A Data Augmentation Method for Deep Learning Based on Multi-Degree of Freedom (DOF) Automatic Image Acquisition

Abstract
:1. Introduction
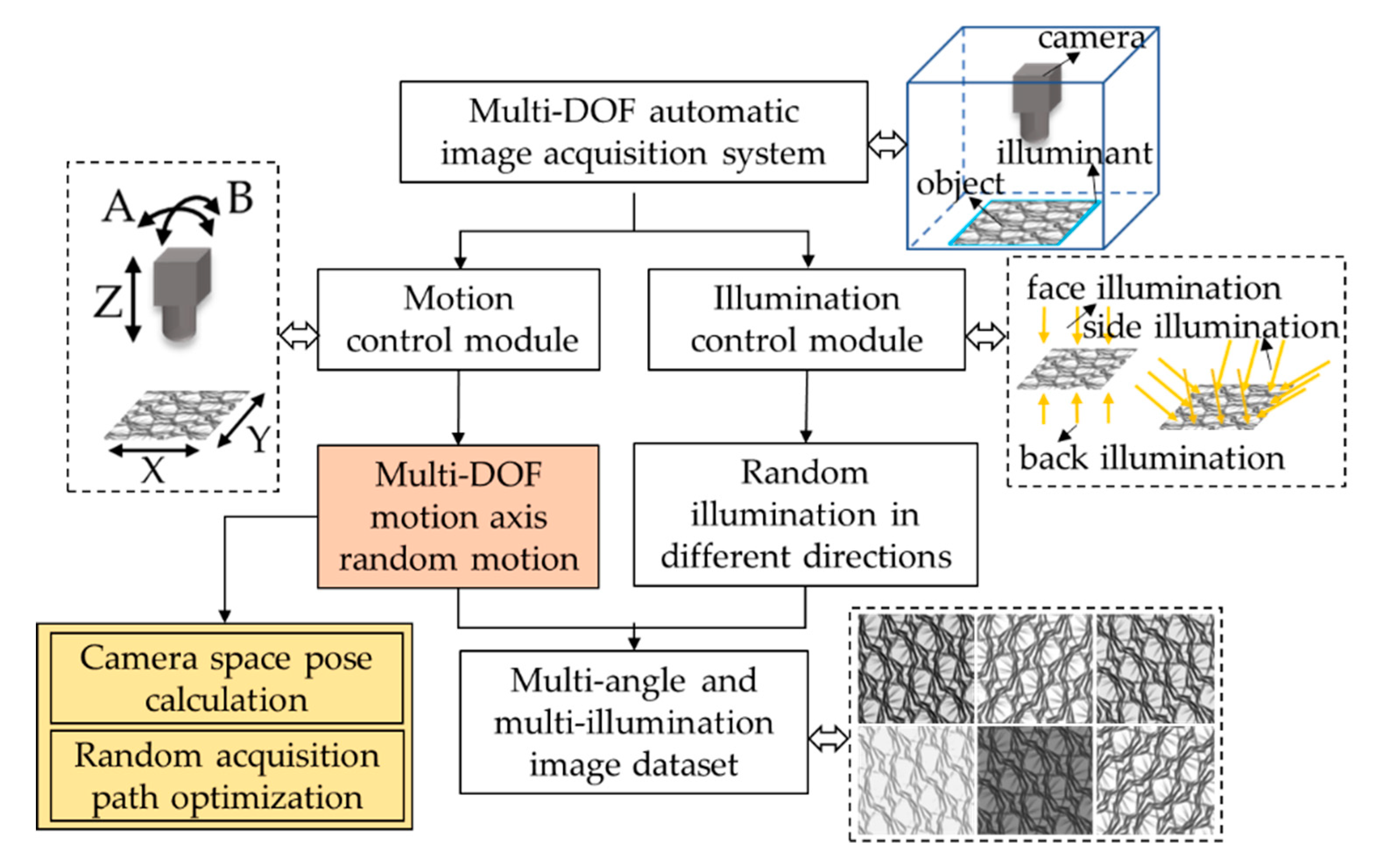
