
UAV Path Planning and Obstacle Avoidance Based on Reinforcement Learning in 3D Environments


Abstract
:1. Introduction
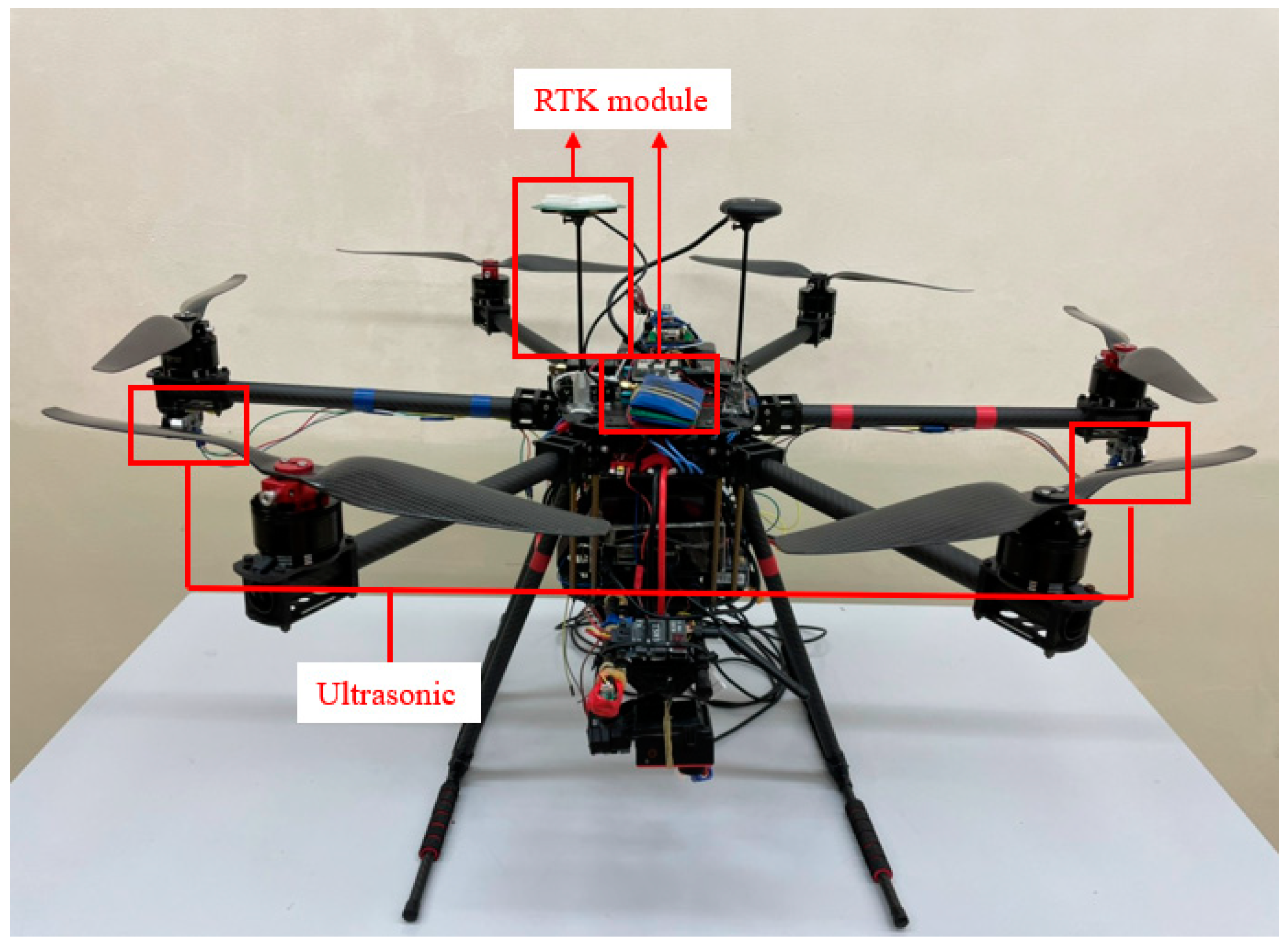
2. System Description
3. Path Planning
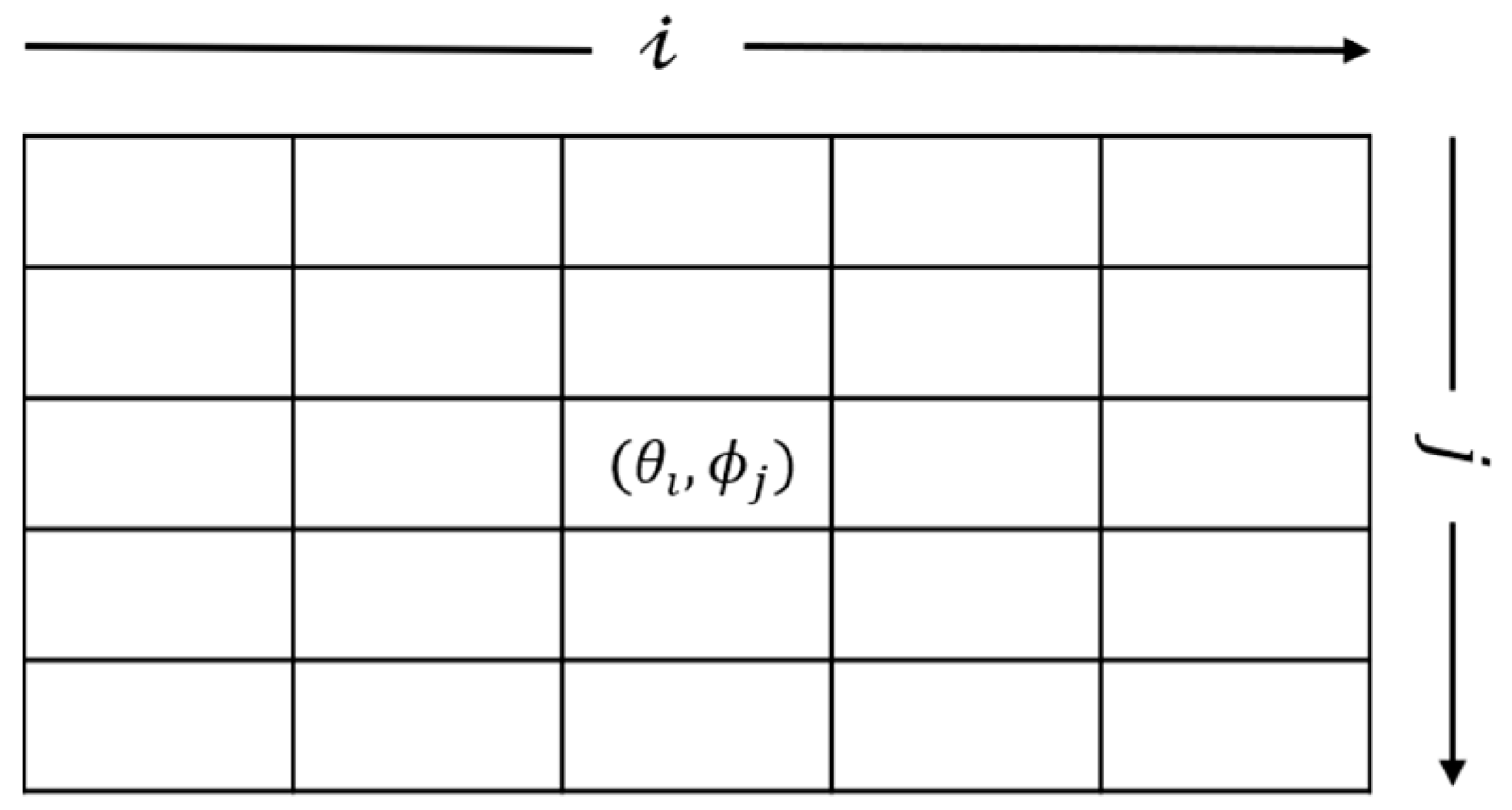
3.1. Markov Decision Process (MDP)
3.2. Bellman Equation
3.3. Policy
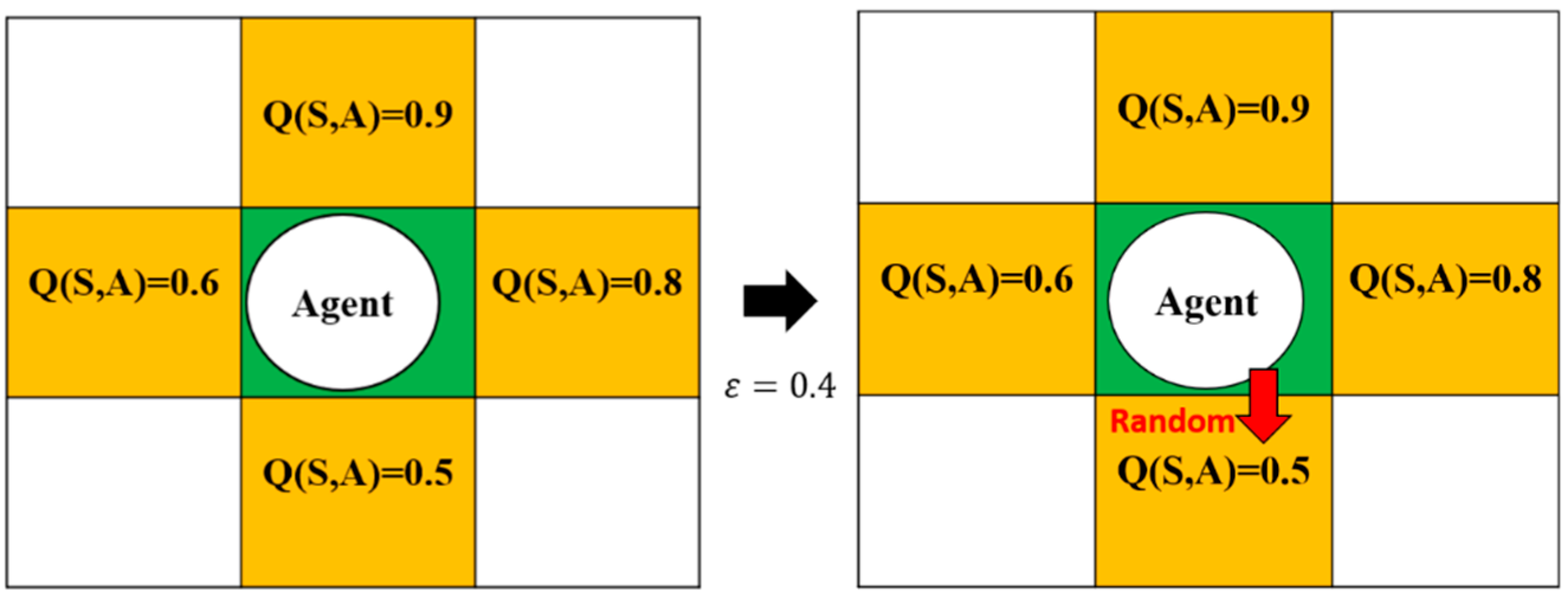
3.4. Q-Learning Algorithm
| Algorithm 1 Q-learning (off-policy TD control) for estimating |
| Initialize arbitrarily, and Repeat (for each episode): Initialize S Repeat (for each step of episode): Choose A from S using policy derived from Q (e.g.,-greedy) Take action A, observe R, ; until S is terminal |
3.5. Reward
3.6. State–Action–Reward–State–Action (SARSA) Algorithm
| Algorithm 2 Sarsa (on-policy TD control) for estimating |
| Initialize arbitrarily, and Repeat (for each episode): Initialize S Choose A from S using policy derived from Q (e.g.,-greedy) Repeat (for each step of episode): Take action A, observe R, Choose from using policy derived from Q (e.g.,-greedy) until S is terminal |
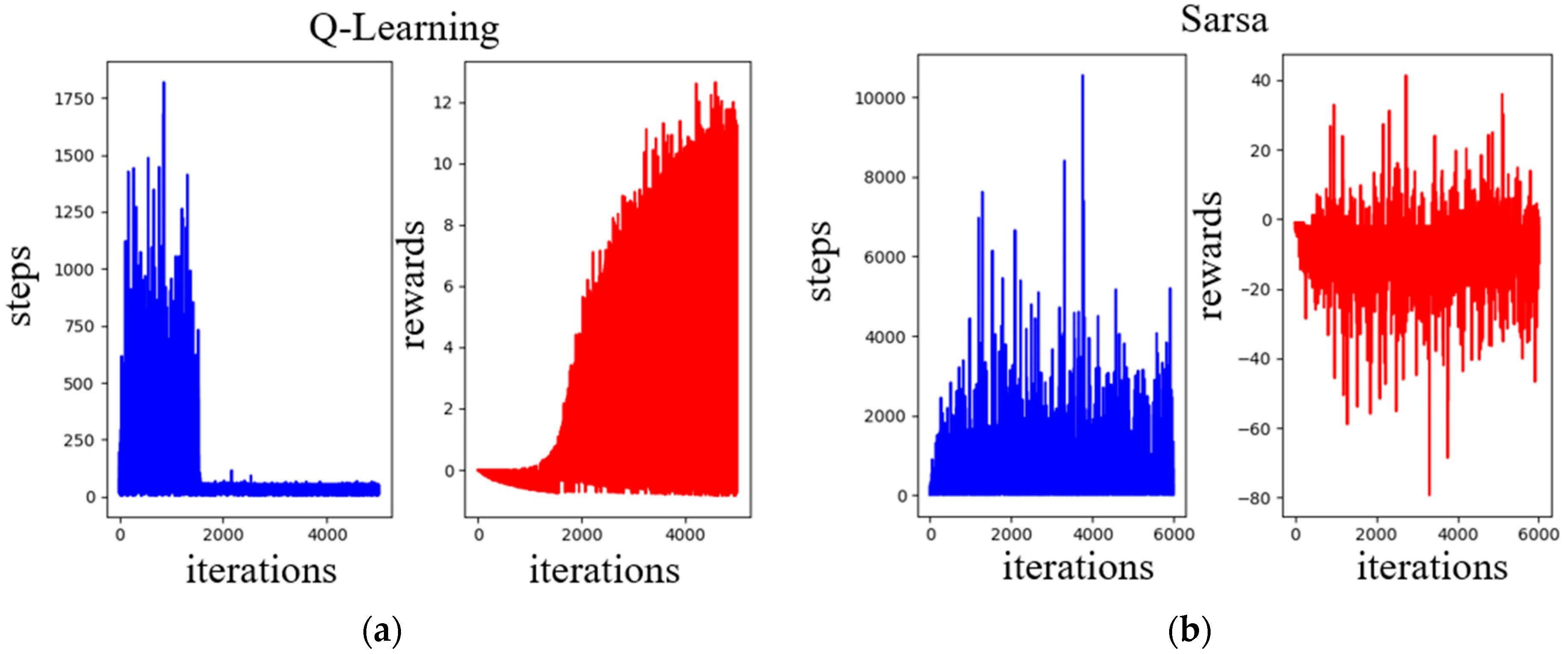
3.7. SARSA Algorithm, Compared with the Q-Learning Algorithm
4. Obstacle Avoidance
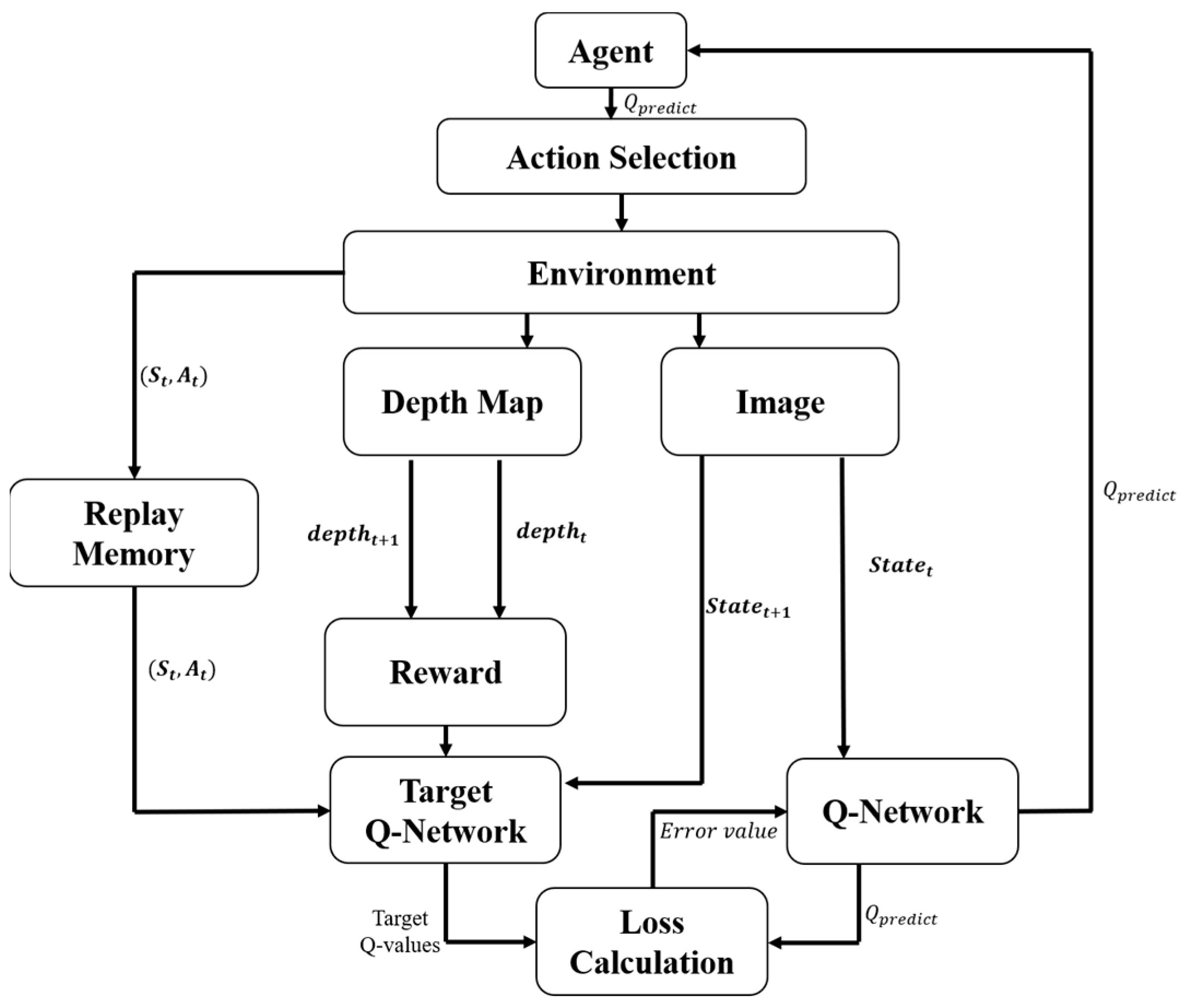
4.1. Deep Q-Learning Algorithm
| Algorithm 3 Deep Q-learning with Experience Replay |
| Initialize replay memory D to capacity N Initialize action-value function Q with random weights For episode = 1, M do Initialize sequence and preprocessed sequenced for t = 1, T do With probability select a random action select a random action otherwise select