Scenario-Based Marine Oil Spill Emergency Response Using Hybrid Deep Reinforcement Learning and Case-Based Reasoning

Abstract
:1. Introduction
- A hybrid method using deep reinforcement learning (DRL) and CBR is proposed to produce a preliminary solution for marine oil spill emergencies.
- To address the uncertainty of marine oil spill accidents, a preprocess of constructing a marine oil spill scenario tree is employed, and the scenario is also used to represent historical cases in our CBR system.
- Reward functions are considered based on different decision intentions to supporting decision making; this approach may be helpful for improving the level of oil spill emergency response.
2. Materials and Methods
- Retention. Scenario analysis is employed to address marine oil spill accident uncertainties, such as spill magnitude uncertainties and the uncertainties related to spill accident evolution. Each individual historical case can be represented as a detailed “chain of consequences”, which is named the scenario chain in this paper. Through the cluster algorithm, similar scenario instances can be merged as a typical scenario, which consequently expands the scenario and forms a branch to construct scenario trees. Through scenario analysis, marine oil spill cases are stored as scenario instances and scenario trees in the scenario library.
- Retrieval. When applying cases to train the proposed hybrid CBR/DRL model, the scenario library is considered as an environment for the agent to explore, and each marine oil spill scenario instance is regarded as a state of the environment. Thus, each instance is a vector composed of features representing the marine oil spill scenario.
- Reuse. The agent chooses the action with the highest expected value using the -greedy strategy. With the probability of the strategy, the algorithm chooses an action based on the available knowledge, and with the probability of , a random action is selected [20].
- Revision. The revision phase uses the DQN to update to the utilities Q for actions chosen by the agent. Eligibilities represent the cumulative contributions of individual state and action combinations in previous time steps.
2.1. Marine Oil Spill Scenario and Scenario Tree Construction Method
2.2. Hybrid DRL/CBR Method for Marine Oil Spill Emergency Response
- State. A marine oil spill scenario instance can be regarded as a state, which is a vector composed of features representing marine oil spill accidents that have been stored in the CBR system. The scenario instance and typical scenario are represented according to Equation (1).
- Reward. An interaction occurs between the marine oil spill scenario observed and the step-by-step process of decision making in a discrete time series. If the emergency response action makes the next scenario safer, the reward of the step is close to 1, and other actions yield reward values close to 0. To reflect the severity of a marine oil spill accident, Dutch scholar W. Koops proposed a DLSA evaluation model for oil spills that used nine individual indicators to analyze oil spill pollution [24]. In the DLSA model, the indicator weights are given by expert knowledge. Human experts, whose time is valuable and scarce, often find it difficult to precisely explain their reasoning. In 1948, the problem of information quantification was solved through the concept of information entropy, which was proposed by Shannon. Based on traditional information entropy, Chen et al. defined the concept of unconventional emergency scenario–response multidimensional entropy [25]. In combination with information theory, we believe that low-probability events that occur during oil spill accidents are important to consider due to our insufficient understanding of these events and the unpredictability of the corresponding risk. In contrast, for accidents with high probability, due to the relatively sufficient knowledge of the corresponding events, response actions can be taken based on the known threat of the accident. In this paper, we consider the quantity of spilled oil, vessel characteristic, sea area, and sea conditions as factors that influence the severity of marine oil spill accidents. In addition, information entropy is employed to assist in measuring the severity of marine oil spill scenarios, instead of using expert knowledge. The eleven indicators considered can be matched among marine oil spill scenario instances. The indicator of scenario instance obeys the distribution . The term is the probability that the indicator has a value at . Thus, the entropy of a marine oil spill scenario can be defined aswhere is the mapping function from indicator to the risk level; the details of this function are given in Appendix A. In this paper, we regard the severity of a marine oil scenario as a binary state that is safe or unsafe. Therefore, we use the sigmoid function [26] to calculate the severity of marine oil scenarios as the reward function,where , and the value of is close to 1, which means that the evolution of marine oil spill accidents tends to become increasingly safe. When the value of is close to 0, the evolution of an accident can gradually become out of control, and the situation can become unsafe. The 11 indicators used in this paper are shown in Table 2.
