A Source Code Similarity Based on Siamese Neural Network



Abstract
:1. Introduction
- We construct a method that incorporates words statistical information in code snippets. This approach regulates the weight of each word to its corresponding sentence representation according to its contribution.
- We propose a siamese neural network that extracts semantic features by utilizing the similarity among source codes and makes code snippets with similar function mapped into similar vectors.
2. Related Work
2.1. Source Code Similarity
2.2. Source Code Representation
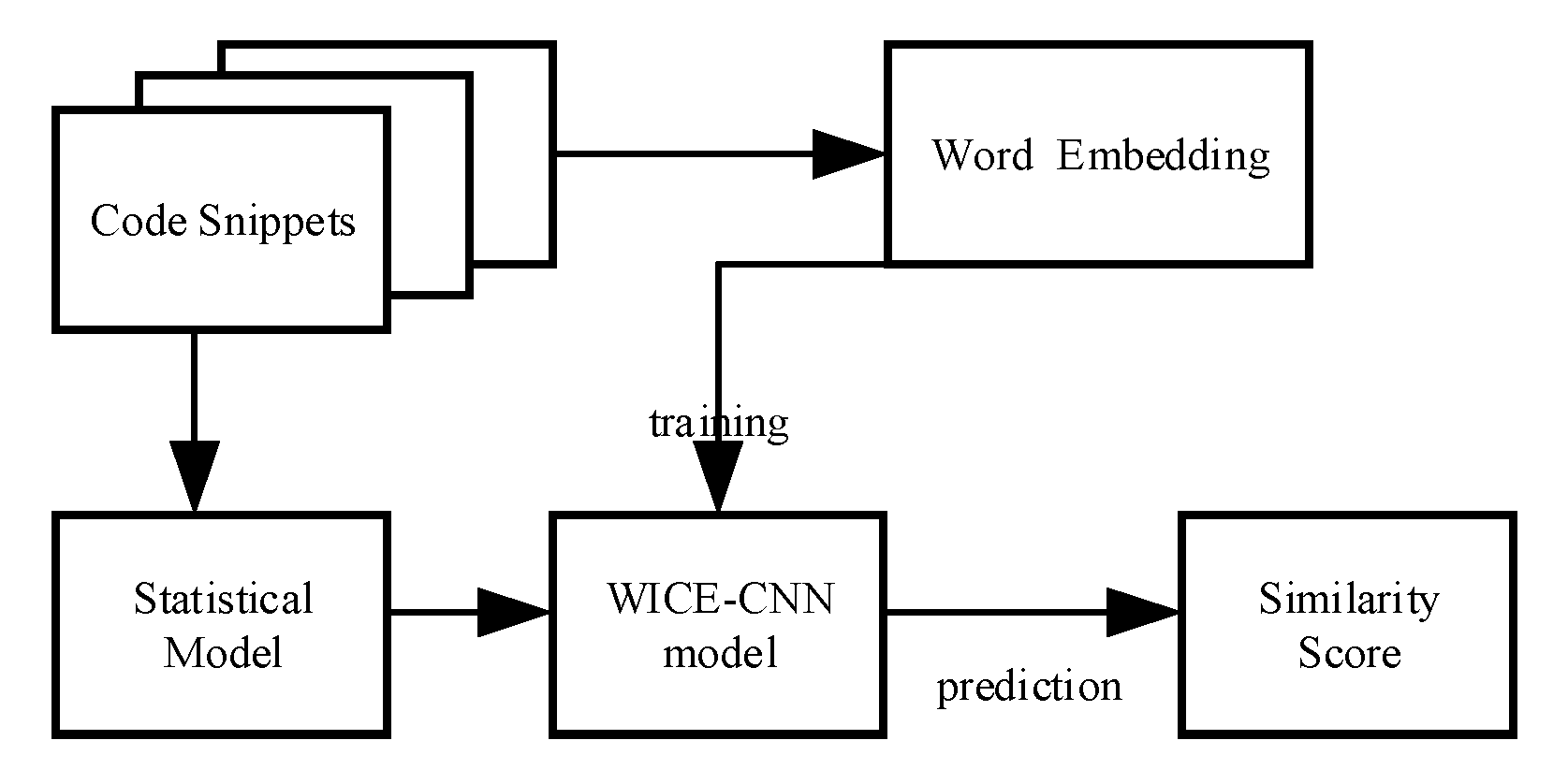
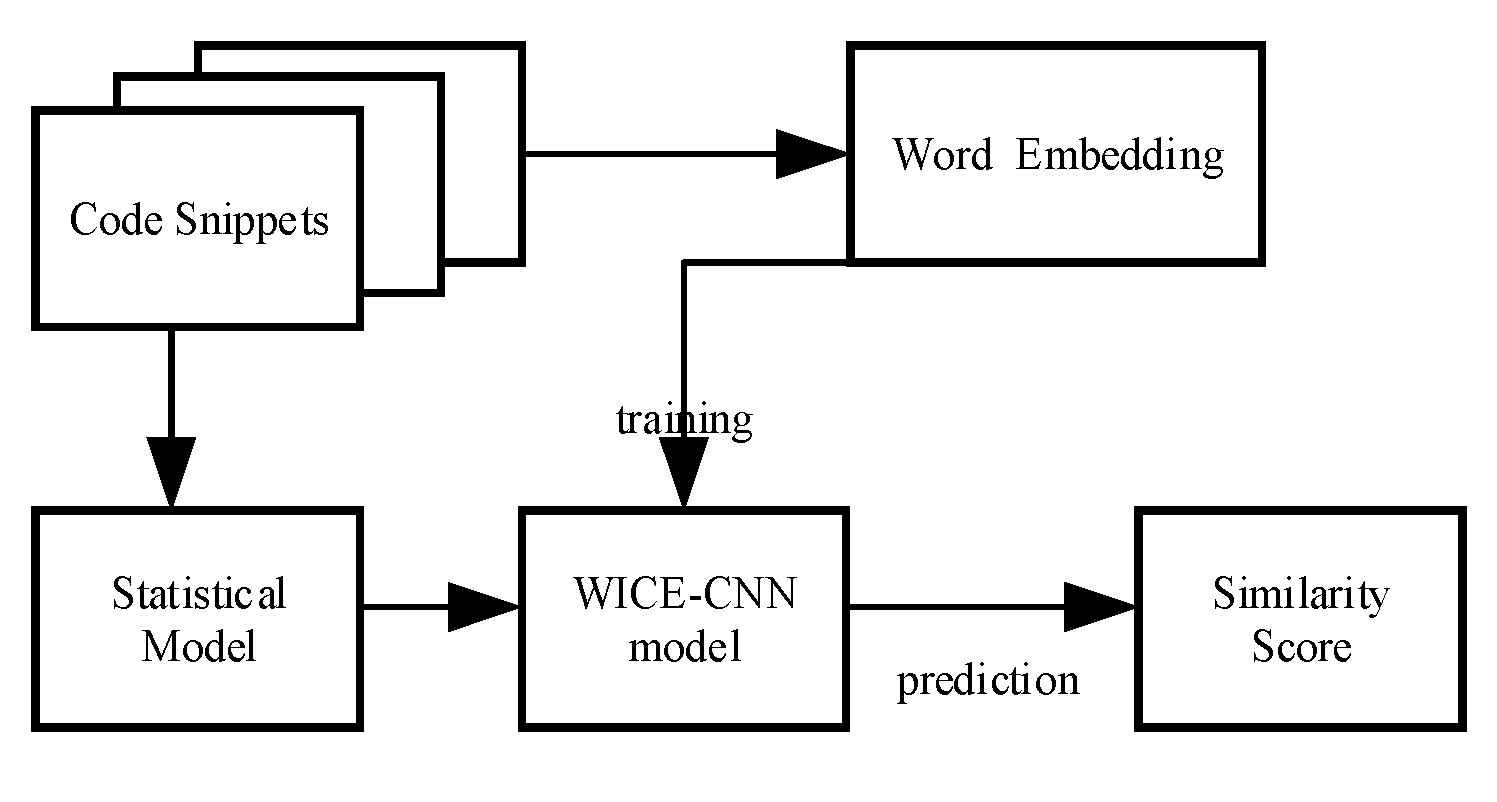
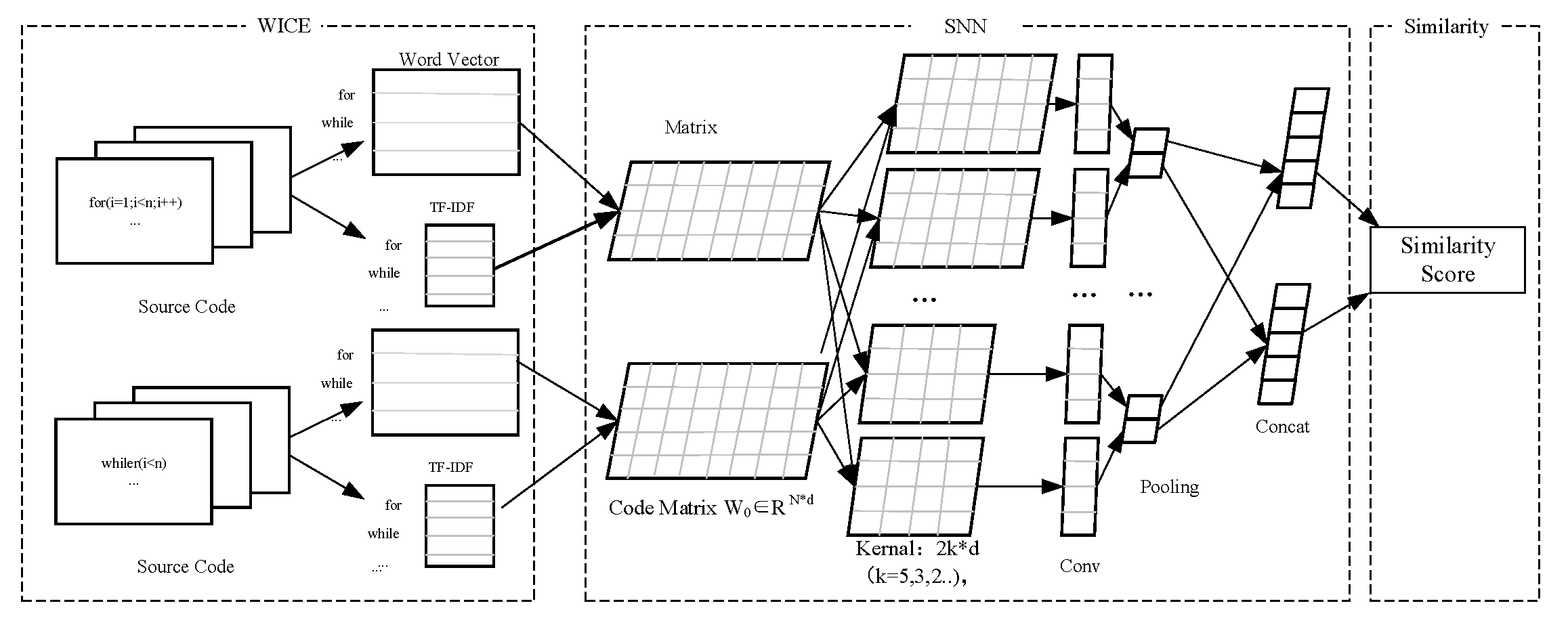
3. WICE-SNN Framework
3.1. Definition of Source Code Similarity
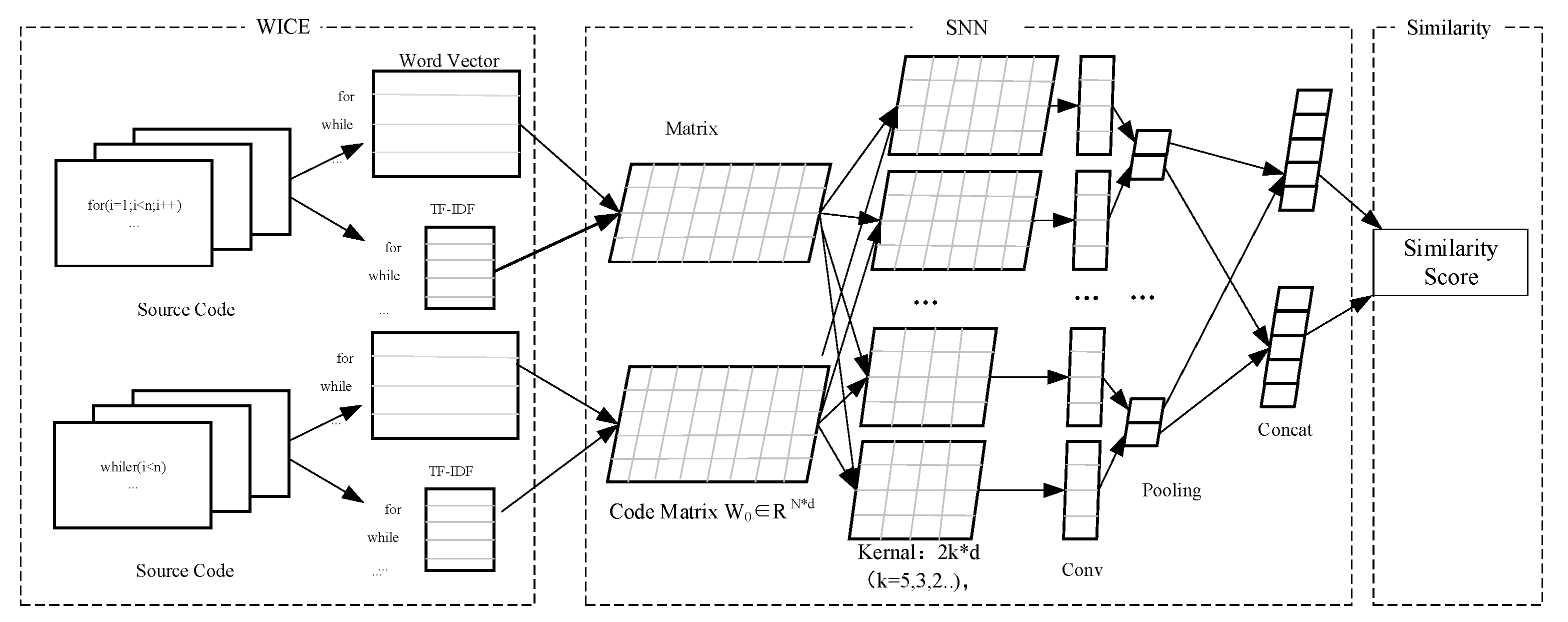
3.2. Details of WICE-SNN
3.2.1. WICE Layer
3.2.2. SNN Layer
3.2.3. Similarity Score Layer
4. Experiments
4.1. Dataset
4.2. Implementation and Comparisons
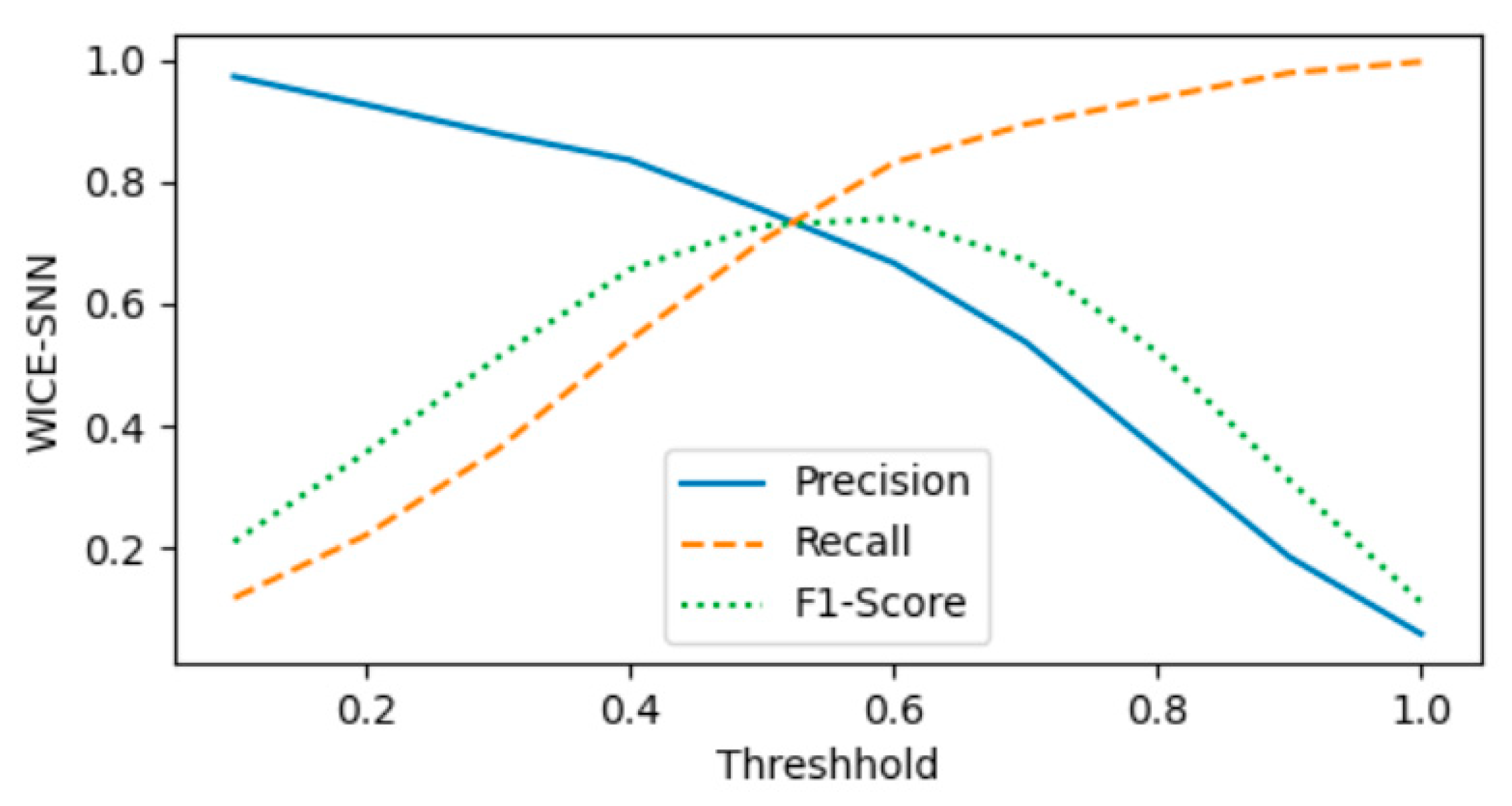
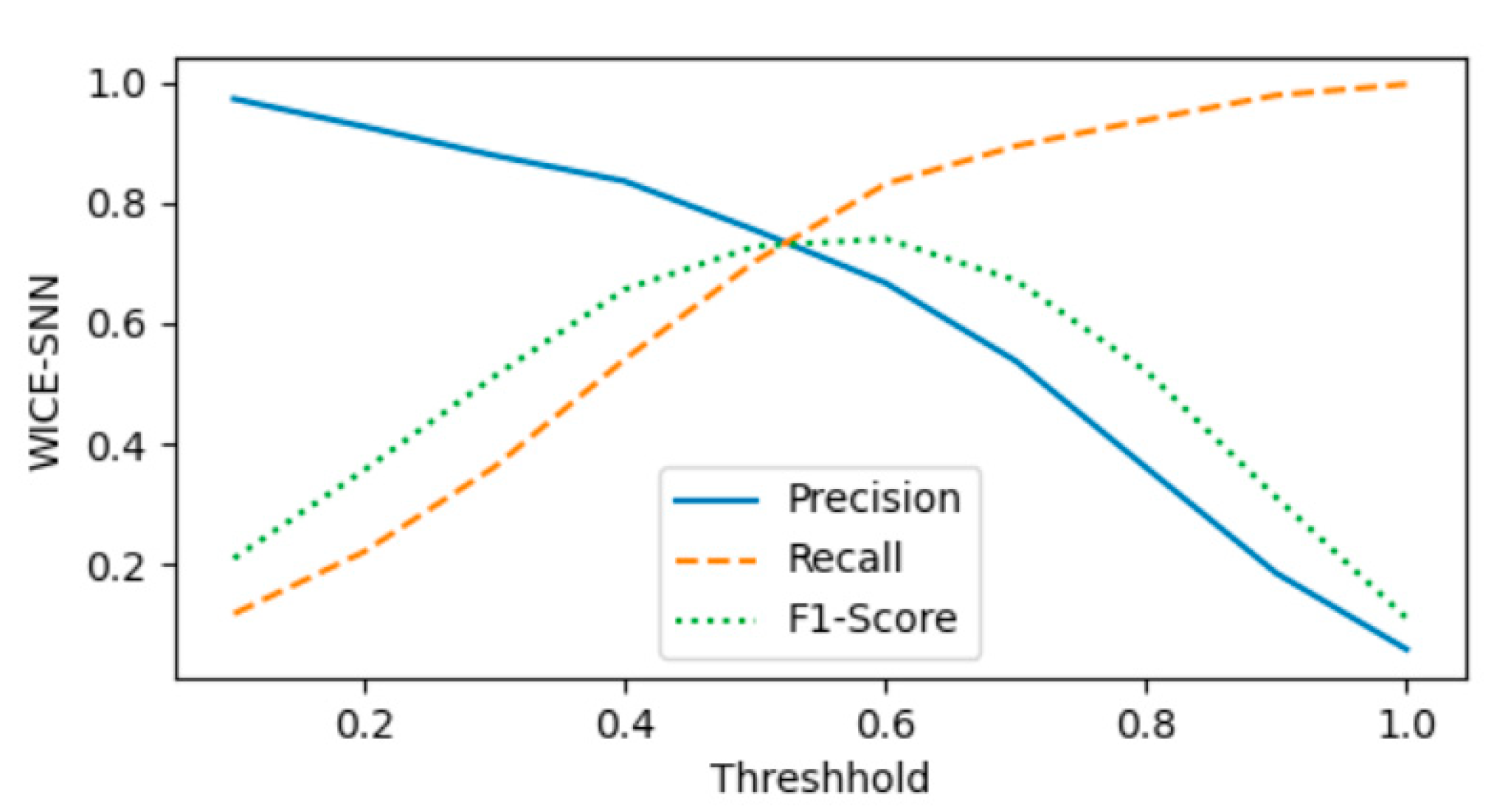
4.3. Experimental Results
5. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Word2Vec | 0.79 | 0.42 | 0.55 |
| WICE | 0.69 | 0.60 | 0.64 |
| N-gram | 0.71 | 0.59 | 0.63 |
| Code2Vec | 0.69 | 0.56 | 0.62 |
| WICE-SNN | 0.67 | 0.83 | 0.74 |
References
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef] [Green Version]