2. The Method of Multi-DOF Image Automatic Acquisition
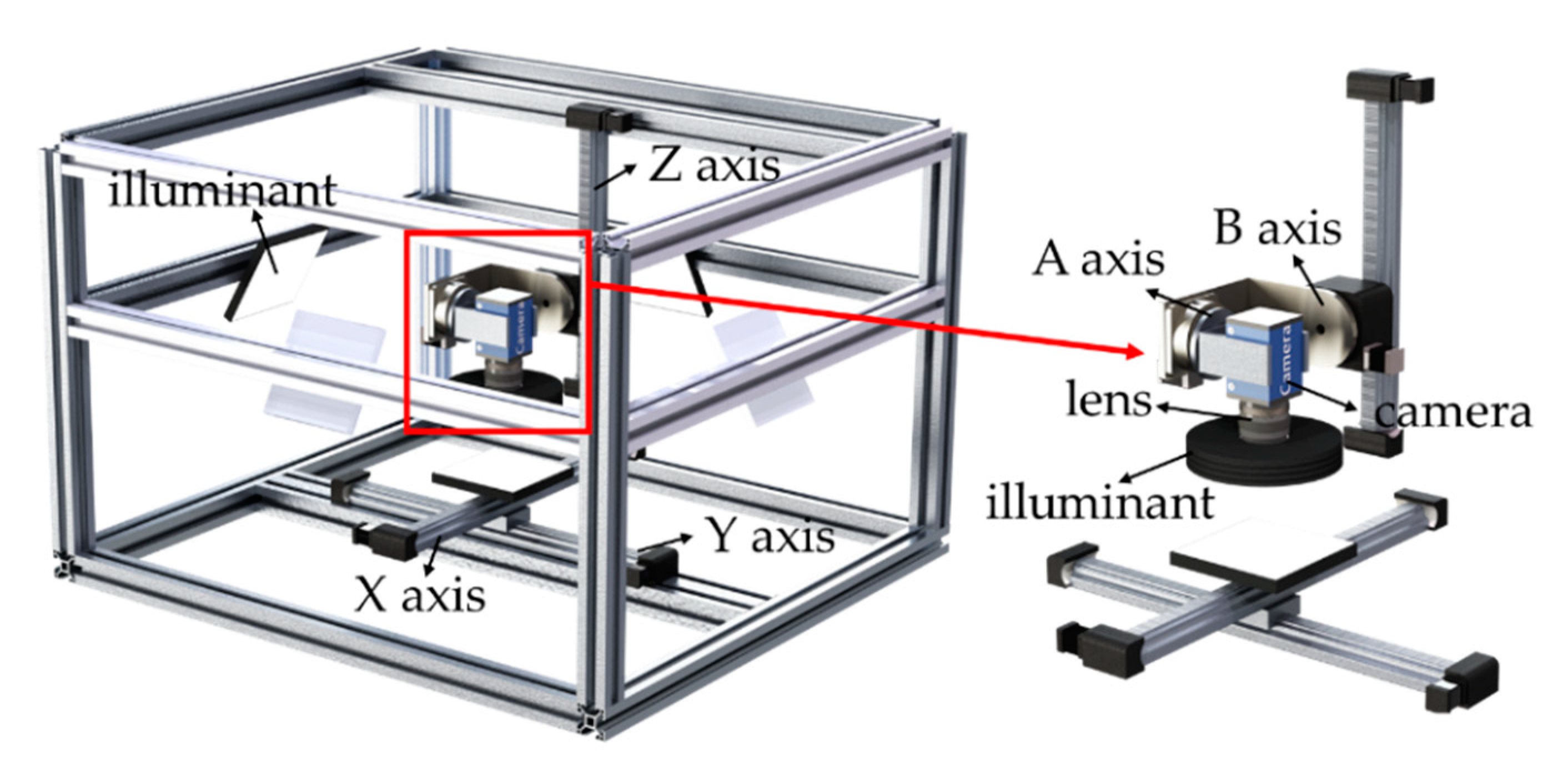
2.1. The Design of System Architecture