Execute action in emulator and observe reward and image Set ,, and preprocess Store transition (,,,) in D Sample random minibatch of transitions (,,,) from D Set Perform a gradient descent step on according to Equation (3) end for end for |
4.2. Microsoft AirSim Environment
4.3. Obstacle Avoidance System in the AirSim Environment
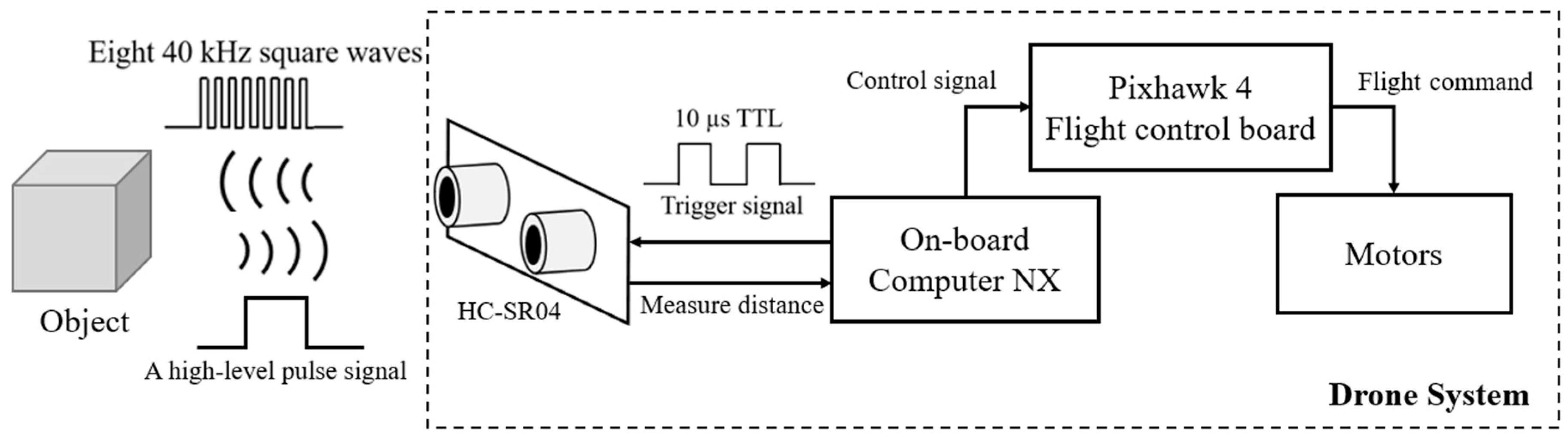
4.4. Ultrasonic Sensor
- Step 1.
- Set the maximum tolerance as 0.3 cm.
- Step 2.
- Send impulse signal and get five data each time from the ultrasonic sensor, then add in the temporary data list.
- Step 3.
- Sort the received data and calculate the median value of the data list.
- Step 4.
- If there is a previous value, go to step 5, or go to step 6.
- Step 5.
- Calculate the difference in the current value and the previous value; if the difference is bigger than the maximum tolerance, then the output is equal to the previous result, plus or minus the maximum tolerance.
- Step 6.
- Record the current value as the previous value and output the result and go to step 2.
- Step 1.
- Set to enter the protection mode when the output value is continuous and the same.
- Step 2.
- Save 30 values to the temporary data list.
- Step 3.
- Compare the first 29 items of data with the last 29 items of data in the temporary data list.
- Step 4.
- If the values are the same, close and restart the measurement.
5. Experimental Results
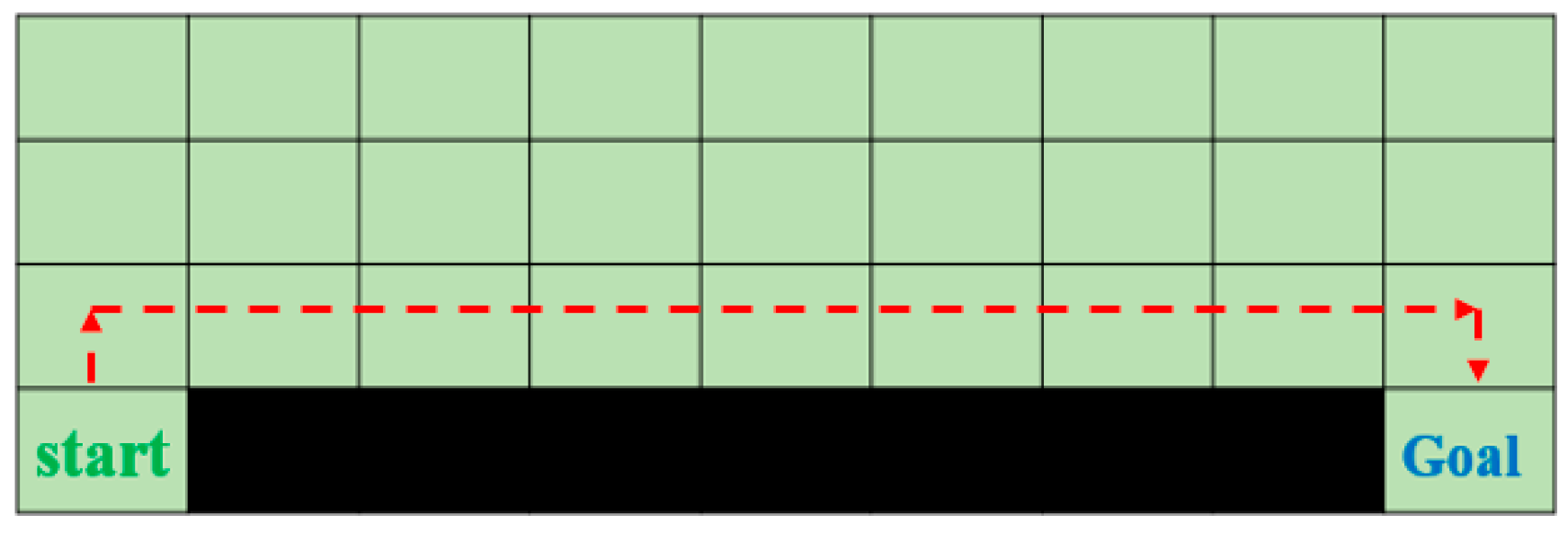
5.1. Path Planning
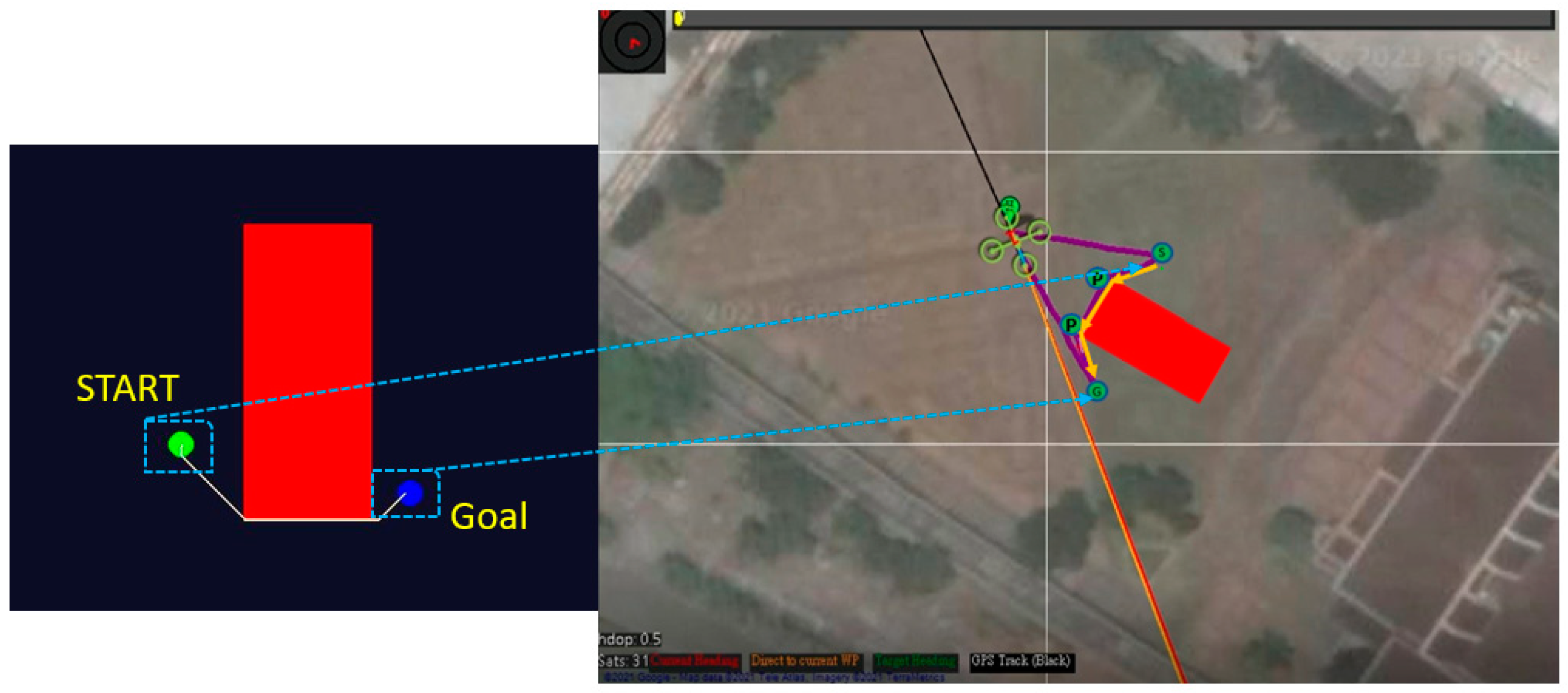
