A Deep Neural Network Based Glottal Flow Model for Predicting Fluid-Structure Interactions during Voice Production



Abstract
:1. Introduction
2. Materials and Methods
2.1. Formulation of the Reduced-Order Model
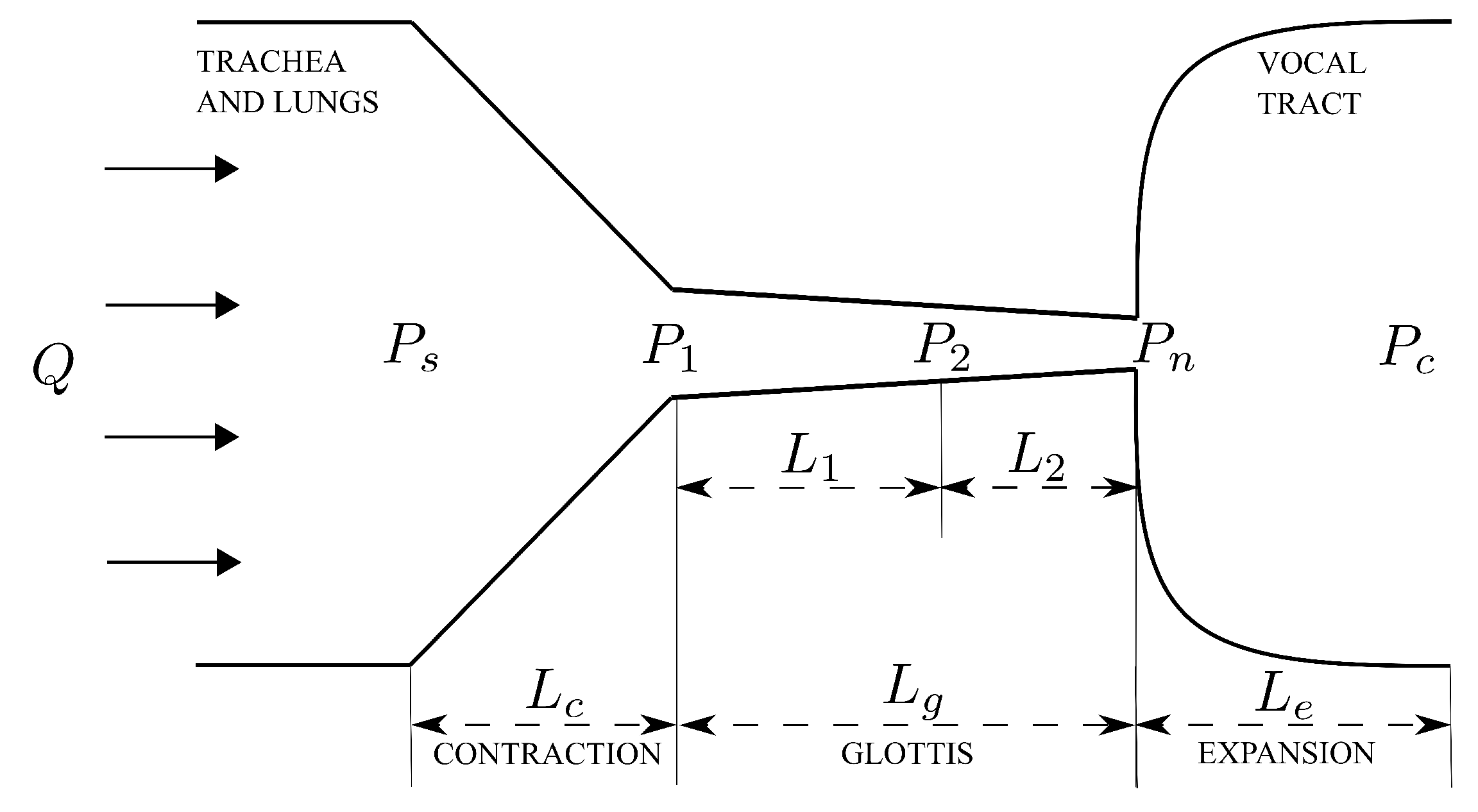
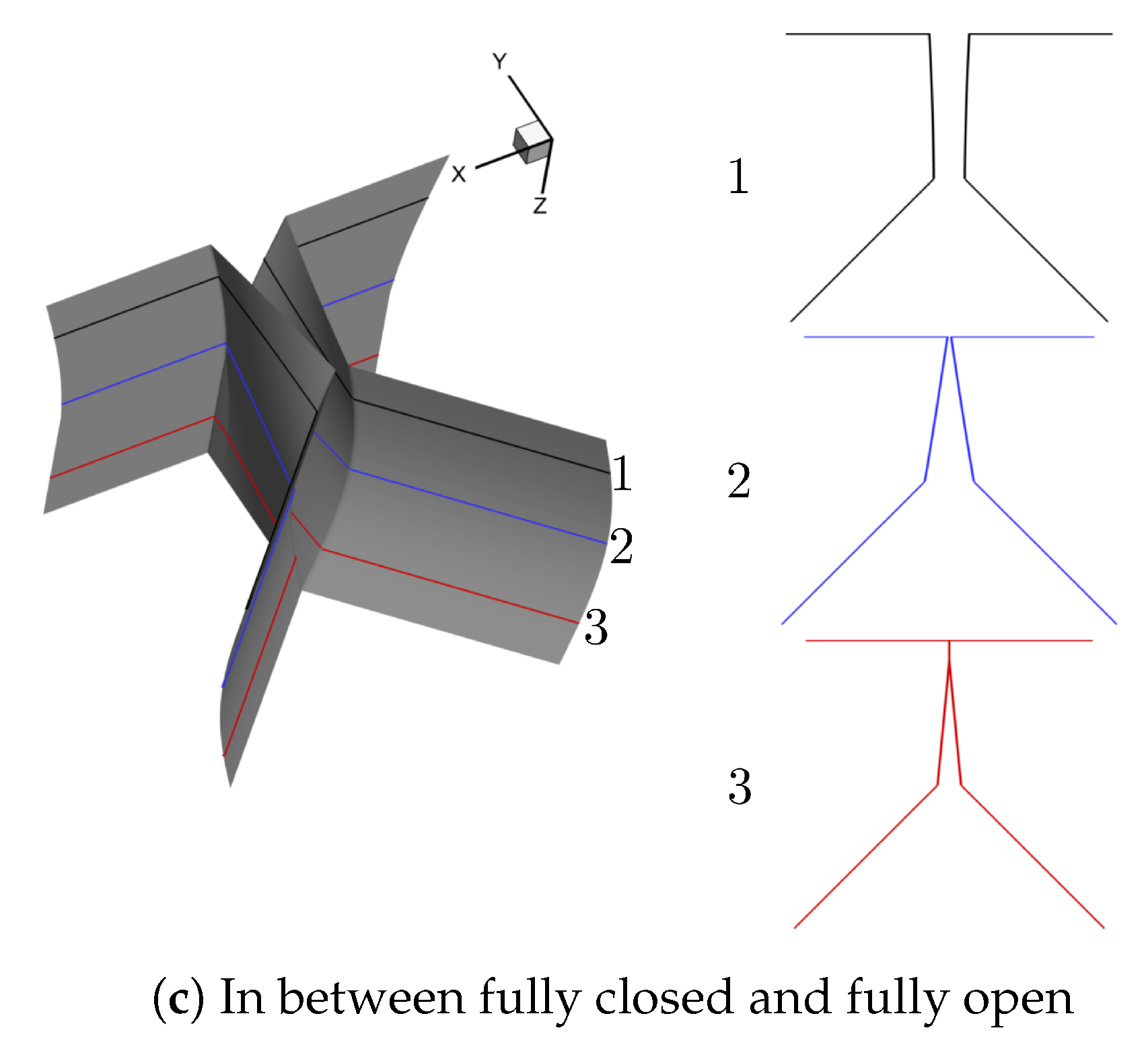
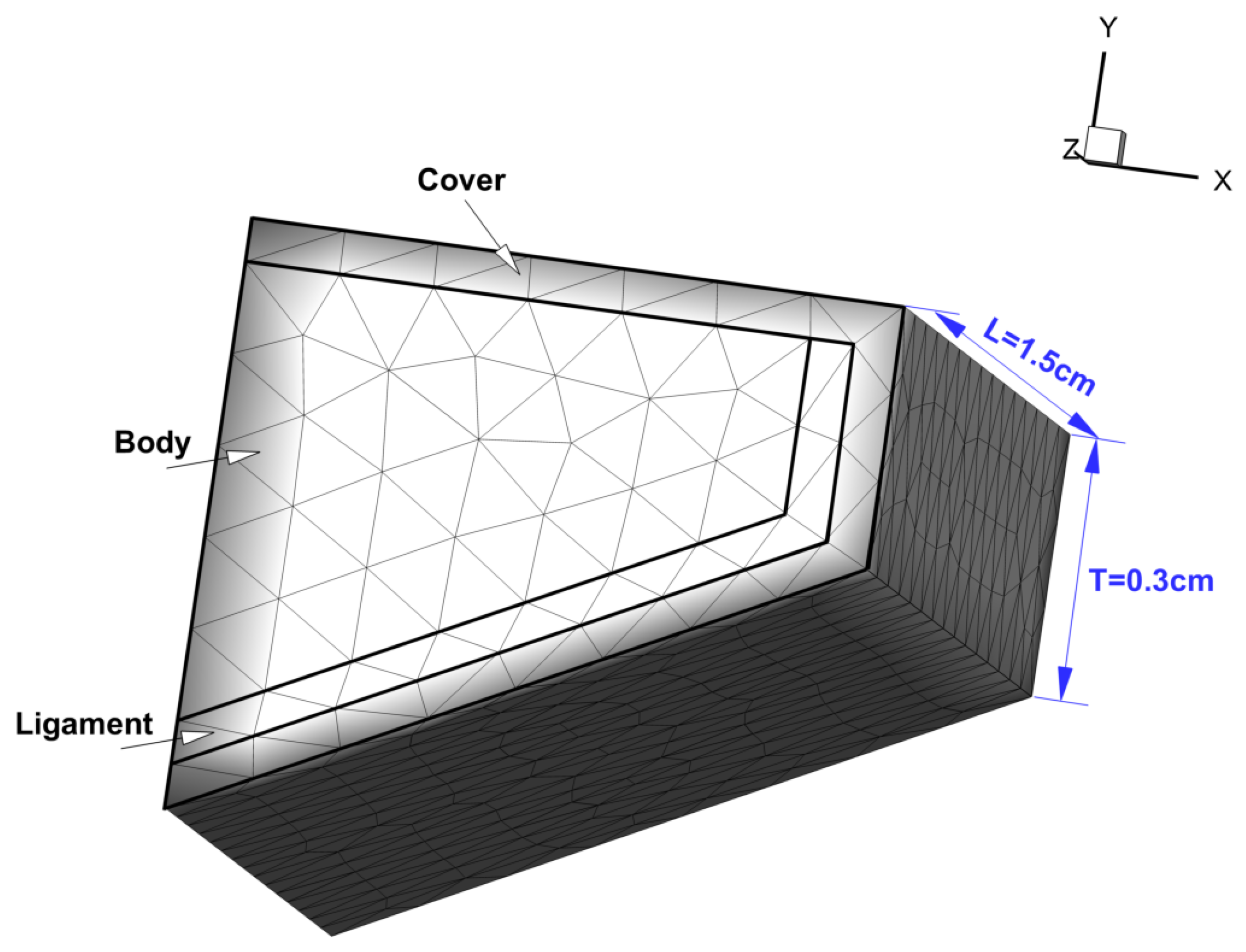
2.1.1. Schematic of the Airway in the Larynx
2.1.2. Modified Bernoulli Equation
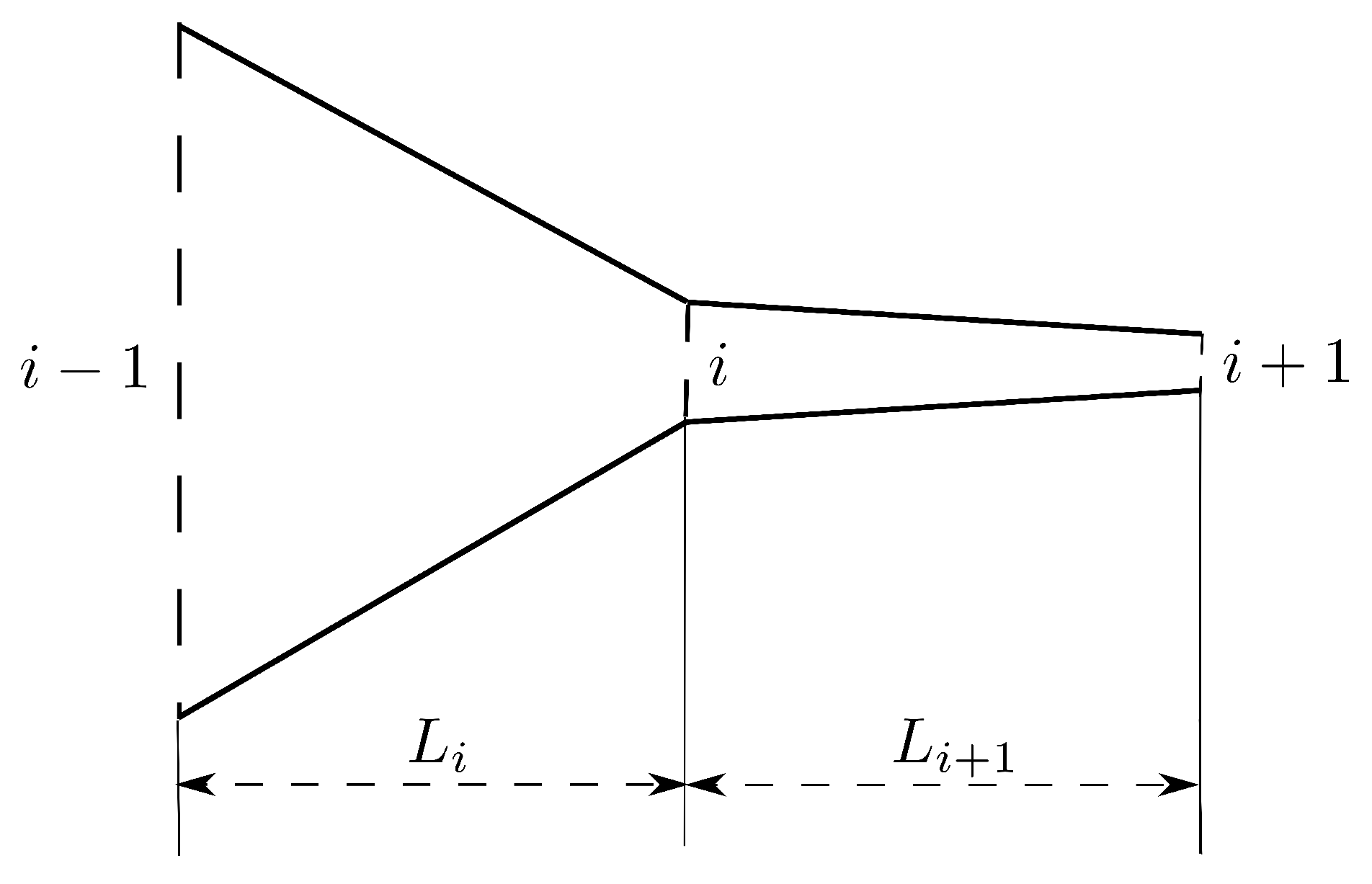
2.1.3. Calculation of the Flow Rate
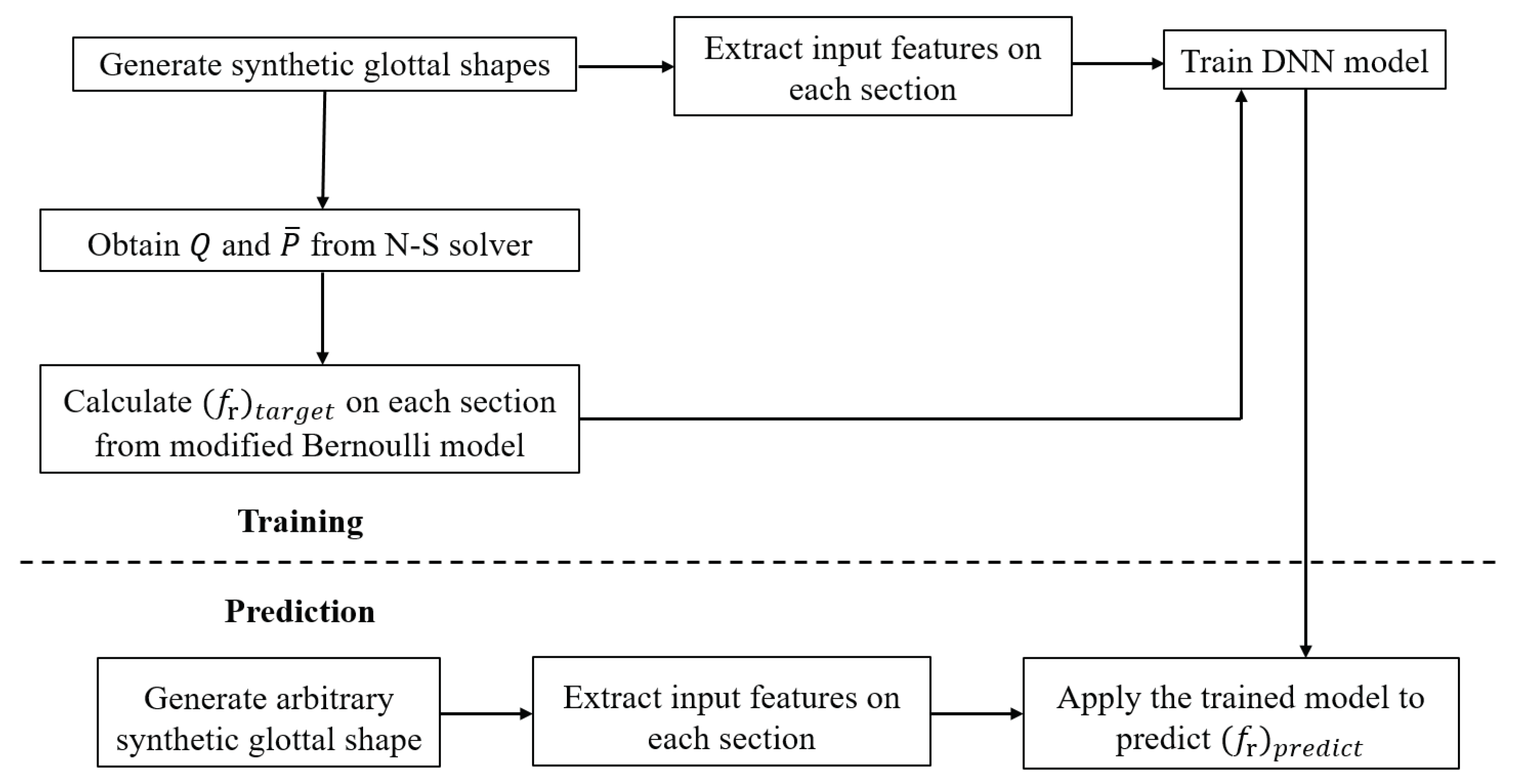
2.2. Implementation of the DNN Model
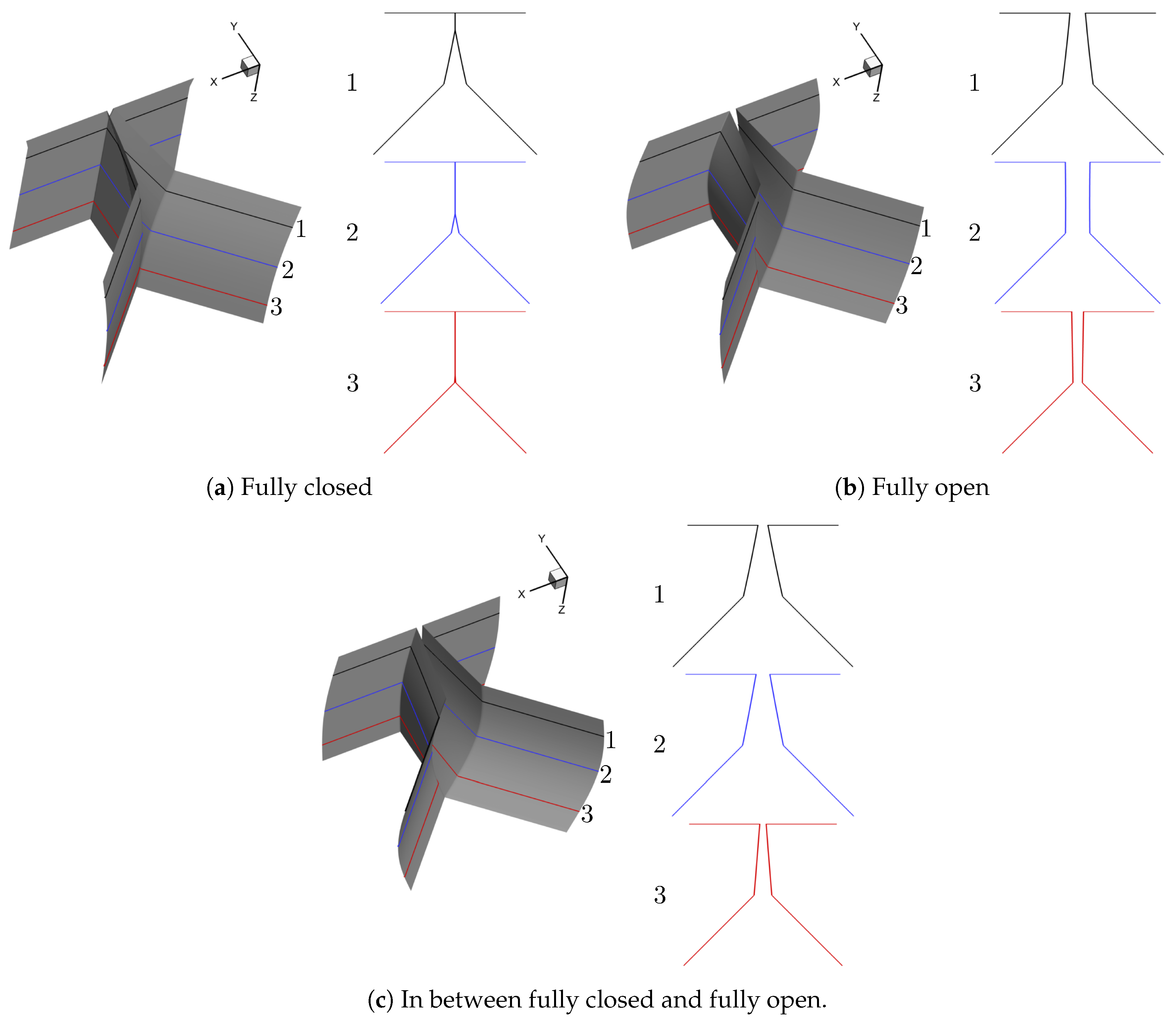
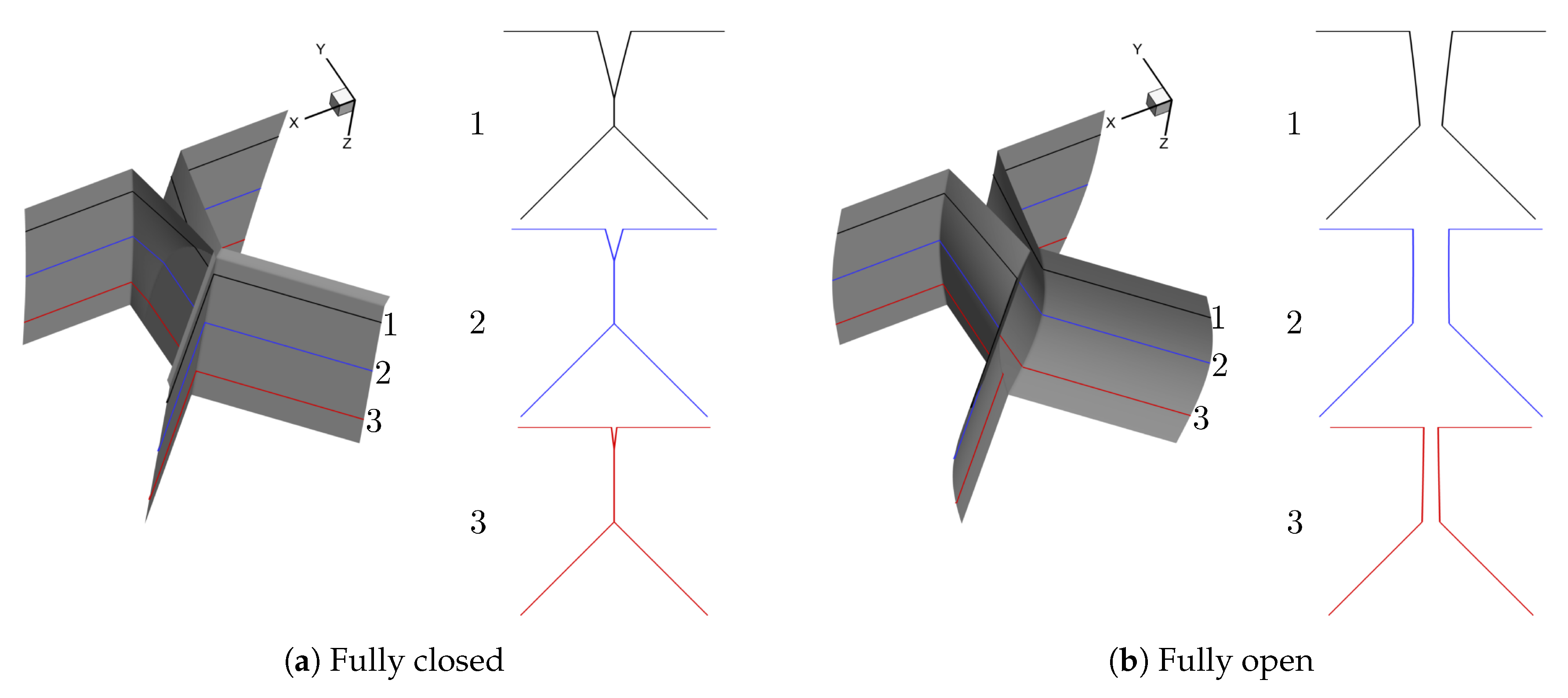
2.2.1. Synthetic Shape Generation
2.2.2. Feature Extraction and Target Value of
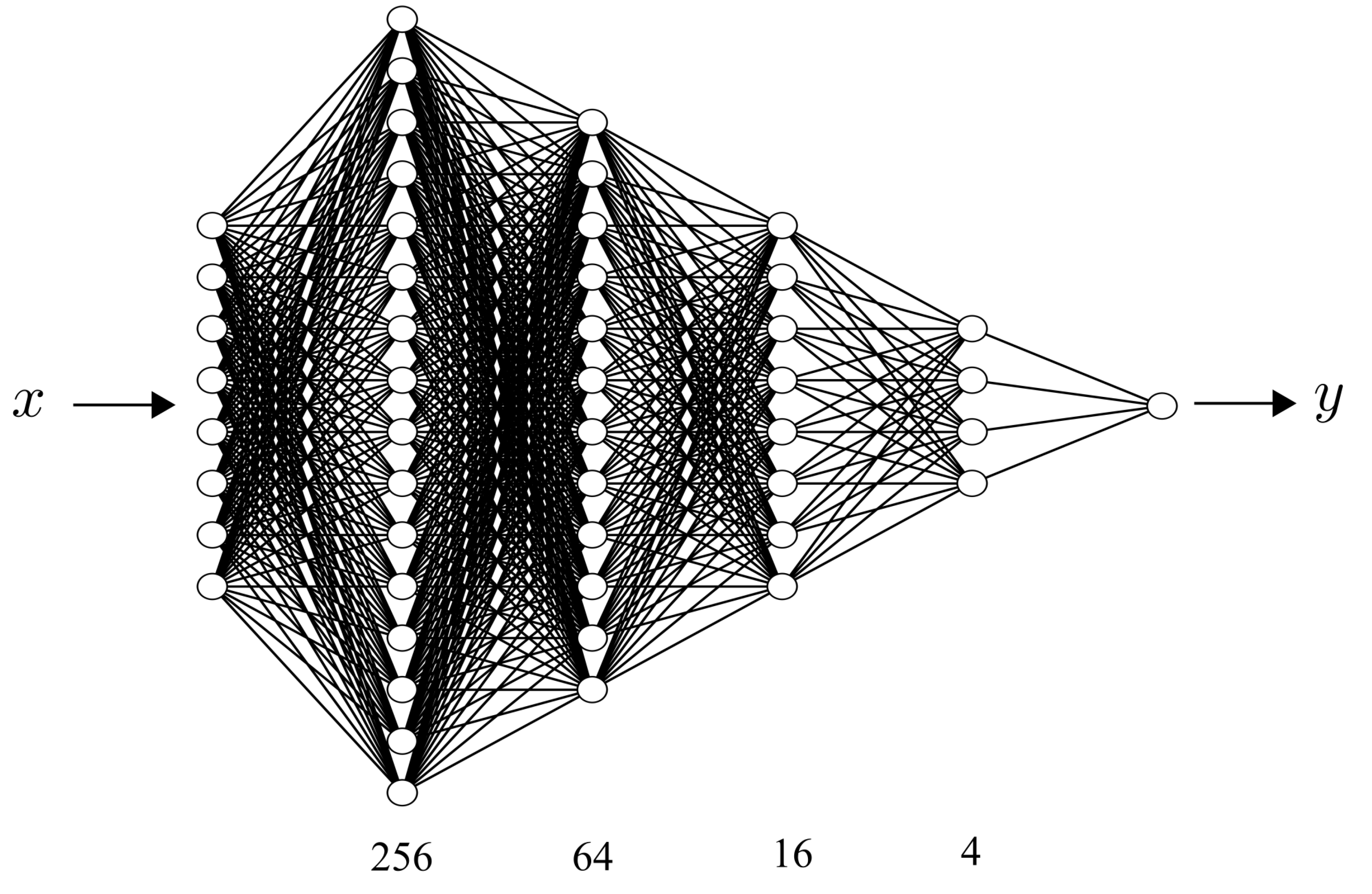
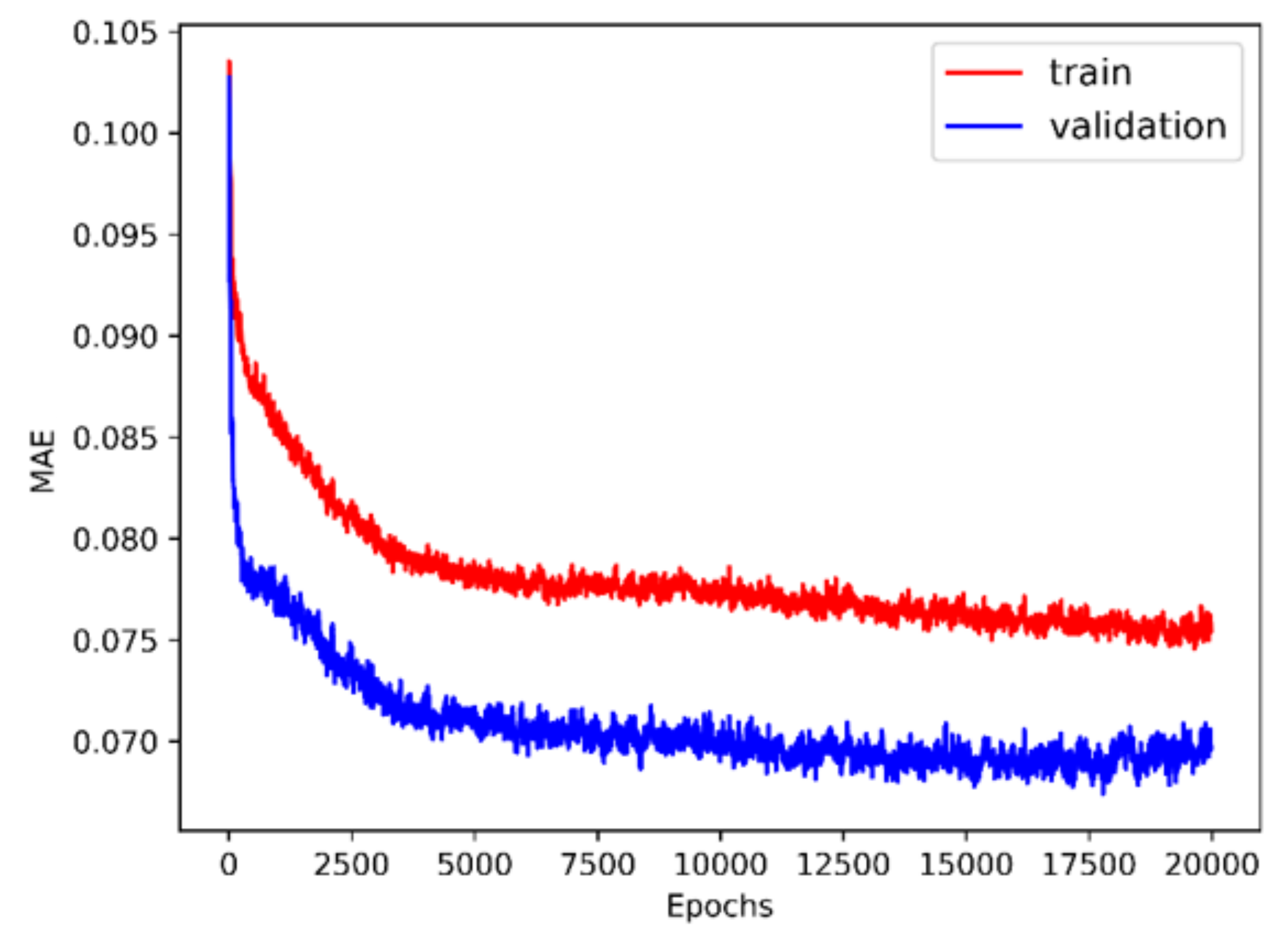
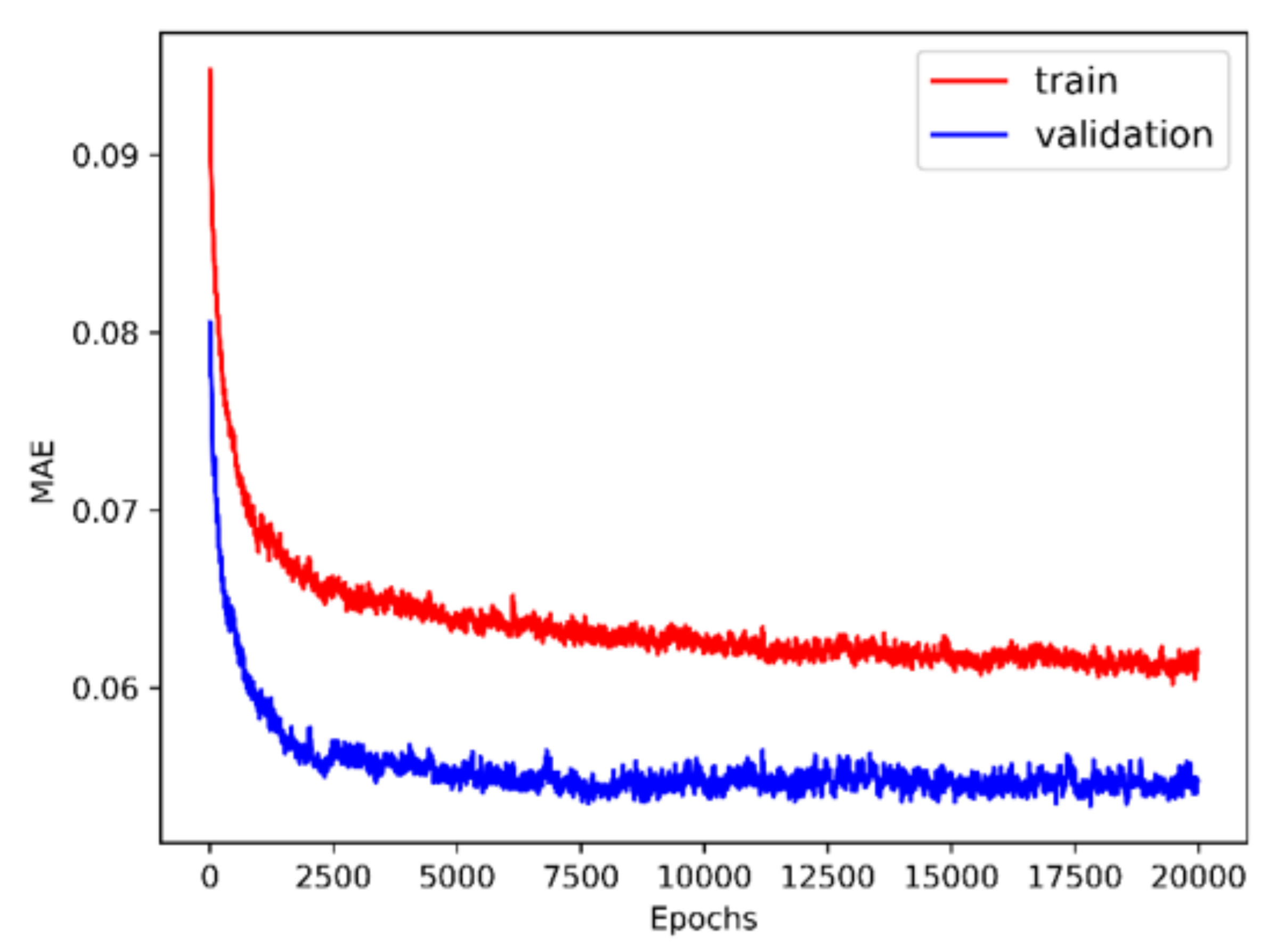
2.2.3. Implementation of the DNN
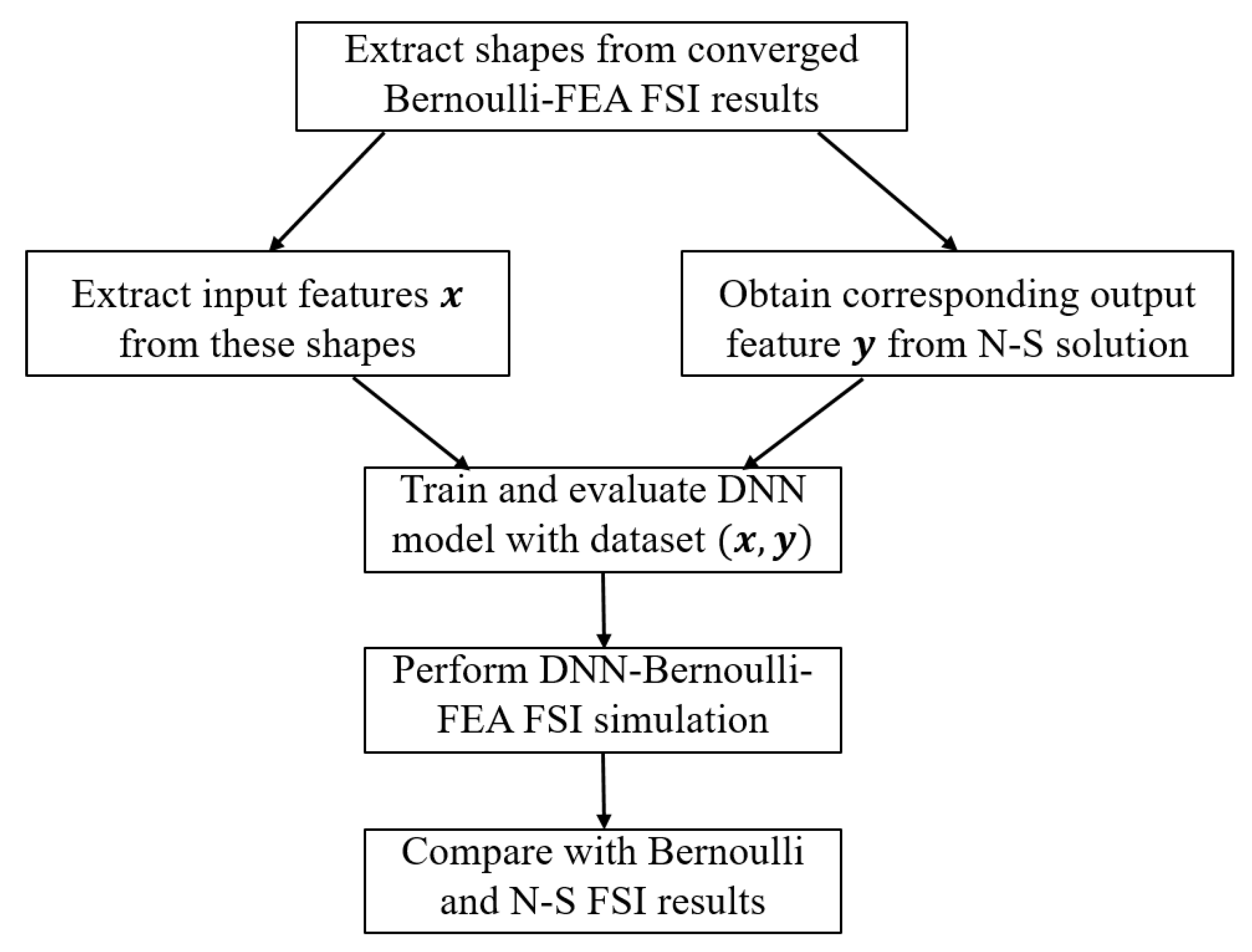
2.3. DNN-Bernoulli Model for FSI Simulation
Prephonatory Geometry of the Vocal Folds
3. Results and Discussion
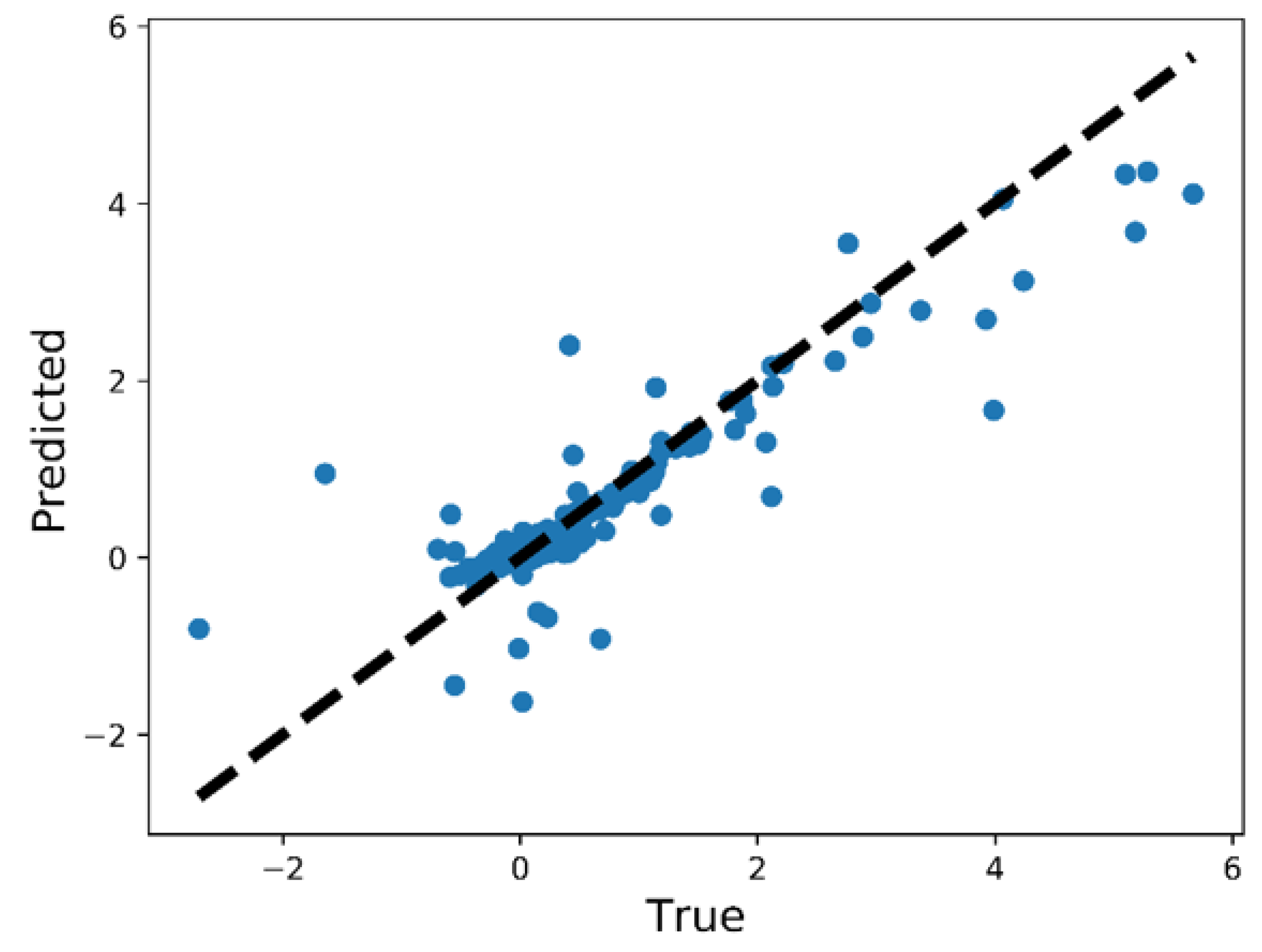
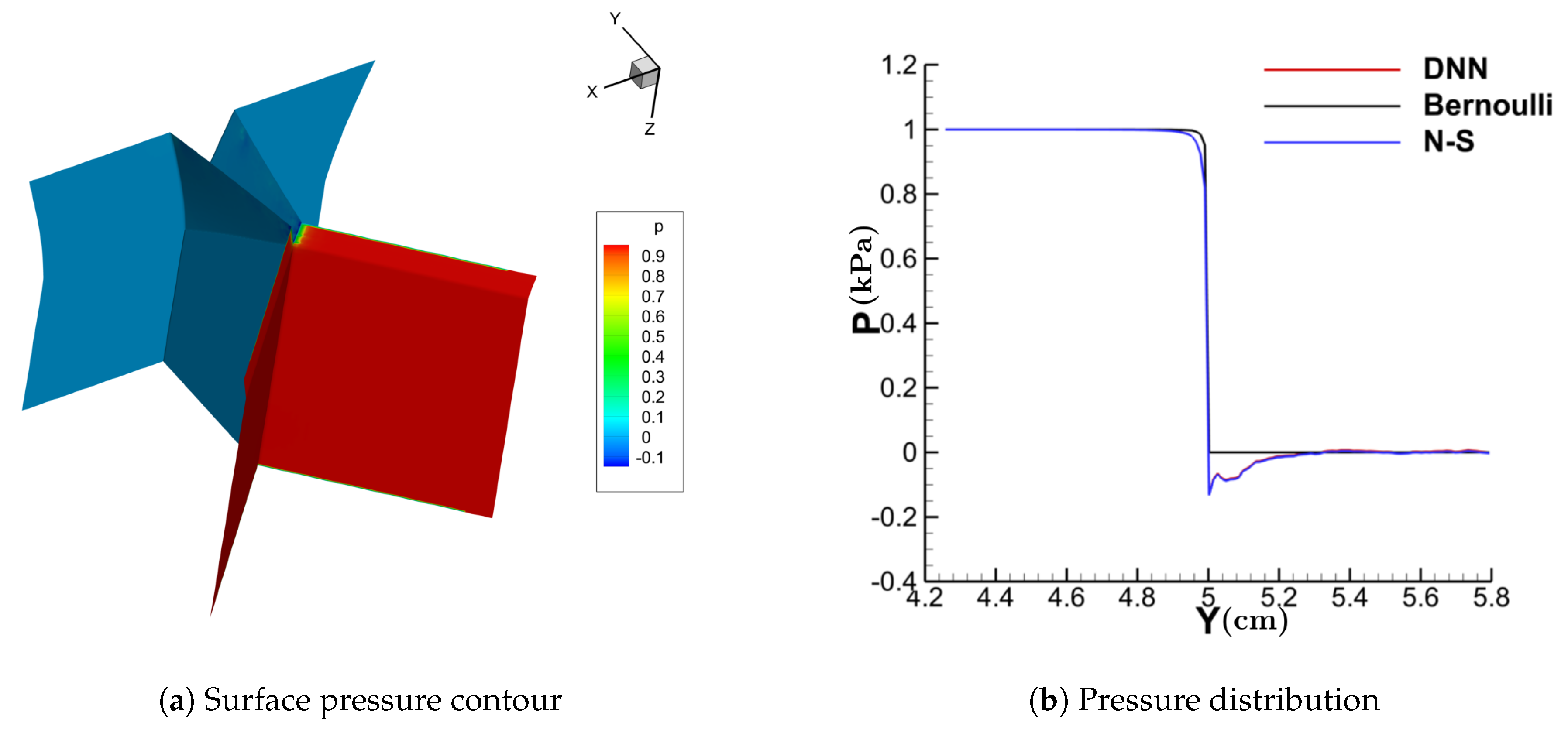
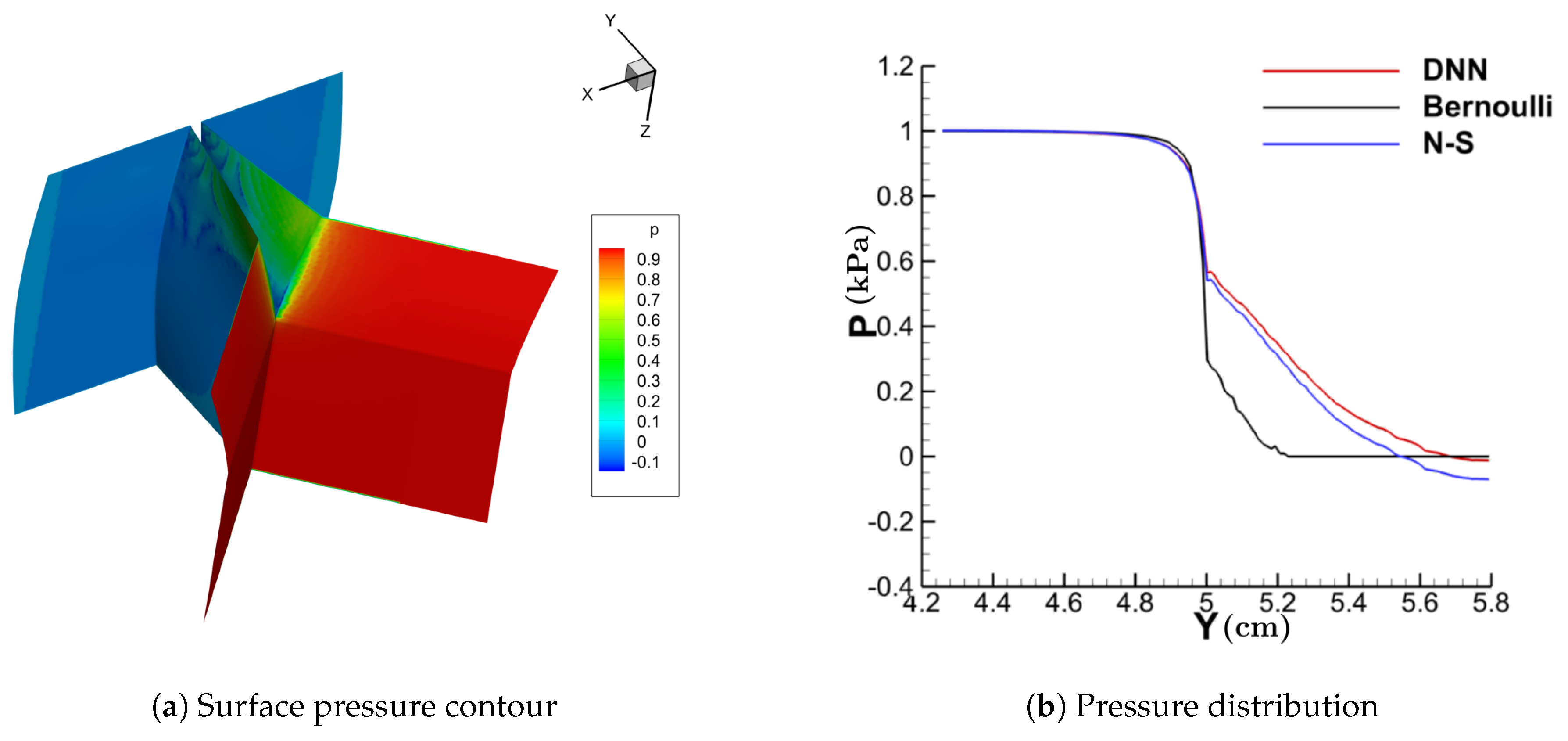
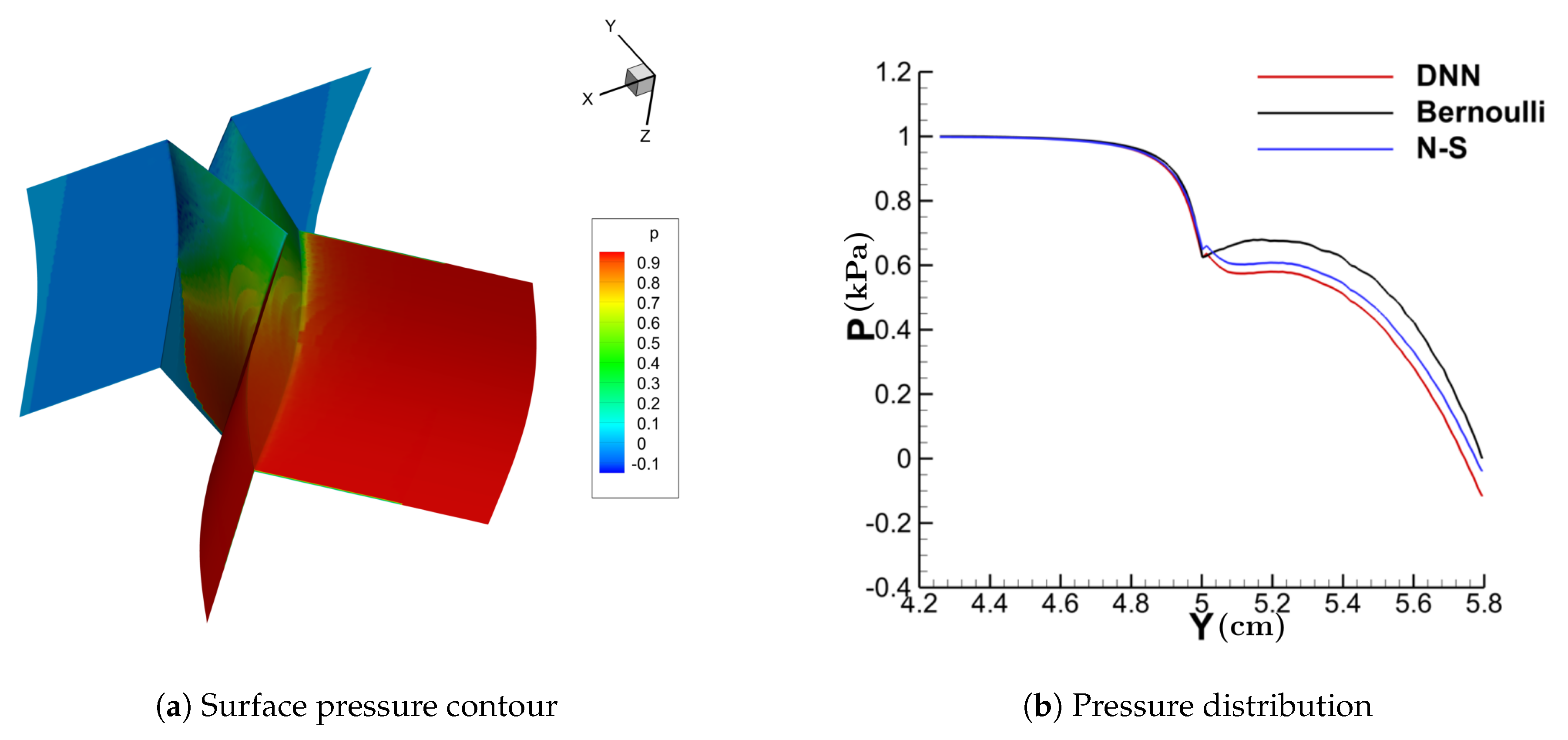
