
Assessing Gender Bias in Particle Physics and Social Science Recommendations for Academic Jobs

 ,
,  , , , and
, , , and
Abstract
:1. Introduction
1.1. Theory and Motivation for Methods
1.1.1. Techniques in Prior Research
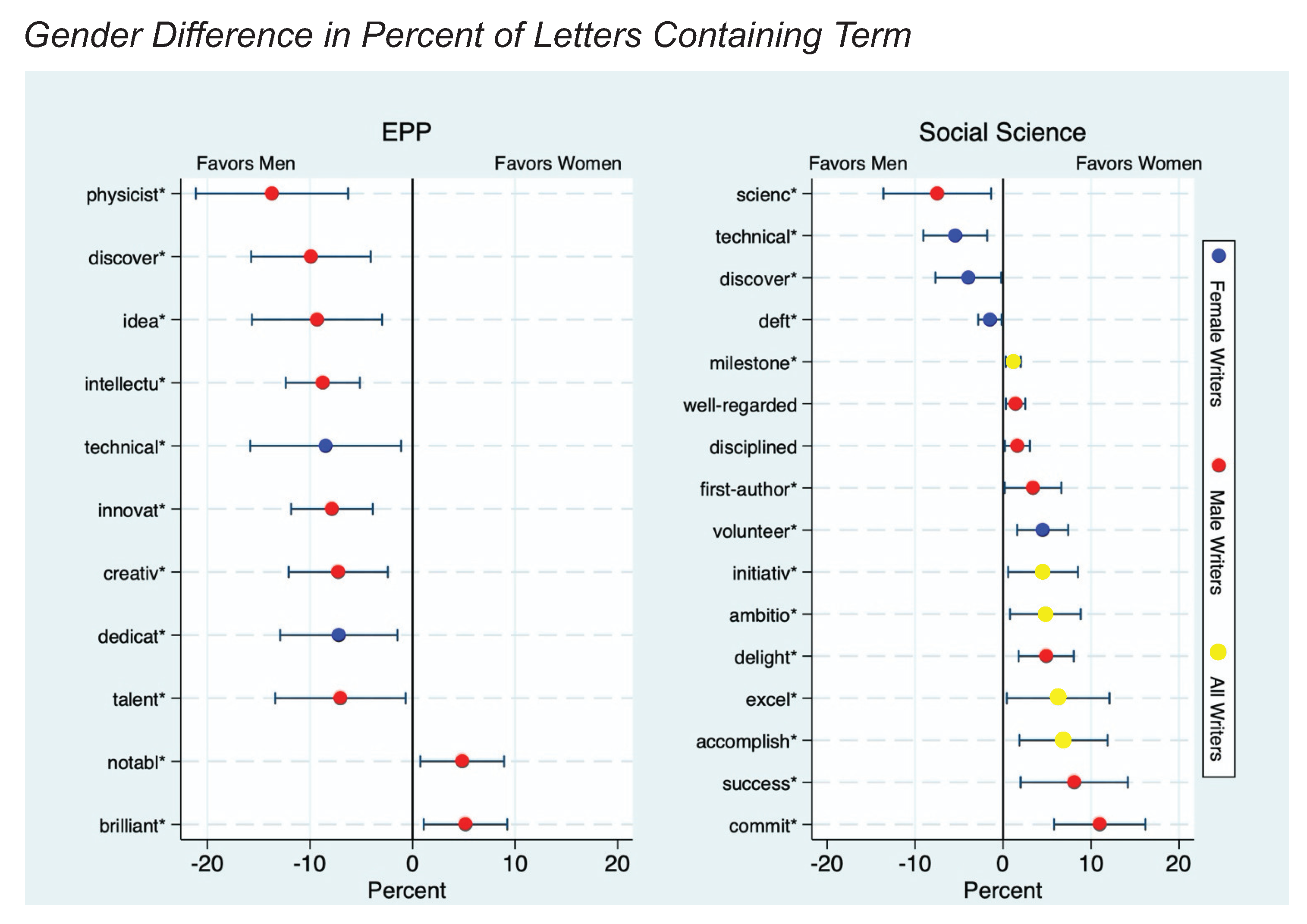
Standout words, which portray a candidate as talented and exciting, are most often found in letters of recommendation for men. Grindstone words, which create the impression that a candidate works hard but is not intellectually exceptional, are more often used for women.
Of the letters for female applicants, 34 percent included grindstone adjectives, whereas 23 percent of the letters for male applicants included them. There is an insidious gender schema that associates effort with women, and ability with men in professional areas. According to this schema, women are hard-working because they must compensate for lack of ability.
- We compared letters written for candidates in two disciplines differing dramatically in the underrepresentation of women. We hypothesize that letters in EPP, a male-dominated field, will show more bias than ones with gender parity, psychology and sociology in the developmental social sciences. Prior studies have not made such a cross-discipline comparison.
- It is of course possible that EPP female candidates are stronger than male candidates and male letter-writers downgrade their letters. We have investigated a sub-sample of letters with writers for a given candidate from both genders; any such difference would be apparent in this sample. We therefore tested for differences between female and male writers using a restricted sample of 918 letters that were written on behalf of 234 candidates with letters from both male and female non-primary advisors (excluding the PhD committee chair). This method allowed direct comparisons of differences in how women and men recommenders depicted the same candidates, thereby ruling out gender differences in candidate accomplishments as an explanation for differences in letters written by female versus male recommenders. We found no greater gender differences between writers for the restricted sample than for the entire sample of 2206 letters, and we therefore report results for the entire sample. With this additional comparison, not previously made in the literature, we can then attribute any observed disciplinary difference to gender bias.
