Learning Effective Feature Representation against User Privacy Protection on Social Networks



Abstract
:1. Introduction
2. Related Work
3. Problem Statement
4. The Proposed Method
4.1. Structure-Attribute Mutually-Reinforced Representation
4.2. Community-Cluster Informed NRL (c2n2v)
4.3. Downstream Tasks
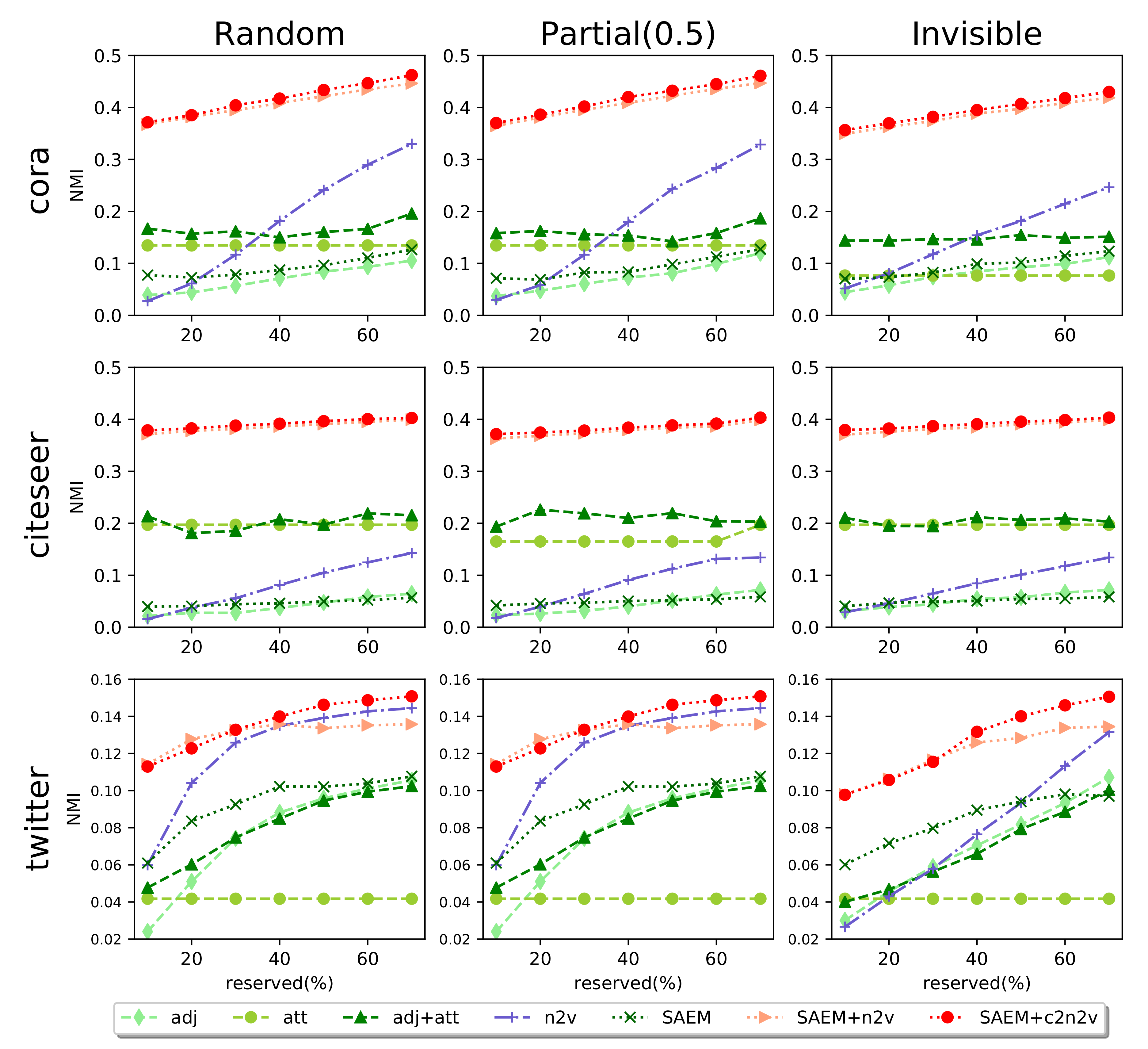
- Community Detection (CD). By regarding node embeddings as features, we apply K-means clustering algorithm implemented by scikit-learn (https://scikit-learn.org/stable/) to detect network communities. The ground-truth number of communities is given. Note that we choose K-means because it is the basic, simple, and widely-used clustering approach. Also since existing network representation learning methods [26,27] utilize K-means to fairly compare different node embedding generation models in the task of community detection, we are advised to follow accordingly.