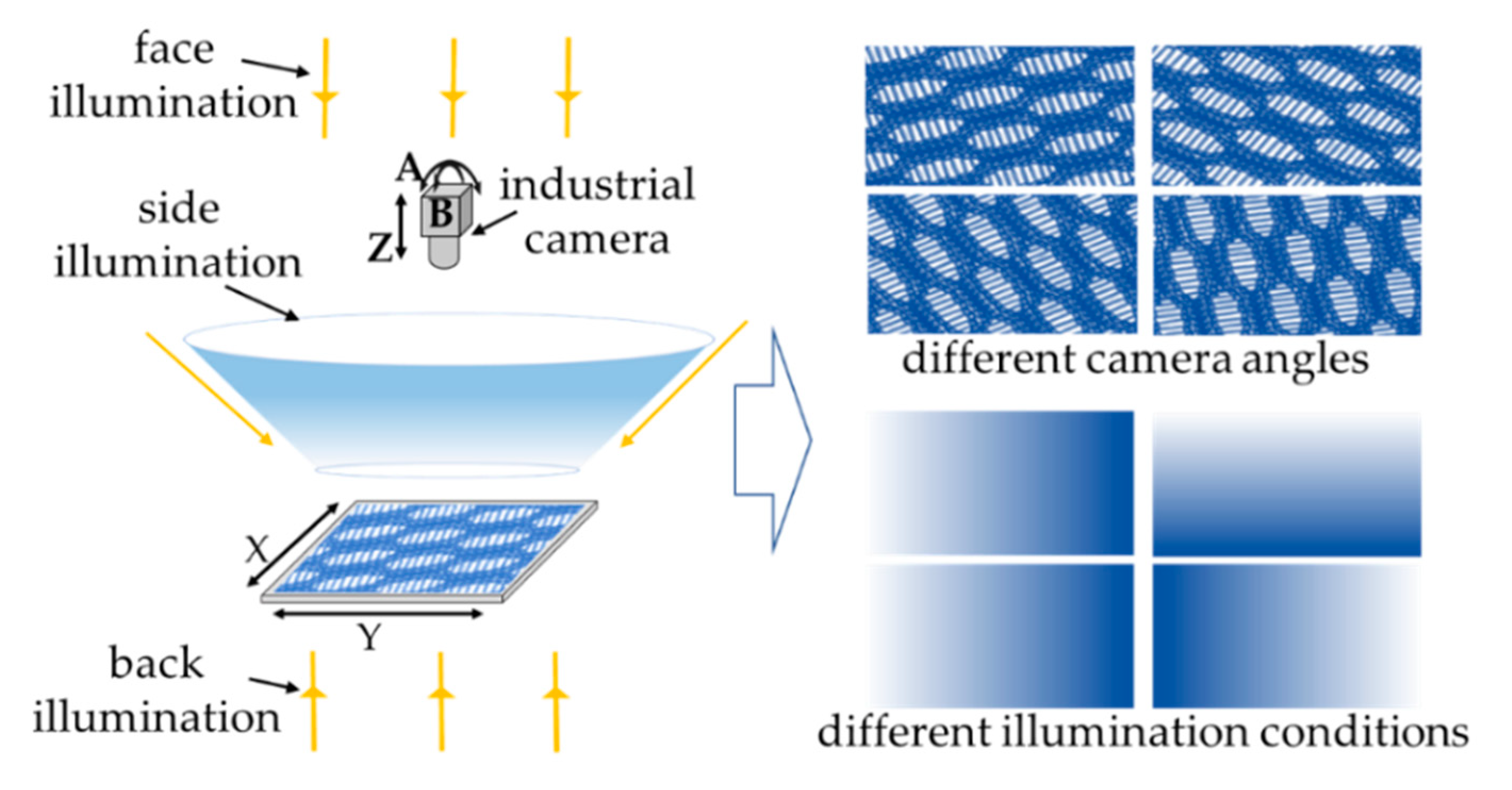
2.2. The Process of System Acquisition
3. The key Technology of the Multi-DOF Automatic Image Acquisition System
