A Room Monitoring System Using Deep Learning and Perspective Correction Techniques





Abstract
:1. Introduction
- We proposed a room monitoring system using deep learning and perspective correction techniques.
- We proposed a new person detection scheme that combines the Mask R-CNN scheme and tile technique.
- We compared and evaluated the proposed scheme and system to verify their feasibility and efficiency.
2. Related Work
2.1. Perspective Correction
2.2. Object Detection
2.3. Room Monitoring System
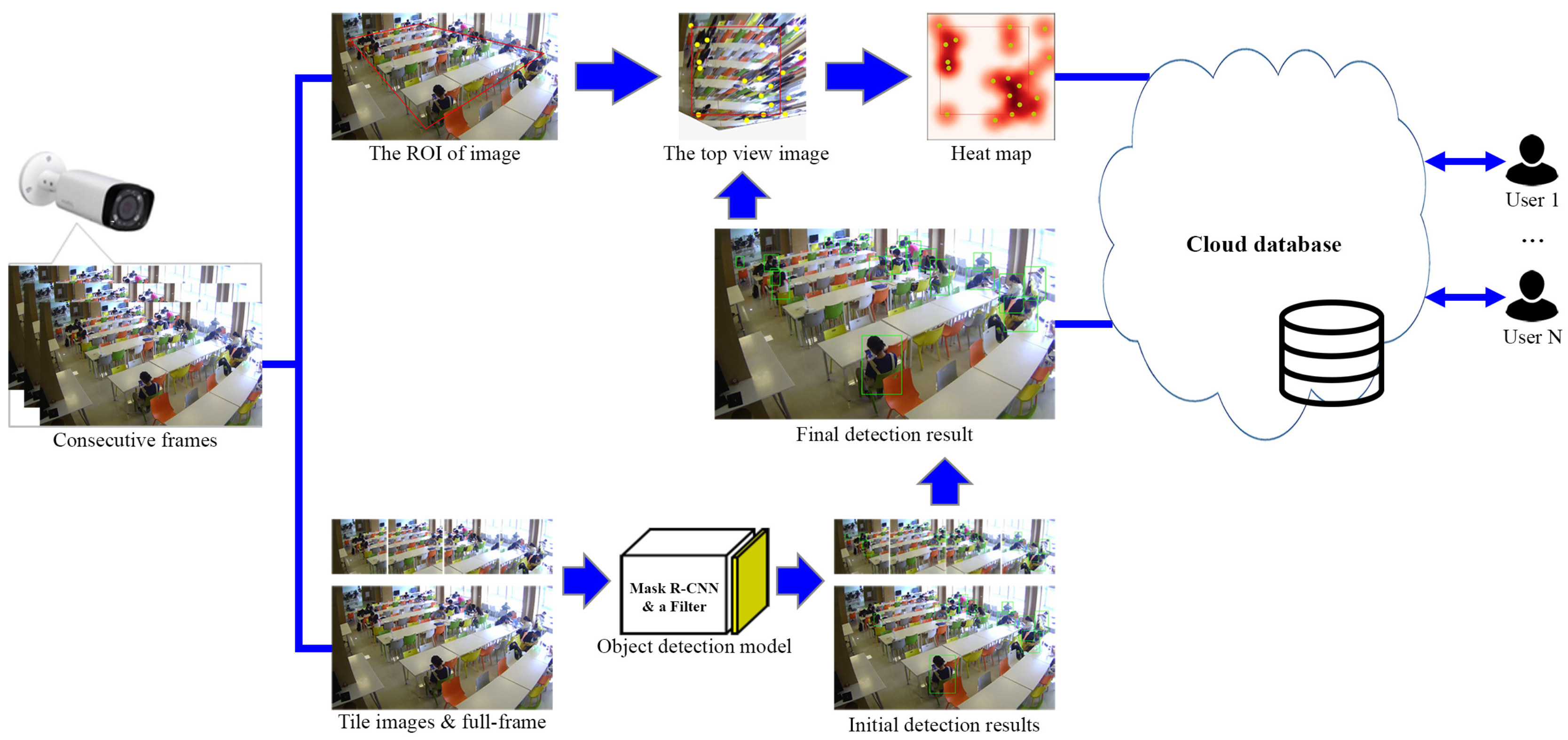
3. The Model of Room Monitoring System
3.1. System Architecture
3.2. Perspective Correction Technique
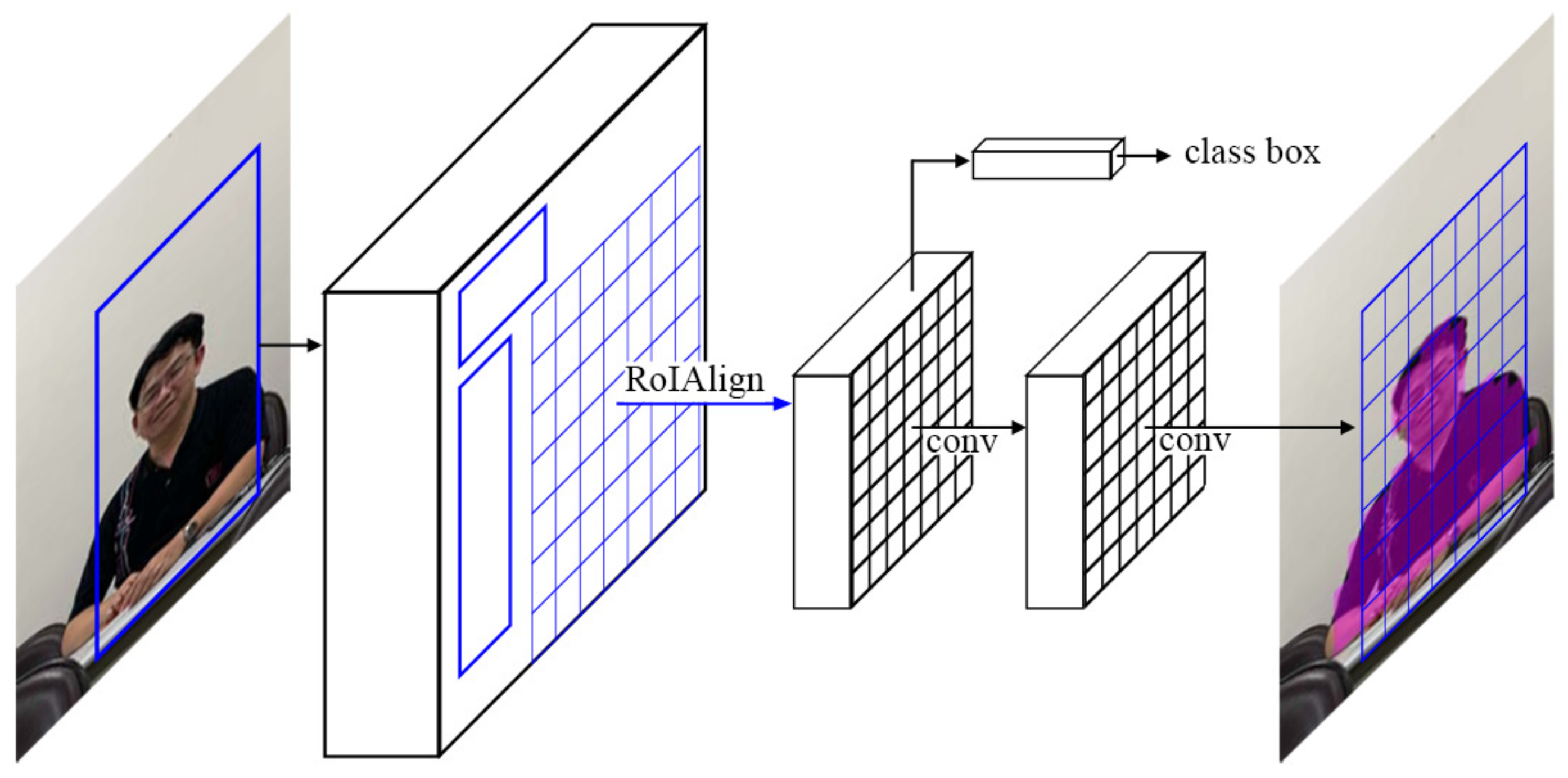
3.3. Proposed Person Detection Scheme
3.3.1. Tile Division
3.3.2. Object Detection and a Person Class Filter
3.3.3. Merging of the Bounding Boxes
| Algorithm 1 Merging the bounding boxes of each tile image in the initial results |
| 1. Input: |
| n: number of tiles |
| m: number of boxes in overlapping areas of tile[i] |
| k: number of boxes of all tiles |
| 2. Output: |
| t: number of new boxes of all tiles |
| 3. set |
| 4. |
| 5. for i in range(0, n-1): |
| 6. =[] |
| 7. for in : |
| 8. =0 |
| 9. for in : |
| 10. if < : |
| 11. |
| 12. |
| 13. if : |
| 14. |
| 15. |
| 16. |
| 17. |
| 18. elif : # |
| 19. |
| 20. return |
- Lines (1, 2) contain the input and output information of the algorithm. The input includes and . contains the bounding boxes of all tile images, and contains the bounding boxes in the overlap areas of all tile images. is the result returned by the algorithm. It includes the new bounding boxes, called intermediate results.
- The parameters are set using Lines (3, 4). is a predefined threshold of IoU that is used to consider whether two neighboring bounding boxes are merged.
- Lines (5–9) consider the neighboring bounding boxes in overlapping area of each tile image.
- Lines (10–12) determine the coupled neighboring bounding boxes with the highest IoU value in overlapping areas. The function is used to calculate the IoU of two boxes, as shown in Equation (4).
- Lines (13–17) show that if IoU value of the coupled neighboring bounding boxes is greater than the IoU threshold, these two coupled neighboring bounding boxes can be merged to create a new bounding box. adds the new bounding box and removes the coupled neighboring bounding boxes.
- Lines (18–20) determine that the complete bounding boxes in the overlapping areas and their IoU values are less than the IoU threshold. removes these bounding boxes. This approach reduces false-positive detection. Finally, the program returns a list of new bounding boxes of tile images.