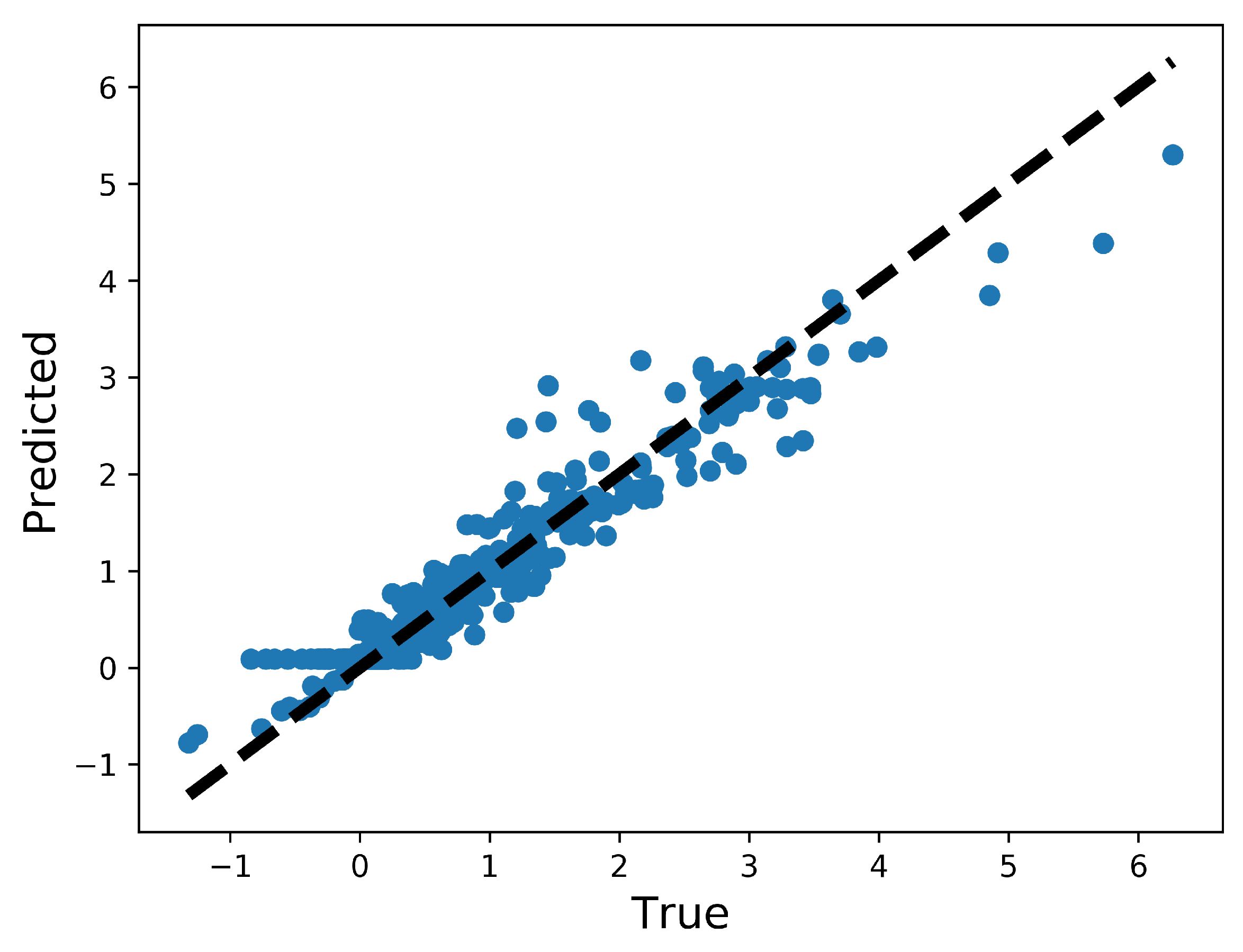
3.1. Performance of the DNN-Bernoulli Model for Synthetic Shapes
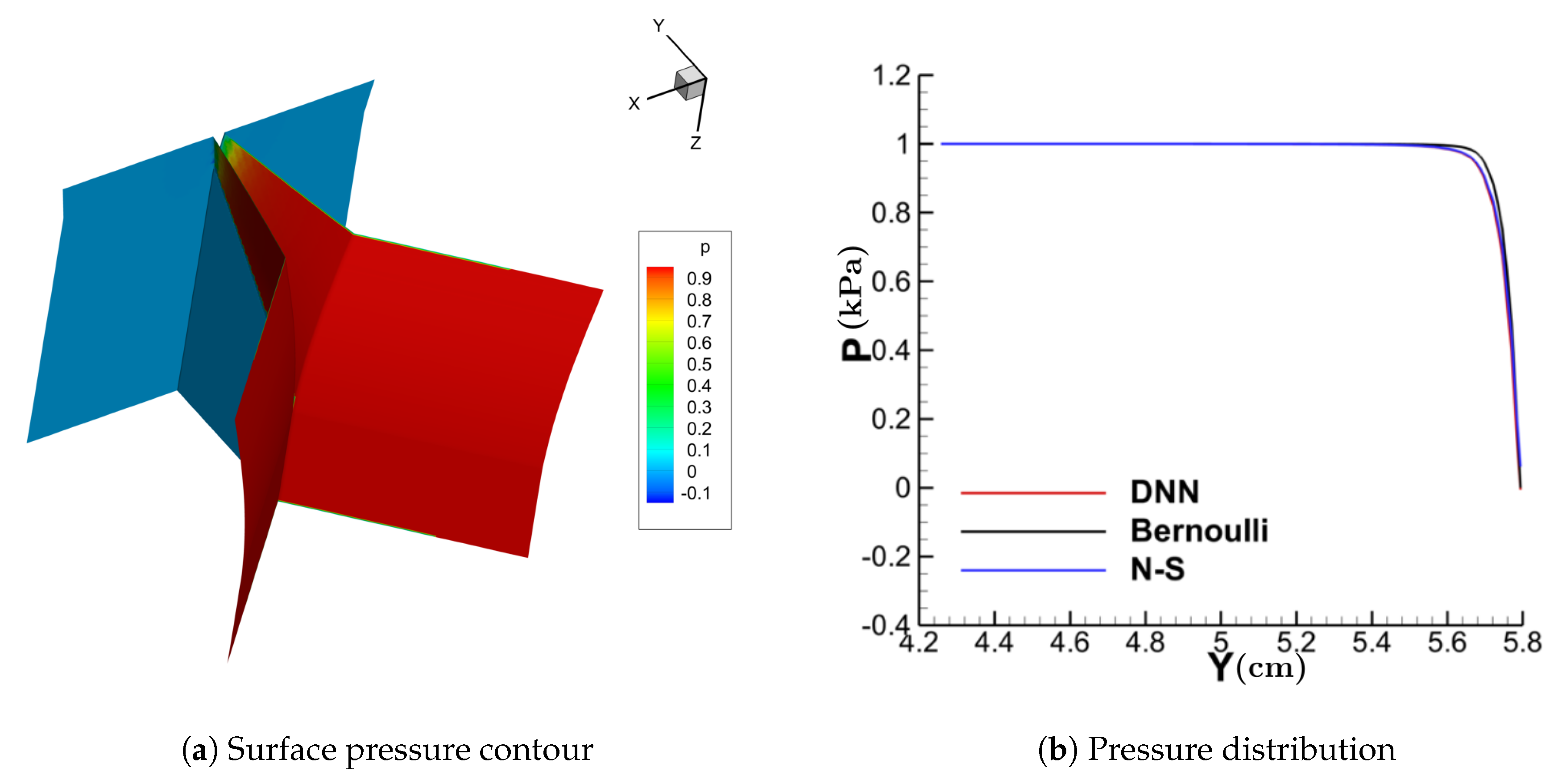
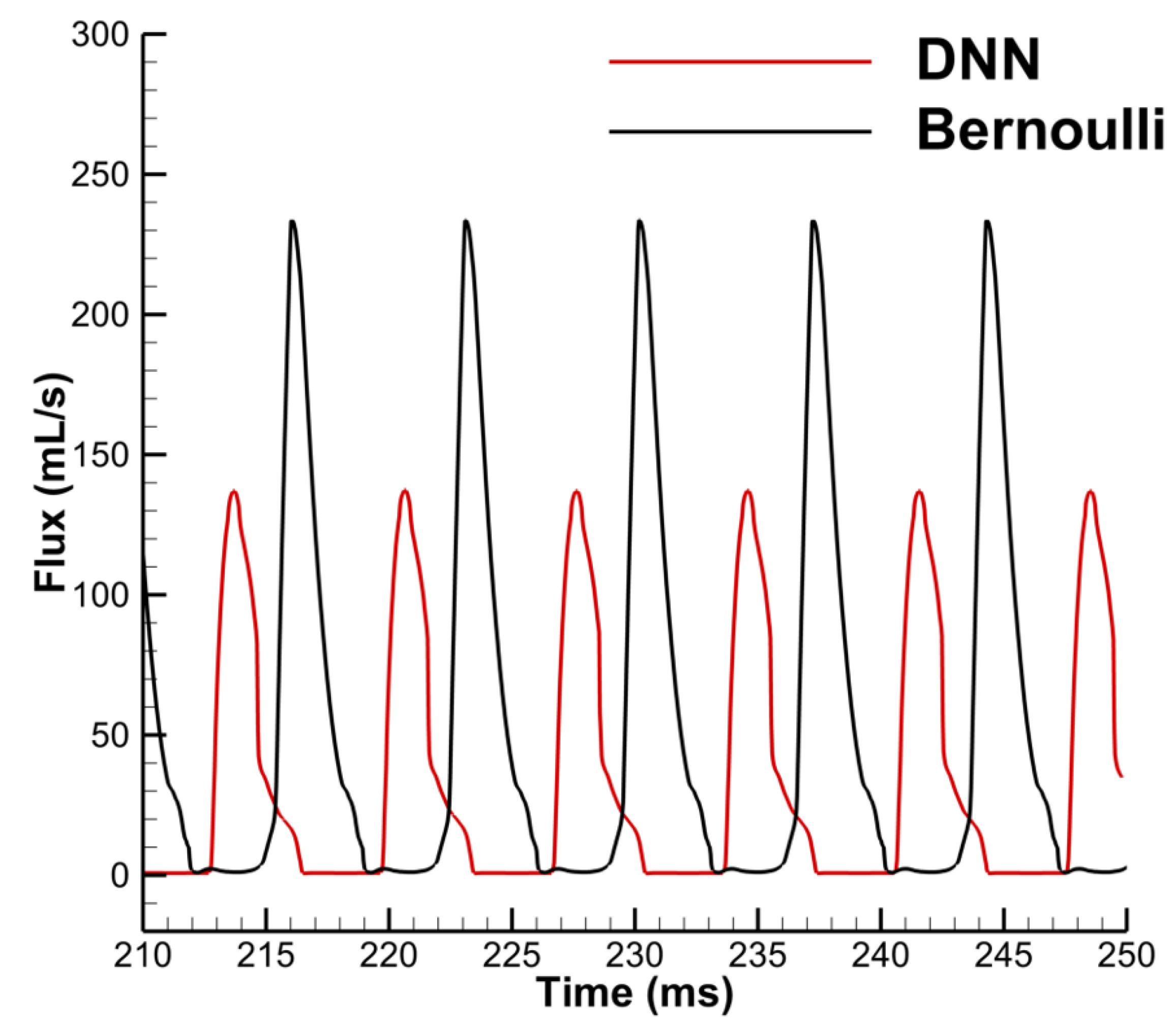
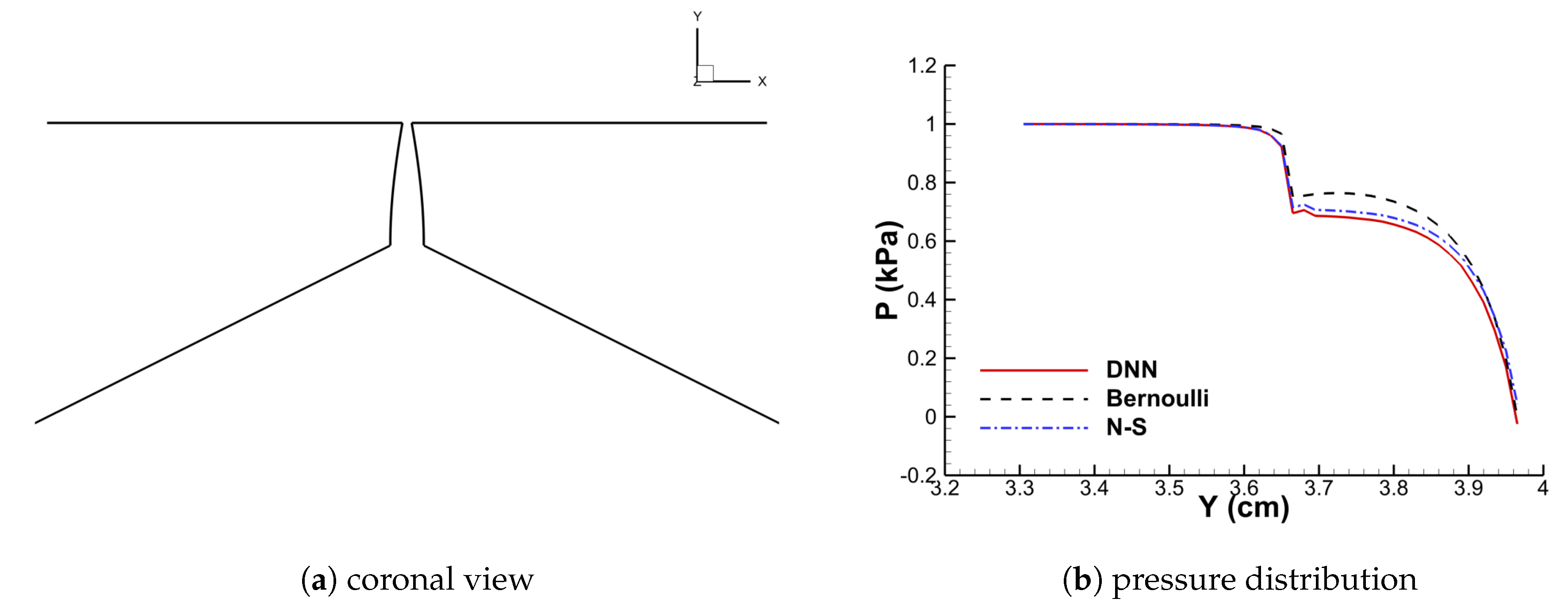
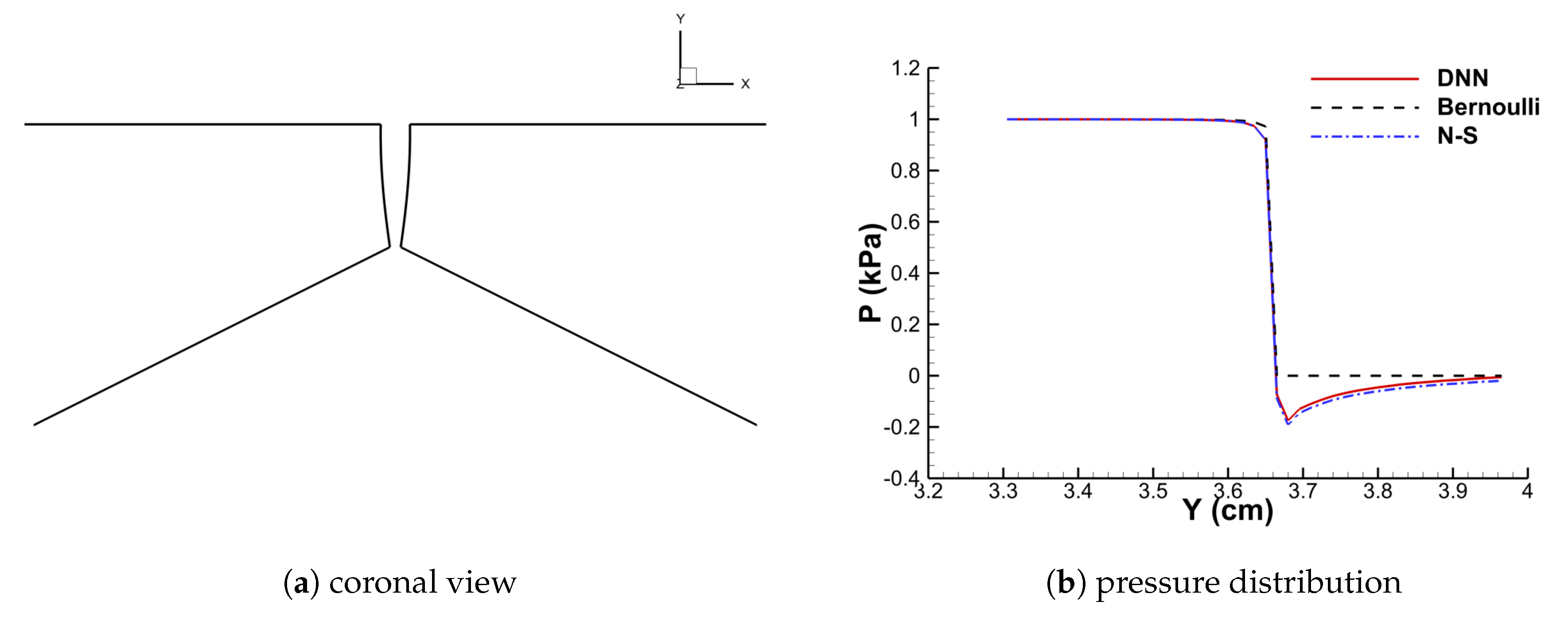
3.2. Performance of the DNN-Bernoulli Model for FSI Simulation
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Titze, I.R. Principles of Voice Production; Prentice Hall: Upper Saddle River, NJ, USA, 1994. [Google Scholar]
- Smith, S.L.; Titze, I.R. Vocal fold contact patterns based on normal modes of vibration. J. Biomech. 2018, 73, 177–184. [Google Scholar] [CrossRef] [PubMed]
- Ishizaka, K.; Flanagan, J.L. Synthesis of voiced sounds from a two-mass model of the vocal cords. Bell Syst. Tech. J. 1972, 51, 1233–1268. [Google Scholar] [CrossRef]
- Titze, I.R. The physics of small-amplitude oscillation of the vocal folds. J. Acoust. Soc. Am. 1988, 83, 1536–1552. [Google Scholar] [CrossRef] [PubMed]
- Story, B.H.; Titze, I.R. Voice simulation with a body-cover model of the vocal folds. J. Acoust. Soc. Am. 1995, 97, 1249–1260. [Google Scholar] [CrossRef] [PubMed]
