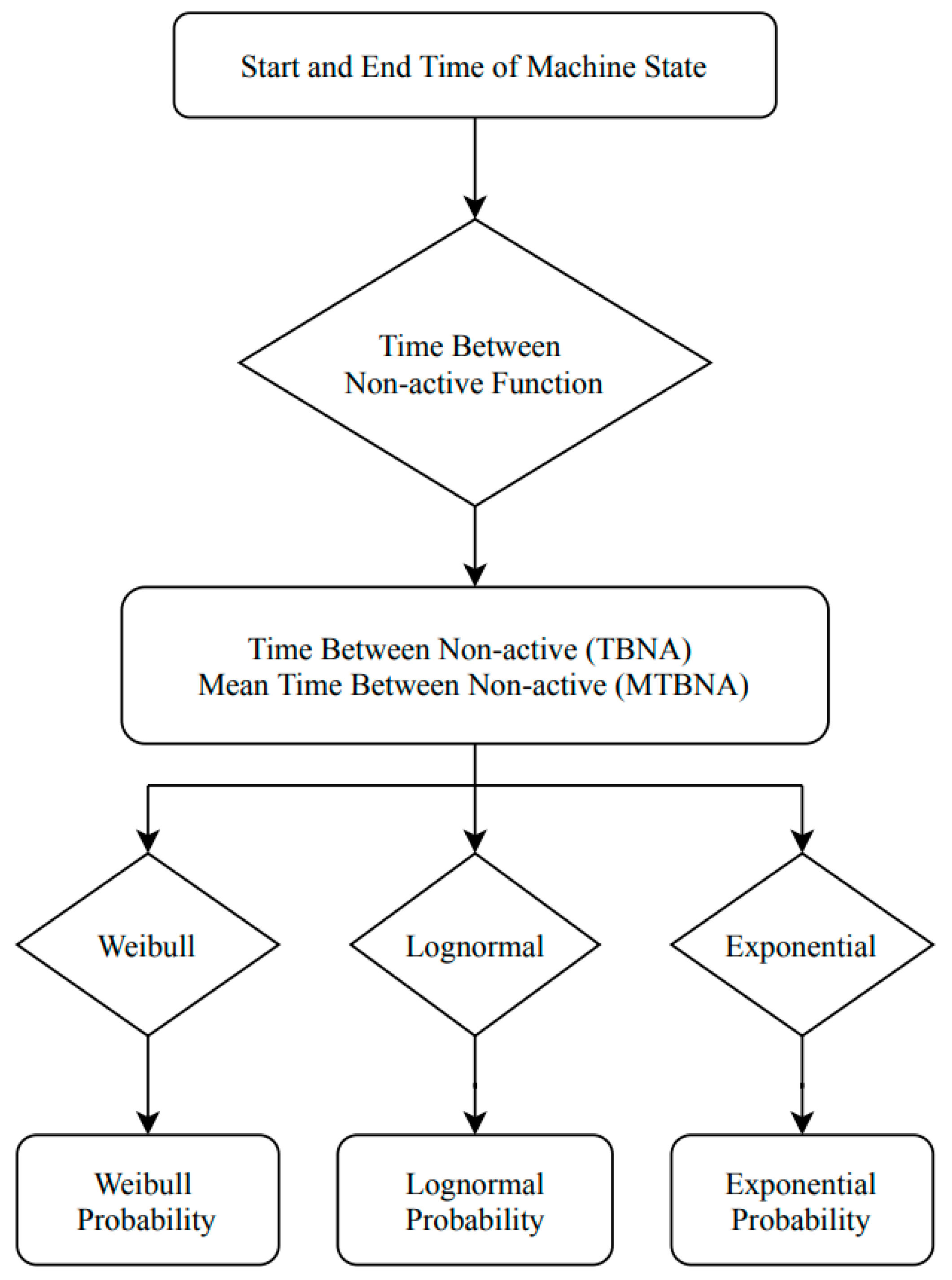
3.2.1. Reliability Features
In this study, the reliability measures that we used for extracting features from raw data included Weibull, lognormal, and exponential distributions. Reliability analysis was a statistical measure for life data [
15,
16]. It was determined by deriving the proportion of methodical variation in a scale, which can be performed by determining the association between the scores obtained from divergent administrations of the scale. Therefore, if the association in reliability analysis was high, the scale yielded consistent results and was, therefore, reliable. To compute the reliability of the machines in a manufacturing line, 2 measures, called the time between non-active states (TBNA) and mean time between non-active (MTBNA) states of the machines, were calculated.
