1. Introduction
Cold rolled strip is a true all-round material in various products such as automobiles, electrical appliances, ships etc. With the rapid development of the economy, the demand for cold rolled strip increases year by year. In the production of cold rolled strip, various defects appear on the surface of the rolled strip due to various reasons such as issues from manufacturing technology, equipment etc. These defects not only affect the appearance of the products, but also degrade the performance of the products. To eliminate these defects, they should be detected at the first instance with a surface inspection system [
1]. The detection system is machine vision-based, which has become the mainstream of all identification methods. Feature extraction and classification are the key steps of the machine vision method. The step “local feature extraction” has been widely used in machine vision for image recognition [
2], image retrieval [
3], image registration [
4], image classification [
5], image mosaicking [
6]. Defects are caused for different reasons and appear in different types. Useful features are extracted from the surface images for the detection and classification of the defects on the surface. The cause of different types of defects can then be tracked and addressed.
New types of defects are often discovered in the production of cold rolled strip. To identify these new defects, the production line is normally suspended and then the classification model is retrained with added sample images for the new defect. If the re-training process takes a long time, the product will be impacted. Therefore, a classification model with fast training and identification algorithms is preferred. In the production line, workers change the rolls of a cold rolling mill when a coil of raw strip steel is run out. If the model retraining can be finished within the time of roll change, the classification model can be quickly adapted to the online real-time identification of new defects. This will avoid the suspension of the production.
In this paper, we will explore various options for the image feature extraction and classification and aim to find the best option for the fast identification of the defects with high classification accuracy and high computing performance for the training of the classification model.
There are several popular feature extraction methods, including Scale Invariant Feature Transform [
7] (SIFT), Speeded Up Robust Feature [
8] (SURF) and Local Binary Pattern [
9] (LBP). Lowe proposed efficient SIFT algorithm to speed up feature extraction. Based on SIFT, Bay proposed more efficient SURF algorithm [
8] to further speed up feature extraction. Ojala presented LBP algorithm [
9], which is a redefinition of the grayscale values of the original image and a simple combination of histogram. Compared to SIFT and SURF, LBP has less computational complexity, leading to higher computing performance in feature extraction.
Literature has reported several popular classification methods, including Back Propagation neural networks [
10] (BP), Support Vector Machine [
11] (SVM) and Extreme Learning Machine [
12] (ELM). The algorithms of BP neural networks are complicated and slow in training. BP neural network requires many iterations to compute weights [
13] and it is easy for it to get stuck in a local minima. The identification of complex surface defects of cold rolled strip is a problem of multi-class classification, in which the classic SVM has some disadvantages [
14]. ELM [
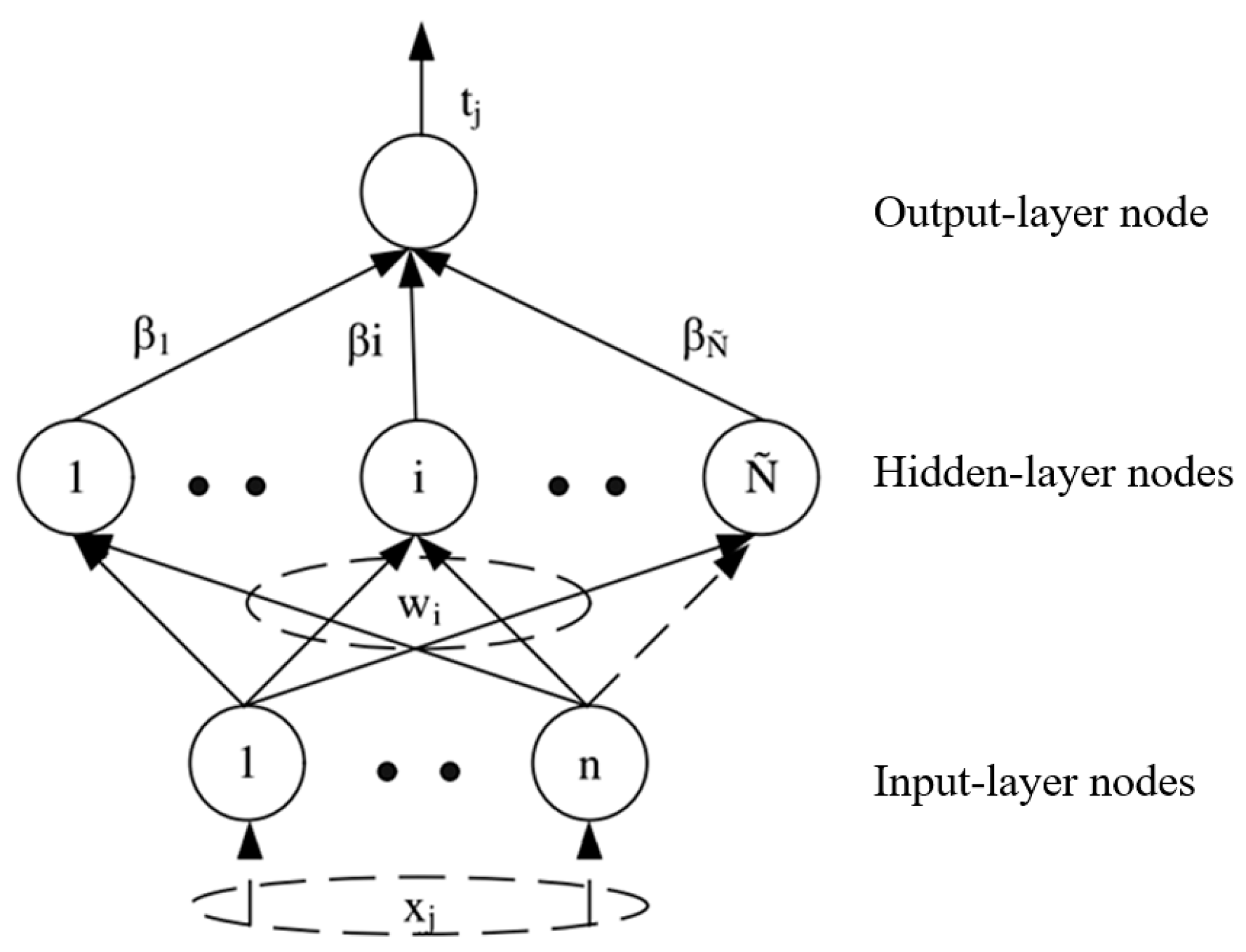
15] (Extreme learning machine) is an improved algorithm based on single hidden layer feedforward neural networks. The only artificial parameter of ELM is the number of hidden layer nodes. Initial weights are randomly generated. ELM is fully automatically implemented without iterative tuning, and it is extremely fast compared to other traditional learning methods. Hence ELM is potentially a solution to satisfy the real-time requirement in online defect identification of cold rolled strip. This paper is organized as follows:
Section 2 introduces the principle of LBP and ELM algorithms;
Section 3 demonstrates the computing performance of LBP and ELM with comparison among several hybrid methods for the surface defect identification;
Section 4 illustrates how the hybrid method of LBP and ELM can be adapted to identify a new defect with an online surface inspection case study; the conclusions are drawn in
Section 5.
