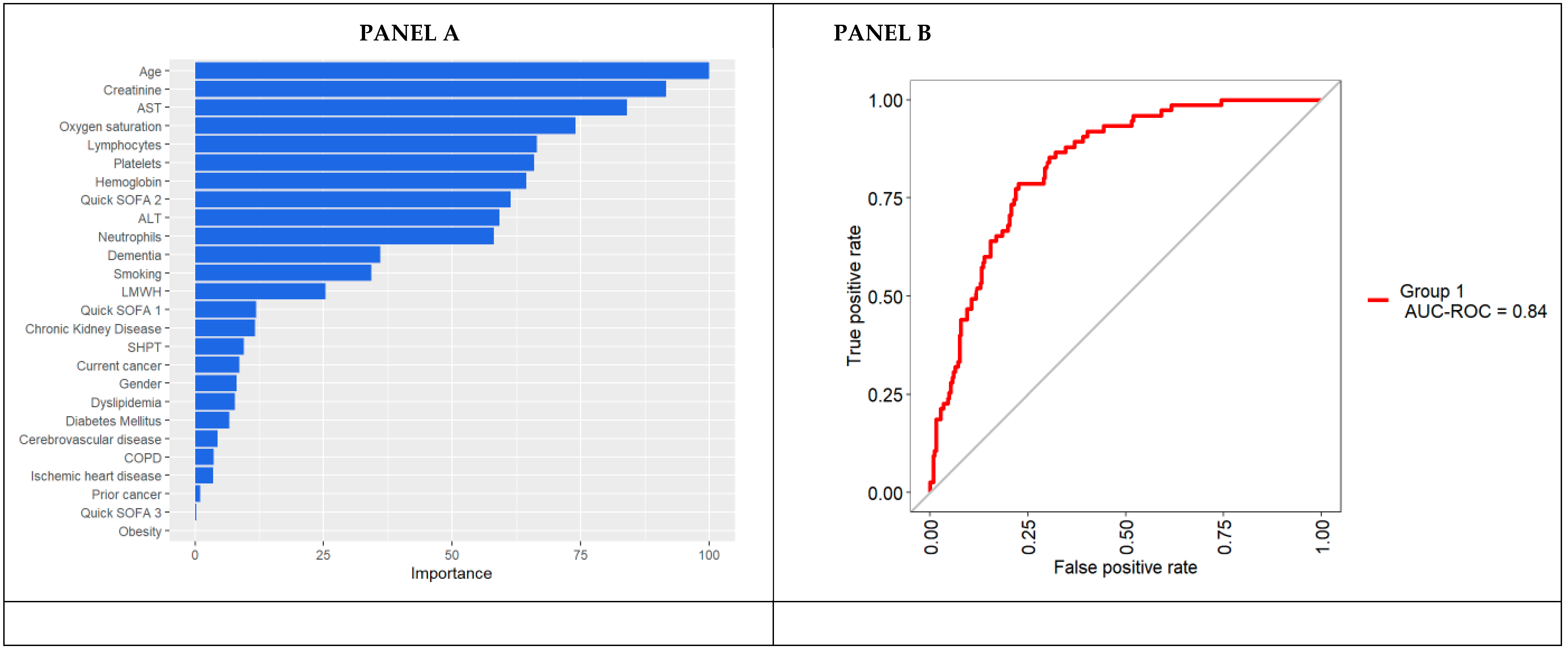
3.2. Variable Importance in Predicting in-Hospital Mortality According to the Random Forest
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sperrin, M.; McMillan, B. Prediction models for covid-19 outcomes. BMJ 2020, 371, m3777. [Google Scholar] [CrossRef]
- Tenforde, M.W.; Kim, S.S.; Lindsell, C.J.; Rose, E.B.; Shapiro, N.I.; Files, D.C.; Gibbs, K.W.; Erickson, H.L.; Steingrub, J.S.; Smithline, H.A.; et al. Symptom Duration and Risk Factors for Delayed Return to Usual Health Among Outpatients with COVID-19 in a Multistate Health Care Systems Network—United States, March–June 2020. Morb. Mortal. Wkly. Rep. 2020, 69, 993. [Google Scholar] [CrossRef]
- Cates, J.; Lucero-Obusan, C.; Dahl, R.M.; Schirmer, P.; Garg, S.; Oda, G.; Hall, A.J.; Langley, G.; Havers, F.P.; Holodniy, M.; et al. Risk for In-Hospital Complications Associated with COVID-19 and Influenza—Veterans Health Administration, United States, October 1, 2018–May 31, 2020. Morb. Mortal. Wkly. Rep. 2020, 69, 1528. [Google Scholar] [CrossRef]
- Michelozzi, P.; De’Donato, F.; Scortichini, M.; Pezzotti, P.; Stafoggia, M.; De Sario, M.; Costa, G.; Noccioli, F.; Riccardo, F.; Bella, A.; et al. Temporal dynamics in total excess mortality and COVID-19 deaths in Italian cities. BMC Public Health 2020, 20, 1–8. [Google Scholar] [CrossRef]
- Grasselli, G.; Pesenti, A.; Cecconi, M. Critical Care Utilization for the COVID-19 Outbreak in Lombardy, Italy: Early Experience and Forecast During an Emergency Response. JAMA 2020, 23, 1545–1546. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Gregori, D.; Azzolina, D.; Lanera, C.; Prosepe, I.; Destro, N.; Lorenzoni, G.; Berchialla, P. A first estimation of the impact of public health actions against COVID-19 in Veneto (Italy). J. Epidemiol. Community Health 2020, 74, 858–860. [Google Scholar] [CrossRef] [PubMed]
- Castro, V.M.; McCoy, T.H.; Perlis, R.H. Laboratory Findings Associated With Severe Illness and Mortality Among Hospitalized Individuals With Coronavirus Disease 2019 in Eastern Massachusetts. JAMA Netw. Open 2020, 3, e2023934. [Google Scholar] [CrossRef] [PubMed]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.J.; Dahly, D.L.; A Damen, J.; A Debray, T.P.; et al. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef] [Green Version]