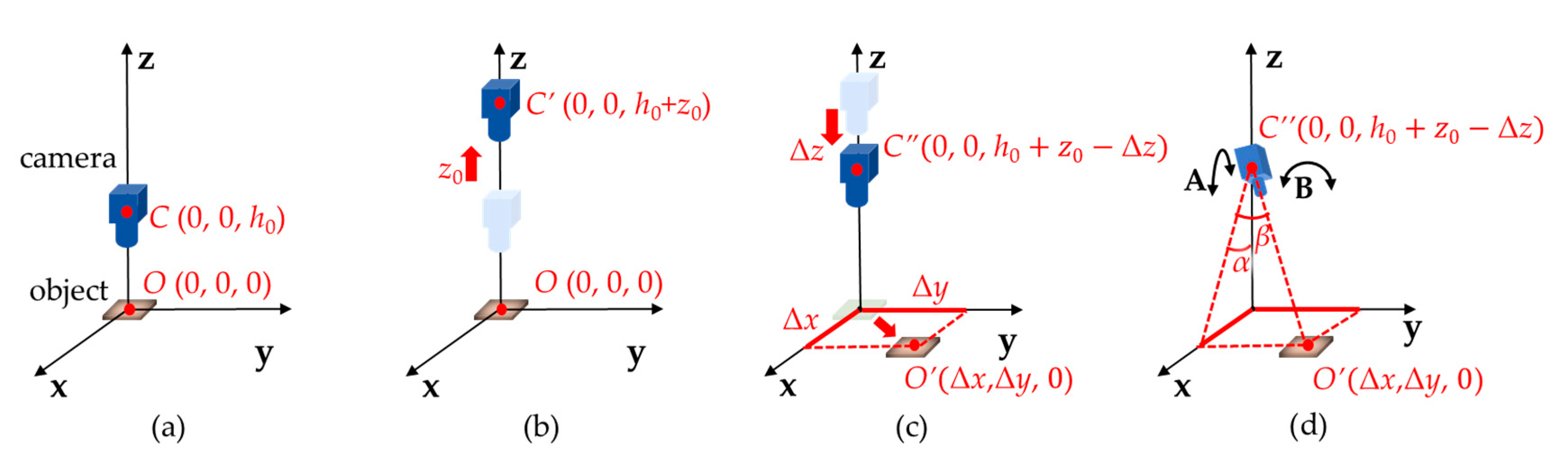
3.1. The Calculation of Camera Position
3.1.1. Camera Position Calculating Method by Mathematical Modeling
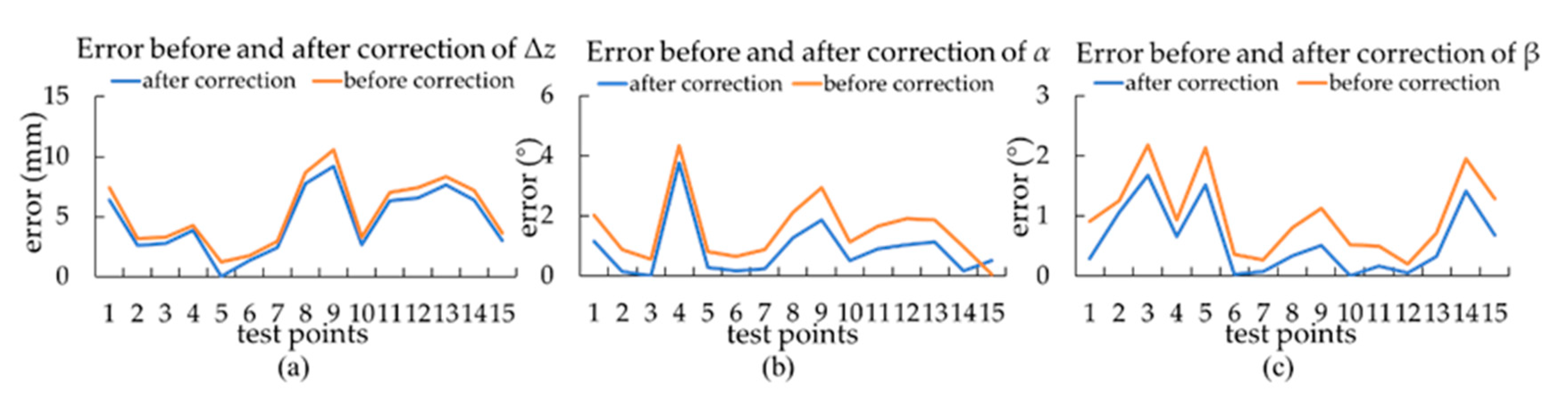