- Steinecke, I.; Herzel, H. Bifurcations in an asymmetric vocal-fold model. J. Acoust. Soc. Am. 1995, 97, 1874–1884. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.J.; Zhang, Y. Chaotic vibration induced by turbulent noise in a two-mass model of vocal folds. J. Acoust. Soc. Am. 2002, 112, 2127–2133. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, J.J. Nonlinear dynamic mechanism of vocal tremor from voice analysis and model simulations. J. Sound Vib. 2008, 316, 248–262. [Google Scholar] [CrossRef] [Green Version]
- Tao, C.; Jiang, J.J. Chaotic component obscured by strong periodicity in voice production system. Phys. Rev. E 2008, 77, 061922. [Google Scholar] [CrossRef] [Green Version]
- Erath, B.D.; Zañartu, M.; Peterson, S.D.; Plesniak, M.W. Nonlinear vocal fold dynamics resulting from asymmetric fluid loading on a two-mass model of speech. Chaos Interdiscip. J. Nonlinear Sci. 2011, 21, 033113. [Google Scholar] [CrossRef]
- Rupitsch, S.J.; Ilg, J.; Sutor, A.; Lerch, R.; Döllinger, M. Simulation based estimation of dynamic mechanical properties for viscoelastic materials used for vocal fold models. J. Sound Vib. 2011, 330, 4447–4459. [Google Scholar] [CrossRef]
