Prediction of Central Carbon Segregation in Continuous Casting Billet Using A Regularized Extreme Learning Machine Model




Abstract
:1. Introduction
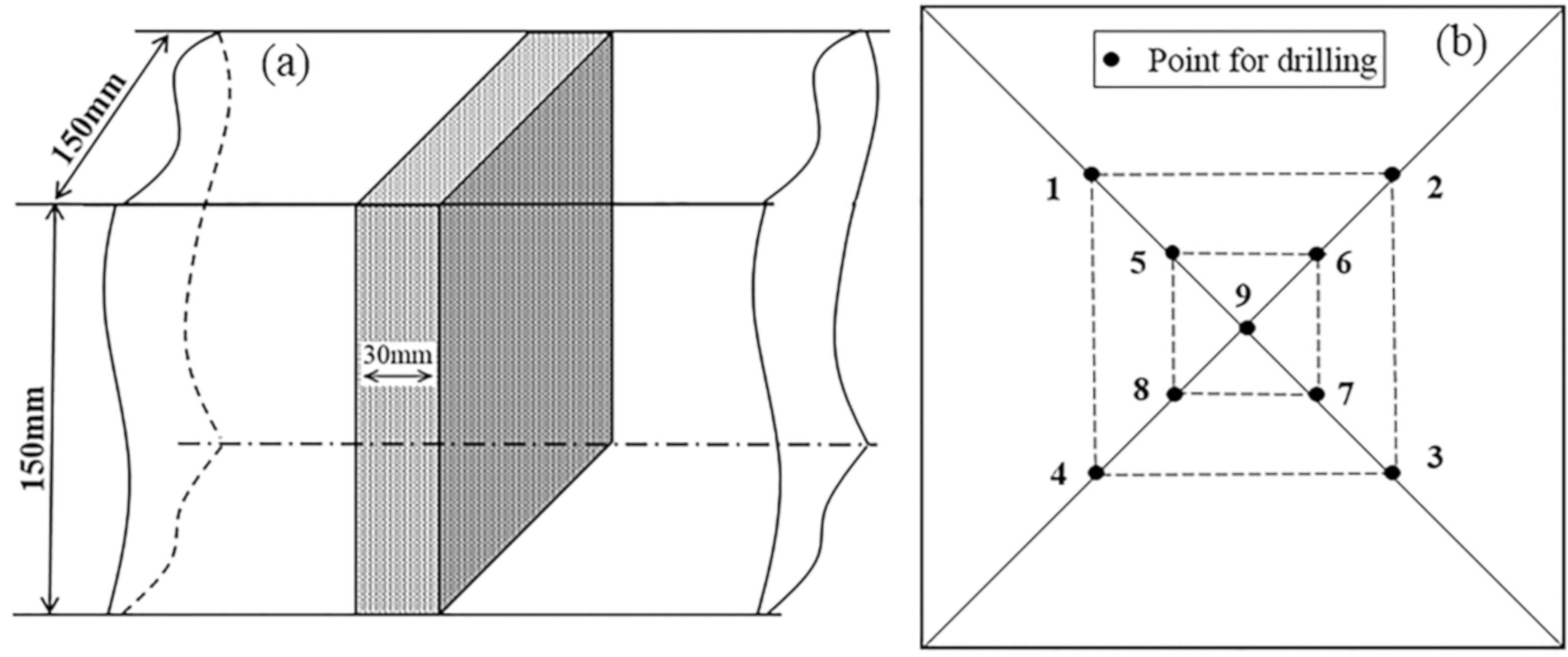
2. Problem Description and Experimental Data
2.1. Problem Description
2.2. Experimental Data
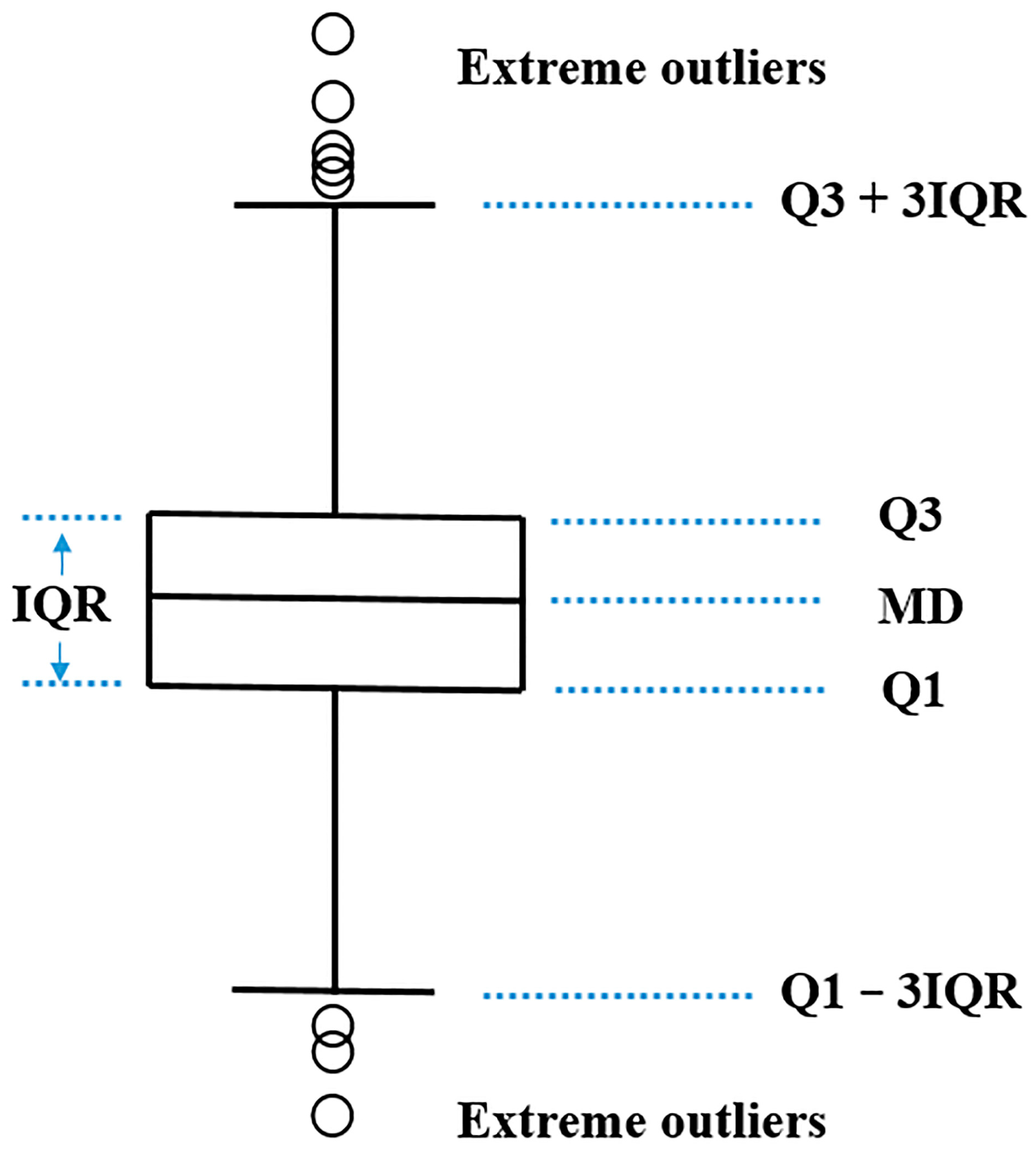
3. Data Cleaning
3.1. Data Normalization
3.2. Outlier Detection
4. Feature Engineering
4.1. Feature Correlation
4.2. Feature Selection
5. Establishment of CSI Prediction Models
5.1. Multiple Linear Regression Model
4.400 × 10−5 X7 − 1.550 × 10−4X8 − 1.380 × 10−4 X9 + 7.000 × 10−6 X10 − 0.028 X11 +
2.000 × 10−3 X12 + 5.380 × 10−4 X13 + 8.647 × 10−3.
5.2. Extreme Learning Machine Model
5.3. Regularized Extreme Learning Machine Model
- (1)
- ELM is only based on the principle of empirical risk minimization and takes the training error minimization as the purpose, while does not take the structural risk into account. Hence, the problem of over-fitting still exists.
- (2)
- The computational robustness problems may occur when the hidden layer output matrix is a non-full column rank matrix or an ill-conditioned matrix because of its randomly generated input weights and biases.
6. Results and Discussion
7. Conclusions
- (1)
- Boxplots can give a visual display of abnormal values in industrial data. GRA simplifies the neural network structure and further improves the hit ratio of data-driven models.
- (2)
- The test results indicate that the predicted values of the MLR model cannot agree well with target values. By contrast, the prediction accuracy of the ELM model is much higher. When predictive errors are within ±0.025 and ±0.03, the prediction accuracy is 84% and 90%, respectively. Moreover, the computation time is only 0.02 s.
- (3)
- In order to further improve the prediction accuracy and generalization ability of the ELM model, this paper proposed an R-ELM model for CSI prediction. The test results show that the prediction accuracy of R-ELM model is higher than that of the MLR model and the ELM model. When predictive errors are within ±0.03 and ±0.025, the prediction accuracy of R-ELM model is 94% and 89%, respectively. Additionally, the correlation coefficient between the target values and predicted values of the R-ELM model is 0.871, while the MLR model and ELM model are 0.571 and 0.813, respectively.
