1. Introduction
Vegetation cover is the set of biophysical attributes of a land surface; its behavior is the cumulative result of several factors that exert control, including climate, soil, altitude gradients, physiography, and biological aspects. Thus, vegetation cover can be a measurable indicator of the functionalities of a mountain ecosystem. Changes in vegetation cover reflect alterations in natural factors that impact vegetation growth and its performance, as well as the occurrence of anthropogenic factors [
1]. The information obtained from monitoring changes in vegetation cover and land use can quantify the effects of primary sources of soil degradation such as deforestation, and the dynamic alteration and transformation of land use over time. Also, this information can serve as essential input in an early warning system for the possible occurrence of potential and irreversible changes in the functionalities of a mountain ecosystem.
The ability to remotely map the vegetation cover of mountain geosystems makes it possible to perform environmental analyses that cannot be easily conducted in the field while monitoring changes in land use. In this context, the additional information provided by geographical information systems and the SVIs are a fundamental requirement for understanding both natural and human-induced changes to vegetation cover and their implications [
2]. Vegetation cover analysis is based on defining a classification scheme and a categorization method that allows the identification of primary units. Categorization is a standard application of satellite images. Current attention is shifting from methods of statistical classification (parametric) to methods based on machine learning (ML) or other non-parametric methods. This shifting is because ML methods do not have data distribution assumptions and can handle complex feature spaces and non-normal data. Existing literature suggests that the RFC offers great potential and achieves better results in the categorization of complex scenes [
3]. In general, the RFC makes very precise classifications, provides information about the importance of the predictors (variables), classifies outliers, estimates missing data, and gives an estimate of the error rate associated with the prediction. The accuracy and importance of the predictors (variables) are automatically generated, and overfitting is not a problem. Also, RFC is not sensitive to outlier data values and contains a set of parameters that is easy to initialize.
Images from the Landsat satellites are useful for detecting vegetation cover changes, with sufficient detail to provide relevant information for understanding processes and supporting decision-making if appropriate categorization schemes and classifiers are used. Unfortunately, the mapping of vast areas in complex landscapes is difficult due to abrupt environmental changes of humidity, altitude, temperature, and topographic. Páramos typically dominate Ecuadorian mountain geosystems, and anthropogenic factors are the primary source of degradation. Cultivation rapidly reduces the functionality of páramos [
4]. This accelerated soil degradation causes a rapid advancement of the agricultural frontier and an accelerated and “irreversible” deterioration of the proper functioning of the páramo soils. It is, therefore, necessary to evaluate vegetation cover in Ecuadorian mountain geosystems efficiently and rapidly to gain a better understanding of the underlying factors that influence vegetation cover, monitor vegetation cover changes, and improve our ability to address emerging incidents promptly.
The objectives of this study were to (1) map vegetation using the RFC, spectral vegetation index, and ancillar geographic data (2) identify important variables that help differentiate vegetation cover, and (3) assess the accuracy of the vegetation cover classification in hard-to-reach Ecuadorian mountain region.
To achieve these objectives , we combined spectral vegetation indices derived from Landsat 7 ETM+ satellite with ancillary geographic data to configure a subset of data to train the RFC algorithm. We subsequently mapped the spatial distribution of the vegetative land cover.
3. Studied Area
The studied area is a mountainous and rugged area with very irregular topography in the Ecuadorian Andes, situated in the Achupallas parish in the southwest of Sangay National Park, province of Chimborazo, Ecuador. It is located 300 km south of the city of Quito and covers an area of 1016 km
2, which is in the rectangle defined by the UTM coordinates
x = 743,089.8;
y = 9,760,133.5 and
x = 782,504.2;
y = 9,715,844.1. Four micro-watersheds (MW) intersect the study area: Ozogoche (OMW), Zula (ZMW), Jubal (JMW), and Pulpito (PMW) (
Figure 1).
Ozogoche and Zula MWs have a gradient mostly ranging from undulating to steep (5% to 25%). Jubal MW exhibits a gradient ranging from steep (12% to 25%) to very steep (50% to 70%). Pulpito MW has slopes ranging from inclined (12% to 25%) to steep (30% and 50%), with steep slopes predominating. Ozogoche MW has altitudes ranging from 3608 to 4124 masl. Zula MW has altitudes ranging from 3093 to 4124 masl. Jubal MW has altitudes ranging from 2062 to 4124 masl. Pulpito MW has altitudes ranging from 2162 to 3608 masl.
The studied area is at the junction of Azuay between Hoya del Chanchán and Hoya del Cañar. The junction of Azuay is a mountain massif formed by high transverse geological structures characterized by a wide range of topographies. It is a transition zone dominated by deep valleys and steep slope hills, where it is difficult to distinguish the Cordillera Real (made up of an ancient volcano-sedimentary rock structure that belongs to the calc-alkaline-andesite-dacite series) and the Cordillera Occidental (made up of metamorphic rocks that correspond to the andesite-dacite-rhyodacite series) [
5].
In Ozogoche MW, there are bodies of natural water, páramo areas, and cultivated pasture areas, with the páramo areas predominating. In Zula MW, there are pasture areas, planted forest areas, and páramo areas. In Jubal MW, there are areas of páramo, cultivated pasture, planted forest areas, and natural forest, with the páramo areas predominating. In Pulpito MW, there are areas of páramo and natural forest. The soil in the studied area is of volcanic origin, with Andosols in most of the area and Inceptisols and Histosols to a lesser extent. The soils texture types are silty, sandy, and sandy loam. Underdeveloped soils can also be found on rocky substrates. The soil textures of Ozogoche MW are silty and clay. In Ozogoche MW, under-developed soils can be seen on the rocky substrate. The soils texture in Zula MW is silty with inclusions of fine sand and sand. The soils of Jubal MW are silty, sandy loam, and sandy clay loam. The soils of Pulpito MW have a silty-sandy loam texture. In Pulpito MW, under-developed soils can be seen on the rocky substrates.