| Algorithm 2 Merging the bounding boxes of intermediate results and full-frame |
| 1. Input: |
| m: number of boxes of tiles in intermediate results |
| k: number of boxes of full-frame |
| 2. Output: |
| t: number of final boxes |
| 3. set |
| 4. set |
| 5. =[] |
| 6. =[] |
| 7. =[] |
| 8. for in enumerate(): |
| 9. =True |
| 10. for in enumerate(): |
| 11. =True |
| 12. =[] |
| 13. while : |
| 14. for in enumerate(): |
| 15. if ==False: continue |
| 16. |
| 17. |
| 18. |
| 19. for in enumerate(): |
| 20. if ==False: continue |
| 21. if : |
| 22. |
| 23. |
| 24. |
| 25. if : |
| 26. |
| 27. |
| 28. |
| 29. if : |
| 30. |
| 31. |
| 32. =False |
| 33. = False |
| 34. elif : |
| 35. |
| 36. |
| 37. =False |
| 38. = False |
| 39. for in enumerate(): |
| 40. if ==False: continue |
| 41. |
| 42. for in enumerate(): |
| 43. if ==False: continue |
| 44. |
| 45. if != 0: break |
| 46. if == 0: |
| 47. |
| 48. =False |
| 49. for in enumerate(): |
| 50. if ==False: continue |
| 51. |
| 52. for in enumerate(): |
| 53. if ==False: continue |
| 54. |
| 55. if != 0: break |
| 56. if == 0: |
| 57. |
| 58. =False |
| 59. |
| 60. return |
- Lines (1, 2) contain the input and output information of the algorithm. The input includes and . contains the bounding boxes of intermediate results, and contains the bounding boxes of the full-frame. is the result returned by the algorithm. It includes the final bounding boxes.
- The parameters are set using Lines (3–7). and are the predefined thresholds of IoU and BTA, respectively, that are used to consider whether two neighboring bounding boxes are merged.
- Lines (8–11) set the initial status of all boxes. and are the status of the bounding boxes in and , respectively.
- Lines (12–20) measure the similarity between bounding boxes in and .
- Lines (29–38) show that if the coupled bounding boxes have a higher IoU or BTA value than the respective thresholds, they can be merged to create a new bounding box. adds the new bounding box, and the status of these coupled bounding boxes is set to false.
- Lines (39–48) determine the bounding boxes that belong to but not to . In other words, their IoU values equal zero and these bounding are added to .
- Similarly, lines (49–58) determine the bounding boxes that belong to but not . These bounding boxes are added to .
- Lines (59–60) reduce the BTA threshold by a fixed each time the algorithm is repeated. Finally, the program returns a list of final bounding boxes.