Acknowledgments
This work is sponsored by The National Natural Science Foundation of China (No. 51674031). The authors are indebted to the Collaborative Innovation Center of Steel Technology (CICST), the University of Science and Technology Beijing (USTB), Quantitative Imaging Research Team (QIRT) and Commonwealth Scientific and Industrial Research Organization (CSIRO) for the development infrastructure and financial support.
Author Contributions
Yang Liu conceived, designed and designed the experiments; Ke Xu and Dadong Wang contributed experiment data, materials and experiment equipments; Yang Liu and Ke Xu analyzed the data; Yang Liu wrote the paper; Ke Xu and Dadong Wang revised the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xu, K.; Liu, S.; Ai, Y. Application of Shearlet Transform to Classification of Surface Defects for Metals. Image Vis. Comput. 2015, 35, 23–30. [Google Scholar] [CrossRef]
- Kawano, Y.; Yanai, K. Food image recognition with deep convolutional features. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; ACM: New York, NY, USA, 2014; pp. 589–593. [Google Scholar]
- Yue-Hei Ng, J.; Yang, F.; Davis, L.S. Exploiting local features from deep networks for image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015; pp. 53–61. [Google Scholar]
- Mohanaiah, P.; Sathyanarayana, P.; GuruKumar, L. Image texture feature extraction using GLCM approach. Int. J. Sci. Res. Publ. 2013, 3, 1. [Google Scholar]
- Romero, A.; Gatta, C.; Camps-valls, G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Bheda, D.; Joshi, M.; Agrawal, V. A study on features extraction techniques for image mosaicing. Int. J. Innov. Res. Comput. Commun. Eng. 2014, 2, 3432–3437. [Google Scholar]
- Li, Y.; Liu, W.; Li, X.; Huang, Q.; Li, X. GA-SIFT: A new scale invariant feature transform for multispectral image using geometric algebra. Inf. Sci. 2014, 281, 559–572. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up Robust Features (surf). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A Comparative Study of Texture Measures with Classification Based on Featured Distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. Neural Netw. 1988, 1 (Suppl. S1), 445–448. [Google Scholar] [CrossRef]
- Jiang, J.; Song, C.; Wu, C.; Marchese, M.; Liang, Y. Support vector machine regression algorithm based on chunking incremental learning. In Proceedings of the International Conference on Computational Science, Reading, UK, 28–31 May 2006; pp. 547–554. [Google Scholar]
- Huang, G.; Zhu, Q.; Siew, C. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Efficient and Effective Algorithms for Training Single-hidden-layer Neural Networks. Pattern Recognit. Lett. 2012, 33, 554–558. [Google Scholar] [CrossRef]
- Hu, J.; Li, D.; Duan, Q.; Han, Y.; Chen, G.; Si, X. Fish species classification by color, texture and multi-class support vector machine using computer vision. Comput. Electron. Agric. 2012, 88, 133–140. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Mohamed, A.A.; Yampolskiy, R.V. An improved LBP algorithm for avatar face recognition. In Proceedings of the 2011 XXIII International Symposium on Information, Communication and Automation Technologies (ICAT), Sarajevo, Bosnia and Herzegovina, 27–29 October 2011; pp. 1–5. [Google Scholar]
- Nanni, L.; Lumini, A.; Brahnam, S. Survey on LBP Based Texture Descriptors for Image Classification. Expert Syst. Appl. 2012, 39, 3634–3641. [Google Scholar] [CrossRef]
- Shan, C. Learning Local Binary Patterns for Gender Classification on Real-world Face Images. Pattern Recognit. Lett. 2012, 33, 431–437. [Google Scholar] [CrossRef]
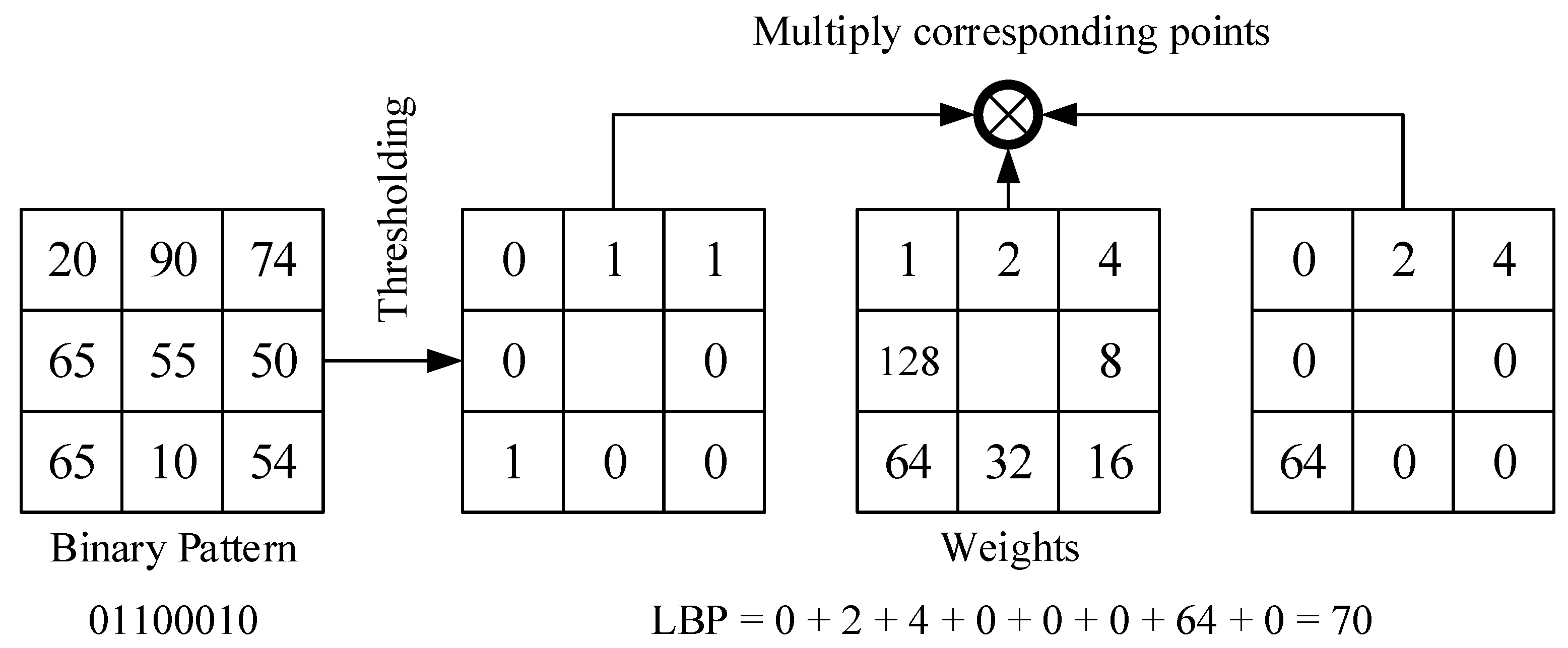
Figure 1.
Principle and encoding process of the LBP (Local Binary Pattern).