Figure 2 illustrates the structure of the reliability analysis.
Based on the TTF [
17,
18] mathematical formulation, we can define the
TBNA state, which is the elapsed time between the non-active states of the machines, and
MTBNA as follows.
Once
TBNA and
MTBNA are calculated, we extract features from raw data using Weibull, lognormal, and exponential distributions. We first obtained the Weibull distribution, which was one of the most widely used lifetime data analyses for reliability engineering [
19]. It can flexibly model various types of lifetime distributions [
20]. In this paper, we used a 2-parameter Weibull distribution, which had scale and shape parameters. Here, the scale parameter was denoted as
, and the shape parameter was denoted as
[
21]. When
was less than 1, the distribution showed a decreasing failure rate over time [
22]. When
was 1, the distribution had a constant failure rate. When the
parameter was greater than 1, the failure rate increased over time [
21]. We estimated the appropriate scale and shape parameters of the Weibull distribution by using the TBNA with maximum likelihood estimation (MLE) method. More specifically, the MLE formula [
23] for determining the parameters of the Weibull distribution is written as follows:
In Equation (3),
was TBNA calculated in Equation (1), and
and
are the numbers of non-zero data points. Once the shape parameter
and scale parameter
of the Weibull distribution was calculated using Equation (3), we could estimate the non-active state rate of the machine using the probability density function of the Weibull as follows:
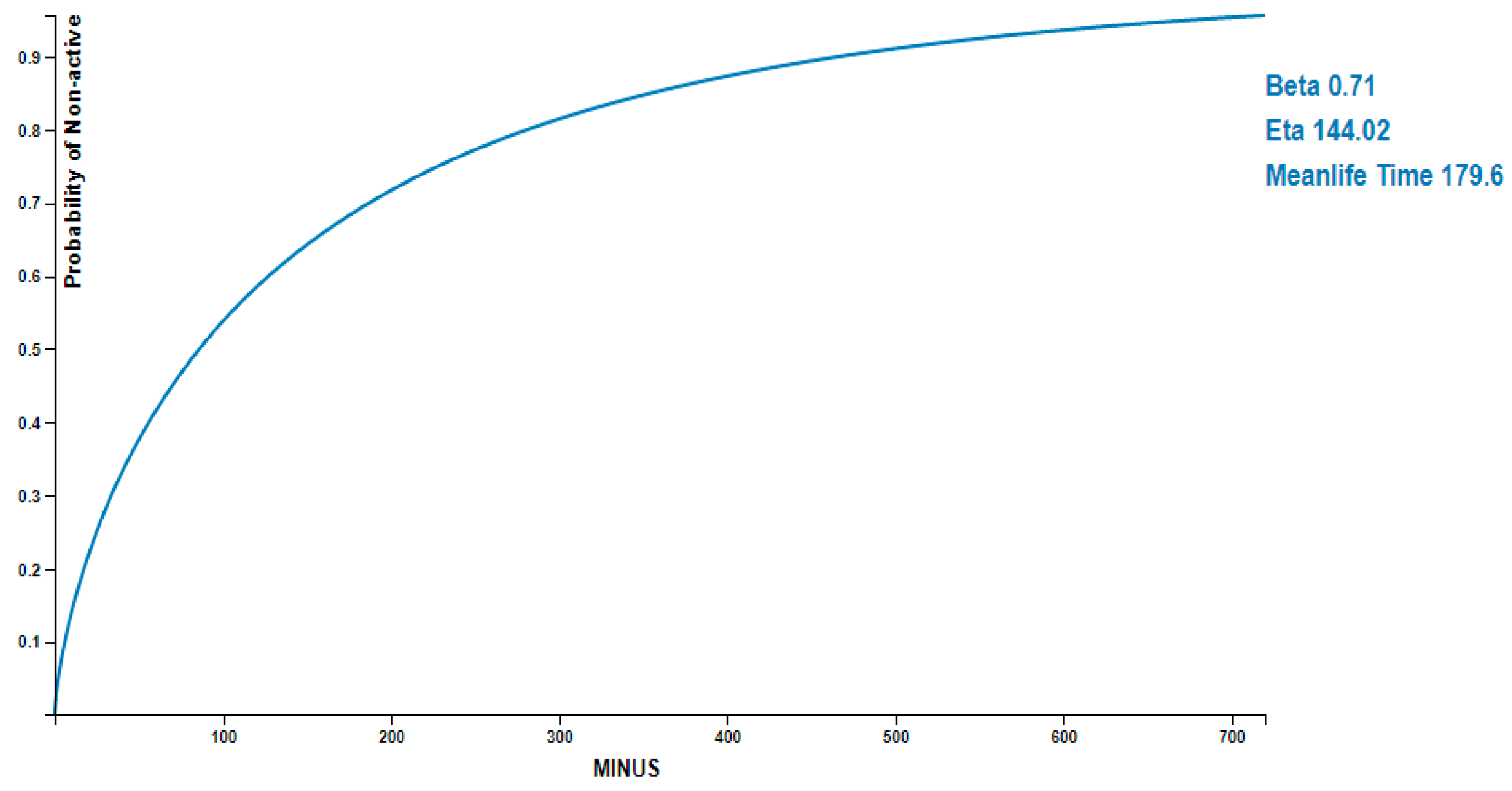
Figure 3 illustrates the fitting curve result of the Weibull distribution with 2 parameters set as
, eta
, and the mean life of the non-active state was set as 179.6, which means that the non-active state of the machine will occur when the machine was operating for approximately 179 min. In
Figure 3, the
x-axis indicated the elapsed time (in minutes) from which the machine was active, and the
y-axis indicated the probability of the non-active state of the machine. From the figure, we can observe the relationship between active and non-active states of the machine. For example, when the probability of non-activation of a facility was 0.8, it means that about 280 min have passed from the time it was activated.
Further, we obtained the lognormal distribution, which was a constant probability distribution of random variables [
24]. This distribution was also widely used to model the lives of units whose failure modes were of the fatigue–stress nature [
25]. Additionally, the lognormal distribution complements the Weibull distribution well for modeling the reliability of a machine. The formula of the lognormal distribution is written as follows:
