
Leak-Off Pressure Using Weakly Correlated Geospatial Information and Machine Learning Algorithms



Abstract
:1. Introduction
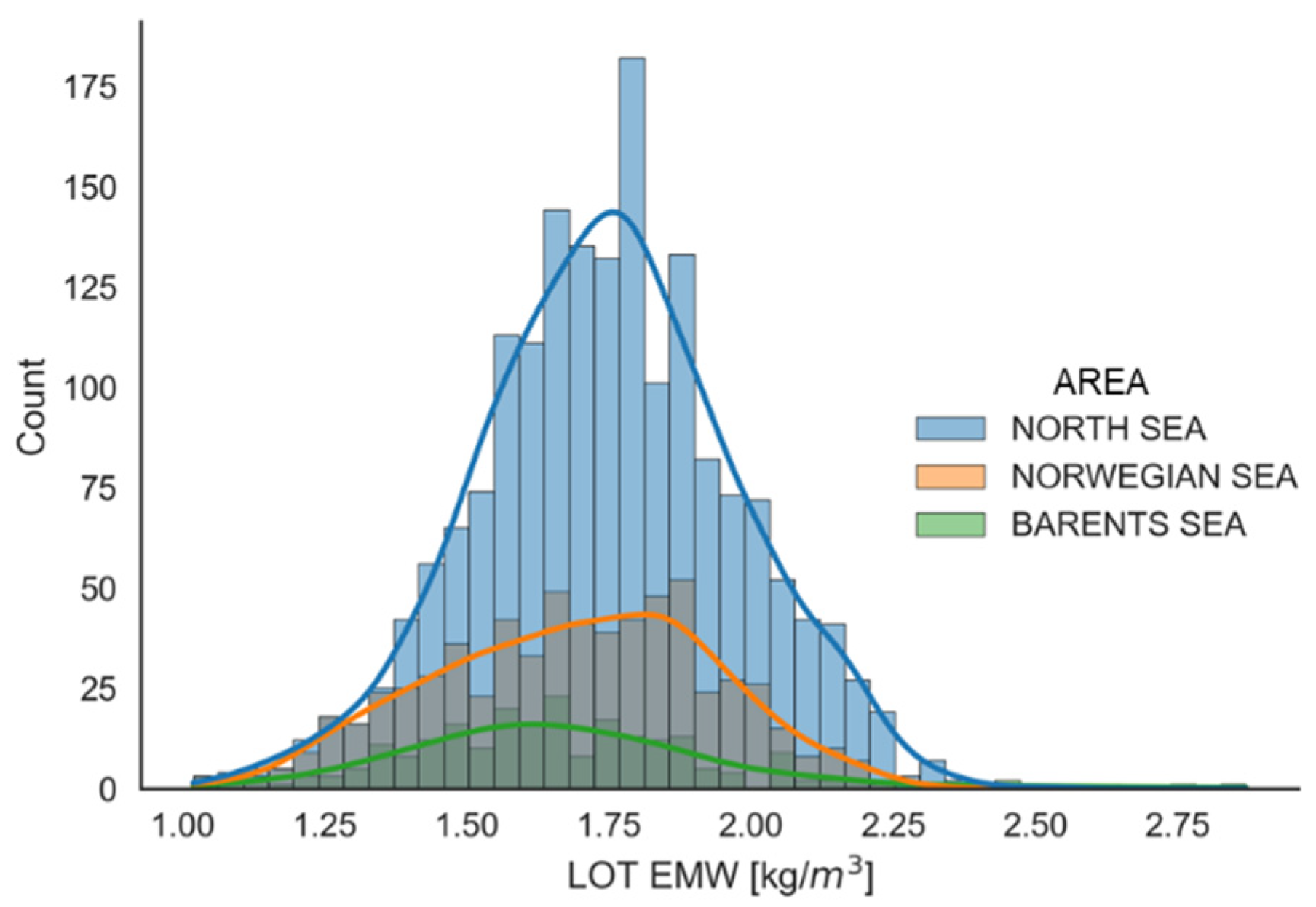
2. Database
3. Machine Learning Algorithms
3.1. Deep Neural Network
3.2. Random Forest (RF)
3.3. Support Vector Machine
3.4. Performance Indicators for Machine Learning (ML) Models
3.5. Hyperparameter Search Algorithms
4. Results of Analyses
4.1. Correlation Analysis of Leak-Off Pressure (LOP) Data
4.2. Pre-Processed Data