- Action. From the branches of scenario trees and the International Tanker Owners Pollution Federation Limited (ITOPF) technical information papers, we developed a relatively comprehensive response action set for marine oil spill emergencies, which can be divided into three categories, as shown in Table 3. In this paper, one-hot coding [27] is employed to digitize discrete and disordered features, and this approach mainly uses an n-bit status registry to encode states. The number of marine oil spill emergency response actions is 15. For example, the action “use of booms” can be encoded as [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], and “use of dispersants” can be encoded as [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0].
3. Experiments and Results
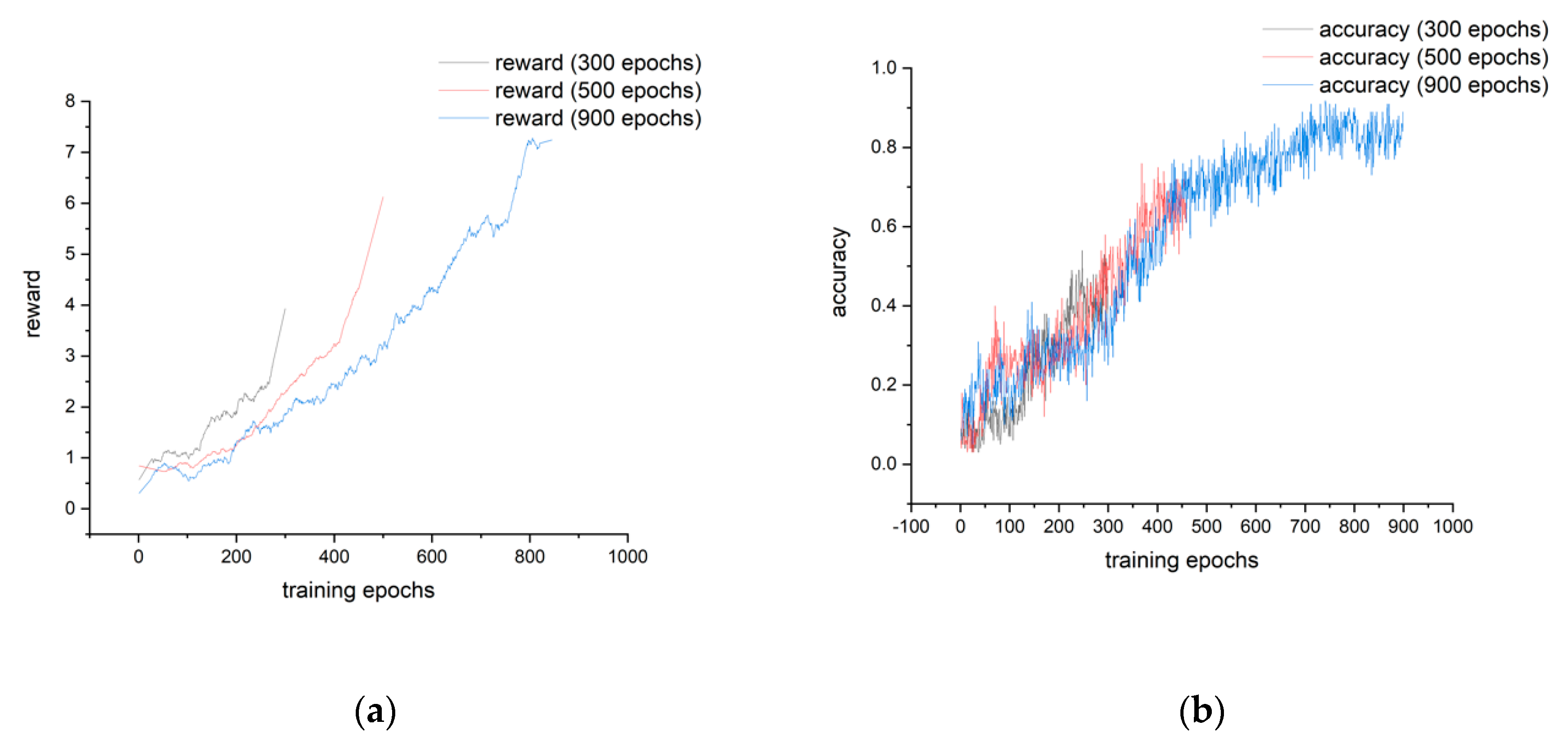
3.1. The Training of the Action Policy Selection Process in Marine Oil Spill Emergency Response
3.2. Comparison of Hybrid Application Results and Similarity Matching Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level of Damage | Evaluation Value |
|---|---|
| Small | 0~0.2 |
| Normal | 0.2~0.4 |
| Dangerous | 0.4~0.6 |
| Very dangerous | 0.6~0.8 |
| Extremely dangerous | 0.8~1.0 |
| Spilled Oil—Toxicity (Soluble Aromatic Hydrocarbon Derivatives) | Evaluation Value |
| Almost insoluble in water and includes no oil-containing aromatic hydrocarbons | 0.2 |
| Heavy kerosene, some aromatic hydrocarbons and other oils | 0.6 |
| Gasoline, light kerosene, many aromatic hydrocarbons and other oils | 1.0 |
| Spilled Oil—Amount (t) | Evaluation Value |
| <5 | 0.1 |
| 5~50 | 0.3 |
| 50~100 | 0.5 |
| 100~150 | 0.7 |
| 150~200 | 0.9 |
| 200 | 1.0 |
| Spilled Oil—Flammable | Evaluation Value |
| Heavy oil, crude oil, etc. | 0.4 |
| Heavy kerosene, etc. | 0.6 |
| Gasoline, light kerosene, etc. | 0.9 |
| Sea Conditions—Wave Height (m) | Evaluation Value |
| <0.1 | 0.1 |
| 0.1~0.5 | 0.2 |
| 0.5~1.25 | 0.4 |
| 1.25~2.5 | 0.6 |
| 2.5~4 | 0.8 |
| 4 | 1.0 |
| Sea Conditions—Wind Speed (m/s) | Evaluation Value |
| <3.3 | 0.1 |
| 3.3~7.9 | 0.2 |
| 7.9~13.8 | 0.4 |
| 13.8~20.7 | 0.6 |
| 20.7~28.4 | 0.8 |
| 28.4 | 1.0 |
| Sea Conditions—Water Temperature (°C) | Evaluation Value |
| 0.1 | |
| 20~25 | 0.3 |
| 15~20 | 0.5 |
| 10~15 | 0.7 |
| 5~10 | 0.9 |
| <5 | 1.0 |
| Sea Conditions—Visibility (n Miles) | Evaluation Value |
| 5 | 0.1 |
| 3~5 | 0.3 |
| 2~3 | 0.5 |
| 1~2 | 0.7 |
| 0.03~1 | 0.9 |
| <0.03 | 1.0 |
| Vessel—Dead Weight Tonnage | Evaluation Value |
| <160,000 | 0.1–0.3 |
| 160,000~319,999 | 0.4–0.6 |
| 320,000~549,999 | 0.7~1.0 |
| Vessel—Age (Year) | Evaluation Value |
| <5 | 0.1 |
| 5~10 | 0.3 |
| 10~15 | 0.5 |
| 15~20 | 0.7 |
| 20~25 | 0.9 |
| 25 | 1 |
| Sea Area—Self-Purification Capacity | Evaluation Value |
| Good | 0.3 |
| Normal | 0.5 |
| Bad | 0.8 |
| Sea Area—Distance to Offshoring (n MILEs) | Evaluation Value |
| >25 | 0.2 |
| 5~25 | 0.5 |
| 5 | 0.9 |
Appendix B
| Order | Ship/Accident Name | Year | Location |
|---|---|---|---|