- Yang, A.; Berry, D.A.; Kaltenbacher, M.; Döllinger, M. Three-dimensional biomechanical properties of human vocal folds: Parameter optimization of a numerical model to match in vitro dynamics. J. Acoust. Soc. Am. 2012, 131, 1378–1390. [Google Scholar] [CrossRef] [PubMed]
- Dollinger, M.; Hoppe, U.; Hettlich, F.; Lohscheller, J.; Schuberth, S.; Eysholdt, U. Vibration parameter extraction from endoscopic image series of the vocal folds. IEEE Trans. Biomed. Eng. 2002, 49, 773–781. [Google Scholar] [CrossRef] [PubMed]
- Titze, I.R. Regulating glottal airflow in phonation: Application of the maximum power transfer theorem to a low dimensional phonation model. J. Acoust. Soc. Am. 2002, 111, 367–376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alipour, F.; Berry, D.A.; Titze, I.R. A finite-element model of vocal-fold vibration. J. Acoust. Soc. Am. 2000, 108, 3003–3012. [Google Scholar] [CrossRef]
- Luo, H.; Mittal, R.; Zheng, X.; Bielamowicz, S.A.; Walsh, R.J.; Hahn, J.K. An immersed-boundary method for flow–structure interaction in biological systems with application to phonation. J. Comput. Phys. 2008, 227, 9303–9332. [Google Scholar] [CrossRef] [Green Version]
