1. Introduction
According to the American Cancer Society, Prostate Cancer (PCa) is the most common type of cancer in Western men [
1]; in 2018, approximately 1.3 million new cases were diagnosed and 359,000 related deaths occurred worldwide [
2]. Despite its incidence and societal impact, the current diagnostic techniques—i.e., Digital Rectal Exam, Prostate-Specific Antigen (PSA) [
3]—may be subjective and error-prone [
4]. Furthermore, intra-tumor heterogeneity is observed in PCa, contributing to disease progression [
5].
Currently, high-resolution multiparametric Magnetic Resonance Imaging (mpMRI) for Computer-Aided Diagnosis (CAD) is gaining clinical and scientific interest [
6] by enabling quantitative measurements for intra- and inter-tumoral heterogeneity based on radiomics studies [
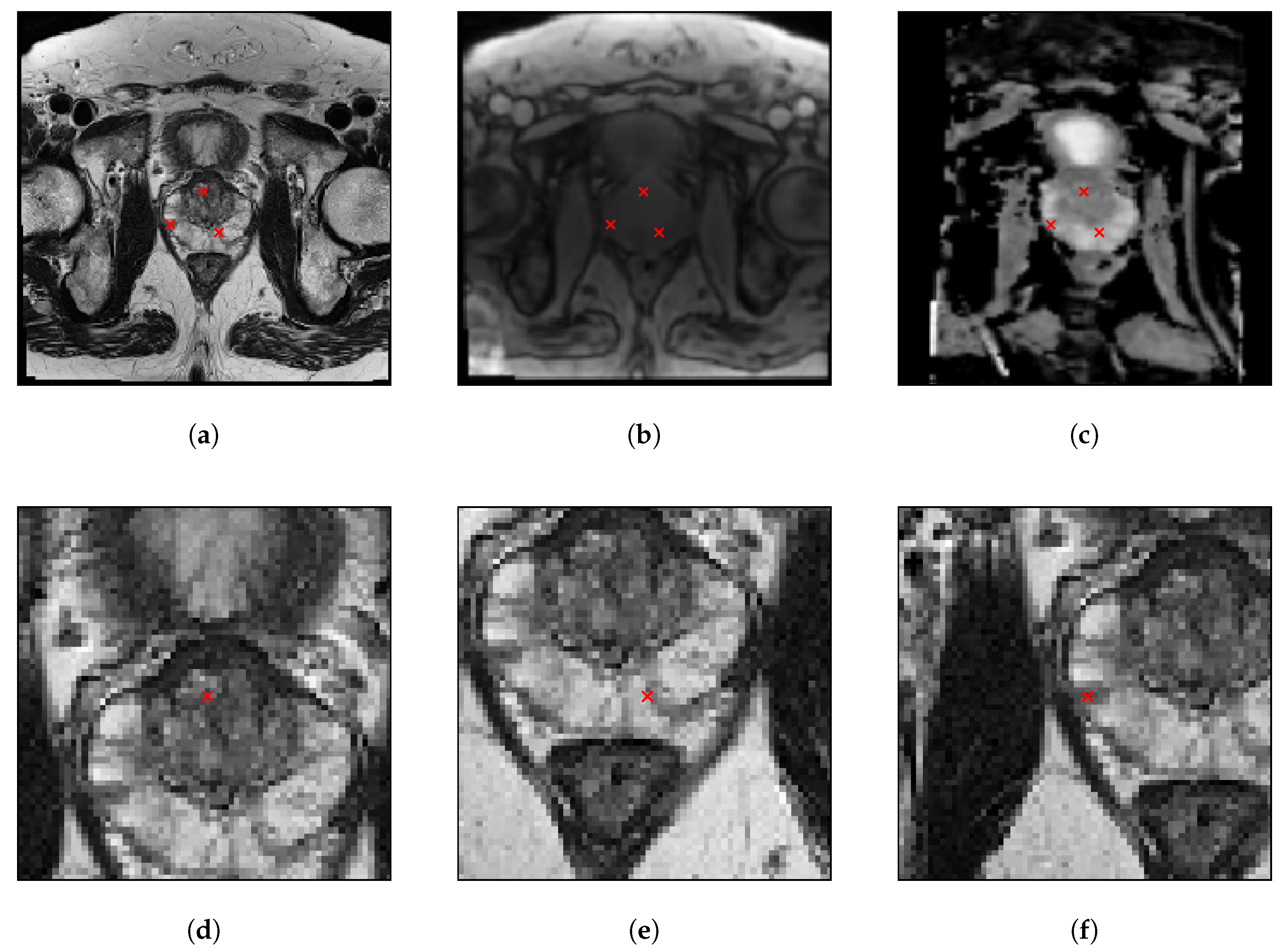
7]. Additional and often complementary information can be acquired by means of different MRI sequences: anatomical information can be obtained using T2-weighted (T2w), T1-weighted (T1w) and Proton Density (PDw) protocols [
4,
8,
9]. Further information is conveyed by functional imaging [
10], allowing for better depiction of multiple aspects of the tumor structure: its micro-environment by estimating the water molecule movement using Diffusion-Weighted Imaging (DWI) and the derived Apparent Diffusion Coefficient (ADC) maps [
11], as well as the vascular structure of the tumor with Dynamic Contrast-Enhanced (DCE) MRI [
12]. Unfortunately, multi-focal tumors in the prostate occur commonly, posing additional challenges for accurate prognoses on MRI [
13]; thus, devising and exploiting advanced Machine Learning methods [
14,
15] for prostate cancer detection and differentiation is clinically relevant [
16].