In the northern part of the studied area, the Achupallas weather station (INAMHI: M5140) recorded an average annual temperature of 10.6 °C, an annual average relative humidity of 73%, and an average annual rainfall of 694 mm [
6]. The INAMHI: M5140 weather station is at UTM coordinates 748,006 and 9,747,233. In the southern part of the studied area, JMW the Jubal weather station (INAMHI: M5138) recorded an average annual temperature of 8.2 °C, an annual average relative humidity of 85.6%, and an average annual rainfall of 981 mm [
6]. The INAMHI: M5138 weather station is at UTM coordinates 756,205 and 9,734,265 [
6]. The average wind speed is 2.16 m s
−1; the faster winds are in the OMW sector, where the maximum speed reaches 6 m s
−1.
The studied area covers the southwest of Sangay National Park. This park is one of the most important protected areas in the tropical Andean region and the third most extensive in the continent of Ecuador. The Sangay National Park was declared a UNESCO World Heritage Site in 1983; it is host to a wide variety of unaltered landscapes, high levels of endemism, and ecological diversity. The park is in a transition zone where warm air currents, loaded with moisture from the southern Amazon convergence with cold and dry air currents from the northern part of the Ecuadorian Andes. Ozogoche MW is a natural fresh water reservoir (Ozogoche lacustrine system) and provides water to the Agoyan and San Francisco Hydroelectric Plants. Zula MW provides its water to the Nizag Hydroelectric Plant. The Jubal and Pulpito MWs contribute their water resources to the Paute Hydroelectric Plant.
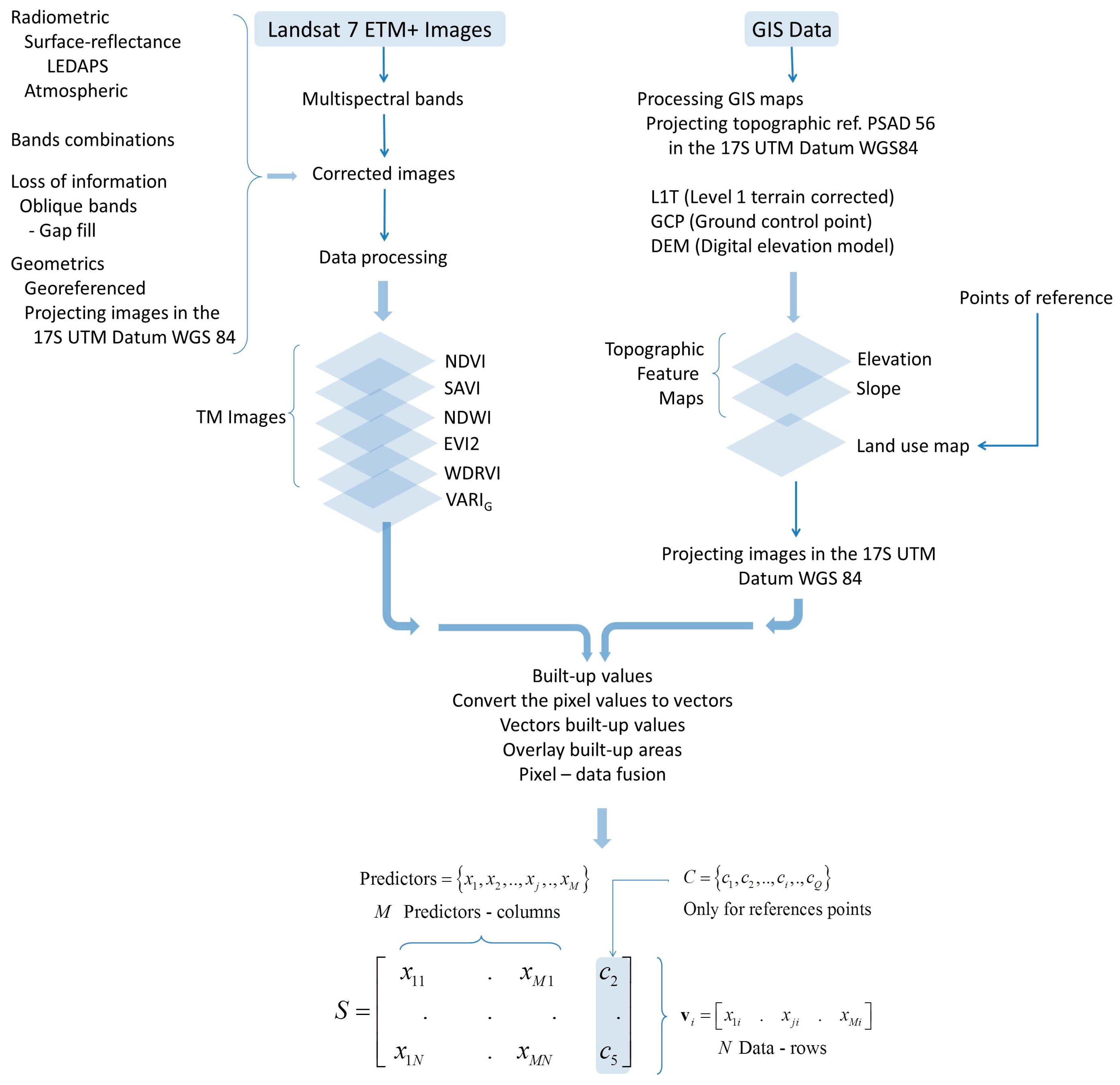
4. Satellite Data and Processing
This study was carried out with images captured by the Landsat 7 satellite with an Enhanced Thematic Mapper (ETM+) sensor (Landsat 7-ETM+). This satellite has a sun-synchronous orbit at an altitude of 705 km, a solar tilt of 98.2°, and a scan strip width of 185 km. It crosses the equator in a descending path at 10:00 AM. with an uncertainty of ±15 min. The Landsat 7-ETM+ has a temporal resolution of 16 days. The signal per pixel of each sensor is coded in an 8 bit binary code (256 different values) [
7]. The scene of the studied area was captured on 4 March 2011 with the following tags: (1) ID: LE70100622011063ASN00; (2) CC: 81%; (3) Date: 2011/3/4; (4) Qlty: 9; (5) Product: ETM + L1T; and (6) path 010 and row 062. Images were selected in such way that the area of study was cloud free.