In Equation (5), is , where is TBNA calculated in Equation (1), the logarithm of MTBN calculated in Equation (2), and the standard deviation of the natural logarithms of TBNA.
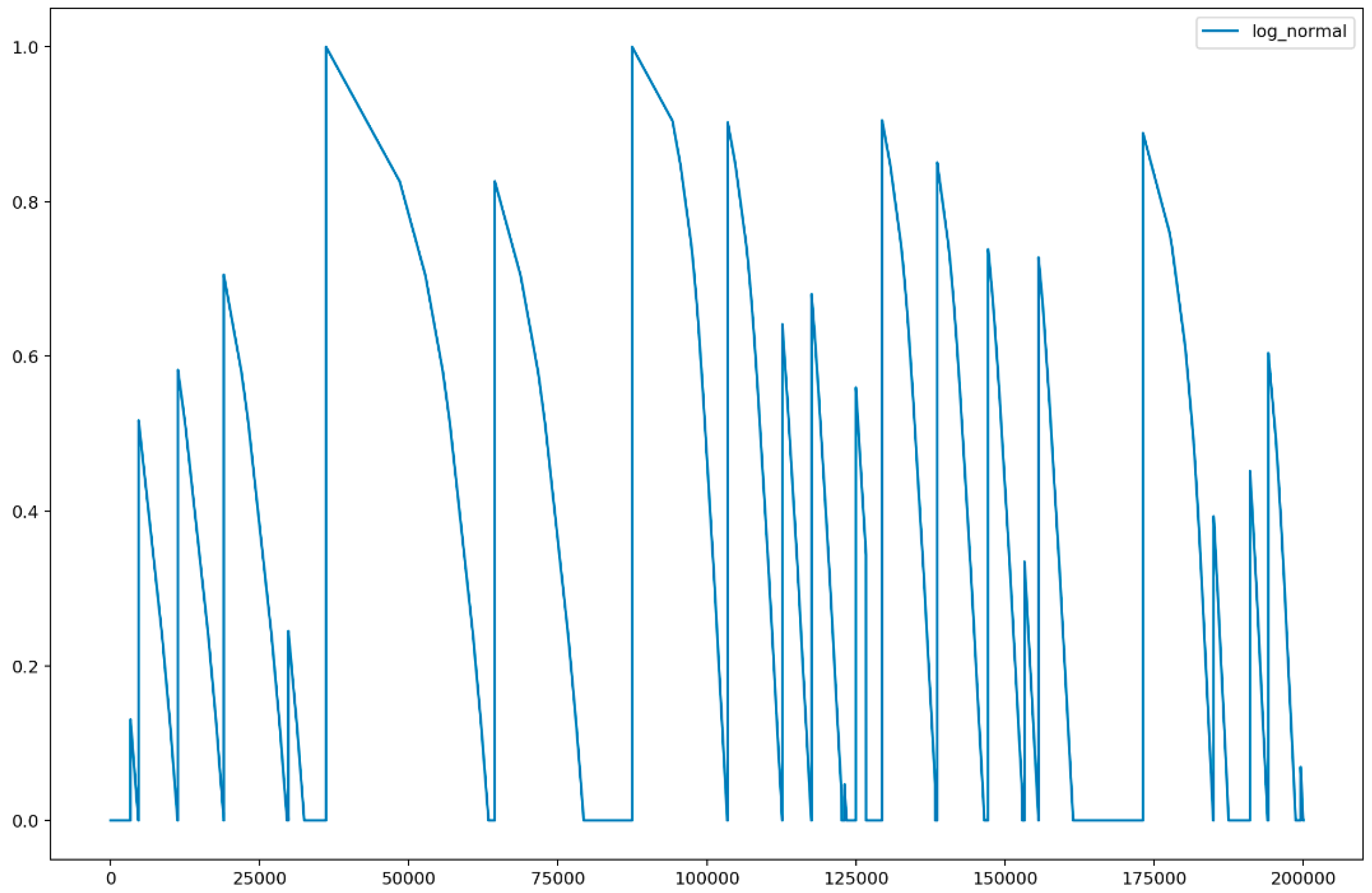
Figure 4 shows the result of lognormal distribution probability. In
Figure 4, the
x-axis indicated the elapsed time (in minutes) from which the machine was active, and the
y-axis indicated the probability of the non-active state of the machine obtained using the lognormal distribution in Equation (5). From the figure, we can observe that a machine enters active and non-active states over time. Here, if the value on the
y-axis was 1, the machine was activated, and if the value was close to 0.0, the probability of non-activation increased. In other words, we can see that lognormal distribution is used to describe the probability of a specific event occurring.
Similar to the Weibull and lognormal distributions, the exponential distribution was typically used in reliability engineering and exhibited a simple distribution [
26]. The exponential distribution was utilized to model the behavior of units that have a constant failure rate. The primary probability density function for the exponential distribution is expressed as follows.
In Equation (6), is the constant rate in the non-active state per unit of measurement, the mean TBNA, and the TBNA during the machine operation.
