Detection of Parking Slots Based on Mask R-CNN

Abstract
:1. Introduction
- (1)
- A method for detecting parking slots based on Mask R-CNN is proposed. Specifically, we employed Resnet101 [33] and feature pyramid networks (FPN) [34] to extract and combine the image features of marking-points, which have more robust detection under varied illumination conditions, compared with traditional detectors and the detector trained by machine learning.
- (2)
- The proposed method can detect parking slots with different tilt angles and accurately separate the parking guidelines from the adjacent lane lines, which is prior to previous methods.
- (3)
- There is a single training image type of previous learning-based methods. We make and collect different types of AVM images for training. The proposed method accurately detects the marking-points in the AVM images with different stitching effects and gives more robust detection results.
2. Research Status
2.1. Traditional Algorithms
2.2. Machine Learning and Deep Learning
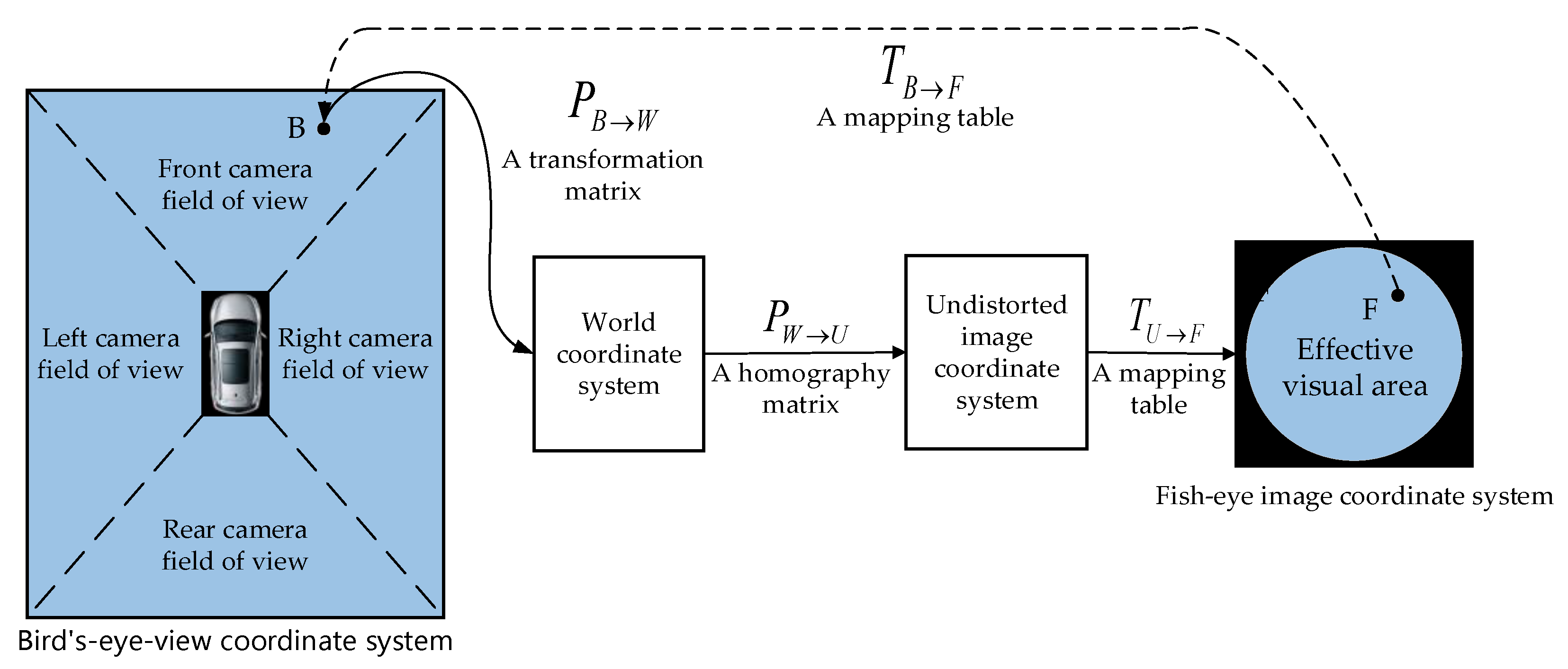
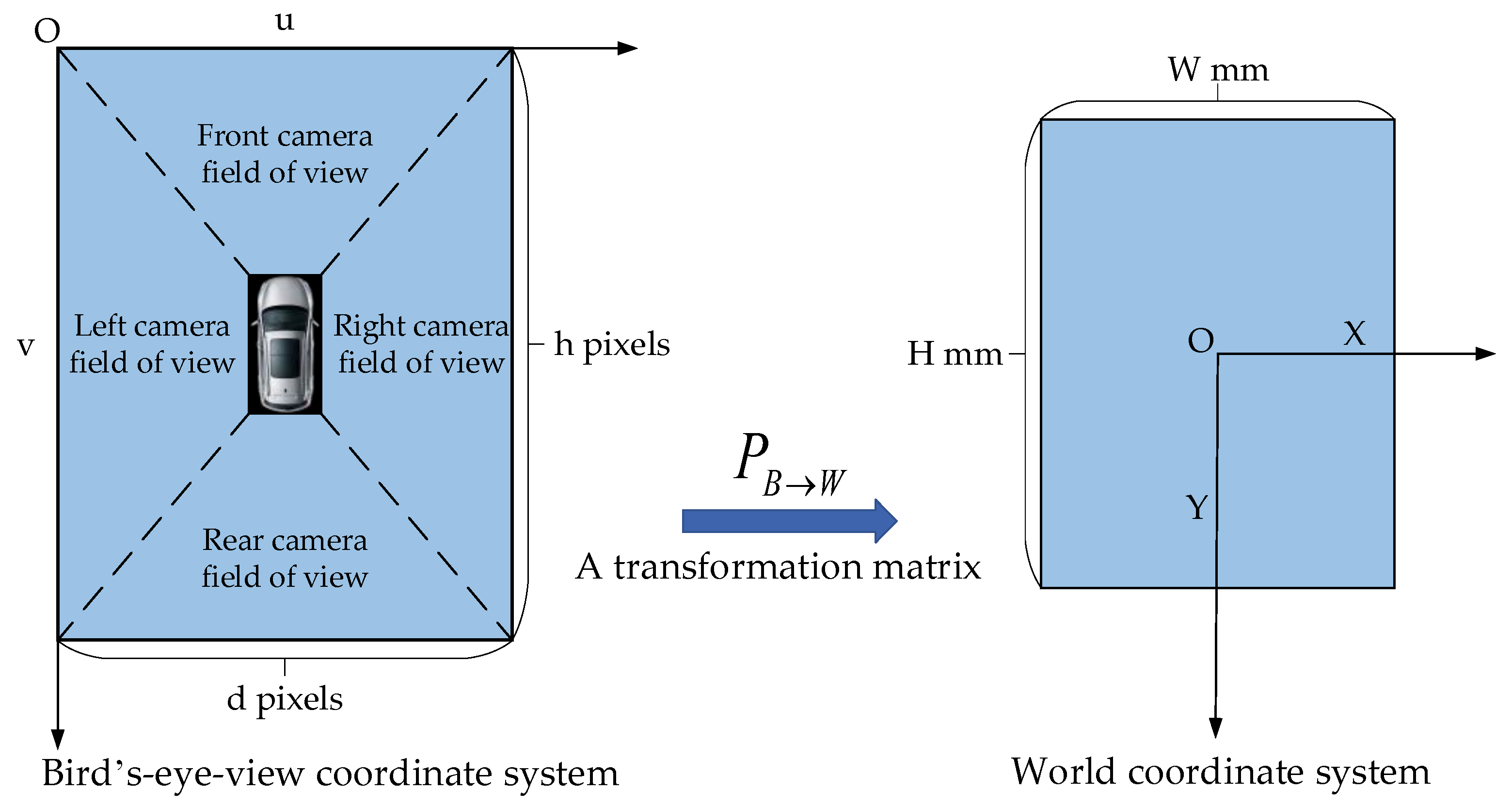
3. Generation of Around-View Images
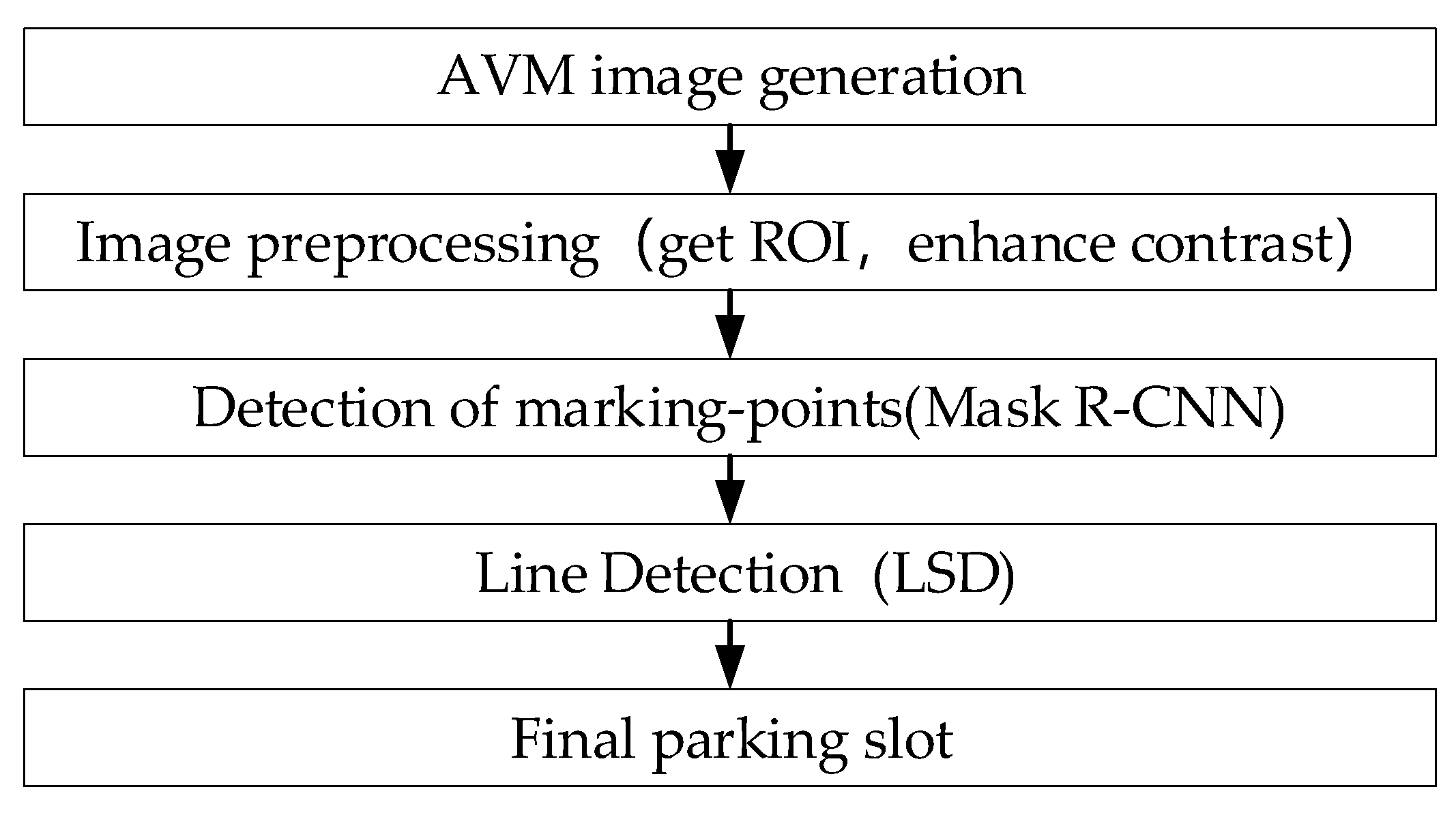
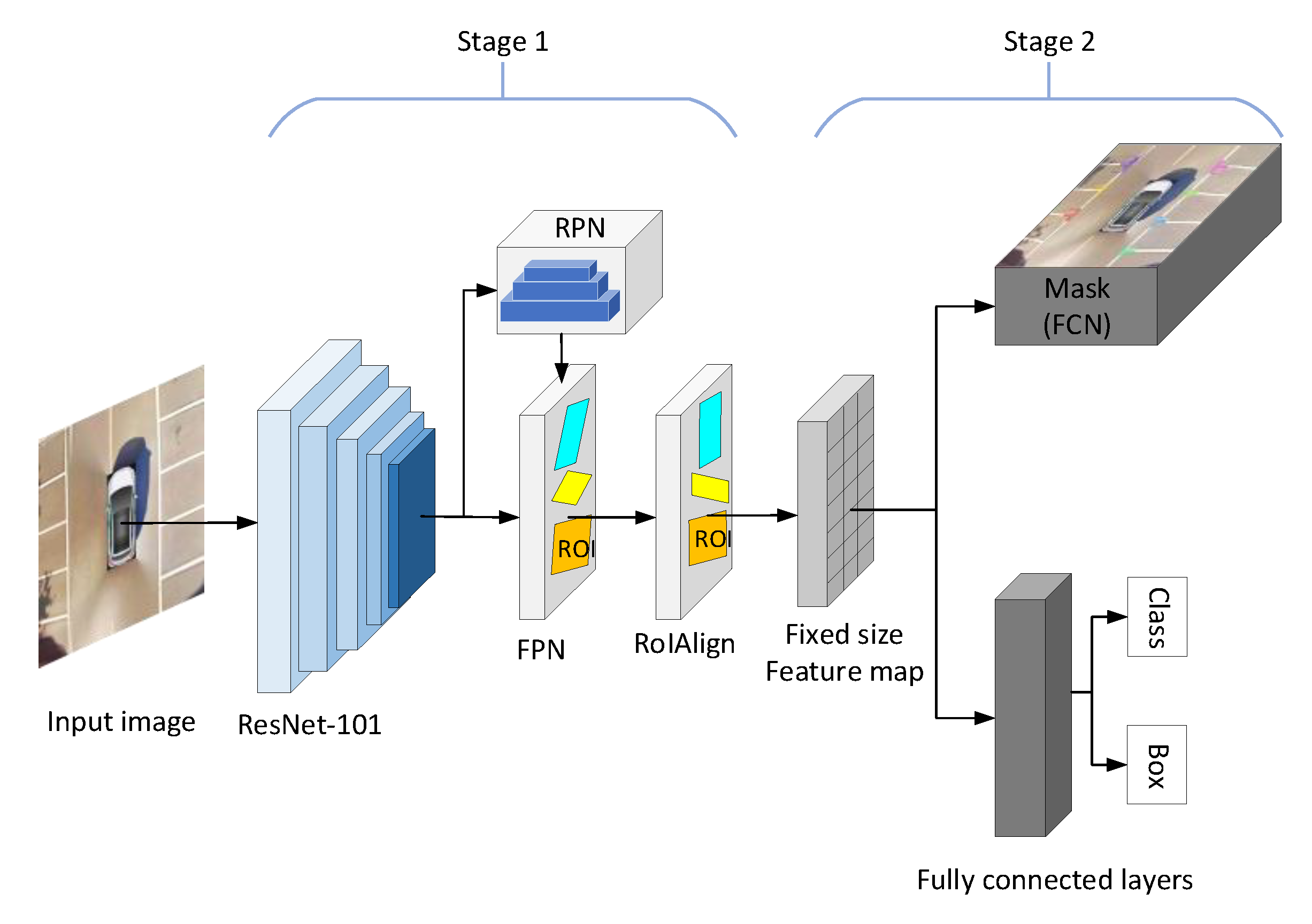
4. Method for Detecting Parking Slots Based on Mask R-CNN
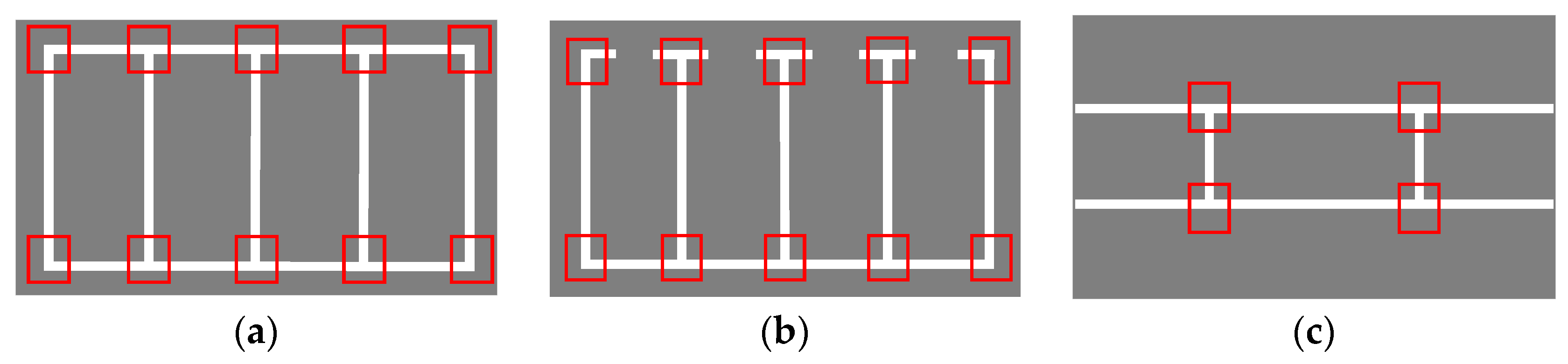
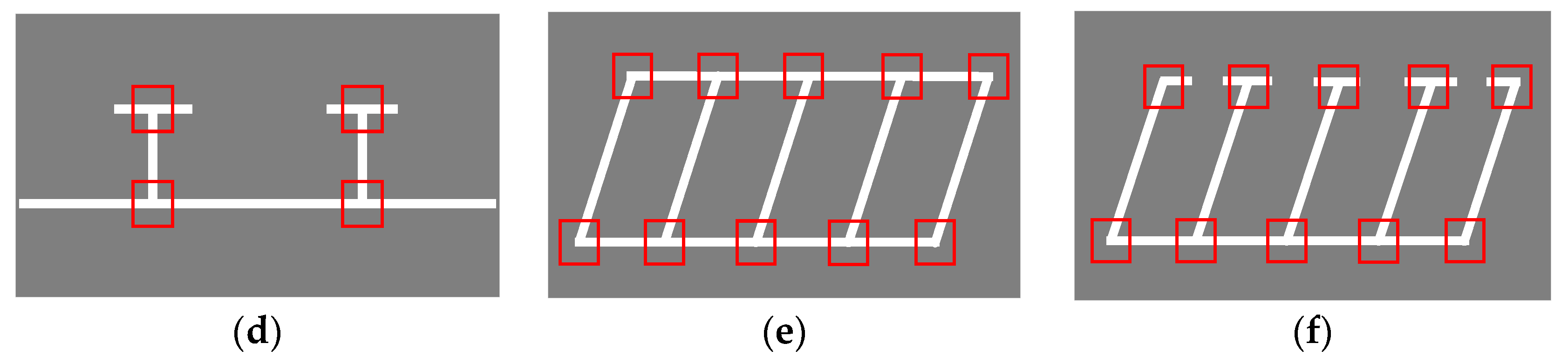
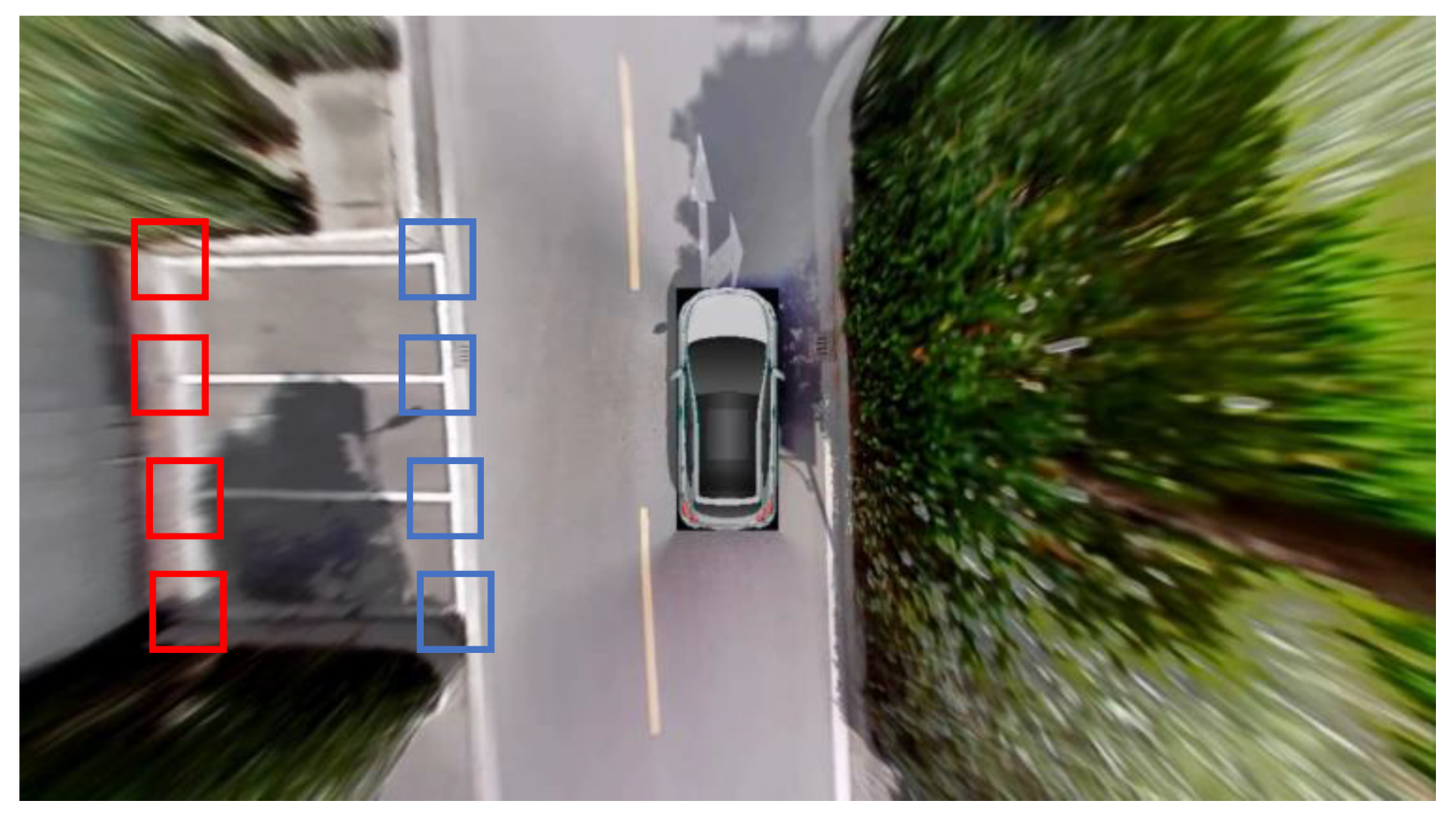
4.1. Production of the Training Set
4.2. Build Mask R-CNN Training Model