5.2. Obstacle Avoidance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Stentz, A. Optimal and efficient path planning for unknown and dynamic environments. Int. J. Robot. Autom. Syst. 1995, 10, 89–100. [Google Scholar]
- LaValle, S.M.; Kuffner, J.J. Randomized kinodynamic planning. Int. J. Robot. Res. 2001, 20, 378–400. [Google Scholar] [CrossRef]
- Sen, Y.; Zhongsheng, W. Quad-Rotor UAV Control Method Based on PID Control Law. In Proceedings of the 2017 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–26 September 2017; pp. 418–421. [Google Scholar] [CrossRef]
- Kamel, B.; Yasmina, B.; Laredj, B.; Benaoumeur, I.; Zoubir, A. Dynamic Modeling, Simulation and PID Controller of Unmanned Aerial Vehicle UAV. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Porto, Portugal, 12–13 July 2017; pp. 64–69. [Google Scholar] [CrossRef]
- Lee, S.; Shim, T.; Kim, S.; Park, J.; Hong, K.; Bang, H. Vision-Based Autonomous Landing of a Multi-Copter Unmanned Aerial Vehicle using Reinforcement Learning. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 108–114. [Google Scholar] [CrossRef]
- Sugimoto, T.; Gouko, M. Acquisition of Hovering by Actual UAV Using Reinforcement Learning. In Proceedings of the 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016; pp. 148–152. [Google Scholar] [CrossRef]
- Lampersberger, T.; Feger, R.; Haderer, A.; Egger, C.; Friedl, M.; Stelzer, A. A 24-GHz Radar with 3D-Printed and Metallized Lightweight Antennas for UAV Applications. In Proceedings of the 2018 48th European Microwave Conference (EuMC), Madrid, Spain, 23–27 September 2018; pp. 1413–1416. [Google Scholar] [CrossRef]
