
A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction

 ,
,
Abstract
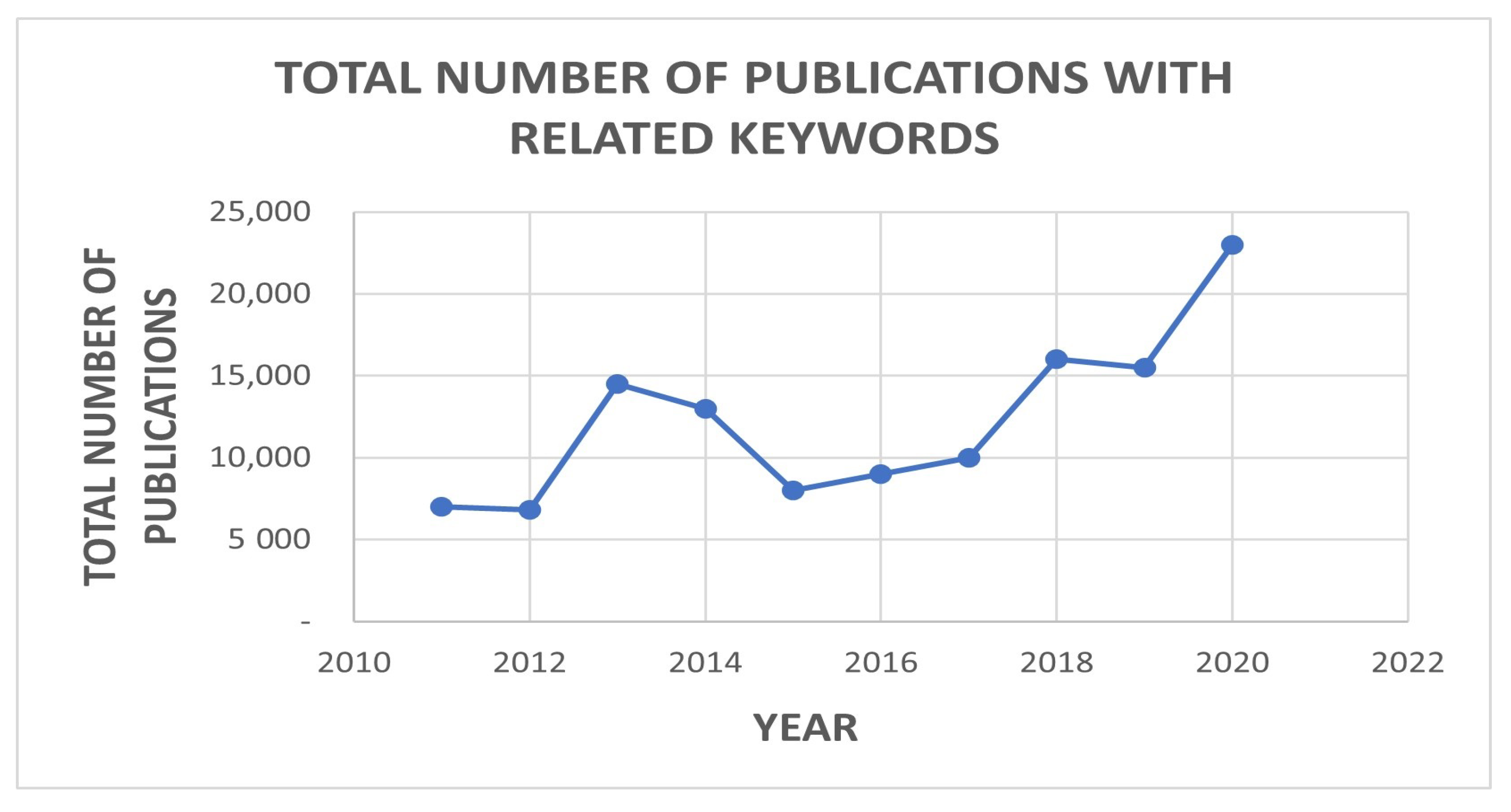
:1. Introduction
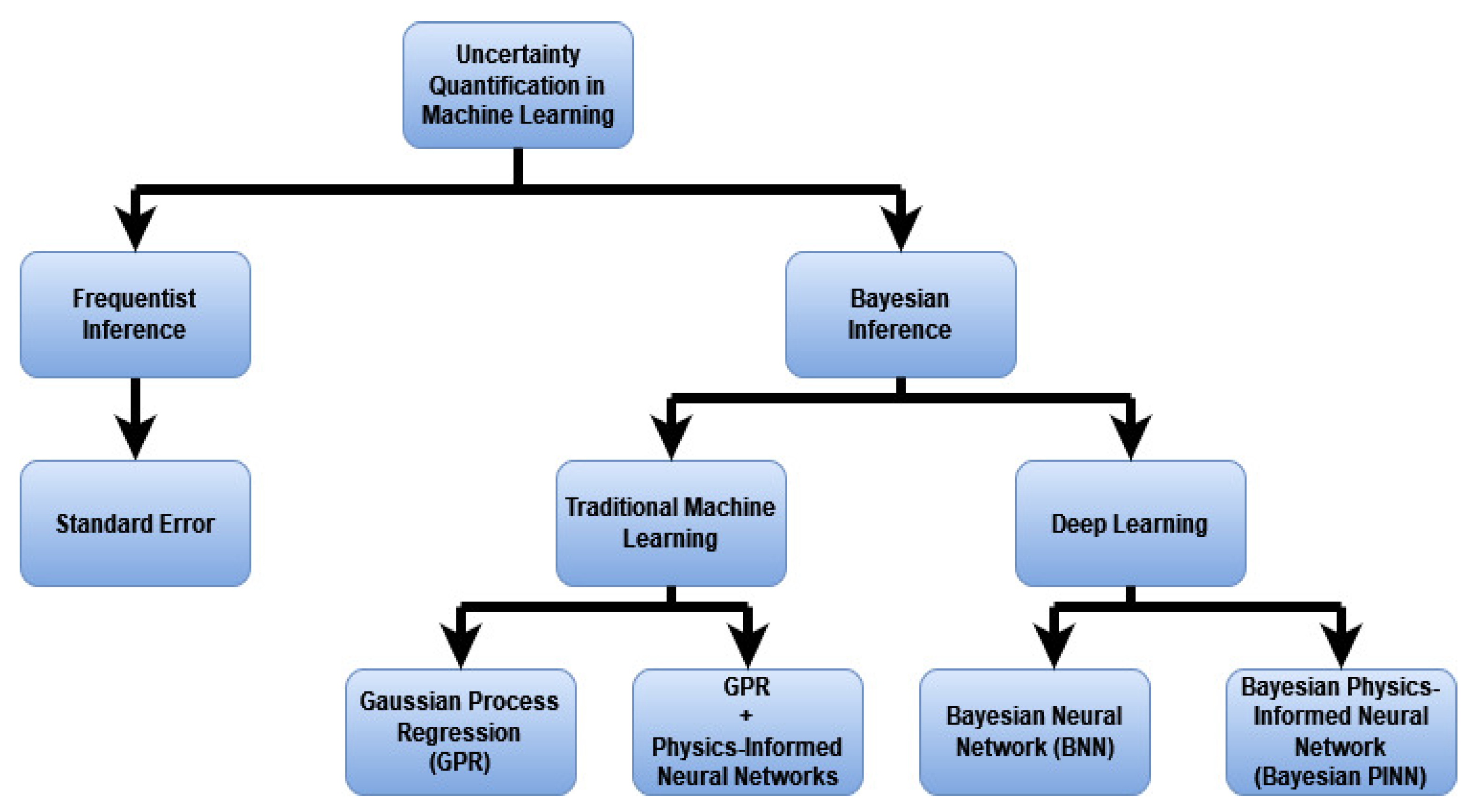
2. Uncertainty Quantification Overview
2.1. Uncertainty and Its Dimensions
- Epistemic uncertainty (parameter uncertainty): This uncertainty accounts for the uncertainty in the model parameters. With a better understanding of the model structure, accurate model relationships and constraints can be captured. In addition, with more data, the model can be trained better; therefore, this kind of uncertainty can be reduced with more knowledge about