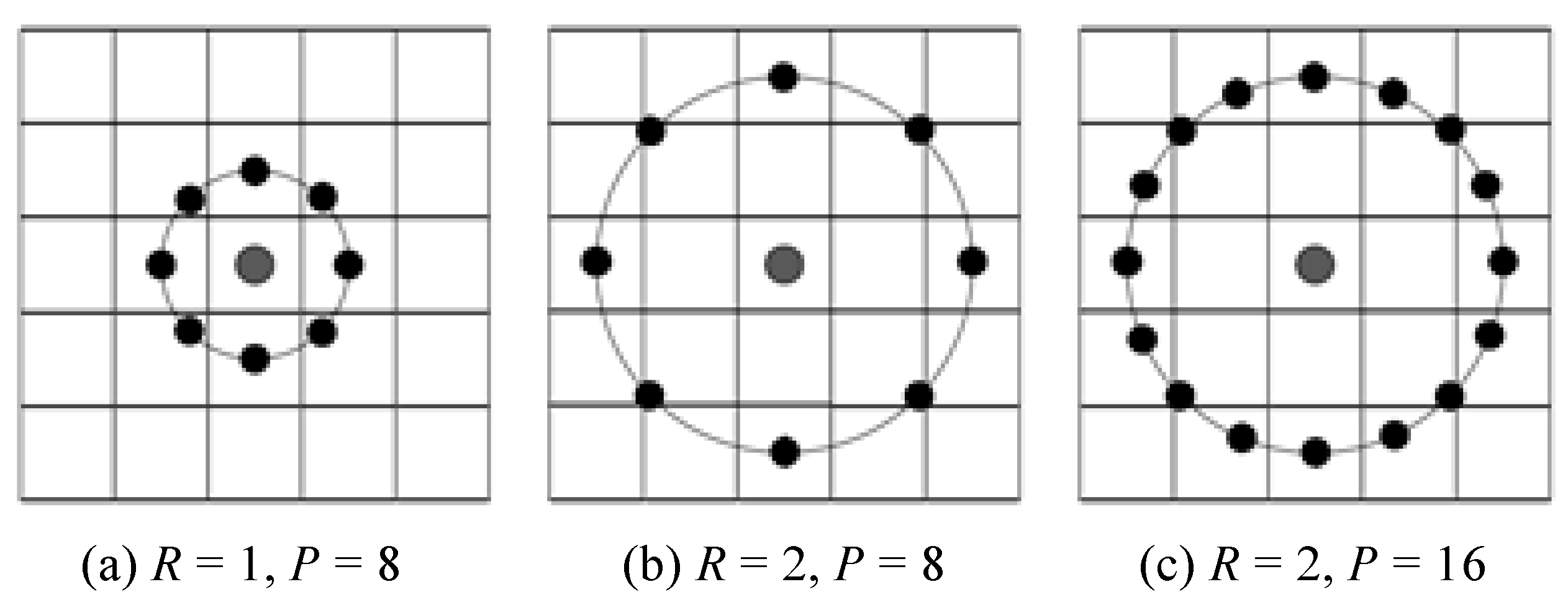
Figure 2.
Principle of improved LBP.
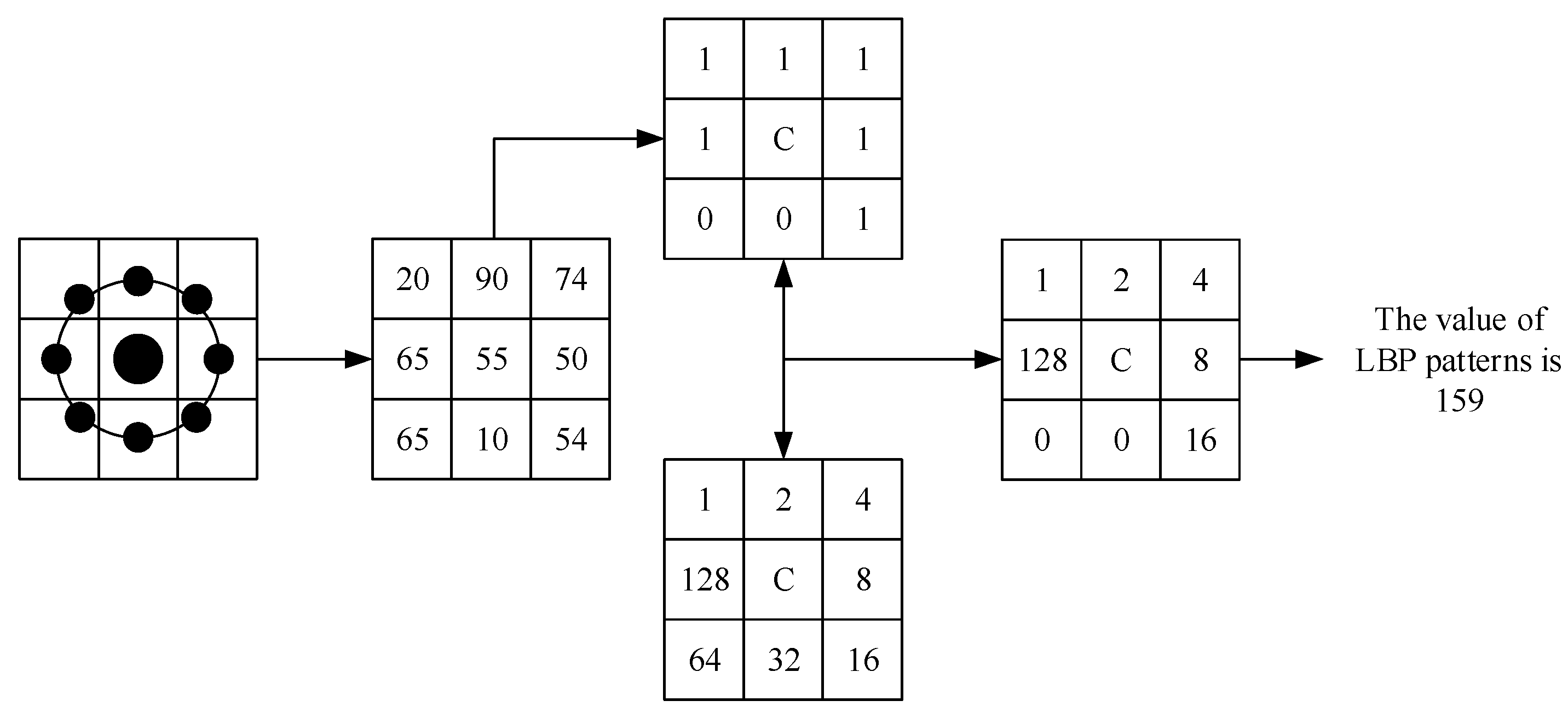
Figure 3.
Encoding process of the improved .
Figure 4.
Model of ELM neural network.
Figure 5.
