


Algorithmic Geology: Tackling Methodological Challenges in Applying Machine Learning to Rock Engineering



Abstract
:1. Introduction
Key Definitions
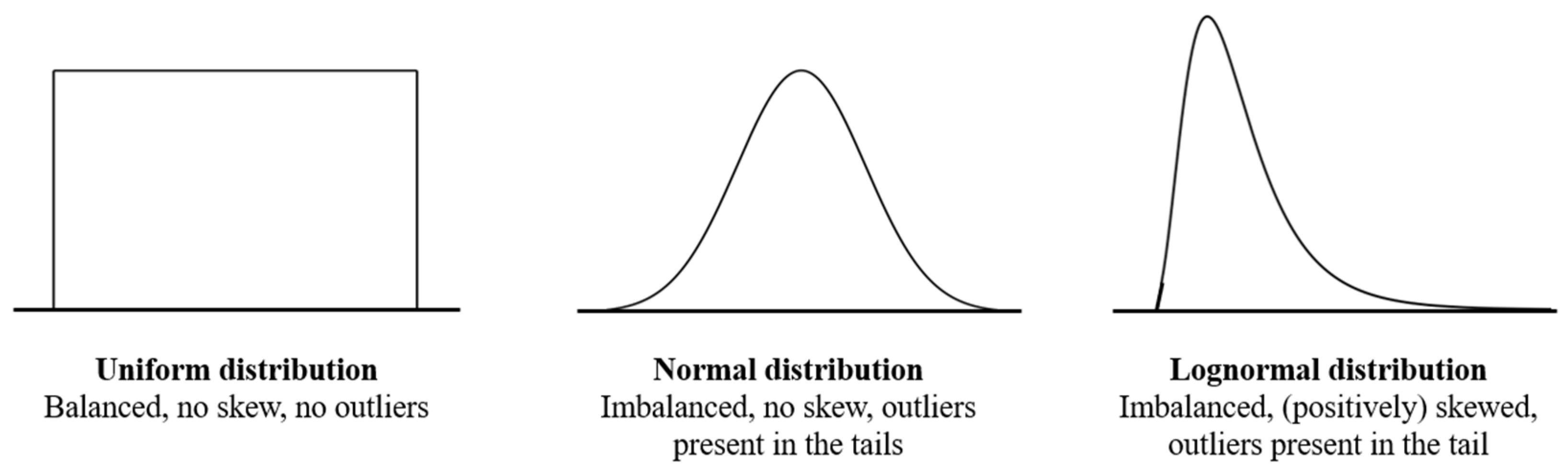
- Imbalanced data: the distribution of classes or bins is not equal [2]. Note that if a continuous variable is binned, the resulting distribution can be imbalanced, although the severity of the imbalance would depend on the bin width chosen.
- Skewed data or distribution: a distribution of data points in a dataset that is not symmetric around the dataset’s mean [3].
- Outliers: broadly defined as data points that differ significantly from other observations (e.g., data points found in the tail of a distribution). However, there is no set mathematical or statistical definition of what constitutes an outlier [4].
- Training and test data: as part of the machine learning workflow, the dataset is split into its training and test data (referred to as the train/test split in this paper). The ML model is first trained on the training data, then the trained model is evaluated on the test data to better understand how well the model will perform on data it has not seen before. The dataset is often randomly shuffled before its train/test split to ensure that the training and test data have the same distribution. The train/test split serves to evaluate the ability of a machine learning model to perform effectively on new and unseen data. Additionally, this practice helps us to identify and reduce the risk of overfitting, a scenario in which a model excels in accurately predicting outcomes based on the training data but struggles to generalize its predictions to new instances (see below).
- Validation data: the training dataset is split into training and validation data. The model is trained on the training data and then refined or tuned on the validation data before being evaluated on the test data. Including a validation dataset provides a more robust method of evaluating the model performance. When working with smaller datasets, a single train/validation split may misrepresent the test data, so it is often recommended that cross-validation be performed. In cross-validation, the training set is divided into k number of folds (five and ten folds are commonly used) and each fold takes a turn at being the validation set. A validation score is determined for each fold, and the scores for all folds are then averaged to determine an average validation score [1].
- Overfitting: the ML model cannot generalize well as it is too complex and fits to the noise in the data. Overfitting can be identified when the model performs significantly better on the training data than the test data and commonly occurs in smaller datasets [5].