Therefore, the tasks of PCa classification can benefit from the combination of several modalities, each conveying clinically useful information [
8,
17]. Clinical consensus for PCa diagnosis typically considers mpMRI by combining T2w with at least two functional imaging protocols [
18]. In this work, T2w, PDw and ADC MRI sequences were chosen as inputs for the models. T2w conveys relevant information about the prostate zonal anatomy [
15] as well as tumor location and extent [
19]: PCa has low signal intensity, which can be suitably detected from the healthy hyper-intense peripheral zone tissue (harboring approximately 70% of PCa cases [
20]), but it is more difficult to differentiate in the central and transitional zones due to their normal low signal intensity [
4,
8].
PDw, by quantifying the amount of water protons contributing to each voxel [
9], provides a good distinction between fat and fluid [
21]. ADC yields a quantitative map of the water diffusion characteristics of the prostatic tissue: PCa typically has packed and dense regions with intra- and inter-cellular membranes that influence water motion [
4,
8]. Lastly, DCE sequences depict the patient’s vascular system in detail, since tumors exhibit a highly vascularized micro-environment, by exploiting a Gadolinium-based contrast medium [
22].
In Deep Learning applications to medical image analysis, some challenges are still present [
23]; namely, (i) the lack of large training data sets, (ii) the absence of reliable ground truth data, and (
iii) the difficulty in training large models [
24]. Nonetheless, some factors are consistently present in successful models [
25]: expert knowledge, novel data preprocessing or augmentation techniques, and the application of task-specific architectures.
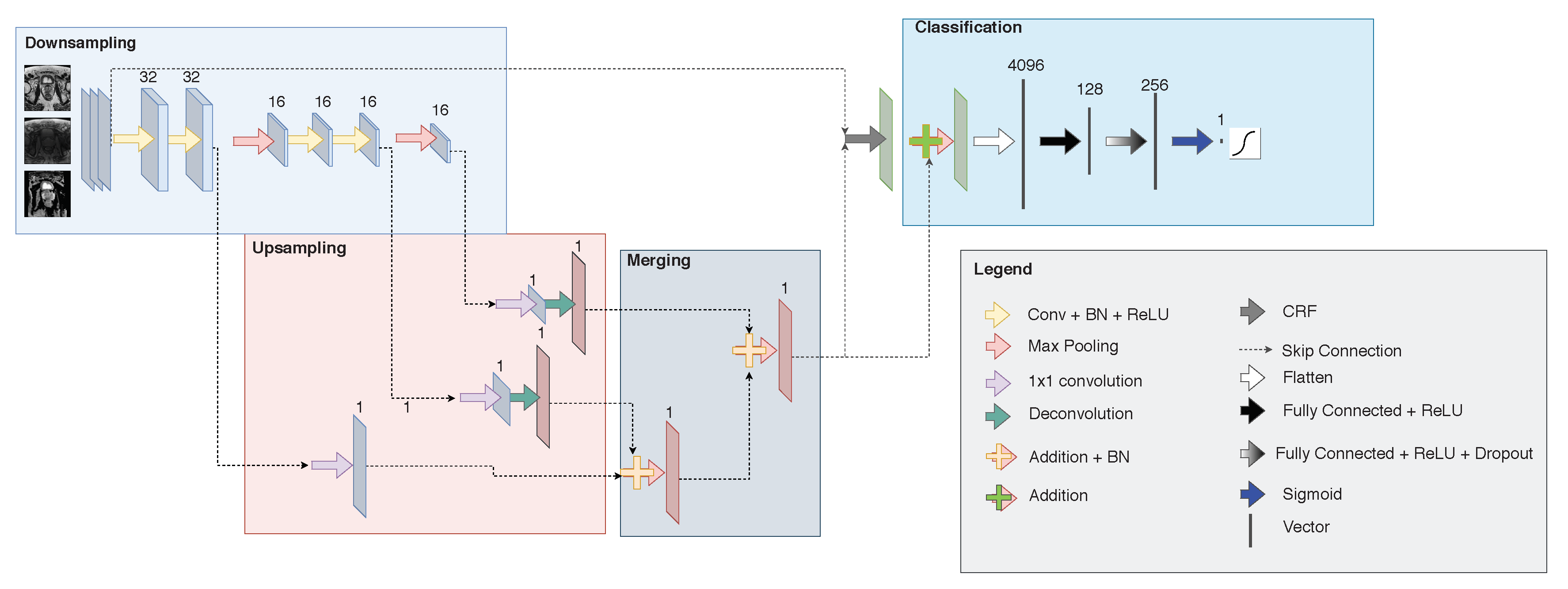
Despite the growing interest in developing novel models for the task of PCa, little effort has been devoted to the addition of new types of layers. Recently, the Semantic Learning Machine (SLM) [
26,
27,
28] neuroevolution algorithm was successfully employed to replace the backpropagation algorithm commonly used in the Fully-Connected (FC) layers of Convolutional Neural Networks (CNNs) [
29,
30]. When compared with backpropagation, SLM achieved higher classification accuracy in PCa detection as well as a training speed-up of one order of magnitude. A CNN architecture developed for the classification task is typically composed of regular layers, which perform convolutions, dot products, batch normalization, or pooling operations. This work integrates a Conditional Random Field (CRF) model as a Recurrent Neural Network (RNN) [
31], generally exploited in segmentation, to the PCa classification problem. In accord with the latest clinical trends aiming at decreasing contrast medium usage [