- Mittal, R.; Zheng, X.; Bhardwaj, R.; Seo, J.H.; Xue, Q.; Bielamowicz, S. Toward a simulation-based tool for the treatment of vocal fold paralysis. Front. Physiol. 2011, 2, 19. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Xue, Q.; Mittal, R.; Beilamowicz, S. A coupled sharp-interface immersed boundary-finite-element method for flow-structure interaction with application to human phonation. J. Biomech. Eng. 2010, 132, 111003. [Google Scholar] [CrossRef] [Green Version]
- Xue, Q.; Zheng, X.; Mittal, R.; Bielamowicz, S. Subject-specific computational modeling of human phonation. J. Acoust. Soc. Am. 2014, 135, 1445–1456. [Google Scholar] [CrossRef] [Green Version]
- Ruty, N.; Pelorson, X.; Van Hirtum, A.; Lopez-Arteaga, I.; Hirschberg, A. An in vitro setup to test the relevance and the accuracy of low-order vocal folds models. J. Acoust. Soc. Am. 2007, 121, 479–490. [Google Scholar] [CrossRef] [Green Version]
- Wurzbacher, T.; Schwarz, R.; Döllinger, M.; Hoppe, U.; Eysholdt, U.; Lohscheller, J. Model-based classification of nonstationary vocal fold vibrations. J. Acoust. Soc. Am. 2006, 120, 1012–1027. [Google Scholar] [CrossRef]