2. Data Quality Issues
3. Data Quantity Issues
3.1. Methodology
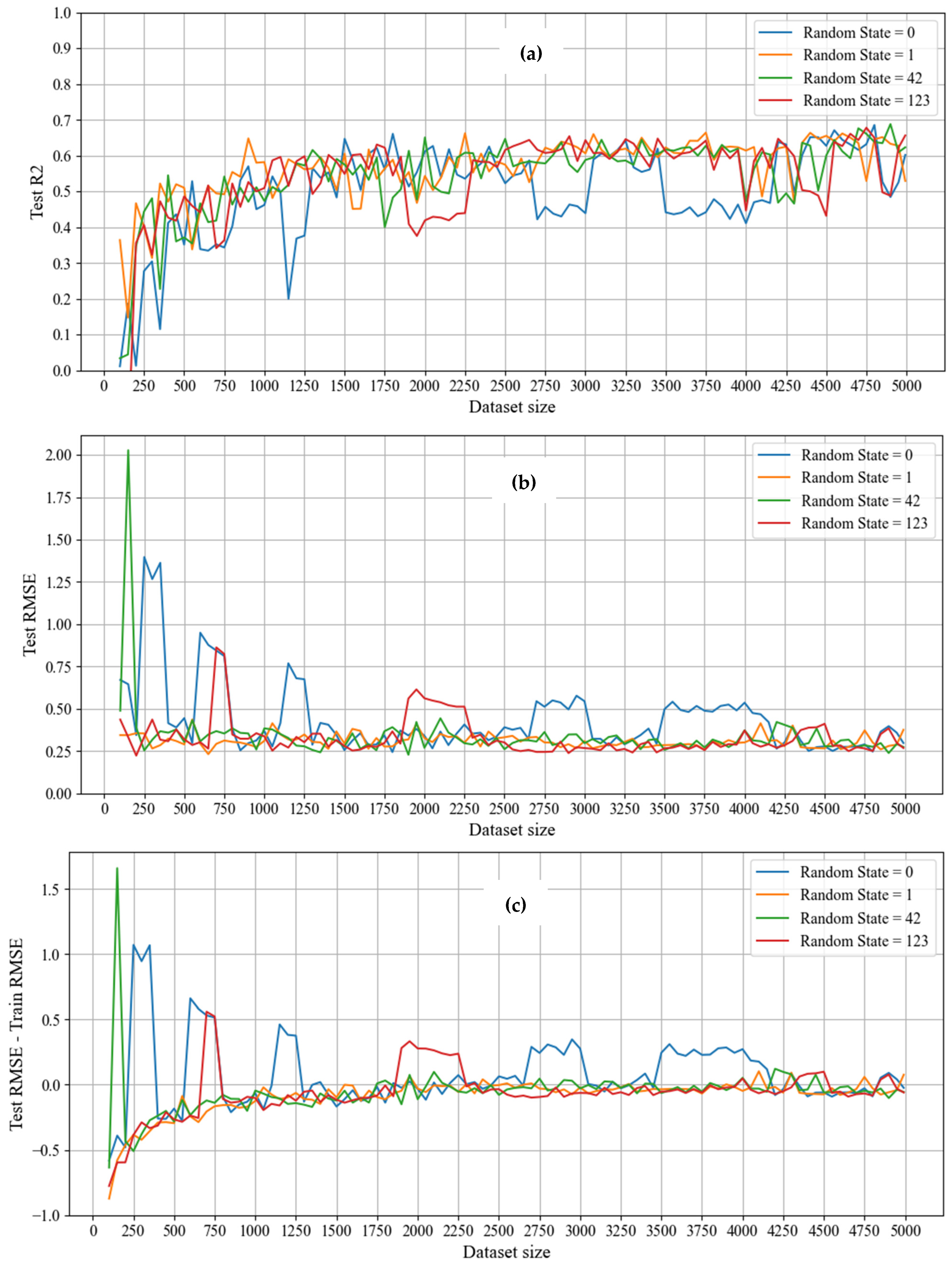
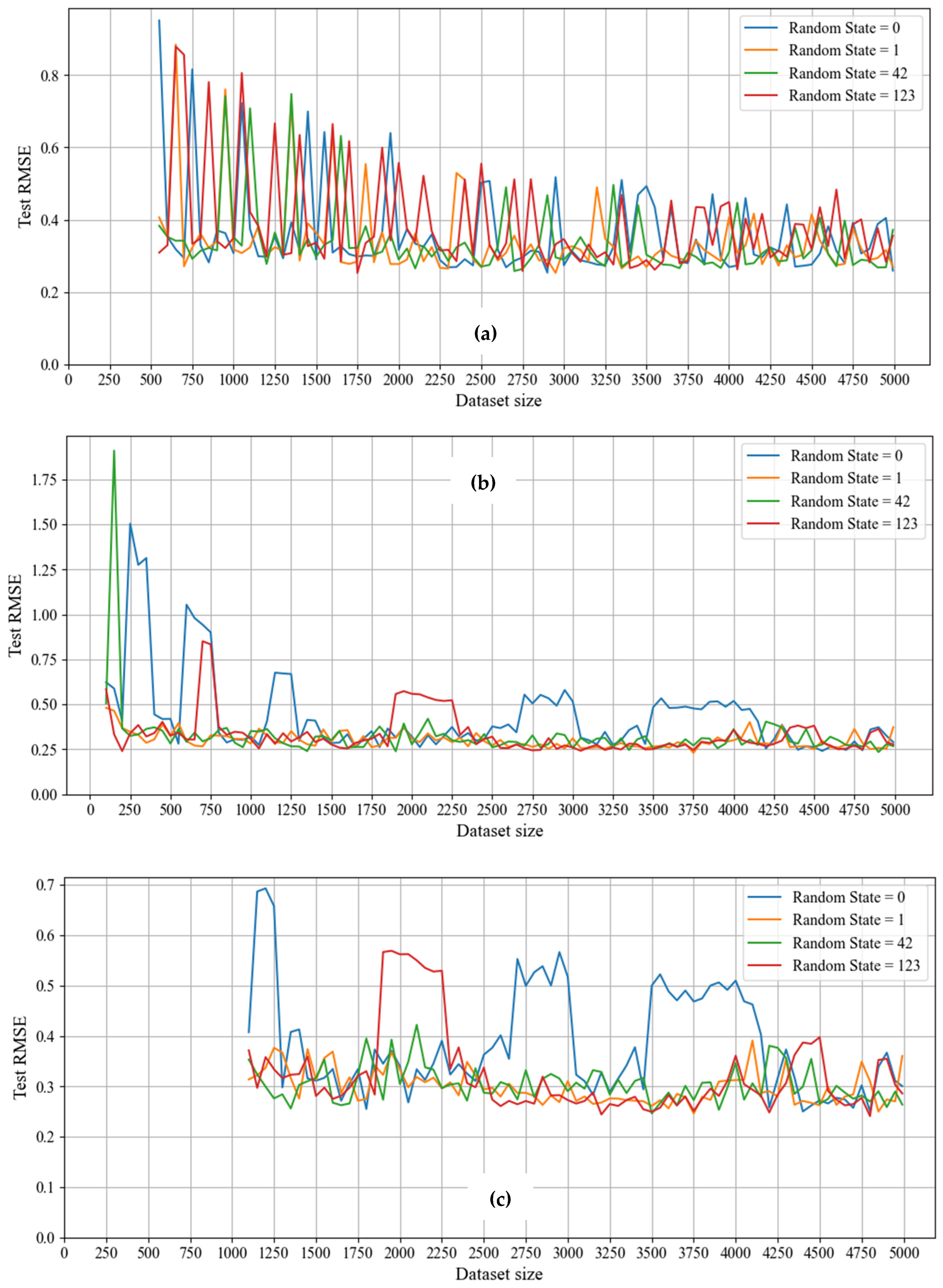
3.2. Data Visualization
3.3. Results
3.4. Skewed and Imbalanced Data
3.5. Limitations
4. Knowledge Issues
5. Conclusions and Recommendations
- Understanding the methodological issues at play.