3.1.2. Camera Position Calculating Method by Data Fitting
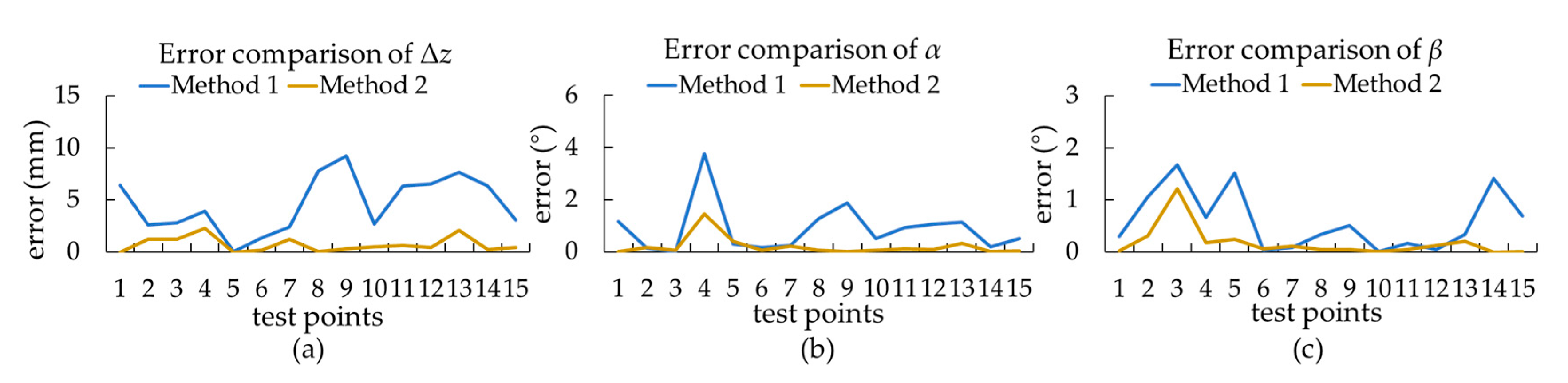
3.1.3. Comparison of the Two Methods