- Zanartu, M.; Mongeau, L.; Wodicka, G.R. Influence of acoustic loading on an effective single mass model of the vocal folds. J. Acoust. Soc. Am. 2007, 121, 1119–1129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, D.A.; Herzel, H.; Titze, I.R.; Krischer, K. Interpretation of biomechanical simulations of normal and chaotic vocal fold oscillations with empirical eigenfunctions. J. Acoust. Soc. Am. 1994, 95, 3595–3604. [Google Scholar] [CrossRef] [PubMed]
- Berry, D.A. Mechanisms of modal and nonmodal phonation. J. Phon. 2001, 29, 431–450. [Google Scholar] [CrossRef]
- Döllinger, M.; Berry, D.A.; Berke, G.S. Medial surface dynamics of an in vivo canine vocal fold during phonation. J. Acoust. Soc. Am. 2005, 117, 3174–3183. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neubauer, J.; Mergell, P.; Eysholdt, U.; Herzel, H. Spatio-temporal analysis of irregular vocal fold oscillations: Biphonation due to desynchronization of spatial modes. J. Acoust. Soc. Am. 2001, 110, 3179–3192. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Van den Berg, J.; Zantema, J.; Doornenbal, P., Jr. On the air resistance and the Bernoulli effect of the human larynx. J. Acoust. Soc. Am. 1957, 29, 626–631. [Google Scholar] [CrossRef]
- Streeter, V.L.; Wylie, E.; Bedford, K. Fluid Mechanics; Civil Engineering Series; WCB/McGraw Hill: New York, NY, USA, 1998. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 8 June 2019).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 8 June 2019).