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and evaluation of clone detection tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Chen, C.; Han, J.; Yu, P.S. GPLAG: Detection of software plagiarism by program dependence graph analysis. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; Association for Computing Machinery ACM: New York, NY, USA, 2006; pp. 872–881. [Google Scholar] [CrossRef]
- Cosma, G.; Joy, M. Towards a definition of source-code plagiarism. IEEE Trans. Educ. 2008, 51, 195–200. [Google Scholar] [CrossRef]
- Cosma, G.; Joy, M. An approach to source-code plagiarism detection and investigation using latent semantic analysis. IEEE Trans. Comput. 2011, 61, 379–394. [Google Scholar] [CrossRef]
- Mens, K.; Lozano, A. Source Code-Based Recommendation Systems, Recommendation Systems in Software Engineering; Springer Science and Business Media LLC, Springer: Berlin/Heidelberg, Germany, 2014; pp. 93–130. [Google Scholar]
- Mcmillan, C.; Poshyvanyk, D.; Grechanik, M.; Xie, Q.; Chen, F. Portfolio: Searching for relevant functions and their usages in millions of lines of code. ACM Trans. Softw. Eng. Methodol. 2013, 22, 1–30. [Google Scholar] [CrossRef]
- Ragkhitwetsagul, C.; Krinke, J.; Clark, D. A comparison of code similarity analysers. Empir. Softw. Eng. 2017, 23, 2464–2519. [Google Scholar] [CrossRef] [Green Version]