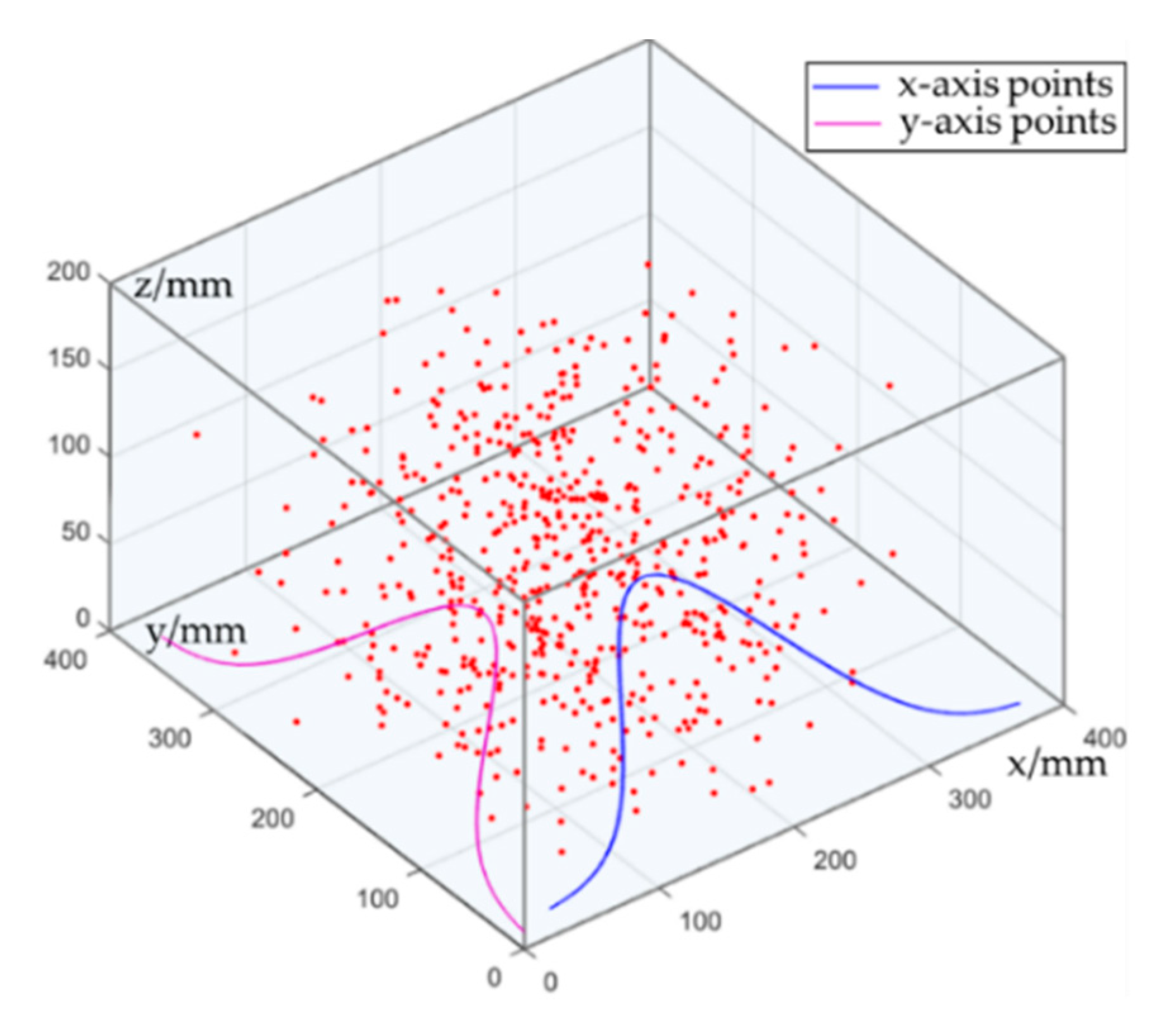
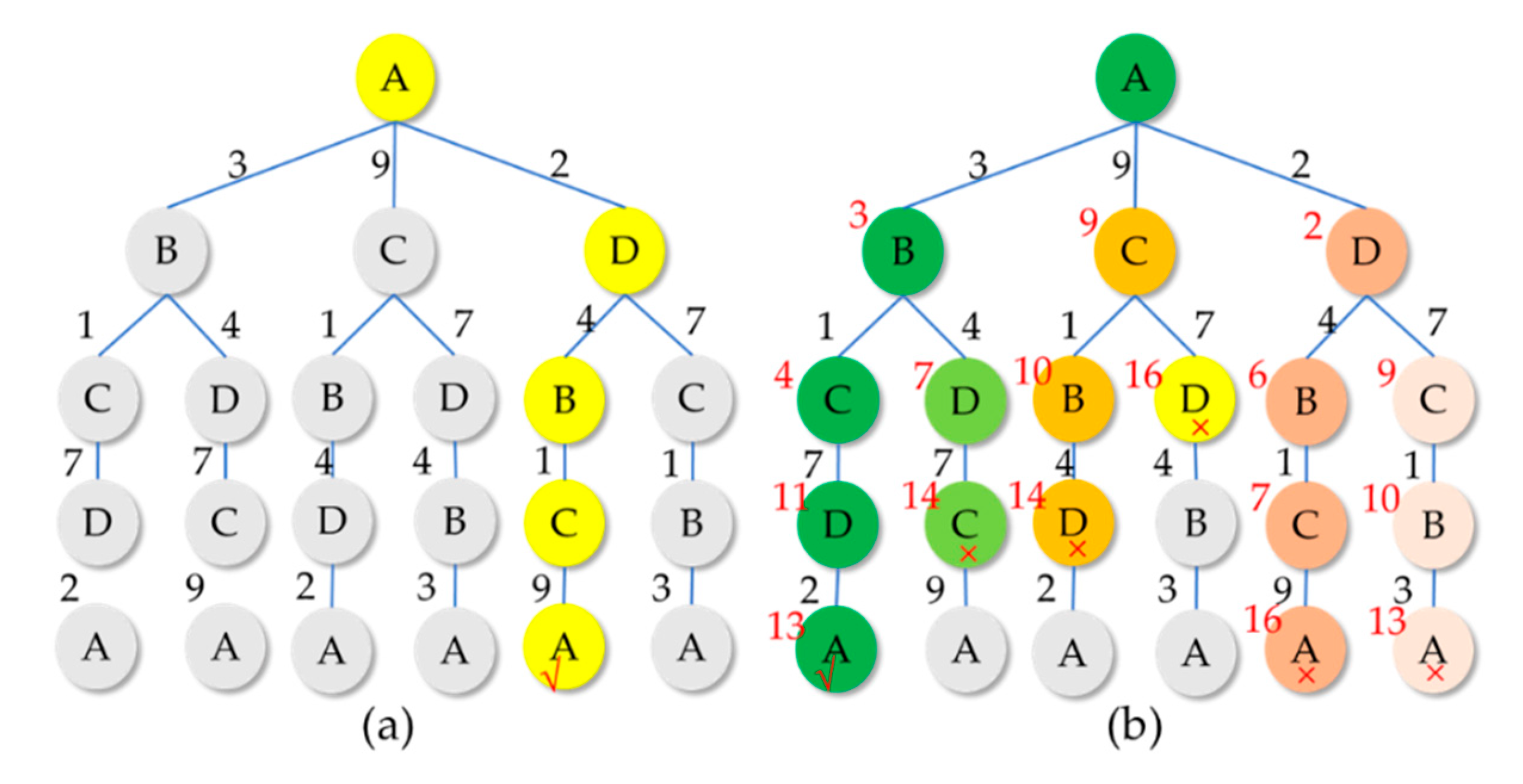
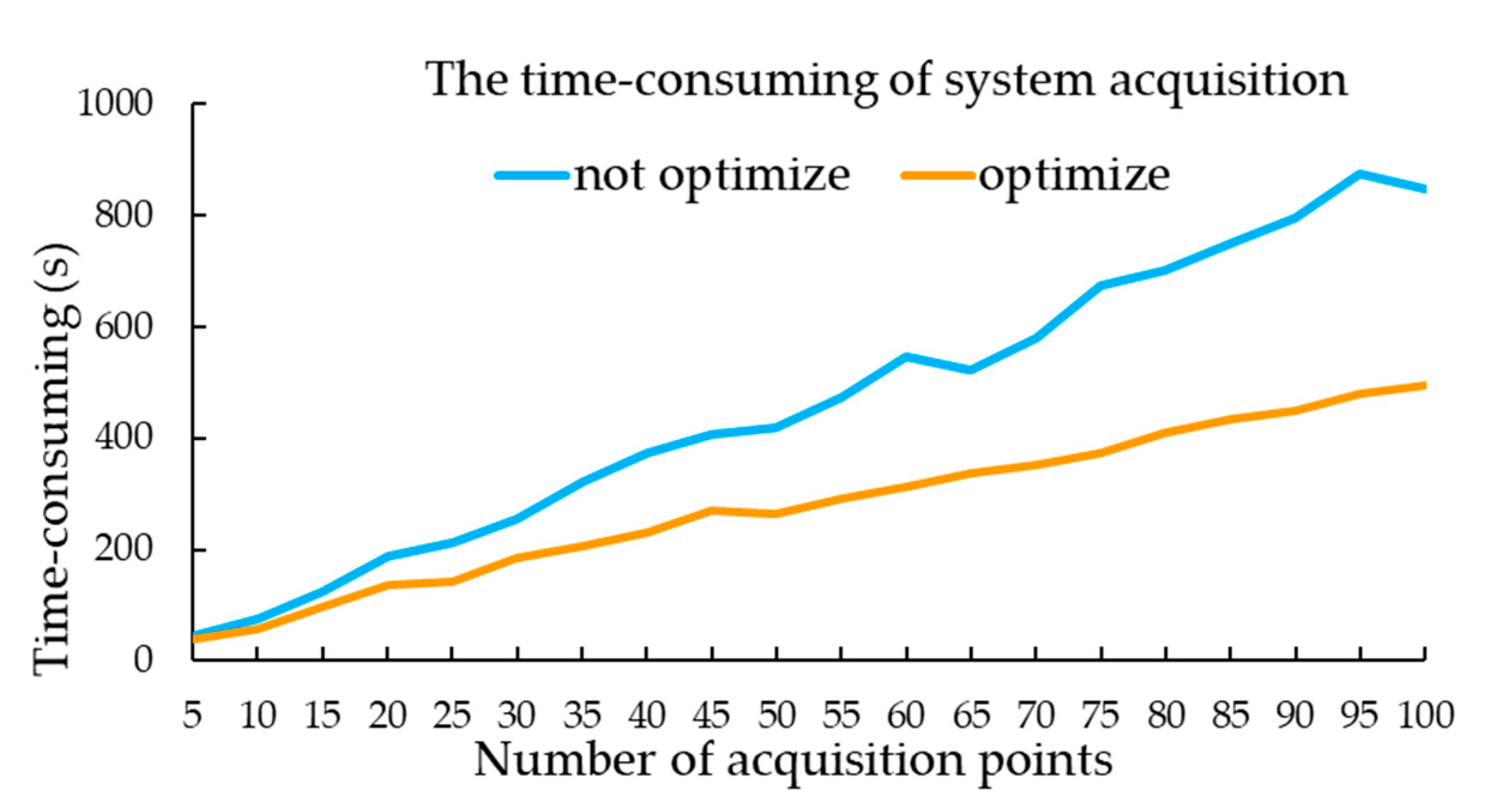
3.2. Random Acquisition Path Optimization