the system in focus. Moreover, epistemic uncertainty is higher in regions with little or no training data and relatively lower in regions with more training data.
- Aleatoric uncertainty (data uncertainty): This uncertainty is related to the noise inherent in the training dataset itself. Such uncertainty cannot be reduced, even if we get more data to train the model.
2.2. Uncertainty Quantification and Propagation
3. Machine Learning and Uncertainty Quantification
3.1. Overview of Machine Learning
3.2. Gaussian Process Regression for Uncertainty Quantification
3.3. Physics-Informed Models and Gaussian Process Regression
4. Uncertainty Quantification, Neural Networks and Deep Learning
4.1. Overview of Deep Learning
4.2. Physics-Informed Models and Deep Learning
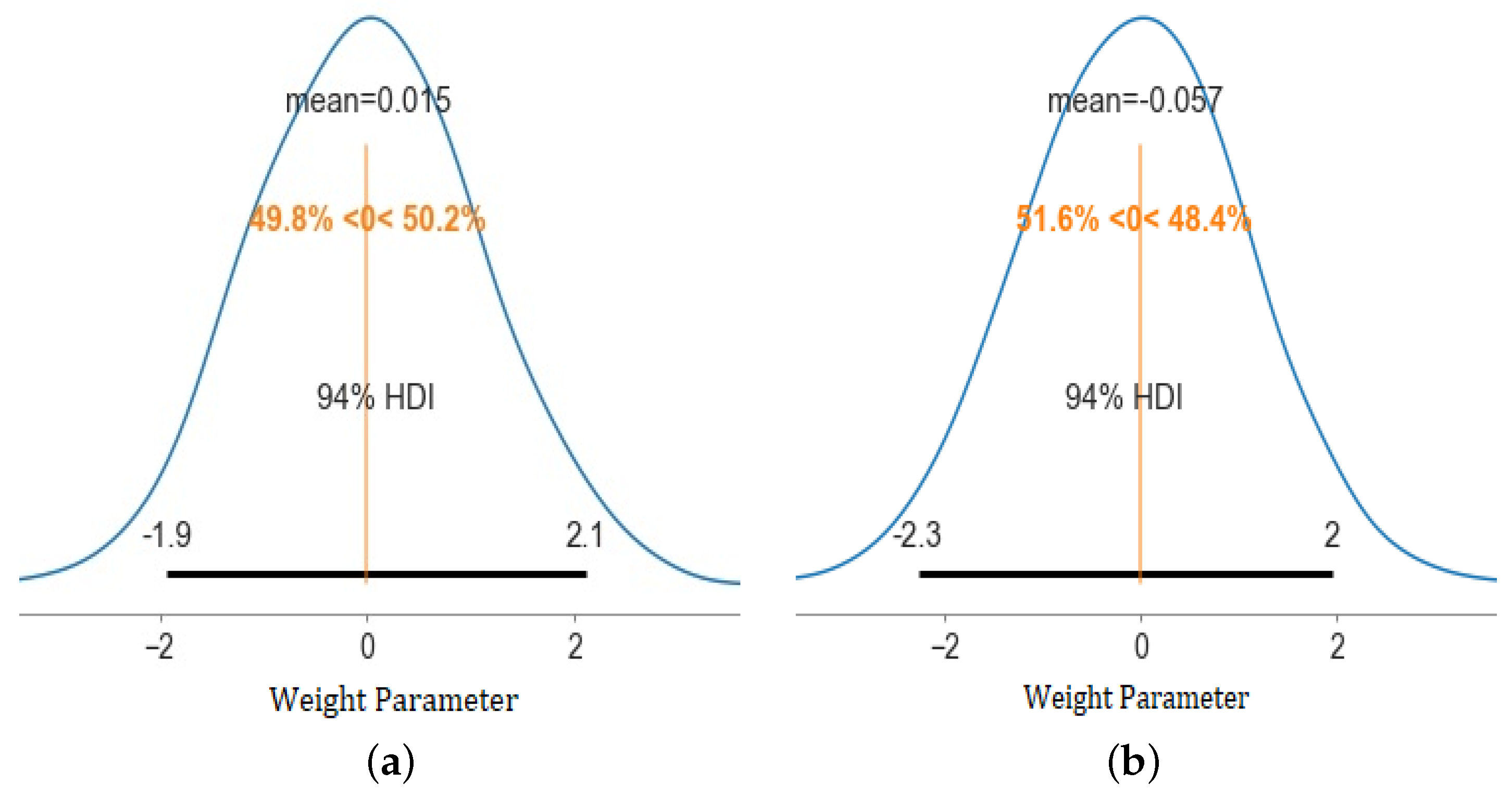
4.3. Bayesian Deep Learning and Uncertainty Quantification
5. Case Studies: Machine Learning in Space Physics Forecasting and the Need for Uncertainty Quantification
5.1. Machine Learning/Deep Learning Methods for Auroral Image Classification and GIC Prediction
5.2. Data Acquisition, Model Setup, and Variables
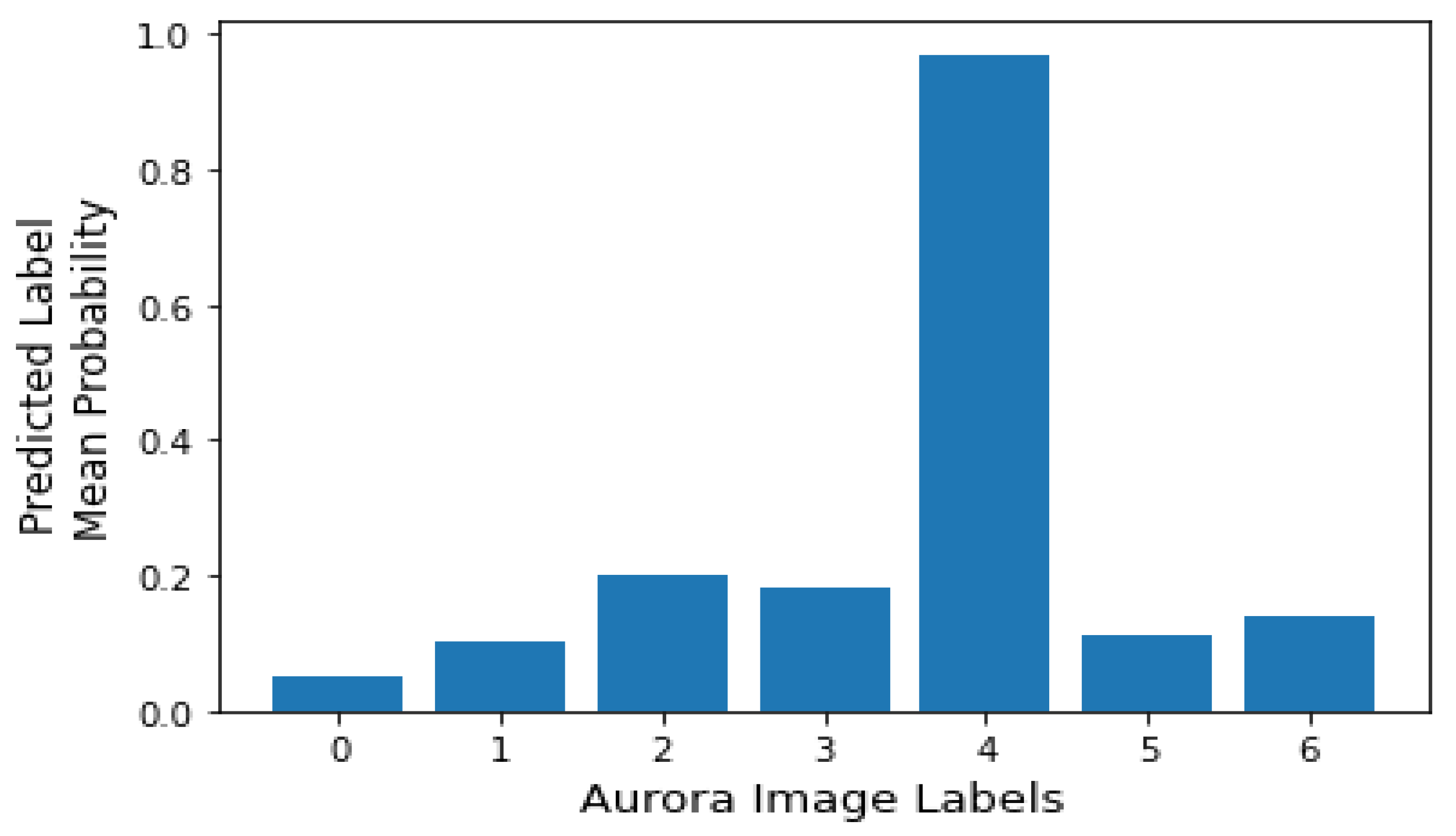
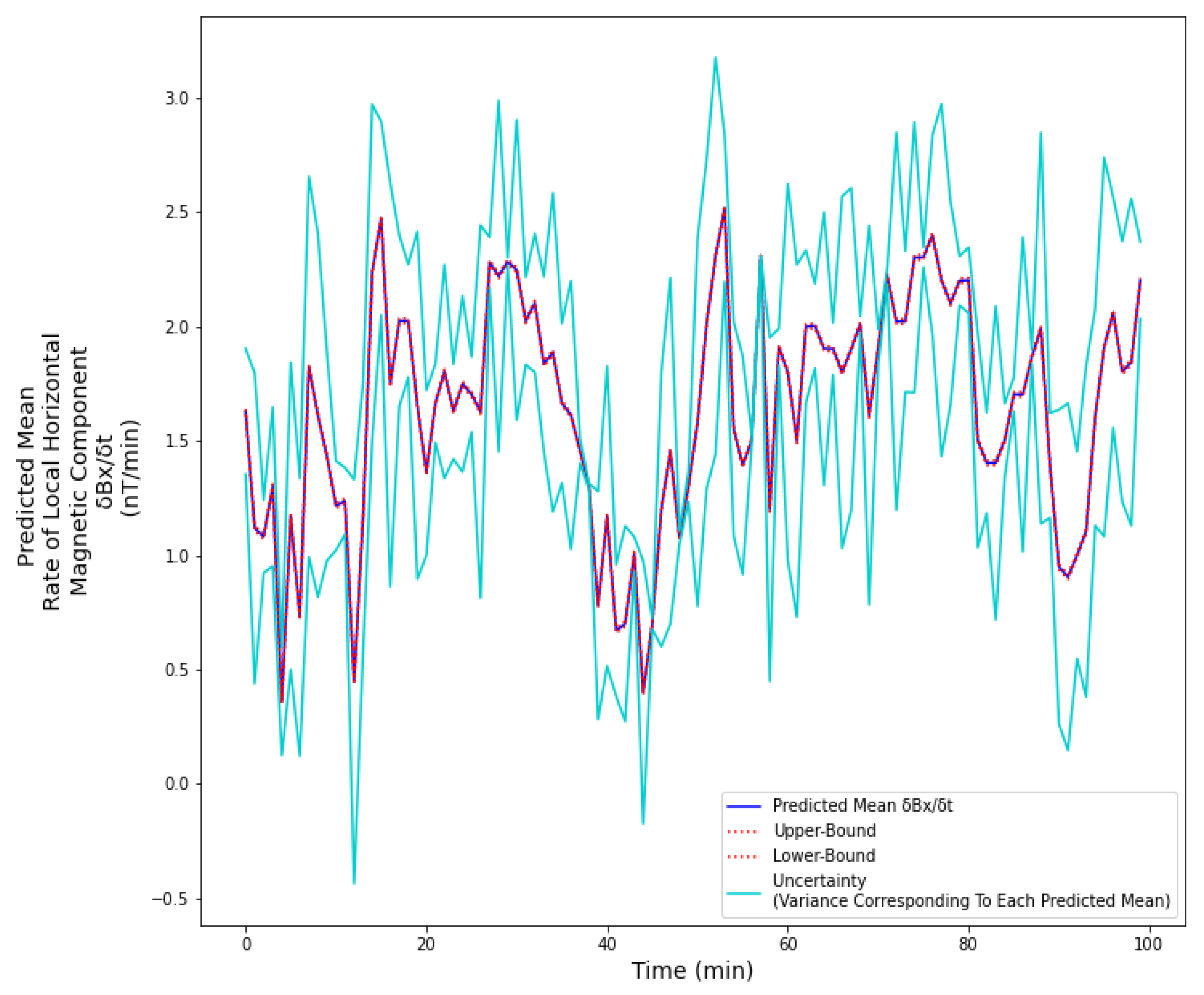
5.3. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McAfee, A.; Brynjolfsson, E. Big Data: The Management Revolution. Harv. Bus. Rev. 2012, 90, 60–66,68,128. [Google Scholar]
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: Survey, opportunities, and challenges. J. Big Data 2019, 6, 44. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Siddique, T. Agrobiodiversity for Pest Management: An Integrated Bioeconomic Simulation and Machine Learning Approach. 2019. Available online: https://www.semanticscholar.org/paper/Agrobiodiversity-For-Pest-Management3A-An-Integrated-Siddique/1c2075401bb28b826c9ce12969d46ae4b4fed13e (accessed on 20 November 2021).