- Link Prediction (LP). This task is to predict the existence of links, given the existing network structure. We need to have the feature vectors of links and non-links. We follow node2vec [4] to employ Hadamard operator, i.e., element-wise product, to generate the feature vectors from the embeddings of two nodes. To obtain links, we remove 50% of edges chosen randomly from the privacy-protected network while ensuring that the residual network is connected. To have non-links, we randomly sample an equal number of node pairs without edges connecting them. Note that since in our experiments, we mainly target at improving node2vec under the privacy protection setting, we follow the setting of the original node2vec method [4] to randomly removing 50% of edges.
- Node Classification (NC). Given a certain fraction of nodes and all of their labels, the goal is to classify the labels for the remaining nodes. Node embeddings are treated as features. We utilize one-vs-rest logistic regression classifier with L2 regularization as the classifier.
5. Experiments
5.1. Evaluation Settings
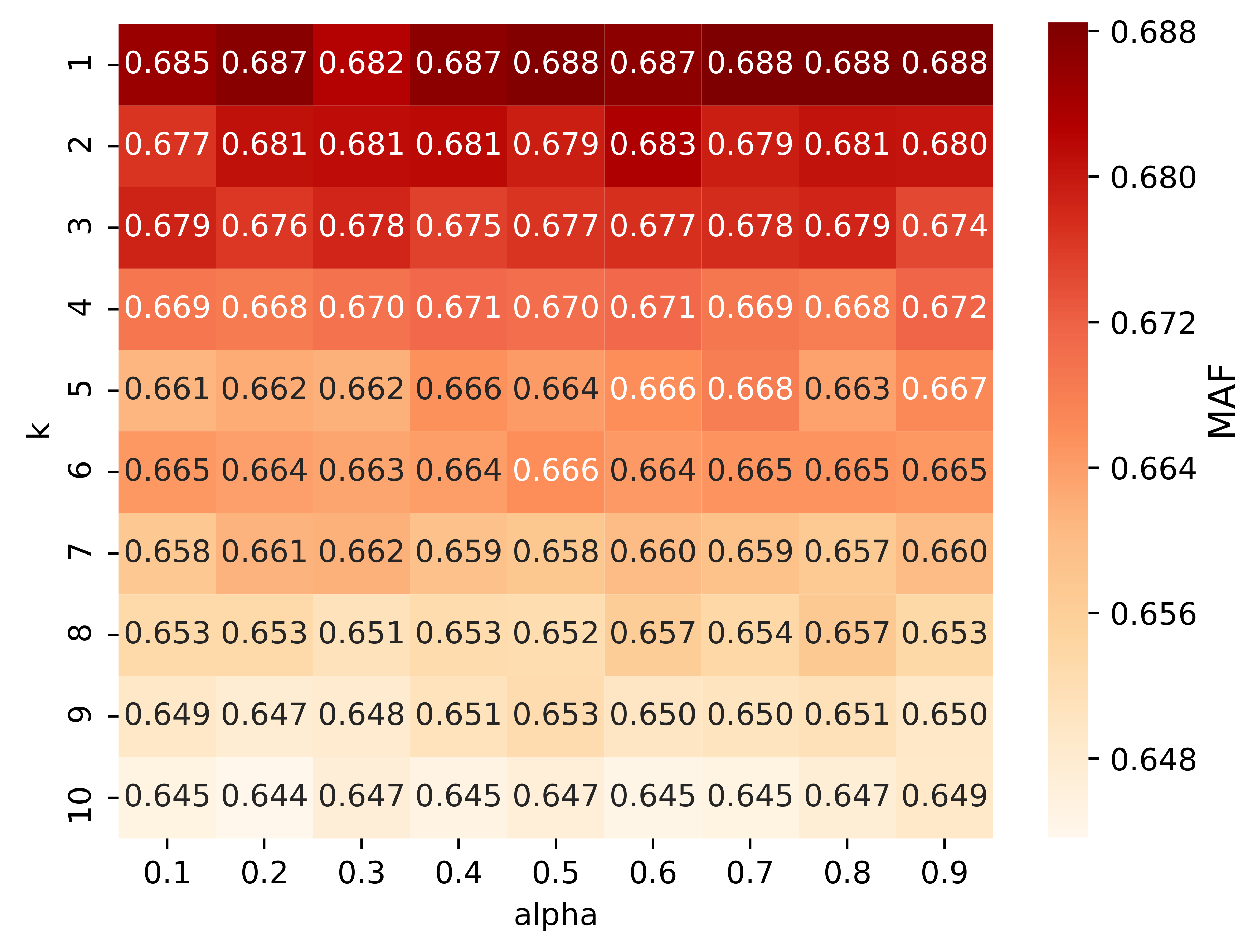
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cui, P.; Wang, X.; Pei, J.; Zhu, W. A Survey on Network Embedding. IEEE Trans. Knowl. Data Eng. TKDE 2018, 31, 833–852. [Google Scholar] [CrossRef] [Green Version]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, WWW, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Huang, X.; Li, J.; Hu, X. Label informed attributed network embedding. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, WSDM, Cambridge, UK, 6–10 February 2017; pp. 731–739. [Google Scholar]