- Visualizing the data and performing exploratory data analysis to gain a better understanding of the data.
- Starting simple and increasing the complexity of your model as needed. Increasing the complexity of the model does not necessarily improve the model and is computationally intensive.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

| Reference | Application | Dataset Size | Results | Data and Code Availability | Concerns |
|---|---|---|---|---|---|
| [29] | Used support vector machine and back-propagation neural network to predict basic rock quality (BQ) class from inputs, including JRC, volumetric joint count (Jv), groundwater condition, etc. | 25 data points (20 for training, 5 for test). Also included a separate dataset of 20 data points to “verify” the accuracy of their model. | Accuracy on the 20 data points to “verify” the accuracy of their model is 95%. | The dataset is not available. The code is not available. | Small and imbalanced dataset (BQ class ranges from 3–5, with the majority being 4). The data is limited to Anhui province in China. The ML model is redundant, as many of the input features are used in the equations to calculate BQ class. The training and test accuracy are not reported. |
| [30] | Used naïve Bayes, random forest, artificial neural network, and support vector machine to predict the rock mass rating (RMR) rock mass class from the RMR ratings for intact rock strength, discontinuity spacing, weathering, persistence, aperture, and presence of water. The inputs were label encoded. | 3216 data points (2144 training, 1072 test). The authors performed their own version of cross-validation, where the model was trained 30 times on a different train/test split and the model performance for each split was averaged. | Average test accuracy ranges from 0.81–0.89 for all models. | The dataset is available. The code is not available. | The authors did not make it clear which RMR version was used (RMR89 was assumed). The authors’ version of cross-validation could result in data leakage (where the test data influence the training of the model). The training results were not reported. The models are redundant, as the model inputs make up 68% of RMR89, however, it is possible to estimate the RQD rating from the discontinuity spacing rating since the two parameters are linked, meaning that there is enough information to estimate the RMR class without the use of ML. |
| [12] | Used support vector machine (SVM), decision trees (DT), random forest (RF), Gaussian process regression (GPR), and ensemble learning (EL) using the previous 4 models to predict the end-bearing capacity of rock-socketed shafts from the unconfined compressive strength of intact rock, geological strength index (GSI), length of shaft within the soil layer, length of shaft within the rock layer, and shaft diameter. | 151 data points (121 training, 30 test points). | SVM: training R2 of 0.56, test R2 of 0.55, training RMSE of 2.13, test RMSE of 2.33. DT: training R2 of 0.80, test R2 of 0.85, training RMSE of 1.38, test RMSE of 1.21. RF: training R2 of 0.82, test R2 of 0.87, training RMSE of 1.38, test RMSE of 1.42. GPR: training R2 of 0.79, test R2 of 0.83, training RMSE of 1.50, test RMSE or 1.54. EL: training R2 of 0.84, test R2 of 0.89, training RMSE of 1.39, test RMSE of 1.17. | The dataset is available but contains 138 data points instead of 151. The code is available upon request. | The dataset is small and some of the models perform better on the test dataset than the training dataset. Refer to Section 3 for additional details. |
| [13] | Used relevance vector regression (RVR) and support vector regression (SVR) to predict RMR values from seismic velocity (Vp and Vs), seismic wave type, orientation, polarity, wave magnitude, and reflection depth. | 132 data points (92 training, 40 test). No validation or cross-validation was performed. | RVR: training R of 0.99, test R of 0.94, training RMSE of 1.4, test RMSE of 4.3. SVR: training R of 0.995, test R of 0.96, training RMSE of 1.1, test RMSE of 3.6. | The dataset and code are not available. | The dataset is small and limited—the test RMR values are concentrated between 0 and 20 and 60–85. The data is also based on two case studies in Iran. The RMR version was not specified by the authors. |