- Hajifathalian, K.; Sharaiha, R.Z.; Kumar, S.; Krisko, T.; Skaf, D.; Ang, B.; Redd, W.D.; Zhou, J.C.; Hathorn, K.E.; Mccarty, T.R.; et al. Development and external validation of a prediction risk model for short-term mortality among hospitalized U.S. COVID-19 patients: A proposal for the COVID-AID risk tool. PLoS ONE 2020, 15, e0239536. [Google Scholar] [CrossRef] [PubMed]
- An, C.; Lim, H.; Kim, D.-W.; Chang, J.H.; Choi, Y.J.; Kim, S.W. Machine learning prediction for mortality of patients diagnosed with COVID-19: A nationwide Korean cohort study. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Yadaw, A.S.; Li, Y.-C.; Bose, S.; Iyengar, R.; Bunyavanich, S.; Pandey, G. Clinical features of COVID-19 mortality: Development and validation of a clinical prediction model. Lancet Digit. Health 2020, 2, e516–e525. [Google Scholar] [CrossRef]
- Gao, Y.; Cai, G.-Y.; Fang, W.; Li, H.-Y.; Wang, S.-Y.; Chen, L.; Yu, Y.; Liu, D.; Xu, S.; Cui, P.-F.; et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat. Commun. 2020, 11, 1–10. [Google Scholar] [CrossRef]
- Vaid, A.; Somani, S.; Russak, A.J.; De Freitas, J.K.; Chaudhry, F.F.; Paranjpe, I.; Johnson, K.W.; Lee, S.J.; Miotto, R.; Richter, F.; et al. Machine Learning to Predict Mortality and Critical Events in a Cohort of Patients With COVID-19 in New York City: Model Development and Validation. J. Med. Internet Res. 2020, 22, e24018. [Google Scholar] [CrossRef]
- Ngiam, K.Y.; Khor, W. Big Data and Machine Learning Algorithms for Health-Care Delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Lorenzoni, G.; Lanera, C.; Azzolina, D.; Berchialla, P.; Gregori, D.; Gregori, D.; Lanera, C.; Berchialla, P.; Catelan, D.; Azzolina, D.; et al. Is a More Aggressive COVID-19 Case Detection Approach Mitigating the Burden on ICUs? Some Reflections from Italy. Crit. Care 2020, 24, 175. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Available online: https://cds.cern.ch/record/2253780 (accessed on 12 October 2019).