| 1 | AEGEAN SEA | 1992 | A Coruña, Spain |
| 2 | AGIOS DIMITRIOS 1 | 2009 | Zhuhai, China |
| 3 | AGIP ABRUZZO | 1991 | Livorno Port, Italy |
| 4 | ALFA 1 | 2012 | Elefsis Bay, Greece |
| 5 | ARAGON | 1989 | Morocco |
| 6 | ARGO MERCHANT | 1976 | Nantucket Shoals, Massachusetts, USA |
| 7 | BALTIC CARRIER | 2001 | Baltic Sea, between Germany and Denmark |
| 8 | BRAER | 1993 | Garth’s Ness, Shetland |
| 9 | BUNGA KELANA 3 | 2010 | Singapore Strait, 13 km south east of Singapore |
| 10 | EAGLE OTOME | 2010 | Sabine Neches waterway, Texas, USA |
| 11 | ECE | 2006 | Channel Islands, UK |
| 12 | ERIKA | 1999 | Bay of Biscay, West of France |
| 13 | EXXON VALDEZ | 1989 | Alaska, USA |
| 14 | FLINTERSTAR | 2015 | Coast of Zeebrugge, Belgium |
| 15 | FU PING YUAN | 2010 | Incheon Port, Republic of Korea |
| 16 | GDANSK | 2011 | Ferrominera Port, Puerto Ordaz, Venezuela |
| 17 | GOLDEN TRADER | 2011 | Western coast, Denmark |
| 18 | GULSAR ANA | 2009 | Madagascar |
| 19 | HAWAIIAN PATRIOT | 1977 | 300 miles west of Hawaii, USA |
| 20 | HEBEI SPIRIT | 2007 | Taean, Republic of Korea |
| 21 | INDEPENDENTA | 1979 | Bosporus, Turkey |
| 22 | JAKOB MAERSK | 1975 | Leixoes Port, Portugal |
| 23 | KATINA P | 1992 | Mozambique Channel, Maputo, Mozambique |
| 24 | KHARK 5 | 1989 | 150 nautical miles off the coast of Morocco |
| 25 | METULA | 1974 | Eastern Strait of Magellan, Chile |
| 26 | NATUNA SEA | 2000 | Singapore Strait/Indonesia/Malaysia |
| 27 | NOVA | 1985 | Khark Island, Iran |
| 28 | OLIVA | 2011 | Nightingale Island, UK |
| 29 | PRESTIGE | 2002 | Spain/France |
| 30 | RENA | 2011 | Tauranga, New Zealand |
| 31 | ROCKNES | 2004 | Bergen, Norway |
| 32 | ROKIA DELMAS | 2006 | La Rochelle, France |
| 33 | SAMHO BROTHER | 2005 | Hsinchu, Taiwan, China |
| 34 | SEA EMPRESS | 1996 | Wales, UK |
| 35 | SEKI | 1994 | Coast of Fujairah, United Arab Emirates |
| 36 | SELENDANG AYU | 2004 | Skan Bay, Unalaska Island, USA |
| 37 | SILVER | 2013 | Coast of Tan-Tan, Morocco |
| 38 | SOLAR 1 | 2006 | Guimaras Straits, Philippines |
| 39 | ST THOMAS DE AQUINAS | 2013 | Cebu Port, Philippines |
| 40 | STOLT VALOR | 2012 | Ras Tanura, Kingdom of Saudi Arabia |
| 41 | TANIO | 1980 | Coast of Brittany, France |
| 42 | TASMAN SPIRIT | 2003 | Karachi Port, Pakistan |
| 43 | TK BREMEN | 2011 | Beach of Kerminihy, Erdeven, France |
| 44 | URQUIOLA | 1976 | Port of La Coruña, Spain |
| 45 | USHUAIA | 2008 | Antarctic Peninsula |
| 46 | SS ALTANTIC EMPRESS | 1979 | 18 miles east of the island of Tobago |
| 47 | ABT SUMMER | 1991 | 900 miles off the coast of Angola |
| 48 | CASTILLO DE BELLVER | 1983 | Cape Town, South Africa |
| 49 | AMOCO CADIZ | 1978 | Coast of Brittany, France |
| 50 | HAVEN | 1991 | Genoa, Italy |
| 51 | ODYSSEY | 1988 | 700 miles off the coast of Nova Scotia, Canada |
| 52 | TORREY CANYON | 1967 | Seven Stone Reef, Land’s End, UK |
| 53 | SEA STAR | 1972 | Gulf of Oman |
| 54 | SANCHI | 2018 | Shanghai, China |
| 55 | IRENES SERENADE | 1980 | Navarino Bay, Greece |