- Dhondt, G. CalculiX CrunchiX User’s Manual Version 2.12. 2017. Available online: http://www.dhondt.de/ccx_2.15.pdf (accessed on 8 June 2019).
- Xue, Q.; Mittal, R.; Zheng, X.; Bielamowicz, S. Computational modeling of phonatory dynamics in a tubular three-dimensional model of the human larynx. J. Acoust. Soc. Am. 2012, 132, 1602–1613. [Google Scholar] [CrossRef] [Green Version]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Q | flow rate |
| prescribed pressure at the entry of the contraction part | |
| pressure at the exit of the contraction part | |
| pressure at one of the sections of the glottis part | |
| pressure at the exit of the glottis part | |
| prescribed pressure at the expansion part | |
| , , | length of the contraction, glottis and expansion parts, respectively |
| , | distance between consecutive sections of the glottis part |
| Input Features | Non-Dimensional Expression |
|---|---|
| Position | |
| Area | |
| Hydraulic diameter | |
| Upstream angle | |
| Downstream angle | |
| Shape change rate | |
| Pressure drop | |
| Re |
| (g/cm3) | (kPa) | (kPa) | (kPa) | |||
|---|---|---|---|---|---|---|
| Cover | 1.043 | 2.01 | 0.9 | 40 | 0.0 | 10 |
| Ligament | 1.043 | 3.31 | 0.9 | 66 | 0.0 | 40 |
| Body | 1.043 | 3.99 | 0.9 | 80 | 0.0 | 20 |
| Bernoulli | 0.27–48.7 | 0.2–19.16 |
| DNN-Bernoulli | 0.01–8.94 | 0.01–8.53 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zheng, X.; Xue, Q. A Deep Neural Network Based Glottal Flow Model for Predicting Fluid-Structure Interactions during Voice Production. Appl. Sci. 2020, 10, 705. https://doi.org/10.3390/app10020705
Zhang Y, Zheng X, Xue Q. A Deep Neural Network Based Glottal Flow Model for Predicting Fluid-Structure Interactions during Voice Production. Applied Sciences. 2020; 10(2):705. https://doi.org/10.3390/app10020705
Chicago/Turabian StyleZhang, Yang, Xudong Zheng, and Qian Xue. 2020. "A Deep Neural Network Based Glottal Flow Model for Predicting Fluid-Structure Interactions during Voice Production" Applied Sciences 10, no. 2: 705. https://doi.org/10.3390/app10020705
APA StyleZhang, Y., Zheng, X., & Xue, Q. (2020). A Deep Neural Network Based Glottal Flow Model for Predicting Fluid-Structure Interactions during Voice Production. Applied Sciences, 10(2), 705. https://doi.org/10.3390/app10020705