3.1. Data Collection and Datasets
The data were obtained from 36 pigs (Yorkshire, Landrace, and Duroc), each weighing
and kept inside four pigpens (with dimensions of
and temperature of 23 °C) at pig farms located in Chungnam, Korea. One study [
13] details the data collection and organization of the targeted respiratory diseases, including mycoplasma hyopneumoniae (MH), porcine reproductive and respiratory syndrome (PRRS), and postweaning multisystemic wasting syndrome (PMWS). When labeling the data, and in situations where the data included irrelevant sound caused by pigs’ footprint or aggressiveness and attacks among themselves, the video recorded was analyzed along with the sound to ensure that the label accurately matched the class. The sound region was detected using the algorithm proposed by Kim and Hanh [
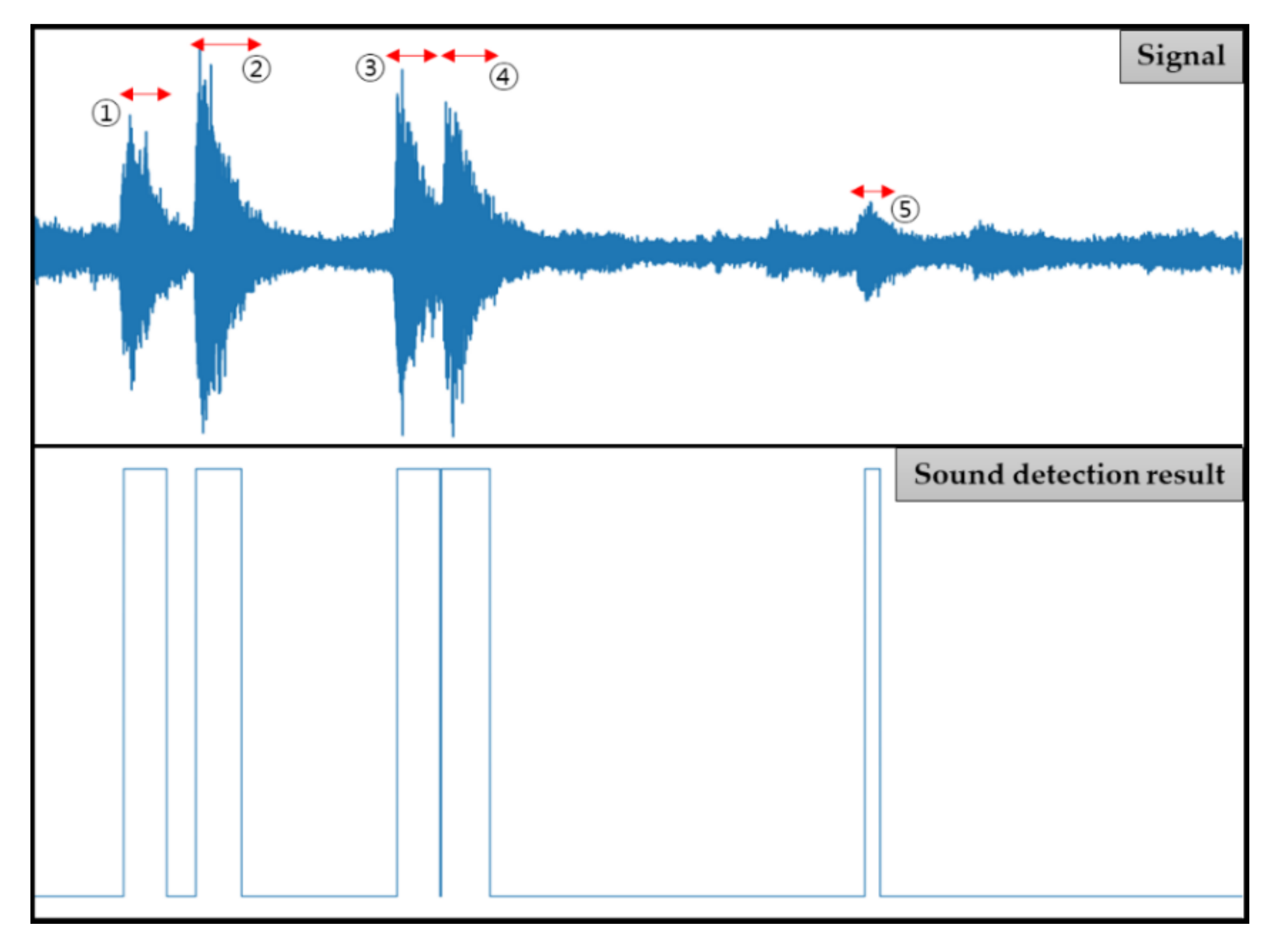
18] through the VAD system previously mentioned. The detected sound data was 0.127 to 2.627 s long, and the sample rate was 44,100 Hz.
