Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model

 , , and
, , and
Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Score Sememes from Synonyms
3.2. Attention-Based Sememe Prediction
4. Experiment and Results
4.1. Dataset
4.2. Experimental Settings
4.3. Results
5. Discussion
5.1. The Two Ways of Combining Synonyms and Word Embedding Vectors
5.2. Impact of the Value of K
5.3. Calculation Performance Analysis
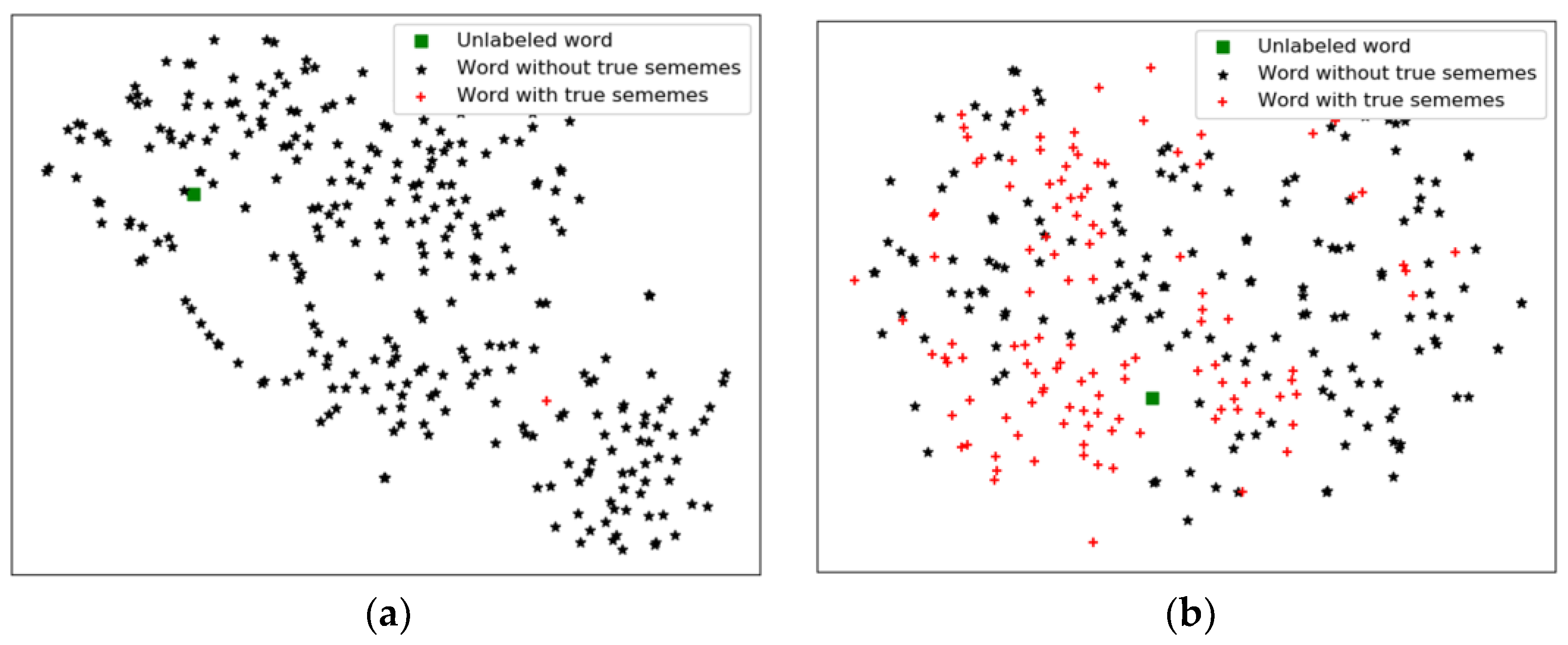
5.4. Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aouicha, M.B.; Taieb, M.A.H.; Marai, H.I. WordNet and Wiktionary-Based Approach for Word Sense Disambiguation. In Transactions on Computational Collective Intelligence XXIX; Springer: Cham, Switzerland, 2018; pp. 123–143. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E. Learning bilingual word embeddings with (almost) no bilingual data. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 451–462. [Google Scholar]
- Chen, Y.; Luo, Z. A Word Representation Method Based on Hownet. Beijing Da Xue Xue Bao 2019, 55, 22–28. [Google Scholar]
- Peng-Hsuan, L. CA-EHN: Commonsense Word Analogy from E-HowNet. arXiv 2019, arXiv:1908.07218. [Google Scholar]
- Iqbal, F.; Fung, B.C.M.; Debbabi, M.; Batool, R.; Marrington, A. Wordnet-based criminal networks mining for cybercrime investigation. IEEE Access 2019, 7, 22740–22755. [Google Scholar] [CrossRef]
- Bloomfield, L. A set of postulates for the science of language. Language 1926, 2, 153–164. [Google Scholar] [CrossRef] [Green Version]
- Goddard, C.; Wierzbicka, A. Semantic and Lexical Universals: Theory and Empirical Findings; John Benjamins Publishing: Amsterdam, The Netherlands, 1994; Volume 25. [Google Scholar]
- Dong, Z.; Dong, Q. Hownet and the Computation of Meaning; World Scientific: Singapore, 2006; pp. 1–303. [Google Scholar]
- Liu, Q.; Li, S. Word similarity computing based on Hownet. Comput. Linguist. Chin. Lang. Process. 2002, 7, 59–76. [Google Scholar]
- Duan, X.; Zhao, J.; Xu, B. Word sense disambiguation through sememe labeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 1594–1599. [Google Scholar]
- Huang, M.; Ye, B.; Wang, Y.; Chen, H.; Cheng, J.; Zhu, X. New word detection for sentiment analysis. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 531–541. [Google Scholar]
- Yang, L.; Kong, C.; Chen, Y.; Liu, Y.; Fan, Q.; Yang, E. Incorporating Sememes into Chinese Definition Modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 1669–1677. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Xu, J.; Ren, X. Evaluating semantic rationality of a sentence: A sememe-word-matching neural network based on hownet. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; pp. 787–800. [Google Scholar]