- Camporeale, E. The Challenge of Machine Learning in Space Weather: Nowcasting and Forecasting. Space Weather 2019, 17, 1166–1207. [Google Scholar] [CrossRef]
- Antuña-Sánchez, J.C.; Román, R.; Cachorro, V.E.; Toledano, C.; López, C.; González, R.; Mateos, D.; Calle, A.; de Frutos, Á.M. Relative sky radiance from multi-exposure all-sky camera images. Atmos. Meas. Tech. 2021, 14, 2201–2217. [Google Scholar] [CrossRef]
- Ayyub, B.M.; Klir, G.J. Uncertainty Modeling and Analysis in Engineering and the Sciences; Chapman and Hall/CRC: London, UK, 2006; pp. 1–378. [Google Scholar] [CrossRef]
- Wang, S.; Dehghanian, P.; Li, L.; Wang, B. A Machine Learning Approach to Detection of Geomagnetically Induced Currents in Power Grids. IEEE Trans. Ind. Appl. 2020, 56, 1098–1106. [Google Scholar] [CrossRef]
- Walker, W.E.; Harremoes, P.; Rotmans, J.; Van Der Sluijs, J.P.; Van Asselt, M.B.A.; Janssen, P.; Krayer Von Krauss, M.P. Defining Uncertainty. Integr. Assess. 2003, 4, 5–17. [Google Scholar] [CrossRef] [Green Version]
- Lele, S.R. How Should We Quantify Uncertainty in Statistical Inference? Front. Ecol. Evol. 2020, 8. [Google Scholar] [CrossRef] [Green Version]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. arXiv 2020, arXiv:2011.06225. [Google Scholar] [CrossRef]
- Siddique, T.; Mahmud, M.S. Classification of fNIRS Data Under Uncertainty: A Bayesian Neural Network Approach. 2021. Available online: https://ieeexplore.ieee.org/document/9398971 (accessed on 20 November 2021).
- Klir, G.J. Uncertainty and Information: Foundations of Generalized Information Theory; Wiley: Hoboken, NJ, USA, 2006; Volume 35, pp. 1297–1299. [Google Scholar] [CrossRef]
- Ravetz, J.; Funtowicz, S. Uncertainty and Quality in Knowledge for Policy; Springer: Berlin, Germany, 1991; p. 229. [Google Scholar]
- Van Asselt, M.B.; Rotmans, J. Uncertainty in Integrated Assessment modelling. From positivism to pluralism. Clim. Chang. 2002, 54, 75–105. [Google Scholar] [CrossRef]
- Sluijs, J.V.D. Anchoring Amid Uncertainty on the Management of Uncertainties in Risk Assessment of Anthropogenic Climate Change; Ludy Feyen: Utrecht, The Netherlands, 1997. [Google Scholar]
- Meyer, V.R. Measurement uncertainty. J. Chromatogr. A 2007, 1158, 15–24. [Google Scholar] [CrossRef]
- International Bureau of Weights and Measures; International Organization for Standardization (Eds.) Guide to the Expression of Uncertainty in Measurement, 1st ed.; International Organization for Standardization: Geneve, Switzerland, 1993. [Google Scholar]
- Volodina, V.; Challenor, P. The importance of uncertainty quantification in model reproducibility. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200071. [Google Scholar] [CrossRef]
- Bai, Y.; Jin, W.L. Chapter 33—Random Variables and Uncertainty Analysis. In Marine Structural Design, 2nd ed.; Bai, Y., Jin, W.L., Eds.; Butterworth-Heinemann: Oxford, UK, 2016; pp. 615–625. [Google Scholar] [CrossRef]
- Mandat, D.; Pech, M.; Hrabovsky, M.; Schovanek, P. A TMO HEAD W ORKSHOP, 2013 All Sky Camera Instrument for Night Sky Monitoring. 2014. Available online: https://arxiv.org/abs/1402.4762 (accessed on 20 November 2021).
- Frigg, R.; Bradley, S.; Du, H.; Smith, L.A. Laplace’s Demon and the Adventures of His Apprentices. Philos. Sci. 2014, 81, 31–59. [Google Scholar] [CrossRef] [Green Version]
- Icke, I.; Bongard, J.C. Improving genetic programming based symbolic regression using deterministic machine learning. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, CEC 2013, Cancun, Mexico, 20–23 June 2013; pp. 1763–1770. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. Int. Conf. Mach. Learn. 2014, 1, 605–619. [Google Scholar]
- Zhang, J.; Yin, J.; Wang, R. Basic framework and main methods of uncertainty quantification. Math. Probl. Eng. 2020, 2020, 6068203. [Google Scholar] [CrossRef]
- Sullivan, T. Introduction to Uncertainty Quantification; Texts in Applied Mathematics; Springer International Publishing: Cham, Switzerland, 2015; Volume 63. [Google Scholar] [CrossRef]
- Iskandarani, M.; Wang, S.; Srinivasan, A.; Carlisle Thacker, W.; Winokur, J.; Knio, O.M. An overview of uncertainty quantification techniques with application to oceanic and oil-spill simulations. J. Geophys. Res. Ocean 2016, 121, 2789–2808. [Google Scholar] [CrossRef] [Green Version]
- Peckham, S.D.; Kelbert, A.; Hill, M.C.; Hutton, E.W. Towards uncertainty quantification and parameter estimation for Earth system models in a component-based modeling framework. Comput. Geosci. 2016, 90, 152–161. [Google Scholar] [CrossRef] [Green Version]
- Camporeale, E.; Shprits, Y.; Chandorkar, M.; Drozdov, A.; Wing, S. On the propagation of uncertainties in radiation belt simulations. Space Weather 2016, 14, 982–992. [Google Scholar] [CrossRef]