The level one of the processing involved the “Level 1 Terrain Corrected” using Ground Control Points (GCP) and Digital Elevation Model (DEM) that improves absolute geodetic accuracy; the WGS-84 ellipsoid was used for the UTM coordinate transformation system. The DEM was provided by INFOPLAN [
8]. The georeferencing of the image was performed using PSAD-56 georeferenced topographic maps supplied by the Military Geographic Institute of Ecuador [
9] and by land inspection.
The preprocessing begins with the process of atmospheric correction, reflectance, and calibration, through the Landsat Ecosystem Disturbance Adaptive Processing System (LEDAPS), and then the images are subjected to a preprocessing code where information is filtered in four stages. First, the metadata is extracted from the Landsat image, and then the digital number (DN) values are calibrated to the Top of Atmosphere (TOA). Second, the soil reflectance is corrected to the TOA by ancillary data. Third, we applied the Automated Cloud Cover Assessment (ACCA) [
10], and finally we use the MODIS/6S algorithm for atmospheric correction; focusing on the radiative transfer with aerosols [
11]. The soil reflectance correction and the cloud cover were obtained with pixels that were detected by the LEDAPS process. A complete image is achieved by the composition of the seven bands. Then, the image is checked for errors given by aerosols, clouds, pixel without information, salt and pepper noise, random variation impulse noise and speckle [
12].
From May 2003, Landsat 7 ETM images exhibit partial loss of information because the scan line corrector were off (SLC-off). Thus, wedge-shaped information gaps are observed on both sides of the scene, and about 20% of the data was lost [
13,
14]. The procedure to overcome the SLC-off effect involved the selection of complementary images to compose a complete scene using gap-fill techniques [
15]. If the image does not need gap-fill, we performed a cloud mask calculation, which allows generating a mask where information has the clouds and shadows generated by LEDAPS. Then, the composed image is joined with the cloud mask to obtain a cloudless image in each band of the composed image. If the image needs gap-fill, we proceeded to multi-fill the images with the image chosen to take into account the order of filling, same that is given by order of importance of the image for the filling (
Table 1).
Finally, the image is re-projected to the area UTM 17 S, datum WGS 84 and the image pixels within the studied area extent were extracted. Also, we integrated land vegetation cover information from 1640 reference points probabilistically sampled.
Figure 2 shows the workflow during the satellite data processing.
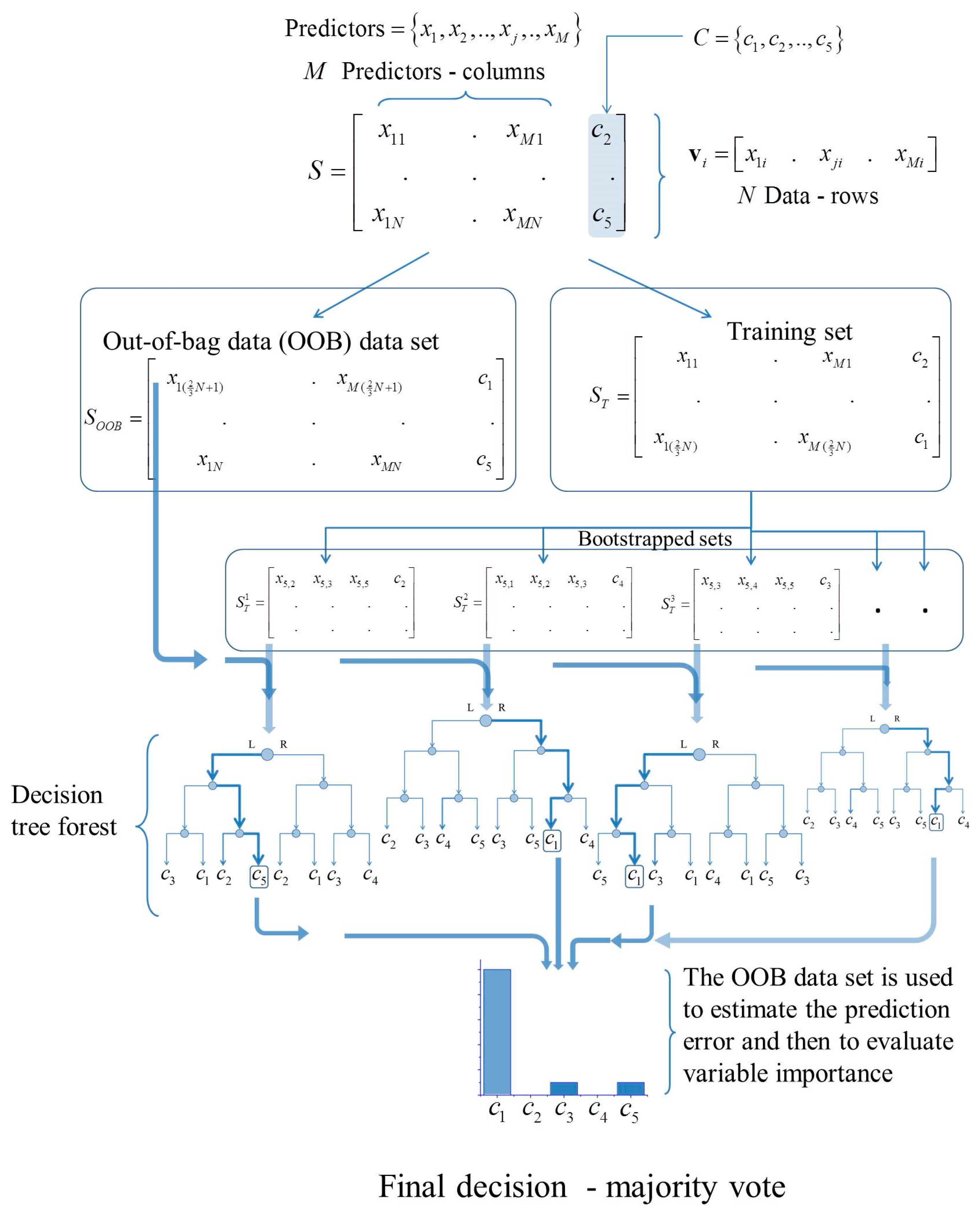
5. The Random Forest Classifier
The RFC bases its performance on the learning that results from training an ensemble (a large number) of decision trees (DT). The RFC provides its best prediction by counting the number of trees that have similar results and selecting the result that was predicted by the most trees. Therefore, the RFC performance is sensitive to the samples used for training [
16]. One of the relevant aspects of the RFC is the random sampling of the training data space. The RFC algorithm randomly selects subsets of data (bootstrap) that serve to train an equal number of DTs while attempting to avoid any correlation between these subsets. The DT can arbitrarily model complex relationships between the input and output without having to assume a normal distribution of the data. The DT can also handle complex data of different types [
17]. The categorization process goes through a set of rules that determine the trajectory followed from the root node to the terminal node in each DT. The DT learns these rules by induction, using a subset of the data from the training set. Thus, DT separates classes by choosing variables and points that best separate them. The main idea is to partition predictor variables into different regions so that the dependent variable can be predicted more accurately.