- Udvardy, P.; Jancsó, T.; Beszédes, B. 3D Modelling by UAV Survey in a Church. In 2019 New Trends in Aviation Development (NTAD); IEEE: Piscataway, NJ, USA, 2019; pp. 189–192. [Google Scholar] [CrossRef]
- Ma, Z.; Ai, B.; He, R.; Wang, G.; Niu, Y.; Zhong, Z. A Wideband Non-Stationary Air-to-Air Channel Model for UAV Communications. IEEE Trans. Veh. Technol. 2020, 69, 1214–1226. [Google Scholar] [CrossRef]
- Feng, K.; Li, W.; Ge, S.; Pan, F. Packages Delivery Based on Marker Detection for UAVs. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 2094–2099. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Xiang, X. A Path Planning Algorithm for UAV Based on Improved Q-Learning. In Proceedings of the 2018 2nd International Conference on Robotics and Automation Sciences (ICRAS), Wuhan, China, 23–25 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, T.; Huo, X.; Chen, S.; Yang, B.; Zhang, G. Hybrid Path Planning of a Quadrotor UAV Based on Q-Learning Algorithm. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5415–5419. [Google Scholar] [CrossRef]
- Li, R.; Fu, L.; Wang, L.; Hu, X. Improved Q-learning Based Route Planning Method for UAVs in Unknown Environment. In Proceedings of the 2019 IEEE 15th International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019; pp. 118–123. [Google Scholar] [CrossRef]
- Hou, X.; Liu, F.; Wang, R.; Yu, Y. A UAV Dynamic Path Planning Algorithm. In Proceedings of the 2020 35th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Zhanjiang, China, 16–18 October 2020; pp. 127–131. [Google Scholar] [CrossRef]