- Hibbert, D.B. The uncertainty of a result from a linear calibration. Analyst 2006, 131, 1273–1278. [Google Scholar] [CrossRef] [Green Version]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Cohen, S. Chapter 2 - The basics of machine learning: Strategies and techniques. In Artificial Intelligence and Deep Learning in Pathology; Cohen, S., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 13–40. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.; Botti, S.; Marques, M.A. Recent advances and applications of machine learning in solid-state materials science. NPJ Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Senel, O. Infill Location Determination and Assessment of Corresponding Uncertainty. Ph.D. Thesis, Texas A & M University, College Station, TX, USA, 2009. [Google Scholar]
- Song, T.; Ding, W.; Liu, H.; Wu, J.; Zhou, H.; Chu, J. Uncertainty quantification in machine learning modeling for multi-step time series forecasting: Example of recurrent neural networks in discharge simulations. Water 2020, 12, 912. [Google Scholar] [CrossRef] [Green Version]
- Jha, A.; Chandrasekaran, A.; Kim, C.; Ramprasad, R. Impact of dataset uncertainties on machine learning model predictions: The example of polymer glass transition temperatures. Model. Simul. Mater. Sci. Eng. 2019, 27, 024002. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Benoudjit, N.; Verleysen, M. On the kernel widths in radial-basis function networks. Neural Process. Lett. 2003, 18, 139–154. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Särkkä, S. Linear operators and stochastic partial differential equations in Gaussian process regression. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2011; pp. 151–158. [Google Scholar] [CrossRef]
- Griffiths, D.J. Introduction to Electrodynamics, 4th ed.; Pearson: Boston, MA, USA, 2013. [Google Scholar]
- Holden, H. (Ed.) Stochastic Partial Differential Equations: A Modeling, White Noise Functional Approach, 2nd ed.; Universitext: London, UK; Springer: New York, NY, USA, 2010. [Google Scholar]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Numerical Gaussian processes for time-dependent and nonlinear partial differential equations. SIAM J. Sci. Comput. 2018, 40, A172–A198. [Google Scholar] [CrossRef] [Green Version]
- Hennig, P.; Osborne, M.A.; Girolami, M. Probabilistic numerics and uncertainty in computations. Proc. R. Soc. A Math. Phys. Eng. Sci. 2015, 471, 20150142. [Google Scholar] [CrossRef] [Green Version]
- Cockayne, J.; Oates, C.; Sullivan, T.; Girolami, M. Probabilistic Meshless Methods for Partial Differential Equations and Bayesian Inverse Problems. arXiv 2016, arXiv:abs/1605.07811. [Google Scholar]
- Dondelinger, F.; Filippone, M.; Rogers, S.; Husmeier, D. ODE parameter inference using adaptive gradient matching with Gaussian processes. J. Mach. Learn. Res. 2013, 31, 216–228. [Google Scholar]
- Ashyraliyev, M.; Fomekong-Nanfack, Y.; Kaandorp, J.A.; Blom, J.G. Systems biology: Parameter estimation for biochemical models: Parameter estimation in systems biology. FEBS J. 2009, 276, 886–902. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girolami, M.; Calderhead, B. Riemann manifold Langevin and Hamiltonian Monte Carlo methods: Riemann Manifold Langevin and Hamiltonian Monte Carlo Methods. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 123–214. [Google Scholar] [CrossRef]
- Conrad, P.R.; Girolami, M.; Särkkä, S.; Stuart, A.; Zygalakis, K. Statistical analysis of differential equations: Introducing probability measures on numerical solutions. Stat. Comput. 2017, 27, 1065–1082. [Google Scholar] [CrossRef]
- Sevakula, R.K.; Au-Yeung, W.M.; Singh, J.P.; Heist, E.K.; Isselbacher, E.M.; Armoundas, A.A. State-of-the-Art Machine Learning Techniques Aiming to Improve Patient Outcomes Pertaining to the Cardiovascular System. J. Am. Heart Assoc. 2020, 9, e013924. [Google Scholar] [CrossRef]
- Pantoja, M.; Behrouzi, A.; Fabris, D. An introduction to deep learning. In Proceedings of the 2012 11th International Conference on Information Science, Signal Processing and their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2018. [Google Scholar]
- Guarascio, M.; Manco, G.; Ritacco, E. Deep Learning. In Encyclopedia of Bioinformatics and Computational Biology; Ranganathan, S., Gribskov, M., Nakai, K., Schönbach, C., Eds.; Academic Press: Oxford, UK, 2019; pp. 634–647. [Google Scholar] [CrossRef]
- Gamboa, J.C.B. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- McDermott, P.L.; Wikle, C.K. Bayesian Recurrent Neural Network Models for Forecasting and Quantifying Uncertainty in Spatial-Temporal Data. Entropy 2019, 21, 184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Sharma, V. Deep Learning Algorithms. Available online: https://www.datarobot.com/wiki/deep-learning/ (accessed on 20 November 2021).
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics Informed Deep Learning (Part II): Data-driven Discovery of Nonlinear Partial Differential Equations. 2017. Available online: http://xxx.lanl.gov/abs/1711.10566 (accessed on 20 November 2021).