- We used the same measures of letter content derived from the Linguistic Inquiry and Word Count (LIWC) dictionaries used in many previous studies: the proportion of total words in the letter that appear in the lists of “achievement” words connoting accomplishment and success, words associated with “ability,” and words that convey affective attraction and aversion called “posemo” and “negemo” in LIWC, or “positive affect” and “negative affect” in the literature (Pennebaker et al. 2015). However, this study used larger samples with a wider array of measures than those in any previous individual paper, including the four measures in previous research described above: “agentic,” “communal,”, “standout,” and “grindstone” (Madera et al. 2009; Schmader et al. 2007; Trix and Psenka 2003). This allowed a simultaneous comparison of all these categories on a single sample, removing systematic errors from comparing different categories in different sets of letters belonging to different disciplines written across multiple decades – our study uses letters written in a single period from 2011–2017.
1.1.2. New Questions and Techniques
- Do men and women prefer to ask writers of the same sex for their letters? This question is different from a lexical analysis and focuses on the behavior of the candidate rather than the words chosen by the recommender. If such “gender homophily” exists, then its source is of interest. Furthermore, gender homophily could be a confounding effect in the lexical analyses: if male and female writers write letters differently, and men and women prefer letters from their own gender, then we may incorrectly attribute differences in the lexical analysis results to bias rather than gender differences in writing style.
- Consider some word or word category that is a potential source of gender bias. We can measure one of two different quantities. We can determine the number of times one of our word categories appears in a letter divided by the number of words in the letter; we will call that rate-per-word, and that is what is normally reported. We can also measure the number of times a word category appears in a letter and count the fraction of letters containing that word category, whether the word category appears once or multiple times. What is the difference between a measurement of the rate per word and a measurement of the fraction of letters? We know some words such as “brilliant” have a high impact on the reader and a single use can have a large effect. Other words, such as those describing teaching, may send a message by accumulation—if you write about someone as a teacher more than as a researcher, no single word has a large effect but the accumulation of such words can send a message. “Research” is mentioned one or more times in nearly every letter, and hence there is a strong signal in writing a letter that never mentions “research”. Despite the effect sizes in many studies being about one word per letter, it has been argued that “only one statement can make a difference” (Madera et al. 2009). In contrast, if a writer uses “research” twice in one letter, that does not necessarily indicate that the writer was more enthusiastic compared to using that same term only once but we cannot determine that from this study.
- Is there a bias in the rank of the writer? The rank of the letter-writer can also send a signal; letters from prestigious sources might carry more weight than other sources. We therefore examined the status of the author.
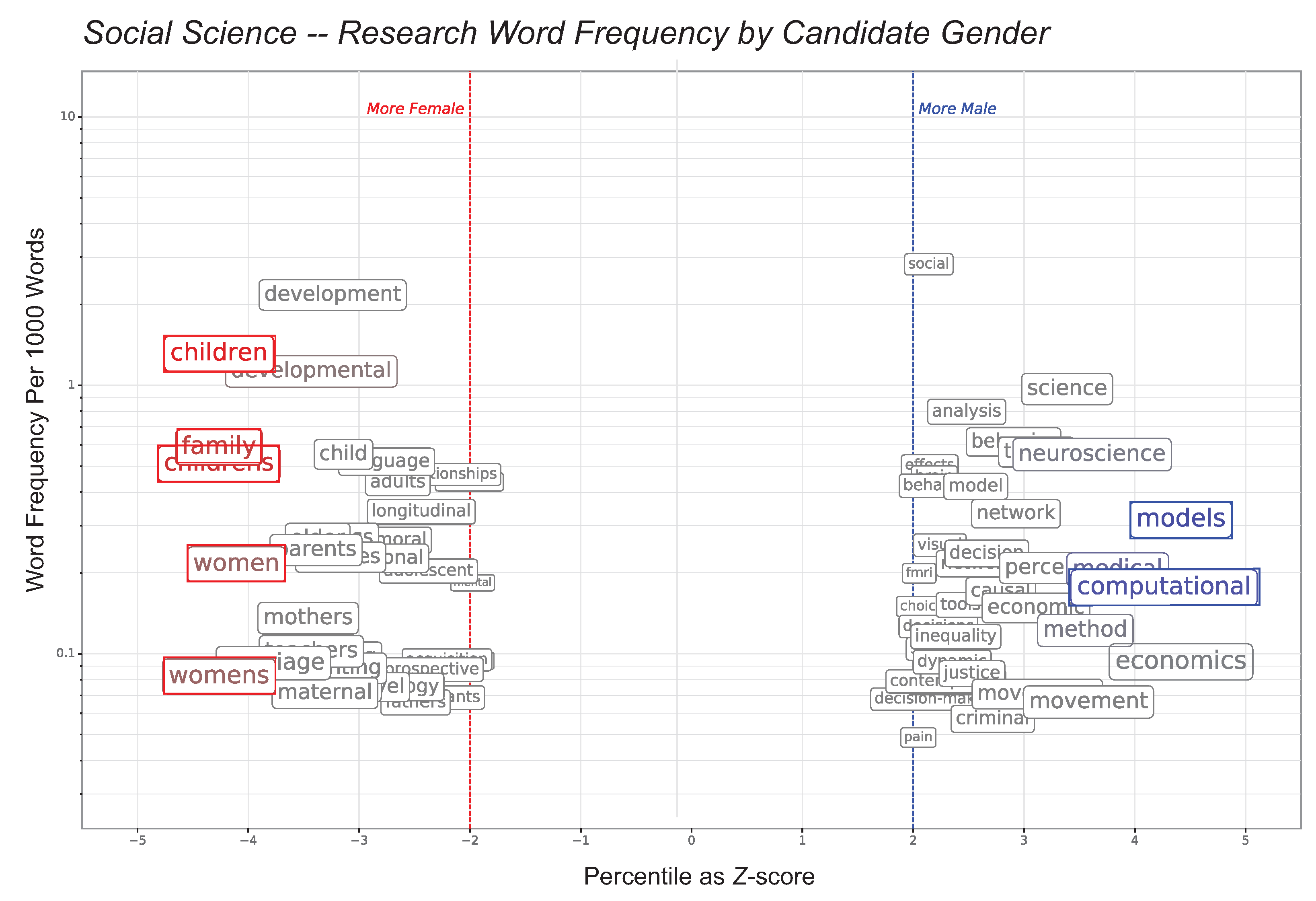
- Are there limitations in using pre-existing word lists? Every discipline has its own signaling phrases, and lists for individual studies chose words and classifications targeted for their discipline and questions. This has led to a given word being assigned to different categories in different papers: several “grindstone” words are classified differently in different papers (Madera et al. 2009; Schmader et al. 2007). A general list such as LIWC 2015 chose and classified words in a manner that might not capture effects that require targeted classification. It would be best to let the data “speak for itself”. We therefore performed an “open-ended” analysis where the actual words used in our sample were examined to see if they were associated with male or female candidates.