- Anwar, A.; Raychowdhury, A. Autonomous Navigation via Deep Reinforcement Learning for Resource Constraint Edge Nodes Using Transfer Learning. IEEE Access 2020, 8, 26549–26560. [Google Scholar] [CrossRef]
- Singla, A.; Padakandla, S.; Bhatnagar, S. Memory-Based Deep Reinforcement Learning for Obstacle Avoidance in UAV With Limited Environment Knowledge. IEEE Trans. Intell. Transp. Syst. 2021, 22, 107–118. [Google Scholar] [CrossRef]
- Duc, N.; Hai, Q.; Van, D.; Trong, T.; Trong, T. An Approach for UAV Indoor Obstacle Avoidance Based on AI Technique with Ensemble of ResNet8 and Res-DQN. In Proceedings of the 2019 6th NAFOSTED Conference on Information and Computer Science (NICS); 2019; pp. 330–335. [Google Scholar] [CrossRef]
- Çetin, E.; Barrado, C.; Muñoz, G.; Macias, M.; Pastor, E. Drone Navigation and Avoidance of Obstacles Through Deep Reinforcement Learning. In Proceedings of the 2019 IEEE/AIAA 38th Digital Avionics Systems Conference (DASC), San Diego, CA, USA, 8–12 September 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Wu, T.; Tseng, S.; Lai, C.; Ho, C.; Lai, Y. Navigating Assistance System for Quadcopter with Deep Reinforcement Learning. In Proceedings of the 2018 1st International Cognitive Cities Conference (IC3), Okinawa, Japan, 7–9 August 2018; pp. 16–19. [Google Scholar] [CrossRef]
- Tu, G.; Juang, J. Path Planning and Obstacle Avoidance Based on Reinforcement Learning for UAV Application. In Proceedings of the 2021 International Conference on System Science and Engineering, Ho Chi Minh City, Vietnam, 26–28 August 2021. [Google Scholar]
