Off-Grid Power Plant Load Management System Applied in a Rural Area of Africa



Abstract
:1. Introduction
- As the proposed predictor is employed to forecast the electrical load of an off-grid power plant applied in a rural area of Africa, to improve the prediction accuracy in real-time processes and reduce the training cost, the proposed predictor is combined with an autoregressive integrated moving average (ARIMA) approach and the Bayesian information criterion (BIC), where BIC is used to achieve automatic model optimization in each step.
- The proposed anomaly detector integrates a support vector machine (SVM), the fruit fly optimization algorithm (FOA), and the cross-entropy loss function to create an independent and sample efficient detection approach to assess the correctness of load data.
- In this paper, a comprehensive analysis of the comparison results is proposed, and the practicability of each model in both prediction and detection is explained and discussed in detail, which provides a reference value for follow-up research.
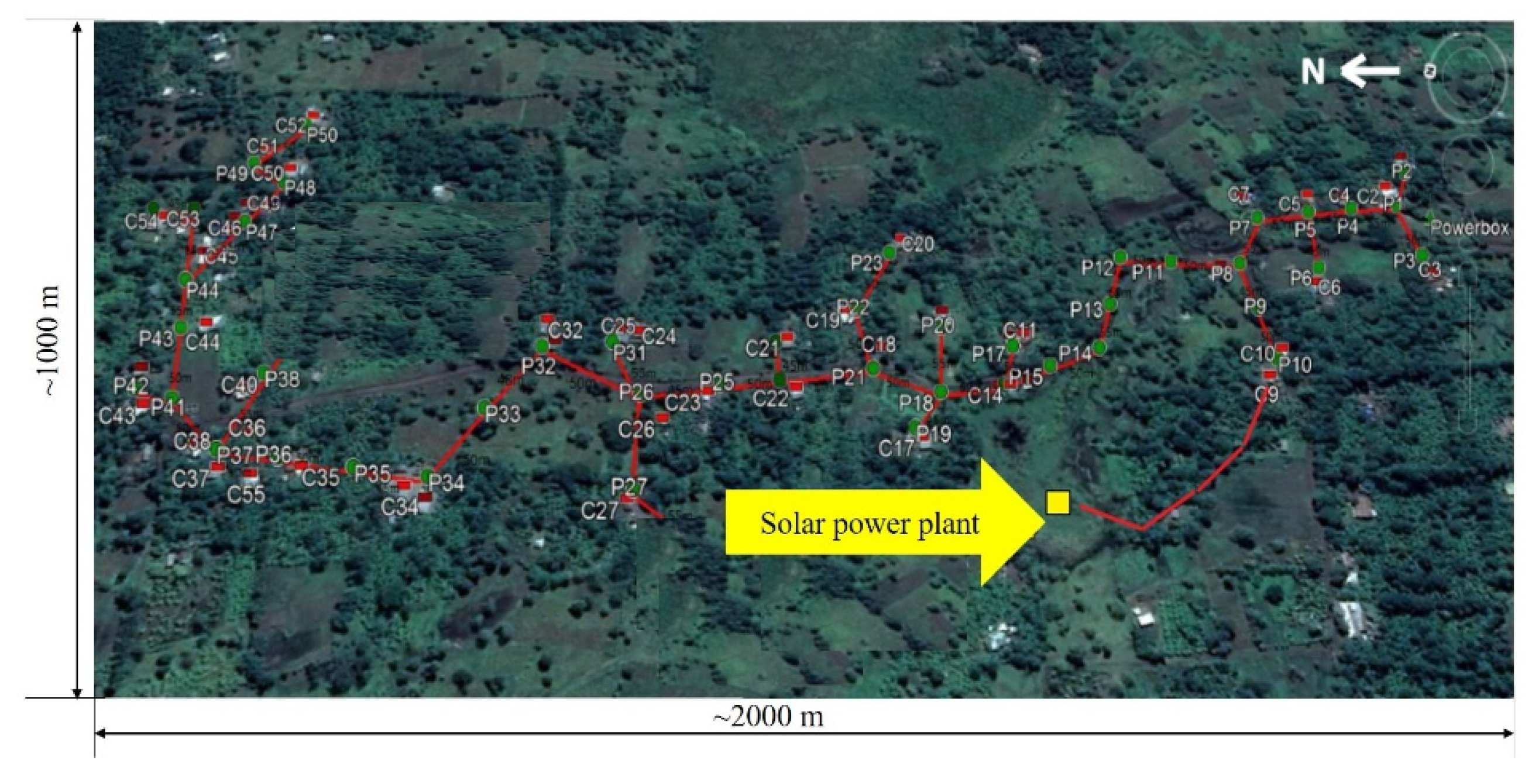
- Our method is applied to detect the load of a standalone solar power plant in rural areas in Tanzania with more than 50 households (longitude: 36.908853, latitude −3.323141). The proposed system not only ensures the security of this power plant, but also brings the possibility of providing uninterrupted energy.
