Automatic Tomato and Peduncle Location System Based on Computer Vision for Use in Robotized Harvesting




Abstract
:1. Introduction
1.1. Literature Review
1.2. Objectives
- Detection of the ripe tomatoes. From the image provided, the system must detect tomatoes that are ripe and segment them from the rest of the image.
- Location of the ripe tomatoes in XY. After recognizing the ripe tomatoes, the system should position them in the XY plane of the image.
- Location of the peduncle in XY. The system should provide the location of the peduncle of the ripe tomatoes in the XY plane of the image.
2. Materials and Methods
2.1. Greenhouse Environment
2.2. Image Acquisition and Processing
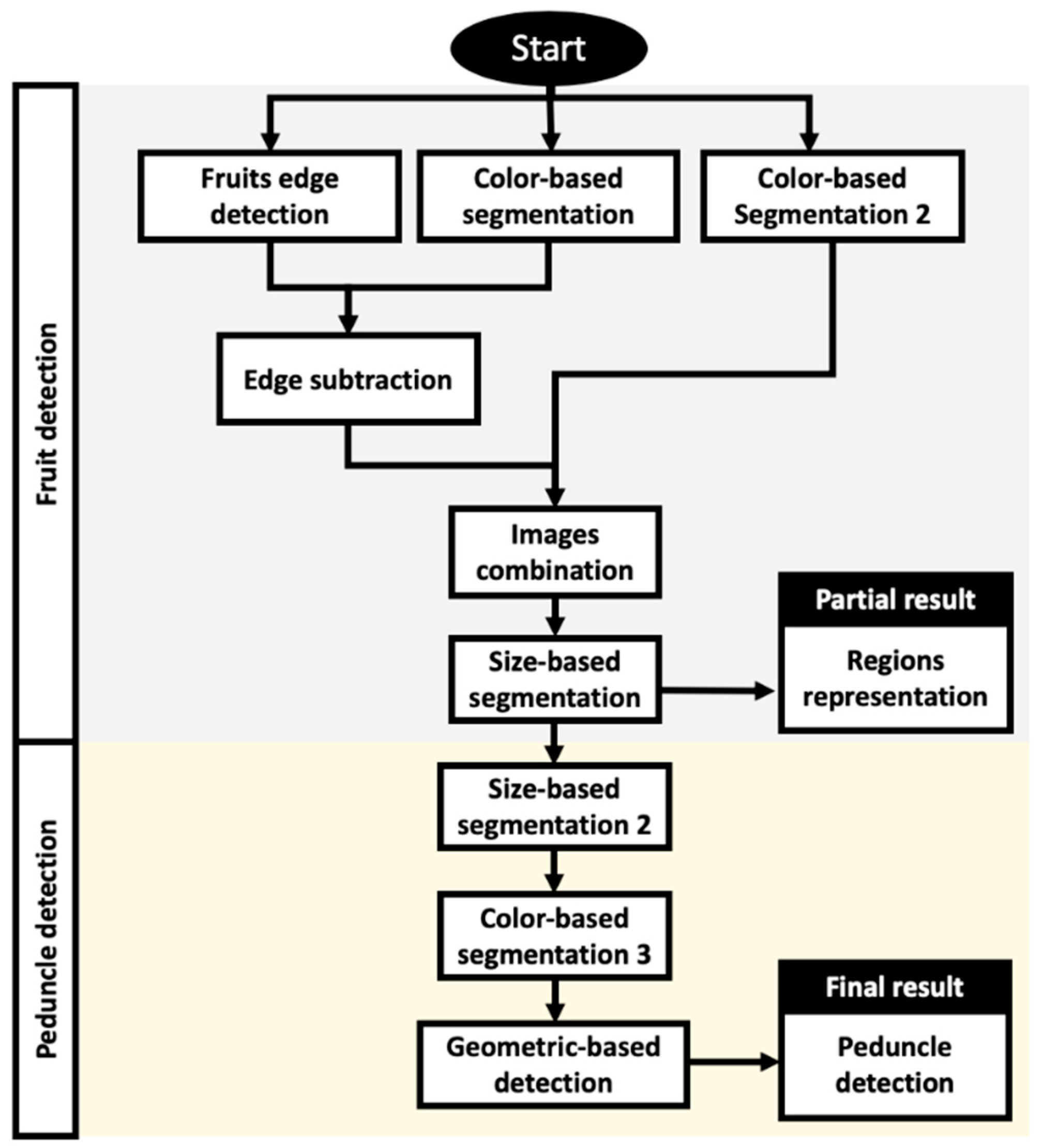