| [26] | Used classification and regression tree (CART) as well as genetic programming (GP) to predict tunnel boring machine (TBM) performance (FPI—field penetration index) from uniaxial compressive strength (UCS), rock quality designation (RQD, joint spacing, partial joint condition rating in RMR89, and rock type code. | 580 data points from 7 tunneling projects (4 from Iran, 1 from New Zealand, 1 from India, 1 from Switzerland; 35% metamorphic, 37% igneous, 28% sedimentary). A train/test split was not performed (to the best of my knowledge). | CART: entire dataset R2 of 0.91, entire dataset of RMSE 6.67. GP: entire dataset R2 of 0.85, entire dataset RMSE of 8.46. | The dataset and code are not available. | A train/test split was not performed (i.e., the model results are for the entire dataset), making it difficult to determine how well the models will generalize (which is the end goal of ML). The authors did not explain what a partial joint condition rating from RMR89 meant. |
| [31] | Used k-nearest neighbors (kNN), naïve Bayes (NB), random forest (RF), artificial neural network (ANN), and support vector machine (SVM) to predict rock compressive strength from acoustic characteristics stemming from hitting the core with a geological hammer (amplitude attenuation coefficient (AAC) and high and low frequency ratio (HLFR)). | 2104 data points (1614 training, 400 test). | kNN: training R2 of 0.98, test R2 of 0.98, training RMSE of 0.6, test RMSE of 0.6. NB: training R2 of 0.88, test R2 of 0.88, training RMSE of 3.84, test RMSE of 3.94. RF: training R2 of 0.98, test R2 of 9.07, training RMSE of 1.1, test RMSE of 1.8. ANN: training R2 of 0.99, test R2 of 0.99, training RMSE of 0.3, test RMSE of 0.3. SVM: training R2 of 0.99, test R2 of 0.99, training RMSE of 0.08, test RMSE of 0.1. | The dataset and code are not available. | AAC and HLFR showed good correlation with rock compressive strength without the use of ML (R2 of 0.91 for AAC and R2 of 0.93 for HLFR), putting into question the practicality of using ML for this application. |
| [32] | Used random forest to predict Is50 classes from fracture frequency, RQD, mineralized veins per meter, rock density, intact rock strength hammer test class, alteration strength index, mineralization strength index, mineralization percent sum, fracture spacing, fracture frequency index, discontinuity frequency index, discontinuity frequency index weighted by orientation, joint set index, rock colour, lower contact, rock texture, rock type, selvage mineralization, mineral metric, rock structure, rock fabric, PLT machine ID. | 7687 data points. The authors performed their own version of cross-validation, where their model was trained on all boreholes except for one, and then tested on the remaining borehole. This was repeated until all boreholes had been used as the ”test dataset”, and the score for each borehole was averaged. | The average accuracy of the boreholes is 39%. | The dataset and code are not available. | The authors’ version of cross-validation could result in data leakage (where the test data influences the training of the model). The training results were not reported. Some of the input features are correlated with one another (ex; fracture frequency and fracture frequency index). The reported accuracy is low and does not represent the true “test” accuracy (which should be lower than the reported 39%). |
| [33] | Used stacked autoencoders (SAEs—a type of deep learning) to predict RMR rock mass class from its input parameters (UCS, RQD, spacing, persistence, aperture, roughness, infilling, weathering, groundwater, and orientation). The rating classes of each input parameter was one-hot binary encoded (ex; the UCS rating class for UCS > 250 MPa was transformed into 1000000, while the UCS rating class for UCS between 100 and 250 MPa was transformed into 0100000, etc.) | 309 data points (232 training, 77 test). | The train and test accuracy are both 100%. | The dataset and code are not available. | The dataset is small, especially for a neural network. The model is redundant as it uses the inputs of RMR to determine RMR, which can be done (and is done) easily without ML in Excel. The authors also did not specify which RMR version was used (RMR89 was assumed). The authors also misused the word calibration, as they referred to one-hot encoding the input features as “calibration”, despite it being a form of data preparation. |
| [34] | Used ANN to predict RMR values from its input parameters (strength, spacing, RQD, joint conditions, and groundwater). | The dataset size is unclear. | The MAPE was less than 1%. It was unclear if this was for the training or test set. | The dataset and code are not available. | The dataset size is unclear, and it is unclear if the model performance is for the training or test set. The model is redundant as it uses the inputs of RMR to determine RMR, which can be done (and is done) easily without ML in Excel. The authors also did not specify which RMR version was used (RMR89 was assumed). |
