Best-Fit Probability Models for Maximum Monthly Rainfall in Bangladesh Using Gaussian Mixture Distributions




Abstract
:1. Introduction
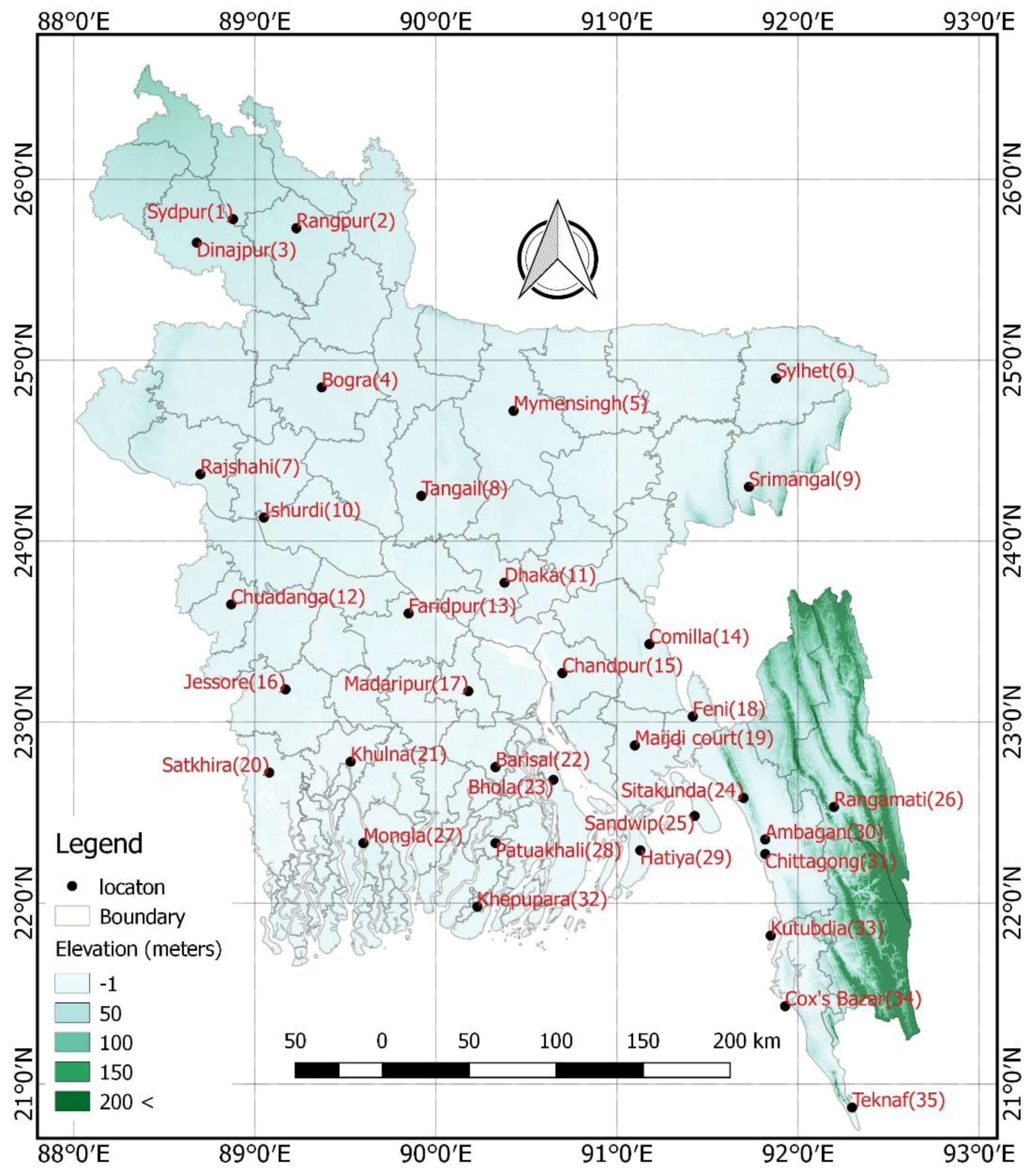
2. Data and Study Area
3. Methodology
3.1. Gaussian Mixture Distributions
3.2. Goodness-of-Fit Tests
3.3. Return Period
4. Result and Discussion
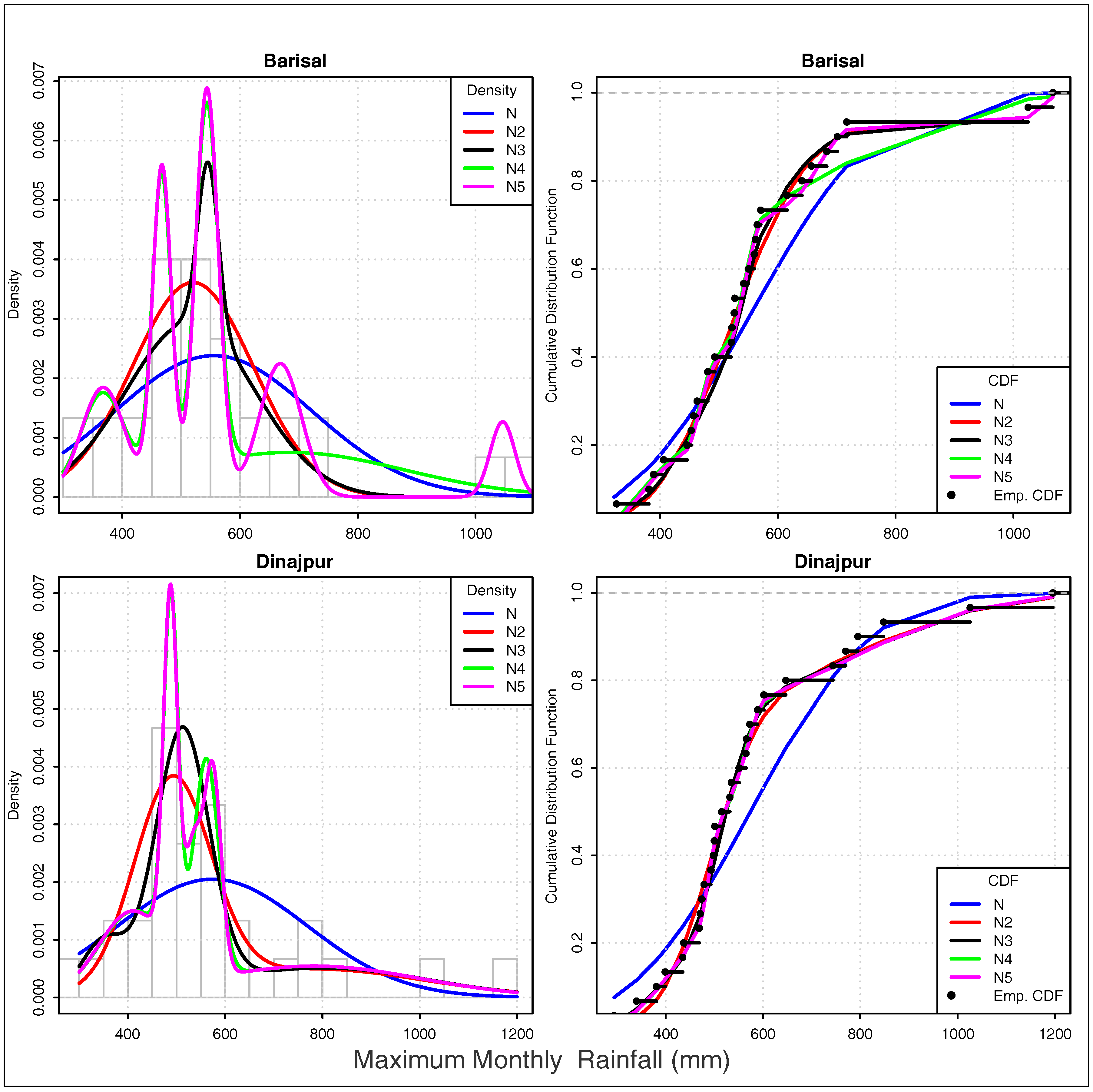
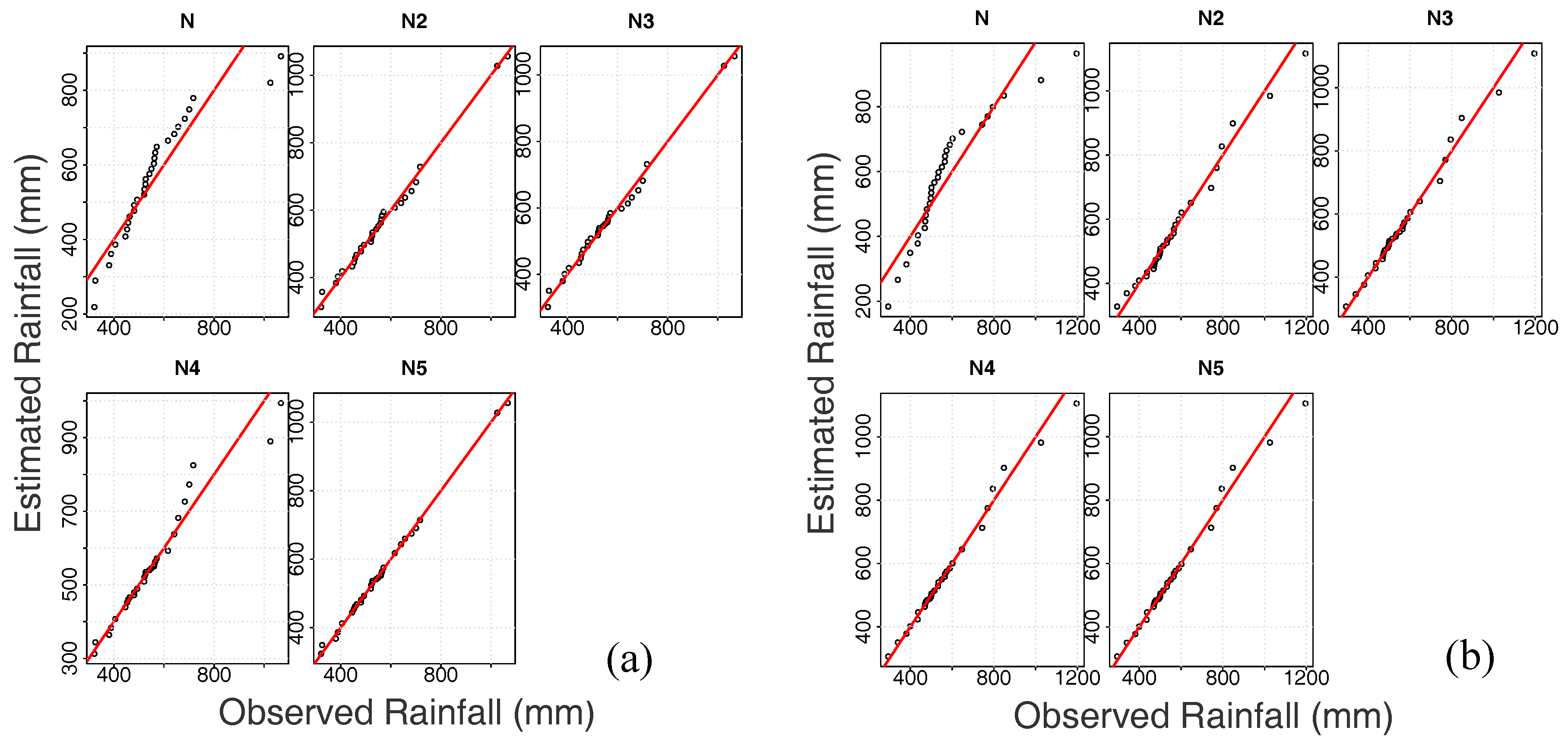