2.3. Tomato Detection Algorithm
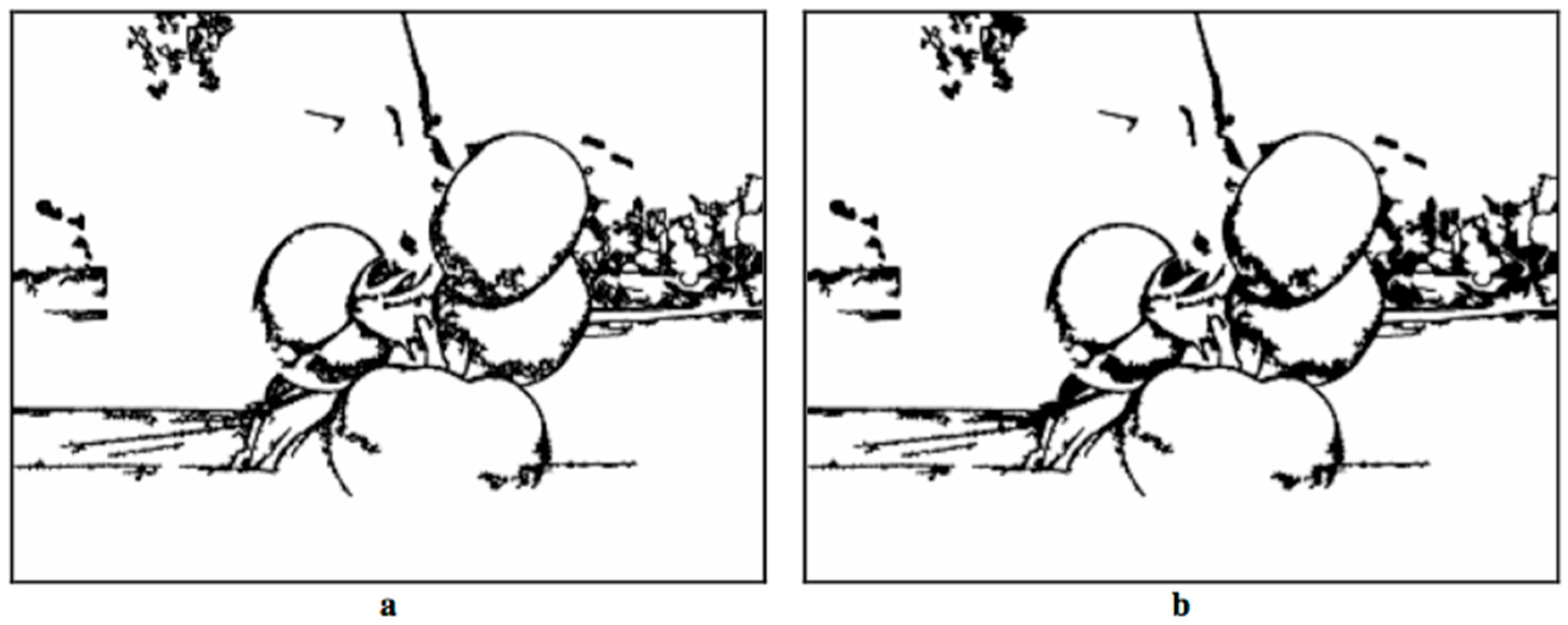
- Tomato-Edge Detection
- Image Binary Inversion
- Segmentation based on color 1 (Figure 9) to obtain a separated region for each mature tomato that appears in the image.


- Color-Based Segmentation 2: Obtaining Separate Regions.
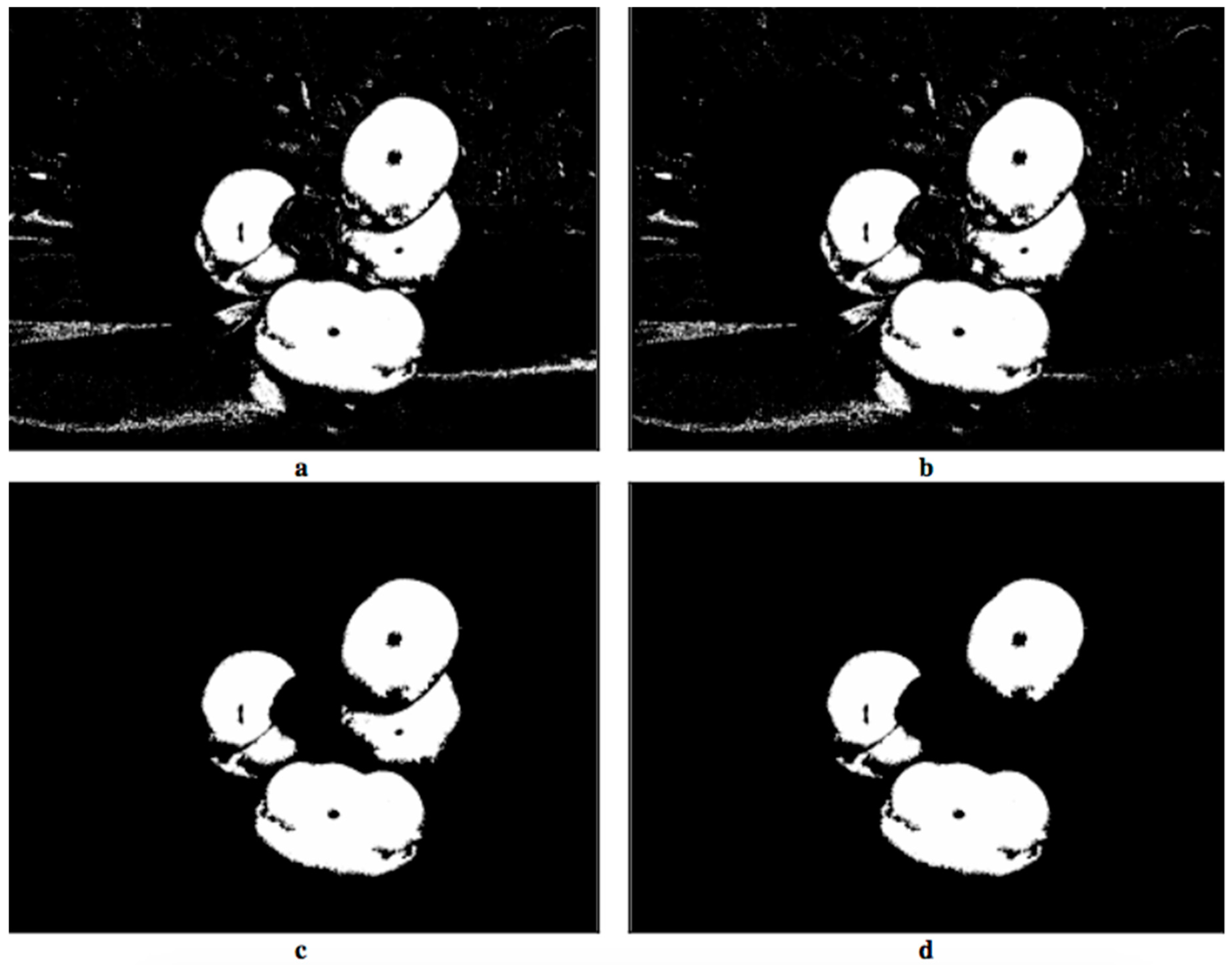
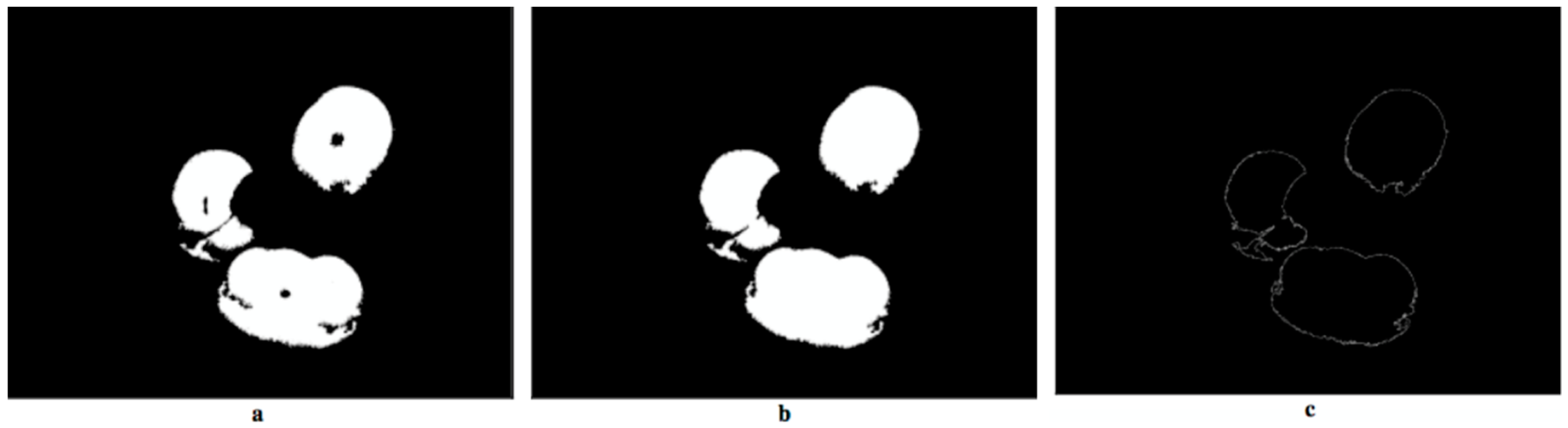
- Image combination (Figure 12): the binary images resulting from edge subtraction (Figure 10b) and color-based Segmentation 2 (Figure 11b) were combined into a single image using the OR (logical addition) operation. Sometimes, after subtracting the edges, a region belonging to the same tomato is divided into two or more smaller