To check the detection performance of pig abnormalities in noisy situations, white Gaussian noise (SNR: 20, 15, 10, 5, and 0 dB) and environmental noise (radio operation, door opening, weak footsteps, and strong footsteps) were synthesized with pig sounds. The radio sound refers to the music played inside the pigsty to suppress stress in pigs and maintain their psychological state at a stable level. The strong footsteps are sounds made by several pigs running around excitedly in the pigsty, and the weak footsteps are those made by a few pigs walking or running around under normal circumstances. Lastly, the sound of the door opening is the one that occurs when the manager enters or leaves the pigpen.
Table 2 lists certain basic information related to environmental noise, and
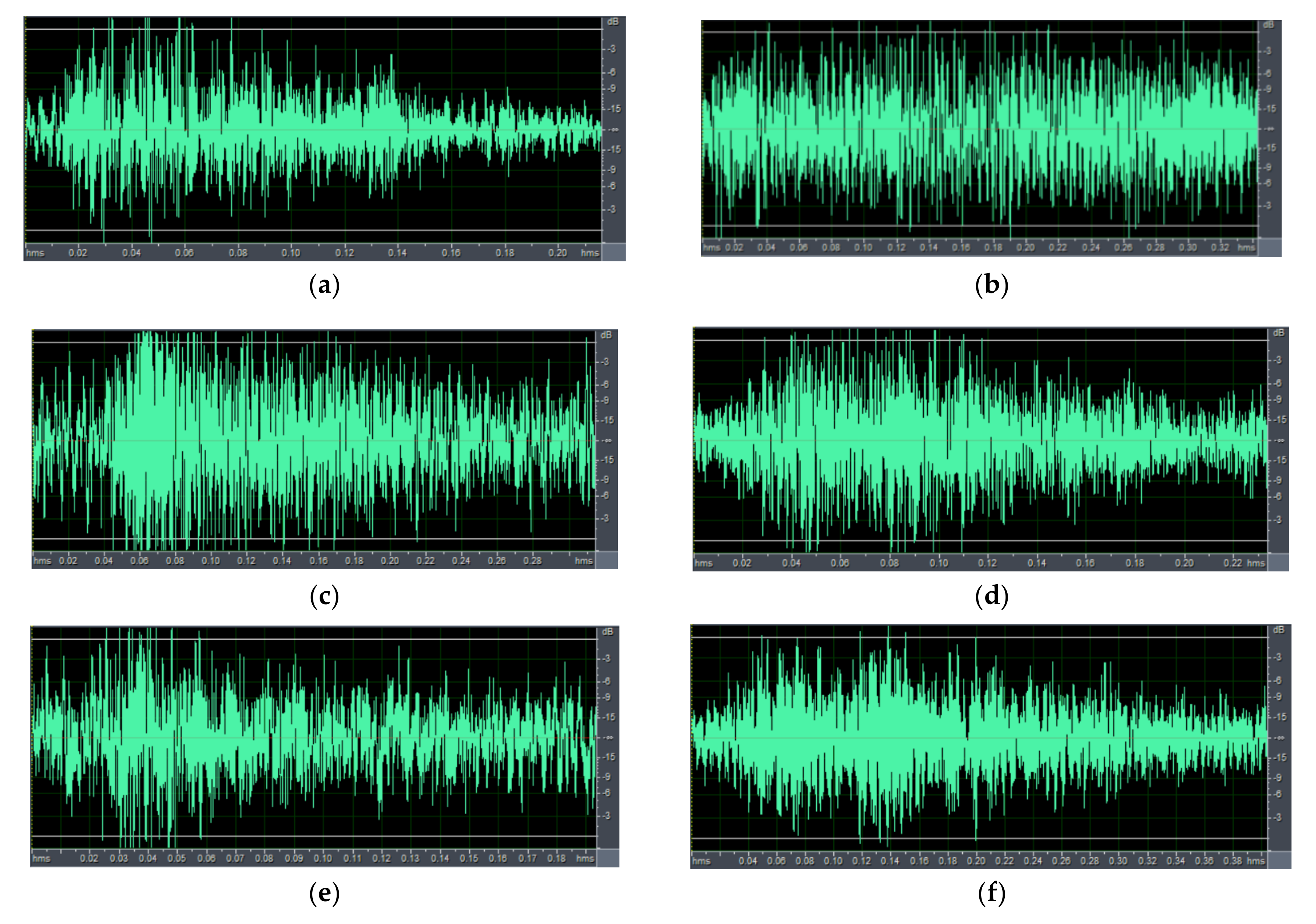
Figure 5 displays examples of signals for various sounds that can be produced by a pig.