4.1. Selecting the Best-Fit Results
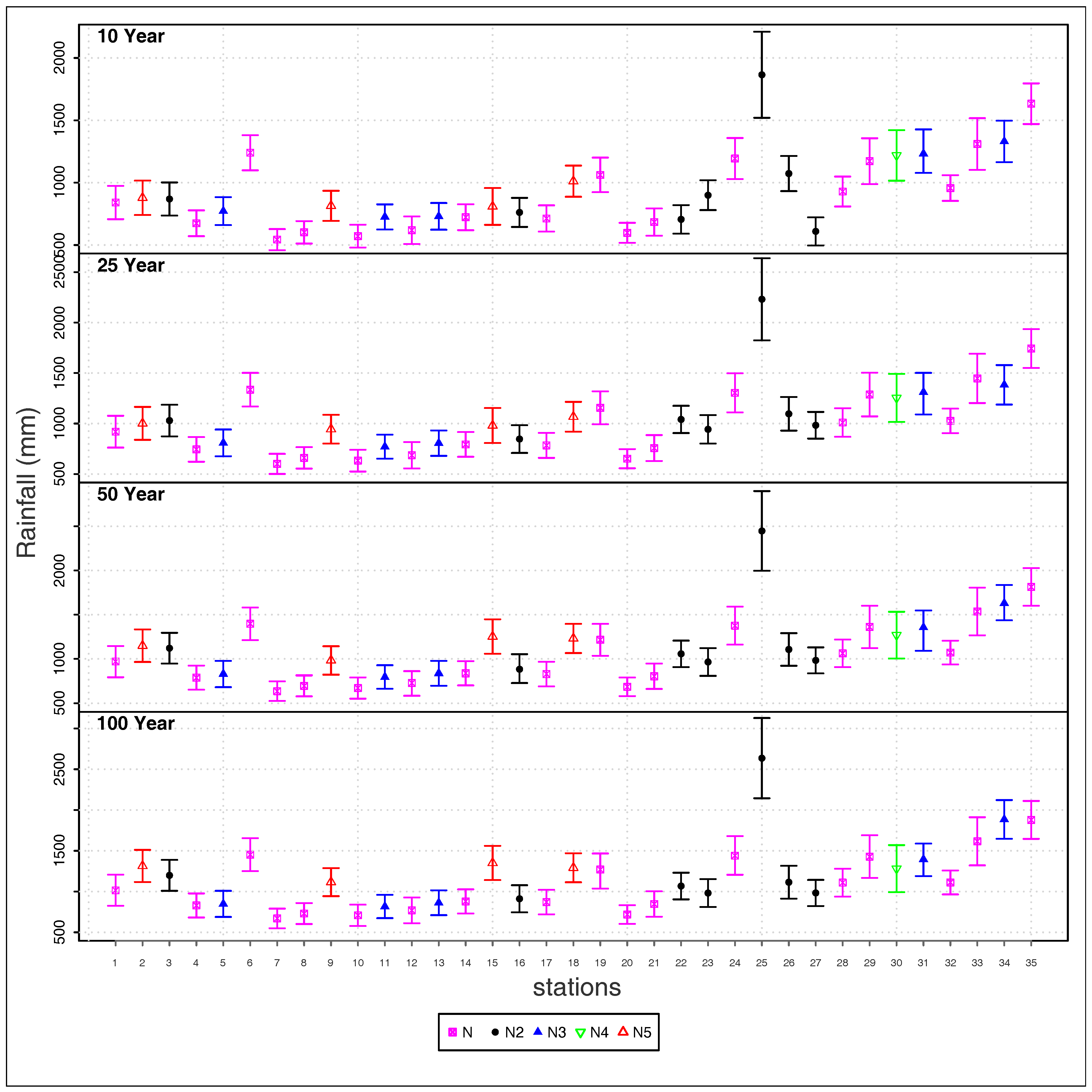
4.2. Return Period Results
4.3. Spatial Variability of Extremes
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Smith, R.L. Extreme value analysis of environmental time series: An application to trend detection in ground-level ozone. Stat. Sci. 1989, 4, 367–377. [Google Scholar] [CrossRef]
- Castillo, E.; Hadi, A.; Balakrishnan, N.; Sarabia, J. Extreme Value and Related Models with Applications in Engineering and Science, 1st ed.; John Wiley & Sons: New York, NY, USA, 2004; pp. 3–18. ISBN 0-471-67172-X. [Google Scholar]
- Longin, F. Extreme Events in Finance: A Handbook of Extreme Value Theory and Its Applications; John Wiley & Sons: Hoboken, NJ, USA, 2016; pp. 1–10. ISBN 1118650190. [Google Scholar]
- Katz, R.; Parlange, M.; Naveau, P. Statistics of extremes in hydrology. Adv. Water Resour. 2002, 25, 1287–1304. [Google Scholar] [CrossRef]
- Smith, R.L. Extreme values. In Environmental Statistics; Department of Statistics, University of North Carolina: Chapel Hill, NC, USA, 2001; pp. 300–357. Available online: www.stat.unc.edu/postscript/rs/envnotes.pdf (accessed on 26 February 2018).