regions. The objective of this step is to link them to form a single region that represents the tomato. An added value is that the area of the regions corresponding to ripe tomatoes increases, maintaining the separation between them.

- Segmentation based on size (Figure 13): in the binary image obtained after combining the images, not only do the regions appear that correspond to the ripe tomatoes in the foreground (which are the ones that really interest us), but many others also do, those belonging to tomatoes from more remote plants, and other objects that are in the environment whose color falls within the established segmentation thresholds, etc.

- Representation of the regions (Figure 14): this shows the user which regions obtained after the segmentation based on size represent the possible “collectible” tomatoes. To achieve this we computed the convex area of Figure 13d. Not all of these will be so, since it will depend on whether their peduncles are visible or not from the perspective from which the image was taken.
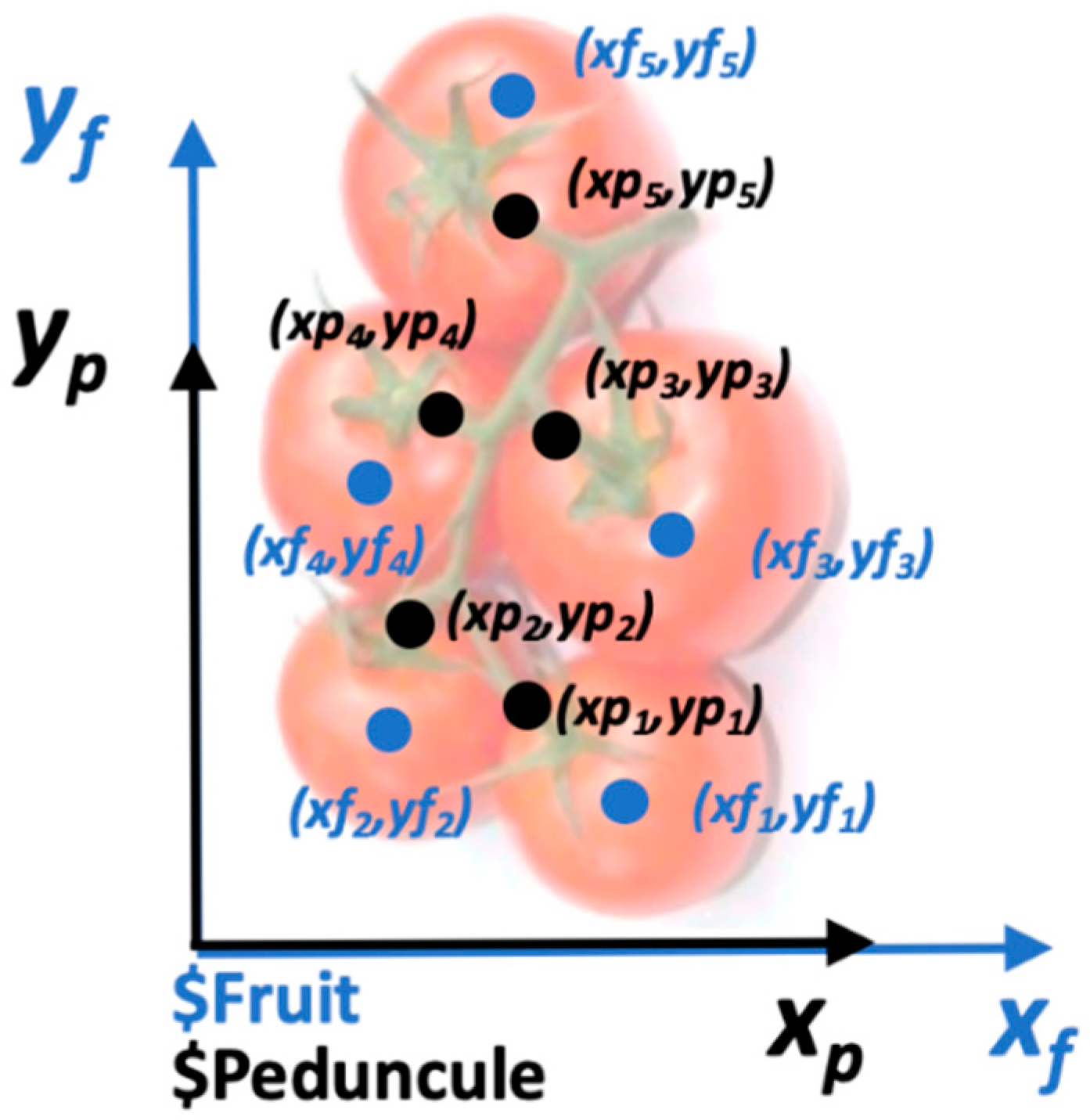
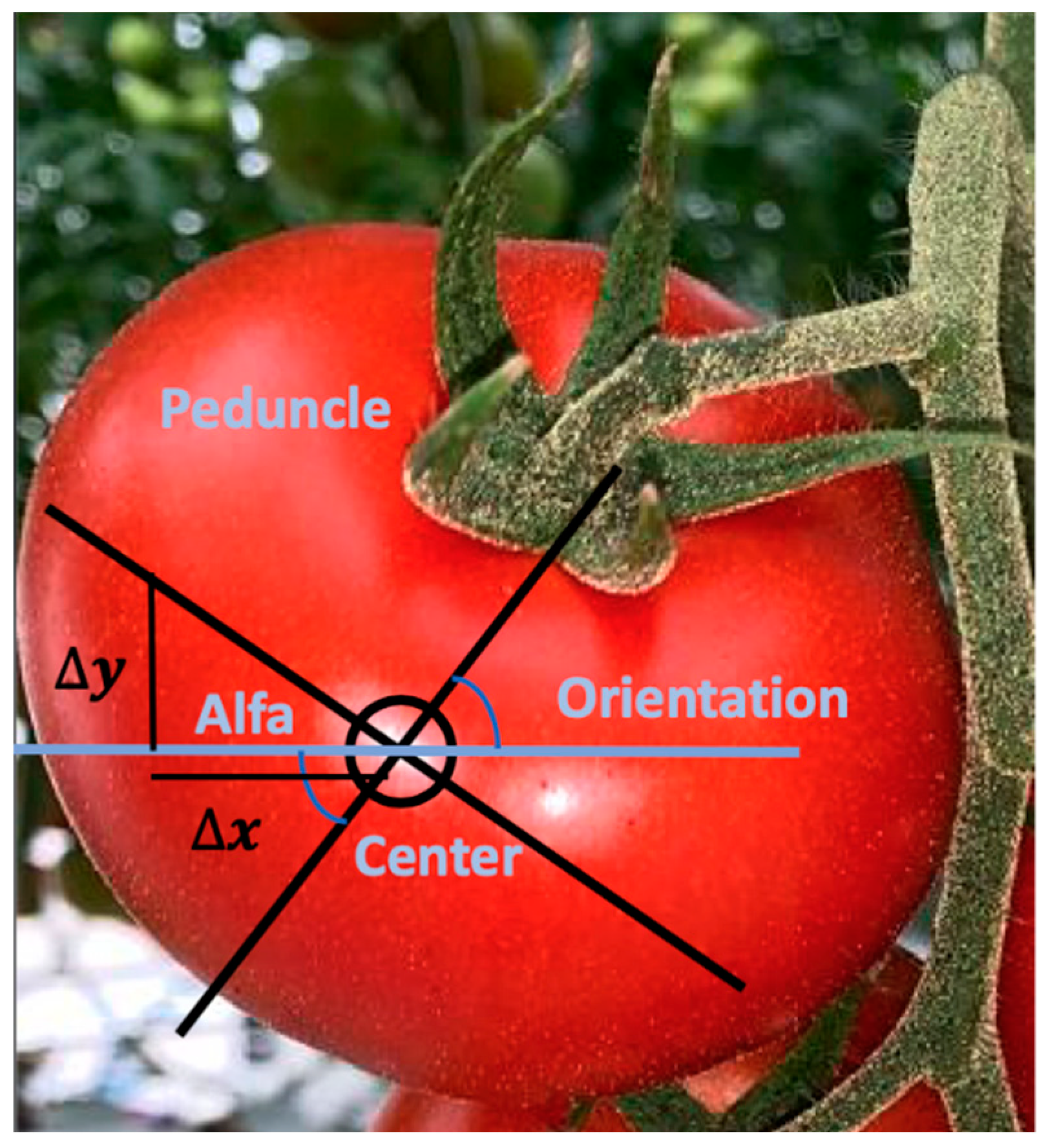
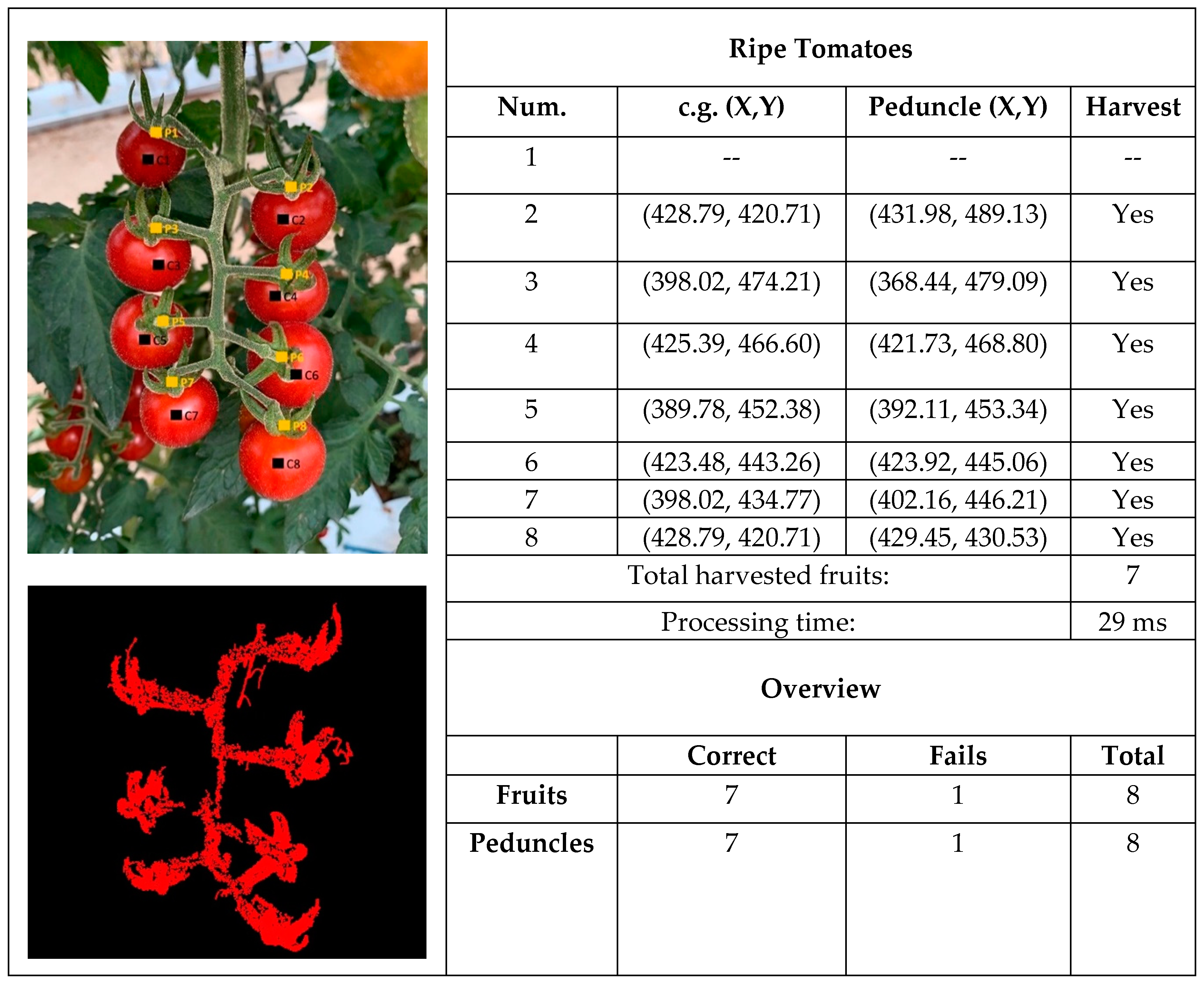
2.4. Location of the Tomatoes and Their Peduncles
- Center X: x coordinate (in pixels) of the region’s c.g.;
- Center Y: y coordinate (in pixels) of the region’s c.g.;
- Height and width in pixels of the circumscribed rectangle;
- Minor axis in pixels of the equivalent Feret ellipse;