- Xie, R.; Yuan, X.; Liu, Z.; Sun, M. Lexical sememe prediction via word embeddings and matrix factorization. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4200–4206. [Google Scholar]
- Jin, H.; Zhu, H.; Liu, Z.; Xie, R.; Sun, M.; Lin, F.; Lin, L. Incorporating Chinese Characters of Words for Lexical Sememe Prediction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Navigli, R.; Ponzetto, S.P. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. Artif. Intell. 2012, 193, 217–250. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1249. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a Web of open data. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2007; Volume 4825 LNCS, pp. 722–735. [Google Scholar]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef] [Green Version]
- Rizkallah, S.; Atiya, A.F.; Shaheen, S. A Polarity Capturing Sphere for Word to Vector Representation. Appl. Sci. 2020, 10, 4386. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Li, W.; Ren, X.; Dai, D.; Wu, Y.; Wang, H.; Sun, X. Sememe prediction: Learning semantic knowledge from unstructured textual wiki descriptions. arXiv 2018, arXiv:1808.05437. [Google Scholar]
- Qi, F.; Lin, Y.; Sun, M.; Zhu, H.; Xie, R.; Liu, Z. Cross-lingual Lexical Sememe Prediction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 358–368. [Google Scholar]
- Bai, M.; Lv, P.; Long, X. Lexical Sememe Prediction with RNN and Modern Chinese Dictionary. In Proceedings of the 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Huangshan, China, 28–30 July 2018; pp. 825–830. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018-Conference Track, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, X.; Xu, L.; Liu, Z.; Sun, M.; Luan, H. Joint learning of character and word embeddings. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Words | Similarity in Embedding Space |
|---|---|---|
| Top similar words in embedding vector | Skating (滑冰) | 0.617 |
| winter Olympics (冬奥会) | 0.573 | |
| Speedskating (速滑) | 0. 536 | |
| Ice Arena (冰场) | 0. 471 | |
| Gymnastics (体操) | 0.466 | |
| Synonyms | complain of an injustice (叫屈) | 0.136 |
| appeal for justice (申冤) | 0.122 | |
| cry out for justice (喊冤) | 0.036 | |
| exonerate (昭雪) | 0.057 | |
| True sememes | Corrections (改正), result (结果), error (误) | |
| Model | MAP |
|---|---|
| SPWE [14] | 0.5610 |
| SPSE [14] | 0.3916 |
| SPASE [14] | 0.3538 |
| SPWE+SPSE [14] | 0.5690 |
| SPWE+SPASE [14] | 0.5684 |
| SPCSE [15] | 0.3105 |
| SPWCF [15] | 0.4529 |
| SPWCF+SPCSE [15] | 0.4849 |
| CSP [15] | 0.6408 |
| LD-seq2seq [23] | 0.3765 |
| SPS | 0.5818 |
| SPSW | 0.6578 |
| ASPSW | 0.6774 |
| α | MAP |
|---|---|
| 0.1 | 0.5820 |
| 0.2 | 0.6023 |
| 0.3 | 0.6222 |
| 0.4 | 0.6416 |
| 0.5 | 0.6578 |
| 0.6 | 0.6718 |
| 0.7 | 0.6787 |
| 0.8 | 0.6764 |
| 0.9 | 0.6674 |
| ASPSW | 0.6774 |