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. [Google Scholar]
- Breiman, L. Machine Learning. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Harrell, F.E.J. Rms: Regression Modeling Strategies, R Package Version 4.1-3. 2014.
- Kuhn, M. Building Predictive Models in R Using the caretPackage. J. Stat. Softw. 2008, 28. [Google Scholar] [CrossRef] [Green Version]
- Grasselli, G.; Zangrillo, A.; Zanella, A.; Antonelli, M.; Cabrini, L.; Castelli, A.; Cereda, D.; Coluccello, A.; Foti, G.; Fumagalli, R. Baseline Characteristics and Outcomes of 1591 Patients Infected with SARS-CoV-2 Admitted to ICUs of the Lombardy Region, Italy. JAMA 2020, 323, 1574–1581. [Google Scholar] [CrossRef] [Green Version]
- Thachil, J. The Versatile Heparin in COVID-19. J. Thromb. Haemost. 2020, 18, 1020–1022. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Baseline Characteristics | N | Before March 21 (n = 149) | After March 21 (n = 192) | Overall (N = 341) | p-Value |
|---|---|---|---|---|---|
| Gender: Female | 341 | 35% (52) | 49% (95) | 43% (147) | 0.007 |
| Male | 65% (97) | 51% (97) | 57% (194) | ||
| Age | 341 | 58.0/70.0/82.0 | 62.5/78.0/87.0 | 60.0/74.0/85.0 | <0.001 |
| Smoking: No | 237 | 79% (94) | 85% (100) | 82% (194) | 0.25 |
| Yes | 21% (25) | 15% (18) | 18% (43) | ||
| Duration of Hospitalization (Days) | 290 | 7.0/12.0/17.0 | 6.0/10.0/16.0 | 7.0/11.0/16.8 | 0.106 |
| Comorbidities | |||||
| Diabetes Mellitus: No | 341 | 73% (109) | 83% (159) | 79% (268) | 0.031 |
| Yes | 27% (40) | 17% (33) | 21% (73) | ||
| SHPT: No | 341 | 48% (72) | 53% (102) | 51% (174) | 0.379 |
| Yes | 52% (77) | 47% (90) | 49% (167) | ||
| Dyslipidemia: No | 341 | 82% (122) | 86% (165) | 84% (287) | 0.309 |
| Yes | 18% (27) | 14% (27) | 16% (54) | ||
| Ischemic heart disease: No | 341 | 91% (136) | 90% (172) | 90% (308) | 0.6 |
| Yes | 9% (13) | 10% (20) | 10% (33) | ||
| Obesity: No | 341 | 93% (138) | 94% (181) | 94% (319) | 0.538 |
| Yes | 7% (11) | 6% (11) | 6% (22) | ||
| Cerebrovascular disease: No | 341 | 95% (142) | 88% (169) | 91% (311) | 0.019 |
| Yes | 5% (7) | 12% (23) | 9% (30) | ||
| Dementia: No | 341 | 87% (129) | 69% (132) | 77% (261) | <0.001 |
| Yes | 13% (20) | 31% (60) | 23% (80) | ||
| Chronic Kidney Disease: No | 331 | 93% (136) | 89% (164) | 91% (300) | 0.293 |
| Yes | 7% (11) | 11% (20) | 9% (31) | ||
| Current cancer: No | 341 | 96% (143) | 91% (175) | 93% (318) | 0.078 |
| Yes | 4% (6) | 9% (17) | 7% (23) | ||
| Previous Cancer: No | 340 | 95% (142) | 95% (182) | 95% (324) | 0.995 |
| Yes | 5% (7) | 5% (9) | 5% (16) | ||
| COPD: No | 340 | 95% (140) | 90% (172) | 92% (312) | 0.096 |
| Yes | 5% (8) | 10% (20) | 8% (28) | ||
| Lab parameters & Vital Signs | |||||
| Neutrophils (×109/L) | 339 | 3.16/4.38/6.56 | 3.24/4.57/7.23 | 3.17/4.50/6.72 | 0.235 |