2. Related Work
3. System Overview
Routine Analysis
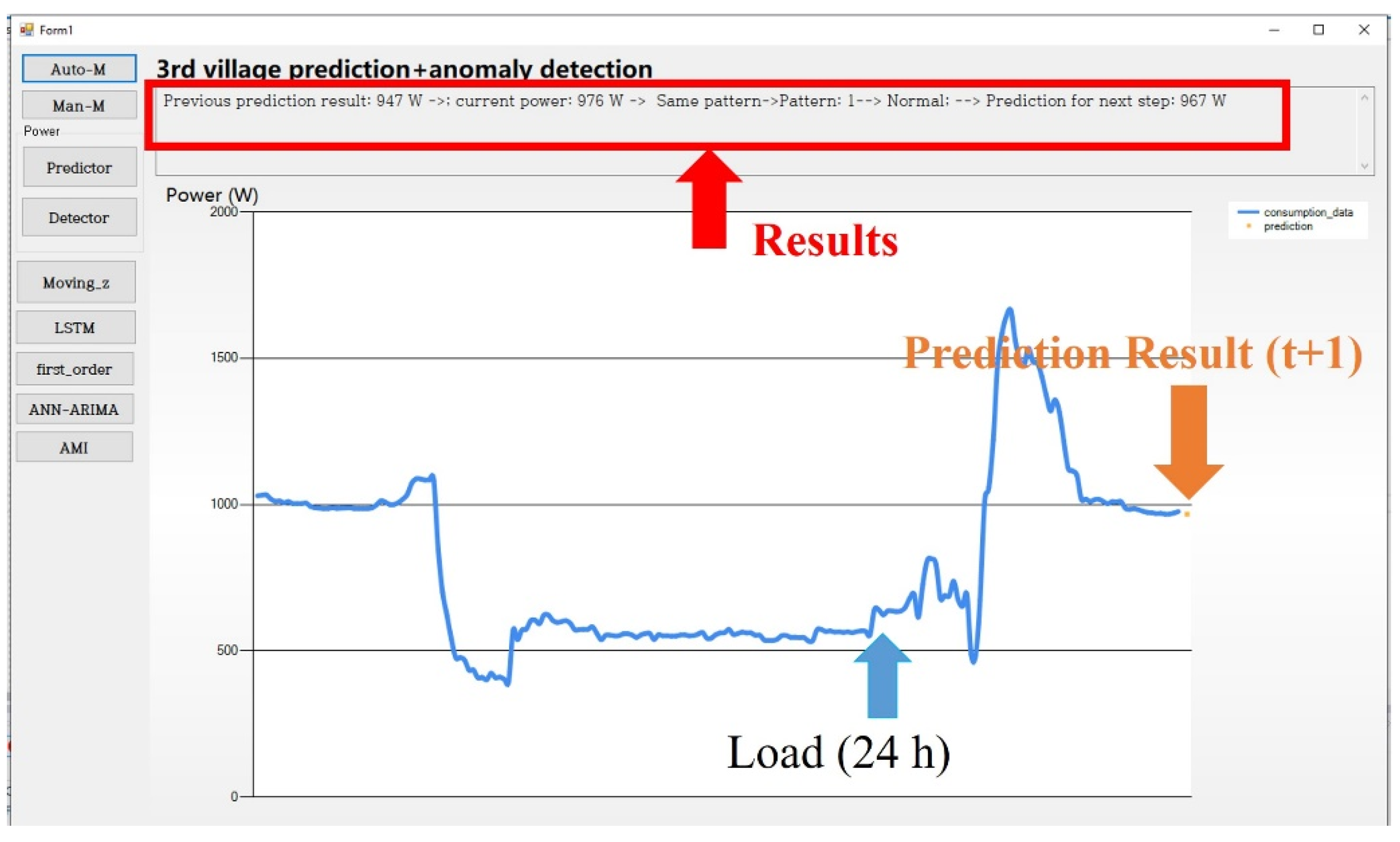
4. Real-Time Load Predictor
5. Pattern Matching-Based Load Anomaly Detector
5.1. Benign Data Training
5.2. Pattern Matching Scheme
5.2.1. Result Pattern Matching
Fruit Fly Optimization Algorithm
- Step 1.
