
African Genomic Medicine Portal: A Web Portal for Biomedical Applications

 , , ,
, , ,  , , , , ,
, , , , ,  ,
,  , , , , , , , , , , , , , , , , , , and
, , , , , , , , , , , , , , , , , , and  add
Show full author list
add
Show full author list
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
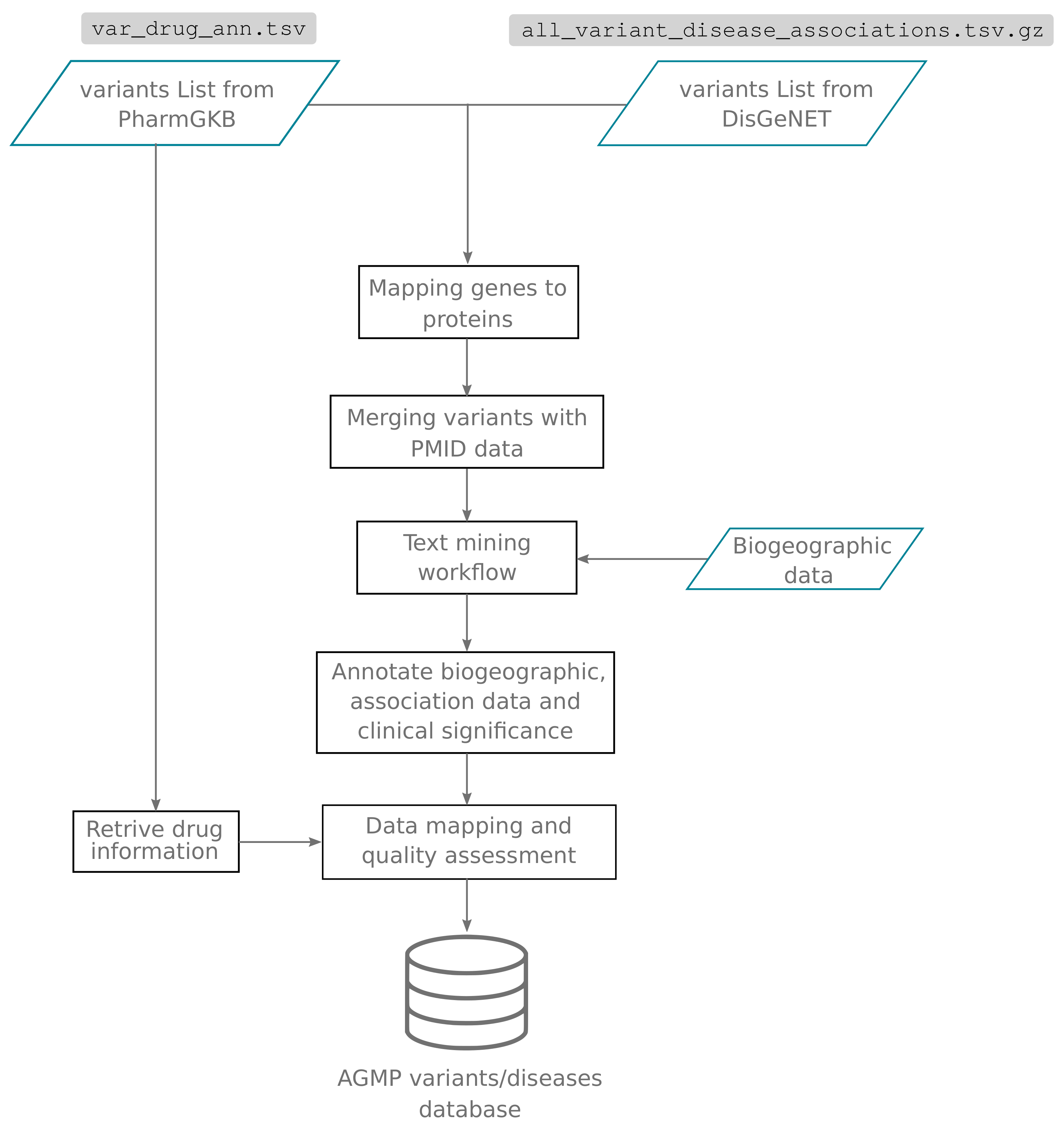
2.1. Content Mining and Curation
2.2. Technical Implementation
3. Results
3.1. AGMP Data Model and Content
3.2. Data Exploration through the Portal
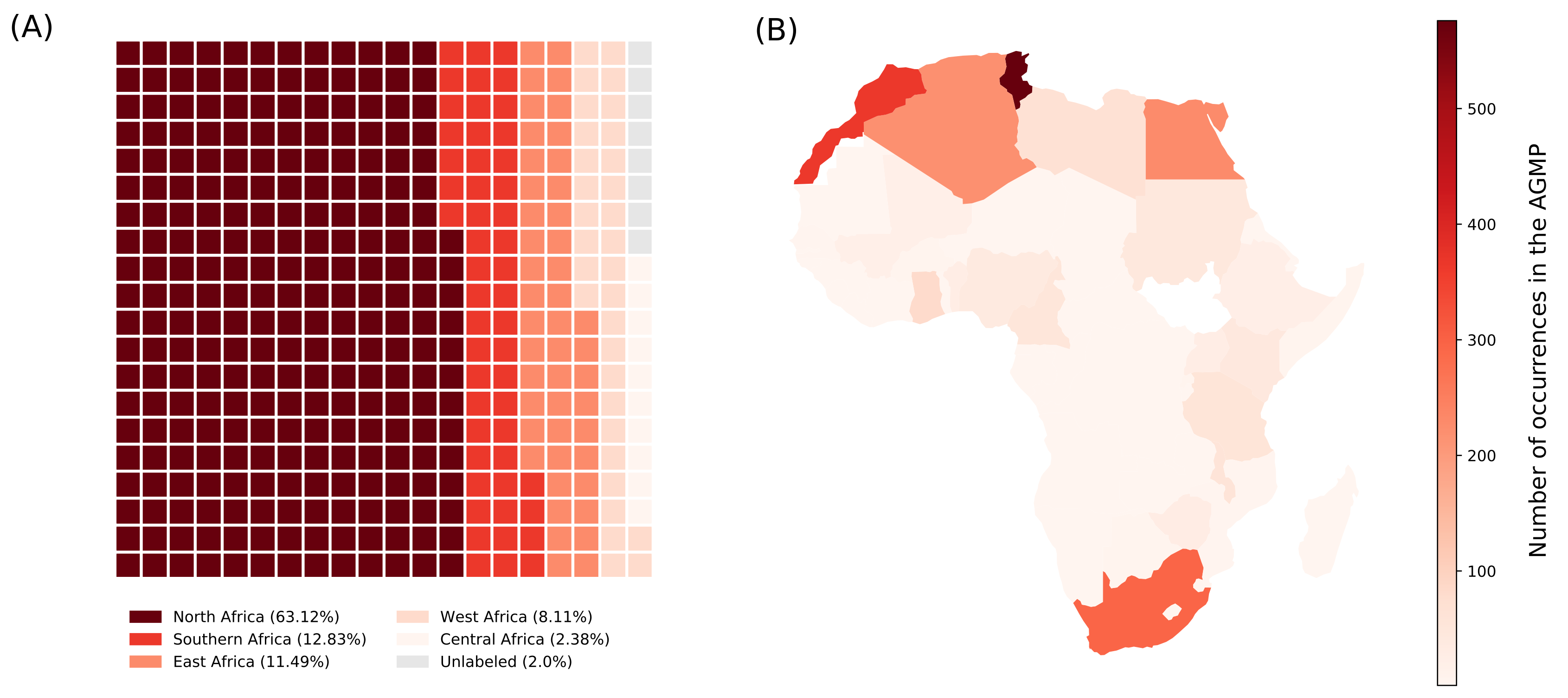
3.3. Representation of African Data in AGMP
3.4. Pharmacogenetic-Related Phenotypes in AGMP
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AGMP | African Medicine Genomic Portal |
| SNV | Single Nucleotide Variant |
References
- H3Africa Consortium; Rotimi, C.; Abayomi, A.; Abimiku, A.; Adabayeri, V.M.; Adebamowo, C.; Adebiyi, E.; Ademola, A.D.; Adeyemo, A.; Adu, D.; et al. Research capacity. Enabling the genomic revolution in Africa. Science 2014, 344, 1346–1348. [Google Scholar] [PubMed] [Green Version]
- Mulder, N.; Zass, L.; Hamdi, Y.; Othman, H.; Panji, S.; Allali, I.; Fakim, Y.J. African Global Representation in Biomedical Sciences. Annu. Rev. Biomed. Data Sci. 2021, 4, 57–81. [Google Scholar] [CrossRef] [PubMed]
- Hamdi, Y.; Zass, L.; Othman, H.; Radouani, F.; Allali, I.; Hanachi, M.; Okeke, C.J.; Chaouch, M.; Tendwa, M.B.; Samtal, C.; et al. Human OMICs and Computational Biology Research in Africa: Current Challenges and Prospects. OMICS 2021, 25, 213–233. [Google Scholar] [CrossRef] [PubMed]
- Pereira, L.; Mutesa, L.; Tindana, P.; Ramsay, M. African genetic diversity and adaptation inform a precision medicine agenda. Nat. Rev. Genet. 2021, 22, 284–306. [Google Scholar] [CrossRef] [PubMed]
- Choudhury, A.; Aron, S.; Botigué, L.R.; Sengupta, D.; Botha, G.; Bensellak, T.; Wells, G.; Kumuthini, J.; Shriner, D.; Fakim, Y.J.; et al. High-depth African genomes inform human migration and health. Nature 2020, 586, 741–748. [Google Scholar] [CrossRef]