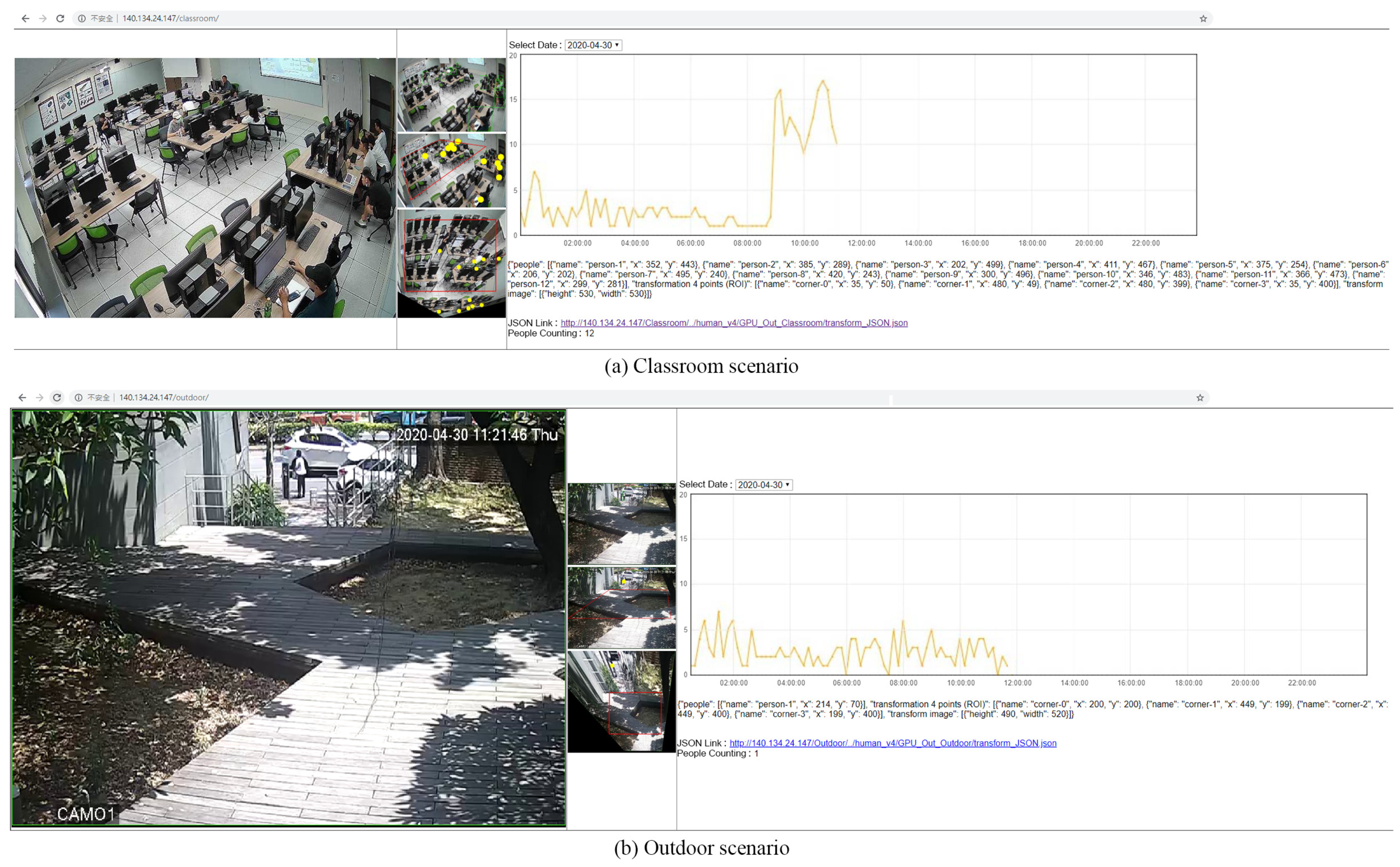
4. System Implementation and Prototype
5. Experimental Results
5.1. Testing Datasets
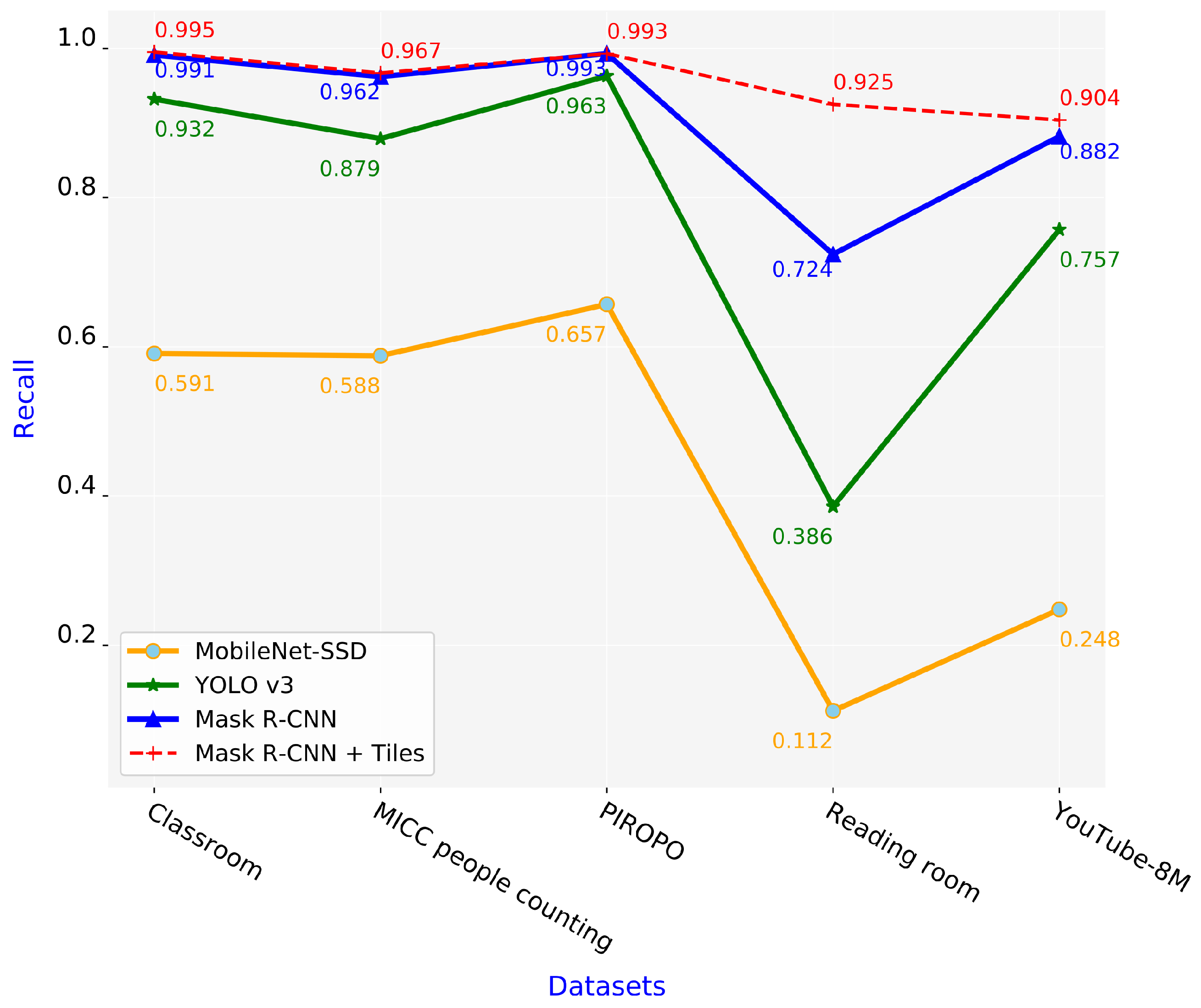
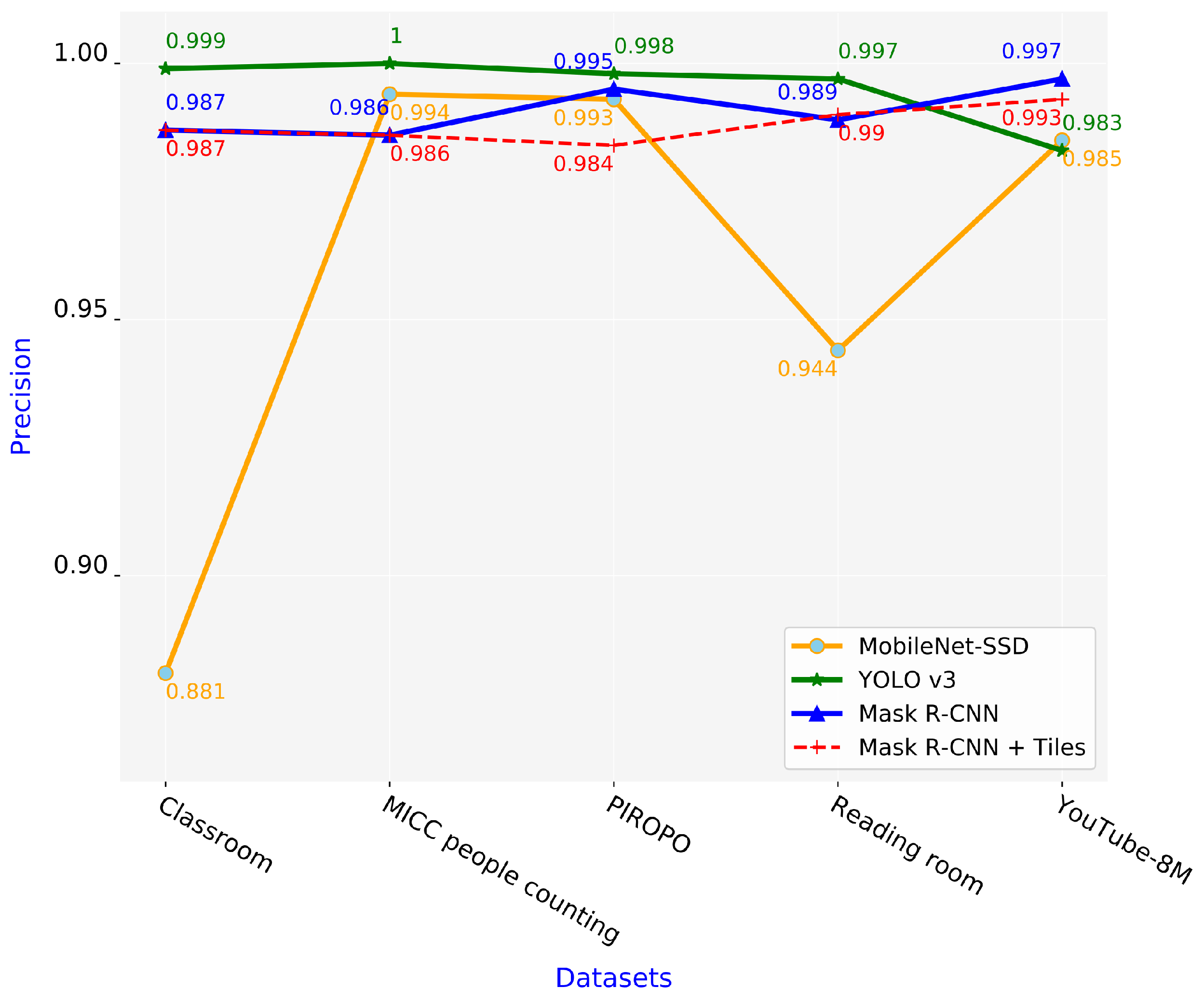
5.2. Comparison of Schemes in Terms of Precision and Recall
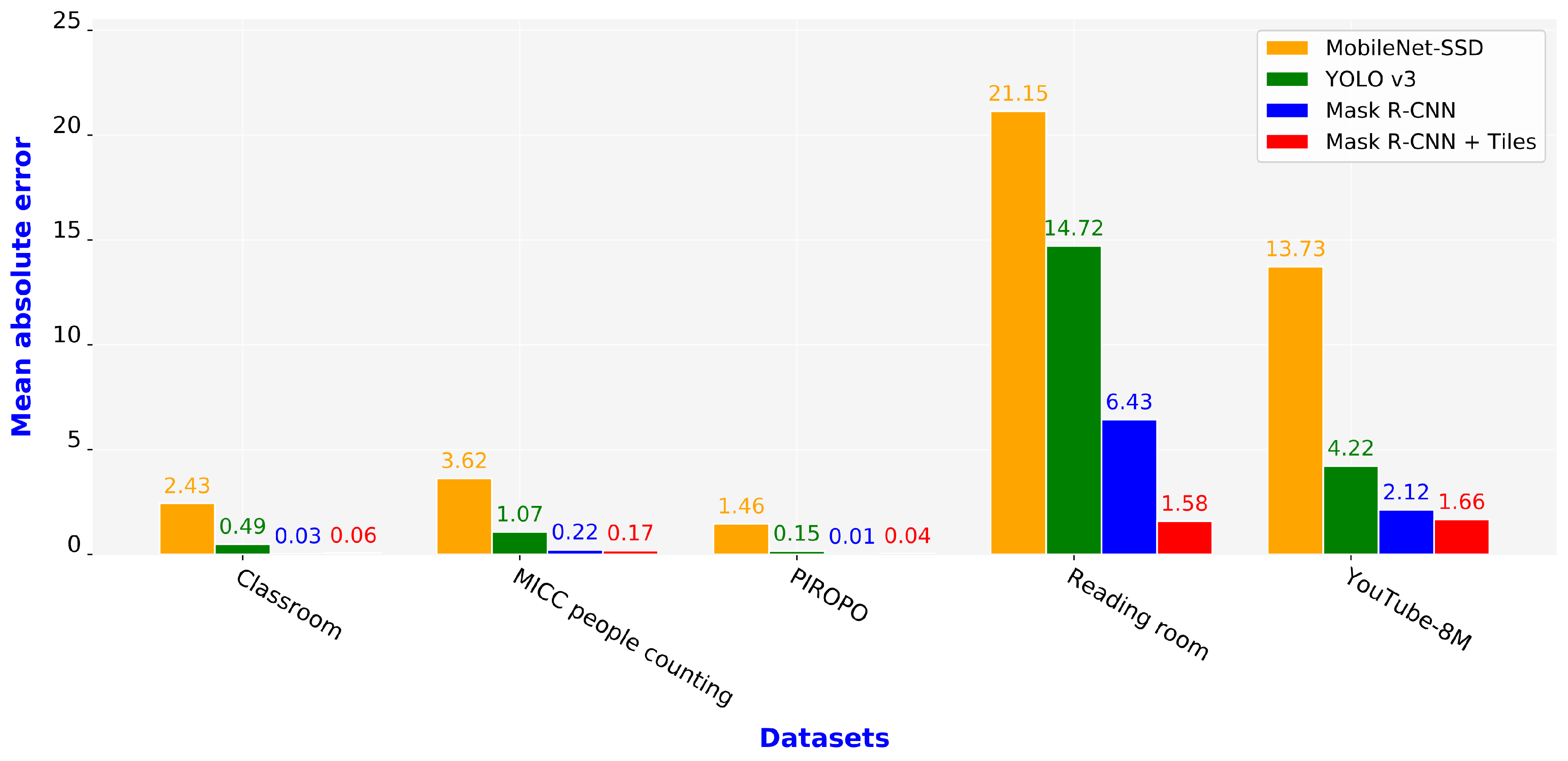
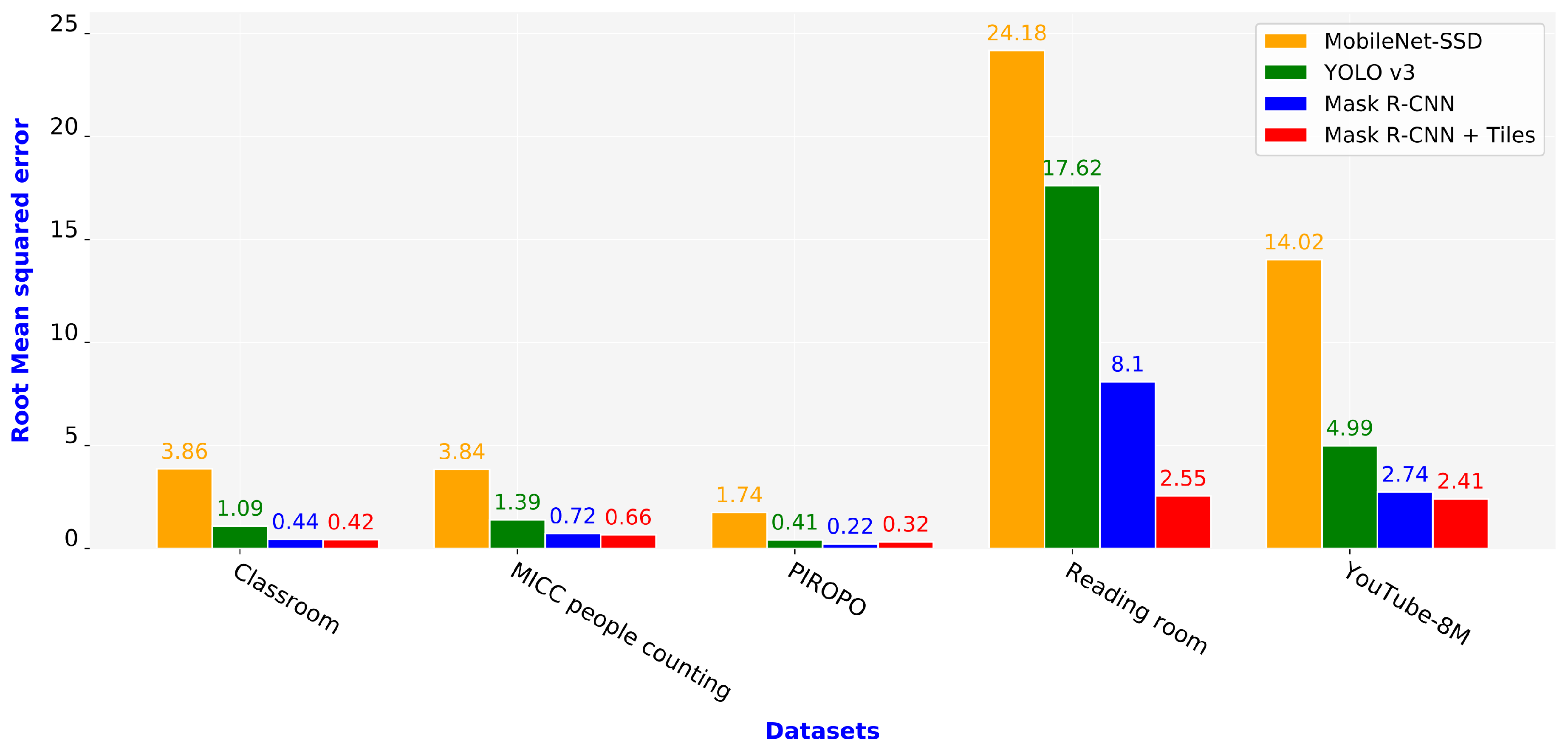
5.3. Evaluation of Schemes Using MAE and RMSE
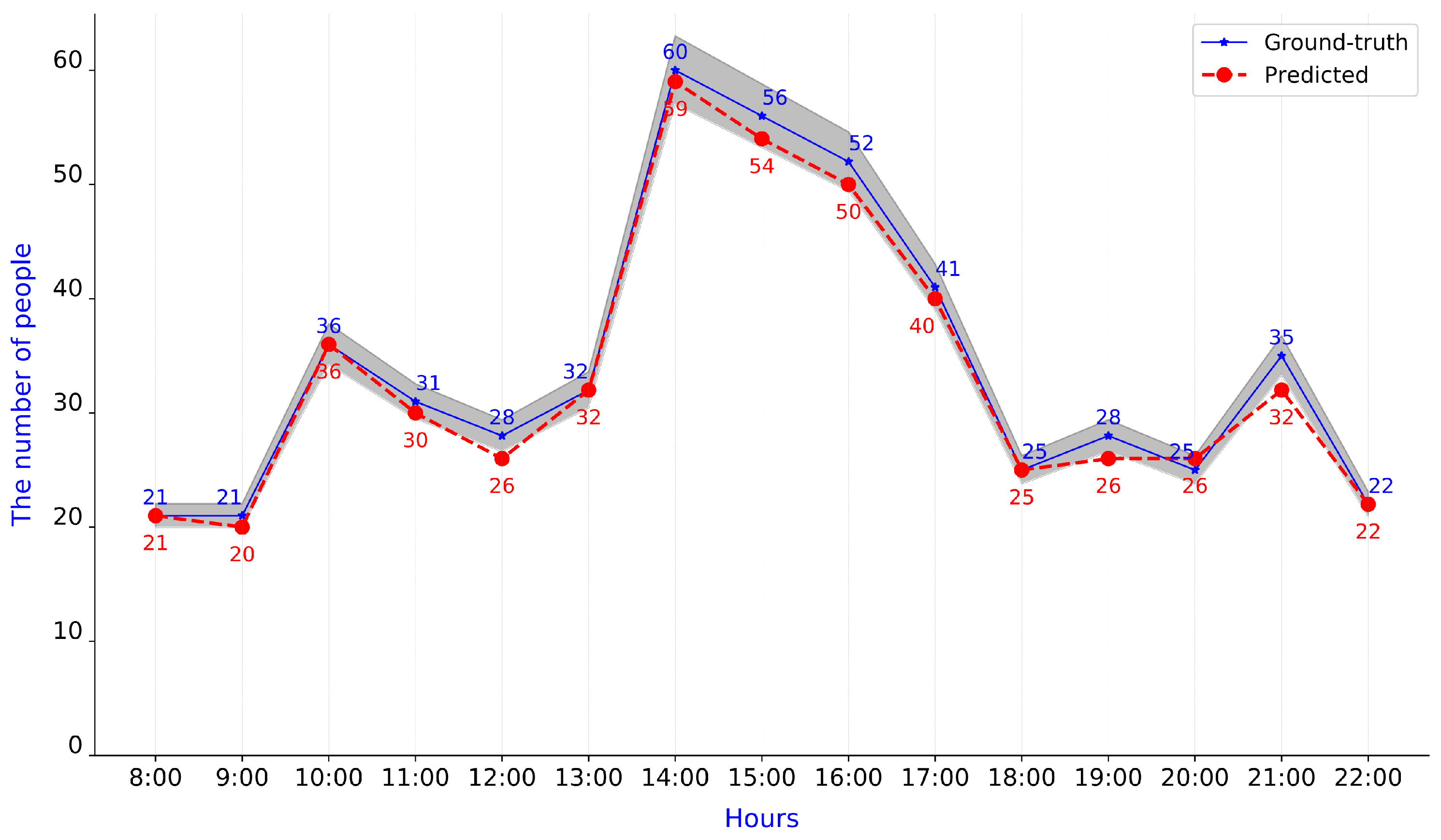
5.4. Analysis of Monitoring System
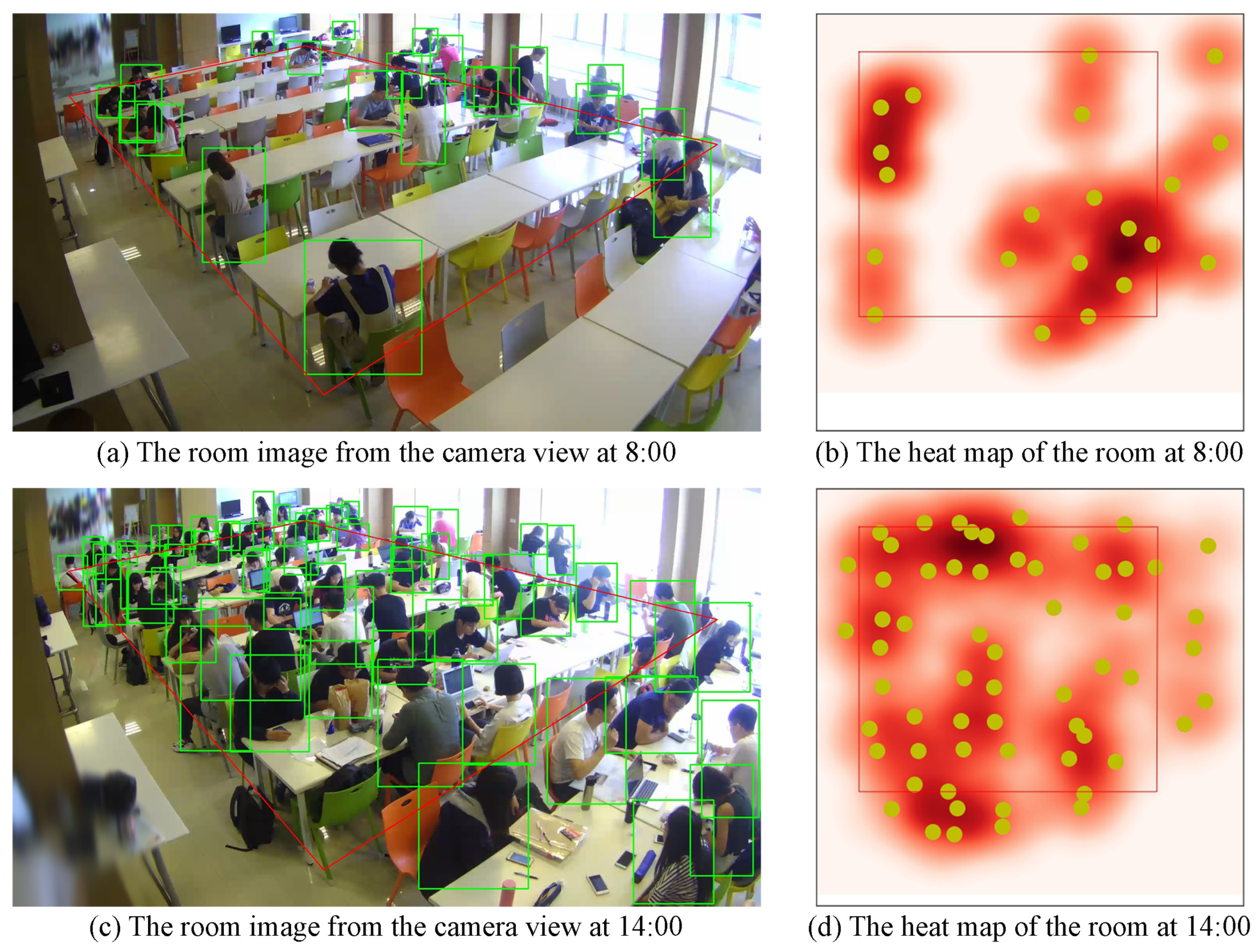
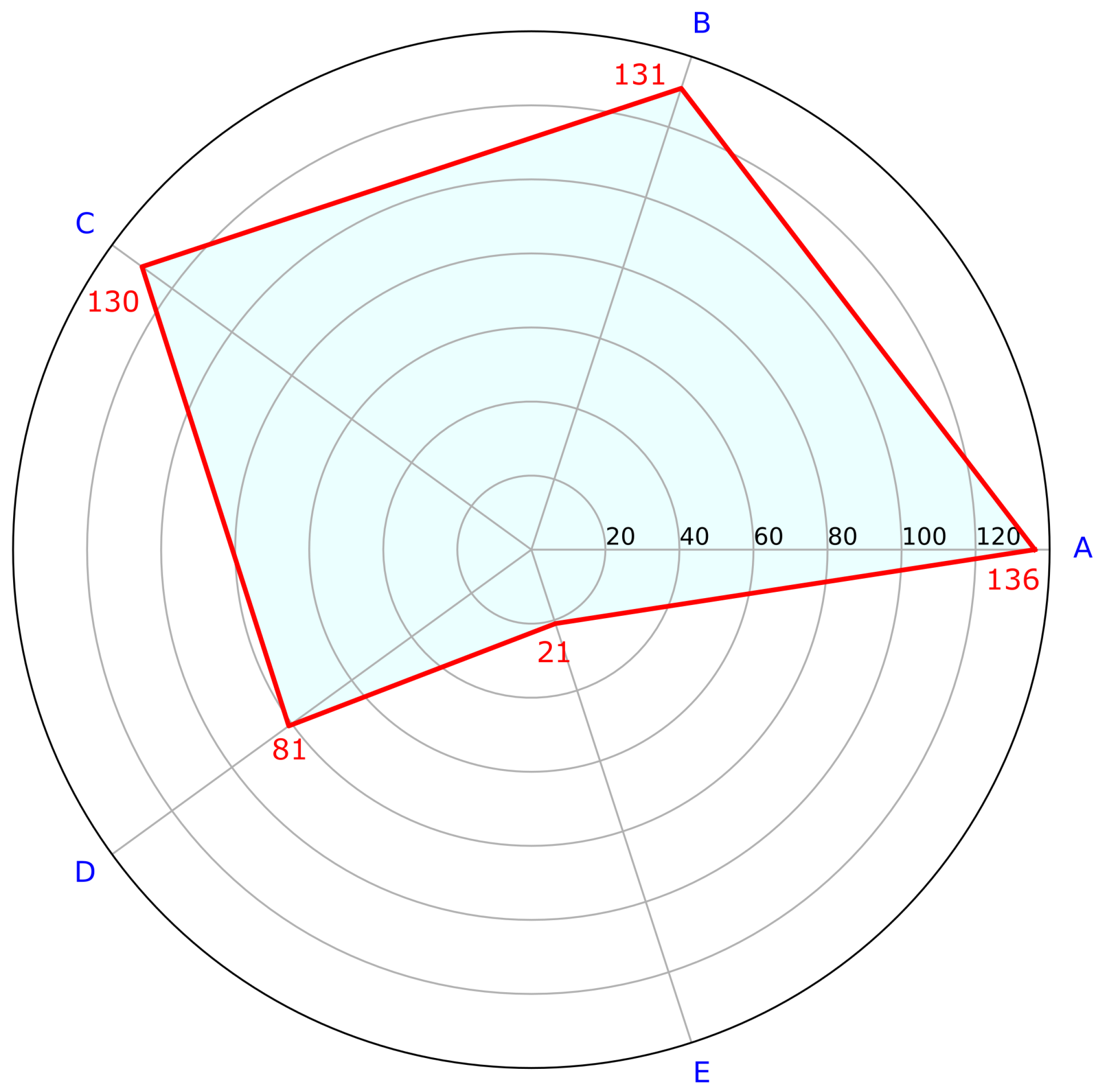
5.5. Evaluation of Used Areas in Room
5.6. Summary
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tariq, O.B.; Lazarescu, M.T.; Iqbal, J.; Lavagno, L. Performance of machine learning classifiers for indoor person localization with capacitive sensors. IEEE Access 2017, 5, 12913–12926. [Google Scholar] [CrossRef]
- Setiawan, A.; Yazid, A.S.; Wahyudi, M.D.R. Room monitoring system using openWRT-based webcam. Int. J. Inform. Dev. 2015, 4, 15–23. [Google Scholar] [CrossRef] [Green Version]
- Mahamad, A.K.; Saon, S.; Hashim, H.; Ahmadon, M.A.; Yamaguchi, S. Cloud-based people counter. Bull. Electr. Eng. Inform. 2020, 9, 284–291. [Google Scholar] [CrossRef]
- Lee, G.C.; Lee, S.H.; Yoo, J. 3-D people counting with a stereo camera on gpu embedded board. Appl. Sci. 2018, 8, 2017. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, V.; Oliveira, H.; Silva, J.A.; Vieira, T.; Oliveira, K. RetailNet: A deep learning approach for people counting and hot spots detection in retail stores. In Proceedings of the 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–31 October 2019; pp. 155–162. [Google Scholar]