- Randomly initialize the following parameters: initial location of fly {, }, maximum iteration number , population size , and random flight distance range .
- Step 2.
- Give the random flight direction and the distance for food searching for each individual fruit fly in a swarm.
- Step 3.
- Initially, the food cannot be seen; therefore, the distance to the origin is estimated (Dist), and the smell concentration judgment value (S) is calculated, which is the reciprocal of the distance:
- Step 4.
- Substitute the smell concentration judgment value (S) into the smell concentration judgment function to determine the smell concentration (Smelli) for a given location of the fruit fly:
- Step 5.
- The fruit fly with the maximum smell concentration among those in a fruit fly group is screened:
- Step 6.
- The best smell concentration value and coordinate (X, Y) are retained. The fruit fly group will use vision to fly toward this location:
- Step 7.
- Repeat the implementation of Steps 2–5 and then determine if the smell concentration is superior to the previous iterative smell concentration; if so, implement Step 6.
Fruit Fly Optimization Algorithm for Optimal Penalty Factor Selection of SVM
- Step 1.
- Generate the initial parameters: {, }, maximum iteration number , population size , and random flight distance range . Set the iteration variable t = 0, and perform the training process from Step 2 to Step 6.
- Step 2.
- Set the iteration variable: t = t + 1.
- Step 3.
- There are three substeps for this step.
- Step 3.1.
- Calculate the flight distance of food searching for fruit fly i, and calculate the smell concentration judgment value.
- Step 3.2.
- Input Si into the SVM to learn the training data (the processed data obtained in the benign data training phase). Use the trained SVM to reclassify the training data and obtain the prediction result series .
- Step 3.3.
- Compare the prediction result series with the real labeling of the training data . Calculate the smell concentration Smelli. The smell concentration judgment function used here is an accumulation function. L is the length of ; therefore, u ranges from 0 to L, and the function compares each term in the prediction result series with the real label of the training data . Initialize an initial integer a = 0; when , a = a + 1. Finally, return a as the smell concentration Smelli.
- Step 4.
- The offspring are generated according to Equations (4)–(6). Then, the offspring are input into the SVM, and the smell concentration value is recalculated.
- Step 5.
- If t = , the stop criterion is satisfied, and the best penalty factor for the SVM can be obtained. Otherwise, return to Step 2.
5.2.2. Comparison of the Classification Results
- If the prediction result and the real load exhibit the same pattern (i.e., ), then the current load data are labeled normal.
- If and exhibit different learned patterns, there are three potential reasons for the difference: (1) the real data are still normal, but it is affected by daily random events, which is unpredictable; (2) a classification error occurs; or (3) the real data are abnormal, and nontechnology loss exists. Regardless of the reason for the difference, the algorithm uses a cross-entropy loss function to assess the classification result of real load data. Because the pattern-matching-based anomaly detector is designed to identify the normal power usage of the off-grid power plant, only the real value of the load is redetected. If no error is observed, then the classification result is determined to be acceptable.
5.2.3. Global Re-Evaluation Process
- Use the cross-entropy loss function to calculate the loss of the benign training data.