2. Materials and Methods
2.1. Data
2.2. Existing Word List Method
2.3. Open-Ended Analysis Methods
2.3.1. Comment on Context
2.3.2. Fraction-of-Letters Analysis
2.4. Mathematical Methods and Non-Normal Distributions
3. Results
3.1. Standard Lexical Content
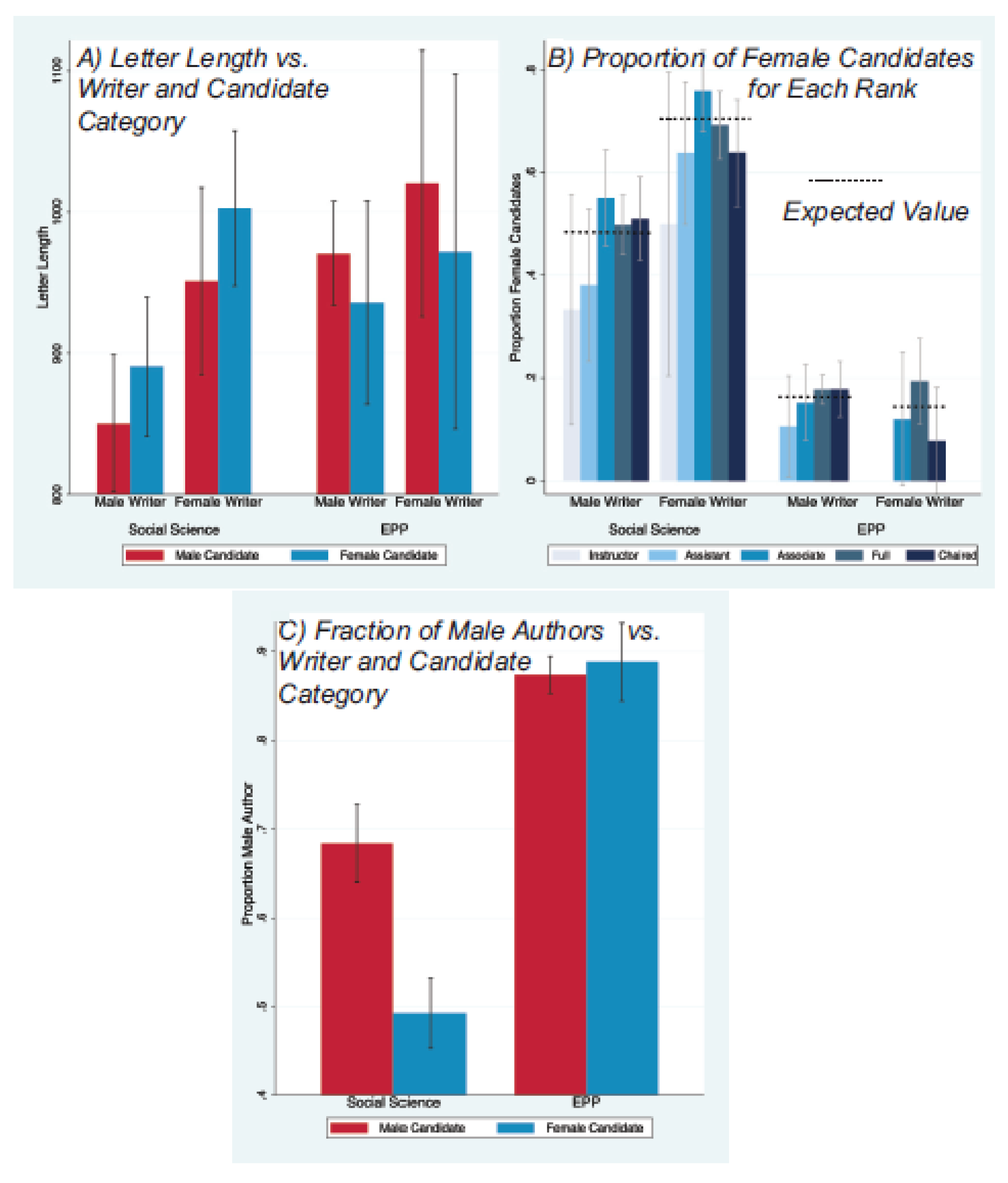
3.2. Letter Length
3.3. Letter Authorship
3.4. Differences Associated with the Sex of Writers
3.4.1. Gender Homophily Effect
3.4.2. Differences in Letters by Male and Female Writers
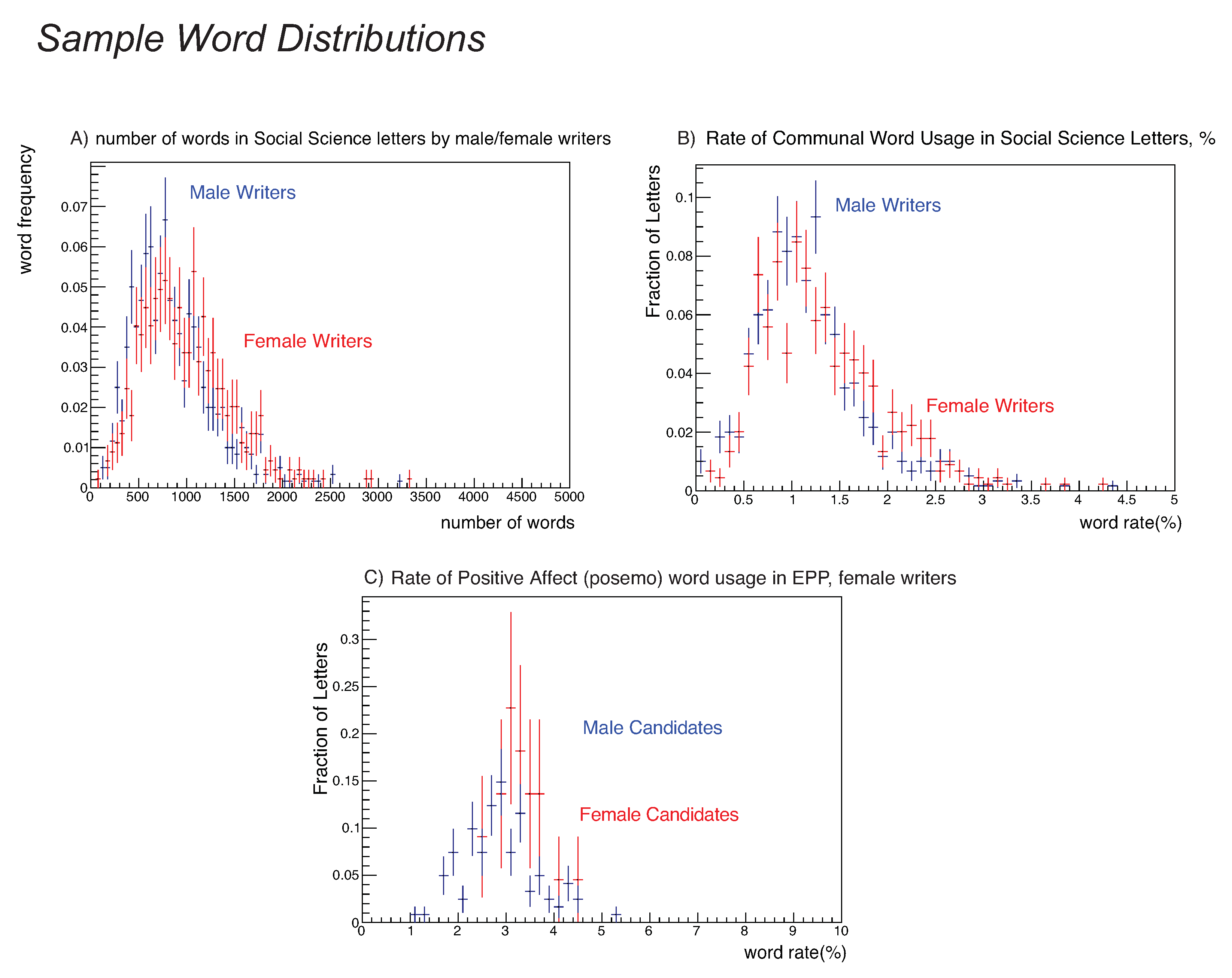
- Female social science writers write longer letters than male Social Science writers. The means differ; an analysis using medians instead of means shows a larger difference; and the distributions themselves are visibly shifted (see Figure 4), Panel A. A Kolmogorov-Smirnov test yields a probability the two distributions are identical.
- The rate of communal word usage by women authors in developmental social science letters was higher than the rate for men authors as shown in Figure 4, Panel B. A Kolmogorov-Smirnov test yields a probability the two distributions are identical. This is interesting in its own right, but combined with our gender homophily observation, earlier interpretations that an observation of higher usage of communal words for women candidates were due to gender bias should be reconsidered. If women tend to write for women candidates, and women writers use more communal terms, the finding that letters for women candidates have more communal terms might be correlated with gender homophily. Further research is required to disentangle these effects.There is also a significant difference in the positive-affect use rate by female writers between male and female candidates, favoring female candidates, as shown in Figure 1 with the per-letter distribution shown in Figure 4, Panel C. Inspection of the letters reveals that positive-affect words such as “brilliant”, “best”, or “creative” and their variants account for the difference in the words-per-letter rate: ; %, 95% CI: [0.20,0.42]%) and a Kolmogorov-Smirnov test for the per-letter rate gave a probability of that the distributions were identical. The words-per-letter rates for both “communal” and positive-affect rates for male EPP authors were consistent.