- Roy, C.K.; Cordy, J.R. NICAD: Accurate detection of near-miss intentional clones using flexible pretty-printing and code normalization. In Proceedings of the 16th IEEE International Conference on Program Comprehension, Amsterdam, The Netherlands, 10–13 June 2008; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2008; Volume 2008, pp. 172–181. [Google Scholar] [CrossRef]
- Baxter, I.; Yahin, A.; Moura, L.; Sant’Anna, M.; Bier, L. Clone detection using abstract syntax trees. In Proceedings of the International Conference on Software Maintenance, ICSM 2003, Amsterdam, The Netherlands, 22–26 September 2003; Institute of Electrical and Electronics Engineers, IEEE: Piscataway, NJ, USA, 2002; Volume 2006, pp. 368–377. [Google Scholar] [CrossRef]
- Chae, D.K.; Ha, J.; Kim, S.W.; Kang, B.J.; Im, E.G. Software plagiarism detection: A graph-based approach. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. CIKM 2013, San Francisco, CA, USA, 27 October–1 November 2013; Association for Computing Machinery ACM: New York, NY, USA, 2013; pp. 1577–1580. [Google Scholar] [CrossRef]
- Hindle, A.; Barr, E.T.; Su, Z.; Gabel, M.; Devanbu, P. On the naturalness of software. In Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2012; Volume 2012, pp. 837–847. [Google Scholar] [CrossRef]
- Karaivanov, S.; Raychev, V.; Vechev, M. Phrase-Based statistical translation of programming languages. In Proceedings of the 2014 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software-Onward! ’14; ACM 2014, Portland, OR, USA, 20–24 October 2014; Association for Computing Machinery ACM: New York, NY, USA, 2014; Volume 2014, pp. 173–184. [Google Scholar] [CrossRef]