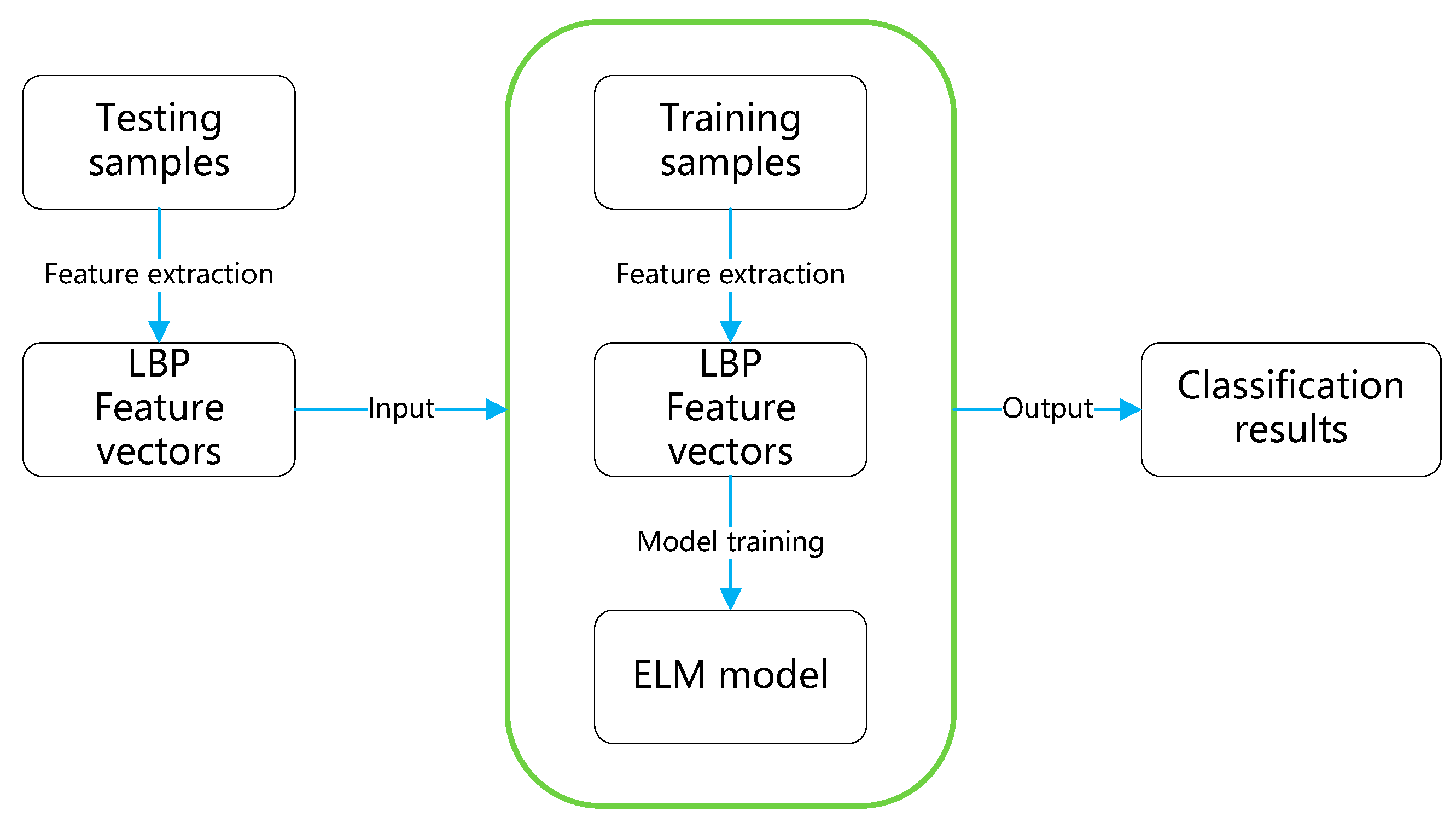
Flowchart of the experiment.
Figure 6.
Original defect images: scratches (a), slags (b), peels (c), no defects (d).
Figure 7.
The images after applying LBP feature extraction: scratches (a), slags (b), peels (c), no defects (d).
