Pansharpening by Complementing Compressed Sensing with Spectral Correction


Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
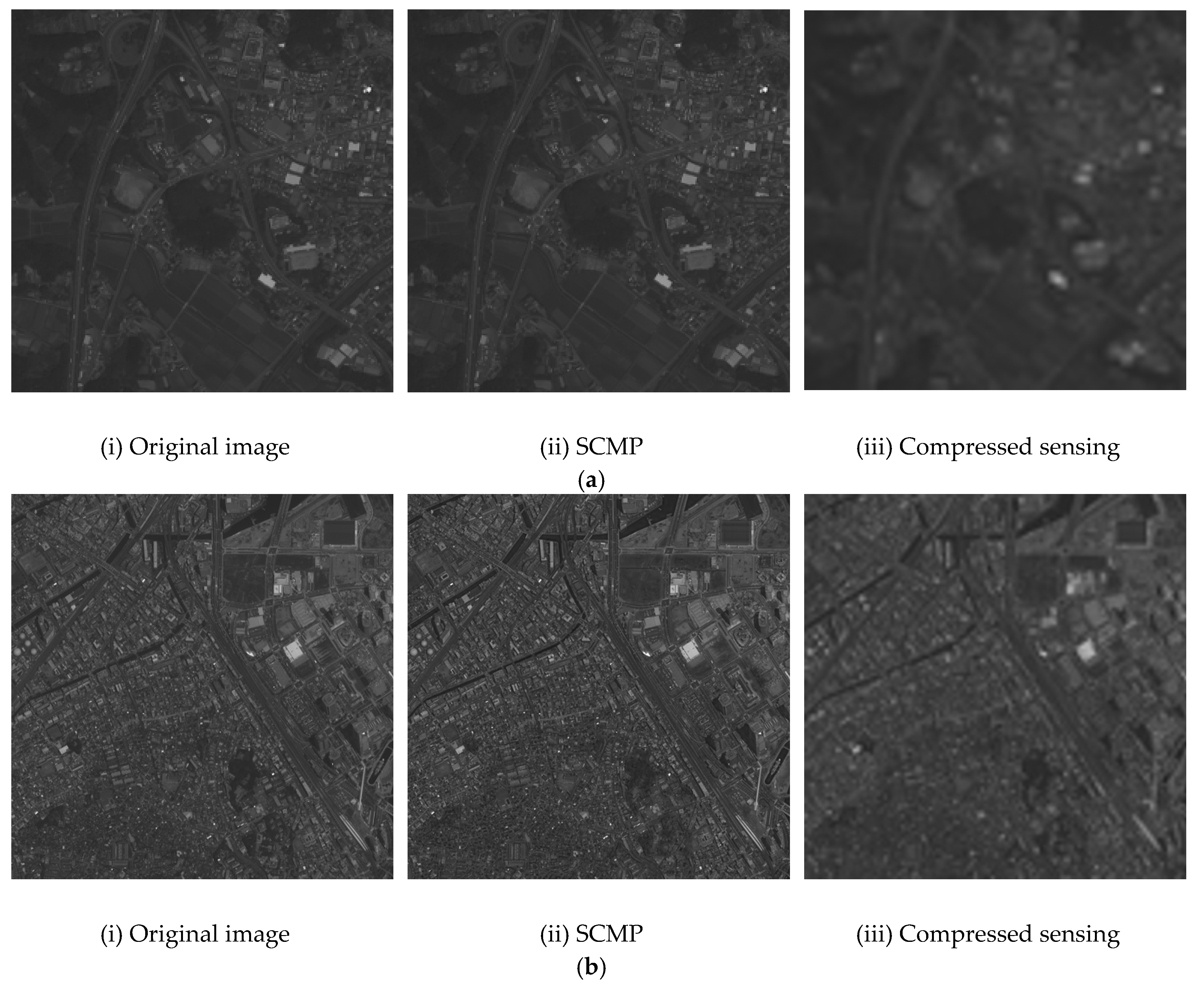
2.1. Image Datasets
2.2. Compressed Sensing
2.3. Proposed Method
2.4. Notation
2.5. Estimation of Coefficients for Intensity Correction
2.6. Dictionary Learning
- (1)
- Obtain and from the training data. Each column of is then normalized.
- (2)
- Set the initial value of the dictionary . Random numbers that follow the Gaussian distribution with mean 0 and variance 1 are normalized for each patch region.
- (3)
- Estimate the sparse representation by solving the optimization problem of Equation (10) by fixing the dictionary .
- (4)
- Estimate the dictionary by solving the optimization problem of Equation (11) by fixing the sparse representation .
- (5)
- Steps (3) and (4) are repeated. (In the experiment, we repeated 40 times.)
- (6)
- The obtained dictionary is normalized for each patch and used as the final trained dictionary .