- Raychev, V.; Vechev, M.; Yahav, E. Code completion with statistical language models. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, Edinburgh, UK, 9–11 June 2014; Association for Computing Machinery ACM: New York, NY, USA, 2014; Volume 49, pp. 419–428. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Nguyen, T.T.; Nguyen, T.N. Divide-and-Conquer approach for multi-phase statistical migration for source code (T). In Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2015; pp. 585–596. [Google Scholar] [CrossRef]
- Zhang, F.Y.; Peng, X.; Chen, C.; Zhao, W.Y. Research on Code Analysis based on Deep Learning. Comput. Appl. Softw. 2018, 35, 15–23. (In Chinese) [Google Scholar]
- Chen, Q.Y.; Li, S.P.; Yan, M.; Xia, X. Code clone detection: A literature review. J. Softw. 2019, 30, 962–980. (In Chinese) [Google Scholar]
- Tufano, M.; Watson, C.; Gabriele, B.; Di, P.; White, M.; Poshyvanyk, D. Deep learning similarities from different representations of source code. In Proceedings of the 15th International Conference on Mining Software Repositories, Gothenburg, Sweden, 28–29 May 2018; pp. 542–553. [Google Scholar] [CrossRef]
- Hellendoorn, V.J.; Devanbu, P. Are deep neural networks the best choice for modeling source code? In Proceedings of the 11th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2017, Paderborn, Germany, 4–8 September 2017; Association for Computing Machinery, ACM: New York, NY, USA, 2017; pp. 763–773. [Google Scholar] [CrossRef]