| [18] | Used Gaussian process regression (GPR), support vector regression (SVR), decision tree (DT), and long short-term memory (LSTM—a type of neural network) to predict cohesion and friction angle of sandstone from uniaxial compressive strength, uniaxial tensile strength, and confining stress. | 233 data points from RockData (195 training, 49 test). The authors performed a 5-fold cross-validation. | For cohesion, the R2 of all of the models ranged from 0.95 to 0.98, while the RMSE ranged from 1.3 to 2.38. For friction angle, the R2 of all the models ranged from 0.6 to 0.85, while the RMSE ranged from 1.86 to 9.88. It was unclear if this was for the training set, test set, or entire dataset. | The dataset is available in RockData. The code is not available. | The dataset size is small, especially for LSTM, and limited to only sandstone. It is unclear if the model performance values are for the training set, test set, or entire dataset, making it difficult, if not impossible, to determine how well the model generalizes. |
| [35] | Used convolutional neural networks (CNN) to predict RQD from core photos. | 124 images (99 training images, 25 test images). | Average test error of 3.24%. RQD for training was determined by two experienced engineers. | The dataset is available upon request. The code is available. | The dataset is small, especially for a CNN. The model has issues differentiating between natural and mechanical fractures. The hard and soundness requirement was not mentioned in the paper. |
| [15] | Used convolutional neural networks (CNN) to predict RQD from core photos. | 7030 images (6400 training images, 630 test images). The training images were of sandstone, while the test images contained 540 sandstone images and 90 limestone images. | Test error for sandstone is 2.58%, while the test error for limestone is 3.17%. | The dataset is not available. The code is available. | The model does not differentiate between natural vs. mechanical fractures and the hard and soundness requirement is not mentioned. The model is limited to sandstone and limestone. |
| [23] | Used artificial neural networks to predict intact rock elastic modulus from uniaxial compressive strength and the unit weight of the rock. | 609 data points (487 training, 122 test). | Training and test results are unclear. | The dataset and code are not available. | The training and test results are unclear. |
| [20] | Used support vector machines with heuristic optimization algorithms (for hyperparameter tuning) to predict the rock mass grade (based on a scale of 1 to 5 using qualitative descriptions) from saturated rock compressive strength, RQD, rock mass integrity factor, and water inflow. | 80 data points from China (64 training, 16 test). The data is available. | Training accuracy of 91% and test accuracy of 94%. | The dataset is available. The code is not available. | The dataset is very small, and the model performs better on the test dataset than the training dataset (despite its limited dataset size). |
| [36] | Used support vector regression to predict the modulus of deformation from the dynamic modulus of elasticity, uniaxial compressive strength, RQD, joint conditions, and joint spacing. | 88 data points. The authors only performed cross-validation on the entire dataset. There is no test dataset. | Cross-validation results for the SVR include R2 of 0.87 and RMSE of 1.01. | The dataset and code are not available. | The authors did not explain how the joint condition parameter was determined. The dataset is small and limited to one site. The results of cross-validation cannot be used to determine how well the model will perform on new, unseen data. A test dataset is missing. |
| [17] | Used k-nearest neighbor (kNN), random forest (RF), multi-layer perceptron (MLP), random tree (RT), and stacked RT-RF-kNN-MLP to predict Young’s modulus (modulus of elasticity) from porosity, Schmidt hammer rebound number, pulse velocity, and Is50. | 92 data points. Performed a sensitivity analysis for each model using different percentages of training data (80%, 85%, and 90% of the entire dataset). | For an 80/20 train/test split: RT: training R2 of 0.84, test R2 of 0.67, training RMSE of 14.92, test RMSE of 20.47. kNN: training R2 of 0.82, test R2 of 0.78, training RMSE of 15.81, test RMSE of 17.02. RF: training R2 of 0.84, test R2 of 0.71, training RMSE of 14.80, test RMSE of 19.04. MLP: training R2 of 0.90, test R2 of 0.77, training RMSE of 11.78, test RMSE of 16.97. Stacked: training R2 of 0.83, test R2 of 0.82, training RMSE of 15, test RMSE of 15.01. | The dataset and code are not available. | The dataset is small. Each input already shows a strong linear correlation with the output. |
