1. Introduction
Increasing the transport flexibility and sustainability of railways has become a crucial demand. This requires shortening the inter-train tracking intervals and a reduction in delays on congested railways. Improvements of the existing train control system and the exploration of next-generation railway control systems are currently attracting attention [
1]. As reported in [
2,
3], the headways of trains at junctions are extended by their absolute braking distances. The capacity benefit in high-speed or complicated railways is limited by the conventional moving-block system. Thus, a further concept of virtual coupling is arousing interest.
Virtual coupling is a novel train control concept that combines individual trains into virtually coupled train sets or train convoys. It aims at running trains closer together and increasing the capacity of the railway without adding more rail lines [
4,
5]. Virtual coupling separates trains with a safety margin from the head of the following train to the rear of the preceding train, even when the preceding train executes an emergency braking operation. The transport capacity can be dynamically adjusted through train coupling and decoupling on the run. This results in no wasted transport capacity and an increase in flexibility. Since trains are coupled with short safety margins, frequent train-to-train communication is required to guarantee real-time information sharing between trains.
To foster research and innovation, the European Shift2Rail Joint Undertaking has devoted many techniques to the next-generation railway control system and proposed the concept “virtual coupling“ [
5,
6]. Felez et al. [
7] indicated the advantages of virtual coupling over moving blocks. Goverde et al. [
4] focused on the development direction and implementation details of virtual coupling. Tilo presented that switch control for virtual coupling railways is a special challenge in [
8].
To shorten the dwell times of trains, Su et al. used integrating timetables and a regulation approach to optimize the efficiency of subway line [
9,
10]. One of the main challenges in virtual coupling is to couple trains quickly and efficiently at merging junctions [
11]. It is urgent to improve the efficiency of the whole travel process. When multiple trains approach a merging junction at the same time, they are prevented from slowing down and/or waiting at the junction until the requested route is fully cleared by previous trains. Train route control is realized by switch control. To guarantee that trains pass switches correctly and safely, switch movements and lock times are set with different speed limits in the normal position and the reverse position.
At junctions, the headways of trains are extended by their absolute braking distances. Trains must reserve large buffer times before switches, resulting in negative effects on the overall travel time. Train operation strategies along continuous routes are discrete. Discrete optimization problem has the non-convex property. Thus, the derivative method cannot solve this problem. In fact, it is difficult to find optimal strategies in a reasonable amount of time. Different control strategies and different initial states remarkably influence the overall coupling efficiency, which makes train coupling a complex process.
To adapt actual control conditions, variable parameters and optimal control strategies are necessary to realize dynamic and efficient control. Braune et al. designed a novel variable engine valve actuator to meet the requirements of high dynamic and low power consumption [
12]. Train control is complex, it requires dynamic analyses and adjustment [
13]. When merging at junctions, train statuses can be different. Trains must reach a coupled state within the specified distance. The operation strategies for every train concern the entire coupling process. Thus, traditional fixed operation strategies cannot fit the actual situation well. Static pre-programmed strategies may fail to reach the coupled state given a certain initial train speed or line distance.
Game theory is an economical approach for solving multi-participant decision-making problems. It considers both the predicted and actual behaviors of each participant [
14]. Game theory includes non-cooperative and cooperative approaches. The former pursues individual profits, while the latter achieves superior total profit through coalition-based cooperation [
15]. Cooperative game theory is successfully used in the control of automated vehicles to make decisions and select appropriate improvement strategies [
16].
Yang et al. [
15] proposed a non-signalized intersection driving model using cooperative game theory and the Shapley allocation method. Liu et al. [
17] proposed a spacing allocation method for vehicular platoons using cooperative game theory and the Shapley values to allocate the spacings fairly. With the gradual deepening of virtual coupling research, it is feasible to regard autonomous trains in a convoy as rational participants. Therefore, game theory will become a practicable method to determine optimal operation strategies.
To solve the virtual coupling-based optimization problem at merging junctions, this paper proposes a novel cooperative game-based method for the coupling process. Train control is realized by discrete control command, which is reflected in different acceleration. To optimize the entire coupling process, the proposed model generates control strategies for trains. The strategy is composed of acceleration in every discrete segment point. Decision-making and the overall and allocation costs of the formed alliance are considered in a cooperative game. The objective of the model is to realize a quick formation and increase the synchronous moving speed of the convoy. It orients the entire train operation control to the coupling process at junctions. The Shapley value is used to allocate the cost of a train coalition.