4.3. Accuracy and Calculation Time for Three Hyperparameter Optimization Methods
4.4. Accuracy and Calculation Time for Three Machine Learning Algorithms
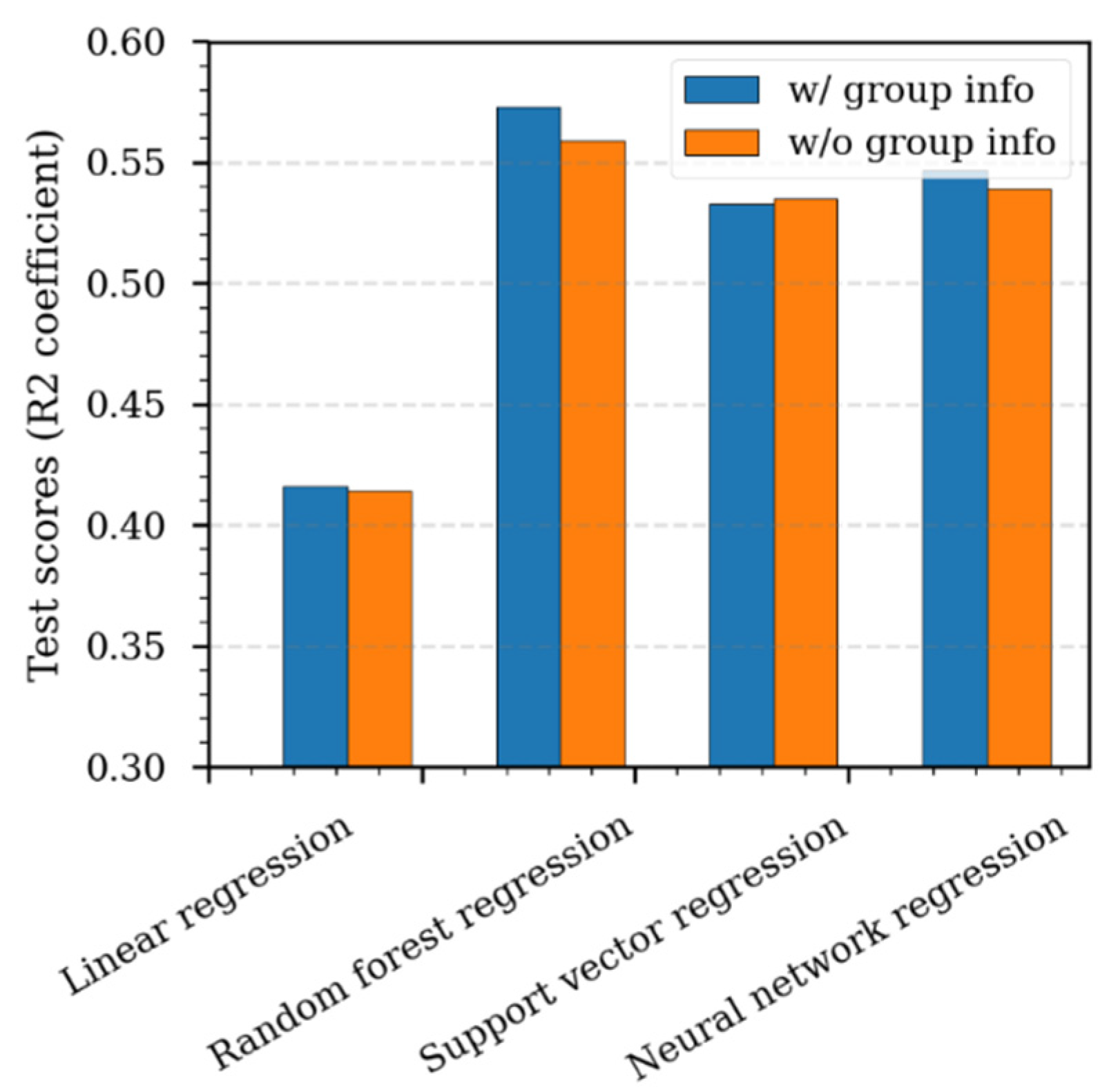
4.5. Effect of Data Grouping on the Machine Learning Prediction
5. Discussion
5.1. Performance of the Three Machine Learning Algorithms
5.2. Correlation between LOP and Geospatial Information
6. Conclusions
- The Bayesian search algorithm was able to optimize hyperparameters more efficiently than the grid search and random search algorithms.