3.5. Comment on Descriptions in Letters Not Captured by LIWC and Doubt-Raisers
- A female writer compared a male candidate to Eeyore from Winnie-the-Pooh. Eeyore is often considered to be suffering from major depressive disorder, but the letter was otherwise favorable and in context the remark was meant as a compliment. Female writers described male candidates as “lovable”, “charming”, “delightful”, “adorable”, and similar words.
- A female writer said that a male candidate had “two adorable children” and used that assertion as evidence of the candidate’s suitability for the position (but not because they had relevant experience with children or anything that related to research).
- A male writer said that a female candidate “demonstrated her ability to multitask through her raising of children while pursuing an academic career.”
3.6. Open-Ended Rate-Per-Word and Fraction-of-Letters Analyses
Open-Ended Rate-Per-Word Analysis
3.7. Open-Ended Fraction-of-Letters Analysis
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Female-to-Male Writer Ratio
- EPP Measurement from Data
- In EPP we counted the number of Associate or Full Professors at representative schools and Laboratories during the period in which the letters were written. We examined the web pages of each department; EPP faculty are readily identifiable. We obtained a value of F(F+M) , or F/M = . An older list from the American Physical Society’s Divison of Particles and Fields membership file (in 2014) was examined for potential letter-writers with the same criterion for academic rank and gave ; that list is confidential. These values are consistent indicating that we are making a reasonable estimate for our EPP writer pool.
- EPP Demographic Studies
- In EPP, we first used data from the American Institute for Physics (Porter and Ivie 2019). These data do not break out the fraction of Assistant, Associate, or Full Professors and report 0.14 for all of EPP in 2017. We checked this estimate against The National Center for Science and Engineering Statistics (National Science Foundation 2019) (NSF 19-301, Table 16, 2018), which gives 0.158 for all of EPP in 2017. Uncertainties are not quoted for either survey.
- Social Science Measurement from Data
- We examined a total of 26 sociology and psychology departments both above and below Cornell in US News and World Report rankings (as a convenient proxy for schools at the same level). For each school, we examined the web pages of each sociology and psychology department and counted Associate and Full Professors, leaving out Assistant Professors, lecturers, adjuncts, and emeriti. The gender of each person was determined from names or pictures. This method was problematic: the definition of faculty in appropriate departments is not uniform and we found the information available on the Internet to be incomplete, out-of-date, or not usefully organized. It could also be that applicants are either from non-psychology departments (education, human development, brain sciences, information sciences, communication departments, medical schools, law schools, or business schools) or worked with researchers from non-psychology departments, possibly biasing a count based on the scan of just sociology and psychology departments. The definition of the relevant department also varied across schools: for example, Cornell’s Department of Human Development has neither sociology nor psychology in its name but is one of the organizational units to which candidates applied. Estimating the expected social science ratio was therefore much more difficult than in EPP. We nonetheless followed this procedure and stopped after (, F=229) in Sociology and () in psychology since the results were not changing with additional statistics and the (unestimated) systematic errors of the method made it pointless to continue. The sum over both departments is for F/M is (statistical errors only). The raw data are available from the authors or at supplementary.
- Social Science Demographic Studies
- We again used NSF’s 2017 Survey of Doctoral Recipients (National Science Foundation 2019). The NSF 2017 Survey of College Graduates tells us the ratio F/(F+M) in 2010 for self-identified sociologist/anthropologists, other social scientists, and secondary teachers was 56%. Although 53% of assistant professors are female in NSF’s national data during the time frame of this study (2010–2017), only around 45% of tenured faculty are female, and as we noted letters were written less often by Assistant Professors. However, the 45% female figure is based on the number of female tenured professors at ALL colleges and universities, not the universities that comprised the bulk of letter writers for this study. More web searches told us there are disproportionately more females at small 2-year and 4-year teaching colleges and more males at the R1s. Furthermore our writers came from more than just psychology departments: we had writers from brain science departments, human development departments, medical schools, business schools, communication departments, law schools and more. A further problem revealed itself at Cornell itself: 10–15% of the faculty in Cornell’s psychology and human development departments have degrees outside psychology in such diverse fields as electrical engineering, political science, biology, and sociology.
Appendix B. Comparison of Current and Former Studies
- Date: We used an open-ended analysis that reversed the word count methodology to provide an internal validation of the word count analyses. Instead of starting with “recommendation” words in published word counts and then measuring their gender frequency, we started with words with gendered frequency and looked for those indicating strength of recommendation. This is an independent analysis that is not dependent on the words in word counts used in the main analysis but rather is based on the gendered associations of all words in actual letters. Between 30% and 86% of the patterns in each word count category matched a word in the letter text, but over 75% of the words in the base vocabulary considered below were not found any word count. Therefore because a great majority of the words in the letters are not in the word count categories, it is possible for large differences in the letters to be overlooked. We examined three variations of mapping letters to sets of tokens (1) within word-category word use differences based on rate per word frequencies, (2) a broad examination of all common words based on rate per word frequencies, and (3) an examination of candidate descriptors based on fraction-of-letters frequencies.