The cooperative game model can generate different optimal strategies for participants according to specific scenes. Compared to the continuous problem, the train operation strategies in this model are discrete, which is reflected in the dimensionality of the optimization problem. The computational complexity scales exponentially with the problem size. It is difficult for a cooperative game model to solve large-scale problems within a reasonable time frame in practice [
18].
In recent years, many studies have attempted to combine complicated optimization problems with cooperative game models. Vehicle platooning control is closely connected with game theory. Bui et al. [
19] proposed a cooperative game theoretic approach and a distributed merging and splitting algorithm to improve traffic flows in large networks. Meng et al. [
20] proposed a multi-colony collaborative ant optimization algorithm based on a cooperative game mechanism and applied it to robot path planning.
Liu et al. [
21] proposed an intelligent train control method based on the DQN algorithm. Ding et al. [
22] aimed at the reconfiguration problem of a distribution network, proposed a multi-objective model based on cooperative game theory, and applied the firefly algorithm to determine the final reconfiguration scheme. The above research shows that characterizing multi-vehicle collaborative control relationships through cooperation and competition has broad prospects. Since its introduction in 1995 [
23], particle swarm optimization (PSO) has been successfully used in many optimization problems.
Yet, the basic PSO algorithm has several shortcomings. Two of the major failure modes are stagnation and convergence to local optima [
24]. Many studies (such as [
25,
26]) have been carried out to relieve and solve this problem. To achieve better performance, PSO is combined with other intelligent algorithms, such as differential evolution [
27,
28], ant colony optimization [
29,
30,
31], and genetic algorithms [
32,
33,
34].
Adaptive methods are also used for refining the coefficient values of PSO [
35,
36,
37]. There are several challenges faced by the basic PSO algorithm when fitting a cooperative model. The discrete control characteristic is reflected in the particle dimension. Operating conditions are reflected in the constraints of the fitness function in PSO.
Thus, to apply a game model in general scenarios, we introduce an improved particle swarm optimization (PSO) approach to solve the strategy decision problem of the game model. To improve the efficiency of solving a cooperative model with large dimensions and complicated constraints, we modify the conventional PSO algorithm in the following aspects. A search speed limit factor and a speed bound are used to prevent solution explosion and limit the maximum and minimum particle movement speeds. Adaptive penalty functions are used to effectively measure the degrees of constraint violations. A no-update method is used to prevent particles from exceeding the search boundary. The mutation algorithm mentioned in [
38] is also used in the improved PSO approach. This helps PSO to enhance population diversity and avoid the local optima problem.
The aim of this work is to propose a novel solution in the field of railways for virtual coupling trains at junctions. The method can realize a quick formation and increase the synchronous moving speed of the convoy and, thus, improve the efficiency of virtual coupling. The cooperative game theorem is used to abstract the coupling process into a concrete model, and the improved PSO is used to find the optimal operation strategies for every train.
The contributions of this paper are as follows. A novel optimization approach for virtual coupling, which aims to improve the coupling efficiency of trains at junctions on the run, is proposed. A game theory-based model is built to represent the strategy decision-making behavior of each train. An improved PSO algorithm is developed to enable the game model to solve larger-scale problems. The proposed approach is applied to a typical coupling scenario. Contrast tests are carried out to compare the proposed optimization approach with two naive control strategies and the unimproved PSO approach. The results show that the coupling efficiency is improved with the proposed optimal operation strategies.
The rest of the paper is organized as follows.
Section 2 presents the problem of merging at junctions, builds a dynamic model for virtual coupling, and discretizes the model.
Section 3 builds a cooperative model and defines several of its important elements.
Section 4 proposes the improved PSO approach and explains the detailed algorithm.
Section 5 shows the simulation scenario and the comparative results of several operation methods.
Section 7 concludes the paper.
3. Cooperative Game Model Design
This paper mainly studies the coupling process of trains. Every autonomous train gathers information from other trains or ground equipment through frequent communication. These trains can be regarded as agents; they can judge conditions and make decisions throughout the whole process. The control behaviors influence each other in a system. Therefore, it is rather difficult to analyze the interactions among agents in theory.