| Nearest Word Number | SPWE | ASPSW |
|---|---|---|
| 10 | 0.5478 | 0.6724 |
| 20 | 0.5566 | 0.6762 |
| 30 | 0.5587 | 0.6773 |
| 40 | 0.5597 | 0.6778 |
| 50 | 0.5602 | 0.6778 |
| 60 | 0.5605 | 0.6776 |
| 70 | 0.5606 | 0.6775 |
| 80 | 0.5608 | 0.6777 |
| 90 | 0.5609 | 0.6777 |
| 100 | 0.5610 | 0.6774 |
| Method | Training Costs (s) | Predicting Costs(s) | Total (s) |
|---|---|---|---|
| SPWE | NA | 2129 | 2129 |
| SPSE | 6510 | 40 | 6550 |
| SPWE+SPSE | 6510 | 2195 | 8705 |
| SPCSE | 41,191 | 2031 | 43,222 |
| SPWCF | NA | 334 | 334 |
| SPWCF+SPCSE | 41,191 | 2417 | 43,608 |
| CSP | 47,701 | 4656 | 52,357 |
| SPS | NA | 22 | 22 |
| SPSW | NA | 2169 | 2169 |
| ASPSW | NA | 2639 | 2639 |
| Words | Top 5 Sememes with SPWE | Top 5 Sememes with ASPSW | True Sememes |
|---|---|---|---|
| Saber (军刀) | tools, Cutting, Breaking, Army, Weapons (用具, 切削, 破开, 军, 武器) | army, weapons, tools, cutting, piercing (军, 武器, 用具, 切削, 扎) | Army, Weapons, Piercing (军, 武器, 扎) |
| Kindergarten (幼儿园) | place, education, teaching, learning, people (场所, 教育, 教, 学习, 人) | place, people, children, care, education, people (场所, 人, 少儿, 照料, 教育) | people, place, children, care (人, 场所, 少儿, 照料) |
| special column (专栏) | Chinese, books, publishing, news, time (语文, 书刊, 出版, 新闻, 时间) | book, special, Chinese, publishing, news (书刊, 特别, 语文, 出版, 新闻) | Parts, Books, special (部件, 书刊, 特别) |
| appease (息怒) | person, be kind, answer, sit, emperor (人, 善待, 答, 坐蹲, 皇) | emotion, angry, stop, person, be kind (情感, 生气, 制止, 人, 善待) | emotion, angry, stop (情感, 生气, 制止) |
| pull, social connections (门路) | rich, become, method, person, intimate (富, 成为, 方法, 人, 亲疏) | method, person, intimate, success, road (方法, 人, 亲疏, 成功, 道路) | person, method, intimate (人, 方法, 亲疏) |
| old woman (妪) | crying, poultry, shouting, diligent, surname (哭泣, 禽, 喊, 勤, 姓) | person, elderly, female, crying, poultry (人, 老年, 女, 哭泣, 禽) | person, elderly, female (人, 女, 老年) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, X.; Li, B.; Yao, H.; Liang, Q.; Li, S.; Gong, J.; Li, X. Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model. Appl. Sci. 2020, 10, 5996. https://doi.org/10.3390/app10175996
Kang X, Li B, Yao H, Liang Q, Li S, Gong J, Li X. Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model. Applied Sciences. 2020; 10(17):5996. https://doi.org/10.3390/app10175996
Chicago/Turabian StyleKang, Xiaojun, Bing Li, Hong Yao, Qingzhong Liang, Shengwen Li, Junfang Gong, and Xinchuan Li. 2020. "Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model" Applied Sciences 10, no. 17: 5996. https://doi.org/10.3390/app10175996
APA StyleKang, X., Li, B., Yao, H., Liang, Q., Li, S., Gong, J., & Li, X. (2020). Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model. Applied Sciences, 10(17), 5996. https://doi.org/10.3390/app10175996