- Onadeko, O.T.; Okunowo, W.O.; Imaga, N.O.A.; Abdulrazaq, M.M.; Onuminya, O.J.; Van-Lare, T.O.; Nwosu, M. Polymorphism rs3737787 of Upstream Stimulatory Factor 1 gene is associated with serum lipid phenotype in Nigerian population. Mol. Cell Probes 2021, 55, 101687. [Google Scholar] [CrossRef]
- Lin, B.M.; Nadkarni, G.N.; Tao, R.; Graff, M.; Fornage, M.; Buyske, S.; Matise, T.C.; Highland, H.M.; Wilkens, L.R.; Carlson, C.S.; et al. Genetics of Chronic Kidney Disease Stages Across Ancestries: The PAGE Study. Front. Genet. 2019, 10, 494. [Google Scholar] [CrossRef] [Green Version]
- Sirugo, G.; Hennig, B.J.; Adeyemo, A.A.; Matimba, A.; Newport, M.J.; Ibrahim, M.E.; Ryckman, K.K.; Tacconelli, A.; Mariani-Costantini, R.; Novelli, G.; et al. Genetic studies of African populations: An overview on disease susceptibility and response to vaccines and therapeutics. Hum. Genet. 2008, 123, 557–598. [Google Scholar] [CrossRef]
- Twesigomwe, D.; Wright, G.E.B.; Drögemöller, B.I.; da Rocha, J.; Lombard, Z.; Hazelhurst, S. A systematic comparison of pharmacogene star allele calling bioinformatics algorithms: A focus on CYP2D6 genotyping. NPJ Genom. Med. 2020, 5, 30. [Google Scholar] [CrossRef]
- Da Rocha, J.E.B.; Othman, H.; Botha, G.; Cottino, L.; Twesigomwe, D.; Ahmed, S.; Drögemöller, B.I.; Fadlelmola, F.M.; Machanick, P.; Mbiyavanga, M.; et al. The Extent and Impact of Variation in ADME Genes in Sub-Saharan African Populations. Front. Pharmacol. 2021, 12, 634016. [Google Scholar] [CrossRef]
- Othman, H.; da Rocha, J.E.B.; Hazelhurst, S. Single Nucleotide Polymorphism Induces Divergent Dynamic Patterns in CYP3A5: A Microsecond Scale Biomolecular Simulation of Variants Identified in Sub-Saharan African Populations. Int. J. Mol. Sci. 2021, 22, 7786. [Google Scholar] [CrossRef] [PubMed]
- Mulder, N.J.; Adebiyi, E.; Alami, R.; Benkahla, A.; Brandful, J.; Doumbia, S.; Everett, D.; Fadlelmola, F.M.; Gaboun, F.; Gaseitsiwe, S.; et al. H3ABioNet, a sustainable pan-African bioinformatics network for human heredity and health in Africa. Genome Res. 2016, 26, 271–277. [Google Scholar] [CrossRef] [PubMed]