Figure 8.
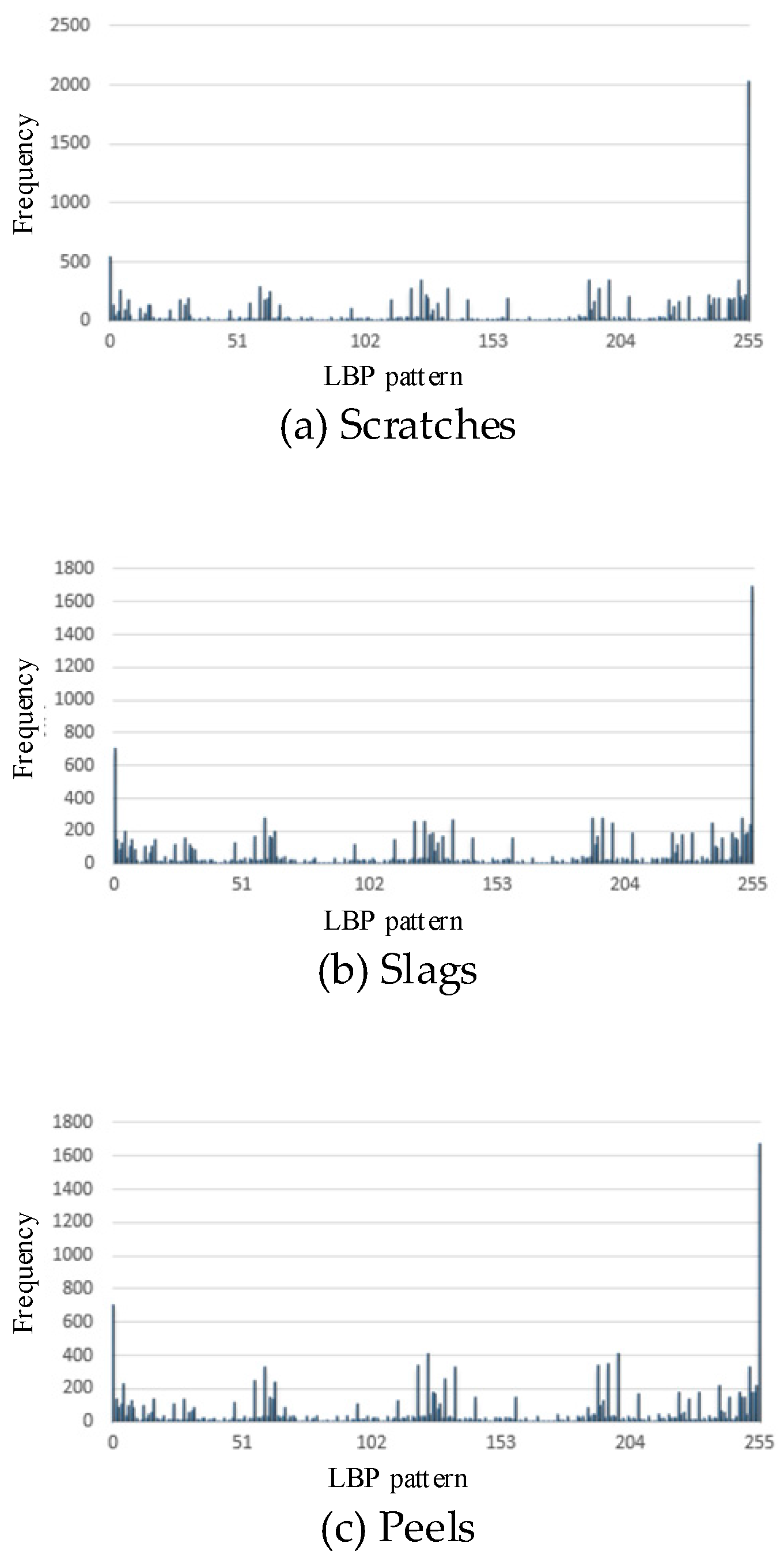
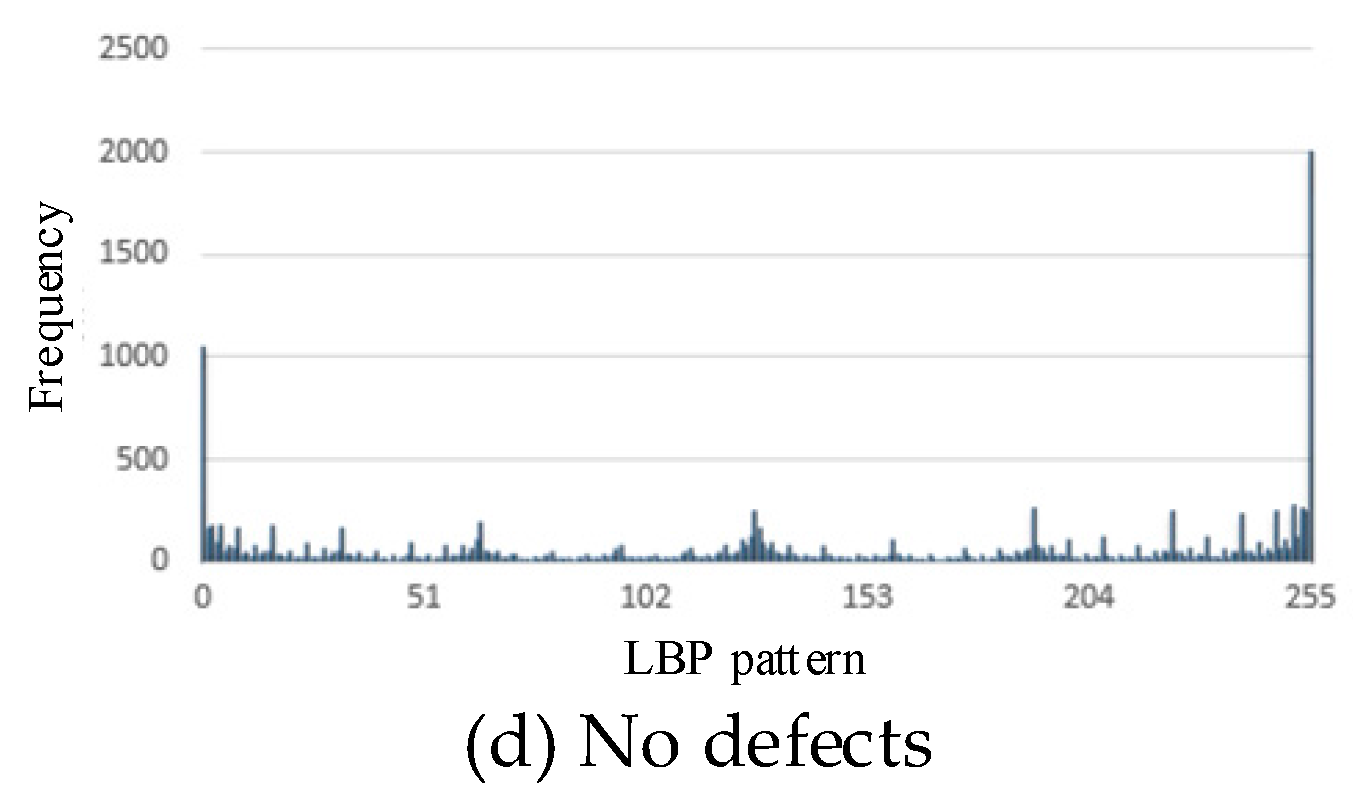
The 256-dimensionial histogram of LBP patterns: scratches (a), slags (b), peels (c), no defects (d).
Figure 9.
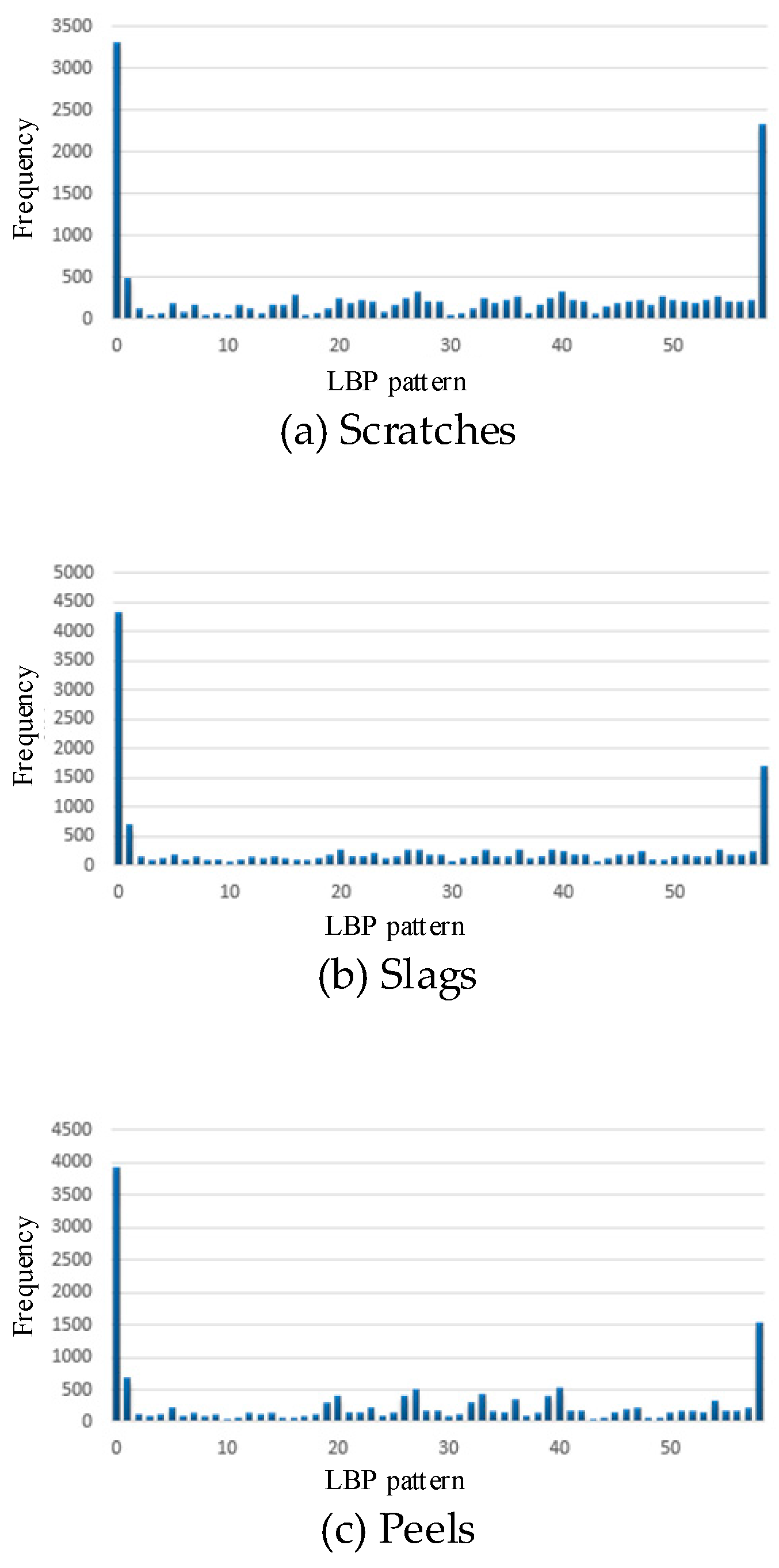