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef]
- Salimans, T.; Kingma, D.; Welling, M. Markov chain monte carlo and variational inference: Bridging the gap. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1218–1226. [Google Scholar]
- Andrieu, C.; De Freitas, N.; Doucet, A.; Jordan, M.I. An introduction to MCMC for machine learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef] [Green Version]
- Liang, F.; Liu, C.; Carroll, R. Advanced Markov Chain Monte Carlo Methods: Learning from Past Samples; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 714. [Google Scholar]
- Camporeale, E.; Johnson, J.R.; Wing, S. (Eds.) Machine Learning Techniques for Space Weather; Elsevier: Amsterdam, The Netherlands; Cambridge, MA, USA, 2018. [Google Scholar]
- Piersanti, M.; Di Matteo, S.; Carter, B.A.; Currie, J.; D’Angelo, G. Geoelectric Field Evaluation during the September 2017 Geomagnetic Storm: MA.I.GIC. Model. Space Weather 2019, 17, 1241–1256. [Google Scholar] [CrossRef] [Green Version]
- Salman, T.M.; Lugaz, N.; Farrugia, C.J.; Winslow, R.M.; Galvin, A.B.; Schwadron, N.A. Forecasting Periods of Strong Southward Magnetic Field Following Interplanetary Shocks. Space Weather 2018, 16, 2004–2021. [Google Scholar] [CrossRef] [Green Version]
- Tsurutani, B.T.; Lakhina, G.S.; Hajra, R. The physics of space weather/solar-terrestrial physics (STP): What we know now and what the current and future challenges are. Nonlinear Process. Geophys. 2020, 27, 75–119. [Google Scholar] [CrossRef] [Green Version]
- Watari, S.; Nakamura, S.; Ebihara, Y. Measurement of geomagnetically induced current (GIC) around Tokyo, Japan. Earth Planets Space 2021, 73, 102. [Google Scholar] [CrossRef]
- de Villiers, J.S.; Kosch, M.; Yamazaki, Y.; Lotz, S. Influences of various magnetospheric and ionospheric current systems on geomagnetically induced currents around the world. Space Weather 2017, 15, 403–417. [Google Scholar] [CrossRef] [Green Version]
- Salman, T.M.; Lugaz, N.; Farrugia, C.J.; Winslow, R.M.; Jian, L.K.; Galvin, A.B. Properties of the Sheath Regions of Coronal Mass Ejections with or without Shocks from STEREO in situ Observations near 1 au. Astrophys. J. 2020, 904, 177. [Google Scholar] [CrossRef]
- Rajput, V.N.; Boteler, D.H.; Rana, N.; Saiyed, M.; Anjana, S.; Shah, M. Insight into impact of geomagnetically induced currents on power systems: Overview, challenges and mitigation. Electr. Power Syst. Res. 2021, 192, 106927. [Google Scholar] [CrossRef]
- Rao, J.; PhD, N.P.; Amariutei, O.; Syrjäsuo, M.; Van De Sande, K.E. Automatic auroral detection in color all-sky camera images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4717–4725. [Google Scholar] [CrossRef]
- Yang, Q.; Liang, J.; Hu, Z.; Zhao, H. Auroral sequence representation and classification using hidden markov models. IEEE Trans. Geosci. Remote Sens. 2012, 50, 5049–5060. [Google Scholar] [CrossRef]
- Kvammen, A.; Wickstrøm, K.; McKay, D.; Partamies, N. Auroral Image Classification With Deep Neural Networks. J. Geophys. Res. Space Phys. 2020, 125, e2020JA027808. [Google Scholar] [CrossRef]
- Yang, Q.; Zhou, P. Representation and Classification of Auroral Images Based on Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 523–534. [Google Scholar] [CrossRef]
- Gao, X.; Fu, R.; Li, X.; Tao, D.; Zhang, B.; Yang, H. Aurora image segmentation by combining patch and texture thresholding. Comput. Vis. Image Underst. 2011, 115, 390–402. [Google Scholar] [CrossRef]
- Yang, Q.; Tao, D.; Han, D.; Liang, J. Extracting Auroral Key Local Structures From All-Sky Auroral Images by Artificial Intelligence Technique. J. Geophys. Res. Space Phys. 2019, 124, 3512–3521. [Google Scholar] [CrossRef] [Green Version]
- Clausen, L.B.; Nickisch, H. Automatic Classification of Auroral Images From the Oslo Auroral THEMIS (OATH) Data Set Using Machine Learning. J. Geophys. Res. Space Phys. 2018, 123, 5640–5647. [Google Scholar] [CrossRef]
- Wintoft, P.; Wik, M.; Viljanen, A. Solar wind driven empirical forecast models of the time derivative of the ground magnetic field. J. Space Weather Space Clim. 2015, 5, A7. [Google Scholar] [CrossRef]
- Keesee, A.M.; Pinto, V.; Coughlan, M.; Lennox, C.; Mahmud, M.S.; Connor, H.K. Comparison of Deep Learning Techniques to Model Connections Between Solar Wind and Ground Magnetic Perturbations. Front. Astron. Space Sci. 2020, 7, 1–8. [Google Scholar] [CrossRef]
- Gjerloev, J.W. The SuperMAG data processing technique: TECHNIQUE. J. Geophys. Res. Space Phys. 2012, 117. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble Learning: Pattern Classification Using Ensemble Methods; World Scientific: Singapore, 2019. [Google Scholar]
- Tang, Y.; Wang, Y.; Cooper, K.M.; Li, L. Towards Big Data Bayesian Network Learning—An Ensemble Learning Based Approach. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June 2014; pp. 355–357. [Google Scholar] [CrossRef]