3.3. Pig Anomaly Classification Results
The data used for sound-based pig anomaly detection included 100 samples of cough, 110 of grunt, 70 of MH, 150 of PMWS, 140 of PRRS, and 140 of Scream, adding up to 710 samples of data. The dataset was divided in the ratio of 8:2, with 8 (568) as the training set and 2 (142) as the testing set. Furthermore, to confirm whether abnormal situations could be detected robustly in various noisy situations, five steps of white Gaussian noise and four environmental noise sounds were used ( by synthesizing them with the original test data.
In the first experiment, MnasNet was trained only with the original data for training that did not contain noise. As mentioned in the Introduction, the CNN-based deep learning structure is known to be robust to noise, but it is still necessary to secure more robust anomaly detection performance. Consequently, in the second experiment, the original data for training and the data obtained by synthesizing SNR 0 with the corresponding data were used in the MnasNet model training. Subsequently, an experiment was conducted to confirm the effectiveness of the filter clustering technique proposed in this study for the corresponding MnasNet structure. Then, another experiment, in which the DM option was applied to MnasNet models before training them, was conducted to be used for performance comparison. For MnasNet, Keras 2.2.4 [
44] and TensorFlow 1.12.0 [
45] were used, and an Adam Optimizer with decay rates β-1 = 0.9 and β-2 = 0.999, a learning rate of 0.001, and a batch size of 142 were used. The first experiment was trained for 80 epochs, whereas the second one for 100 epochs, and default settings were used as hyper-parameters for the training. After filter clustering was applied to MnasNet, additional training was performed on the pruned MnasNet model for fine-tuning. The evaluation index used in the experimental results is the F1-score, which is calculated as follows [
46]:
where true positive (TP) represents the data accurately classified as true, false positive (FP) represents the inaccurate identification of data as true, and false negative (FN) represents the data inaccurately identified as false. Precision indicates the ratio of how much of the data predicted as a specific class actually belongs to it, and recall indicates the ratio of accurately detecting a specific class.
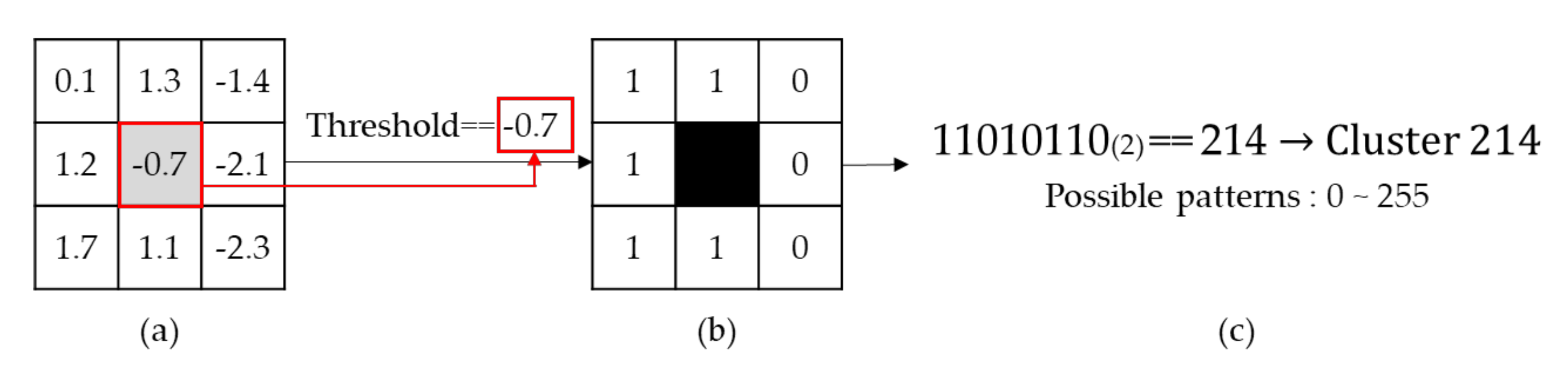
Table 3 presents the experimental results of identifying abnormalities in pigs after training with only clean data (not containing any synthesized noise). The table illustrates the results of three experiments with MnasNet using different DM values and three experiments related to filter clustering. The DM values in the first three experiments represent the rate at which the filters are maintained. DM 1.0 represents the training performed without pruning any filters of MnasNet, which we will refer to as the basic structure of MnasNet for the remainder of the paper, and DM set to 0.75 and 0.5 are the ones where MnasNet filters are removed at rates of 25% and 50%, respectively, before the training. However, the remaining three experiments are the result of applying the filter clustering technique to the trained model of the basic structure of MnasNet. In the order of listing, the first experiment uses the model resulting from applying the initial filter clustering algorithm [