According to Hastie et al. [
18], the RFC does not require much tuning. Three parameters need to be set by the user in order to produce the ensemble of DTs; the number of DTs to be generated (ntree), the number of predictor variables to be selected at random and tested for the best split when growing the DTs (ptry), and the minimun amount of data in the terminal node (nodesize). We found that the magnitude of the error was the smallest with ntree = 500, ptry = 3 and nodesize = 3, and the classification accuracy stabilize much before the 500 DT is achieved.
How is a new object classified using RFC? We used the vector containing all the attributes of the new object as input for each of the DTs that make up the full set. The output of each DT is a classification (one vote). The RFC selects as its prediction the result predicted by the most trees with the highest number of votes [
17].
Figure 3 shows the structure and flow of information in the context of the RFC.
Figure 3 illustrates only the flow of information using a portion of the data; that portion was divided into one data set for DT training and another data set for validation (“out-of-bag” (OOB) data subset), error calculation, and estimating the importance of the variables.
The RFC quantifies the importance of the variables in two ways. (1) The first relates to the gain of information achieved when the partition is performed on each node of each DT. This value is accumulated for each predictor in all DTs; a higher value indicates a more relevant predictor for performing the partition and therefore the classification; (2) The algorithm also uses the samples in an OOB subset to develop a measure of the importance of the predictors and thus estimate the predictive strength of each predictor. Once the DTs have been trained, all the data of the OOB subset go through all the DTs, and the accuracy of the prediction is recorded. The values of predictor
j are randomly permuted in the OOB subset, all the data goes through the DTs, and once again, the accuracy of the prediction is recorded. This permutation causes a decrease in the accuracy of all DTs; all the decreases are averaged, and the resulting value is used as an indicator of the importance via permutations of predictor
j. The random permutation effect effectively nullifies the effect of the variable, similar to what occurs when we set a coefficient in a linear model to zero [
18]. In this study, we used the variables importance indicator via random permutations to find the key variables that are highly related to the effectiveness of the classifier. We will also use this indicator to determine a small number of predictors that are “sufficient” for making accurate predictions or forecasts.
We selected the relevant variables from the group of predictor variables that were initially proposed regarding the quantification that the RFC performs of the importance of the variables and the average error in the final prediction. In this way, it was also possible to optimize the correction factor L, which accounts for the reflectivity of the soil in the analytical expression that determines the soil adjusted vegetation index as defined in the Equation (2). Similarly, we found the optimal value of constant “a” in the equation of the wide dynamic range vegetation index, see Equation (5).
We did not analyze autocorrelation relationship between different variables because correlated variables do not affect the predictive performance of a RFC. Since each split in each tree is the split that yields the maximum improvement. One consequence of correlated variables is that the variable importance
scores among variables that are correlated lower than what they would be if there were no correlated variables. The issue of correlates variables is prominent in high-dimensional problems like in genomics [
19]. Strobl et al. [
19] developed a conditional permutation scheme for the computation of the variable importance measure. The resulting conditional variable importance reflects the true impact of each predictor variable more reliable than the original permutacion approach. We did not implement the conditional permutation approach because our objective was to find a small number of predictor variables sufficient for a good performance of the RFC and we did not want to find important variables for interpretation purpose. Similarly, we did not perfom an independent validation becauce it has been stated that one compelling component of RFC is that there is no need for independent validation [
20]. One issue with RFC arises when the clases in categorical response variables are imbalance. Imbalances in the response variable result in biased classification accuracy. This is due to the boostrap over-representing the majority class, leading to under-prediction of the minority class [
20]. We circunved this problem by training the RFC with equal allocation of samples in each stratum.
8. Spectral Vegetation Indices
The spectral vegetation index (SVI) is a number that expresses the physiological and biophysical characteristics of the vegetation. SVIs are derived from the solar reflectance spectrum of vegetal material. The solar reflectance spectrum is characteristic of each plant species or the reflective surface of water bodies, pavements, and other surfaces. In general, the SVI is a function of one or more solar reflectivity values in the same number of spectral bands. Knowing the spectral signature of water and other elements that coexist in vegetal material allows for inferring biophysical and physiological aspects of interest in the vegetal material responsible for the total reflectance spectrum.
The reflectivity values measured are converted into a numeric value through an analytical expression that determines the SVI. Thus, each SVI defines a metric for one or more physiological or biophysical aspects of the vegetation. However, the effectiveness of the SVI is affected to varying degrees by soil properties, atmospheric conditions (clouds, particles and wind), topographical conditions (altitude, slope and aspect), sunlight, and the calibration and viewing geometry of sensors [
29]. Thus, a good SVI should be sensitive to these influencing factors; to achieve this, correction factors are incorporated depending on the nature of the influencing factor. Alternatively, one can determine the minimum set of spectral bands whose reflectance values only provide information about the aspect of interest and combine these values into a SVI. Thus, after slightly more than 50 years of development, there are currently over 150 SVIs proposed in existing literature, although few have been systematically evaluated [
1]. With calculated SVI values, we can make inferences about the structure of vegetal material, the state of vegetation cover, photosynthetic capacity, the density and distribution of leaves, leaf water content, mineral deficiencies and evidence of the existence of stressful elements or conditions in plant development.