- Dow, C.R.; Ngo, H.H.; Lee, L.H.; Lai, P.Y.; Wang, K.C.; Bui, V.T. A crosswalk pedestrian recognition system by using deep learning and zebra-crossing recognition techniques. Softw. Pract. Exp. 2019, 1–15. [Google Scholar] [CrossRef]
- Kiran, A.G.; Murali, S. Automatic rectification of perspective distortion from a single image using plane homography. Int. J. Comput. Sci. Appl. 2013, 3, 47–58. [Google Scholar]
- Yang, S.J.; Ho, C.C.; Chen, J.Y.; Chang, C.Y. Practical homography-based perspective correction method for license plate recognition. In Proceedings of the 2012 International Conference on Information Security and Intelligent Control, Yunlin, Taiwan, 14–16 August 2012; pp. 198–201. [Google Scholar]
- Suran, K. QR code image correction based on corner detection and convex hull algorithm. J. Multimed. 2013, 8, 662–668. [Google Scholar]
- Li, K.; Meng, F.; Huang, Z.; Wang, Q. A correction algorithm of QR code on cylindrical surface. J. Phys. Conf. Ser. 2019, 1237, 1–6. [Google Scholar] [CrossRef]
- Santana-Cedrés, D.; Gomez, L.; Alemán-Flores, M.; Salgado, A.; Esclarín, J.; Mazorra, L.; Alvarez, L. Automatic correction of perspective and optical distortions. Comput. Vis. Image Underst. 2017, 161, 1–10. [Google Scholar] [CrossRef]
- Yang, S.; Lin, C.; Liao, K.; Zhao, Y.; Liu, M. Unsupervised fisheye image correction through bidirectional loss with geometric prior. J. Vis. Commun. Image Represent. 2020, 66, 1–10. [Google Scholar] [CrossRef]
- Rong, J.; Huang, S.; Shang, Z.; Ying, X. Radial lens distortion correction using convolutional neural networks trained with synthesized images. In Proceedings of the 13th Asian Conference on Computer Vision (ACCV’16), Taipei, Taiwan, 20–24 November 2016; pp. 35–49. [Google Scholar]