- Orientation: ellipse orientation in degrees.
- X center: x coordinate (in pixels) of the center of gravity of the region’s external contour. To distinguish it from Center X of the first set, we will call it Center XGdExt;
- Y center: y coordinate (in pixels) of the center of gravity of the region’s external contour. To distinguish it from the Y Center of the first set, we will call it Y Center YGdExt.
2.5. Plant Detection
2.6. Peduncle Detection
3. Results
- That corresponding to the location of the tomatoes;
- That corresponding to the location of the peduncles;
- That corresponding to the tomato peduncle set.
- Failure 1: An object that should have been detected/located is NOT detected or located;
- Failure 2: An object is detected or located that should NOT have been detected/located;
- Failure 3: An object that should be detected/located by the system, is detected/located but not correctly.
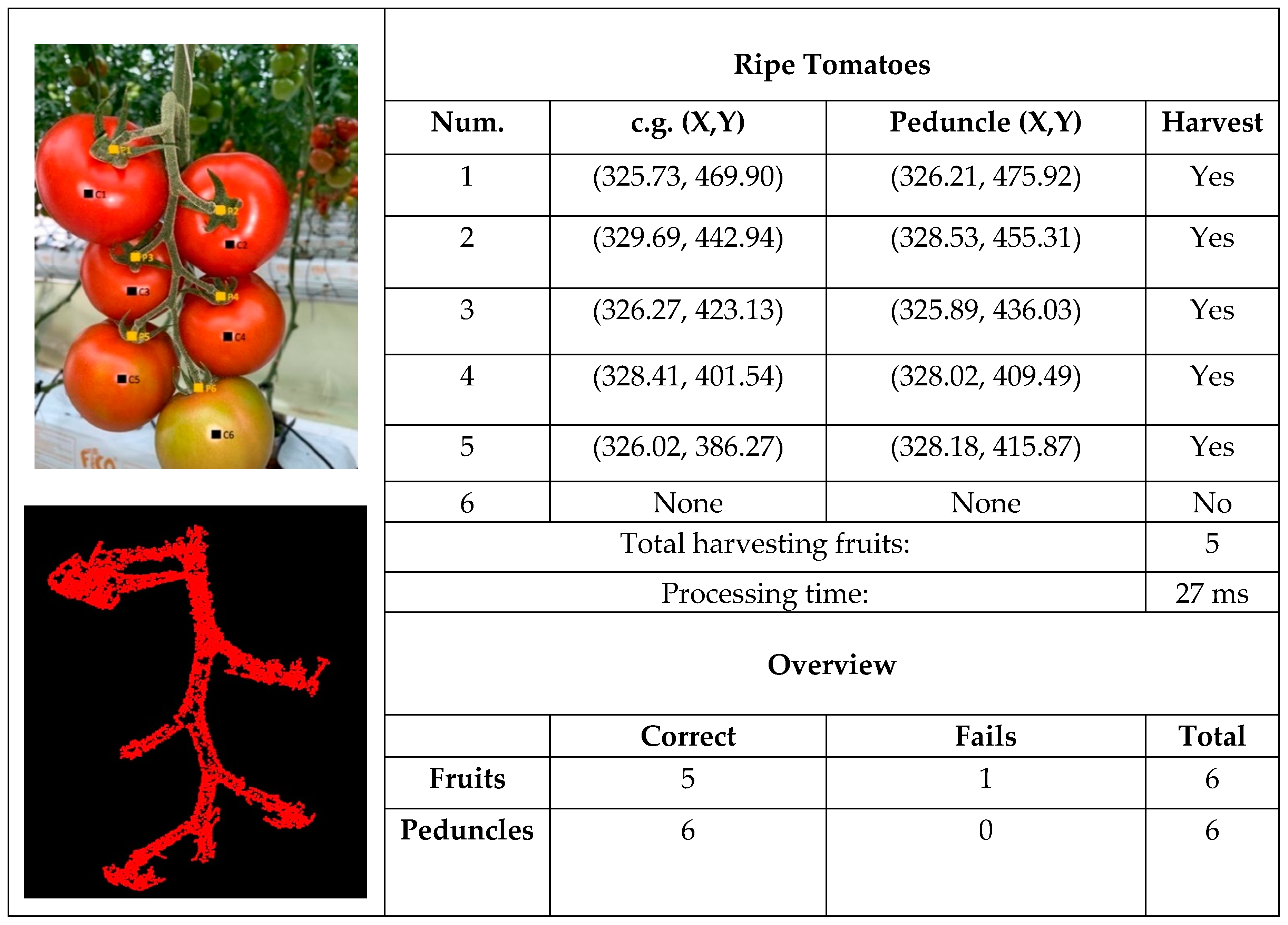
3.1. Beef Tomatoes
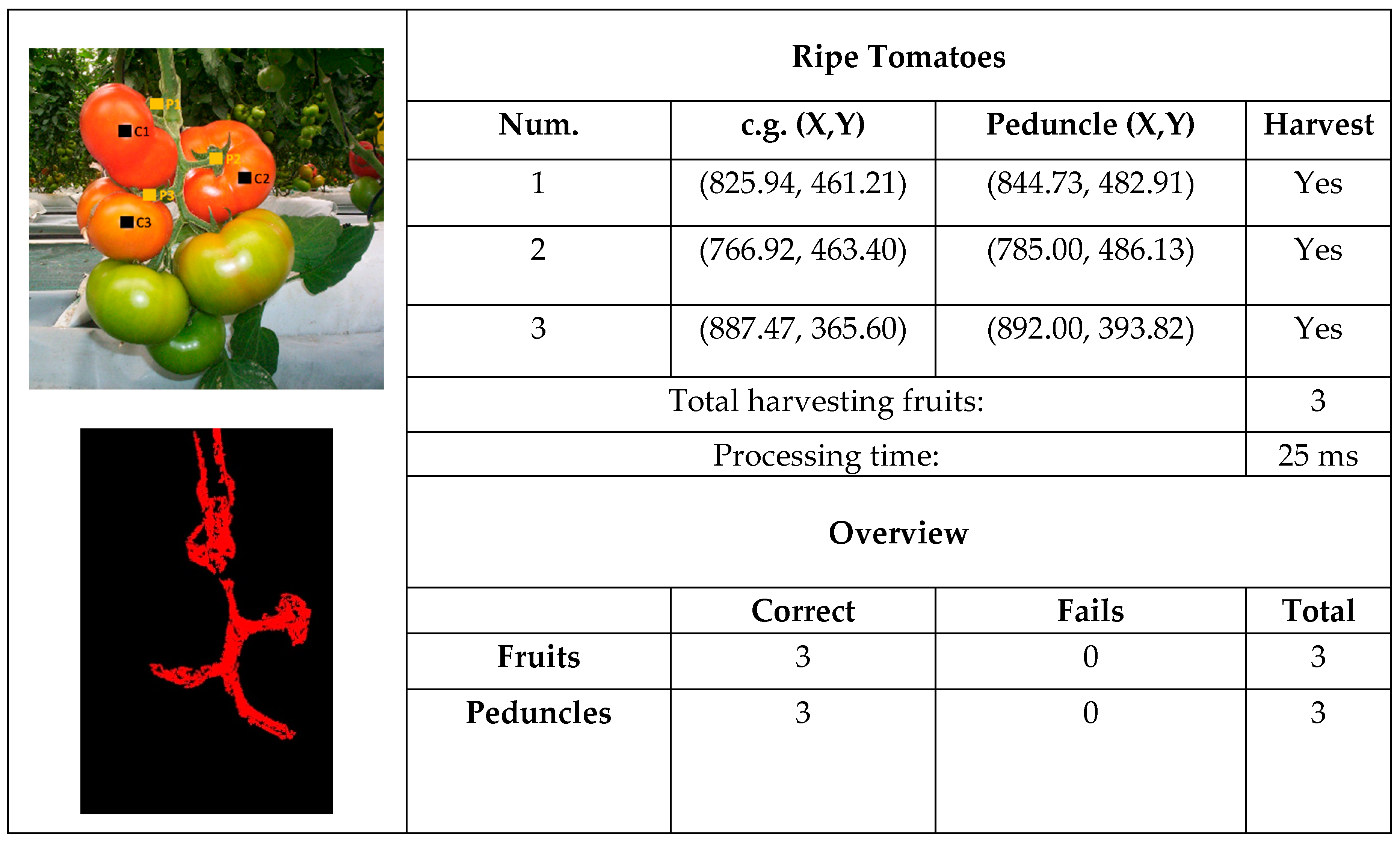
3.2. Cluster Tomatoes
4. Discussion
- Detection of ripe tomatoes: the system detected those ripe tomatoes located in the foreground of the image whose surfaces were not occluded by the plant or the fruit that surround it, or at least, not so much that they could not be collected. Specifically, it detected the “candidate” tomatoes to be collected, representing each of them by a single region (convex area) separated from the rest.