- Different Fields: Some previous studies examined applicants for jobs in fields that are less math-intensive and have much greater female representations than EPP (for example, medicine, biology, and geoscience). It is therefore even more curious that some of these studies found gender bias in letters of recommendation, while we found little evidence of gender bias in EPP. We therefore urge extreme caution in generalizing our results beyond EPP and social science, including even other subfields of physics such as theoretical particle physics. The core values for a field such as EPP, which requires large collaborative efforts (hence, a possibly greater emphasis on communal and grindstone traits), may differ from fields in which research is carried out by much smaller collaborative teams or even by lone individuals. Again, the social sciences are usually less collaborative and math-intensive than EPP and have dramatically higher representations of women than EPP so we expected the social science effects if anything to be markedly smaller, which they were not.
- Nationality of Writers: Some prior findings, particularly Dutt et al. (2016), that are inconsistent with the current findings contained a large proportion of letters written by recommenders from outside America. That study finds non-US letters are much shorter and they are less enthusiastic than letters written by American scientists. Thus, there is evidence that differences in letter length and tone vary significantly across cultures, with letters written by Americans being longer and more positive than those emanating from other regions. The vast majority of the letters in the present study were written by Americans; in contrast, in Dutt et al. (2016), 530 out of 1224 letters were written by scientists outside the US. Thus, the current study clarifies what (until now) has been a set of seemingly contradictory findings that result from studies that are mostly small-scale and based on samples lacking important controls (such as the unavailability of letters for unsuccessful applicants, or too small subsamples of female writers to do gendered analyses). Some, but not all, of these earlier studies have reported evidence of gender bias; however, there are many exceptions and contradictions that we enumerate next.
- Sample Size: The current study is based on the largest sample of letters thus far examined, 2206 letters. Prior studies varied from 237 letters in Li et al. (2017) to 1224 letters in Dutt et al. (2016). This is important because the smaller samples precluded examining correlations between the gender of applicant and the gender of the writer. As noted elsewhere in this article, it is important to remember that candidates typically apply to many positions and letters for a given candidate rarely differ substantively from one search to another. Therefore, the letters in our samples are likely to resemble those submitted by these applicants to other searches beyond these two institutions. Nonetheless, caution is needed when generalizing these results; for example, the internal culture of EPP, with large collaborations requiring communal behavior, may differ from other fields of physics.
- Dependent Variables: With the exception of McCarthy and Goffin (2001) the current study employs the largest number of dependent variables: length, agentic, communal, grindstone, standout, achievement, positive affect, negative affect, ability, homophily, and writer status. The current study also included an internal validation using words not limited to the word counts used by prior researchers, an analysis that was bottom-up. This analysis began with words associated with gender that were not contained in any of the word counts; that is, after finding few gender differences in the myriad dependent measures examined, the current study undertook an independent test that confirmed no other terms associated with gender were related to ability; instead, they were words that described research topics that tended to be gendered (as perhaps implied our findings, women in developmental social science being more likely to study family processes and men to study neuroscience.)
- Control of Background: Only a few prior studies attempted to control for applicants’ personal characteristics (by using number of publications, conference presentations, class rank, and/or awards as covariates). These are less than ideal controls for other ways applicants can differ (e.g., status of their mentor, quality of the journals in which they publish, prestige of their university, their contribution to multi-authored studies). In contrast, the current study included an analysis of a subsample of 918 of the 2206 letters for candidates with letters from both genders, neither of whom was the candidates primary advisor. Each candidate thereby contributed to the measures for each writer gender. This minimizes differences between male and female candidates caused by gender differences in applicants’ personal characteristics. However, it does not address the possibility that differences in letters for male and female candidates might reflect unmeasured differences in candidate qualifications.
- Comparing Disciplines that Differ in Women’s Representations: The current study contrasted two disciplines in which women are disparately represented. Only Dutt et al. (2016) examined a math-intensive field, the analysis of letters for postdoctoral positions in geoscience. This current study examined an even more male-dominated field, EPP (Elementary Particle Physics) and contrasted it with fields with high female representation, psychology and sociology. This contrast provided a principled basis for the expectation of larger correlations between gender and the dependent variables within the less female-represented field, EPP.
Small differences were found in the categories of words used to describe male and female candidates and white and UiO candidates. These differences were not present in the standardized LOR compared with traditional LOR. It is possible that the use of standardized LOR may reduce gender- and race-based bias in the narrative assessment of applicants.
A similar discrepancy has been noted in studies analyzing letters of recommendation for surgical residency and suggests that applicants preferentially ask men faculty over women faculty for letters of recommendation… If applicants believe that letters from writers of higher academic rank carry more weight, then the larger proportion of men at higher academic rank could be one explanation for this difference…
Although there were some minor differences favoring women, language in letters of recommendation to an academic orthopaedic surgery residency program were overall similar between men and women applicants… Given the similarity in language between men and women applicants, increasing women applicants may be a more important factor in addressing the gender gap in orthopaedics.
Standout words in letters of recommendation…portray a candidate as talented and exciting, (and) are most often found in letters of recommendation for men. Grindstone words create the impression that a candidate works hard but is not intellectually exceptional, (and) are more often used for women…As a result of that discrepancy, female candidates seem both more boring and less intellectually promising than their male competitors.