- Mavromichalaki, H.; Souvatzoglou, G.; Sarlanis, C.; Mariatos, G.; Plainaki, C.; Gerontidou, M.; Belov, A.; Eroshenko, E.; Yanke, V. Space weather prediction by cosmic rays. Adv. Space Res. 2006, 37, 1141–1147. [Google Scholar] [CrossRef]
- Kuwabara, T.; Bieber, J.W.; Clem, J.; Evenson, P.; Pyle, R.; Munakata, K.; Yasue, S.; Kato, C.; Akahane, S.; Koyama, M.; et al. Real-time cosmic ray monitoring system for space weather. Space Weather 2006, 4. [Google Scholar] [CrossRef]
- Erdmann, M.; Glombitza, J.; Walz, D. A deep learning-based reconstruction of cosmic ray-induced air showers. Astropart. Phys. 2018, 97, 46–53. [Google Scholar] [CrossRef]
- Tsai, Y.L.S.; Chung, Y.; Yuan, Q.; Cheung, K. Inverting cosmic ray propagation by Convolutional Neural Networks. arXiv 2020, arXiv:2011.11930. [Google Scholar]
- Jóhannesson, G.; de Austri, R.R.; Vincent, A.; Moskalenko, I.; Orlando, E.; Porter, T.; Strong, A.; Trotta, R.; Feroz, F.; Graff, P.; et al. Bayesian analysis of cosmic ray propagation: Evidence against homogeneous diffusion. Astrophys. J. 2016, 824, 16. [Google Scholar] [CrossRef]
- Smith, R.C. Uncertainty Quantification: Theory, Implementation, and Applications; Siam: Bangkok, Thailand, 2013. [Google Scholar]
- Knipp, D.J. Advances in Space Weather Ensemble Forecasting. Space Weather 2016, 14, 52–53. [Google Scholar] [CrossRef]
- Tóth, G.; van der Holst, B.; Sokolov, I.V.; De Zeeuw, D.L.; Gombosi, T.I.; Fang, F.; Manchester, W.B.; Meng, X.; Najib, D.; Powell, K.G.; et al. Adaptive numerical algorithms in space weather modeling. J. Comput. Phys. 2012, 231, 870–903. [Google Scholar] [CrossRef] [Green Version]
- Schunk, R.W.; Scherliess, L.; Eccles, V.; Gardner, L.C.; Sojka, J.J.; Zhu, L.; Pi, X.; Mannucci, A.J.; Butala, M.; Wilson, B.D.; et al. Space weather forecasting with a Multimodel Ensemble Prediction System (MEPS). Radio Sci. 2016, 51, 1157–1165. [Google Scholar] [CrossRef] [Green Version]
- Morley, S.K.; Welling, D.T.; Woodroffe, J.R. Perturbed Input Ensemble Modeling With the Space Weather Modeling Framework. Space Weather 2018, 16, 1330–1347. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Solving partial differential equations using deep learning and physical constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Shin, Y.; Darbon, J.; Karniadakis, G.E. On the convergence of physics informed neural networks for linear second-order elliptic and parabolic type PDEs. Commun. Comput. Phys. 2020, 28, 2042–2074. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature Citation | Implemented Model | Objective |
|---|---|---|
| [71] (2014) | Support Vector Machines (SVM); Used feature selection methods: Local Binary Pattern (LBP) and Scale Invariant Feature Transform (SIFT) | Auroral image classification into 3 labels |
| [72] (2012) | Hidden Markov Model (HMM) | Auroral image classification into 4 categories; Used Sequences of Auroral images to capture temporal properties |
| [74] (2020) | Three Convolutional Neural (CNN) Network Variants, AlexNet, VGG-16, and Inception-v4 | Auroral image classification, into 4 labels |
| [76] (2019) | Cycle-consistent Adversarial Network (CAN) | Classify auroral images by extracting Key Local Structures (KLS) |
| [77] (2018) | Pre-trained Deep Neural Network for feature extraction; Ridge classifier for classification | Nightside Auroral image classification into 6 labels |
| [73] (2020) | Variants of Deep Neural Network Architectures: VGG, AlexNet, and ResNet | Nightside Auroral image classification into 7 labels |
| [9] (2020) | Hybrid model: Uses Wavelet Transforms (WT) and Short-Time Fourier Transform (STFT) for feature extraction, along with Convolutional Neural Network (CNN) | Detect GIC |
| [78] (2015) | Elman Neural Network | Predict the 30 min maximum perturbation of the horizontal magnetic component |
| [79] (2020) | Two separate models: feed-forward NN and Long-Short Term Memory (LSTM) Neural Network | Predict the East and North component of the geomagnetic field, which, in turn, was used to derive the change in horizontal component |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siddique, T.; Mahmud, M.S.; Keesee, A.M.; Ngwira, C.M.; Connor, H. A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction. Geosciences 2022, 12, 27. https://doi.org/10.3390/geosciences12010027
Siddique T, Mahmud MS, Keesee AM, Ngwira CM, Connor H. A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction. Geosciences. 2022; 12(1):27. https://doi.org/10.3390/geosciences12010027
Chicago/Turabian StyleSiddique, Talha, Md Shaad Mahmud, Amy M. Keesee, Chigomezyo M. Ngwira, and Hyunju Connor. 2022. "A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction" Geosciences 12, no. 1: 27. https://doi.org/10.3390/geosciences12010027
APA StyleSiddique, T., Mahmud, M. S., Keesee, A. M., Ngwira, C. M., & Connor, H. (2022). A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction. Geosciences, 12(1), 27. https://doi.org/10.3390/geosciences12010027