- Zheng, Y.; Wang, L.; Xi, P. Improved Ant Colony Algorithm for Multi-Agent Path Planning in Dynamic Environment. In Proceedings of the 2018 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Xi’an, China, 15–17 August 2018; pp. 732–737. [Google Scholar] [CrossRef]
- Zhang, D.; Xian, Y.; Li, J.; Lei, G.; Chang, Y. UAV Path Planning Based on Chaos Ant Colony Algorithm. In Proceedings of the 2015 International Conference on Computer Science and Mechanical Automation (CSMA), Washington, DC, USA, 23–25 October 2015; pp. 81–85. [Google Scholar] [CrossRef]
- Yujie, L.; Yu, P.; Yixin, S.; Huajun, Z.; Danhong, Z.; Yong, S. Ship Path Planning Based on Improved Particle Swarm Optimization. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 20 November–2 December 2018; pp. 226–230. [Google Scholar] [CrossRef]
- Markov, A.A. Extension of the Limit Theorems of Probability Theory to a Sum of Variables Connected in a Chain; Reprinted in Appendix B of: R. Howard. Dynamic Probabilistic Systems, Volume 1: Markov Chains; John Wiley and Sons: Hoboken, NJ, USA, 1971. [Google Scholar]
- Sammut, C.; Webb, G.I. (Eds.) Bellman Equation. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. 16 Greedy Algorithms. In Introduction to Algorithms; MIT Press: Cambridge, MA, USA, 2001; p. 370. ISBN 978-0-262-03293-3. [Google Scholar]