- Input the real load data and the matched pattern obtained from the improved SVM model into the training dataset (to build a new dataset), and use the (new) cross-entropy loss function to recalculate the loss.
- Calculate the difference in the losses ε and compare the difference with the thresholdc. If ε is smaller than the thresholdc, the classification result of the improved SVM is acceptable, and the load is benign. Otherwise, even if the improved SVM indicates that the load is associated with a learned pattern, the algorithm considers the load to be abnormal. Considering the normal power usage of humans over time, according to the results of variation analysis, the thresholdc in this study is set as a changeable constant that varies with time. The influence of this variable threshold on the detection accuracy will be discussed later. Figure 4 shows a flowchart of the pattern-matching-based anomaly detector.
6. Experimental Results and Comparison
6.1. Experimental Results
6.1.1. Test A
6.1.2. Test B
6.1.3. Test C
6.2. Comparison and Evaluation
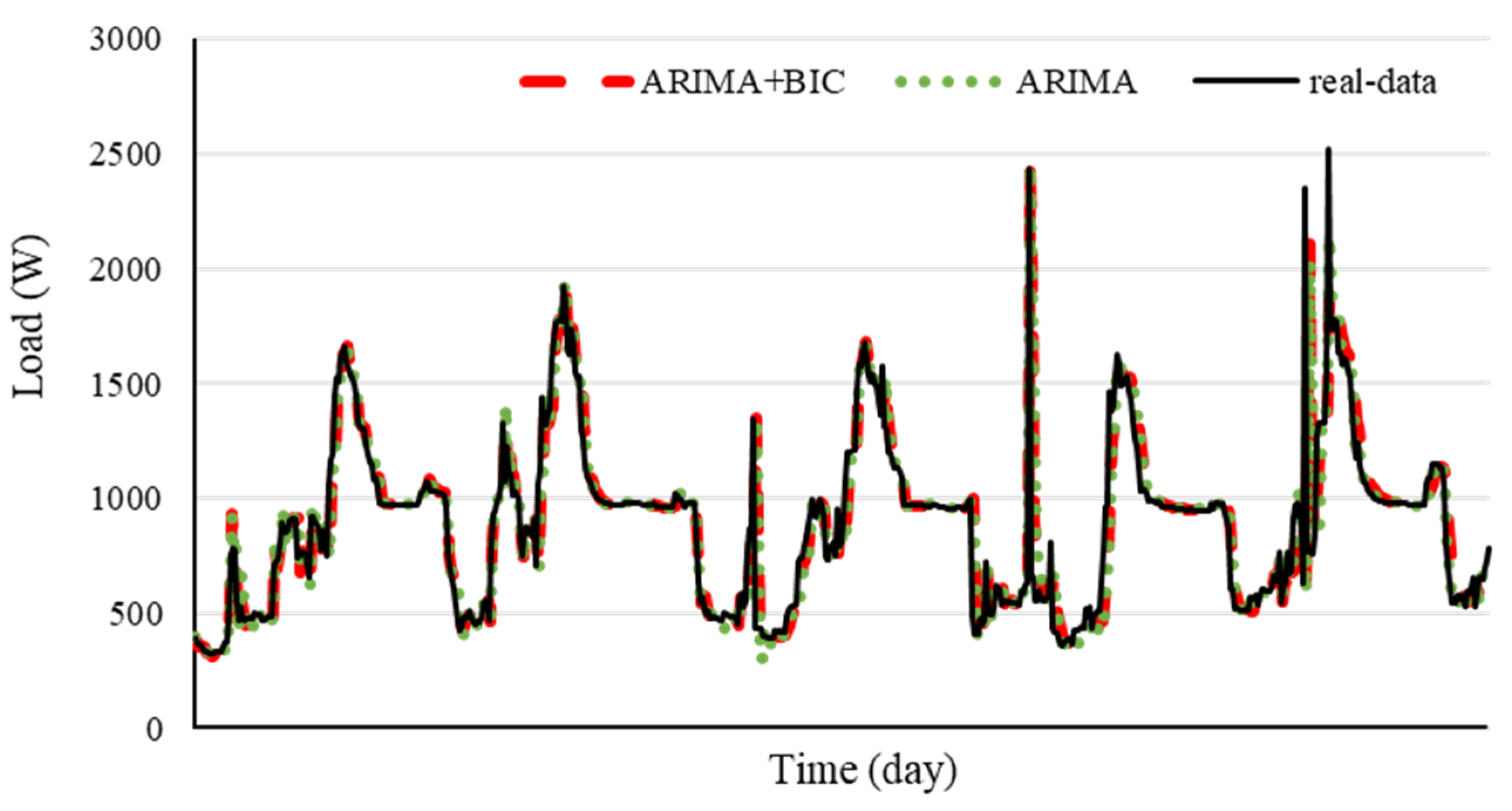
6.2.1. Prediction Results of Comparisons
6.2.2. Comparison of Anomaly Detection Results
6.3. Previous Work Comparison and Evaluation
6.3.1. Prediction Accuracy
6.3.2. Anomaly Detection Accuracy
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, X.; Ha, B. Low-cost far-field wireless electrical load monitoring system applied in an off-grid rural area of Tanzania. Sustain. Cities Soc. 2020, 59, 102209. [Google Scholar] [CrossRef]
- Energy Information Administration (US). International Energy Outlook 2016, with Projections to 2040; Government Printing Office: Washington, WA, USA, 2016.
- Hansen, U.E.; Pedersen, M.B.; Nygaard, I. Review of solar PV policies, interventions and diffusion in East Africa. Renew. Sustain. Energy Rev. 2015, 46, 236–248. [Google Scholar] [CrossRef] [Green Version]
- World Loses $89.3 Billion to Electricity Theft Annually, $58.7 Billion in Emerging Markets. Available online: https://www.prnewswire.com/news-releases/world-loses-893-billion-to-electricity-theft-annually-587-billion-in-emerging-markets-300006515.html/ (accessed on 17 June 2020).
- Wang, X.; Ahn, S.H. Real-time prediction and anomaly detection of electrical load in a residential community. Appl. Energy 2020, 259, 114145. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, W.W.; Black, J. Anomaly detection in premise energy consumption data. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, Quebec, QC, Canada, 2–6 August 2011. [Google Scholar]