- The three machine learning algorithms (random forest, support vector machine, deep neural network) showed higher predictive scores than the multivariate linear regression. However, if the inputs were not scaled, the support vector machine and the neural network regression algorithms resulted in poorer scores than the multivariate linear regression.
- When the geographical area information (i.e., North Sea, Norwegian Sea, and Barents Sea) was taken separately in the machine learning analysis, the models performed only slightly better than the models considering all data from the three geographical areas together.
- However, even well-optimized models do not result in meaningfully higher test scores than its highest correlation coefficient or the score of linear regression. This could be related to the small number of data points (3000 or less) and the weak correlation between the LOP and the input (i.e., geospatial) parameters.
- For geomechanics and geotechnics applications, where there are limited numbers of data (e.g., less than 10,000 data points), this study clearly shows that the random forest regression algorithm with Bayesian parameter optimization provides a promising performance in terms of accuracy and short calculation times. However, test scores that are not meaningfully higher than moderate correlation coefficients may suggest that accurate predictions can depend more on the number of well-correlated parameters available than the use of fancy ML algorithms and advanced optimization algorithms.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Yin, S.-X. Fracture Gradient Prediction: An Overview and an Improved Method. Pet. Sci. 2017, 14, 720–730. [Google Scholar] [CrossRef] [Green Version]
- Eaton, B.A. Fracture Gradient Prediction and Its Application in Oilfield Operations. J. Pet. Technol. 1969, 21, 1353–1360. [Google Scholar] [CrossRef]
- Hubbert, M.K.; Willis, D.G. Mechanics of Hydraulic Fracturing. Trans. AIME 1957, 210, 153–168. [Google Scholar] [CrossRef]
- Matthews, W.R.; Kelly, J. How to Predict Formation Pressure and Fracture Gradient. Oil Gas J. 1967, 65, 92–1066. [Google Scholar]
- Breckels, I.M.; van Eekelen, H.A.M. Relationship between Horizontal Stress and Depth in Sedimentary Basins. J. Pet. Technol. 1982, 34, 2191–2199. [Google Scholar] [CrossRef]
- Andrews, J.S.; de Lesquen, C. Stress Determination from Logs. Why the Simple Uniaxial Strain Model Is Physically Flawed but Still Gives Relatively Good Matches to High Quality Stress Measurements Performed on Several Fields Offshore Norway; 53rd U.S. Rock Mechanics/Geomechanics Symposium: New York, NY, USA, June 2019. [Google Scholar]
- Wrona, T.; Pan, I.; Gawthorpe, R.L.; Fossen, H. Seismic Facies Analysis Using Machine LearningMachine-Learning-Based Facies Analysis. Geophysics 2018, 83, O83–O95. [Google Scholar] [CrossRef]
- Jia, Y.; Ma, J. What Can Machine Learning Do for Seismic Data Processing? An Interpolation Application. Geophysics 2017, 82, V163–V177. [Google Scholar] [CrossRef]
- Yin, Z.; Jin, Y.; Liu, Z. Practice of Artificial Intelligence in Geotechnical Engineering. J. Zhejiang Univ. Sci. A 2020, 21, 407–411. [Google Scholar] [CrossRef]
- Factpages—NPD. Available online: https://factpages.npd.no/ (accessed on 1 December 2020).
- Choi, J.C.; Skurtveit, E.; Grande, L. Deep Neural Network Based Prediction of Leak-Off Pressure in Offshore Norway. In Proceedings of the Offshore Technology Conference, Houston, TX, USA, 26 April 2019. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]
- Beautiful Soup Documentation—Beautiful Soup 4.4.0 Documentation. Available online: https://beautiful-soup-4.readthedocs.io/en/latest/# (accessed on 1 December 2020).