| Lymphocytes (×109/L) | 339 | 0.640/0.915/1.263 | 0.670/0.890/1.345 | 0.650/0.900/1.320 | 0.784 |
| Neutrophils/Lymphocytes (×109/L) | 338 | 2.69/4.42/7.96 | 3.23/5.09/9.36 | 2.97/4.93/8.93 | 0.297 |
| Hemoglobin (g/L) | 339 | 116/130/142 | 116/128/140 | 116/128/140 | 0.586 |
| D-dimer (μg/L) | 124 | 134/192/416 | 148/301/675 | 142/227/636 | 0.089 |
| Creatinine (μmol/L) | 337 | 67.8/84.0/104.2 | 63.0/78.0/96.0 | 67.0/81.0/102.0 | 0.075 |
| Platelets (×109/L) | 338 | 148/189/234 | 150/198/246 | 148/196/244 | 0.445 |
| AST (U/L) | 292 | 25.2/35.5/49.0 | 26.0/37.0/60.0 | 26.0/36.5/55.2 | 0.265 |
| ALT (U/L) | 298 | 20.0/27.0/40.0 | 15.8/25.0/43.2 | 17.0/26.0/42.0 | 0.2 |
| Procalcitonin (PCT) (μg/L) | 208 | 0.0400/0.0800/0.1400 | 0.0500/0.1200/0.3950 | 0.0475/0.1000/0.2600 | 0.03 |
| Troponine (ng/L) | 31 | 6.0/25.0/90.0 | 10.5/26.5/64.5 | 9.5/25.0/68.0 | 0.848 |
| Oxygen saturation (%) | 244 | 93.8/96.0/98.0 | 93.0/95.0/97.0 | 93.0/95.5/98.0 | 0.541 |
| Quick SOFA | 341 | 0/0/1 | 0/0/1 | 0/0/1 | 0.048 |
| pO2 (mmHg) | 213 | 54.0/64.0/71.0 | 56.0/64.0/73.2 | 55.0/64.0/72.0 | 0.567 |
| Glasgow Coma Scale >/= 15 : No | 341 | 84% (125) | 70% (135) | 76% (260) | 0.003 |
| Yes | 16% (24) | 30% (57) | 24% (81) | ||
| Drug therapy | |||||
| ARIXTRA: No | 111 | 59% (37) | 35% (17) | 49% (54) | 0.015 |
| Yes | 41% (26) | 65% (31) | 51% (57) | ||
| LMWH: No | 286 | 28% (35) | 12% (20) | 19% (55) | 0.001 |
| Yes | 72% (88) | 88% (143) | 81% (231) | ||
| Antiviral: No | 340 | 51% (76) | 97% (186) | 77% (262) | <0.001 |
| Yes | 49% (73) | 3% (5) | 23% (78) | ||
| Plaquenil: No | 340 | 24% (36) | 18% (34) | 21% (70) | 0.15 |
| Yes | 76% (113) | 82% (157) | 79% (270) | ||
| Antibiotic: No | 340 | 5% (7) | 4% (8) | 4% (15) | 0.82 |
| Yes | 95% (142) | 96% (183) | 96% (325) | ||
| Tocilizumab: No | 340 | 95% (141) | 97% (186) | 96% (327) | 0.189 |
| Yes | 5% (8) | 3% (5) | 4% (13) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tezza, F.; Lorenzoni, G.; Azzolina, D.; Barbar, S.; Leone, L.A.C.; Gregori, D. Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques. J. Pers. Med. 2021, 11, 343. https://doi.org/10.3390/jpm11050343
Tezza F, Lorenzoni G, Azzolina D, Barbar S, Leone LAC, Gregori D. Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques. Journal of Personalized Medicine. 2021; 11(5):343. https://doi.org/10.3390/jpm11050343
Chicago/Turabian StyleTezza, Fabiana, Giulia Lorenzoni, Danila Azzolina, Sofia Barbar, Lucia Anna Carmela Leone, and Dario Gregori. 2021. "Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques" Journal of Personalized Medicine 11, no. 5: 343. https://doi.org/10.3390/jpm11050343
APA StyleTezza, F., Lorenzoni, G., Azzolina, D., Barbar, S., Leone, L. A. C., & Gregori, D. (2021). Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques. Journal of Personalized Medicine, 11(5), 343. https://doi.org/10.3390/jpm11050343