- Coles, S. An Introduction to Statistical Modeling of Extreme Values, 1st ed.; Springer: London, UK, 2001; pp. 1–72. ISBN 978-1-84996-874-4. [Google Scholar]
- MacDonald, A.; Scarrott, C.J.; Lee, D.; Darlow, B.; Reale, M.; Russell, G. A flexible extreme value mixture model. Comput. Stat. Data Anal. 2011, 55, 2137–2157. [Google Scholar] [CrossRef]
- Wilks, D.S. Comparison of three-parameter probability distributions for representing annual extreme and partial duration precipitation series. Water Resour. Res. 1993, 29, 3543–3549. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Basford, K.E. Mixture Modelss: Inference and Applications to Clustering, 1st ed.; Marcel Dekker, Inc.: New York, NY, USA, 1987; pp. 1–8. ISBN 0-8247-7691-7. [Google Scholar]
- McLachlan, G.J.; Peel, D. Finite Mixture Models, 1st ed.; John Wiley & Sons: New York, NY, USA, 2000; pp. 1–19. ISBN 0-471-00626-2. [Google Scholar]
- Zhuang, X.; Huang, Y.; Palaniappan, K.; Zhao, Y. Gaussian Mixture Density Modeling, Decomposition, and Applications. IEEE Trans. Image Process. 1996, 5, 1293–1302. [Google Scholar] [CrossRef] [PubMed]
- Reyonlds, D. Gaussian mixture models. In Encyclopedia of Biometrics, 2nd ed.; Li, S.Z., Jain, A.K., Eds.; Springer: New York, NY, USA, 2007; pp. 827–832. ISBN 978-1-4899-7487-7. [Google Scholar]
- Lee, K.J.; Guillemot, L.; Yue, Y.L.; Kramer, M.; Champion, D.J. Application of the Gaussian mixture model in pulsar astronomy—Pulsar classification and candidates ranking for the Fermi 2FGL catalogue. Mon. Not. R. Astron. Soc. 2012, 424, 2832–2840. [Google Scholar] [CrossRef]
- Gregor, J. An algorithm for the decomposition of a distribution into Gaussian components. Biometrics 1969, 25, 79–93. [Google Scholar] [CrossRef] [PubMed]
- Wirjanto, T.S.; Xu, D. The Applications of Mixtures of Normal Distributions in Empirical Finance: A Selected Survey; Working Paper; University of Waterloo: Waterloo, ON, Canada, 2009. [Google Scholar]
- He, J. Mixed model based multivariate statistical analysis of multiply censored environmental data. Adv. Water Resour. 2013, 59, 14–24. [Google Scholar] [CrossRef]
- Diehli, T.; Potter, K.W. Mixed flood distribution in Wisconsin. In Hydrologic Frequency Modeling; Singh, V.P., Ed.; Springer: Dordrecht, The Netherlands, 1987; pp. 213–226. [Google Scholar]
- Fan, Y.R.; Huang, W.W.; Huang, G.H.; Li, Y.P.; Huang, K.; Li, Z. Hydrologic risk analysis in the Yangtze River basin through coupling Gaussian mixtures into copulas. Adv. Water Resour. 2016, 88, 170–185. [Google Scholar] [CrossRef]
- Vrac, M.; Naveau, P. Stochastic downscaling of precipitation: From dry events to heavy rainfalls. Water Resour. Res. 2007, 43, W07402. [Google Scholar] [CrossRef]