2.7. Reconstruction Process
- (1)
- The low-resolution RGB images are upsampled via bicubic interpolation to the size of the PAN image. The upsampled low-resolution intensity is calculated using Equation (6) with the upsampled RGB image.
- (2)
- The feature map is obtained from the upsampled low-resolution intensity After applying the four filters shown in Section 2.6 to , the feature map is obtained, where the overlap of adjacent patches are and for horizontal and vertical directions. is then obtained from where the overlap of adjacent patches are and for horizontal and vertical directions.
- (3)
- The sparse representation is calculated using Equation (12).
- (4)
- The high-resolution intensity image is obtained from the sparse representation and the high-resolution dictionary by Equation (13), and it is normalized for each patch. The average value of the th patch, , is calculated with the upsampled low-resolution intensity , and it is added to the patch of the high-resolution intensity using Equation (14).
- (5)
- Using the patches of the obtained high-resolution intensity , the image is reconstructed. The mean value of the overlapped pixels is used as the value of the pixel in the adjacent overlapping patches.
2.8. Tradeoff Process
2.9. Generalized IHS Method
3. Results
3.1. Experimental Setup
3.1.1. Quality Evaluation
3.1.2. Dictionary Learning
3.1.3. Reconstruction Process
3.1.4. Coefficients for Intensity Correction
3.1.5. Tradeoff Parameter
3.2. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Amro, I.; Mateos, J.; Vega, M.; Molina, R.; Katsaggelos, A.K. A survey of classical methods and new trends in pansharpening of multispectral images. EURASIP J. Adv. Signal Process. 2011, 2011, 79. [Google Scholar] [CrossRef] [Green Version]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef] [Green Version]
- Pohl, C.; Van Genderen, J.L. Review article Multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef] [Green Version]
- Tu, T.M.; Su, S.C.; Shyu, H.C.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Zhou, J.; Civco, D.L.; Silander, J.A. A wavelet transform method to merge Landsat TM and SPOT panchromatic data. Int. J. Remote Sens. 1998, 19, 743–757. [Google Scholar] [CrossRef]
- Laben, C.A.; Brower, B.V. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pan-Sharpening. U.S. Patent 6,011,875, 4 January 2000. [Google Scholar]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 17, 674–693. [Google Scholar] [CrossRef] [Green Version]
- Shensa, M.J. The Discrete Wavelet Transform: Wedding the À Trous and Mallat Algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Burt, P.J.; Adelson, E.H. The Laplacian Pyramid as a Compact Image Code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2300–2312. [Google Scholar] [CrossRef]
- Zhang, Q.; Guo, B. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super—Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef] [Green Version]
- Vivone, G.; Addesso, P.; Restaino, R.; Dalla Mura, M.; Chanussot, J. Pansharpening Based on Deconvolution for Multiband Filter Estimation. IEEE Trans. Geosci. Remote Sens. 2019, 57, 540–553. [Google Scholar] [CrossRef]
- Fei, R.; Zhang, J.; Liu, J.; Du, F.; Chang, P.; Hu, J. Convolutional Sparse Representation of Injected Details for Pansharpening. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1595–1599. [Google Scholar] [CrossRef]
- Yin, H. PAN-Guided Cross-Resolution Projection for Local Adaptive Sparse Representation-Based Pansharpening. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4938–4950. [Google Scholar] [CrossRef]
- Wang, X.; Bai, S.; Li, Z.; Song, R.; Tao, J. The PAN and ms image pansharpening algorithm based on adaptive neural network and sparse representation in the NSST domain. IEEE Access 2019, 7, 52508–52521. [Google Scholar] [CrossRef]