4], we analyzed only the non-contrast-enhanced mpMRI sequences to assess also the feasibility of our methodology from a patient safety and health economics perspective [
32].
Research Questions.
We specifically address two questions:
Contributions.
Our main contributions are the following:
In particular, the proposed approach aimed at outperforming XmasNet, a network specifically created for dealing with prostate cancer MRI data. This network is the most state-of-the-art for this kind of application. Thus, outperforming it would be a valuable contribution in the medical field, as it shows how the integration of CRFs in XmasNet could improve the performance of the commonly used XmasNet architecture.
The manuscript is organized as follows.
Section 2 introduces the theoretical foundations of CRFs and the Deep Neural Network (DNN) architectures underlying the devised method.
Section 3 presents the characteristics of the analyzed prostate mpMRI dataset, as well as the proposed method.
Section 4 shows and critically analyzes the achieved experimental results. Finally,
Section 5 concludes the paper and suggests future research avenues.
4. Results
This section presents and discusses the achieved experimental results. The best performing configuration of each architecture is shown in
Table 5. These results suggest that the choice of the parameters is strictly related to the considered architecture, and it is something that must be taken into account before tackling the PCa classification problem.
Table 6 reports the average values of loss and AUROC on the training and test sets, allowing for a comparative analysis of the different architectures considered in this study.
According to these results, AlexNet is the best architecture when considering the values of the loss function on the training instances, but it severely overfits the training data, as shown when considering the test set. On the training set, the second-best performer is XmasNet-CRFpp, but also for this architecture a severe amount of overfitting can be noticed when one focuses on the loss function on the test set. Still considering the training set, the third-best performer is VGG16, which also produces the lowest (i.e., the best) average loss function value on the test set. When comparing XmasNet and CRF-Xmasnet, it is worth noting that the two architectures produce similar values for the loss function on the training set, and they are the worst performers when compared against the other investigated architectures. When considering the values of the loss function produced by the networks that integrate CRFs into their basic architecture, one can notice that this combination achieves the worst (i.e., highest) values on the training set, but it allows us to reduce the amount of overfitting produced by some of the basic architectures. This is particularly evident when AlexNet and CRF-AlexNet are compared. In this case, CRF is actually working as a global regularizer.