We can generally group SVIs into indicators that use signals from broadband, narrow band, foliar nitrogen, foliar water content, dry or senescent carbon, leaf pigment and sunlight efficiency sensors [
30]. The indicators that use signals from broadband sensors comprise indices of vegetation quantity and vigor (chlorophyll content). These indices compare reflectivity values in the near-infrared and red bands, where chlorophyll absorbs photons to convert light into stored energy through photosynthesis. A reduction of the reflectance in the near-infrared band and an increase of the reflectance in the red band can occur due to an increase in chlorophyll concentration in the leaf, an increase in the leaf area, a decrease of foliage clumping and a change in foliage architecture. This simultaneous decrease/increase in these two bands is reflected in an increase of the SVI that uses broadband sensors. These SVIs are sensitive to the combined effect of chlorophyll concentration of the foliage, leaf area, foliage clumping and architecture. However, they do not provide quantitative information for any biological or environmental factor contributing to the fraction of absorbed photosynthetically active radiation (fAPAR). They do provide comprehensive information about the quantity and quality of the photosynthetic material in the vegetation, and this is essential in order to understand the state of the vegetation for any purpose. These SVIs are used, among other applications, in vegetation phenology studies, climate impact and land use assessments, and plant productivity modeling [
30]. From this group of indicators that use signals from broadband sensors, we can highlight, among others, the normalized difference vegetation index (NDVI), the soil adjusted vegetation index (SAVI) and the two-band enhanced vegetation index (EVI2).
The NDVI was initially proposed by Rouse et al. [
31] and is defined as the quotient resulting from subtracting the reflectivity measured in the red band (
ρR) from the reflectivity measured in the near-infrared band (
ρNIR) divided by the number that results from adding (
ρNIR) and (
ρR); see Equation (1). The symbol
ρ denotes the reflectivity measured and its subscript denotes the electromagnetic spectrum band used.
The NDVI value varies between −1 and 1. Vegetal material corresponds only to positive values; the higher the index, the higher the chlorophyll content. Values close to zero indicate sparse vegetation on bare soil. Materials that absorb more radiation in the near-infrared than in the visible (such as water) produce negative NDVI values [
1,
32]. The NDVI exhibits limitations related to the photons reflected by the ground. To overcome this limitation, Huete [
33] considered the spectral signature of a typical soil and modified the NDVI expression by explicitly incorporating a correction factor (
L) that accounted for the effect of the soil in a spectral indicator called SAVI; see Equation (2). Huete [
33] found that an
L value of 0.5 was acceptable in a wide range of vegetation covers. In reality, however, a prior knowledge of the vegetation and an iterative process are required to determine the optimal
L value [
34].
When the NDVI is plotted vs. the leaf projected area index per unit of ground surface area (LAI), it should be noted that once the LAI is greater than a certain value (near one) the sensitivity of the NDVI to the LAI value reduces significantly and its behavior becomes asymptotic [
35,
36]. This behavior suggests that the NDVI will never reach values close to one in dense vegetation conditions; on the contrary, at a certain LAI value, the variation will not be significant. This can be explained if we consider that all the photons in the visible range are absorbed when LAI values are high. Consequently, this behavior confirms that prior to being an indicator of LAI, the NDVI is first and foremost an indicator of photosynthetic capacity and primary production [
1].
The NDVI is also sensitive to attenuation and dispersion by the atmosphere and to particles (aerosols) present in the atmosphere [
35,
37,
38,
39]. To overcome this limitation, researchers have focused on the reflectivity in the red band because the spectral components with wavelengths in the visible range are more sensitive to smoke and aerosols in the atmosphere. Kaufman and Tanre [
37] corrected the effect of aerosols in the atmosphere by using the reflectivity difference between the blue and the red bands as the reflectivity value of interest. Thus, these authors proposed the atmospherically resistant vegetation index (ARVI). Another alternative that was developed to correct for the atmospheric effect in NDVI values consisted of using the reflectance in the shortwave infrared band (SWIR: 1600 to 2100 nm) as a
substitute of the red band in the original NDVI expression, as the long-wavelength spectral components were less sensitive to smoke and aerosols in the atmosphere. Thus, Karnieli et al. [
40] proposed the aerosol-free vegetation index (AFRI) based on the high correlations found between the reflectance values in visible bands and shortwave infrared bands. The authors replaced the reflectance value in the red band of the NDVI expression with the estimated value based on the linear relationship they found with the reflectance in the shortwave infrared band.
The enhanced vegetation index (EVI) was developed to provide greater sensitivity in regions with high biomass while minimizing the influence of the soil and the atmosphere. The EVI corrects distortions caused by particles in the air as well as the brightness of the soil. The EVI does not become “saturated” as easily as the NDVI in areas with large amounts of chlorophyll production. The EVI was originally proposed as a function of the reflectance values in the blue, red and near-infrared bands. However, subsequent studies exposed serious controversies that made its use questionable and caused its discontinuation [
1]. Alternatively, when the effects of atmospheric conditions are negligible and the data quality is good, it has been proposed to replace the EVI with EVI2, which uses only two bands (red and near-infrared) and is a modified version of the NDVI—see Equation (3) [
35]. The EVI2 maintains the sensitivity and linearity shown by EVI in conditions of high biomass and minimizes the influence of the soil. The EVI2 is based on the assumption that a linear relationship exists between the reflectance values measured in the red band and the blue band.