29], the second one uses the result of applying the 8-bit filter clustering technique to only the convolutional layer comprising
filters of the MnasNet, and the last one uses the model resulting from applying the 8-bit filter clustering technique to all layers of MnasNet to identify abnormalities in pig sounds.
The experimental results indicated that when DM was set to 0.75 or 0.5, the model’s identification performance could not be maintained because the results showed a significant drop. In contrast, the three experiments using the filter clustering technique showed that the identification performance was well maintained despite a decrease in the number of filters in the neural network. This demonstrated that the MnasNet model’s identification performance was not affected by the removal of filters that were not relevant for the identification, which was different from removing filters randomly from MnasNet using the DM. However, for SNRs 15, 10, 5, and 0, with strong white Gaussian noise and door opening noise (environmental noise), we noticed that the identification performance was generally low for all algorithms.
Unlike the previous experiments, the experimental results listed in
Table 4 are from the training performed using a dataset containing data obtained by synthesizing white Gaussian noise SNR 0 and clean data. As shown in
Table 4, compared to the previous experimental results, the F1-score has considerably increased with values ranging from 0.107 to 0.277, and the pig’s abnormality is stably identified not only in white Gaussian noise conditions but also in environments containing environmental noise. In particular, the average F1-score result of the 8-bit filter clustering method proposed in this study is 0.947, the highest identification result, which is 0.025 higher than the result obtained using the basic structure of MnasNet (DM 1.0). In addition, as presented in
Table 5, the number of parameters of the neural network is 646,624 and the execution time for detecting a pig’s abnormality from sound converted to spectrogram images on the TX-2 board is 0.253 s/image. While this model has a size that is 76.3% smaller than the basic structure of MnasNet, its execution time is 0.220 s faster, which proves that the proposed method produces the most optimized model. Thus, this model can be executed in real time, and as shown in
Table 4, provides the best identification results.
Table 6 displays a confusion matrix of the results after applying the 8-bit filter clustering method, shown in
Table 4, to all layers of MnasNet. The results confirmed that it effectively detected abnormalities related to pigs’ respiratory diseases and screams resulting from attacks between pigs.