More interesting experimental findings can be extracted when focusing on the AUROC values. In particular, AlexNet outperforms the remaining architectures on the training set, but due to the overfitting that affects the resulting model, its performance on the test set are significantly lower. More in detail, when considering the test set, VGG16 outperforms the other networks in terms of AUROC. When comparing the AUROC values obtained by XmasNet and CRF-XmasNet, the architecture with CRFs outperforms XmasNet on both the training and test instances. Additionally, the XmasNet-CRFpp architecture outperforms CRF-XmasNet and XmasNet on the training set, but its performance are the poorest on the test set. This behavior is aligned with the analysis performed by Zheng et al. [
31], in which the use of CRFs as a postprocessing step was compared against an end-to-end approach. With regard to CRF-AlexNet and CRF-VGG16, different behaviors can be noticed. While the use of CRFs with AlexNet is beneficial for reducing overfitting, as well as for obtaining a model with an AUROC on the test set that is higher compared to the baseline architecture (i.e., AlexNet), the effect on VGG16 is different. In particular, the use of CRFs within VGG16 causes moderate overfitting, thus producing a final model that is not able to outperform VGG16 on the test set. All in all, considering the architectures that use CRFs, it is possible to observe that they, on average, perform comparably on the test set. This could be explained with the regularization effect obtained by using CRFs, and it is an aspect that deserves future investigation to better understand the outstanding peak performance, along with the high-variability of the results, obtained via CRFs. While the analysis of the average values does not show a particular advantage in considering CRFs for solving the task at hand, a more in-depth analysis shows an interesting phenomenon. In particular,
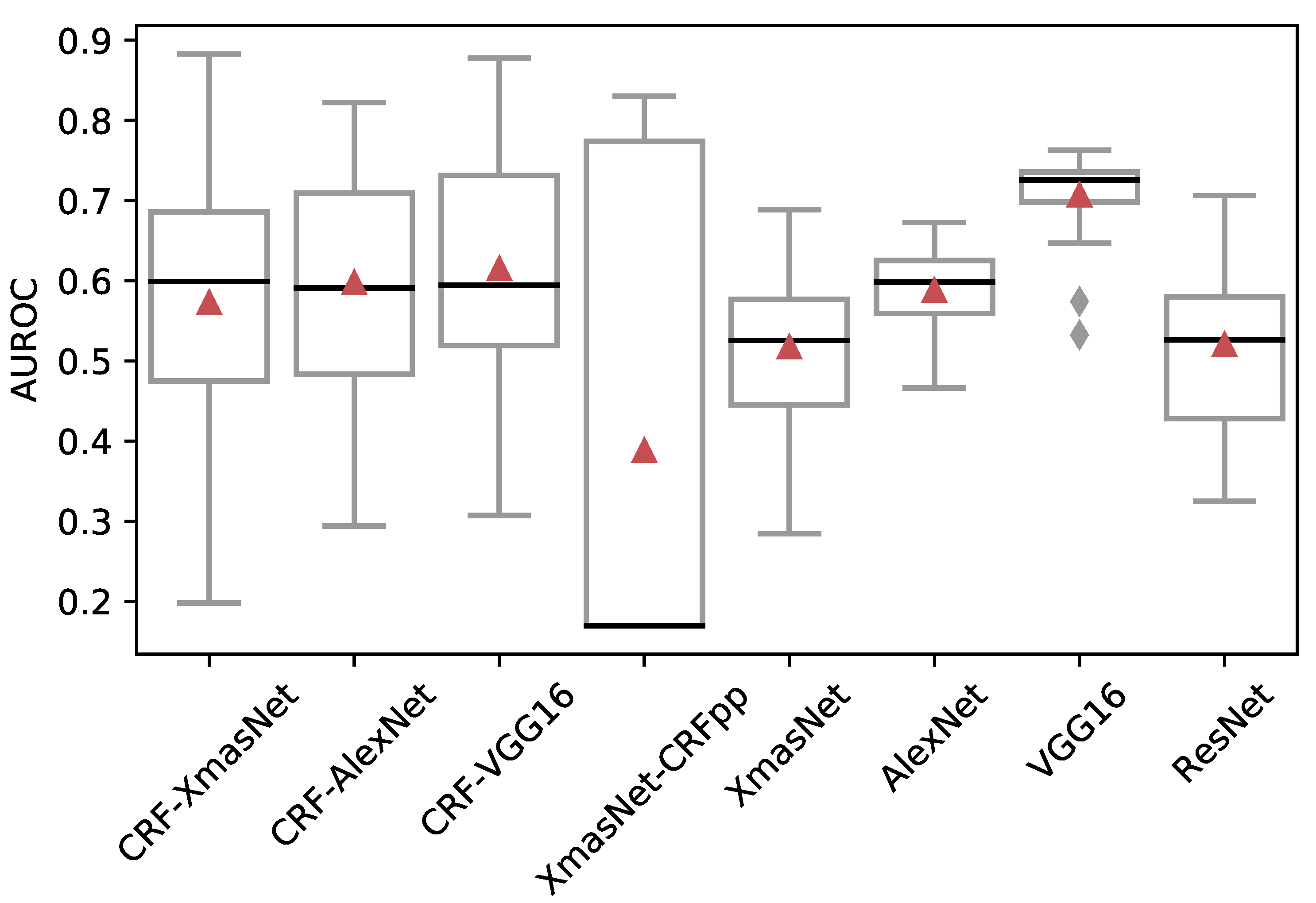
Figure 3 displays the boxplots of the AUROC on the test set for the proposed CRF-XmasNet, and the other considered architectures. According to these figures, it is interesting to note that the best performing model was obtained by using CRFs in the end-to-end approach. Additionally, all the architectures that integrate CRFs yielded the best peak performance (i.e., the highest AUROC values). Nonetheless, CRF-RNN presents a considerably higher variability in terms of both AUROC and BCE when compared against the other architectures. Thus, an additional systematic investigation must be dedicated to a better understanding of this experimental evidence. Being able to identify the reasons that lead to this high-variability may allow us to modify the training process to prevent this behavior and guide the training process towards the identification of a model with performance that cannot be achieved by the existing network architectures. We hypothesize that the batch size of 1 might cause the high-variability of the CNNs’ performance embedding CRF-RNNs. Unfortunately, due to the hardware limitations, we were not able to investigate the effect of this parameter on the performance of the network: the literature suggests that a small batch size value can result in a poor convergence of the model towards the global optima [