| [37] | Used support vector machine (SVM), k-nearest neighbor (kNN), random forest (RF), gradient boosting decision tree (GBDT), decision tree (DT), logistic regression (LR), multi-layer perceptron (MLP), and a stacking ensemble classifier to predict rock mass class (on a scale of 1 to 5) from 10 TBM operational parameters (cutterhead rotational speed, pitch angle of gripper shoes, gear sealing pressure, pressure of gripper shoes, output frequency of main drive motor, internal pump pressure, penetration rate, control pump pressure, torque penetration index, and roll position of gripper shoes). | 7538 data points (6784 training, 754 test). A 10-fold cross-validation was performed. | SVM: test accuracy of 89%, test F1 of 0.89. kNN: test accuracy of 88%, test F1 of 0.87. RF: test accuracy of 91%, test F1 of 0.90. GBDT: test accuracy of 92%, test F1 of 0.92. DT: test accuracy of 87%, test F1 of 0.87. LR: test accuracy of 79%, test F1 of 0.75. MLP: test accuracy of 81%, test F1 of 0.80. Stacked ensemble classifier: test accuracy of 93%, test F1 of 0.93. | The dataset and code are not available. | Training results were not provided. |
| [38] | Used a back-propagation neural network to predict the rock mass deformation modulus from the uniaxial compressive strength of intact rock, RQD, dry density, porosity, number of joints per meter, and GSI. A genetic algorithm was used to optimize the neural network. | 120 data points. The amount of data in the training and test datasets was not clear. Data are limited to four sites in Iran and consist predominantly of sedimentary rocks. | Training R of 0.981, test R of 0.4. Training MSE of 3.16, test MSE of 5.21. | The dataset and code are not available. | The dataset size is small, especially for a neural network, and limited to sedimentary rocks. The size of the training and test datasets were not mentioned. The authors did not mention how the rock mass deformation modulus values were determined and how reliable these values are, despite mentioning that the credibility of the results of in situ tests are questionable. |
Appendix B












References
- Yang, B.; Tsai, A.; Mitelman, A.; Tsai, R.; Elmo, D. The importance of data quantity in machine learning—How small is too small? In Proceedings of the GeoSaskatoon 2023, Saskatoon, SK, Canada, 1–4 October 2023. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Measures of skewness and kurtosis. In Engineering Statistics Handbook; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012. [Google Scholar]
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1974.
- What Is Overfitting? Available online: https://www.ibm.com/topics/overfitting (accessed on 1 December 2023).
- Debrusk, C. The risk of machine learning bias (and how to prevent it). MIT Sloan Manag. Rev. 2018, 15, 1. [Google Scholar]
- Manyika, J.; Silberg, J.; Presten, B. What do we do about the biases in AI? Harv. Bus. Rev. 2019. [Google Scholar]
- Pells, P.J.; Bieniawski, Z.T.; Hencher, S.R.; Pells, S.E. Rock quality designation (RQD): Time to rest in peace. Can. Geotech. J. 2017, 54, 825–834. [Google Scholar] [CrossRef]
- Elmo, D.; Stead, D. The role of behavioural factors and cognitive biases in rock engineering. Rock Mech. Rock Eng. 2021, 54, 2109–2128. [Google Scholar] [CrossRef]
- Yang, B.; Mitelman, A.; Elmo, D.; Stead, D. Why the future of rock mass classification systems requires revisiting their empirical past. Q. J. Eng. Geol. Hydrogeol. 2022, 55, qjegh2021-039. [Google Scholar] [CrossRef]
- Yang, B.; Elmo, D. Why engineers should not attempt to quantify GSI. Geosciences 2022, 12, 417. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, L. A machine learning-based method for predicting end-bearing capacity of rock-socketed shafts. Rock Mech. Rock Eng. 2022, 55, 1743–1757. [Google Scholar] [CrossRef]
- Gholami, R.; Rasouli, V.; Alimoradi, A. Improved RMR rock mass classification using artificial intelligence algorithms. Rock Mech. Rock Eng. 2013, 46, 1199–1209. [Google Scholar] [CrossRef]
- Rechlin, A.J.; Luth, S.; Giese, R. Rock mass classification based on seismic measurements using support vector machines. In Proceedings of the 12th ISRM Congress, Beijing, China, 18–21 October 2011. [Google Scholar]