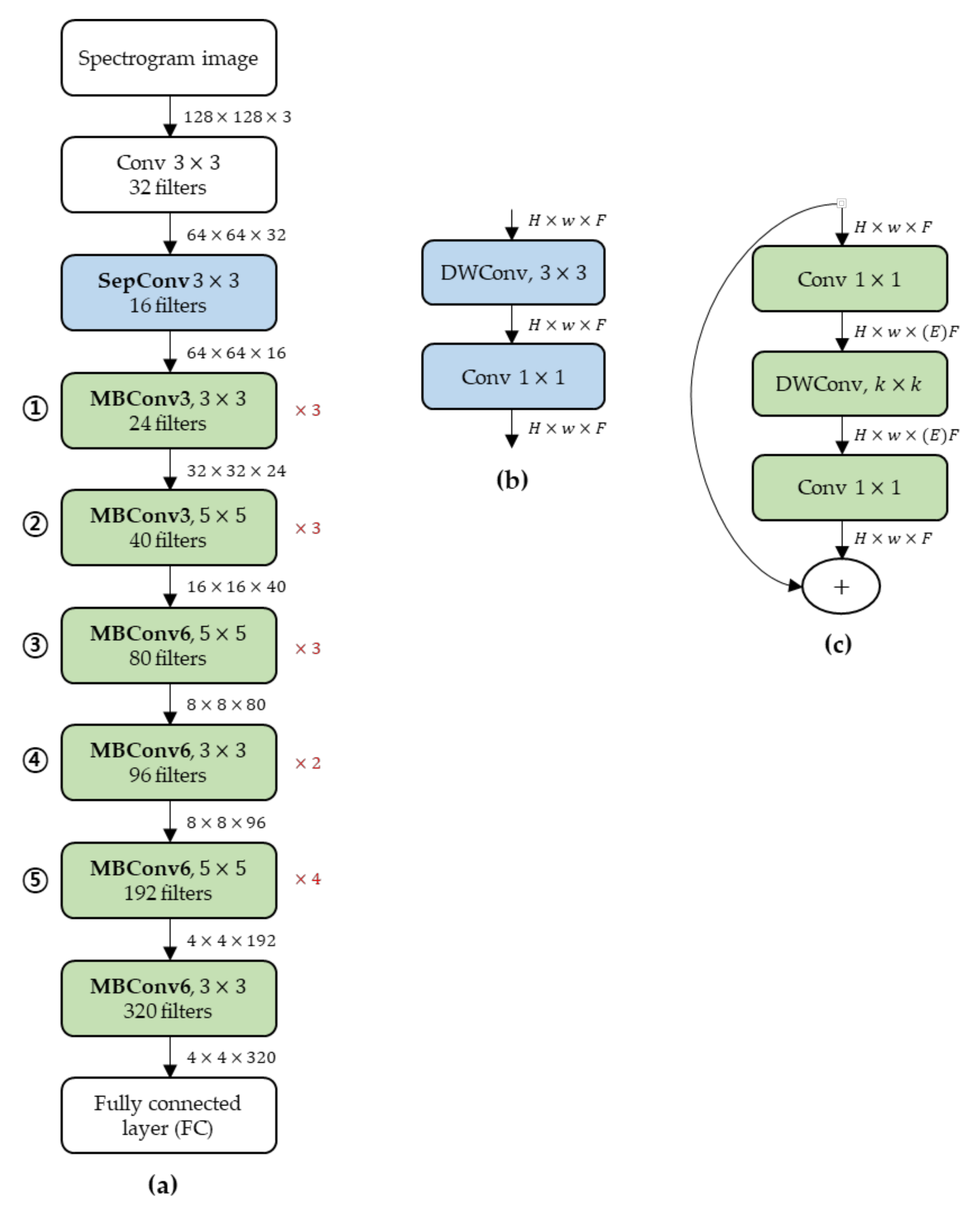
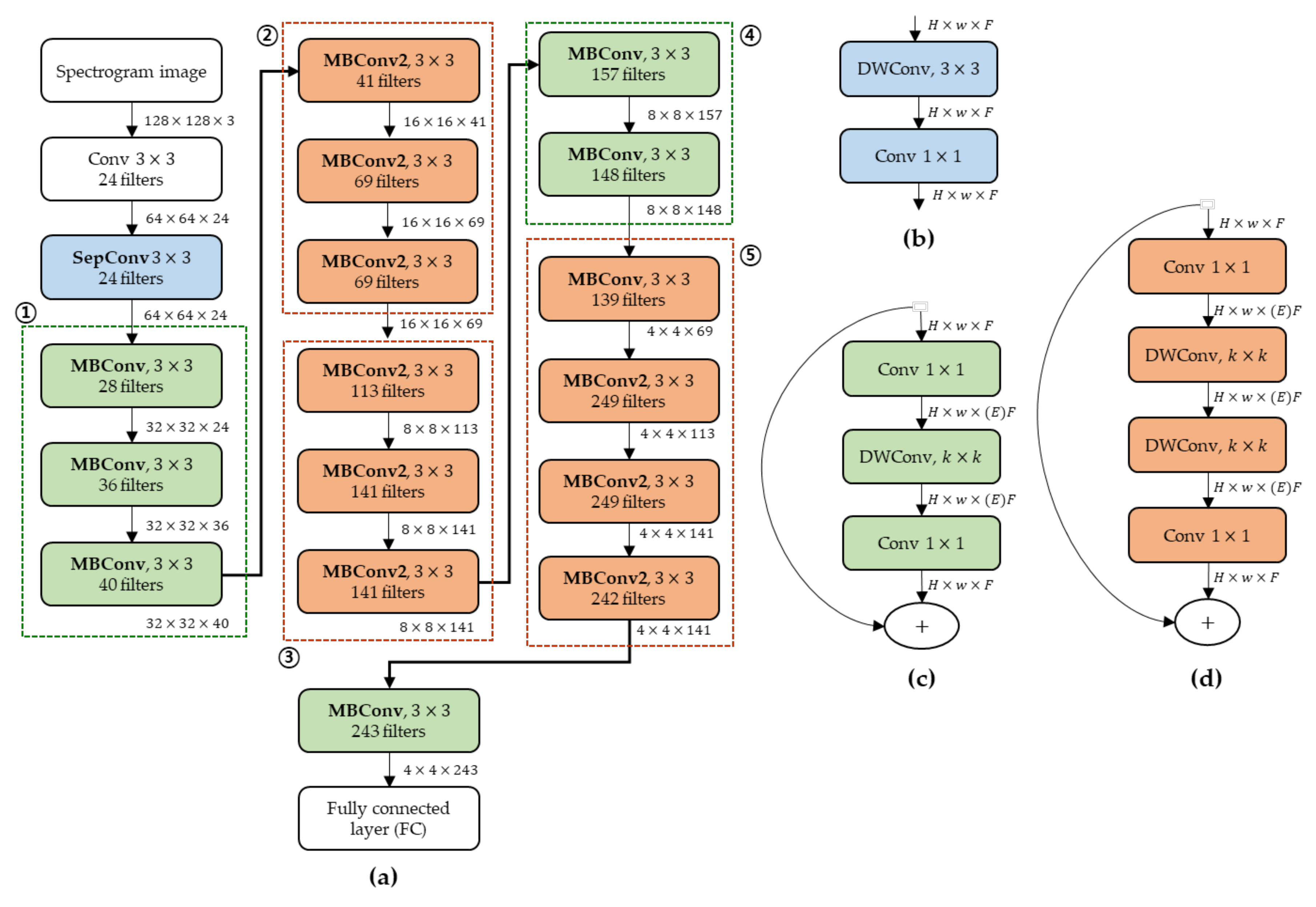
Figure 7 illustrates the compressed MnasNet structure after pruning the filters that are irrelevant to the identification performance using the 8-bit filter clustering method. As previously described in
Section 2.2.2, to apply the 8-bit filter clustering method to all layers of MnasNet, the MBConv layers composed of
filters were changed to comprise two hierarchical
filters. Therefore, the interior of the existing MBConv structure was changed to a structure with two DWConvs, named MBConv2, as shown in
Figure 7d. In addition, in MBConv in the MnasNet model, layers having the same number of filters were repeated; hence, we represented them as one and added symbols
on the right side of the layers (see
Figure 3a). However, when the 8-bit filter clustering algorithm is applied to MnasNet, the number of filters belonging to each layer of the repeated MBConv changes. Therefore, the MBConv, which had the same number of filters that was repeated 3 times in the basic MnasNet structure, was drawn only once and marked with the symbol
on its right side (see ① in
Figure 3a). The same MBConv had to be expressed by dividing it into 3 MBConvs with different numbers of filters after applying our proposed method (see ① in
Figure 7a).
Table 7 and
Table 8 summarize a comparison of results between other studies and our proposed method. However, because the previous studies conducted experiments without considering the noise generated in pigpens, the results using only clean data in the test dataset were used to ensure a fair and accurate comparison. For cough detection, the following three performance indicators were used: cough by disease detection rate (CDR), false-positive rate (FPR), and false-negative rate (FNR). The description of the performance index is described in detail by Chung et al. [
13].
Table 7 presents a comparison of the results of detecting cough caused by disease using our proposed method and that used by other studies.
Table 8 presents a comparison of the results of identifying respiratory diseases in pigs using our proposed method and that used by Chung et al. [
13].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}