4. Experiments and Discussions
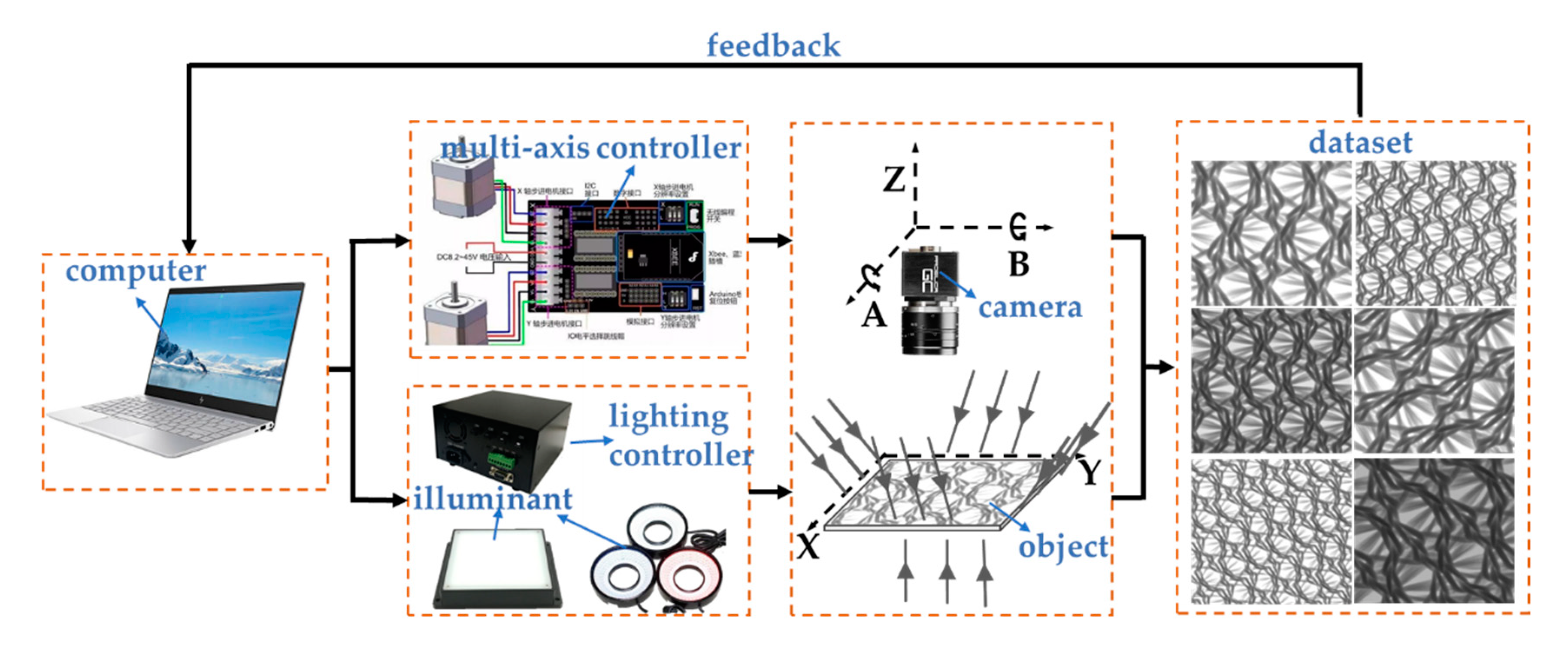
4.1. Construction of Multi-DOF Automatic Image Acquisition System
4.2. Image Acquisition Experiment