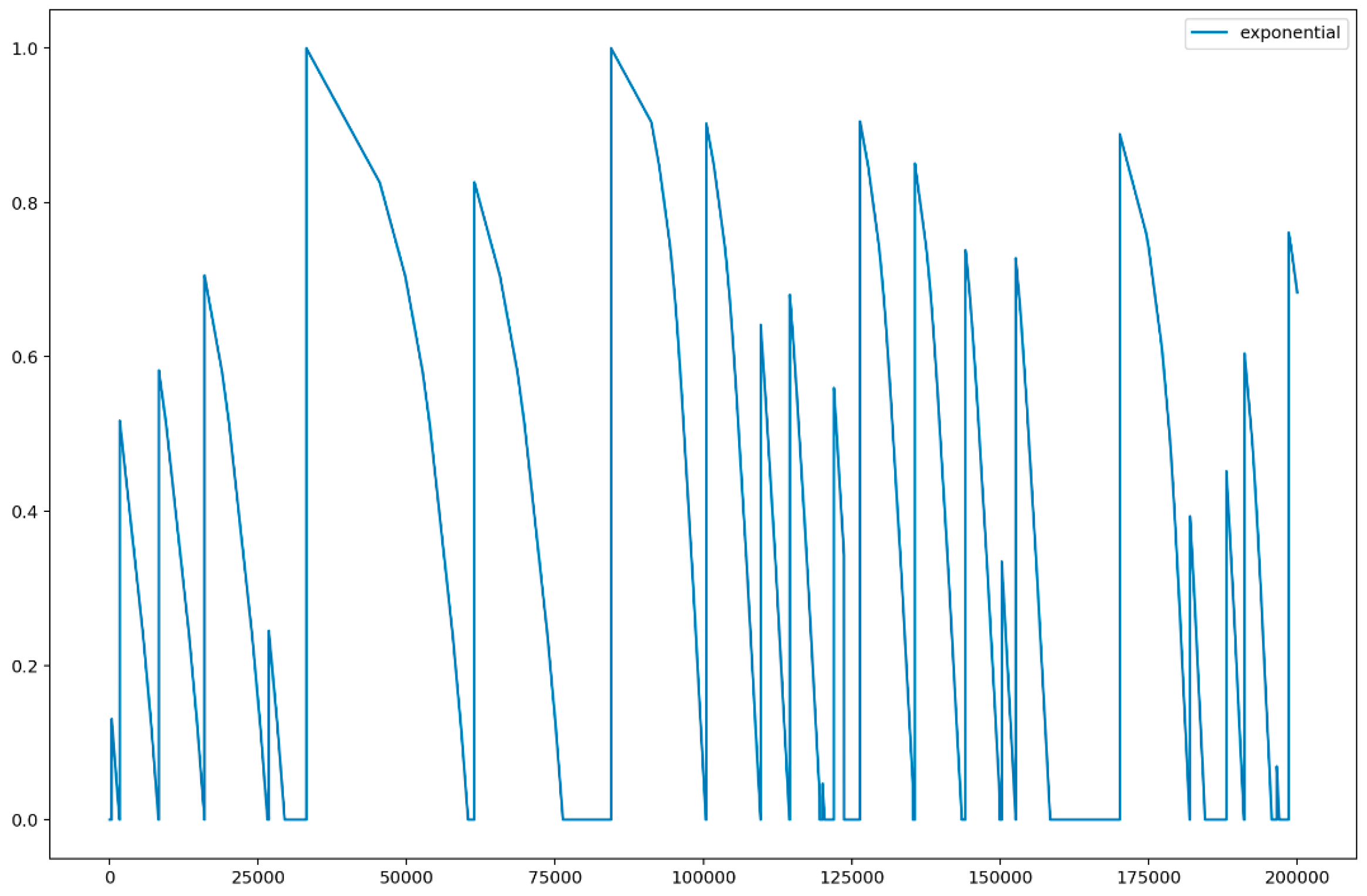
Figure 5 illustrates the result of the exponential distribution. In
Figure 5, the
x-axis indicated the elapsed time (in minutes) from which the machine was active, and the
y-axis indicated the probability of a non-active state of the machine obtained using exponential distribution in Equation (6). Similar to
Figure 4,
Figure 5 demonstrated that a machine entered active and non-active states over time. Unlike lognormal distributions, the exponential distribution model the time elapsed between events and represented the amount of time until the machine enters into a non-active state.
In feature extraction using reliability analysis, we extracted 4 features, including TBNA, Weibull probability, lognormal probability, and exponential probability. These 4 features will be used later to model the prediction of the non-active state of machines.
Table 2 shows the 4 elements extracted from the reliability analysis.