- El Desouky MMEK, A.A. Hybrid adaptive techniques for electric-load forecast using ANN and ARIMA. IEE Proc. Gener. Transm. Distrib. 2010, 147, 213–217. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Combining neural networks and ARIMA models for hourly temperature forecast. IEEE Comput. Soc. 2000, 4, 414–419. [Google Scholar]
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C.K. Comparison of ARIMA and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 2014, 7. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Tian, H.; Li, Y. Comparison of two new ARIMA ANN and ARIMA-Kalman hybrid methods for wind speed prediction. Appl. Energy 2012, 98, 415–424. [Google Scholar] [CrossRef]
- Naveena, K.; Singh, S.; Rathod, S.; Singh, A. Abhishek Singh Hybrid ARIMA-ANN Modelling for Forecasting the Price of Robusta Coffee in India. Int. J. Curr. Microbiol. Appl. Sci. 2017, 6, 1721–1726. [Google Scholar] [CrossRef]
- Fenza, G.; Gallo, M.; Loia, V. Drift-aware methodology for anomaly detection in smart grid. IEEE Access 2019, 7, 9645–9657. [Google Scholar] [CrossRef]
- Jokar, P.; Arianpoo, N.; Leung, V.C. Electricity theft detection in AMI using customers’ consumption patterns. IEEE Trans. Smart Grid 2015, 7, 216–226. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y.; Wang, J.Y. Analytical investigation of autoencoder-based methods for unsupervised anomaly detection in building energy data. Appl Energy 2018, 211, 1123–1135. [Google Scholar] [CrossRef]
- Pereira, J.; Margarida, S. Unsupervised anomaly detection in energy time series data using variational recurrent autoencoders with attention. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018. [Google Scholar]
- Iwayemi, A.; Zhou, C. SARAA: Semi-supervised learning for automated residential appliance annotation. IEEE Trans. Smart Grid 2015, 8, 779–786. [Google Scholar] [CrossRef]
- Wang, X.; Yang, I.; Ahn, S.H. Sample Efficient Home Power Anomaly Detection in Real Time Using Semi-Supervised Learning. IEEE Access 2019, 7, 139712–139725. [Google Scholar] [CrossRef]
- Owoye, O. The causal relationship between taxes and expenditures in the G7 countries: Cointegration and error-correction models. Appl. Econ. Lett. 1995, 2, 19–22. [Google Scholar] [CrossRef]
- Nie, H.; Liu, G.; Liu, X.; Wang, Y. Hybrid of ARIMA and SVMs for short-term load forecasting. Energy Procedia 2012, 16, 1455–1460. [Google Scholar] [CrossRef] [Green Version]
- Findley, D.F. Counterexamples to parsimony and BIC. Ann. Inst. Stat. Math. 1991, 43, 505–514. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Amorim, R.C.; Hennig, C. Recovering the number of clusters in data sets with noise features using feature rescaling factors. Inf. Sci. 2015, 324, 126–145. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Fang, L.; Su, S.; Lv, Y. Parameters Optimization of SVMBased on Improved FOA and Its Application in Fault Diagnosis. JSW 2015, 10, 1301–1309. [Google Scholar] [CrossRef]