- Alzubaidi, F.; Mostaghimi, P.; Si, G.; Swietojanski, P.; Armstrong, R.T. Automated rock quality designation using convolutional neural networks. Rock Mech. Rock Eng. 2022, 55, 3719–3734. [Google Scholar] [CrossRef]
- Shen, J.; Jimenez, R. Predicting the shear strength parameters of sandstone using genetic programming. Bull. Eng. Geol. Environ. 2018, 77, 1647–1662. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Asteris, P.G.; Mohammed, A.S.; Alexakis, D.E.; Mamou, A.; Armaghani, D.J. Introducing stacking machine learning approaches for the prediction of rock deformation. Transp. Geotech. 2022, 34, 100756. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A.; Mohammadi, M.; Salim, S.G.; Ali, H.F.H.; Ibrahim, H.H.; Abdulhamid, S.N.; Nejati, H.R.; Rashidi, S. Machine learning techniques to predict rock strength parameters. Rock Mech. Rock Eng. 2022, 55, 1721–1741. [Google Scholar] [CrossRef]
- Fathipour-Azar, H. Shear strength criterion for rock discontinuities: A comparative study of regression approaches. Rock Mech. Rock Eng. 2023, 56, 4715–4725. [Google Scholar] [CrossRef]
- Hu, J.; Zhou, T.; Ma, S.; Yang, D.; Guo, M.; Huang, P. Rock mass classification prediction model using heuristic algorithms and support vector machines: A case study of Chambishi copper mine. Sci. Rep. 2022, 12, 928. [Google Scholar] [CrossRef]
- Rocscience. SWedge—Surface Wedge Analysis of Slopes. 2023. Available online: https://www.rocscience.com/software/swedge (accessed on 1 December 2023).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artifical Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sonmez, H.; Gokceoglu, C.; Nefeslioglu, H.A.; Kayabasi, A. Estimation of rock modulus: For intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int. J. Rock Mech. Min. Sci. 2006, 43, 224–235. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Asteris, P.G.; Armaghani, D.J.; Tahir, M.M. Supervised machine learning techniques to the prediction of tunnel boring machine penetration rate. Appl. Sci. 2019, 19, 3715. [Google Scholar] [CrossRef]
- Rossbach, P. Neural Networks vs Random Forests—Does It Always Have to Be Deep Learning? 2018. Available online: https://blog.frankfurt-school.de/neural-networks-vs-random-forests-does-it-always-have-to-be-deep-learning/ (accessed on 1 December 2023).
- Salimi, A.; Rostami, J.; Moormann, C. Application of rock mass classification systems for performance estimation of rock TBMs using regression tree and artificial intelligence algorithms. Tunneling Undergr. Space Technol. 2019, 92, 103046. [Google Scholar] [CrossRef]
- Lin, Y.; Zhou, K.; Li, J. Application of cloud model in rock burst prediction and performance comparison with three machine learning algorithms. IEEE Access 2018, 6, 30958–30968. [Google Scholar] [CrossRef]
- Elmo, D.; Mitelman, A.; Yang, B. Examining rock engineering knowledge through a philosophical lens. Geosciences 2022, 12, 174. [Google Scholar] [CrossRef]
- Liu, K.; Liu, B.; Fang, Y. An intelligent model based on statistical learning theory for engineering rock mass classification. Bull. Eng. Geol. Environ. 2018, 78, 4533–4548. [Google Scholar] [CrossRef]
- Santos, A.E.M.; Lana, M.S.; Pereira, T.M. Evaluation of machine learning methods for rock mass classification. Neural Comput. Appl. 2021, 34, 4633–4642. [Google Scholar] [CrossRef]
- Ren, Q.; Wang, G.; Li, M.; Han, S. Prediction of rock compressive strength using machine learning algorithms based on spectrum analysis of geological hammer. Geotech. Geol. Eng. 2018, 37, 475–489. [Google Scholar] [CrossRef]
- Thielsen, C.; Furtney, J.K.; Valencia, M.E.; Pierce, M.; Orrego, C.; Stonestreet, P.; Tennant, D. Application of machine learning to the estimation of intact rock strength from core logging data: A case study at the Newcrest Cadia East Mine. In Proceedings of the 56th US Rock Mechanics/Geomechanics Symposium, Santa Fe, NM, USA, 26–29 June 2022. [Google Scholar]
- Sheng, D.; Yum, J.; Tan, F.; Tong, D.; Yan, T.; Lv, J. Rock mass quality classification based on deep learning: A feasibility study for stacked autoencoders. J. Rock Mech. Geotech. Eng. 2023, 15, 1749–1758. [Google Scholar] [CrossRef]
- Brousset, J.; Pehovaz, H.; Quispe, G.; Raymundo, C.; Moguerza, J.M. Rock mass classification method applying neural networks to minimize geotechnical characterization in underground Peruvian mines. Energy Rep. 2023, 9, 376–386. [Google Scholar] [CrossRef]
- Su, R.; Zhao, Q.; Zheng, T.; Han, G.; Jiang, J.; Hu, J. A framework for RQD calculation based on deep learning. Min. Metall. Explor. 2023, 40, 1567–1583. [Google Scholar] [CrossRef]