- Tokic, M. Adaptive ε-greedy Exploration in Reinforcement Learning Based on Value Differences. In KI 2010: Advances in Artificial Intelligence; Lecture Notes in Computer Science, 6359; Springer-Verlag: Berlin/Heidelberg, Germany, 2010; pp. 203–210. [Google Scholar] [CrossRef] [Green Version]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Xu, D.; Fang, Y.; Zhang, Z.; Meng, Y. Path Planning Method Combining Depth Learning and Sarsa Algorithm. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; pp. 77–82. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, W.; Wang, Z.; Ding, B. Neural Q Learning Algorithm based UAV Obstacle Avoidance. In Proceedings of the 2018 IEEE CSAA Guidance, Navigation and Control Conference (CGNCC), Xiamen, China, 10–12 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Xiaodong, Y.; Rui, L.; Yingjing, S.; Xiang, C. Obstacle Avoidance for Outdoor Flight of a Quadrotor Based on Computer Vision. In Proceedings of the 2017 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 3841–3846. [Google Scholar] [CrossRef]
- Hu, J.; Niu, Y.; Wang, Z. Obstacle Avoidance Methods for Rotor UAVs Using RealSense Camera. In Proceedings of the 2017 Chinese Automation Congress (CAC); 2017; pp. 7151–7155. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Airsim Open Source Platform at Github. Available online: https://github.com/Microsoft/AirSim (accessed on 23 July 2020).
- Huang, T.; Juang, J. Real-time Path Planning and Fuzzy Based Obstacle Avoidance for UAV Application. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Kagawa, Japan, 31 August–3 September 2020. [Google Scholar]











































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error (cm) | Error Percentage | Cost Time (s) | ||
|---|---|---|---|---|