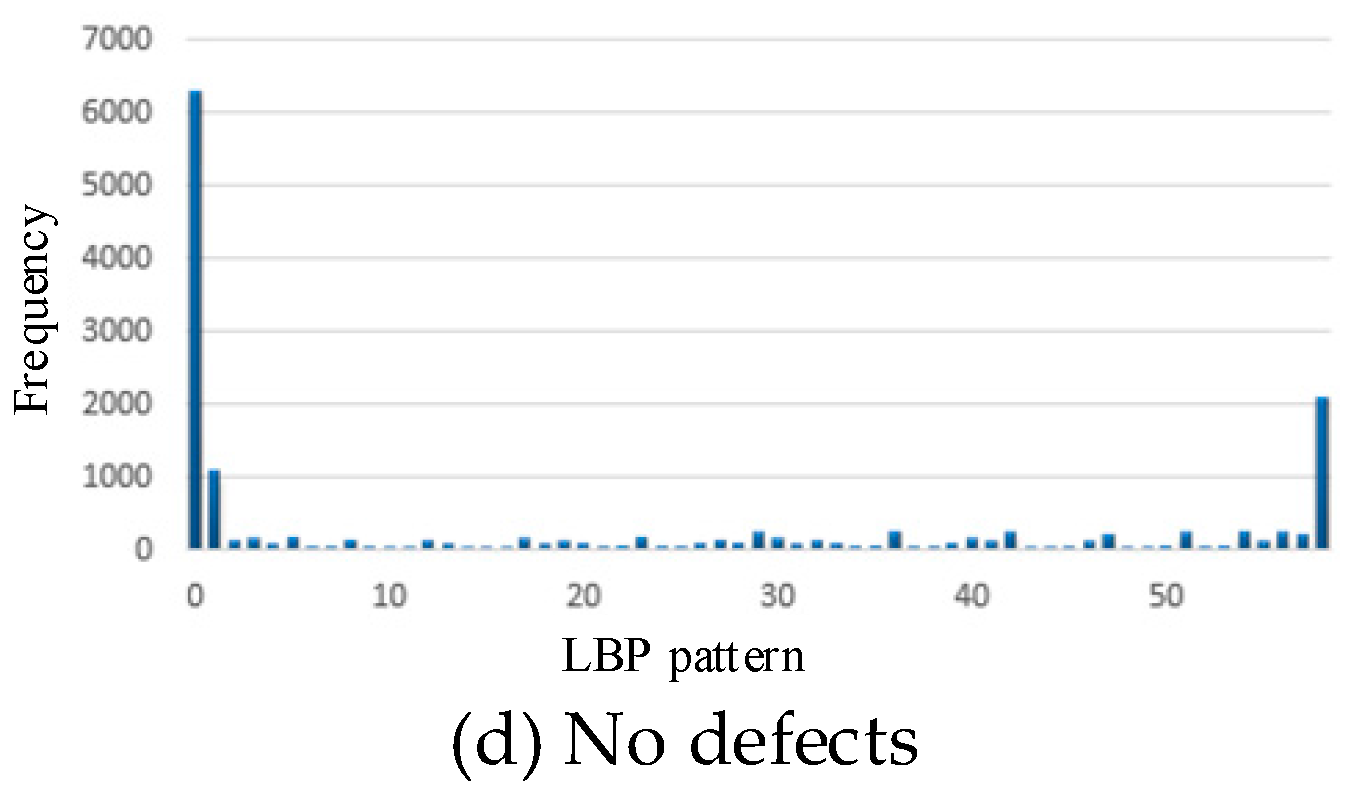
59-dimensional histogram of LBP patterns: scratches (a), slags (b), peels (c), no defects (d).
Figure 10.
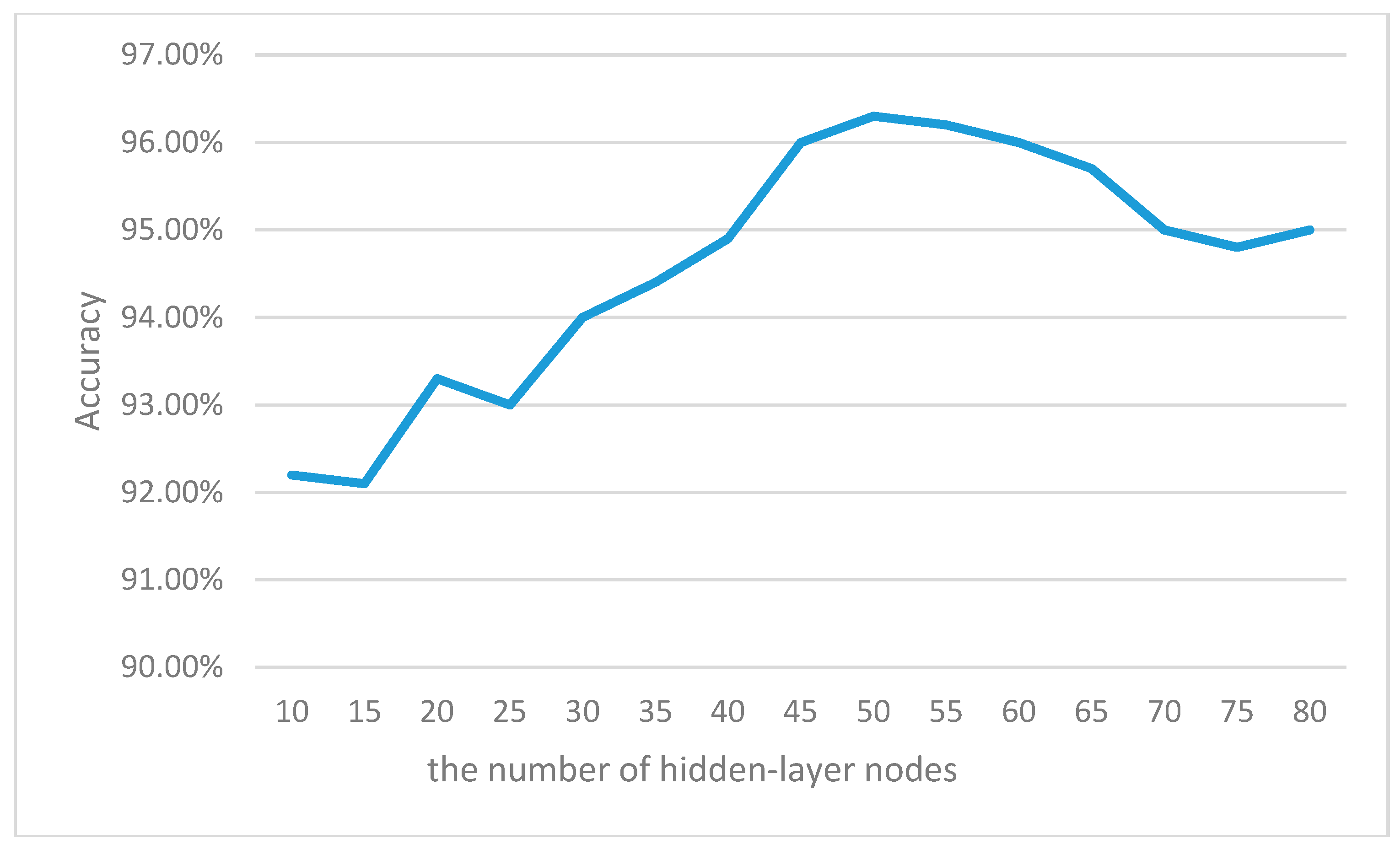
Accuracy of cross-validation test with different hidden-nodes numbers.