The normalized difference water index (NDWI) is an indicator of foliar water content. Water classification is required to map the distribution, morphology, and connectivity over large areas. Water classification is also useful when excluding it from processing routines that are directed toward other purposes [
41]. Several indicators of water have been used for identification purposes based on the solar reflectance spectrum provided by remote satellite sensors. The NDWI was initially proposed by McFeeters [
42]; see Equation (4). The index uses the reflectance values measured in the near-infrared and green bands (
ρR) to quantify the presence of water bodies while reducing the impact of soil reflectivity and vegetation cover. We added the McFeeters subscript to distinguish the indicator from other indices that are also identified with the letters NDWI.
This study explored the use of multiple SVIs as predictors of the vegetation cover in our studied area. Indexes EVI2, SAVI, NDVI, and NDWI were calculated using Equations (1)–(4), respectively. However, we also used the indices “Wide Dynamic Range Vegetation Index” (WDRVI) [
38] and “Visible Atmospherically Resistant Index — Green” (VARI
G) [
43,
44] with Equations (8) and (9), respectively.
The indices are calculated on a piel-by-pixel basis and when we loss any bit we imported it using the Nearest Neighbor Interpolation algorithm [
45] and an appropriate reclassification is carried out to assess their value with respect to the different types of land use. We used SVIs as preditor varibles and not the image band because the SVIs carrie information about the spectral signature of the vegetative material and the image band by itselft does not. The SVI derived from information provided by remote sensors is the primary source of information for monitoring and assessing the vegetation cover of the land surface [
1,
46]. For example, the vegetation analysis and detection of changes in vegetation patterns are important in the assessment and monitoring of natural resources [
2].
9. Results and Discussion
Figure 5 shows the importance of the variables in the RFC performance, which decreased with the following trend: Altitude > EVI2 > WDRVI > NDVI > NDWI > SAVI > VARI
G. Low values are associated with variables with little relevance for the categorization and RFC performance. Predictor variables with little importance provide limited information and do not reduce the Shannon entropy of the information. However, this hierarchical framework must be taken with caution because the correlation among the variables could have had an impact on the relative assessment of importance but do not affect the predictive performance of a RFC.
Figure 5 also shows that the topographic variable “Altitude” provided more information—with a relative importance of 100%—than any of the SVIs used in this study. Thus, “Altitude” significantly increases the accuracy of the categorization of the different basic units of vegetation cover. “Altitude” is a topographic variable derived from the digital elevation model scaled to the spatial resolution of the SVIs (30 m). The vital importance of altitude suggests that the spatial distribution of the categories of vegetation cover in the study region depends on the topography or the temperature [
47]. In our studied area, the altitude varies from 2162 masl to 4124 masl. “Altitude” is a terrain variable that affects the microclimate and indirectly affects plant physiology. “Altitude” is the most relevant environmental variable in the spatial distribution of vegetation. The space allocation of forests in mountain regions is related to the altitude, slope, and aspect.
The two-band enhanced vegetation index—with a relative importance of 57.32%—was second in importance to “Altitude”, and its information contribution was higher than that provided by the NDVI. This result agrees with the fact the NDVI is directly related to primary production (photosynthesis-chlorophyll), whereas EVI2 is more related to the leaf area index (LAI) and does not lose sensitivity in areas with dense vegetation and abundant chlorophyll production [
1].
The wide dynamic range vegetation index—WDRVI—exhibited greater importance (37.74%) than the NDVI (34.16%) and less importance than the EVI2 (57.32%). Studies conducted by Gitelson [
36] showed that the WDRVI indicator exhibits greater sensitivity to LAI than the NDVI. This index has been widely used to estimate the “Green LAI”. We found that a constant “
a” in the expression of the WDRVI indicator (see Equation (5)) required a value of 0.05 for the importance of the WDRVI in the classifier results to reach 37.74%. With
a = 0.05, the WDRVI spectral index provided the most information to the classifier and contributed to an information entropy reduction. The WDRVI is an algebraic transformation of the NDVI that is implemented to increase the sensitivity of the NDVI when the LAI indicator is greater than 1.
The relative importance of the NDVI was 34.16%. Under dense vegetation conditions (LAI > 1), the NDVI never reaches values close to 1 and loses sensitivity (its variants will be insignificant) to the value of the LAI [
35,
36]. This because NDVI is mainly an indicator of photosynthetic capacity and primary production and not of leaf area [
1].
The normalized difference water index—NDWI—had an importance of 30.38% and provided slightly less information than the NDVI and a little more than the SAVI. The NDWI separates water bodies fairly well from other bodies; the NDWI assumes negative values when the reflectance is due to vegetal material and values greater than zero when the reflectance is due to water bodies.
In general, when the vegetation is very dense, the value of constant L approaches zero, and the SAVI is equivalent to the NDVI. When the terrain is bare and has little or no vegetation cover, the value of constant L approaches 1. The soil adjusted vegetation index—SAVI—had an importance of 25.96% in RFC results. We found that constant “L” in the expression of the SAVI indicator (see Equation (2)) must have a value of 0.15 for the importance of SAVI to reach 25.96% in the classifier results.
The visible atmospherically resistant index—VARI
G—had the lowest importance (17.86%) of the set of predictor variables. Previous studies conducted by Gitelson et al. [
46] showed that VARI
G is sensitive to the entire range (0 to 100%) of variation of the vegetal fraction (VF). Moreover, the NDVI shows high sensitivity to the VF within the range of 0 to 50% and begins to exhibit an asymptotic behavior (saturation effect) when the VF exceeds 50%. The VARI
G indicator was developed to estimate crop conditions because it exhibits a good correlation with nitrogen contents (g N/m
2) [
43].