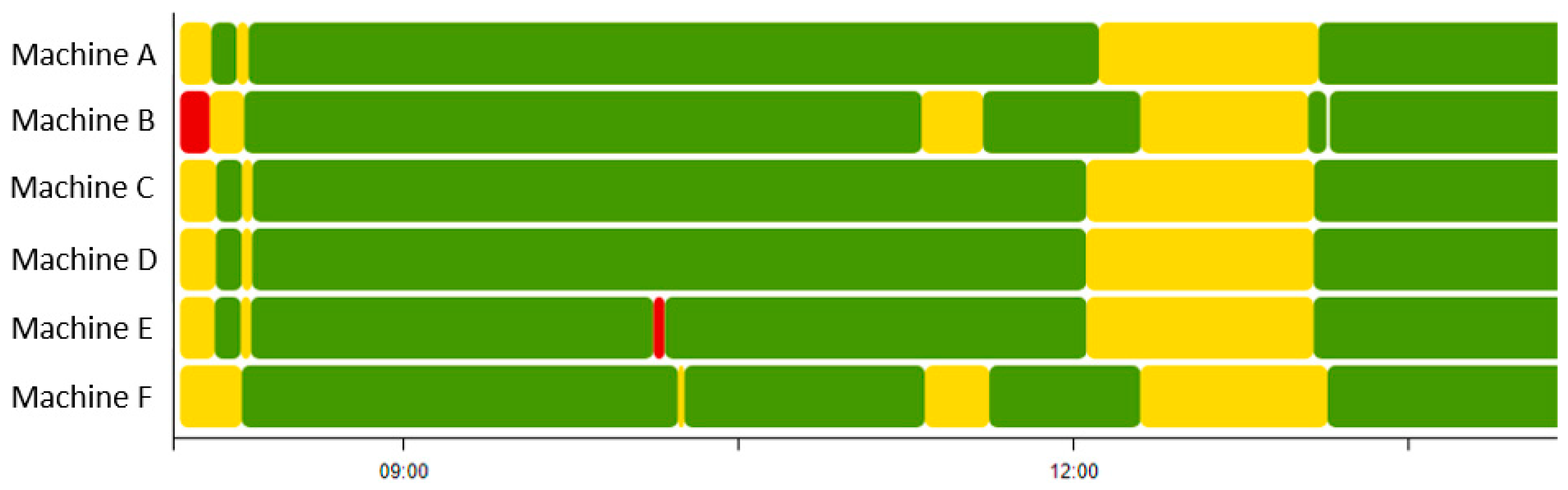
3.2.2. MSTV Features
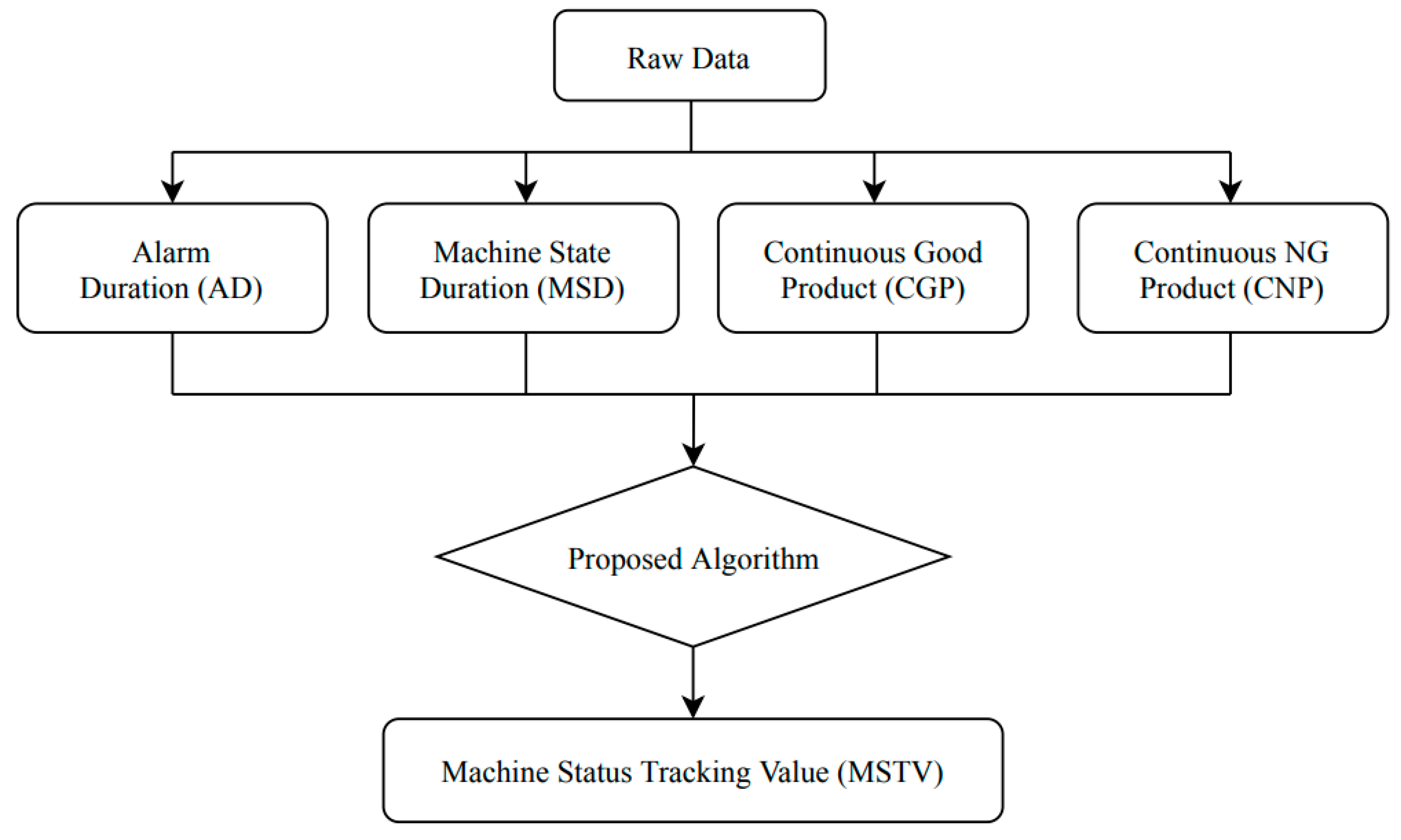
To distinguish the active and non-active patterns of the machine more effectively, we proposed a method to combine various essential factors from the raw dataset related, i.e., the alarm duration (AD), machine state duration (MSD), continuous good product (CGP), and continuous NG product (CNP) to extract new features that can learn the machine’s behavior during operation. We call these features an MSTV.
Figure 6 shows the architecture of the proposed feature extraction.
Kang et al. [
27] proposed the detection of significant arms using outlier detection algorithms, which indicated the importance of alarm for tracking the behavior of a machine, particularly during the occurrence of an unusual event. Hence, in this experiment, we retrieved the AD during operation as a combined feature for extracting the new useful feature. Meanwhile, the machine duration (MD) provided beneficial information for verifying the behavior of the machine because it indicated the time required by the machine to change from one state to another. Recall from
Section 3.1 that a machine can have the following 5 states: Run, wait, stop, offline, and manual, among which run and wait were considered as active states, and stop, offline and manual were considered as non-active states. The CGP means the number of high-quality products produced. The CNP was the quantity of poor-quality products produced.
Based on these 4 features, we define
MSTV as follows:
In Equation (7), , , and are weight values assigned to each factor, respectively. Here, the weight values indicate the importance of the factors that influence the non-active state of the machines. In this case, the importance was determined through discussions with the operators in the factory, and the most important factors were determined as the MSD, followed by the AD. Next was the number of normal products continuously and the number of abnormal products continuously produced by the machine. In consideration of these factors, in this paper, weights were given as 2, 3, 1.5, and 1, respectively.