- Fejerskov, M.; Lindholm, C. Crustal Stress in and around Norway: An Evaluation of Stress-Generating Mechanisms. Geol. Soc. Lond. Spec. Publ. 2000, 167, 451–467. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chollet, F. Keras: Deep Learning Library for Theano and Tensorflow. 2015. Available online: https://Keras.Io (accessed on 15 June 2019).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning; USENIX: Savannah, GA, USA, 2016; pp. 265–283. [Google Scholar]
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Delft, The Netherlands, 2009; Volume 2, pp. 1–127. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Gilbert, G.; Cepeda, J.M.; Lysdahl, A.O.K.; Piciullo, L.; Hefre, H.; Lacasse, S. Modelling of Shallow Landslides with Machine Learning Algorithms. Geosci. Front. 2021, 12, 385–393. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Eberhart, R.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the MHS’95, the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Chicco, D. Ten Quick Tips for Machine Learning in Computational Biology. BioData Min. 2017, 10. [Google Scholar] [CrossRef] [PubMed]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:12062944. [Google Scholar]
- Head, T.; MechCoder, G.L.; Shcherbatyi, I. Scikit-Optimize/Scikit-Optimize: V0.5.2; Zenodo: 2018. Available online: http://doi.org/10.5281/zenodo.1207017 (accessed on 18 April 2021).
- Hinkle, D.E.; Wiersma, W.; Jurs, S.G. Applied Statistics for the Behavioral Sciences; Houghton Mifflin: Boston, MA, USA, 2003; ISBN 978-0-618-12405-3. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2001, 2–3, 18–22. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:200514165. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ng, A. CS229 Course Notes: Deep Learning; Stanford University: Stanford, CA, USA, 2018. [Google Scholar]
- Micheletti, N.; Foresti, L.; Robert, S.; Leuenberger, M.; Pedrazzini, A.; Jaboyedoff, M.; Kanevski, M. Machine Learning Feature Selection Methods for Landslide Susceptibility Mapping. Math. Geosci. 2014, 46, 33–57. [Google Scholar] [CrossRef] [Green Version]
- Veronesi, F.; Schillaci, C. Comparison between Geostatistical and Machine Learning Models as Predictors of Topsoil Organic Carbon with a Focus on Local Uncertainty Estimation. Ecol. Indic. 2019, 101, 1032–1044. [Google Scholar] [CrossRef]
- Chiaramonte, L.; White, J.A.; Trainor-Guitton, W. Probabilistic Geomechanical Analysis of Compartmentalization at the Snøhvit CO2 Sequestration Project. J. Geophys. Res. Solid Earth 2015, 120, 1195–1209. [Google Scholar] [CrossRef] [Green Version]
- Andrews, J.; Fintland, T.G.; Helstrup, O.A.; Horsrud, P.; Raaen, A.M. Use of Unique Database of Good Quality Stress Data to Investigate Theories of Fracture Initiation, Fracture Propagation and the Stress State in the Subsurface; American Rock Mechanics Association: Houston, TX, USA, 2016. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geographical Area | Number of Data Points | LOP EMW a [g/cm3] | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD b | Min c | 25% d | 50% e | 75% f | Max g | ||
| North Sea | 1943 | 1.74 | 0.23 | 1.02 | 1.59 | 1.74 | 1.89 | 2.53 |
| Norwegian Sea | 708 | 1.69 | 0.24 | 1.02 | 1.51 | 1.70 | 1.87 | 2.36 |
| Barents Sea | 268 | 1.65 | 0.29 | 1.03 | 1.47 | 1.62 | 1.80 | 2.87 |
| All NCS h | 2919 | 1.72 | 0.24 | 1.02 | 1.57 | 1.73 | 1.88 | 2.87 |