References
- Adamo, Shelley A. 2013. Attrition of women in the biological sciences. Bioscience 63: 43–48. [Google Scholar] [CrossRef] [Green Version]
- Blue, Jennifer, Adrienne L. Traxler, and Ximena C. Cid. 2018. Gender matters. Physics Today 71: 40–46. [Google Scholar] [CrossRef] [Green Version]
- Ceci, Stephen J., Donna K. Ginther, Shulamit Kahn, and Wendy M. Williams. 2014. Women in Academic Science: A Changing Landscape. Psychological Science in the Public Interest 15: 75–141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dutt, Kulheli, Danielle F. Pfaff, Ariel F. Bernstein, Joseph S. Dillard, and Caryn J. Block. 2016. Gender differences in recommendation letters for postdoctoral fellowships in geoscience. Nature Geoscience 9: 805–8. [Google Scholar] [CrossRef]
- Eaton, Asia A., Jessica F. Saunders, Ryan K. Jacobson, and Keon West. 2020. How gender and race stereotypes impact the advancement of scholars in STEM: Professors’ biased evaluations of physics and biology post-doctoral candidates. Sex Roles 82: 127–41. [Google Scholar] [CrossRef]
- Fermi National Accelerator Laboratory. 2020. Fermilab Web Page. Available online: http://www.fnal.gov (accessed on 15 September 2021).
- French, Judith C., Samuel J. Zolin, Erika Lampert, Alexandra Aiello, Kalman P. Bencsath, Kaitlin A. Ritter, Andrew T. Strong, Jeremy M. Lipman, Michael A. Valente, and Ajita S. Prabhu. 2019. Gender and Letters of Recommendation: A Linguistic Comparison of the Impact of Gender on General Surgery Residency Applicants. Journal of Surgical Education 76: 899–905. [Google Scholar] [CrossRef] [PubMed]
- Goulden, Marc, Mary Anne Mason, and Karie Frasch. 2011. Keeping women in the science pipeline. Annals of American Academy of Political and Social Science 638: 141–62. [Google Scholar] [CrossRef]
- Hill, Catherine, Christianne Corbett, and Andresse St. Rose. 2010. Why so Few? AAUW. Available online: https://www.aauw.org/app/uploads/2020/03/why-so-few-research.pdf (accessed on 15 March 2020).
- Kaminski, Deborah, and Cheryl Geisler. 2012. Survival Analysis of Faculty Retention in Science and Engineering by Gender. Science 335: 864–66. [Google Scholar] [CrossRef]
- Kelchtermans, Stijn, and Reinhilde Veugelers. 2013. Top research productivity and its persistence: Gender as a double-edged sword. Review of Economics and Statistics 95: 273–85. [Google Scholar] [CrossRef]
- Kobayashi, Audrey N., Robert S. Sterling, Sean A. Tackett, Brant W. Chee, Dawn M. Laporte, and Casey Jo Humbyrd. 2020. Are There Gender-based Differences in Language in Letters of Recommendation to an Orthopaedic Surgery Residency Program? Clinical Orthopaedics and Related Research 478: 1400–8. [Google Scholar] [CrossRef]
- Leslie, Sarah-Jane, Andrei Cimpian, Meredith Meyer, and Edward Freeland. 2015. Expectations of brilliance underlie gender distributions across academic disciplines. Science 347: 262–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Simaio, Abra L. Fant, Danielle M. McCarthy, Danielle Miller, Jill Craig, and Amy Kontrick. 2017. Gender Differences in Language of Standardized Letter of Evaluation Narratives for Emergency Medicine Residency Applicants. AEM Education and Training 1: 334–39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Madera, Juan M., Michelle R. Hebl, and Randi C. Martin. 2009. Gender and letters of recommendation for academia: Agentic and communal differences. Journal of Applied Psychology 94: 1391–99. [Google Scholar] [CrossRef] [PubMed]
- Martinez, Larry R., Katharine R. O’Brien, and Michelle R. Hebl. 2017. Fleeing the ivory tower: Gender differences in the turnover experiences of women faculty. Journal of Women’s Health 26: 580–86. [Google Scholar] [CrossRef]
- McCarthy, Julie M., and Richard D. Goffin. 2001. Improving the validity of letters of recommendation: An investigation of three standardized reference forms. Military Psychology 13: 199–222. [Google Scholar] [CrossRef]
- Messner, Anna H., and Erika Shimahara. 2008. Letters of Recommendation to an Otolaryngology/Head and Neck Surgery Residency Program: Their Function and the Role of Gender. The Laryngoscope 118: 1335–44. [Google Scholar] [CrossRef]
- Meyer, Meredith, Andrei Cimpian, and Sarah-Jane Leslie. 2015. Women are underrepresented in fields where success is believed to require brilliance. Frontiers in Psychology 6. [Google Scholar] [CrossRef]
- Miller, George A. 1995. WordNet: A Lexical Database for English. Available online: https://wordnet.princeton.edu (accessed on 15 September 2021).
- Moss-Racusin, Corinne A., John F. Dovidio, Victoria L. Brescoll, Mark J. Graham, and Jo Handelsman. 2012. Science faculty’s subtle gender biases favor male students. Proceedings of the National Academy of Sciences 109: 16474–79. [Google Scholar] [CrossRef] [Green Version]
- National Academy of Science, National Academy of Engineering, and Institute of Medicine. 2007. Beyond Bias And Barriers: Fulfilling the Potential of Women in Academic Science and Engineering. Washington: The National Academies Press. [Google Scholar] [CrossRef]
- National Research Council. 2010. Gender Differences at Critical Transitions in the Careers of Science, Engineering, and Mathematics Faculty; Washington: The National Academies Press. [CrossRef]
- National Science Foundation. 2019. Data Tables. National Center for Science and Engineering Statistics, NSF 20-300 (2019), Table 9-5. Available online: https://ncses.nsf.gov/pubs/nsf19304/data (accessed on 15 September 2021).