| 35 | 34.97 | 0.03 | 0.08% | 0.0205 |
| 60 | 59.88 | 0.12 | 0.20% | 0.0311 |
| 75 | 75.69 | 0.69 | 0.92% | 0.0363 |
| 100 | 100.45 | 0.45 | 0.45% | 0.0429 |
| 200 | 198.79 | 1.21 | 0.605% | 0.0812 |
| 250 | 246.42 | 3.58 | 1.432% | 0.0965 |
| 300 | 297.28 | 2.72 | 0.906% | 0.1203 |
| 350 | 346.58 | 3.42 | 0.977% | 0.1299 |
| 400 | 394.56 | 5.44 | 1.36% | 0.1483 |
| 450 | 443.42 | 6.58 | 1.462% | 0.1712 |
| Environment 1 | SARSA | Q-Learning |
|---|---|---|
| path length | 62 steps | 42 steps |
| exploration time | 32 min | 15 min |
| Environment 2 | SARSA | Q-Learning |
|---|---|---|
| path length | 140 steps | 46 steps |
| exploration time | 45 min | 25 min |
| Iterations | Batch Size | ||
|---|---|---|---|
| 140,000 | 32 | 0.95 | 0.000006 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, G.-T.; Juang, J.-G. UAV Path Planning and Obstacle Avoidance Based on Reinforcement Learning in 3D Environments. Actuators 2023, 12, 57. https://doi.org/10.3390/act12020057
Tu G-T, Juang J-G. UAV Path Planning and Obstacle Avoidance Based on Reinforcement Learning in 3D Environments. Actuators. 2023; 12(2):57. https://doi.org/10.3390/act12020057
Chicago/Turabian StyleTu, Guan-Ting, and Jih-Gau Juang. 2023. "UAV Path Planning and Obstacle Avoidance Based on Reinforcement Learning in 3D Environments" Actuators 12, no. 2: 57. https://doi.org/10.3390/act12020057
APA StyleTu, G. -T., & Juang, J. -G. (2023). UAV Path Planning and Obstacle Avoidance Based on Reinforcement Learning in 3D Environments. Actuators, 12(2), 57. https://doi.org/10.3390/act12020057