| Geographical Area | TVD MSLa [m] | Water Depth [m] | Latitude [°] | Longitude [°] | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| North Sea | 1905.7 | 1147.9 | 162.7 | 105.5 | 59.46 | 1.78 | 2.67 | 0.67 |
| Norwegian Sea | 2054.8 | 1123.6 | 420.9 | 313.1 | 65.08 | 0.99 | 6.96 | 1.36 |
| Barents Sea | 1417.2 | 845.1 | 333.3 | 131.2 | 71.94 | 0.65 | 21.95 | 2.86 |
| All NCS | 1901.7 | 1122.9 | 238.6 | 211.3 | 61.90 | 4.17 | 5.37 | 5.52 |
| LOP Geographical Location | Depth of LOP Measurement | Water Depth | Latitude | Longitude | ||||
|---|---|---|---|---|---|---|---|---|
| r | p-Value | r | p-Value | r | p-Value | r | p-Value | |
| North Sea | 0.64 | <0.001 | −0.17 | <0.001 | −0.23 | <0.001 | −0.01 | 0.723 |
| Norwegian Sea | 0.58 | <0.001 | −0.42 | <0.001 | −0.10 | 0.028 | 0.15 | <0.001 |
| Barents Sea | 0.25 | 0.004 | −0.22 | 0.001 | −0.07 | 0.598 | 0.16 | 0.004 |
| All NCS | 0.57 | <0.001 | −0.29 | <0.001 | −0.18 | <0.001 | −0.08 | <0.001 |
| Absolute Correlation Coefficient r | Interpretation |
|---|---|
| 0.9–1.0 | Very strong |
| 0.7–0.9 | Strong |
| 0.4–0.7 | Moderate |
| 0.2–0.4 | Weak |
| 0.0–0.2 | Negligible |
| Performance Parameter | Grid Search | Random Search | Bayesian Search | |
|---|---|---|---|---|
| Accuracy of test dataset | RMSE a | 0.158 | 0.157 | 0.158 |
| R2 b | 0.567 | 0.572 | 0.570 | |
| Accuracy of train dataset | RMSE | 0.055 | 0.079 | 0.055 |
| R2 | 0.945 | 0.889 | 0.946 | |
| Total calculation time [s] | 10,795.5 | 733.2 | 1251.9 | |
| Number of iterations | 4536 | 100 | 100 | |
| Calculation time per iteration [s] | 2.4 | 7.3 | 12.5 | |
| ML Algorithms | Hyperparameters | Search Range | Optimized Value |
|---|---|---|---|
| RF | max_depth | 1–100 | 63 |
| max_features | [‘auto’, ‘sqrt’, ‘log2’] | sqrt | |
| min_samples_leaf | 1–5 | 1 | |
| min_samples_split | 2–10 | 2 | |
| n_estimators | 1–1000 | 782 | |
| bootstrap | [True, False] | TRUE | |
| warm_start | [True, False] | True | |
| SVM | C | 1–1000 | 1 |
| gamma | 0.01–100 | 69.077 | |
| DNN | batch_size | 10–1000 | 345 |
| epochs | 100–1000 | 892 | |
| n_layer | 1–10 | 5 | |
| n_node_in_layer | 4–1024 | 958 | |
| drop_out_percent | 0–0.9 | 0.05 | |
| learning_rate | 0.0001–0.01 | 0.0008 | |
| activation_output | [Relu, Linear] | Relu |
| Test Score | Multivariate Linear Regression | RF | SVM | DNN |
|---|---|---|---|---|
| RMSE | 0.184 | 0.157 | 0.164 | 0.162 |
| R2 | 0.416 | 0.573 | 0.534 | 0.547 |
| Calculation time [s] | <1 | 996 | 283 | 47,853 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.C.; Liu, Z.; Lacasse, S.; Skurtveit, E. Leak-Off Pressure Using Weakly Correlated Geospatial Information and Machine Learning Algorithms. Geosciences 2021, 11, 181. https://doi.org/10.3390/geosciences11040181
Choi JC, Liu Z, Lacasse S, Skurtveit E. Leak-Off Pressure Using Weakly Correlated Geospatial Information and Machine Learning Algorithms. Geosciences. 2021; 11(4):181. https://doi.org/10.3390/geosciences11040181
Chicago/Turabian StyleChoi, Jung Chan, Zhongqiang Liu, Suzanne Lacasse, and Elin Skurtveit. 2021. "Leak-Off Pressure Using Weakly Correlated Geospatial Information and Machine Learning Algorithms" Geosciences 11, no. 4: 181. https://doi.org/10.3390/geosciences11040181
APA StyleChoi, J. C., Liu, Z., Lacasse, S., & Skurtveit, E. (2021). Leak-Off Pressure Using Weakly Correlated Geospatial Information and Machine Learning Algorithms. Geosciences, 11(4), 181. https://doi.org/10.3390/geosciences11040181