We use a cooperative game to model the confrontation and cooperation of agents in virtual coupling control. Cost functions describe the tasks of all agents. The goal of solving this model is to obtain a set of strategies, thereby, minimizing the entire cost (or maximizing the entire payoff) of the game. This section introduces the cooperative game model, defines the cost function of the game, and then uses the Shapley theorem to solve it.
3.1. Strategy Set
The running statuses of trains depend on the operation strategies in this model. Let
be the strategy set of the cooperative model.
denotes the strategy set of train
k, which can be described as a two-dimensional acceleration matrix:
where
is the
ith strategy for train
k, which is composed of acceleration at every segment point.
represents the acceleration of segment point
j in
.
can be any value in
, in which
is the lower bound of the acceleration and
is the upper bound of the acceleration. The train state
can be calculated using Equations (14) and (15).
In a game, n virtual coupling trains are participants, and train k has distance segments. Thus, the strategy dimensionality of train i is . As the value of the acceleration in each segment can be infinitely large, the strategy set of each participant can be infinitely large.
The task of the cooperative game model is to match strategies from every train and calculate the overall cost function . It is difficult to find the optimal solution of this problem within a reasonable time frame. Therefore, a search algorithm is required for this model. The improved PSO algorithm is discussed in the next section.
3.2. Cooperative Game Model and the Cost Functions
This study considers the selection of a control strategy for every train in the coupling process as a cooperative game model. n coupling trains in a platoon correspond to n participants in a game. The game can be described as . The participant set , i denotes participant i. The entire cost function of the coalition is . Let P be a coalition consisting of participants from the coalition. is a subset of N. The total cost of coalition P can be denoted as . Let i, j, k be trains i, j and k, respectively.
The coalition can be expressed as ∅, , , , …, We make the following assumptions and abstract the coupling process into a cooperative game model.
The cooperators in a coalition can benefit from the game only when the number of participants is greater than 2; otherwise, the cost function is positive infinity. , .
After passing the switches in the coupling process, the order in which the trains are arranged is fixed. This means that a train in a convoy or platoon cannot skip its predecessor. Thus, the coalition can only take in the form of a queue , , …, . The cost functions of other coalition forms are positive infinity.
The cost functions of this problem consist of three parts: a formation time, a running speed, and the summed extra interval distance to the predecessor in a coupled platoon.
The cost functions are the main goals of each agent or the coalition. The compositions of are as follows.
For a coupled platoon, let
be the distance between train
j and train
k. The distance difference cost
of the convoy is defined as follows:
Let
be the running speed of train
k, the speed cost
can be described as follows:
Let
be the speed difference between train
j and train
k, the speed difference cost
can be described as follows:
Let
be the running time of train
k. For phase of trains before the switch, the time cost function
is as follows:
After passing the switch, the time cost function
is as follows:
Function
transforms the distance to time:
Function
transforms train speed to time:
where
denotes the required distance for braking. Let
,
,
, and
be the distribution weights of the distance cost, speed cost, speed difference cost, and time cost, respectively. They determine the importance levels of these four goals.
The cost function of trains can be divided into two phases. For phase of trains before the switch, the cost function
is as follows:
Let
be the distance between train
i and train
j,
be the distance between train
j and train
k,
be the distance between train
k and train
, and
be the train sequence. The cost function
of the phase of train beyond the switch is as follows.
where
denotes that train
i is always the leading train. Let
be
when
. The values of
,
,
, and
are considered as 1 in this paper, but they can be different according to different requirements. For the phase of trains beyond the switch, the total cost function is the sum of
and
:
3.3. Solution of the Cooperative Game
Given sets
and
, we denote
to be set
minus set
. The marginal cost
of the phase of trains before the switch is as follows.
According to (24),
is as follows:
Given a sequence
, we define
to be the removing of an element
k from
. The margin cost
of the phase of trains beyond the switch is as follows.
According to (25),
is as follows:
At the end of the coupling process, the marginal cost function is the sum of cost functions in two phases:
The cost distribution scheme is the preparatory phase of cooperation. We use Shapeley values to distribute coalition costs. For participant
i, the cost is apportioned by the following equation:
where
denotes the participants number in coalition
P and
is the probability for
to form a specific coalition.
Let
be the
r constraint of the problem and
m be the total number of constraints. The solution of the cooperative game is to minimize the cost function
, as shown in (34) and (35):
Formula (35) represents all constraints of the game model. The minimized cost function is the optimization of the final coupled convoy, which has smaller running intervals, better synchronism and a faster speed than other platoons. The constraints of the model in (35) are as follows:
The parameters are shown in
Table 1.