References
- Paulson, P.; Juell, P. Reinforcement learning in case-based systems. IEEE Potentials 2004, 23, 31–33. [Google Scholar] [CrossRef]
- Chou, J.S. Applying AHP-based CBR to estimate pavement maintenance cost. Tsinghua Sci. Technol. 2008, 13, 114–120. [Google Scholar] [CrossRef]
- Zhai, Z.; Martínez Ortega, J.F.; Beltran, V.; Lucas Martínez, N. An Associated Representation Method for Defining Agricultural Cases in a Case-Based Reasoning System for Fast Case Retrieval. Sensors 2019, 19, 5118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amailef, K.; Lu, J. Ontology-supported case-based reasoning approach for intelligent m-Government emergency response services. Decis. Support Syst. 2013, 55, 79–97. [Google Scholar] [CrossRef]
- Mata, A.; Rodríguez, J.M.C. Forecasting the probability of finding oil slicks using a CBR system. Expert Syst. Appl. 2009, 36, 8239–8246. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Li, X.Y. Improving emergency response to cascading disasters: Applying case-based reasoning towards urban critical infrasture. Int. J. Disaster Risk Reduct 2018, 30, 244–256. [Google Scholar]
- Keke, Z.; Nianxue, L.; Yingbing, L. STGA-CBR: A Case-Based Reasoning Method Based on Spatiotemporal Trajectory Similarity Assessment. IEEE Access 2020, 8, 22378–22385. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J. A Case-Based Reasoning Model for Retrieving Window Replacement Costs through Industry Foundation Class. Appl. Sci. 2019, 9, 4728. [Google Scholar] [CrossRef] [Green Version]
- Gabel, T.; Riedmiller, M. CBR for state value function approximation in reinforcement learning. In International Conference on Case-Based Reasoning; Springer: Berlin/Heidelberg, Germany, 2005; pp. 206–221. [Google Scholar]
- Watson, I.; Marir, F. Case-based reasoning—A review. Knowl. Eng. Rev. 1994, 9, 327–354. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, Z.-P.; Yuan, Y.; Li, H. A FTA-based method for risk decision-making in emergency response. Comput. Oper. Res. 2014, 42, 49–57. [Google Scholar] [CrossRef] [PubMed]
- Duan, W.; He, B. Emergency Response System for Pollution Accidents in Chemical Industrial Parks, China. Int. J. Environ. Res. Public Heal. 2015, 12, 7868–7885. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, L.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Sigaud, O.; Buffet, O. Markov Decision Processes in Artificial Intelligence; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Kolodner, J. Cased-Based Reasoning Morgan Kaufmann; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993. [Google Scholar]
- Leake, D.B. Case-Based Reasoning: Experiences, Lessons, and Future Directions; AAAIPress/MIT Press: Menlo Park, CA, USA, 1996. [Google Scholar]