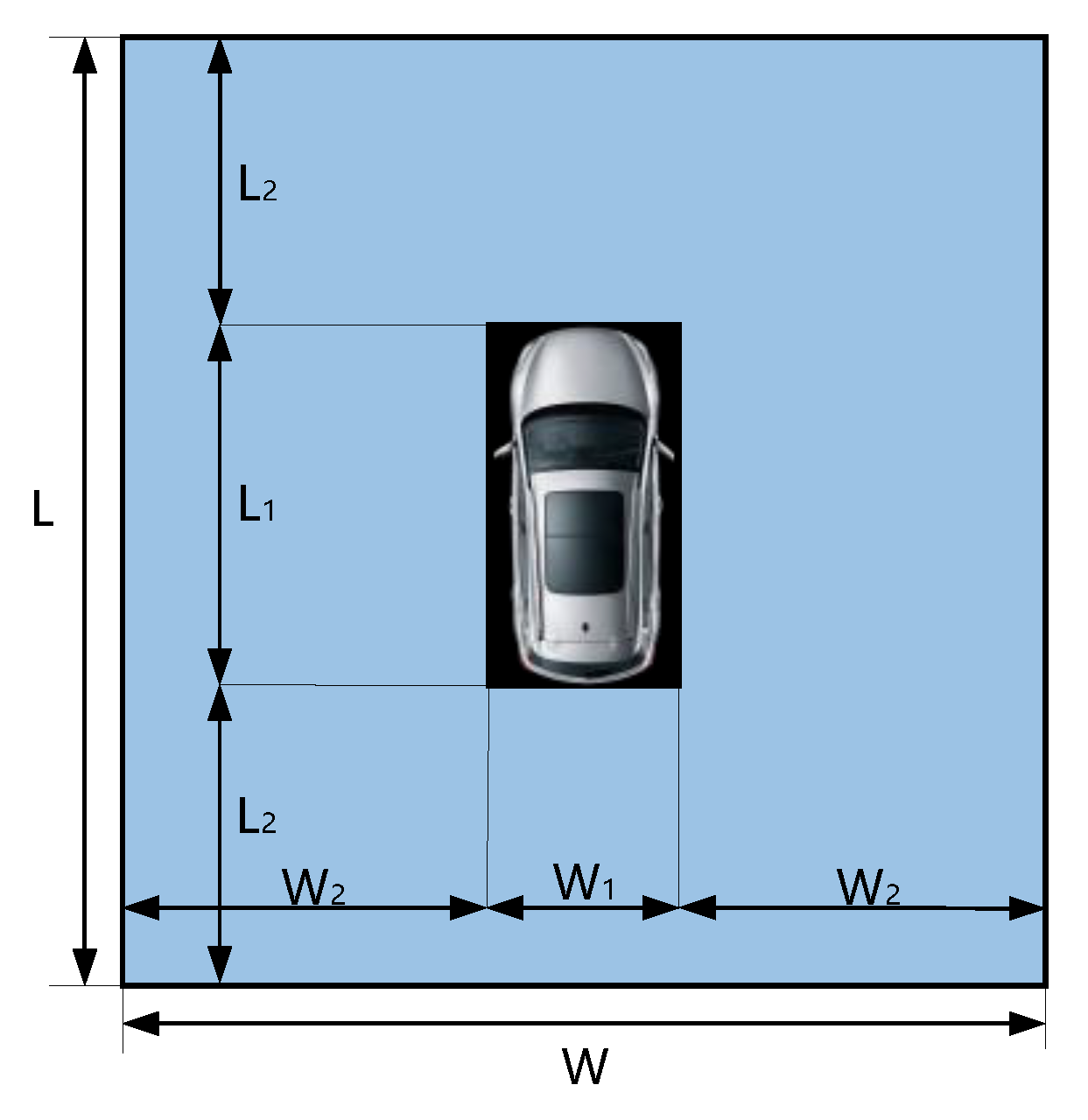
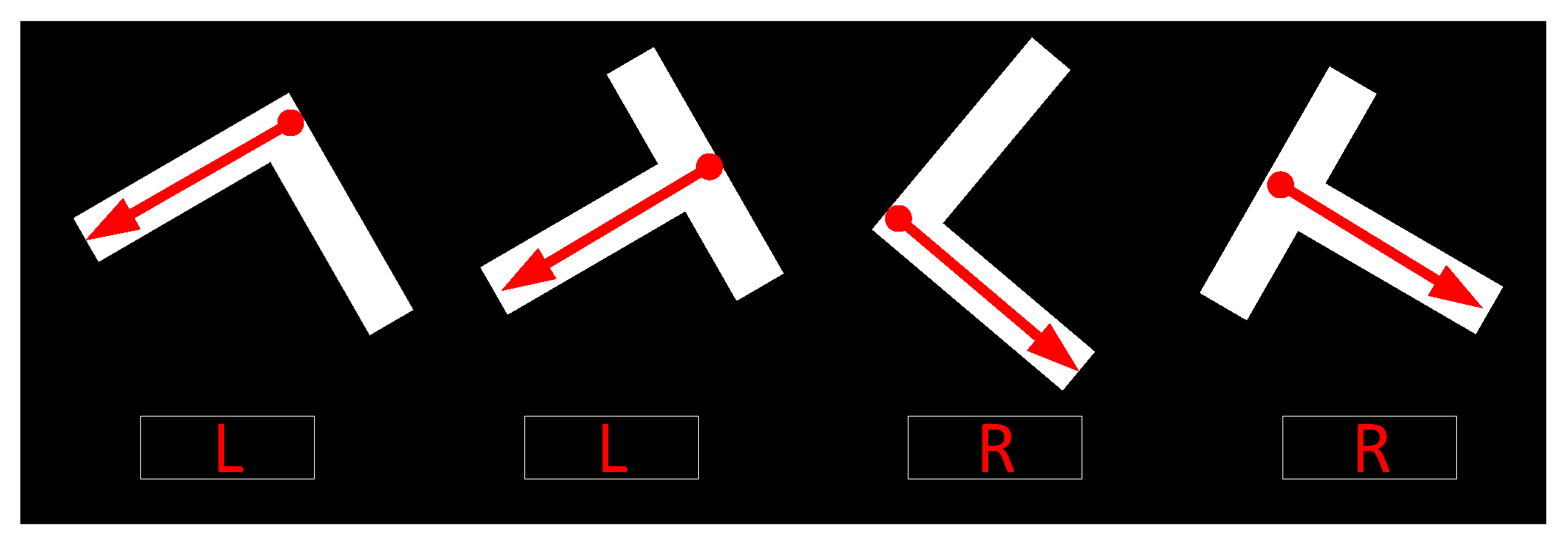
4.3. Parking-Slot Inference Base on Marking-Points
5. Experimental Result
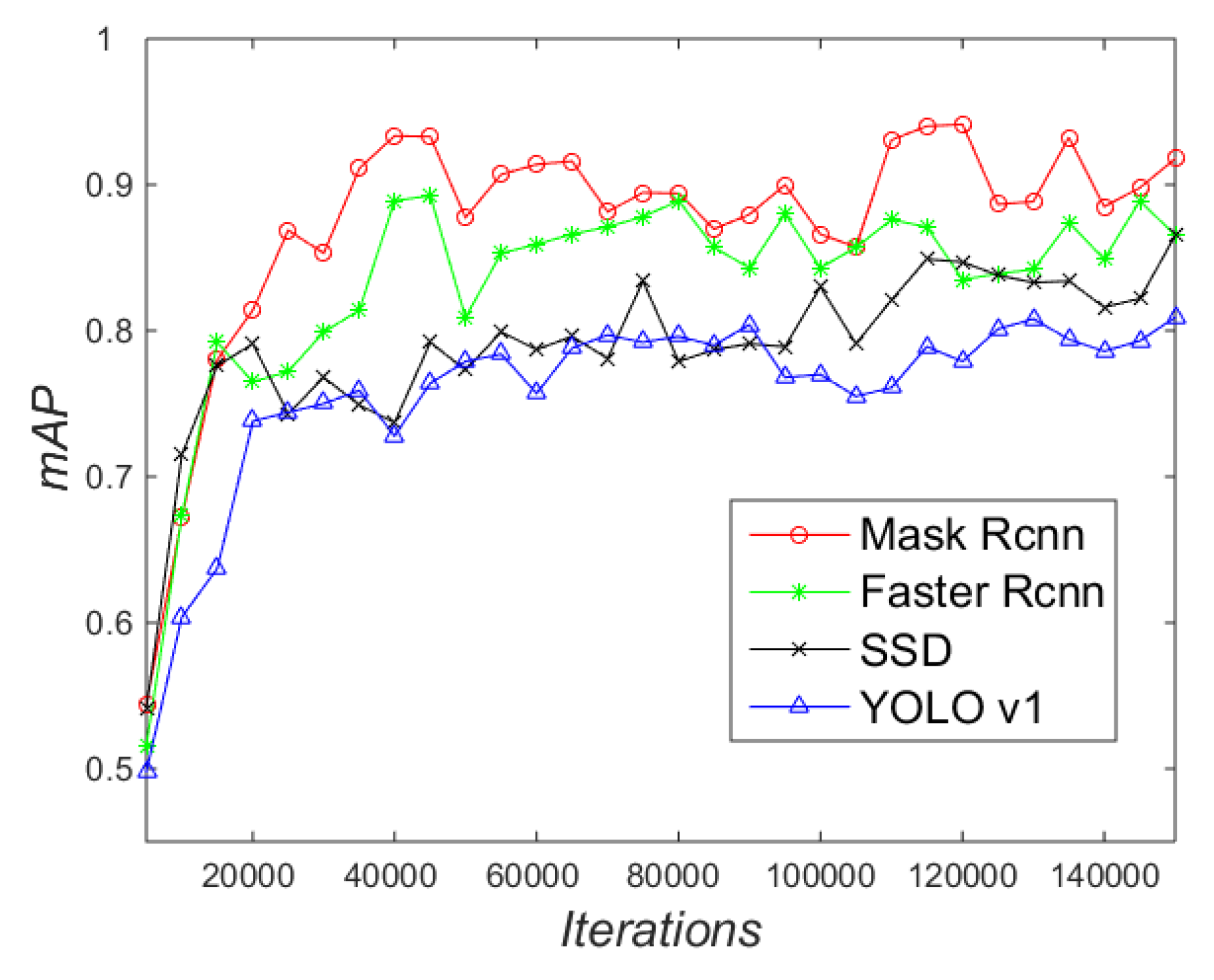
5.1. Training Platform and Selection of Pre-Training Model
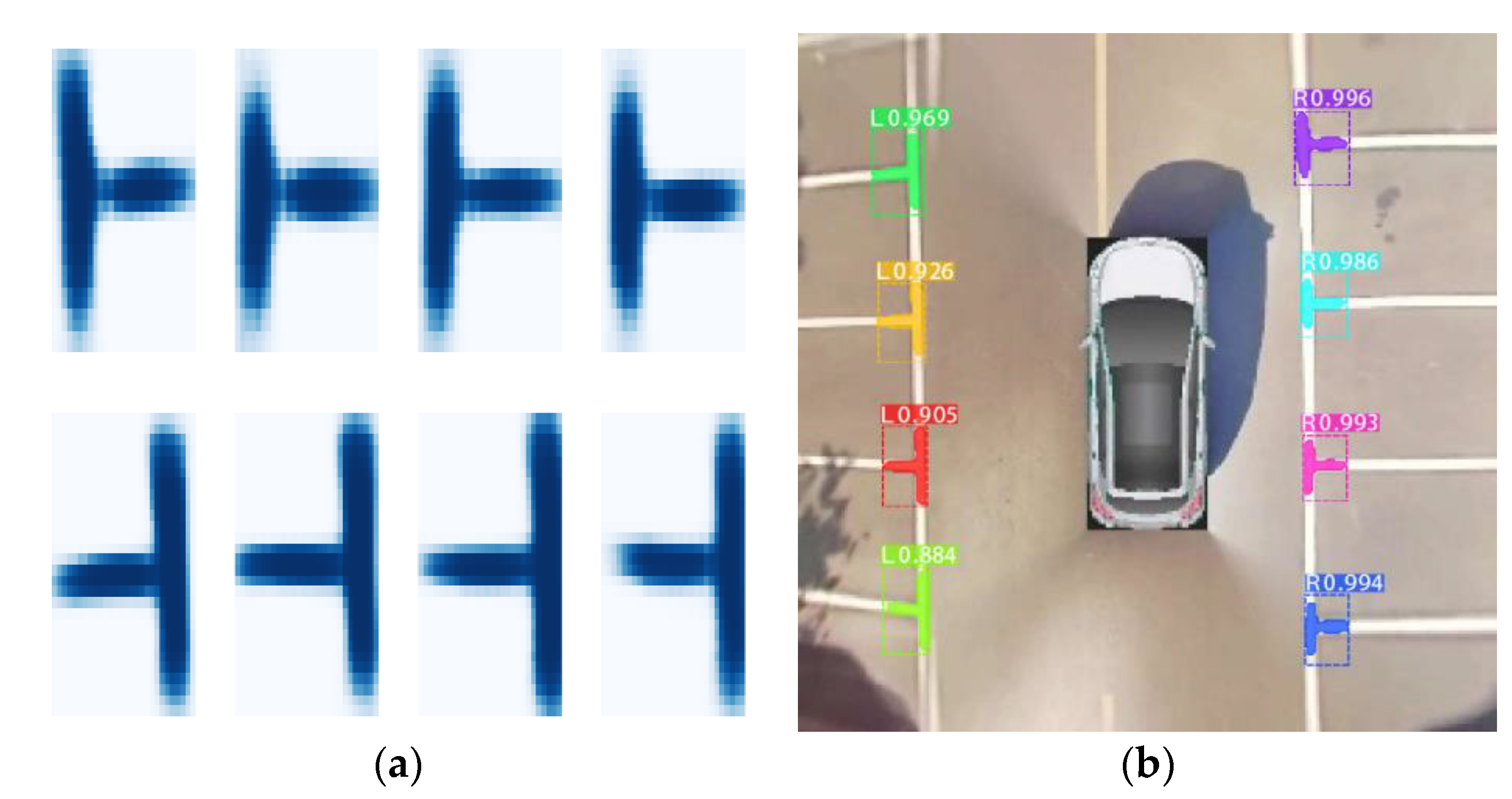
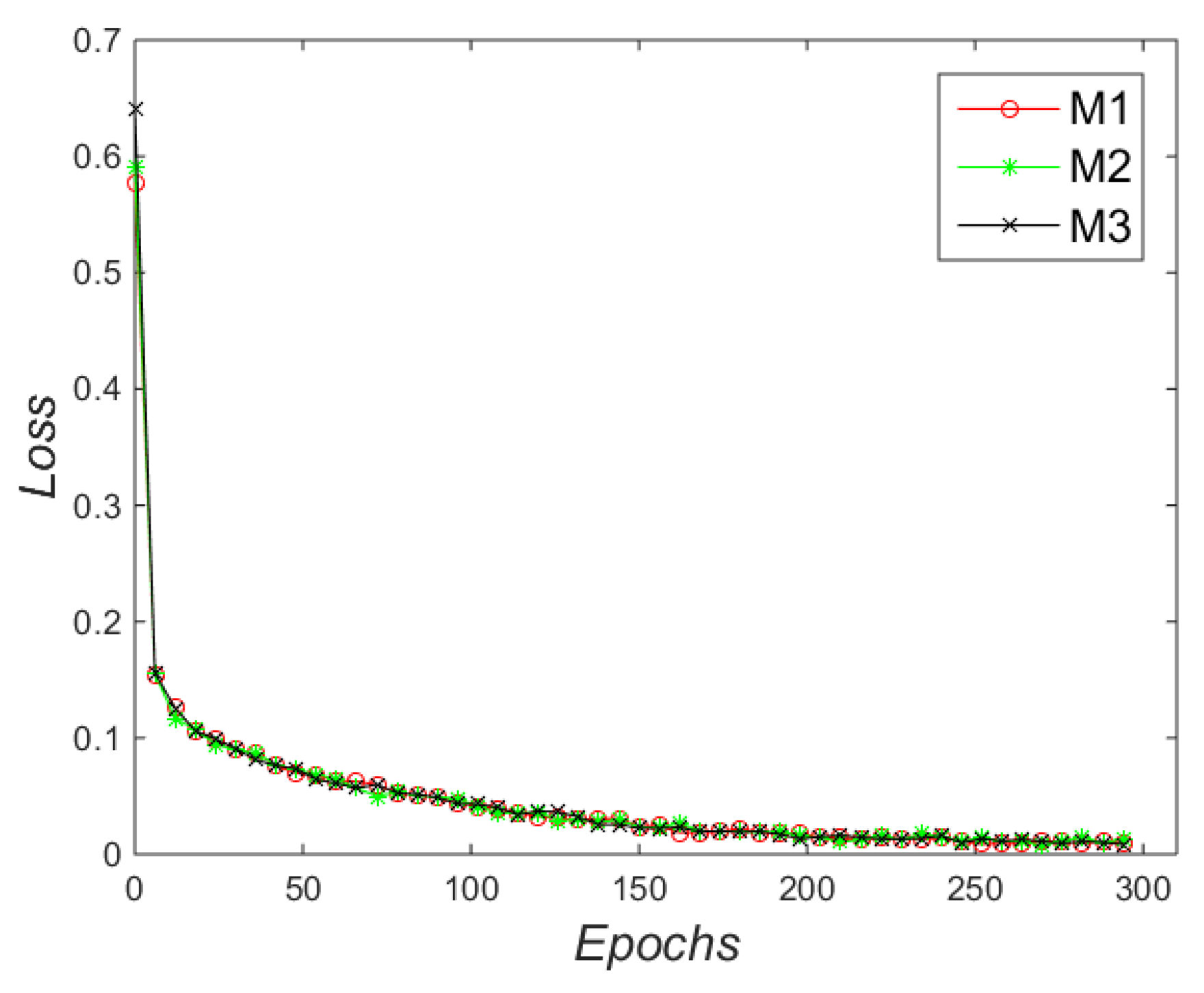
5.2. Evaluating the Performance of Marking-Point Detection
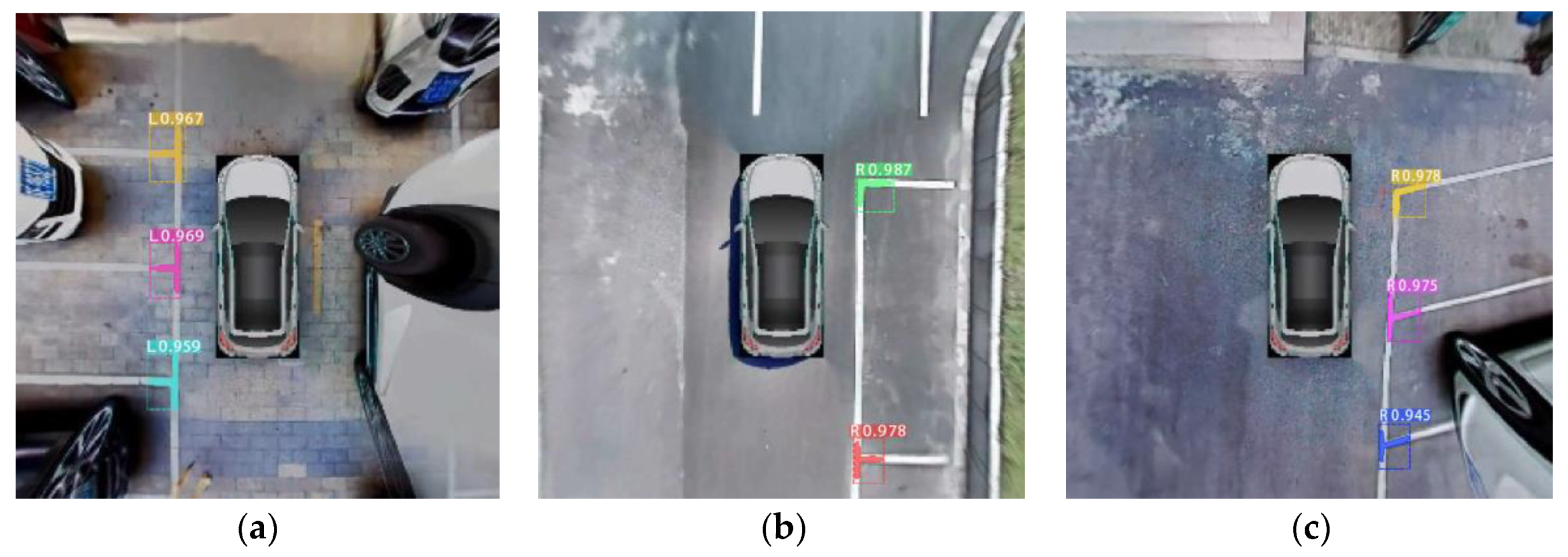
5.3. Evaluating the Performance of Parking-Slot Detection
6. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Hua, Y.; Ma, S.; Ma, J.; Jiang, H.; Zhang, D. Integrated model of assisted parking system and performance evaluation with entropy weight extended analytic hierarchy