- Yin, X.; Wang, X.; Yu, J.; Zhang, M.; Fua, P.; Tao, D. FishEyeRecNet: A multi-context collaborative deep network for fisheye image rectification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 469–484. [Google Scholar]
- Lőrincz, S.B.; Pável, S.; Csató, L. Single view distortion correction using semantic guidance. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Liao, K.; Lin, C.; Zhao, Y.; Gabbouj, M. DR-GAN: Automatic radial distortion rectification using conditional gan in real-time. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 725–733. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Plastiras, G.; Kyrkou, C.; Theocharides, T. Efficient convnet-based object detection for unmanned aerial vehicles by selective tile processing. In Proceedings of the 12th International Conference on Distributed Smart Cameras, Eindhoven, The Netherlands, 3–4 September 2018; pp. 1–6. [Google Scholar]
- Růžička, V.; Franchetti, F. Fast and accurate object detection in high resolution 4K and 8K video using GPUs. In Proceedings of the 2018 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 25–27 September 2018; pp. 1–7. [Google Scholar]
- Unel, F.O.; Ozkalayci, B.O.; Cigla, C. The power of tiling for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–10. [Google Scholar]
- Wang, Y.; Zhang, Y.; Zhang, Y.; Zhao, L.; Sun, X.; Guo, Z. SARD: Towards scale-aware rotated object detection in aerial imagery. IEEE Access 2019, 7, 173855–173865. [Google Scholar] [CrossRef]
- Ward, S.; Gittens, M.; Rock, N.; James, K. CampusEMonitor: Intelligent campus environment room monitoring system. In Proceedings of the 2019 ACM SIGUCCS Annual Conference, New Orleans, LA, USA, 3–6 October 2019; pp. 165–172. [Google Scholar]
- An, J.; Chung, W.Y. Wavelength-division multiplexing optical transmission for EMI-free indoor fine particulate matter monitoring. IEEE Access 2018, 6, 74885–74894. [Google Scholar] [CrossRef]