- (4)
- Response surface analysis was conducted on the predictions of the R-ELM model, and the results are consistent with metallurgical mechanism. Moreover, the test results of C80D steel samples from two casters agree well with the predicted values of the R-ELM model. The above conclusions further verify the correctness and generalization ability of the R-ELM model.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, R.J.; Fu, J.X.; Wu, Y.X.; Yang, Y.J.; Zhu, Y.Y.; Zhang, M. Representative technologies for hot charging and direct rolling in global steel industry. ISIJ Int. 2015, 55, 1816–1821. [Google Scholar]
- Zhou, T.; Zhang, P.; Kuuskman, K.; Cerilli, E.; Cho, S.H.; Burella, D.; Zurob, H.S. Development of medium-to-high carbon hot-rolled steel strip on a thin slab casting direct strip production complex. Ironmak. Steelmak. 2017, 45, 603–610. [Google Scholar]
- Pickering, E.J. Macrosegregation in steel ingots: The applicability of modelling and characterisation techniques. ISIJ Int. 2013, 53, 935–949. [Google Scholar] [CrossRef] [Green Version]
- Ludlow, V.; Normanton, A.; Anderson, A.; Thiele, M.; Ciriza, J.; Laraudogoitia, J.; Knoop, W. Strategy to minimise central segregation in high carbon steel grades during billet casting. Ironmak. Steelmak. 2005, 32, 68–74. [Google Scholar] [CrossRef]
- Choudhary, S.K.; Ganguly, S. Morphology and segregation in continuously cast high carbon steel billets. ISIJ Int. 2007, 47, 1759–1766. [Google Scholar] [CrossRef] [Green Version]
- Vušanović, I.; Vertnik, R.; Šarler, B. A simple slice model for prediction of macrosegregation in continuously cast billets. In Proceedings of the 3rd International Conference on Advances in Solidification Processes, Aachen, The Netherlands, 7–10 June 2011. [Google Scholar]
- Dong, Q.; Zhang, J.; Qian, L.; Yin, Y. Numerical modeling of macrosegregation in round billet with different microsegregation models. ISIJ Int. 2017, 57, 814–823. [Google Scholar] [CrossRef] [Green Version]
- Combea, H.; Založnik, M.; Hans, S.; Richy, P.E. Prediction of macrosegregation in steel ingots: Influence of the motion and the morphology of equiaxed grains. Metall. Mat. Trans. B. 2009, 40, 289–304. [Google Scholar] [CrossRef]
- Singh, A.K.; Basu, B.; Ghosh, A. Role of appropriate permeability model on numerical prediction of macrosegregation. Metall. Mat. Trans. B. 2006, 37, 799–809. [Google Scholar] [CrossRef]
- García, P.J.; González, V.M.; Álvarez, J.C.; Bayón, R.M.; Sirgo, J.Á.; Díaz, A.M. A new predictive model of centerline segregation in continuous cast steel slabs by using multivariate adaptive regression splines approach. Materials 2015, 8, 3562–3583. [Google Scholar]
- García, P.; García, E.; Álvarez, J.; González, V.; Mayo, R.; Mateos, F. A comparison of several machine learning techniques for the centerline segregation prediction in continuous cast steel slabs and evaluation of its performance. J. Comput. Appl. Math. 2018, 330, 877–895. [Google Scholar] [CrossRef]
- Normanton, A.S.; Barber, B.; Bell, A.; Spaccarotella, A.; Holappa, L.; Laine, J.; Peters, H.; Link, N.; Ors, F.; Lopez, A.; et al. Developments in online surface and internal quality forecasting of continuously cast semis. Ironmak. Steelmak. 2004, 31, 376–382. [Google Scholar] [CrossRef]
- Chen, H.Z.; Yang, J.P.; Lu, X.C.; Yu, X.Z.; Liu, Q. Quality prediction of the continuous casting bloom based on the extreme learning machine. Chin. J. Eng. 2018, 40, 815–821. [Google Scholar]
- Davis, J.J.; Clark, A.J. Data preprocessing for anomaly based network intrusion detection: A review. Appl. Artif. Intell. 2011, 30, 353–375. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C.; Yang, Q. Data preparation for data mining. Appl. Artif. Intell. 2003, 17, 375–381. [Google Scholar] [CrossRef]
- Cassar, D.R.; Carvalho, A.C.P.L.F.; Zanotto, E.D. Predicting glass transition temperatures using neural networks. Acta Mater. 2018, 159, 249–256. [Google Scholar] [CrossRef]
- Aicha, A.B. Noninvasive detection of potentially precancerous lesions of vocal fold based on glottal wave signal and SVM approaches. Procedia Comput. Sci. 2018, 126, 586–595. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Yan, C. A framework for knowledge discovery in massive building automation data and its application in building diagnostics. Autom Constr. 2015, 50, 81–90. [Google Scholar] [CrossRef]