- Halstead, M.H. Elements of Software Science; Elsevier North-Holland: New York, NY, USA, 1977. [Google Scholar]
- Komondoor, R.; Horwitz, S. Using slicing to identify duplication in source code. In International Static Analysis Symposium, Lecture Notes in Computer Science; Springer Science and Business Media LLC, Springer: Berlin/Heidelberg, Germany, 2001; pp. 40–56. [Google Scholar]
- Ignacio, A.F.; Carlos Francisco, M.; Gerardo, S.; Juan Manuel, T.M.; Grigori, S. Unsupervised Sentence Representations as Word Information Series: Revisiting TF-IDF. Comput. Speech Lang. 2019, 56, 107–129. [Google Scholar] [CrossRef] [Green Version]
- He, X.F.; Ai, J.L.; Song, Z.T. Multi-Source data fusion for health monitoring of unmanned aerial vehicle structures. Appl. Math. Mech. 2018, 39, 395–402. (In Chinese) [Google Scholar]
- Nguyen, A.T.; Nguyen, T.D.; Phan, H.D.; Nguyen, T.N. A deep neural network language model with contexts for source code. In Proceedings of the IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER), Campobasso, Italy, 20–23 March 2018; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2018; pp. 323–334. [Google Scholar] [CrossRef]
- Ottenstein, K.J. An algorithmic approach to the detection and prevention of plagiarism. ACM SIGCSE Bull. 1976, 8, 30–41. [Google Scholar] [CrossRef] [Green Version]