- Htun, S.N.N.; Zin, T.T.; Hama, H. Virtual grounding point concept for detecting abnormal and normal events in home care monitoring systems. Appl. Sci. 2020, 10, 3005. [Google Scholar] [CrossRef]
- Basalamah, S.; Khan, S.D.; Ullah, H. Scale driven convolutional neural network model for people counting and localization in crowd scenes. IEEE Access 2019, 7, 71576–71584. [Google Scholar] [CrossRef]
- Anh, B.N.; Son, N.T.; Lam, P.T.; Chi, L.P.; Tuan, N.H.; Dat, N.C.; Trung, N.H.; Aftab, M.U.; Dinh, T.V. A computer-vision based application for student behavior monitoring in classroom. Appl. Sci. 2019, 9, 4729. [Google Scholar]
- Jiang, B.; Xu, W.; Guo, C.; Liu, W.; Cheng, W. A classroom concentration model based on computer vision. In Proceedings of the ACM Turing Celebration Conference-China (ACM TURC 2019), Chengdu, China, 17–19 May 2019; pp. 1–6. [Google Scholar]
- Matilda, S.; Shahin, K. Student attendance monitoring system using image processing. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Puducherry, India, 29–30 March 2019; pp. 1–4. [Google Scholar]
- Liu, Z.; Wang, S.; Ding, X. ROI perspective transform based road marking detection and recognition. In Proceedings of the 2012 International Conference on Audio, Language and Image Processing, Shanghai, China, 16–18 July 2012; pp. 841–846. [Google Scholar]
- Li, X.; Li, S.; Bai, W.; Cui, X.; Yang, G.; Zhou, H.; Zhang, C. Method for rectifying image deviation based on perspective transformation. IOP Conf. Ser. Mater. Sci. Eng. 2017, 231, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Ansari, I.; Lee, Y.; Jeong, Y.; Shim, J. Recognition of car manufacturers using faster R-CNN and perspective transformation. J. Korea Multimed. Soc. 2018, 21, 888–896. [Google Scholar]