- Whirl-Carrillo, M.; McDonagh, E.M.; Hebert, J.M.; Gong, L.; Sangkuhl, K.; Thorn, C.F.; Altman, R.B.; Klein, T.E. Pharmacogenomics knowledge for personalized medicine. Clin. Pharmacol. Ther. 2012, 92, 414–417. [Google Scholar] [CrossRef] [PubMed]
- Piñero, J.; Ramírez-Anguita, J.M.; Saüch-Pitarch, J.; Ronzano, F.; Centeno, E.; Sanz, F.; Furlong, L.I. The DisGeNET knowledge platform for disease genomics: 2019 update. Nucleic Acids Res. 2020, 48, D845–D855. [Google Scholar] [CrossRef] [Green Version]
- Durinck, S.; Spellman, P.T.; Birney, E.; Huber, W. Mapping identifiers for the integration of genomic datasets with the R/Bioconductor package biomaRt. Nat. Protoc. 2009, 4, 1184–1191. [Google Scholar] [CrossRef] [Green Version]
- Wishart, D.S.; Knox, C.; Guo, A.C.; Shrivastava, S.; Hassanali, M.; Stothard, P.; Chang, Z.; Woolsey, J. DrugBank: A comprehensive resource for in silico drug discovery and exploration. Nucleic Acids Res. 2006, 34, D668–D672. [Google Scholar] [CrossRef]
- Kalman, L.V.; Agúndez, J.; Appell, M.L.; Black, J.L.; Bell, G.C.; Boukouvala, S.; Bruckner, C.; Bruford, E.; Caudle, K.; Coulthard, S.A.; et al. Pharmacogenetic allele nomenclature: International workgroup recommendations for test result reporting. Clin. Pharmacol. Ther. 2016, 99, 172–185. [Google Scholar] [CrossRef]
- Gaedigk, A.; Ingelman-Sundberg, M.; Miller, N.A.; Leeder, J.S.; Whirl-Carrillo, M.; Klein, T.E. The Pharmacogene Variation (PharmVar) Consortium: Incorporation of the Human Cytochrome P450 (CYP) Allele Nomenclature Database. Clin. Pharmacol. Ther. 2018, 103, 399–401. [Google Scholar] [CrossRef] [Green Version]
- Gaedigk, A.; Sangkuhl, K.; Whirl-Carrillo, M.; Twist, G.P.; Klein, T.E.; Miller, N.A. The Evolution of PharmVar. Clin. Pharmacol. Ther. 2019, 105, 29–32. [Google Scholar] [CrossRef] [Green Version]