- Gao, H.; Huang, H. Deep Attributed Network Embedding. In Proceedings of the International Joint Conferences on Artificial Intelligence, IJCAI, Stockholm, Sweden, 2018, 13–19 July; pp. 3364–3370.
- Benevenuto, F.; Rodrigues, T.; Cha, M.; Almeida, V. Characterizing User Behavior in Online Social Networks. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, IMC ’09, Chicago IL, USA, 4–10 November 2009; pp. 49–62. [Google Scholar]
- McAuley, J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, NIPS ’12, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 539–547. [Google Scholar]
- Liu, H.; Pardoe, D.; Liu, K.; Thakur, M.; Cao, F.; Li, C. Audience Expansion for Online Social Network Advertising. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 165–174. [Google Scholar]
- Rath, B.; Gao, W.; Ma, J.; Srivastava, J. Utilizing computational trust to identify rumor spreaders on Twitter. Soc. Netw. Anal. Min. 2018, 8, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Guy, I. Social Recommender Systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 511–543. [Google Scholar]
- Xu, D.; Yuan, S.; Wu, X.; Phan, H. DPNE: Differentially Private Network Embedding. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, PAKDD, Melbourne, Australia, 3–6 June 2018; pp. 235–246. [Google Scholar]
- Zhang, S.; Ni, W. Graph Embedding Matrix Sharing With Differential Privacy. IEEE Access 2019, 7, 89390–89399. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages and Programming, part II ICALP 2006, Venice, Italy, 10–14, July 2006; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany; Volume 4052, pp. 1–12.