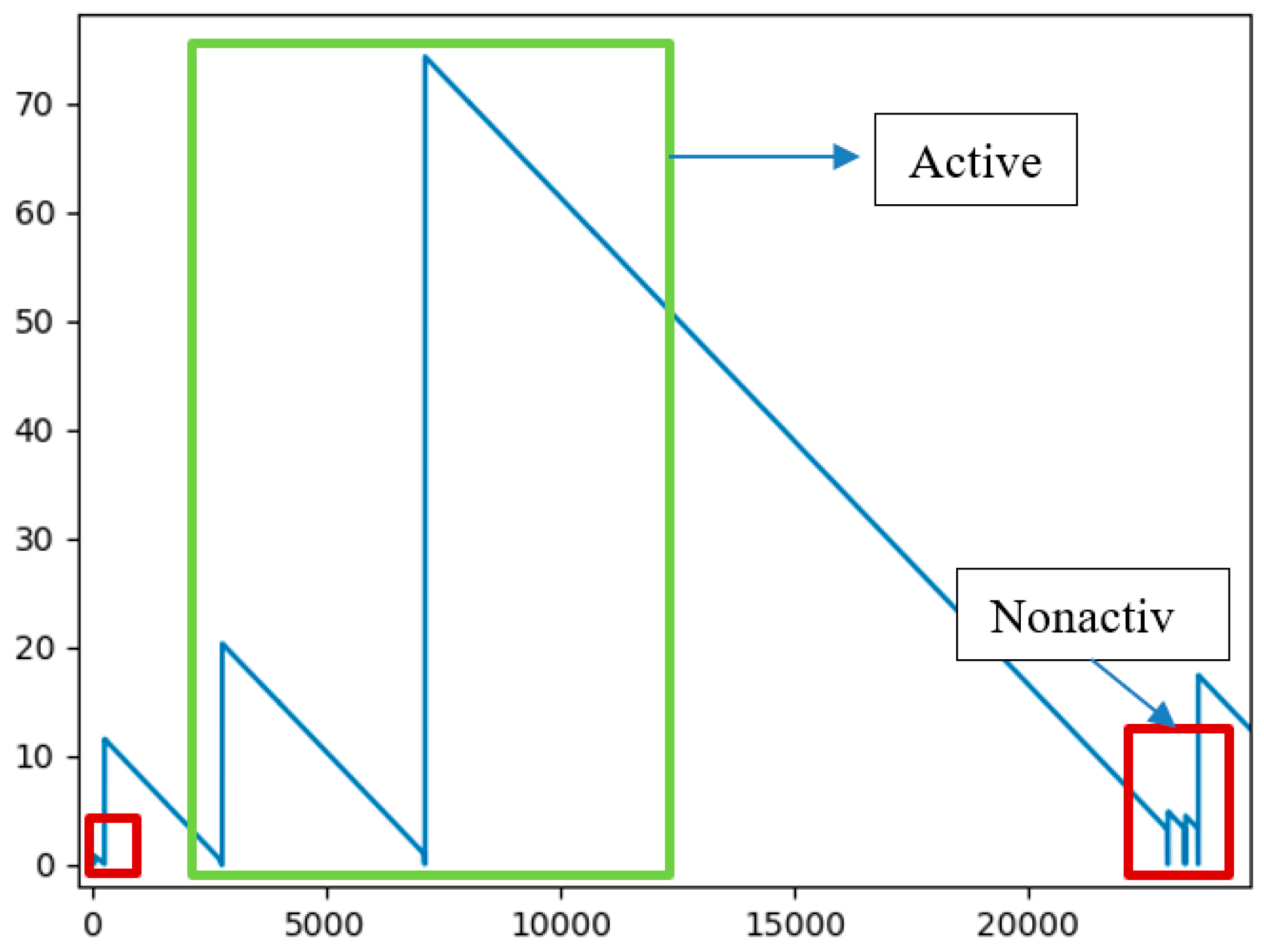
Figure 7 shows the results of MSTV feature extraction. In
Figure 7, the
x-axis indicated the elapsed time (in minutes) from which the machine was active, and the
y-axis indicated the probability of a non-active state of the machine obtained using MSTV in Equation (7). From the figure, we can observe that if the value was close to 0 (indicated in red rectangles), the probability of non-activation increased. On the other hand, we can see that the active state (green rectangle) occurred as the probability curve of MSTV goes higher. As shown in
Figure 7, after employing the proposed feature extraction approach to extract the MSTV, the patterns of the active and non-active states of the machine can be distinguished well by combining 4 indispensable elements from the raw dataset to extract new utilitarian features.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}