- Location of the ripe tomatoes in XY: once detected, the system located the ripe tomatoes in the XY plane of the image by calculating the position of their centers.
- Location of the tomato peduncle in XY: for each ripe tomato detected, the system indicated whether or not its peduncle was visible from the position where the image was captured. If the peduncle was visible, the system located it by providing its position in the image’s XY plane and informed us that the tomato could be collected. If the peduncle was not visible, the system advises as such, and informs us that the tomato cannot be collected.
5. Conclusions
- The identification and location of the ripe tomatoes and their peduncles;
- The use of flash to acquire the images minimized the illumination variations effects;
- Another very important contribution of this vision system was that it can be used for any tomato-harvesting robot, without having to develop a new vision system for each end-effector prototype, because it locates the needed tomato parts for the different types of harvesting: cutting or embracing/ absorbing.
Author Contributions
Funding
Conflicts of Interest
References
- Food and Agriculture Organization of the United Nations (FAO). Available online: http://www.fao.org/ (accessed on 10 September 2019).
- Valera, D.L.; Belmonte, L.J.; Molina-Aiz, F.D.; López, A.; Camacho, F. The greenhouses of Almería, Spain: Technological analysis and profitability. Acta Hortic. 2017, 1170, 219–226. [Google Scholar] [CrossRef]
- Callejón-Ferre, Á.J.; Montoya-García, M.E.; Pérez-Alonso, J.; Rojas-Sola, J.I. The psychosocial risks of farm workers in south-east Spain. Saf. Sci. 2015, 78, 77–90. [Google Scholar] [CrossRef]
- Sistler, F.E. Robotics and Intelligent Machines in Agriculture. IEEE J. Robot. Autom. 1987, RA-3, 3–6. [Google Scholar] [CrossRef]
- Sarig, Y. Robotics of Fruit Harvesting: A State-of-the-art Review. J. Agric. Eng. Res. 1993, 54, 265–280. [Google Scholar] [CrossRef]
- Ceres, R.; Pons, J.L.; Jimenez, A.R.; Martin, J.M.; Calderon, L. Design and implementation of an aided fruit—Harvesting robot. Ind. Robot 1998, 25, 337–346. [Google Scholar] [CrossRef]
- Pons, J.L.; Ceres, R.; Jiménez, A. Mechanical Design of a Fruit Picking Manipulator: Improvement of Dynamic Behavior. In Proceedings of the IEEE International Conference on Robotics and Automation, Minneapolis, MN, USA, 22–28 April 1996. [Google Scholar]
- Bulanon, D.M.; Kataoka, T.; Okamoto, H.; Hata, S. Development of a real-time machine vision system for the apple harvesting robot. In Proceedings of the SICE Annual Conference, Sapporo, Japan, 4–6 August 2004; Hokkaido Institute of Technology: Sapporo, Japan, 2004. [Google Scholar]
- Gotou, K.; Fujiura, T.; Nishiura, Y.; Ikeda, H.; Dohi, M. 3-D vision system of tomato production robot. In Proceedings of the IEEE/ASME Int. Conference on Advanced Intelligent Mechatronics, Kobe, Japan, 20–24 July 2003; pp. 1210–1215. [Google Scholar]
- Bac, C.W.; van Henten, E.J.; Hemming, J.; Edan, Y. Harvesting robots for high-value crops: State-of-the-art review and challenges ahead. J. Field Robot 2014, 31, 888–911. [Google Scholar] [CrossRef]
- Bachche, S. Deliberation on Design Strategies of Automatic Harvesting Systems: A Survey. Robotics 2015, 4, 194–222. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Gong, L.; Huang, Y.; Liu, C. A review of key techniques of vision-based control for harvesting robot. Comput. Electron. Agric. 2016, 127, 311–323. [Google Scholar] [CrossRef]
- Pereira, C.; Morais, R.; Reis, M. Recent Advances in Image Processing Techniques for Automated Harvesting Purposes: A Review. In Proceedings of the Intelligent Systems conference, London, UK, 7–8 September 2017. [Google Scholar]
- Mavridou, E.; Vrochidou, E.; Papakostas, G.A.; Pachidis, T.; Kaburlasos, V.G. Machine Vision Systems in Precision Agriculture for Crop Farming. J. Imaging 2019, 5, 89. [Google Scholar] [CrossRef] [Green Version]
- Schillaci, G.; Pennisi, A.; Franco, F.; Longo, D. Detecting Tomato Crops in Greenhouses Using a Vision-Based Method. In Proceedings of the III Int. Conference SHWFA (Safety Health and Welfare in Agriculture and in Agro-food Systems), Ragusa, Italy, 3–6 September 2012; pp. 252–258. [Google Scholar]
- Ji, C.; Zhang, J.; Yuan, T.; Li, W. Research on Key Technology of Truss Tomato Harvesting Robot in Greenhouse. Appl. Mech. Mater. 2014, 442, 480–486. [Google Scholar] [CrossRef]
- Feng, Q.; Wang, X.; Wang, G.; Li, Z. Design and Test of Tomatoes Harvesting Robot. In Proceedings of the IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 949–952. [Google Scholar]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining AdaBoost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Robust Tomato Recognition for Robotic Harvesting Using Feature Images Fusion. Sensors 2016, 16, 173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Ling, Y.; Zhang, H.; Zheng, S. The Design and Realization of Cherry Tomato Harvesting Robot Based on IOT. iJOE 2016, 12, 23–26. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Liu, C.; Huang, Y. Dual-arm Robot Design and Testing for Harvesting Tomato in Greenhouse. IFAC-PapersOnLine 2016, 49, 161–165. [Google Scholar] [CrossRef]