- Zimmerman, P.A.; Buckler-White, A.; Alkhatib, G.; Spalding, T.; Kubofcik, J.; Combadiere, C.; Weissman, D.; Cohen, O.; Rubbert, A.; Lam, G.; et al. Inherited resistance to HIV-1 conferred by an inactivating mutation in CC chemokine receptor 5: Studies in populations with contrasting clinical phenotypes, defined racial background, and quantified risk. Mol. Med. 1997, 3, 23–36. [Google Scholar] [CrossRef] [Green Version]
- Altman, R.B. PharmGKB: A logical home for knowledge relating genotype to drug response phenotype. Nat. Genet. 2007, 39, 426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pinero, J.; Bravo, A.; Queralt-Rosinach, N.; Gutiérrez-Sacristán, A.; Deu-Pons, J.; Centeno, E.; García-García, J.; Sanz, F.; Furlong, L.I. DisGeNET: A comprehensive platform integrating information on human disease-associated genes and variants. Nucleic Acids Res. 2017, 45, D833–D839. [Google Scholar] [CrossRef] [PubMed]
- Huddart, R.; Fohner, A.E.; Whirl-Carrillo, M.; Wojcik, G.L.; Gignoux, C.R.; Popejoy, A.B.; Bustamante, C.D.; Altman, R.B.; Klein, T.E. Standardized Biogeographic Grouping System for Annotating Populations in Pharmacogenetic Research. Clin. Pharmacol. Ther. 2019, 105, 1256–1262. [Google Scholar] [CrossRef] [PubMed]
- Arauna, L.R.; Hellenthal, G.; Comas, D. Dissecting human North African gene-flow into its western coastal surroundings. Proc. Biol. Sci. 2019, 286, 20190471. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fregel, R.; Méndez, F.L.; Bokbot, Y.; Martín-Socas, D.; Camalich-Massieu, M.D.; Santana, J.; Morales, J.; Ávila Arcos, M.C.; Underhill, P.A.; Shapiro, B.; et al. Ancient genomes from North Africa evidence prehistoric migrations to the Maghreb from both the Levant and Europe. Proc. Natl. Acad. Sci. USA 2018, 115, 6774–6779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Botigué, L.R.; Henn, B.M.; Gravel, S.; Maples, B.K.; Gignoux, C.R.; Corona, E.; Atzmon, G.; Burns, E.; Ostrer, H.; Flores, C.; et al. Gene flow from North Africa contributes to differential human genetic diversity in southern Europe. Proc. Natl. Acad. Sci. USA 2013, 110, 11791–11796. [Google Scholar] [CrossRef] [Green Version]