4. The Improved Particle Swarm Optimization Algorithm
Particle swarm optimization (PSO) is widely used for practical optimization problems. In our cooperative game model, the scale is large, the constraints are complicated, and the basic PSO algorithm performs poorly on this problem. To solve the above issues, this paper improves upon the basic PSO algorithm and fits it to the model. The objective of this algorithm is to minimize the cost function of the coalition, which is described in (34).
The improved PSO algorithm aims to minimize the objective function
. Taking the constraints into consideration, we transform this problem into an unconstrained problem. Let
be the penalty function and
be the fitness function of the algorithm, which can be described as follows:
The penalty function consists of the constraints in (35). An adaptive penalty function is designed to prevent the penalty function from being too large or too small:
The penalty coefficient
is defined as follows:
where
is the ratio of the number of feasible solutions to the number of total solutions in an iteration and
is an adjustable parameter. The penalty is adaptive according to the ratio of feasible solutions. Thus, the constrained problem becomes an unconstrained problem.
In this model, the particle dimension is vast, and bound constraints are imposed on every dimension of each particle. The conventional PSO algorithm easily falls into local optima under these conditions. In addition, the efficiency of the algorithm is confined. To address these deficiencies, we improve the algorithm in the following ways. To prevent solution explosion caused by a search speed that is too fast, we add a speed limit factor
to the iterative formula:
The meanings of the variables in the above two equations are explained in
Table 2.
To increase the search efficiency of the algorithm, we add a search speed constraint
to reduce the possibility of a particle being out of range. The value range of
V is as follows:
We add judgment to the search process. If the particle exceeds the basic position constraint, we use the last position to replace the current position. The basic PSO algorithm usually cannot strike a balance between its global searching ability and local search ability. To overcome this shortcoming, this paper uses the self-adapting inertia weight
proposed in [
38]:
where
is the maximum inertia weight,
is the minimum inertia weight,
I is the current number of iterations, and
is the maximum number of iterations.
In the iterative process, if a particle is in the current best position, other particles draw close to it quickly. If it is a local optima, the particle swarm no longer searches in the solution space. Thus, the algorithm falls into this local optima. According to (43) and (44), the next position of the particle swarm depends on the original search speed, the optimal particle fitness, and the global optimal fitness. The search speed can be changed if we change the global optimal fitness through a mutation algorithm; therefore, the search direction of the particle swarm changes. It is possible for the algorithm to find new optimal particle fitness and global optimal fitness values.
This paper uses the mutation algorithm mentioned in [
38]. Let
be the fitness of particle
i and
be the average fitness of the particle swarm; the group fitness variance
describes the aggregation degree of the particle swarm, as follows:
where
f is the normalized calibration factor, which can be calculated as follows:
The group fitness variance represents the aggregation degree of the particle swarm. The smaller it is, the more the swarm is aggregated. Otherwise, the swarm is more dispersed.
If the swarm gathers too early, the algorithm stagnates in a local optima solution. This causes the algorithm to exhibit low efficiency or even fail. Within the maximum number of iterations, the global optimal fitness mutates as a mutation probability
to increase the population diversity.
where
k is a random value in
;
is related to the actual conditions and is much lower than the maximum value of
.
can be set to a small value; thus, the optimal fitness moves to this value.
The mutation of
adopts the stochastic disturbance approach. Let
be the
kth dimension of
and
be a random number obeying a Gaussian
distribution; the mutated
is as follows:
The improved PSO algorithm can adaptively adjust the parameters according to the solution conditions. The algorithm is shown in Algorithm 1.
| Algorithm 1: Improved PSO Algorithm |
![Actuators 10 00207 i001]() |
7. Conclusions and Future Works
In this paper, we addressed the problem of optimal operation control strategies for virtual coupling trains at junctions. First, we formulated a cooperative game-based model for the coupling process as an optimal problem. Then, the cost function was formulated. The game was solved by minimizing the cost function of the coalition. Finally, we designed an improved PSO to find the optimal solution of the model and generate strategies for trains.