- Pan, C.C.; Bai, J.; Yang, G.K.; Wong, D.S.H.; Jang, S.S. An inferential modeling method using enumerative PLS based nonnegative garrote regression. J. Process Control. 2012, 22, 1637–1646. [Google Scholar] [CrossRef]
- He, F.; Zhang, L.Y. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. J. Process Control 2018, 66, 51–58. [Google Scholar] [CrossRef]
- Zhai, L.; Khoo, L.P.; Zhong, Z.W. Design concept evaluation in product development using rough sets and grey relation analysis. Expert Syst. Appl. 2009, 36, 7072–7079. [Google Scholar] [CrossRef]
- Chan, J.W.K.; Tong, T.K.L. Multi-criteria material selections and end-of-life product strategy: Grey relational analysis approach. Mater. Des. 2007, 28, 1539–1546. [Google Scholar] [CrossRef]
- Chen, W.; Kong, F.; Wang, B.; Li, Y. Application of grey relational analysis and extreme learning machine method for predicting silicon content of molten iron in blast furnace. Ironmak. Steelmak. 2018, 45, 1–6. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Horata, P.; Chiewchanwattana, S.; Sunat, K. Robust extreme learning machine. Neurocomputing 2013, 102, 31–44. [Google Scholar] [CrossRef]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic forecasting of wind power generation using extreme learning machine. IEEE Trans. Power Syst. 2014, 29, 1033–1044. [Google Scholar] [CrossRef] [Green Version]
- Deng, W.; Zheng, Q.; Chen, L. Regularized extreme learning machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Na, W.B.; Su, Z.W.; Ji, Y.F. Research of single well production prediction based on improved extreme learning machine. In Proceedings of the 2013 2nd International Conference on Measurement, Instrumentation and Automation, Guilin, China, 23–24 April 2013; pp. 1296–1300. [Google Scholar]
- Huynh, H.T.; Won, Y. Regularized online sequential learning algorithm for single-hidden layer feedforward neural networks. Pattern Recogn. Lett. 2011, 32, 1930–1935. [Google Scholar] [CrossRef]
- Scholes, A. Segregation in continuous casting. Ironmak. Steelmak. 2005, 32, 101–108. [Google Scholar] [CrossRef]
- Huang, X.; Thomas, B.G.; Najjar, F.M. Modeling superheat removal during continuous casting of steel slabs. Metall. Mater. Trans. B. 1992, 23, 339–356. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Composition | C | Si | Mn | P | S | Cr | Cu |
|---|---|---|---|---|---|---|---|
| Mass fraction, % | 0.79~0.82 | 0.15~0.35 | 0.60~0.90 | ≤0.025 | ≤0.025 | ≤0.25 | ≤0.25 |
| Symbols | Names of Production Parameters | Units |
|---|---|---|
| X1 | Carbon content in molten steel | wt. % |
| X2 | Silicon content in molten steel | wt. % |
| X3 | Manganese content in molten steel | wt. % |
| X4 | Phosphorus content in molten steel | wt. % |
| X5 | Sulfur content in molten steel | wt. % |
| X6 | Secondary cooling water flow rate in zone1 | L/min |
| X7 | Secondary cooling water flow rate in zone2 | L/min |
| X8 | Secondary cooling water flow rate in zone3 | L/min |
| X9 | Secondary cooling intensity | L/kg |
| X10 | Pouring temperature | °C |
| X11 | Casting speed | m/min |
| X12 | Superheat | °C |
| X13 | Mold water flow rate | L/min |
| X14 | Mold water temperature difference | °C |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, L.; Zhang, J.; Liu, Q.; Zeng, F.; Chen, J.; Guan, M. Prediction of Central Carbon Segregation in Continuous Casting Billet Using A Regularized Extreme Learning Machine Model. Metals 2019, 9, 1312. https://doi.org/10.3390/met9121312
Zou L, Zhang J, Liu Q, Zeng F, Chen J, Guan M. Prediction of Central Carbon Segregation in Continuous Casting Billet Using A Regularized Extreme Learning Machine Model. Metals. 2019; 9(12):1312. https://doi.org/10.3390/met9121312
Chicago/Turabian StyleZou, Leilei, Jiangshan Zhang, Qing Liu, Fanzheng Zeng, Jun Chen, and Min Guan. 2019. "Prediction of Central Carbon Segregation in Continuous Casting Billet Using A Regularized Extreme Learning Machine Model" Metals 9, no. 12: 1312. https://doi.org/10.3390/met9121312
APA StyleZou, L., Zhang, J., Liu, Q., Zeng, F., Chen, J., & Guan, M. (2019). Prediction of Central Carbon Segregation in Continuous Casting Billet Using A Regularized Extreme Learning Machine Model. Metals, 9(12), 1312. https://doi.org/10.3390/met9121312