Figure 11.
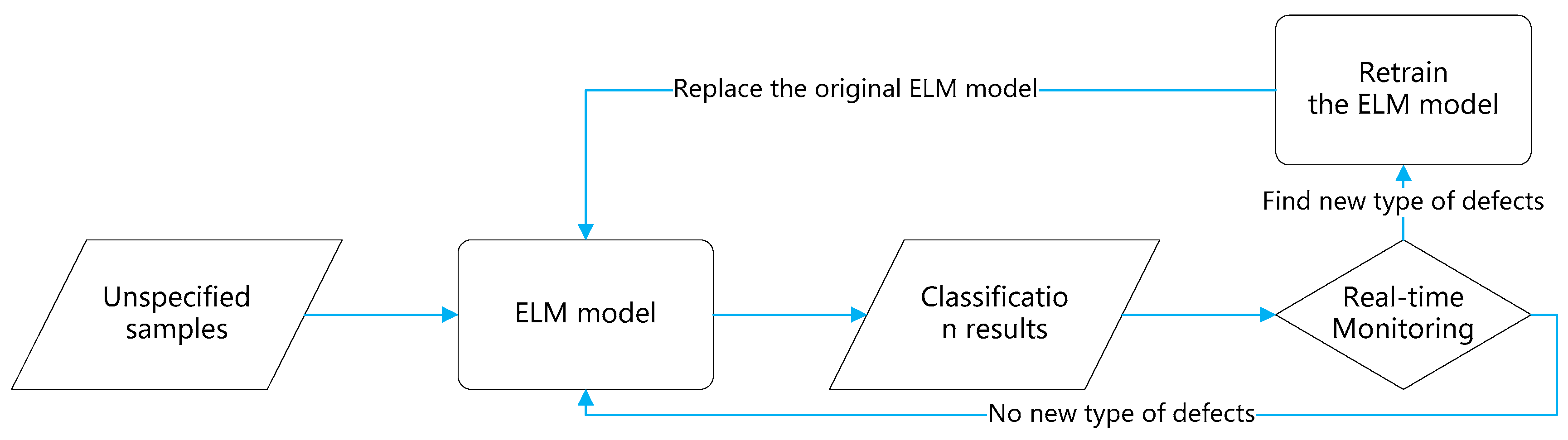
Flowchart of the online monitoring system.
Figure 12.
Four defect types: scratches (a), slags (b), peels (c), no defects (d).
Figure 13.
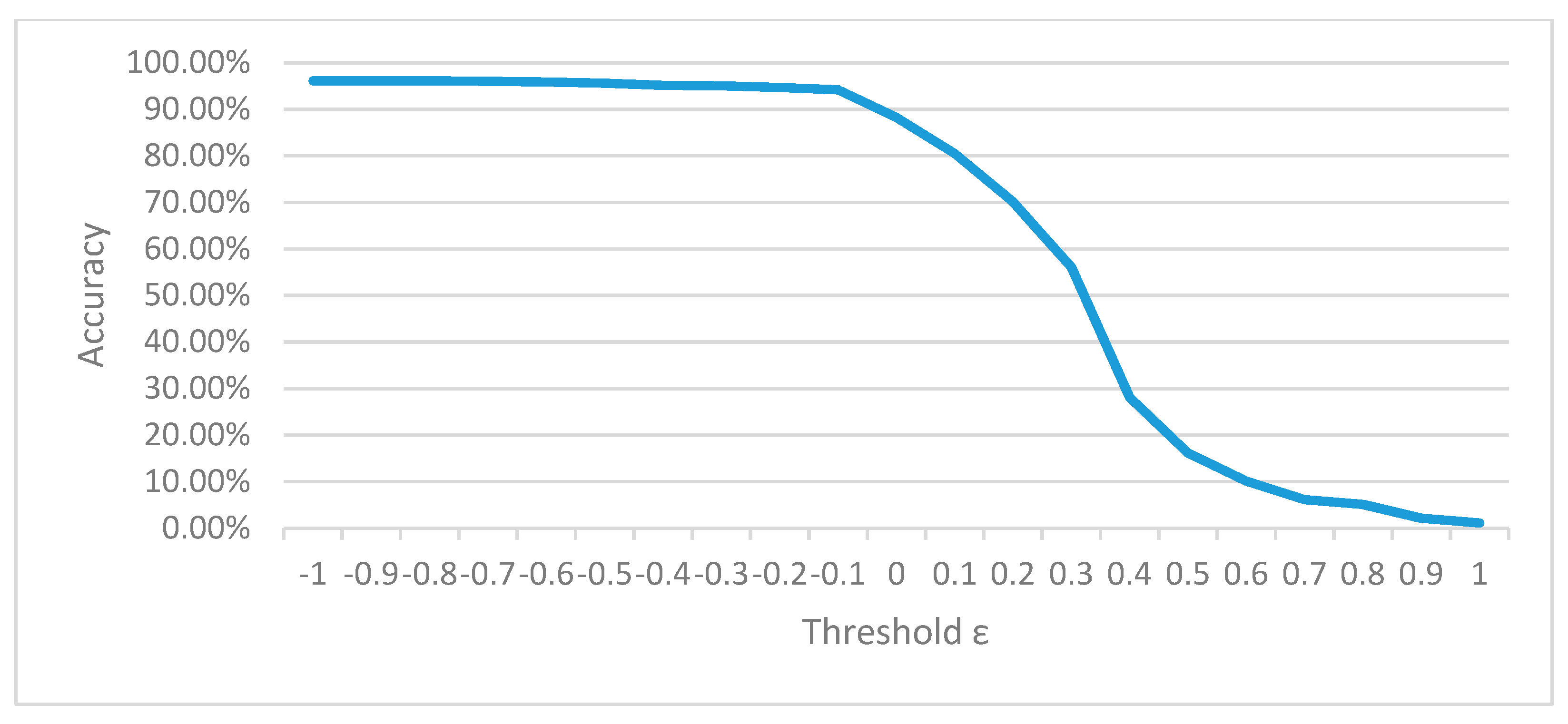
Classification accuracy changes with different threshold values.
Table 1.
The number of training and testing samples.
| Defect Type | Number of Training Samples | Number of Testing Samples |
|---|
| Scratch | 296 | 216 |
| Slag | 178 | 100 |
| Peel | 362 | 302 |
| No defect | 512 | 512 |
Table 2.