- White, M.; Tufano, M.; Vendome, C.; Poshyvanyk, D. Deep learning code fragments for code clone detection. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, ASE 2016, Singapore, 3–7 September 2016; Association for Computing Machinery ACM: New York, NY, USA, 2016; pp. 87–98. [Google Scholar] [CrossRef]
- Lam, A.N.; Nguyen, A.T.; Nguyen, H.A.; Nguyen, T.N. Combining deep learning with information retrieval to localize buggy files for bug reports (N). In Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2015; Volume 2015, pp. 476–481. [Google Scholar] [CrossRef]
- Huo, X.; Thung, F.; Li, M.; Lo, D.; Shi, S.-T. Deep Transfer Bug Localization. IEEE Trans. Softw. Eng. 2019, 99, 1. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, CA, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 26, pp. 3111–3119. [Google Scholar]
- Ye, X.; Shen, H.; Ma, X.; Bunescu, R.; Liu, C. From word embeddings to document similarities for improved information retrieval in software engineering. In Proceedings of the 38th International Conference on Software Engineering, ICSE ’16, Austin, TX, USA, 14–22 May 2016; Association for Computing Machinery ACM: New York, NY, USA, 2016; pp. 404–415. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Nguyen, A.T.; Phan, H.D.; Nguyen, T.N. Exploring API embedding for API usages and applications. In Proceedings of the IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2017; Volume 2017, pp. 438–449. [Google Scholar] [CrossRef]