68]. Focusing on the differences between XmasNet-CRFpp and CRF-RNN, one can notice that the former architecture presents an even greater variability and, moreover, it produces worse performance when compared with the proposed CRF-RNN architecture. This fact highlights the importance of using CRFs in the end-to-end model, thus exploiting CRFs’ capabilities in leveraging feature relationships during the training process of the RNN.
From the analysis of the results, it is possible to draw some conclusions: focusing on the base architectures (i.e., without embedding the CRF-RNN), the very deep networks (i.e., VGG16 and AlexNet) are the best performers (both in terms of BCE and AUROC) when compared against the other state-of-the-art architectures (i.e., ResNet and XmasNet). The poor performance of ResNet may be justified by the reduced number of training images available for such a complex network. Lastly, there is an improvement between the CRF-XmasNet and XmasNet, as shown in the test sets (AUROC =
vs.
, respectively). Considering the CRF-RNN component, CRF-XmasNet is characterized by a high-variability of AUROC and BCE, but it showed superior performance compared to XmasNet and XmasNet-CRFpp. CRF-AlexNet provides comparable performance with respect to the baseline AlexNet architecture, while embedding the CRF-RNN component into VGG16 results in poorer performance (in terms of test AUROC) than the baseline VGG16 architecture. The high-variability of CRF-XmasNet (approximately
and
higher than those of XmasNet and VGG16, respectively) deserves an in-depth investigation. We might argue that this variability causes the performance differences to not be statistically significant, as shown in
Table 7, where the
p-values of the Wilcoxon test on paired data (with a significance level
) from the test AUROC metrics are provided. On the other hand, being able to understand the source of this variability could help in guiding the search process towards highly-performing models that are characterized by AUROC values that cannot be achieved by relying on the other state-of-the-art architectures. The same investigation regards CRF-AlexNet and CRF-VGG16 that also present high-variability in terms of performance. While several alternatives were tested to reduce this high-variability (i.e., batch normalization, different weight initialization or hyperparameters), no significant improvement was achieved without affecting the performance of the resulting network. However, despite this drawback, we believe that the use of CRF has potential. In particular, focusing on CRF-XmasNet, even with the introduction of an early stopping criterion that limits the training epochs to 50, the performance improved while the training time was naturally reduced. More specifically, CRF-XmasNet required (on average) a training time of
s (with a standard deviation of
s), while XmasNet required
s (with a standard deviation of
s). A Wilcoxon test (with a significance level
) was executed to statistically assess these results. A
p-value of
suggests that the difference (in terms of running time) between the two architectures is statistically significant.