- Radouani, F.; Zass, L.; Hamdi, Y.; Rocha, J.D.; Sallam, R.; Abdelhak, S.; Ahmed, S.; Azzouzi, M.; Benamri, I.; Benkahla, A.; et al. A review of clinical pharmacogenetics Studies in African populations. Per. Med. 2020, 17, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Fadlelmola, F.M.; Zass, L.; Chaouch, M.; Samtal, C.; Ras, V.; Kumuthini, J.; Panji, S.; Mulder, N. Data Management Plans in the genomics research revolution of Africa: Challenges and recommendations. J. Biomed. Inform. 2021, 122, 103900. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Othman, H.; Zass, L.; da Rocha, J.E.B.; Radouani, F.; Samtal, C.; Benamri, I.; Kumuthini, J.; Fakim, Y.J.; Hamdi, Y.; Mezzi, N.; et al. African Genomic Medicine Portal: A Web Portal for Biomedical Applications. J. Pers. Med. 2022, 12, 265. https://doi.org/10.3390/jpm12020265
Othman H, Zass L, da Rocha JEB, Radouani F, Samtal C, Benamri I, Kumuthini J, Fakim YJ, Hamdi Y, Mezzi N, et al. African Genomic Medicine Portal: A Web Portal for Biomedical Applications. Journal of Personalized Medicine. 2022; 12(2):265. https://doi.org/10.3390/jpm12020265
Chicago/Turabian StyleOthman, Houcemeddine, Lyndon Zass, Jorge E. B. da Rocha, Fouzia Radouani, Chaimae Samtal, Ichrak Benamri, Judit Kumuthini, Yasmina J. Fakim, Yosr Hamdi, Nessrine Mezzi, and et al. 2022. "African Genomic Medicine Portal: A Web Portal for Biomedical Applications" Journal of Personalized Medicine 12, no. 2: 265. https://doi.org/10.3390/jpm12020265
APA StyleOthman, H., Zass, L., da Rocha, J. E. B., Radouani, F., Samtal, C., Benamri, I., Kumuthini, J., Fakim, Y. J., Hamdi, Y., Mezzi, N., Boujemaa, M., Okeke, C. J., Tendwa, M. B., Sanak, K., Chaouch, M., Panji, S., Kefi, R., Sallam, R. M., Ghoorah, A. W., ... Kamal Kassim, S. (2022). African Genomic Medicine Portal: A Web Portal for Biomedical Applications. Journal of Personalized Medicine, 12(2), 265. https://doi.org/10.3390/jpm12020265