- Ansari, I.; Shim, J. Brief paper: Vehicle manufacturer recognition using deep learning and perspective transformation. J. Multimed. Inf. Syst. 2019, 6, 235–238. [Google Scholar] [CrossRef]
- Geometric Image Transformations. Available online: https://docs.opencv.org/2.4/modules/imgproc/doc/geometric_transformations.html (accessed on 22 December 2019).
- Chen, Y.C. A tutorial on kernel density estimation and recent advances. arXiv 2017, arXiv:1704.03924. [Google Scholar] [CrossRef]
- Mask R-CNN. Available online: https://github.com/matterport/Mask_RCNN (accessed on 15 November 2019).
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- COCO—Common Objects in Context. Available online: http://cocodataset.org/#home (accessed on 15 November 2019).
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Intersection over Union (IoU) for Object Detection. Available online: https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/ (accessed on 22 December 2019).
- MobileNet-SSD. Available online: https://github.com/chuanqi305/MobileNet-SSD (accessed on 15 November 2019).
- Karnalim, O.; Budi, S.; Santoso, S.; Handoyo, E.D.; Toba, H.; Nguyen, H.; Malhotra, V. FACE—Face at classroom environment: Dataset and exploration. In Proceedings of the 2018 Eighth International Conference on Image Processing Theory, Tools and Applications (IPTA), Xi’an, China, 7–10 November 2018; pp. 1–6. [Google Scholar]
- Bondi, E.; Seidenari, L.; Bagdanov, A.D.; Bimbo, A.D. Real-time people counting from depth imagery of crowded environments. In Proceedings of the 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS 2014), Seoul, Korea, 26–29 August 2014; pp. 337–342. [Google Scholar]