- Sharma, M.; Holmes, M.; Santamaría, J.; Irani, A.; Isbell, C.; Ram, A. Transfer Learning in Real-Time Strategy Games Using Hybrid CBR/RL. IJCAI 2007, 7, 1041–1046. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, University Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Huang, K.; Nie, W.; Luo, N. A Method of Constructing Marine Oil Spill Scenarios from Flat Text Based on Semantic Analysis. Int. J. Environ. Res. Public Heal. 2020, 17, 2659. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man, Cybern. Part B (Cybernetics) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosenstein, M.T.; Barto, A.G.; Si, J. Supervised Actor-Critic Reinforcement Learning; Wiley-IEEE Press: Hoboken, NJ, USA, 2004; pp. 359–380. [Google Scholar]
- Cai, W.; Zheng, Y.; Shi, Y.; Zhong, H. Threat Level Forecast for Ship’s Oil Spill-Based on BP Neural Network Model. In Proceedings of the 2009 International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 11–13 December 2009; pp. 1–4. [Google Scholar]
- Chen, Y.; Yang, N.; Song, Z. Research on Unconventional Emergency Scenario-Response Multidimensional Scenario Entropy. In Mathematics in Practice and Theory; Chinese Academy of Sciences: Beijing, China, 2015; Volume 45, No.12. [Google Scholar]
- Finney, D.J. Probit Analysis: A Statistical Treatment of the Sigmoid Response Curve; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Golson, S. One-hot state machine design for FPGAs. In Proceedings of the 3rd Annual PLD Design Conference & Exhibit, Santa Clara, CA, USA, 30 March 1993; Volume 1. [Google Scholar]





| Order | Category | Scenario Element | Scenario Element Attributes |
|---|---|---|---|
| 1 | Hazard | Crude oil | Flash point; Condensation point; Density; Glue content; Sulphur content; Nitrogen content; Hydrogen content; Wax content; Asphalt value; Acid value; Carbon residue; Kinematic viscosity; Distillation range |
| Oil slick | Color; Cover area; Thickness | ||
| Sea condition | Window speed; Wave height; Water temperature; Sea visibility | ||
| 2 | Exposure | Oil tanker | Offshore distance; Vessel age; Tonnage; Amount of spilled oil |
| Offshore oil and gas platform | Geographic position; Vertical height; Carrying capacity | ||
| Marine organisms | Creature name; Wildlife habitat; Number of dead creatures; State of fire or explosion | ||
| Fisheries and mariculture | Geographic position; Breeding number; Species | ||
| Subsea tunnel | Geographic position; Buried depth of tunnel; Length of tunnel; Damaged area | ||
| Port infrastructure | Geographic position; Coastline length; Use of the facility |
| Order | Category | Indicator |
|---|---|---|
| 1 | Spilled oil | Toxicity |
| Amount | ||
| Flammable | ||
| 2 | Vessel | Age |
| Tonnage | ||
| 3 | Sea area | Distance to offshoring |
| Self-purge ability | ||
| 4 | Sea conditions | Wind speed |
| Wave height | ||
| Water temperature | ||
| Visibility |
| Order | Category | Human Behavior |
|---|---|---|
| 1 | Cleaning spilled oil | Use of booms |
| Use of dispersants | ||
| Use of mechanical recycling and sorbent materials | ||
| 2 | Rescue | Tow oil vessel (potentially over a wide area) |
| Hang signal lights and establish anchors | ||