- Chen, C.; Xing, Z.; Wang, X. Unsupervised software-specific morphological forms inference from informal discussions. In Proceedings of the IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2017; pp. 450–461. [Google Scholar] [CrossRef]
- Peng, H.; Mou, L.; Li, G.; Liu, Y.; Zhang, L.; Jin, Z. Building program vector representations for deep learning. In International Conference on Knowledge Science, Engineering and Management; Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2015; Volume 9403, pp. 547–553. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Li, G.; Jin, Z.; Zhang, L.; Wang, T. Convolutional neural network over tree structure for programming language processing. In Proceedings of the 30th AAAI Conference on Artifical Intelligence, Menlo Park, CA, USA, 12–17 February 2016; pp. 1287–1293. [Google Scholar] [CrossRef]
- White, M.; Tufano, M.; Martinez, M.; Monperrus, M.; Poshyvanyk, D. Sorting and transforming program repair ingredients via deep learning code similarities. In Proceedings of the IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), Hangzhou, China, 24–27 February 2019; Institute of Electrical and Electronics Engineers IEEE: Piscataway, NJ, USA, 2019; pp. 479–490. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Liu, T.; Tan, L. Automatically learning semantic features for defect prediction. In Proceedings of the 38th International Conference on Software Engineering-ICSE ’16, Austin, TX, USA, 14–22 May 2016; Association for