- Pennebaker, James W., Ryan L. Boyd, Kayla Jordan, and Kate Blackburn. 2015. The Development and Psychometric Properties of LIWC 2015. Austin: University of Texas at Austin. [Google Scholar]
- Porter, Anne Marie, and Rachel Ivie. 2019. Women In Physics and Astronomy. Available online: https://www.aip.org/statistics/reports/women-physics-and-astronomy-2019 (accessed on 15 September 2021).
- Powers, Alexa, Katherine Gerrull, Rachel Rothman, Sandra A. Klein, Rick W. Wright, and Christopher J. Dy. 2020. Race- and Gender-Based Differences in Descriptions of Applicants in the Letters of Recommendation for Orthopaedic Surgery Residency. JB & JS Open Access 5: e20.00023. [Google Scholar] [CrossRef]
- Schmader, Toni, Jessica Whitehead, and Vicki H. Wysocki. 2007. A linguistic comparison of letters of recommendation for male and female chemistry and biochemistry job applicants. Sex Roles 57: 509–14. [Google Scholar] [CrossRef] [Green Version]
- Sheltzer, Jason M., and Joan C. Smith. 2014. Elite male faculty in the life sciences employ fewer women. Proceedings of the National Academy of Sciences 111: 10107–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skibba, Ramin. 2019. Women in physics. Nature Reviews Physics 1: 298–300. [Google Scholar] [CrossRef]
- Su, Rong, and James Rounds. 2015. All STEM fields are not created equal: People and things interests explain gender disparities across STEM fields. Frontiers in Psychology 6: 1–20. [Google Scholar] [CrossRef] [Green Version]
- Trix, Frances, and Carolyn Psenka. 2003. Exploring the Color of Glass: Letters of Recommendation for Female and Male Medical Faculty. Discourse & Society 14: 191–220. [Google Scholar] [CrossRef]
- Valian, Virginia. 1998. Why So Slow? The Advancement of Women. Cambridge: The MIT Press. [Google Scholar]
- Wang, Ming-Te, Jacquelynne S. Eccles, and Sarah Kenny. 2013. Not lack of ability but more choice: Individual and gender differences in choice of careers in science, technology, engineering, and mathematics. Psychological Science 24: 770–75. [Google Scholar] [CrossRef] [PubMed]
- Williams, Wendy M., and Stephen J. Ceci. 2015. National hiring experiments reveal 2:1 faculty preference for women on STEM tenure track. Proceedings of the National Academy of Sciences 112: 5360–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Yu, and Kimberlee A. Shauman. 2003. Women in Science: Career Processes and Outcomes. Cambridge: Harvard University Press. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Male Writer | Female Writer | Sum | Total Male | Total Female | |||
|---|---|---|---|---|---|---|---|
| Candidate | Male | Female | Male | Female | Candidates | Candidates | |
| EPP | 842 | 176 | 121 | 22 | 1161 | 206 | 39 |
| Social Science | 301 | 298 | 139 | 307 | 1045 | 163 | 222 |
| EPP | Social Science | |
|---|---|---|
| Letters/Male Candidate | ||
| Letters/Female Candidate | ||
| Female Writers/Male Candidate | ||
| Female Writers/Female Candidate | ||
| Male Writers/Male Candidate | ||
| Female Writers/Female Candidate | ||
| Female Writers/Male Writers | ||
| Male candidates | ||
| Female Candidates | ||
| Expected from Pool of Writers | ||
| F/M of Potential Writers | ||
|---|---|---|
| EPP | Social Science | |
| Literature Sources | ||
| Examination of Departments | ||
| Male Writer | Female Writer | |||
|---|---|---|---|---|
| Candidate | Male | Female | Male | Female |
| EPP Total | 842 | 176 | 121 | 22 |
| EPP Both Genders | 302 | 47 | 121 | 22 |
| Social Science Total | 301 | 298 | 139 | 307 |
| Social Science Both Genders | 133 | 214 | 104 | 221 |
| Candidate Gender | Writer Gender | “Brilliant” in Letter | Total Letters |
|---|---|---|---|
| Female | Female | 3 | 22 |
| Female | Male | 13 | 176 |
| Male | Female | 4 | 121 |
| Male | Male | 24 | 842 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernstein, R.H.; Macy, M.W.; Williams, W.M.; Cameron, C.J.; Williams-Ceci, S.C.; Ceci, S.J. Assessing Gender Bias in Particle Physics and Social Science Recommendations for Academic Jobs. Soc. Sci. 2022, 11, 74. https://doi.org/10.3390/socsci11020074
Bernstein RH, Macy MW, Williams WM, Cameron CJ, Williams-Ceci SC, Ceci SJ. Assessing Gender Bias in Particle Physics and Social Science Recommendations for Academic Jobs. Social Sciences. 2022; 11(2):74. https://doi.org/10.3390/socsci11020074
Chicago/Turabian StyleBernstein, Robert H., Michael W. Macy, Wendy M. Williams, Christopher J. Cameron, Sterling Chance Williams-Ceci, and Stephen J. Ceci. 2022. "Assessing Gender Bias in Particle Physics and Social Science Recommendations for Academic Jobs" Social Sciences 11, no. 2: 74. https://doi.org/10.3390/socsci11020074
APA StyleBernstein, R. H., Macy, M. W., Williams, W. M., Cameron, C. J., Williams-Ceci, S. C., & Ceci, S. J. (2022). Assessing Gender Bias in Particle Physics and Social Science Recommendations for Academic Jobs. Social Sciences, 11(2), 74. https://doi.org/10.3390/socsci11020074