process and two-tuple linguistic information. Adv. Mech. Eng. 2016, 8, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Ye, H.; Jiang, H.; Ma, S.; Tang, B.; Wahab, L. Linear model predictive control of automatic parking path tracking with soft constraints. Int. J. Adv. Robot. Syst. 2019, 16. [Google Scholar] [CrossRef] [Green Version]
- Al-Turjman, F.; Malekloo, A. Smart parking in IoT-enabled cities: A survey. Sustain. Cities Soc. 2019, 49, 101608. [Google Scholar] [CrossRef]
- Heimberger, M.; Horgan, J.; Yogamani, S.; Hughes, C.; McDonald, J. Computer vision in automated parking systems: Design, implementation and challenges. Image Vis. Comput. 2017, 68, 88–101. [Google Scholar] [CrossRef]
- De Almeida, P.R.; De Oliveira, L.E.S.; Britto, A.S.; Silva, E.J.; Koerich, A.L. PKLot—A robust dataset for parking lot classification. Expert Syst. Appl. 2015, 42, 4937–4949. [Google Scholar] [CrossRef] [Green Version]
- Schmid, M.R.; Ates, S.; Dickmann, J. Parking Space Detection with Hierarchical Dynamic Occupancy Grids. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 254–259. [Google Scholar]
- Dube, R.; Hahn, M.; Schuetz, M. Detection of Parked Vehicles from a Radar Based Occupancy Grid. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 1415–1420. [Google Scholar]
- Jung, H.G.; Cho, Y.H.; Yoon, P.J.; Kim, J. Scanning Laser Radar-Based Target Position Designation for Parking Aid System. IEEE Trans. Intell. Transp. Syst. 2008, 9, 406–424. [Google Scholar] [CrossRef]