Computing Machinery ACM: New York, NY, USA, 2016; pp. 297–308. [Google Scholar] [CrossRef]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. Code2vec: Learning distributed representations of code. In Proceedings of the ACM on Programming Languages; Association for Computing Machinery ACM: New York, NY, USA, 2019; Volume 3, pp. 1–29. [Google Scholar] [CrossRef] [Green Version]
- Github. Available online: https://github.com/tech-srl/code2vec (accessed on 1 November 2019).



| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Word2Vec | 0.79 | 0.42 | 0.55 |
| WICE | 0.69 | 0.60 | 0.64 |
| N-gram | 0.71 | 0.59 | 0.63 |
| Code2Vec | 0.69 | 0.56 | 0.62 |
| WICE-SNN | 0.67 | 0.83 | 0.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, C.; Wang, X.; Qian, C.; Wang, M. A Source Code Similarity Based on Siamese Neural Network. Appl. Sci. 2020, 10, 7519. https://doi.org/10.3390/app10217519
Xie C, Wang X, Qian C, Wang M. A Source Code Similarity Based on Siamese Neural Network. Applied Sciences. 2020; 10(21):7519. https://doi.org/10.3390/app10217519
Chicago/Turabian StyleXie, Chunli, Xia Wang, Cheng Qian, and Mengqi Wang. 2020. "A Source Code Similarity Based on Siamese Neural Network" Applied Sciences 10, no. 21: 7519. https://doi.org/10.3390/app10217519
APA StyleXie, C., Wang, X., Qian, C., & Wang, M. (2020). A Source Code Similarity Based on Siamese Neural Network. Applied Sciences, 10(21), 7519. https://doi.org/10.3390/app10217519