- He, L.; Rao, Y.; Li, J.; Chanussot, J.; Plaza, A.; Zhu, J.; Li, B. Pansharpening via Detail Injection Based Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1188–1204. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed Sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. A new pan-sharpening method using a compressed sensing technique. IEEE Trans. Geosci. Remote Sens. 2011, 49, 738–746. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Remote sensing image fusion via sparse representations over learned dictionaries. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4779–4789. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Shen, H.; Zhang, L. A practical compressed sensing-based pan-sharpening method. IEEE Geosci. Remote Sens. Lett. 2012, 9, 629–633. [Google Scholar] [CrossRef]
- Jiang, C.; Zhang, H.; Shen, H.; Zhang, L. Two-step sparse coding for the pan-sharpening of remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1792–1805. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. A sparse image fusion algorithm with application to pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2827–2836. [Google Scholar] [CrossRef]
- Zhu, X.X.; Grohnfeldt, C.; Bamler, R. Exploiting Joint Sparsity for Pansharpening: The J-SparseFI Algorithm. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2664–2681. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Zhang, H.; Li, J.; Zhang, L.; Shen, H. An online coupled dictionary learning approach for remote sensing image fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1284–1294. [Google Scholar] [CrossRef]
- Elad, M. Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing; Springer: New York, NY, USA, 2010; ISBN 978-1441970107. [Google Scholar]
- Vicinanza, M.R.; Restaino, R.; Vivone, G.; Dalla Mura, M.; Chanussot, J. A pansharpening method based on the sparse representation of injected details. IEEE Geosci. Remote Sens. Lett. 2015, 12, 180–184. [Google Scholar] [CrossRef]
- Ghahremani, M.; Ghassemian, H. Remote Sensing Image Fusion Using Ripplet Transform and Compressed Sensing. IEEE Geosci. Remote Sens. Lett. 2015, 12, 502–506. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, M.; Yang, S.; Xing, Y.; Qu, R. Fusion of Panchromatic and Multispectral Images via Coupled Sparse Non-Negative Matrix Factorization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5740–5747. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Motion analysis for image enhancement: Resolution, occlusion, and transparency. J. Vis. Commun. Image Represent. 1993, 4, 324–335. [Google Scholar] [CrossRef] [Green Version]
- Ayas, S.; Gormus, E.T.; Ekinci, M. An efficient pan sharpening via texture based dictionary learning and sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2448–2460. [Google Scholar] [CrossRef]
- Tsukamoto, N.; Sugaya, Y.; Omachi, S. Spectrum Correction Using Modeled Panchromatic Image for Pansharpening. J. Imaging 2020, 6, 20. [Google Scholar] [CrossRef] [Green Version]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Wang, Z.; Bovik, A.C. A Universal Image Quality Index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Wald, L. Quality of high resolution synthesised images: Is there a simple criterion? In Proceedings of the Third Conference Fusion of Earth Data: Merging Point Measurements, Raster Maps and Remotely Sensed Images; Ranchin, T., Wald, L., Eds.; SEE/URISCA: Nice, France, 2000; pp. 99–103. [Google Scholar]
- Kruse, F.A.; Lefkoff, A.B.; Boardman, J.W.; Heidebrecht, K.B.; Shapiro, A.T.; Barloon, P.J.; Goetz, A.F.H. The spectral image processing system (SIPS)—Interactive visualization and analysis of imaging spectrometer data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Proceedings of the 19th International Conference on Neural Information Processing Systems; Schölkopf, B., Platt, J.C., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 801–808. [Google Scholar]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE pan sharpening of very high resolution multispectral images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 228–236. [Google Scholar] [CrossRef]
- Song, Y.; Wu, W.; Liu, Z.; Yang, X.; Liu, K.; Lu, W. An adaptive pansharpening method by using weighted least squares filter. IEEE Geosci. Remote Sens. Lett. 2016, 13, 18–22. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, L.; Huang, S.; Tang, Y.; Wan, W. Pansharpening for Multiband Images with Adaptive Spectral-Intensity Modulation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3196–3208. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Nihonmatsu | Yokohama | |