- Taqi, F.; Al-Langawi, F.; Abdulraheem, H.; El-Abd, M. A Cherry-Tomato Harvesting Robot. In Proceedings of the 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 463–468. [Google Scholar]
- Wang, L.; Zhao, B.; Fan, J.; Hu, X.; Wei, S.; Li, Y.; Zhou, Q.; Wei, C. Development of a tomato harvesting robot used in greenhouse. Int. J. Agric. Biol. Eng. 2017, 10, 140–149. [Google Scholar]
- Zhang, L.; Jia, F.; Gui, G.; Hao, X.; Gao, W.; Wang, M. Deep Learning Based Improved Classification System for Designing Tomato Harvesting Robot. IEEE Access 2018, 6, 67940–67950. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.C.; Zou, W.; Fan, P.F.; Zhang, C.F.; Wang, X. Design and test of robotic harvesting system for cherry tomato. Int. J. Agric. Biol. Eng. 2018, 11, 96–100. [Google Scholar] [CrossRef]
- Malik, M.H.; Zhang, T.; Li, H.; Zhang, M.; Shabbir, S.; Saeed, A. Mature Tomato Fruit Detection Algorithm Based on improved HSV and Watershed Algorithm. IFAC PapersOnLine 2018, 51, 431–436. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, L.; Zhou, B.; Liu, C.; Huang, Y.; Wang, T. Dual-arm cooperation and implementing for robotic harvesting tomato using binocular vision. Robot. Auton. Syst. 2019, 114, 134–143. [Google Scholar]
- Lin, G.; Tang, Y.; Zou, X.; Cheng, J.; Xiong, J. Fruit detection in natural environment using partial shape matching and probabilistic Hough transform. Precis. Agric. 2019. [Google Scholar] [CrossRef]
- Yuan, T.; Lin, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.; Li, L.; Zhang, C.; Zhang, W. Robust Cherry Tomatoes Detection Algorithm in Greenhouse Scene Based on SSD. Agriculture 2020, 10, 160. [Google Scholar] [CrossRef]
- Yoshida, T.; Fukao, T.; Hasegawa, T. A Tomato Recognition Method for Harvesting with Robots using Point Clouds. In Proceedings of the 2019 IEEE/SICE International Symposium on System Integration (SII), Paris, France, 14–16 January 2019; pp. 456–461. [Google Scholar] [CrossRef]
- González, R.; Woods, R. Digital Image Processing, 4th ed.; Pearson: New York, NY, USA, 2018. [Google Scholar]
- Rodríguez, F.; Moreno, J.C.; Sánchez, J.A.; Berenguel, M. Grasping in agriculture: State-of-the-art and main characteristics. In Grasping in Robotics; Springer: London, UK, 2013; pp. 385–409. [Google Scholar]
- Kondo, N.; Yata, K.; Iida, M.; Shiigi, T.; Monta, M.; Kurita, M.; Omori, H. Development of an end-effector for a tomato cluster harvesting robot. Eng. Agric. Environ. Food 2010, 3, 20–24. [Google Scholar] [CrossRef]
- Ling, P.P.; Ehsani, R.; Ting, K.C.; Chi, Y.T.; Ramalingam, N.; Klingman, M.H.; Draper, C. Sensing and end-effector for a robotic tomato harvester. In Proceedings of the 2004 ASAE Annual Meeting, American Society of Agricultural and Biological Engineers, Golden, CO, USA, 4–6 November 2004; p. 1. [Google Scholar]
- Monta, M.; Kondo, N.; Ting, K.C. End-effectors for tomato harvesting robot. In Artificial Intelligence for Biology and Agriculture; Springer: Dordrecht, The Netherlands, 1998; pp. 1–25. [Google Scholar]
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Success and Failure Rates | Total Elements That Should Have Been Correctly Located by the System * | |
|---|---|---|
| (a) Tomatoes | Success | 90% |
| Failure 1 | 10% | |
| Failure 2 | 0% | |
| Failure 3 | 0% | |
| (b) Peduncles | Success | 91.3% |
| Failure 1 | 8.7% | |
| Failure 2 | 0% | |
| Failure 3 | 0% | |
| (c) Tomatoes peduncles | Success | 80.8% |
| Failure 1 | 19.2% | |
| Failure 2 | 0% | |
| Failure 3 | 0% | |
| Success and Error Rates | Of the Total Elements That Should Have Been Correctly Located by the System * | |
|---|---|---|
| (a) Tomatoes | Success | 79.7% |
| Failure 1 | 6.8% | |
| Failure 2 | 0% | |
| Failure 3 | 11.9% | |
| (b) Peduncles | Success | 69.5% |
| Failure 1 | 27.1% | |
| Failure 2 | 0% | |
| Failure 3 | 3.4% | |
| (c) Tomatoes peduncles | Success | 63.2% |
| Failure 1 | 29.4% | |
| Failure 2 | 0% | |
| Failure 3 | 7.4% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benavides, M.; Cantón-Garbín, M.; Sánchez-Molina, J.A.; Rodríguez, F. Automatic Tomato and Peduncle Location System Based on Computer Vision for Use in Robotized Harvesting. Appl. Sci. 2020, 10, 5887. https://doi.org/10.3390/app10175887
Benavides M, Cantón-Garbín M, Sánchez-Molina JA, Rodríguez F. Automatic Tomato and Peduncle Location System Based on Computer Vision for Use in Robotized Harvesting. Applied Sciences. 2020; 10(17):5887. https://doi.org/10.3390/app10175887
Chicago/Turabian StyleBenavides, M., M. Cantón-Garbín, J. A. Sánchez-Molina, and F. Rodríguez. 2020. "Automatic Tomato and Peduncle Location System Based on Computer Vision for Use in Robotized Harvesting" Applied Sciences 10, no. 17: 5887. https://doi.org/10.3390/app10175887
APA StyleBenavides, M., Cantón-Garbín, M., Sánchez-Molina, J. A., & Rodríguez, F. (2020). Automatic Tomato and Peduncle Location System Based on Computer Vision for Use in Robotized Harvesting. Applied Sciences, 10(17), 5887. https://doi.org/10.3390/app10175887