- Furrer, E.M.; Katz, R.W. Improving the simulation of extreme precipitation events by stochastic weather generators. Water Resour. Res. 2008, 44, W12439. [Google Scholar] [CrossRef]
- Hundecha, Y.; Pahlow, M.; Schumann, A. Modeling of daily precipitation at multiple locations using a mixture of distributions to characterize the extremes. Water Resour. Res. 2009, 45, W12412. [Google Scholar] [CrossRef]
- Stendinger, J.R.; Vogel, R.M.; Foufoula-Georgiou, E. Frequency Analysis of Extreme Events. In Handbook of Hydrology, 1st ed.; Maidment, D.A., Ed.; McGraw-Hill: New York, NY, USA, 1993; Chapter 18; ISBN 0070397325. [Google Scholar]
- Alam, M.A.; Emura, K.; Farnham, C.; Yuan, J. Best-Fit Probability Distributions and Return Periods for Maximum Monthly Rainfall in Bangladesh. Climate 2018, 6, 9. [Google Scholar] [CrossRef]
- Tan, K.; Chu, M. Estimation of Portfolio Return and Value at Risk using a class of Gaussian Mixture Distributions. Int. J. Bus. Financ. Res. 2012, 6, 97–107. [Google Scholar]
- Hass, M. Value-at-Risk via mixture distributions reconsidered. Appl. Math. Comput. 2009, 215, 2103–2119. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2008; pp. 1–40. ISBN 978-0-471-20170-0. [Google Scholar]
- Gumbel, E.J. The return period of flood flows. Ann. Math. Stat. 1941, 12, 163–190. [Google Scholar] [CrossRef]
- Thomas, H.A. Frequency of minor floods. J. Boston Soc. Civ. Eng. 1949, 35, 425–442. [Google Scholar]
- Benjamin, J.R.; Cornell, C.A. Probability, Statistics, and Decision for Civil Engineers, 1st ed.; McGraw-Hill: New York, NY, USA, 1970; pp. 232–235. ISBN 978-0-486-78072-6. [Google Scholar]
- Eslamian, S.S.; Feizi, H. Maximum Monthly Rainfall Analysis Using L-Moments for an Arid Region in Isfahan Province, Iran. J. Appl. Meteorol. Climatol. 2007, 46, 494–503. [Google Scholar] [CrossRef]
- Ahsan, M.N.; Chowdhary, M.A.M.; Quadir, D.A. Variability and rends of summer monsoon rainfall over Bangladesh. J. Hydrol. Meteorol. 2010, 7, 1–17. [Google Scholar] [CrossRef]
- Kapur, J.N. Maximum-Entropy Models in Science and Engineering, 1st ed.; Wiley Eastern Limited: New Delhi, India, 1989; pp. 44–47. ISBN 81-224-0216-X. [Google Scholar]
- Christopher, M.B. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, NY, USA, 2016; pp. 430–439. ISBN 978-0387-31073-2. [Google Scholar]
- Everitt, B.S.; Hand, D.J. Finite Mixture Distributions, 1st ed.; Chapman and Hall: London, UK, 1981; pp. 25–57. ISBN 0-412-22420-8. [Google Scholar]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Proceeding in the Second International Symposium on Information Theory; Petrov, B.N., Caski, F., Eds.; Akademiai Kiado: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Graedel, T.E.; Kleiner, B. Exploratory analysis of atmospheric data. In Probability, Statistics and Decision Making in the Atmospheric Sciences, 1st ed.; Murphy, A.H., Katz, R.W., Eds.; Westview: Boulder, CO, USA, 1985; pp. 1–43. ISBN 0865311528. [Google Scholar]