|---|---|---|---|
| Original image | PAN image | 1024 × 1024 | 1792 × 1792 |
| MS image | 256 × 256 | 448 × 448 | |
| Training image | PAN image (for high-resolution dictionary) | 256 × 256 | 448 × 448 |
| Test image | PAN image | 256 × 256 | 448 × 448 |
| MS image | 64 × 64 | 112 × 112 | |
| Coefficient | Nihonmatsu | Yokohama |
|---|---|---|
| (NIR) | 0.3857 | 0.3789 |
| (Blue) | 0.2199 | 0.2549 |
| (Green) | 0.1980 | 0.1123 |
| (Red) | 0.0486 | 0.1099 |
| Tradeoff Parameter | Nihonmatsu | Yokohama | ||||
|---|---|---|---|---|---|---|
| CC | ERGAS | S | CC | ERGAS | S | |
| 0.0 | 0.899 | 2.415 | 1.186 | 0.944 | 2.393 | 0.405 |
| 0.1 | 0.908 | 2.250 | 1.016 | 0.949 | 2.148 | 0.327 |
| 0.2 | 0.915 | 2.123 | 0.892 | 0.952 | 1.996 | 0.283 |
| 0.3 | 0.920 | 2.041 | 0.815 | 0.953 | 1.961 | 0.274 |
| 0.4 | 0.922 | 2.008 | 0.783 | 0.949 | 2.050 | 0.302 |
| 0.5 | 0.921 | 2.027 | 0.800 | 0.941 | 2.248 | 0.371 |
| 0.6 | 0.916 | 2.097 | 0.873 | 0.926 | 2.529 | 0.491 |
| 0.7 | 0.906 | 2.213 | 1.011 | 0.903 | 2.870 | 0.679 |
| 0.8 | 0.891 | 2.369 | 1.228 | 0.871 | 3.251 | 0.963 |
| 0.9 | 0.871 | 2.557 | 1.550 | 0.828 | 3.660 | 1.385 |
| 1.0 | 0.846 | 2.769 | 2.000 | 0.775 | 4.088 | 2.000 |
| Method | CC | UIQI | ERGAS | |||
|---|---|---|---|---|---|---|
| Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | |
| Ideal | 1.0 | 1.0 | 0.0 | |||
| SR | 0.846 | 0.775 | 0.807 | 0.709 | 2.769 | 4.088 |
| SR+BP | 0.853 | 0.785 | 0.822 | 0.742 | 2.709 | 4.009 |
| Method | CC | UIQI | ERGAS | |||
|---|---|---|---|---|---|---|
| Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | |
| Ideal | 1.0 | 1.0 | 0.0 | |||
| SCMP | 0.899 | 0.944 | 0.779 | 0.915 | 2.415 | 2.393 |
| SR | 0.846 | 0.775 | 0.807 | 0.709 | 2.769 | 4.088 |
| TP | 0.920 | 0.949 | 0.825 | 0.926 | 2.041 | 2.050 |
| Method | CC | UIQI | ERGAS | |||
|---|---|---|---|---|---|---|
| Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | |
| Ideal | 1.0 | 1.0 | 0.0 | |||
| BP | 0.853 | 0.785 | 0.822 | 0.742 | 2.709 | 4.009 |
| TP | 0.920 | 0.949 | 0.825 | 0.926 | 2.041 | 2.050 |
| Method | CC | UIQI | ||
|---|---|---|---|---|
| Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | |
| ideal | 1.0 | 1.0 | ||
| fast IHS [5] | 0.783 | 0.914 | 0.717 | 0.901 |
| GS [7] | 0.508 | 0.860 | 0.373 | 0.838 |
| BDSD [41] | 0.860 | 0.887 | 0.864 | 0.851 |
| WLS [42] | 0.866 | 0.884 | 0.870 | 0.759 |
| MDSIm [43] | 0.791 | 0.865 | 0.736 | 0.823 |
| SCMP [35] | 0.883 | 0.928 | 0.864 | 0.910 |
| ISSR (Dict-natural) [13] | 0.831 | 0.765 | 0.918 | 0.704 |
| ISSR (Dict-self) [13] | 0.831 | 0.759 | 0.917 | 0.701 |
| SR-D | 0.845 | 0.786 | 0.914 | 0.710 |
| SRayas [34] | 0.787 | 0.758 | 0.851 | 0.703 |
| Proposed | 0.906 | 0.937 | 0.903 | 0.918 |
| Method | ERGAS | SAM | ||
|---|---|---|---|---|
| Nihonmatsu | Yokohama | Nihonmatsu | Yokohama | |
| ideal | 0.0 | 0.0 | ||
| fast IHS [5] | 3.471 | 3.716 | 1.898 | 2.367 |
| GS [7] | 5.046 | 3.563 | 2.748 | 1.950 |
| BDSD [41] | 3.026 | 3.361 | 1.925 | 2.326 |
| WLS [42] | 2.815 | 3.816 | 1.699 | 2.123 |
| MDSIm [43] | 3.321 | 3.515 | 1.658 | 2.189 |
| SCMP [35] | 2.673 | 2.697 | 1.753 | 2.176 |
| ISSR (Dict-natural) [13] | 3.118 | 4.419 | 1.749 | 2.324 |
| ISSR (Dict-self) [13] | 3.124 | 4.474 | 1.750 | 2.331 |
| SR-D | 3.007 | 4.226 | 1.897 | 2.649 |
| SRayas [34] | 3.497 | 4.476 | 1.765 | 2.299 |
| Proposed | 2.336 | 2.424 | 1.688 | 2.159 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsukamoto, N.; Sugaya, Y.; Omachi, S. Pansharpening by Complementing Compressed Sensing with Spectral Correction. Appl. Sci. 2020, 10, 5789. https://doi.org/10.3390/app10175789
Tsukamoto N, Sugaya Y, Omachi S. Pansharpening by Complementing Compressed Sensing with Spectral Correction. Applied Sciences. 2020; 10(17):5789. https://doi.org/10.3390/app10175789
Chicago/Turabian StyleTsukamoto, Naoko, Yoshihiro Sugaya, and Shinichiro Omachi. 2020. "Pansharpening by Complementing Compressed Sensing with Spectral Correction" Applied Sciences 10, no. 17: 5789. https://doi.org/10.3390/app10175789
APA StyleTsukamoto, N., Sugaya, Y., & Omachi, S. (2020). Pansharpening by Complementing Compressed Sensing with Spectral Correction. Applied Sciences, 10(17), 5789. https://doi.org/10.3390/app10175789