- Zhou, J.; Navarro-Serment, L.E.; Hebert, M. Detection of Parking Spots Using 2D Range Data. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 1280–1287. [Google Scholar]
- Ibisch, A.; Stuemper, S.; Altinger, H. Towards Autonomous Driving in a Parking Garage: Vehicle Localization and Tracking Using environment-embedded LIDAR Sensors. In Proceedings of the 2013 Ieee Intelligent Vehicles Symposium, Gold Coast, Australia, 23–26 June 2013; pp. 829–834. [Google Scholar]
- Tong, L.; Cheng, L.; Li, M.; Wang, J.; Du, P. Integration of LiDAR Data and Orthophoto for Automatic Extraction of Parking Lot Structure. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 503–514. [Google Scholar] [CrossRef]
- Jiang, H.B.; Ye, H.; Ma, S.D. Method for accurately identifying parking space of automatic parking system based on multi-sensor data fusion. J. Chongqing Univ. Technol. 2019, 33, 1–10. [Google Scholar]
- Jeong, S.H.; Choi, C.G.; Oh, J.N.; Yoon, P.J.; Kim, B.S.; Kim, M.; Lee, K.H. Low cost design of parallel parking assist system based on an ultrasonic sensor. Int. J. Automot. Technol. 2010, 11, 409–416. [Google Scholar] [CrossRef]
- Ford Fusion. Available online: http://www.ford.com/cars/fusion/features/#page=-Feature15 (accessed on 23 February 2019).
- BMW 7 Series Sedan. Available online: http://www.bmw.com/com/en/newvehicles/7series/sedan/2012/showroom/driver_assistance/park-assistant.html (accessed on 23 February 2019).