- Pan, W.T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 2012, 26, 69–74. [Google Scholar] [CrossRef]
- Kroese, D.P.; Rubinstein, R.Y.; Taimre, T. Application of the cross-entropy method to clustering and vector quantization. J. Glob. Optim. 2007, 37, 137–157. [Google Scholar] [CrossRef]
- Glantz, S.A.; Slinker, B.K.; Neilands, T.B. Primer of Applied Regression and Analysis of Variance; McGraw-Hill: New York, NY, USA, 1990. [Google Scholar]
- Pontius, R.G.; Thontteh, O.; Chen, H. Components of information for multiple resolution comparison between maps that share a real variable. Environ. Ecol. Stat. 2008, 15, 111–142. [Google Scholar] [CrossRef]
- Chou, J.S.; Telaga, A.S. Real-time detection of anomalous power consumption. Renew. Sustain. Energy Rev. 2014, 33, 400–411. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Advantages | Limitations | |
|---|---|---|---|
| Regression model | Anomaly detection and power usage prediction | Low prediction and detection accuracy | |
| Classification model | Supervised | High detection accuracy | High training cost |
| Unsupervised | No training cost | Weak interpretability | |
| Semi-supervised | High detection accuracy and low training cost | The relationship between labeled data and unlabeled data need to be known | |
| This work | Anomaly detection and future power usage prediction; High detection accuracy | Relatively high training cost | |
| Items | R2 | RMSD |
|---|---|---|
| ARIMA + BIC (this study) | 0.7378 | 174.0777 |
| ARIMA (1,1,1) | 0.7148 | 191.0377 |
| Items | F1 |
|---|---|
| FOA-SVM | 0.9536 |
| SVM | 0.8083 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Rhee, H.S.; Ahn, S.-H. Off-Grid Power Plant Load Management System Applied in a Rural Area of Africa. Appl. Sci. 2020, 10, 4171. https://doi.org/10.3390/app10124171
Wang X, Rhee HS, Ahn S-H. Off-Grid Power Plant Load Management System Applied in a Rural Area of Africa. Applied Sciences. 2020; 10(12):4171. https://doi.org/10.3390/app10124171
Chicago/Turabian StyleWang, Xinlin, Herb S. Rhee, and Sung-Hoon Ahn. 2020. "Off-Grid Power Plant Load Management System Applied in a Rural Area of Africa" Applied Sciences 10, no. 12: 4171. https://doi.org/10.3390/app10124171
APA StyleWang, X., Rhee, H. S., & Ahn, S. -H. (2020). Off-Grid Power Plant Load Management System Applied in a Rural Area of Africa. Applied Sciences, 10(12), 4171. https://doi.org/10.3390/app10124171