| Firefighting and fire extinction | ||
| Stopping ship leaks | ||
| Rescue crew | ||
| Abandon vessel | ||
| Voluntary stranding | ||
| 3 | Protection of sensitive marine resources | Shut down sensitive resources |
| Spontaneous recovery | ||
| Biological recovery | ||
| Construct artificial reefs | ||
| Enhancement of fishery resources |
| Order | Typical Scenario | Scenario Instance |
|---|---|---|
| 1 | Tanker collision scenario | Set spilled oil amount. All other parameters are set as default values. Sea condition parameter values set to “normal”. Scenario instance extracted from the case “ATLANTIC EMPRESS”. |
| 2 | Tanker fire scenario | Set spilled oil amount, where the spilled oil is flammable. All other parameters are set as default values. Sea condition parameter values set to “normal”. Scenario instance extracted from the case “ATLANTIC EMPRESS”. |
| 3 | Oil spill scenario | Set spilled oil amount. Sea condition parameter values set to “normal”. Scenario instance extracted from the case “BRAER”. |
| Set spilled oil amount. Sea condition parameter values set to “dangerous”. Scenario instance extracted from the case “TANIO”. | ||
| 4 | Marine organism death scenario | Assume the spilled oil has been cleaned up. Sea condition parameter values set to “normal”. Scenario instance extracted from the case “BRAER”. |
| Scenario Instance | Scenario Similarity Matching | Scenario-Based Hybrid DRL/CBR |
|---|---|---|
| Tanker collision scenario | “Firefighting and fire extinction” | “Use of booms” “Use of dispersants” “Use of mechanical recycling and sorbent materials” “Firefighting and fire extinction” |
| Tanker fire scenario | “Firefighting and fire extinction” | “Firefighting and fire extinction” |
| Oil spill scenario-BREAR | None | “Use of booms” “Use of dispersants” “Use of mechanical recycling and sorbent materials” |
| Oil spill scenario-TANIO | “Cleaning spilled oil” methods are not recommended | “Stopping ship leaks” |
| Marine organism death scenario | None | “Shut down sensitive resources” |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, K.; Nie, W.; Luo, N. Scenario-Based Marine Oil Spill Emergency Response Using Hybrid Deep Reinforcement Learning and Case-Based Reasoning. Appl. Sci. 2020, 10, 5269. https://doi.org/10.3390/app10155269
Huang K, Nie W, Luo N. Scenario-Based Marine Oil Spill Emergency Response Using Hybrid Deep Reinforcement Learning and Case-Based Reasoning. Applied Sciences. 2020; 10(15):5269. https://doi.org/10.3390/app10155269
Chicago/Turabian StyleHuang, Kui, Wen Nie, and Nianxue Luo. 2020. "Scenario-Based Marine Oil Spill Emergency Response Using Hybrid Deep Reinforcement Learning and Case-Based Reasoning" Applied Sciences 10, no. 15: 5269. https://doi.org/10.3390/app10155269
APA StyleHuang, K., Nie, W., & Luo, N. (2020). Scenario-Based Marine Oil Spill Emergency Response Using Hybrid Deep Reinforcement Learning and Case-Based Reasoning. Applied Sciences, 10(15), 5269. https://doi.org/10.3390/app10155269