We included the topographic variable “Slope” as a predictor variable in the initial calculations. Our studied area exhibits slopes that range from undulating (5%) to very steep (70%). It is well known that the “Slope” can be relevant in a spatial distribution of vegetation that requires large amounts of moisture and has a significant influence on the microclimate. Because “Slope” affects water conditions in the soil as well as temperature. The slope is one of the sources of heterogeneity in the landscape that is related to the spatial distribution of the vegetation in mountain regions [
48]. The tests performed showed that the slope has little importance (less than 3%) on the RFC results in the categorization of basic units of coverage in our study region. By excluding the “Slope” from the group of predictor variables, the change in the overall percentage of correct classifications did not exceed 1%; we, therefore, decided to remove this variable from the group of predictor variables. Our results showed that the slope was not useful in reducing the entropy of the information provided by the set of predictor variables. We explain this behavior in our setting because of the terrain, in general, is very irregular and has areas with various slopes and has very dense and diverse vegetation cover.
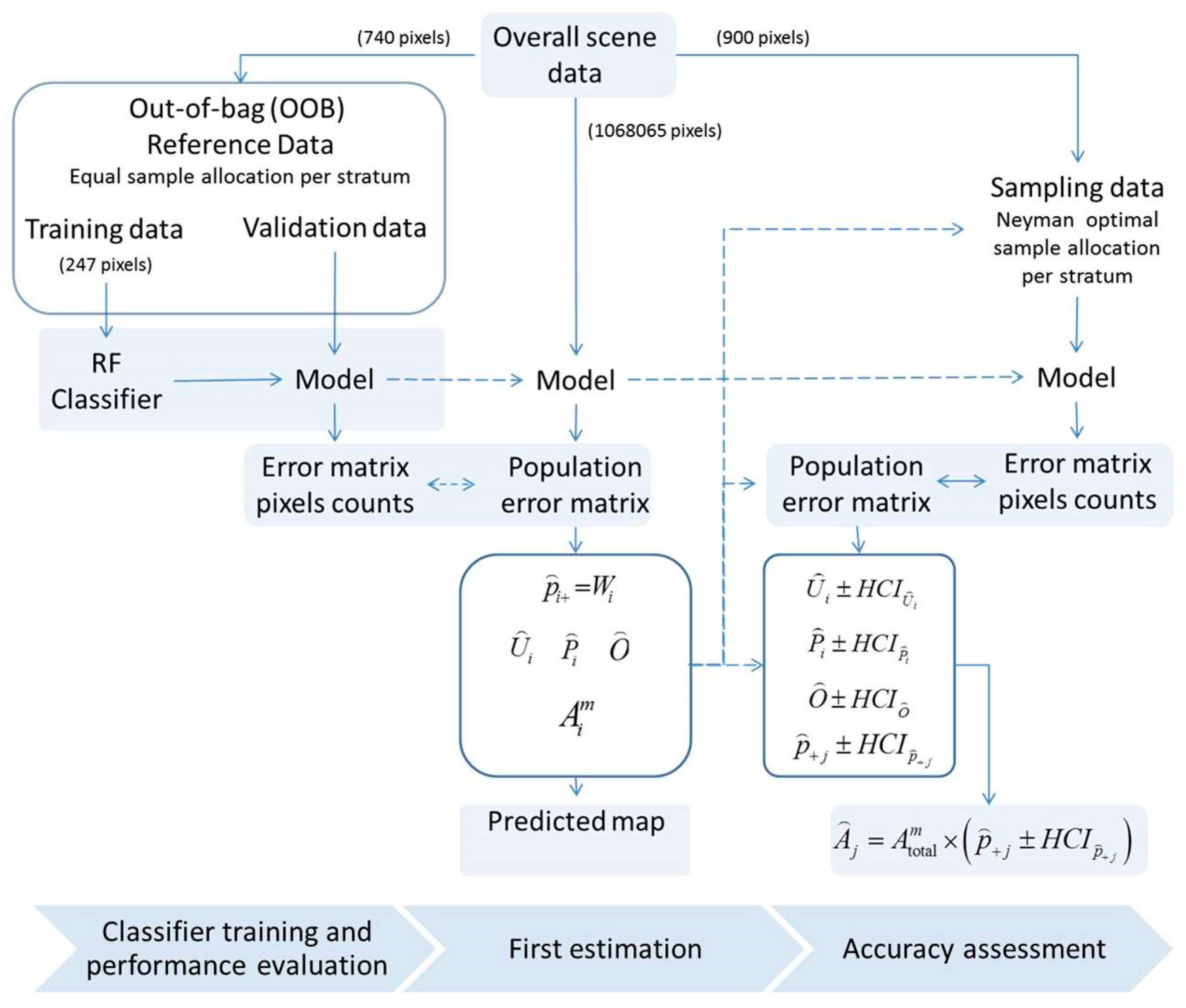
With this group of predictor variables, the overall percentage of correct categorizations made with the OOB data subset were 93.78% (see
Table 5). This value is relatively acceptable if we consider the difficulties of the studied region and that we only used 247 pixels to train the algorithm. In general, these areas are located in hard-to-reach areas, possess very uneven topography and extreme climates, and offer little available local information.
Table 5 shows the overall trained RFC performance—error matrix expressed in
pixel counts—and upon training with equal sample allocation in each stratum. The equations used to estimate the error matrix, UA, PA, and OA are listed in
Table 5. The percentages of correct classifications of pixels from the FOR, PAR, CRO, and PAS categories were 92.43%, 94.05%, 95.14%, and 93.51%, respectively. Of the 185 pixels associated with each of the classes, the classifier correctly categorized 171 from the FOR, 174 from the PAR, 176 from CRO, and 173 from the PAS.
Table 6 lists the values of the population error matrix with cell entries expressed regarding the estimated proportion of the area, and upon the training of RFC with equal sample allocation in each stratum. The equations used to estimate the error matrix, UA, PA, and OA are listed in
Table 2.
We run on the whole data set of 1,068,065 pixels from the overall scene through the predictive RFC model, and we get the map shown in
Figure 6. This map shows a predicted distribution of the different vegetation cover in the study area and its predicted proportions within the whole map (see
Table 6). The proportion of category’s area derived from simple
pixel counts for FOR, PAR, CRO and PAS are 0.2340, 0.5403, 0.1896 and 0.0361, respectively.