- Yen, B.C. Risks in hydrologic design of engineering projects. J. Hydraul. Div. Am. Soc. Civ. Eng. 1970, 96, 959–965. [Google Scholar]
- Sarker, A.A.; Rashid, A.K.M.M. Landslide and Flashflood in Bangladesh. In Disaster Risk Reduction Approaches in Bangladesh; Shaw, R., Mallick, F., Islam, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 165–189. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| St.No | Station Name | Elevation (m) | Missing Values (%) | Observed Period | St.No | Station Name | Elevation (m) | Missing Values (%) | Observed Period |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Sydpur | 45 | 0 | 1991–2013 | 19 | Maijdi Court | 9 | 0.41 | 1984–2013 |
| 2 | Rangpur | 34 | 0 | 1984–2013 | 20 | Satkhira | 6 | 0 | 1984–2013 |
| 3 | Dinajpur | 37 | 0.03 | 1984–2013 | 21 | Khulna | 4 | 0.28 | 1984–2013 |
| 4 | Bogra | 20 | 0.05 | 1984–2013 | 22 | Barisal | 4 | 0.05 | 1984–2013 |
| 5 | Mymensingh | 19 | 0 | 1984–2013 | 23 | Bhola | 5 | 0.05 | 1984–2013 |
| 6 | Sylhet | 35 | 0.07 | 1984–2013 | 24 | Sitakunda | 4 | 0.24 | 1984–2013 |
| 7 | Rajshahi | 20 | 0.14 | 1984–2013 | 25 | Sandwip | 6 | 1.58 | 1984–2013 |
| 8 | Tangail | 10 | 0.07 | 1987–2013 | 26 | Rangamati | 63 | 0.05 | 1984–2013 |
| 9 | Srimangal | 43 | 1.19 | 1984–2013 | 27 | Mongla | 4 | 0 | 1991–2013 |
| 10 | Ishurdi | 14 | 0.14 | 1984–2013 | 28 | Patuakhali | 3 | 0 | 1984–2013 |
| 11 | Dhaka | 9 | 0.03 | 1984–2013 | 29 | Hatiya | 4 | 15.18 | 1984–2013 |
| 12 | Chuadanga | 12 | 0.92 | 1989–2013 | 30 | Ambagan | 21 | 0 | 1999–2013 |
| 13 | Faridpur | 9 | 0 | 1984–2013 | 31 | Chittagong | 6 | 13.86 | 1984–2013 |
| 14 | Comilla | 12 | 0.06 | 1984–2013 | 32 | Khepupara | 3 | 0.34 | 1984–2013 |
| 15 | Chandpur | 7 | 0.14 | 1984–2013 | 33 | Kutubdia | 6 | 0.15 | 1985–2013 |
| 16 | Jessore | 7 | 0 | 1984–2013 | 34 | Cox’s Bazar | 4 | 0.32 | 1984–2013 |
| 17 | Madaripur | 5 | 0.02 | 1984–2013 | 35 | Teknaf | 4 | 0.06 | 1984–2013 |
| 18 | Feni | 8 | 0.34 | 1984–2013 |
| St.No | Station Name | Best-Fit Statistic Results | Highest Ranked Distribution (Sum of Ranks) | ||
|---|---|---|---|---|---|
| AIC | BIC | RMSPE | |||
| 1 | Sydpur | N (304.89) | N (307.16) | N5 (3.36) | N (7) |
| 2 | Rangpur | N5 (374.15) | N5 (393.76) | N5 (1.76) | N5 (3) |
| 3 | Dinajpur | N2 (395.76) | N2 (402.77) | N4 (2.64) | N2 (6) |
| 4 | Bogra | N (389.22) | N (392.02) | N5(3.34) | N (6) |
| 5 | Mymensingh | N3 (381.7) | N3 (392.91) | N5(1.52) | N3 (4) |
| 6 | Sylhet | N (407.99) | N (410.79) | N4(1.37) | N (7) |
| 7 | Rajshahi | N4 (375.9) | N (379.96) | N3 (2.61) | N (6) |