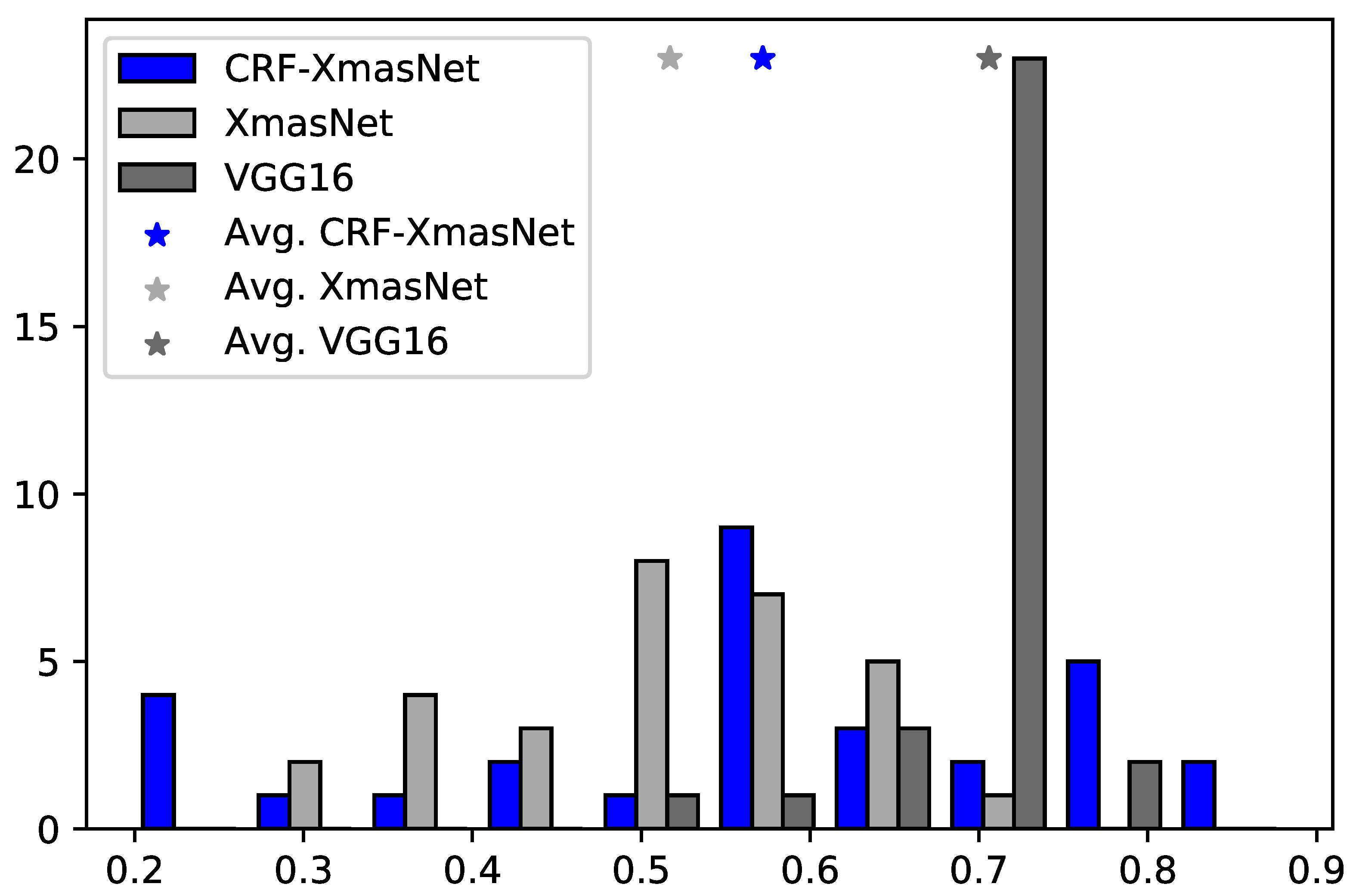
Lastly,
Figure 4 shows that, although CRF-XmasNet reveals unstable performance, it also achieved top-of-the-class performance when compared against the best competitor, VGG16. In particular:
in 8 out of 30 runs, the test AUROC of the CRF-XmasNet was higher than the best obtained with XmasNet;
the top 6 best performing runs, considering CRF-XmasNet and XmasNet, were achieved by CRF- XmasNet;
19 of the 30 CRF-XmasNet runs obtained a performance higher than their average value;
22 of the CRF-XmasNet runs outperformed the XmasNet average value.