- Meybodi, E.E.; DastBaravarde, A.; Hussain, S.K.; Karimdost, S. Machine-learning method applied to provide the best predictive model for rock mass deformability modulus. Environ. Earth Sci. 2023, 82, 149. [Google Scholar] [CrossRef]
- Hou, S.; Liu, Y.; Yang, Q. Real-time prediction of rock mass classification based on TBM operation big data and stacking technique of ensemble learning. J. Rock Mech. Geotech. Eng. 2022, 14, 123–143. [Google Scholar] [CrossRef]
- Majdi, A.; Beiki, M. Evolving neural network using a genetic algorithm for predicting the deformation modulus of rock masses. Int. J. Rock Mech. Min. Sci. 2010, 47, 246–253. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



| Performance Metric | Random_State 1 = 0 | Random_State = 1 | Random_State = 42 | Random_State = 123 |
|---|---|---|---|---|
| Test R2 | 0.33 | 0.49 | 0.54 | −4.26 |
| Test RMSE | 1.35 | 0.33 | 0.23 | 1.00 |
| Hyperparameter Tuning | Performance Metric | Random_State = 0 | Random_State = 1 | Random_State = 42 | Random_State = 123 |
|---|---|---|---|---|---|
| None | Test R2 | 0.19 | 0.39 | 0.55 | 0.50 |
| Test RMSE | 1.97 | 2.02 | 2.34 | 2.35 | |
| RandomizedSearchCV | Test R2 | 0.35 | 0.39 | 0.44 | 0.5 |
| Test RMSE | 1.77 | 2.02 | 2.61 | 2.34 | |
| BayesSearchCV | Test R2 | 0.35 | 0.40 | 0.49 | 0.59 |
| Test RMSE | 1.77 | 2.01 | 2.49 | 2.13 |
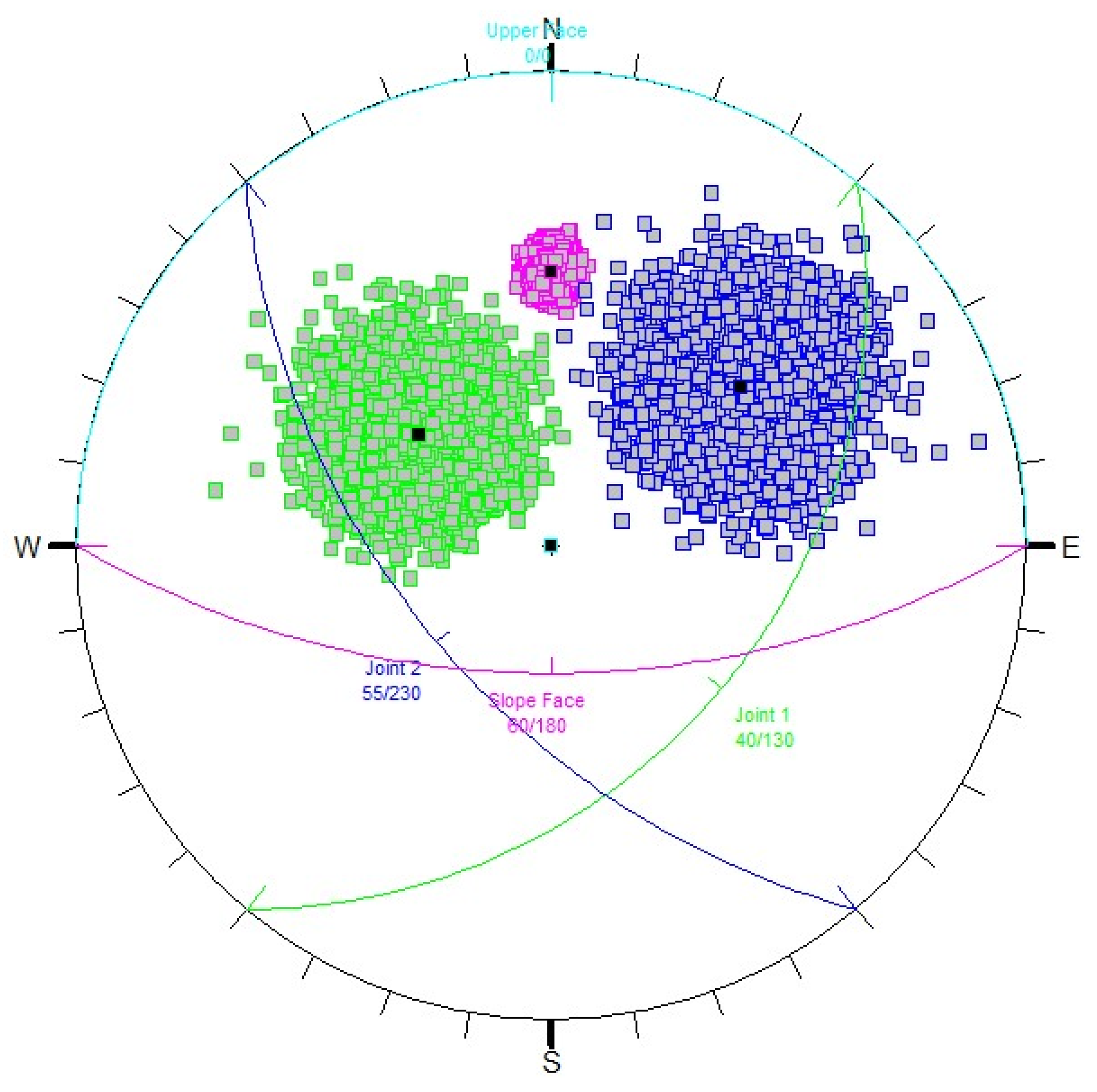
| Input Parameter | Mean | Min | Max | Standard Deviation | Distribution | |
|---|---|---|---|---|---|---|
| Slope | Dip (°) | 60 | 50 | 70 | 2 | Normal |
| Dip direction (°) | 180 | 170 | 190 | 2 | Normal | |
| Joint 1 | Dip (°) | 40 | - | - | - | Fisher K = 40 |
| Dip direction (°) | 130 | - | - | - | ||
| Joint 2 | Dip (°) | 55 | - | - | - | Fisher K = 40 |
| Dip direction (°) | 230 | - | - | - | ||
| Joint 1 | Cohesion (MPa) | 0 | - | - | - | - |
| Friction angle (°) | 30 | 20 | 40 | 2 | Normal | |
| Joint 2 | Cohesion (MPa) | 0 | - | - | - | - |
| kNNRegressor | MLPRegressor | ||
|---|---|---|---|
| Model 1a | Standardization | Model 1b | Standardization |
| Model 2a | Standardization, PCA | Model 2b | Standardization, PCA |
| Model 3a | Standardization, hyperparameter tuning with 5-fold cross-validation | Model 3b | Standardization, hyperparameter tuning with 5-fold cross-validation |
| Model 4a | Standardization, stratified sampling | Model 4b | Standardization, stratified sampling |
| Model 5 | Standardization, ln transformation | ||
| kNNClassifier | MLPClassifier | ||
|---|---|---|---|
| Model 6a | Standardization | Model 6b | Standardization |
| Model 7a | Standardization, PCA | Model 7b | Standardization, PCA |
| Model 8a | Standardization, hyperparameter tuning with 5-fold cross-validation | Model 8b | Standardization, hyperparameter tuning with 5-fold cross-validation |
| Model 9a | Standardization, stratified sampling | Model 9b | Standardization, stratified sampling |
| Model 10a | Standardization, oversampling | Model 10b | Standardization, oversampling |
| Model 11a | Standardization, SMOTE | Model 11b | Standardization, SMOTE |
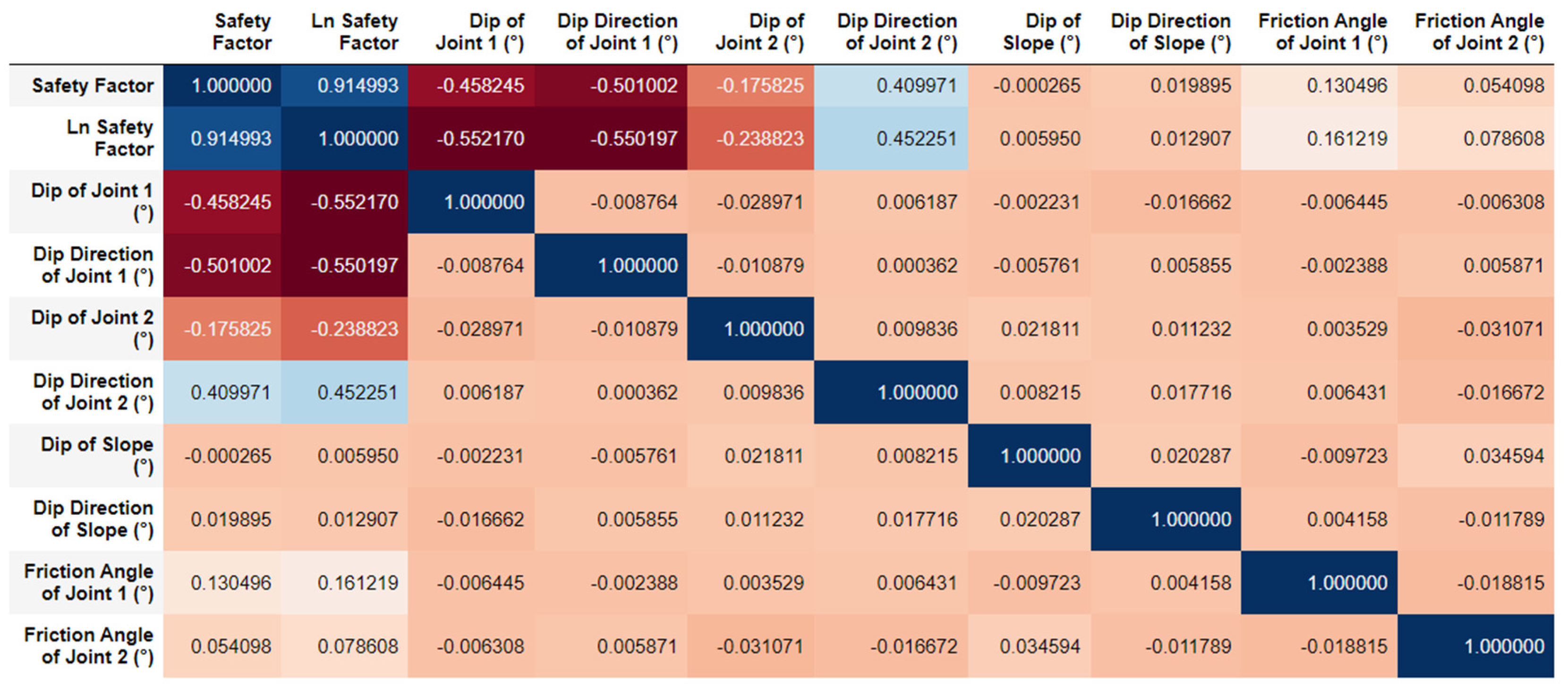
| Parameter | Mean | Median | Min | Max | Standard Deviation | |
|---|---|---|---|---|---|---|
| Input features | Dip of joint 1 (°) | 41 | 41 | 10 | 76 | 9 |
| Dip direction of joint 1 (°) | 130 | 130 | 77 | 186 | 14 | |
| Dip of joint 2 (°) | 55 | 55 | 18 | 86 | 9 | |
| Dip direction of joint 2 (°) | 230 | 230 | 184 | 272 | 11 | |
| Dip of slope (°) | 60 | 60 | 52 | 67 | 2 | |
| Dip direction of slope (°) | 180 | 180 | 173 | 187 | 2 | |
| Friction angle of joint 1 (°) | 30 | 30 | 22 | 37 | 2 | |
| Friction angle of joint 2 (°) | 30 | 30 | 23 | 38 | 2 | |
| Target | Safety factor | 1.16 | 1.06 | 0.38 | 12.56 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Heagy, L.J.; Morgenroth, J.; Elmo, D. Algorithmic Geology: Tackling Methodological Challenges in Applying Machine Learning to Rock Engineering. Geosciences 2024, 14, 67. https://doi.org/10.3390/geosciences14030067
Yang B, Heagy LJ, Morgenroth J, Elmo D. Algorithmic Geology: Tackling Methodological Challenges in Applying Machine Learning to Rock Engineering. Geosciences. 2024; 14(3):67. https://doi.org/10.3390/geosciences14030067
Chicago/Turabian StyleYang, Beverly, Lindsey J. Heagy, Josephine Morgenroth, and Davide Elmo. 2024. "Algorithmic Geology: Tackling Methodological Challenges in Applying Machine Learning to Rock Engineering" Geosciences 14, no. 3: 67. https://doi.org/10.3390/geosciences14030067
APA StyleYang, B., Heagy, L. J., Morgenroth, J., & Elmo, D. (2024). Algorithmic Geology: Tackling Methodological Challenges in Applying Machine Learning to Rock Engineering. Geosciences, 14(3), 67. https://doi.org/10.3390/geosciences14030067