- Zhang, Z.Y. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Schou, J.; Scherrer, P.H.; Bush, R.I.; Wächter, R.; Couvidat, S.; Rabello-Soares, M.C.; Bogart, R.S.; Hoeksema, J.T.; Liu, Y.; Duvall, T.L.; et al. Design and Ground Calibration of the Helioseismic and Magnetic Imager (HMI) Instrument on the Solar Dynamics Observatory (SDO). Sol. Phys. 2011, 275, 229–259. [Google Scholar] [CrossRef] [Green Version]
- Brook, A.; Ben Dor, E. Automatic Registration of Airborne and Spaceborne Images by Topology Map Matching with SURF Processor Algorithm. Remote. Sens. 2011, 3, 65–82. [Google Scholar] [CrossRef] [Green Version]
- Sedaghat, A.; Ebadi, H. Remote Sensing Image Matching Based on Adaptive Binning SIFT Descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, G.; Jia, Z. An Image Stitching Algorithm Based on Histogram Matching and SIFT Algorithm. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1754006. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.-Y.; Hsu, C.-M. A visual method for the detection of Available Parking Slots. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics, Banff, AB, Canada, 5–8 October 2017; pp. 2980–2985. [Google Scholar]
- Suhr, J.K.; Jung, H.G. Fully-automatic Recognition of Various Parking Slot Markings in Around View Monitor (AVM) Image Sequences. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 1294–1299. [Google Scholar]
- Suhr, J.K.; Jung, H.G. Full-automatic recognition of various parking slot markings using a hierarchical tree structure. Opt. Eng. 2013, 52, 37203. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Sensor Fusion-Based Vacant Parking Slot Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2013, 15, 21–36. [Google Scholar] [CrossRef]
- Jung, H.G.; Kim, D.S.; Yoon, P.J. Parking slot markings recognition for automatic parking assist system. In Proceedings of the 2006 IEEE Intelligent Vehicles Symposium, Tokyo, Japan, 13–15 June 2006; pp. 106–113. [Google Scholar]
- Wang, B.; Zhang, H.; Yang, M.; Wang, X.; Ye, L.; Guo, C. Automatic Parking Based on a Bird’s Eye View Vision System. Adv. Mech. Eng. 2014, 6, 847406. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. A Universal Vacant Parking Slot Recognition System Using Sensors Mounted on Off-the-Shelf Vehicles. Sensors 2018, 18, 1213. [Google Scholar] [CrossRef] [Green Version]
- Houben, S.; Komar, M.; Hohm, A. On-Vehicle Video-Based Parking Lot Recognition with Fisheye Optics. In Proceedings of the 2013 16th International IEEE Conference on Intelligent Transportation Systems, The Hague, The Netherlands, 6–9 October 2013; pp. 7–12. [Google Scholar]
- Lee, S.; Seo, S.-W. Available parking slot recognition based on slot context analysis. IET Intell. Transp. Syst. 2016, 10, 594–604. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Von Gioi, R.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S. Identity Mappings in Deep Residual Networks. Computer. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar]
- Cole, M.W.; Reynolds, J.R.; Power, J.D.; Repovš, G.; Anticevic, A.; Braver, T.S. Multi-task connectivity reveals flexible hubs for adaptive task control. Nat. Neurosci. 2013, 16, 1348–1355. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Li, X.; Huang, J.; Shen, Y.; Wang, D. Vision-Based Parking-Slot Detection: A Benchmark and a Learning-Based Approach. Symmetry 2018, 10, 64. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Lin, C.; Zhao, Y. Geometric Features-Based Parking Slot Detection. Sensors 2018, 18, 2821. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zinelli, A.; Musto, L.; Pizzati, F. A deep-learning approach for parking slot detection on surround-view images. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 29 August 2019; pp. 603–608. [Google Scholar] [CrossRef]
- Jang, C.H.; Sunwoo, M. Semantic segmentation-based parking space detection with standalone around view monitoring system. Mach. Vis. Appl. 2018, 30, 309–319. [Google Scholar] [CrossRef]
- Cai, B.Y.; Alvarez, R.; Sit, M.; Duarte, F.; Ratti, C. Deep Learning-Based Video System for Accurate and Real-Time Parking Measurement. IEEE Internet Things J. 2019, 6, 7693–7701. [Google Scholar] [CrossRef] [Green Version]
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C.; Meghini, C.; Vairo, C. Deep learning for decentralized parking lot occupancy detection. Expert Syst. Appl. 2017, 72, 327–334. [Google Scholar] [CrossRef]
- Yamada, K.; Mizuno, M. A vehicle parking detection method using image segmentation. Electron. Commun. Jpn. Part III Fundam. Electron. Sci. 2001, 84, 25–34. [Google Scholar] [CrossRef]
- OpenCL Overview. Available online: https://www.khronos.org/opencl/ (accessed on 8 August 2019).
- LabelMe Annotation Tool. Available online: https://github.com/CSAILVision/LabelMeAnnotationTool (accessed on 20 August 2019).
- MS COCO. Available online: http://mscoco.org/ (accessed on 5 August 2019).
- Fluorescence Microscopy Denoising Dataset. Available online: https://github.com/yinhaoz/denoising-fluorescenc (accessed on 25 February 2019).
- Object-Co-Skeletonization-with-Co-Segmentation. Available online: https://github.com/jkoteswarrao/Object-Coskelet-onization-with-Co-segmentation (accessed on 18 March 2019).
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, LasVegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Dataset. Available online: https://cslinzhang.github.io/ps/ (accessed on 20 August 2019).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Speed (fps) |
|---|---|
| Mask R-CNN | 2 |
| Faster R-CNN | 7 |
| SSD | 18 |
| YOLO v1 | 22 |
| Method | SLOT | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| M1 | 256 | 89.5% | 89.3% | 90.4% | 89.8% |
| M2 | 256 | 90.2% | 91.2% | 88.7% | 89.9% |
| M3 | 256 | 93.4% | 94.5% | 92.7% | 93.5% |
| Method in [16] | 256 | 88.8% | 86.9% | 87.3% | 87.0% |
| Faster R-CNN [37] | 256 | 82.2% | 82.6% | 80.9% | 81.7% |
| Corner-based [23] | 256 | 70.5% | 74.3% | 72.4% | 73.3% |
| Line-based [26] | 256 | 77.8% | 80.3% | 75.2% | 77.6% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Jiang, H.; Ma, S.; Jiang, Z. Detection of Parking Slots Based on Mask R-CNN. Appl. Sci. 2020, 10, 4295. https://doi.org/10.3390/app10124295
Jiang S, Jiang H, Ma S, Jiang Z. Detection of Parking Slots Based on Mask R-CNN. Applied Sciences. 2020; 10(12):4295. https://doi.org/10.3390/app10124295
Chicago/Turabian StyleJiang, Shaokang, Haobin Jiang, Shidian Ma, and Zhongxu Jiang. 2020. "Detection of Parking Slots Based on Mask R-CNN" Applied Sciences 10, no. 12: 4295. https://doi.org/10.3390/app10124295
APA StyleJiang, S., Jiang, H., Ma, S., & Jiang, Z. (2020). Detection of Parking Slots Based on Mask R-CNN. Applied Sciences, 10(12), 4295. https://doi.org/10.3390/app10124295