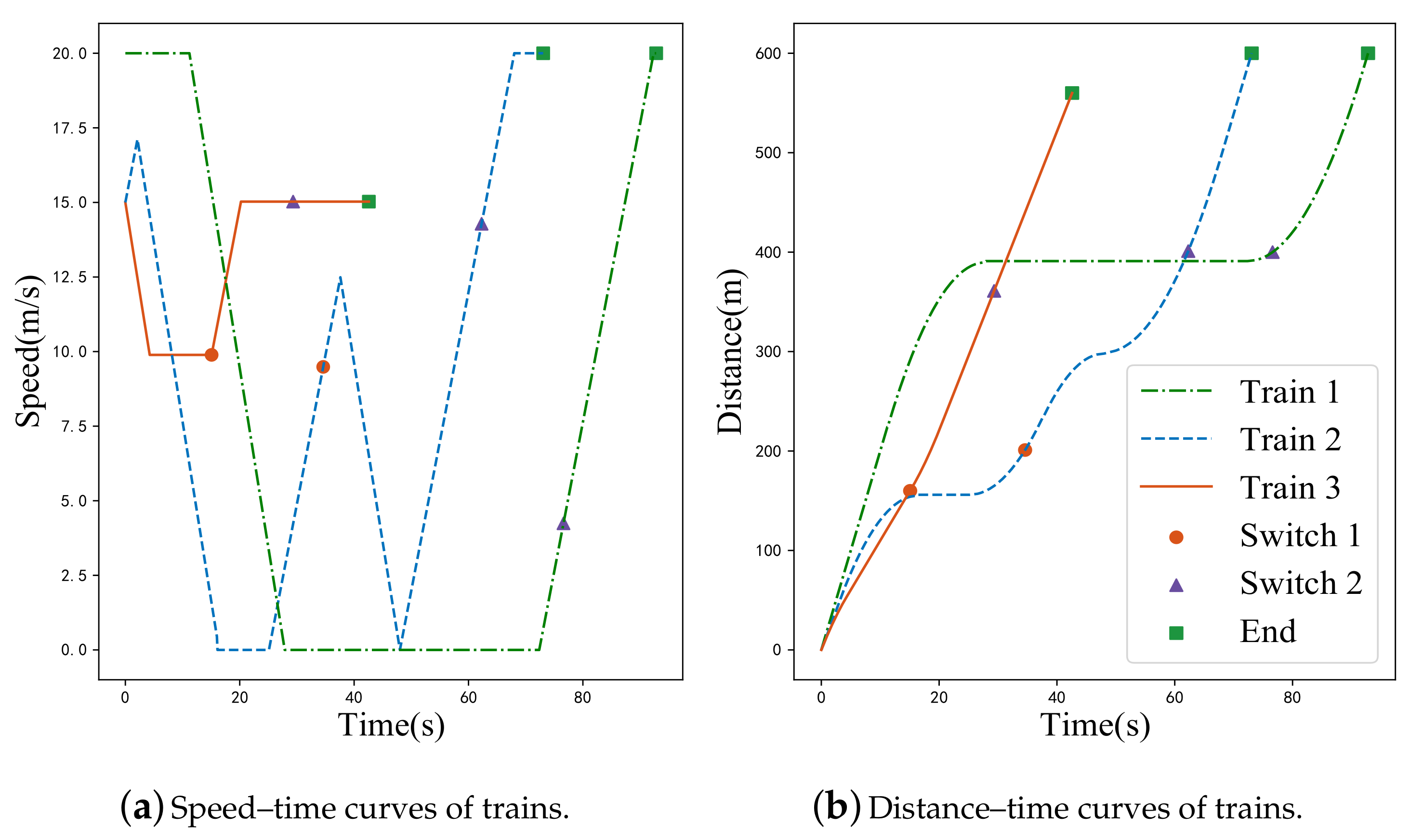
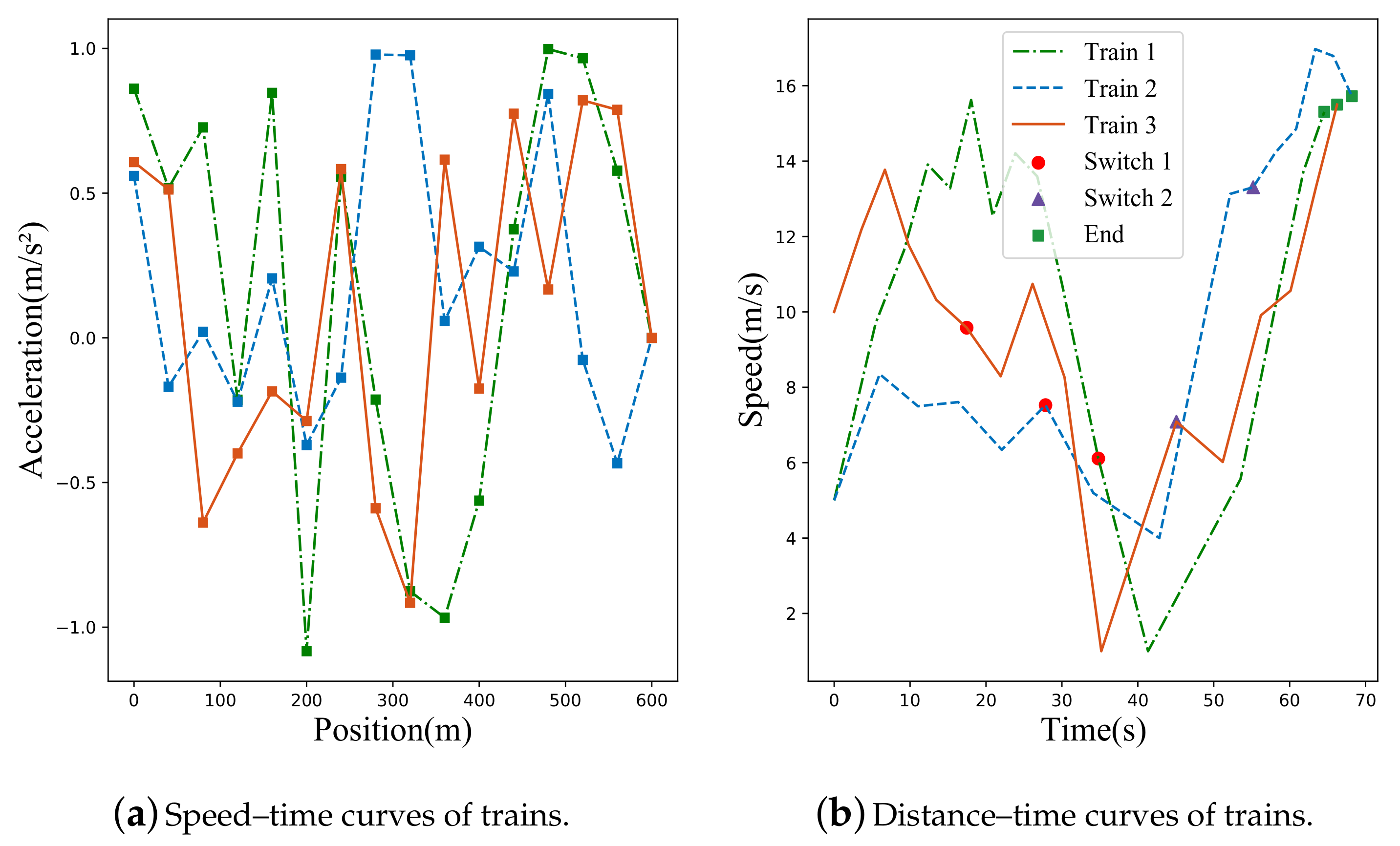
The proposed method was validated through simulation and then compared with two pre-programmed train operation strategies and the unimproved PSO strategies generating method. The proposed method can generate different operation strategies for every train according to specific conditions. Compared with the two naive strategies, the proposed method reached coupled status in the planned position. It is almost impossible for the naive strategies to reach the coupled status within such a short distance. Compared with the unimproved PSO strategies generating method, the proposed method can better adapt the cooperative game model and obtain an optimal solution. Nevertheless, the unimproved PSO strategy demonstrated great contingency and easy convergence to local optima. This can cause extra waiting time or even failure of the coupling process.
Furthermore, the proposed method demonstrated shorter coupling times. Compared with naive strategy 1, naive strategy 2, and the unimproved PSO strategy, it decreased train operation time by 41.7%, 22.10%, and 54.85%, respectively. The proposed method also had a faster coupled speed. Compared with naive strategy 1, naive strategy 2, and the unimproved PSO strategy, it increased train operation speed by 4.2%, 6.3%, and 63.08%, respectively.
Future research should attempt to extend the virtual coupling optimization to a multi-object problem. Energy conservation and comfort should be considered for better passenger experience and environmental protection.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}