- Rahman, T.; Surma, B.; Backes, M.; Zhang, Y. Fairwalk: Towards Fair Graph Embedding. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI, Macao, China, 10–16 August 2019; pp. 3289–3295. [Google Scholar]
- Bose, A.; Hamilton, W. Compositional Fairness Constraints for Graph Embeddings. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 9–15 June 2019; pp. 715–724. [Google Scholar]
- Zhang, Z.; Yang, H.; Bu, J.; Zhou, S.; Yu, P.; Zhang, J.; Ester, M.; Wang, C. ANRL: Attributed Network Representation Learning via Deep Neural Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18. International Joint Conferences on Artificial Intelligence Organization, Stockholm, Sweeden, 13–19 July 2018; pp. 3155–3161. [Google Scholar]
- Wang, H.; Chen, E.; Liu, Q.; Xu, T.; Du, D.; Su, W.; Zhang, X. A United Approach to Learning Sparse Attributed Network Embedding. In Proceedings of the IEEE International Conference on Data Mining, ICDM, Singapore, Singapore, 17–20 November 2018; pp. 557–566. [Google Scholar]
- Wang, J.; Shen, H.T.; Song, J.; Ji, J. Hashing for Similarity Search: A Survey. arXiv 2014, arXiv:cs.DS/1408.2927. [Google Scholar]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lovasz, L. Random Walks on Graphs: A Survey. Bolyai Soc. Math. Stud. 1993, 2, 1–46. [Google Scholar]
- Bottou, L. Stochastic gradient learning in neural networks. Proc. Neuro Nımes 1991, 91. [Google Scholar]
- Tian, F.; Gao, B.; Cui, Q.; Chen, E.; Liu, T.Y. Learning Deep Representations for Graph Clustering. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, AAAI ’14, Québec City, QU, Canada, 27–31 July 2014; pp. 1293–1299. [Google Scholar]
- Chen, Z.; Chen, C.; Zhang, Z.; Zheng, Z.; Zou, Q. Variational Graph Embedding and Clustering with Laplacian Eigenmaps. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 2019, 10–16 August 2019; pp. 2144–2150. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Yang, J.; Leskovec, J. Defining and Evaluating Network Communities Based on Ground-Truth. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, ICDM ’12, Brussels, Belgium, 10 December 2012; pp. 745–754. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Kuhl, N.; Lobana, J.; Meske, C. Do you comply with AI? – Personalized explanations of learning algorithms and their impact on employees’ compliance behavior. arXiv 2020, arXiv:cs.CY/2002.08777. [Google Scholar]
- Meske, C.; Bunde, E. Using Explainable Artificial Intelligence to Increase Trust in Computer Vision. arXiv 2020, arXiv:cs.HC/2002.01543. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Nodes | #Edges | #Components | #Attributes | |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 78 | 1433 |
| Citeseer | 3312 | 4715 | 438 | 3703 |
| 212 | 5054 | 1.6 | 1178 |
| Cora | Citeseer | ||||||
|---|---|---|---|---|---|---|---|
| Random | Partial (0.5) | Invisible | Random | Partial (0.5) | Invisible | ||
| CD | n2v | 0.422 | 0.422 | 0.397 | 0.391 | 0.384 | 0.390 |
| c2n2v | 0.434 | 0.432 | 0.407 | 0.396 | 0.388 | 0.395 | |
| LP | n2v | 0.846 | 0.850 | 0.848 | 0.913 | 0.912 | 0.914 |
| c2n2v | 0.854 | 0.858 | 0.857 | 0.918 | 0.918 | 0.920 | |
| NC | n2v | 0.706 | 0.709 | 0.704 | 0.635 | 0.631 | 0.633 |
| c2n2v | 0.711 | 0.710 | 0.714 | 0.640 | 0.638 | 0.638 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.-T.; Zeng, Z.-Y. Learning Effective Feature Representation against User Privacy Protection on Social Networks. Appl. Sci. 2020, 10, 4835. https://doi.org/10.3390/app10144835
Li C-T, Zeng Z-Y. Learning Effective Feature Representation against User Privacy Protection on Social Networks. Applied Sciences. 2020; 10(14):4835. https://doi.org/10.3390/app10144835
Chicago/Turabian StyleLi, Cheng-Te, and Zi-Yun Zeng. 2020. "Learning Effective Feature Representation against User Privacy Protection on Social Networks" Applied Sciences 10, no. 14: 4835. https://doi.org/10.3390/app10144835
APA StyleLi, C. -T., & Zeng, Z. -Y. (2020). Learning Effective Feature Representation against User Privacy Protection on Social Networks. Applied Sciences, 10(14), 4835. https://doi.org/10.3390/app10144835