| 8 | Tangail | N (340.42) | N (343.01) | N2 (1.31) | N (4) |
| 9 | Srimangal | N5 (375.67) | N5 (395.29) | N5 (1.78) | N5 (3) |
| 10 | Ishurdi | N (382.11) | N (384.91) | N5(2.51) | N (5) |
| 11 | Dhaka | N3 (384.59) | N (390.43) | N5 (1.89) | N3 (6) |
| 12 | Chuadanga | N (323.73) | N (326.17) | N5(2.84) | N (6) |
| 13 | Faridpur | N3 (381.59) | N2 (392.48) | N4 (1.8) | N3 (5) |
| 14 | Comilla | N (389.59) | N (392.39) | N5(1.29) | N (5) |
| 15 | Chandpur | N5 (378.87) | N5 (398.48) | N5 (1.96) | N5 (3) |
| 16 | Jessore | N2 (392.14) | N2 (399.15) | N5 (1.87) | N2 (6) |
| 17 | Madaripur | N (390.4) | N (393.2) | N4(1.34) | N (5) |
| 18 | Feni | N5 (375.52) | N5 (395.14) | N5 (2.84) | N5 (3) |
| 19 | Maijdi Court | N5 (402.56) | N (409.5) | N5(0.91) | N (7) |
| 20 | Satkhira | N5 (371.38) | N (376.98) | N4(1.6) | N (7) |
| 21 | Khulna | N5 (389.96) | N (395.13) | N2 (2.1) | N (6) |
| 22 | Barisal | N2 (381.6) | N2 (388.6) | N2 (2.77) | N2 (3) |
| 23 | Bhola | N2 (394.57) | N (400.75) | N5 (2.07) | N2 (5) |
| 24 | Sitakunda | N (417.13) | N (419.93) | N5 (1.69) | N (7) |
| 25 | Sandwip | N3 (427.37) | N3 (438.31) | N2 (−3.35) | N2 (5) |
| 26 | Rangamati | N2 (402.14) | N2 (409.15) | N4 (2.85) | N2 (5) |
| 27 | Mongla | N2 (261.95) | N2 (267.63) | N2 (3.85) | N2 (3) |
| 28 | Patuakhali | N (398.24) | N (401.04) | N3(1.51) | N (5) |
| 29 | Hatiya | N (363.83) | N (366.34) | N5 (3.75) | N (7) |
| 30 | Ambagan | N4 (183.44) | N4 (191.23) | N5 (2.03) | N4 (4) |
| 31 | Chittagong | N3 (355.94) | N (363.86) | N5 (1.69) | N3 (6) |
| 32 | Khepupara | N (389.05) | N (391.86) | N4 (1.62) | N (6) |
| 33 | Kutubdia | N2 (409.68) | N2 (416.52) | N2(4.18) | N2 (3) |
| 34 | Cox’s Bazar | N5 (368.89) | N3 (388.22) | N4 (1.07) | N3 (6) |
| 35 | Teknaf | N (416.61) | N (419.41) | N3 (1.28) | N (7) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alam, M.A.; Farnham, C.; Emura, K. Best-Fit Probability Models for Maximum Monthly Rainfall in Bangladesh Using Gaussian Mixture Distributions. Geosciences 2018, 8, 138. https://doi.org/10.3390/geosciences8040138
Alam MA, Farnham C, Emura K. Best-Fit Probability Models for Maximum Monthly Rainfall in Bangladesh Using Gaussian Mixture Distributions. Geosciences. 2018; 8(4):138. https://doi.org/10.3390/geosciences8040138
Chicago/Turabian StyleAlam, Md Ashraful, Craig Farnham, and Kazuo Emura. 2018. "Best-Fit Probability Models for Maximum Monthly Rainfall in Bangladesh Using Gaussian Mixture Distributions" Geosciences 8, no. 4: 138. https://doi.org/10.3390/geosciences8040138
APA StyleAlam, M. A., Farnham, C., & Emura, K. (2018). Best-Fit Probability Models for Maximum Monthly Rainfall in Bangladesh Using Gaussian Mixture Distributions. Geosciences, 8(4), 138. https://doi.org/10.3390/geosciences8040138