Overall, the proposed approach provides satisfactory performance when compared against XmasNet, a state-of-the-art CNN architecture specifically designed for dealing with PCa mpMRI data. These results suggest the suitability of integrating CRF-RNN within XmasNet. While experimental results showed very good performance achieved by VGG16 and AlexNet, these results could be related to the reduced size of the PROSTATEx17 dataset [
69]. That is, considering a dataset with thousands of MRI studies, XmasNet might outperform the other competitors because it is specifically designed for extracting salient features from MRI data. Therefore, we believe that CRF-XmasNet provides an important contribution for practitioners in the medical imaging field, as it shows how the integration of CRFs into XmasNet outperforms the baseline XmasNet architecture.
5. Discussion and Conclusions
In this work, the potential of integrating the CRF-RNN mechanism into a CNN architecture is presented, not only for MIA applications but also for the Image Classification field in general-purpose Computer Vision. This joint approach is built upon previous work that has shown that the combination of CRFs and CNNs in a hybrid end-to-end model can achieve promising performance across several benchmark datasets in image segmentation tasks [
31,
47,
49,
51,
52,
70]. The proposed CRF-XmasNet architecture leads to an interesting improvement over its baseline architecture (XmasNet [
33]), and its best performance is comparable with the one obtained with deeper neural architectures, namely: AlexNet [
34], VGG16 [
44], and ResNet [
45]. Additionally, our work showed that the use of CRFs as a postprocessing method is not suitable for the classification problem taken into account. This result corroborates the analysis reported in [
31]. CRF-RNN can achieve competitive performance by also reducing the training time when compared against the baseline architecture. Despite these advantages, the integration of CRFs produces results characterized by a higher variability when compared against the other considered architectures. This phenomenon was observed also when the CRF-RNN component was integrated into AlexNet and VGG16. In this case, the two resulting architectures (i.e., CRF-AlexNet and CRF-VGG16) were characterized by high-variability of performance on both training and test sets.
The amount of homogeneous and well-prepared datasets represents an important challenge in biomedical imaging [
24]. As a matter of fact, Deep Learning research has been recently focusing on issues related to medical imaging datasets with limited sample size, achieving promising performance by means of weakly-/semi-supervised schemes [
49,
71] as well as Generative Adversarial Network (GAN)-based data augmentation [
72,
73]. Moreover, methods tailored to each particular clinical application should be devised, such as for improving the model generalization abilities even in the case of small datasets collected from multiple institutions [
15].
Given the common ground that the Machine Learning and Image Classification fields share, more promising and robust performance may be achieved by the further integration of CRFs into CNNs. For instance, CNN architecture tuning [
74] might reduce the variability encountered in the experiments involving CRF-XmasNet and the other CNNs embedding CRFs. This contribution can open additional research directions aimed at investigating the performance variability of the CRF-RNNs when integrated into CNNs as an end-to-end approach, thus allowing for their use in a clinical environment.
In conclusion, the proposed end-to-end PCa detection approach might be used as a CAD, before the conventional mpMRI interpretation by experienced radiologists, aiming at increasing sensitivity and reducing operator dependence upon multiple readers [
6]. To improve CS PCa classification performance, the combination with metabolic imaging might provide complementary clinical insights into tumor responses to oncological therapies [
75]. Novel nuclear medicine tracers for Positron Emission Tomography (PET) [
76] and hyperpolarized carbon-13 (
13C) and sodium (
23Na) MRI [
77] can considerably improve the specificity for evaluating PCa with respect to conventional imaging, by understanding the pyruvate conversion to lactate for estimating the cancer grade [
78]. From a computational perspective, novel solutions must be devised to combine multi-modal imaging data [
79]. In the case of DNNs, a topology explicitly designed for information exchange—between sub-networks processing the data from a single modality—through cross-connections, such as in the case of cross-modal CNNs (X-CNNs) [
80], might be suitable for combining multi-modal imaging data.









{kind=link}
{kind=link}
{kind=link}
{kind=link}