Comparison of average computation time among LBP, SIFT and SURF.
| Method | Sample Size (Pixels)
(0.3 mm/Pixel) | Dimensions | Computation Time (ms) |
|---|
| LBP | 128 × 128 | 256 | 15 |
| LBP | 128 × 128 | 59 (After dimension reduction) | 15 |
| SIFT | 128 × 128 | 128 × number of features | 72 |
| SURF | 128 × 128 | 64 × number of features | 22 |
Table 3.
Comparison of training time among ELM and other models.
| Learning Model | Sample Size | Feature Dimensions | Parameters | Training Time (ms) |
|---|
| BP | 1348 | 256 | 50 hidden nodes | 153,354 |
| BP | 1348 | 59 | 50 hidden nodes | 41,017 |
| SVM | 1348 | 256 | Linear Kernel | 6338 |
| SVM | 1348 | 59 | Linear Kernel | 6137 |
| ELM | 1348 | 256 | 50 hidden nodes | 2059 |
| ELM | 1348 | 59 | 50 hidden nodes | 865 |
Table 4.
Confusion matrix using ELM with 256-dimensional feature vectors.
| Defect Type | Scratch | Slag | Peel | No Defect | Correctly Classified | Sample Number | Classification Accuracy |
|---|
| Scratch | 204 | 0 | 2 | 10 | 204 | 216 | 94.44% |
| Slag | 5 | 85 | 6 | 4 | 85 | 100 | 85.00% |
| Peel | 6 | 5 | 281 | 10 | 281 | 302 | 93.05% |
| No defect | 0 | 3 | 4 | 505 | 505 | 512 | 98.63% |
| Total | 215 | 93 | 293 | 529 | 1075 | 1130 | 95.13% |
Table 5.
Confusion matrix using ELM with 59-dimensional feature vectors.
| Defect Type | Scratch | Slag | Peel | No Defect | Correctly Classified | Sample Number | Classification Rate |
|---|
| Scratch | 206 | 4 | 2 | 4 | 206 | 216 | 95.37% |
| Slag | 1 | 89 | 6 | 4 | 89 | 100 | 89.00% |
| Peel | 3 | 5 | 289 | 5 | 289 | 302 | 95.70% |
| No defect | 0 | 0 | 0 | 512 | 512 | 512 | 100.00% |
| Total | 210 | 98 | 297 | 525 | 1096 | 1130 | 96.99% |
Table 6.
Comparison of the computation and classification performance among ELM and other methods.
| Method | Average Classification Accuracy | Feature Dimensions | Classification Time
(ms Per Sample) |
|---|
| SURF + SVM | 90.57% | 64 × number of features | 138 |
| LBP + BP | 69.71% | 256 | 33 |
| LBP + BP | 82.45% | 59 | 21 |
| LBP + SVM | 94.47% | 256 | 47 |
| LBP + SVM | 95.01% | 59 | 43 |
| LBP + ELM | 95.13% | 256 | 17 |
| LBP + ELM | 96.99% | 59 | 15 |
Table 7.
The number of training samples for each defect type.
| Defect Type | Number of Training Samples |
|---|
| Scratch | 160 |
| Slag | 80 |
| Peel | 200 |
| No significant defect | 300 |
Table 8.
Confusion matrix with unknown defect type.
| Defect Type | Scratch | Slag | Peel | No Defect | Unknown Defect | Total | Classification Accuracy |
|---|
| Scratch | 109 | 0 | 2 | 7 | 2 | 120 | 90.83% |
| Slag | 6 | 49 | 3 | 1 | 1 | 60 | 81.67% |
| Peel | 3 | 2 | 132 | 11 | 2 | 150 | 88.00% |
| No defect | 0 | 0 | 1 | 218 | 1 | 220 | 99.09% |
| Total | 118 | 51 | 138 | 237 | 6 | 550 | 92.36% |
Table 9.
Confusion matrix with the addition of pores defect.
| Defect Type | Scratch | Slag | Peel | No Defect | Unknown Defect | Total | Classification Accuracy |
|---|
| Scratch | 109 | 0 | 2 | 7 | 2 | 120 | 90.83% |
| Slag | 6 | 49 | 3 | 1 | 1 | 60 | 81.67% |
| Peel | 3 | 2 | 132 | 11 | 2 | 150 | 88.00% |
| No defect | 0 | 0 | 1 | 218 | 1 | 220 | 99.09% |
| Pore | 0 | 2 | 0 | 0 | 28 | 30 | N/A |
| Total | 118 | 53 | 138 | 237 | 34 | 580 | 87.59% |
Table 10.
New confusion matrix using retrained ELM with new samples of “pore”.
| Defect Type | Scratch | Slag | Peel | No Defect | Pore | Unknown Defect | Total | Classification Accuracy |
|---|
| Scratch | 108 | 0 | 3 | 7 | 0 | 2 | 120 | 90.00% |
| Slag | 5 | 49 | 3 | 1 | 1 | 1 | 60 | 81.67% |
| Peel | 4 | 3 | 131 | 10 | 0 | 2 | 150 | 87.33% |
| No defect | 0 | 0 | 2 | 216 | 0 | 2 | 220 | 98.18% |
| Pore | 0 | 4 | 2 | 4 | 18 | 2 | 30 | 60.00% |
| Total | 117 | 56 | 141 | 238 | 19 | 9 | 580 | 90.00% |
Table 11.
Confusion matrix with new samples of the defect type “white spot”.
| Defect Type | Scratch | Slag | Peel | No Defect | Pore | Unknown Defect | Total | Classification Accuracy |
|---|
| Scratch | 108 | 0 | 3 | 7 | 0 | 2 | 120 | 90.00% |
| Slag | 5 | 49 | 3 | 1 | 1 | 1 | 60 | 81.67% |
| Peel | 4 | 3 | 131 | 10 | 0 | 2 | 150 | 87.33% |
| No defect | 0 | 0 | 2 | 216 | 0 | 2 | 220 | 98.18% |
| Pore | 0 | 4 | 2 | 4 | 18 | 2 | 30 | 60.00% |
| White spot | 0 | 0 | 1 | 2 | 0 | 22 | 25 | N/A |
| Total | 117 | 56 | 142 | 240 | 19 | 31 | 605 | 86.28% |
Table 12.
Confusion matrix obtained using the retrained ELM with new samples of “white spot”.
| Defect Type | Scratch | Slag | Peel | No Defect | Pore | White Spot | Unknown Defect | Total | Classification Accuracy |
|---|
| Scratch | 106 | 0 | 4 | 6 | 0 | 2 | 2 | 120 | 88.33% |
| Slag | 4 | 47 | 2 | 2 | 3 | 0 | 2 | 60 | 78.33% |
| Peel | 2 | 3 | 133 | 11 | 0 | 0 | 1 | 150 | 88.67% |
| No defect | 0 | 0 | 0 | 217 | 0 | 1 | 2 | 220 | 98.64% |
| Pores | 0 | 5 | 3 | 2 | 18 | 1 | 1 | 30 | 60.00% |
| White spot | 0 | 0 | 1 | 7 | 0 | 17 | 0 | 25 | 68.00% |
| Total | 112 | 55 | 143 | 245 | 21 | 21 | 8 | 605 | 88.93% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}