- PIROPO Dataset. Available online: https://sites.google.com/view/visionlearning/databases/piropo-database (accessed on 5 March 2020).
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- YouTube-8M Video. Available online: https://youtu.be/UHz4fh93SOc (accessed on 5 March 2020).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Resolution of Image | Number of Images Used | Number of People | Average Number of People Per Image |
|---|---|---|---|---|
| Classroom | 1024 × 1024, 1024 × 576, 576 × 1024 | 100 | 738 | 7.38 |
| MICC people counting | 640 × 480 | 100 | 885 | 8.85 |
| PIROPO | 704 × 576 | 100 | 431 | 4.31 |
| YouTube-8M | 1440 × 1080 | 100 | 1836 | 18.36 |
| Reading room | 1920 × 1072 | 100 | 2401 | 24.01 |
| Schemes | MobileNet-SSD | YOLO v3 | Mask R-CNN | Mask R-CNN + Tiles |
|---|---|---|---|---|
| Processing rate (fps) | 14.08 | 3.97 | 2.05 | 0.53 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, H.-H.; Lin, F.-C.; Sehn, Y.-T.; Tu, M.; Dow, C.-R. A Room Monitoring System Using Deep Learning and Perspective Correction Techniques. Appl. Sci. 2020, 10, 4423. https://doi.org/10.3390/app10134423
Ngo H-H, Lin F-C, Sehn Y-T, Tu M, Dow C-R. A Room Monitoring System Using Deep Learning and Perspective Correction Techniques. Applied Sciences. 2020; 10(13):4423. https://doi.org/10.3390/app10134423
Chicago/Turabian StyleNgo, Huu-Huy, Feng-Cheng Lin, Yang-Ting Sehn, Mengru Tu, and Chyi-Ren Dow. 2020. "A Room Monitoring System Using Deep Learning and Perspective Correction Techniques" Applied Sciences 10, no. 13: 4423. https://doi.org/10.3390/app10134423
APA StyleNgo, H. -H., Lin, F. -C., Sehn, Y. -T., Tu, M., & Dow, C. -R. (2020). A Room Monitoring System Using Deep Learning and Perspective Correction Techniques. Applied Sciences, 10(13), 4423. https://doi.org/10.3390/app10134423