Table 7 lists the values of the estimated map area for each stratum, the map accuracy, and the incertitude assessment of estimated values using the equal sample allocation in each stratum. The equations used to estimate the values are listed in
Table 2. The estimated area of FOR, PAR, CROP, and PAS is 21,702 ± 1027 ha, 51,015 ± 1593 ha, 18,585 ± 1429 ha and 4823 ± 960 ha, respectively.
However, the OA is 94.80%, the UA for each class is above 90%, and the PA for the PAS is equal to 66.57% (see
Table 6). Forest always surrounds PAS and PAS represents a relatively small proportion (3.61%) compared to FOR (23.40%). Thus, a small error in PAS’s pixel counts (PAS producer’s accuracy is 93.51%, see
Table 5) yields smaller PA (66.57%) in the proportion of the area cover by PAS. The smaller the proportion more pixels at the boundaries and less inside, so any error counting pixel at the boundary yield bigger error pixel counts. The lowest values of the producer accuracy for the PAS (66.57%) prompted us to compose a newest error and population matrix. Therefore, we performed a Neyman sample allocation in each stratum.
Table 7 lists the number of samples in each stratum while performing a NOA of samples. We kept the RFC model trained with equal number of samples allocated to each stratum, and re-run the RFC with the new set of samples. A new error matrix and population matrix were calculated using equations in
Table 2 and
Table 3. From the newest error matrix, the new UA and PA for the PAS class are 82.81% and 93.51%, respectively. From the newest
population error matrix, the estimated UA and PA is 82.81% and 82.28%, respectively. The new OA is 95.53%. Therefore, we find the error-corrected areas by performing a NOA of the sample in each stratum (
Table 8 and
Table 9).
Table 9 lists the values of the new estimated map area for each stratum, the map accuracy, and incertitude assessment of the error-adjusted areas. Thus, the NOA allows an error-adjustment for the FOR’s map area from 21,702 ± 1027 ha to 22,293 ± 772 ha; the PAR’s area from 51,015 ± 1593 ha to 52,319 ± 1057 ha, the CRO’s area from 18,583 ± 1429 ha to 18,011 ± 1014 ha; the PAS’s area from 4823 ± 960 ha to 3492 ± 596 ha (
Table 7 and
Table 9).
Table 10 lists the values of the overall disagreement assessment and the disagreement assessment by category.
The equal allocation stage yields a 5.20% of overall disagreement with 1.78% due to quantity disagreement and 3.42% due to allocation disagreement (see
Table 10). The disagreement assessment of PAS class shows the biggest relative disagreement (22.58%) with a 72.25% of the relative disagreement because of quantity disagreement and 27.75% because of allocation disagreement. Meanwhile, the relative disagreement of the other categories remains below 10%. The NOA stage yields a 4.47% of overall disagreement with 0.43% because of overall quantity disagreement and 4.04% because of OAD. The disagreement assessment of the PAS class shows a relative disagreement of 17.45% with a 1.86% due to quantity disagreement and 98.14% due to allocation disagreement. Thus, the new sample allocation adjusts PAS quantity disagreement from 72.25% to 1.86% and the allocation disagreement from 27.75% to 98.14%.
Our results suggest that CRO had occupied areas initially from the PAR in a proportion of 0.2560 ± 0.0146. Thus, at to 2011, the PAR had lost approximately 26% (around 18,011 ± 1014 ha) of its pristine coverage due to anthropogenic factors. The PAR resilience and functionality is constantly threatened by the expansion of the CRO cover. Establishing crop promotes spreading of the agricultural frontier and a speeded and irreversible decline of the proper functioning of PAR soils in the Ecuadorian mountain geosystem.
10. Conclusions
We had defined a methodological framework for mapping hard-to-reach mountain geosystems. The relevant factors characterizing the vegetation cover in the studied area were the topographic variables “Altitude” and the next SVIs: EVI2, WDRVI_05, NDVI, SAVI_L15, and VARIG. “Altitude” and EVI2 provide more information on vegetation cover than the traditional NDVI and SAVI, particularly when the reflectance of red is low, and the NDVI is “saturated”, as it occurs in conditions of high chlorophyll production (high density of vegetation).
Within this new framework, the RFC has shown great potential to improve the method of the study and mapping of land cover as well as the study of the underlying phenomena responsible for changes in coverage and the use of the land in complex areas such as the mountain geosystems. The RFC confirms the importance of predictor variables, regardless of their nature (whether spectral or topographic) and the information they provide (thus reducing entropy in the data set), in achieving a more accurate categorization. This feature of the RFC is important because previous studies of vegetation and land use in these complex and heterogeneous regions have required significant amounts of information from multiple sources with a large number of variables.
One apparent disadvantage of the RFC is that it is hard to understand the rules used to categorize the primary units of coverage; intrinsically, this is because there are a set number of rules and subsets of these rules that are captured in a significant number of DTs. Each DT corresponds to an ensemble or a set of predictor variables that enables the exploration of data space using the reduction of information entropy as a fundamental criterion. However, an RFC that excels in its performance demands a good statistical representation of the space, data and predictor variables. For training an RFC, any data can be used; there is no sampling design requirement. However, the reference data must be acquired using a probability sampling design that includes a randomization component. Training samples must be representative of the target classes and class balanced. Otherwise, there is no assurance the results “faithfully” represent the study area. Although the accuracy of the RFC, the estimates of class areas taken directly from a map are subject to classification error and may or may not, adequately represent the real area on the ground. The stratified estimation approach and the NOA of samples do circumvent not only the effects of classification errors, but also allows an assessment of the uncertainty of each class area estimate. The quantity disagreement and the allocation disagreement assessment light up a much more enlightened path for the study of an RFC performance in a mapping application.
The combined use of SVIs, supplementary topographic information, and algorithms such as the RFC results in the most appropriate technology for achieving the goal of mapping complex mountain landscapes as well as mapping and monitoring strategies aimed at conservation and management. The methodological framework developed in this research based on the Random Forest Classifier is an appropriate and highly accurate method of classifying land cover when remotely sensed spectral imagery and ancillary data are combined. The resulting land cover classification can be both accurate and usable on a large spatial scale.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}