4.2.1. Image Acquisition by the System
4.2.2. Collect Images Manually
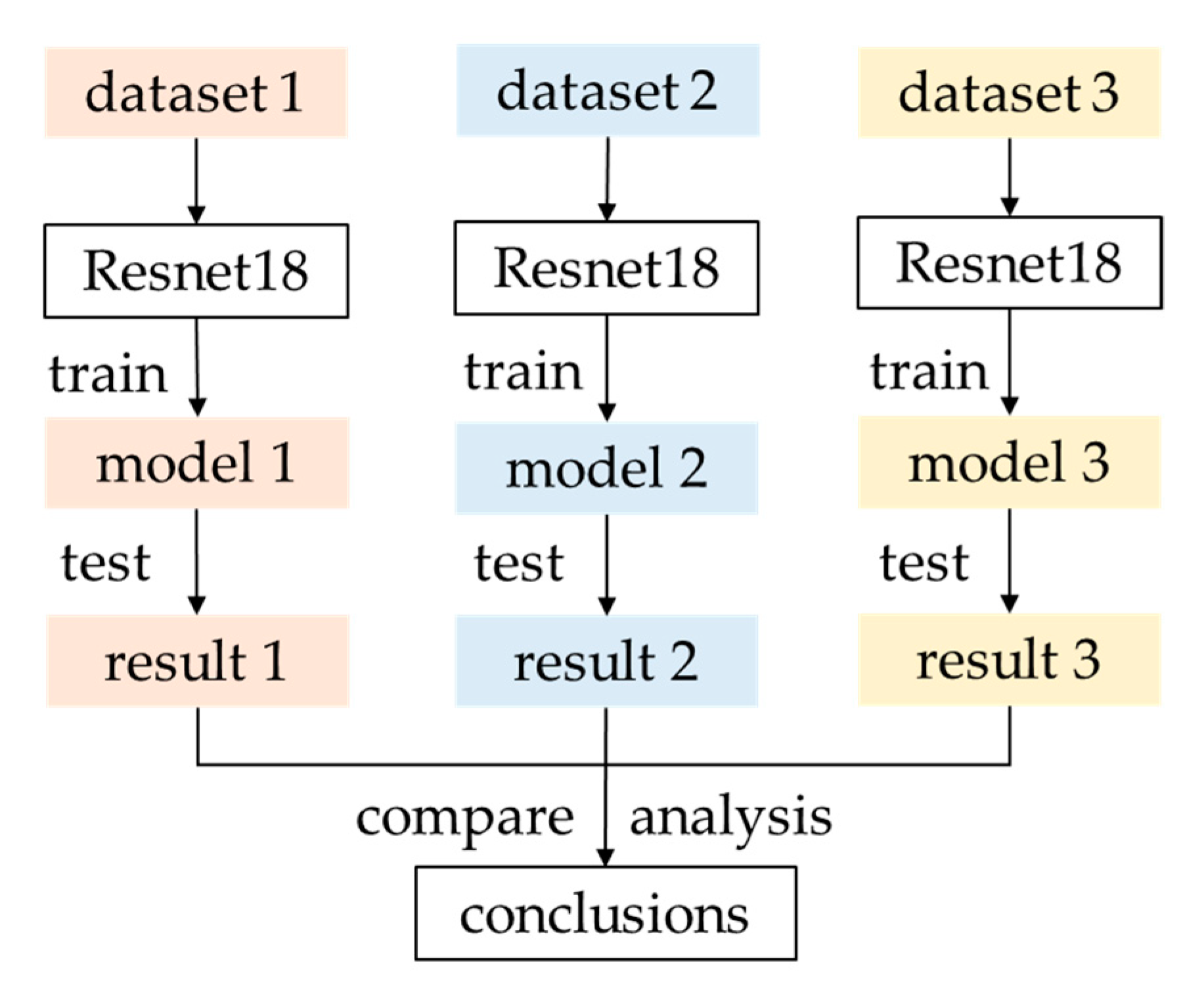
4.3. Datasets Comparison Experiment
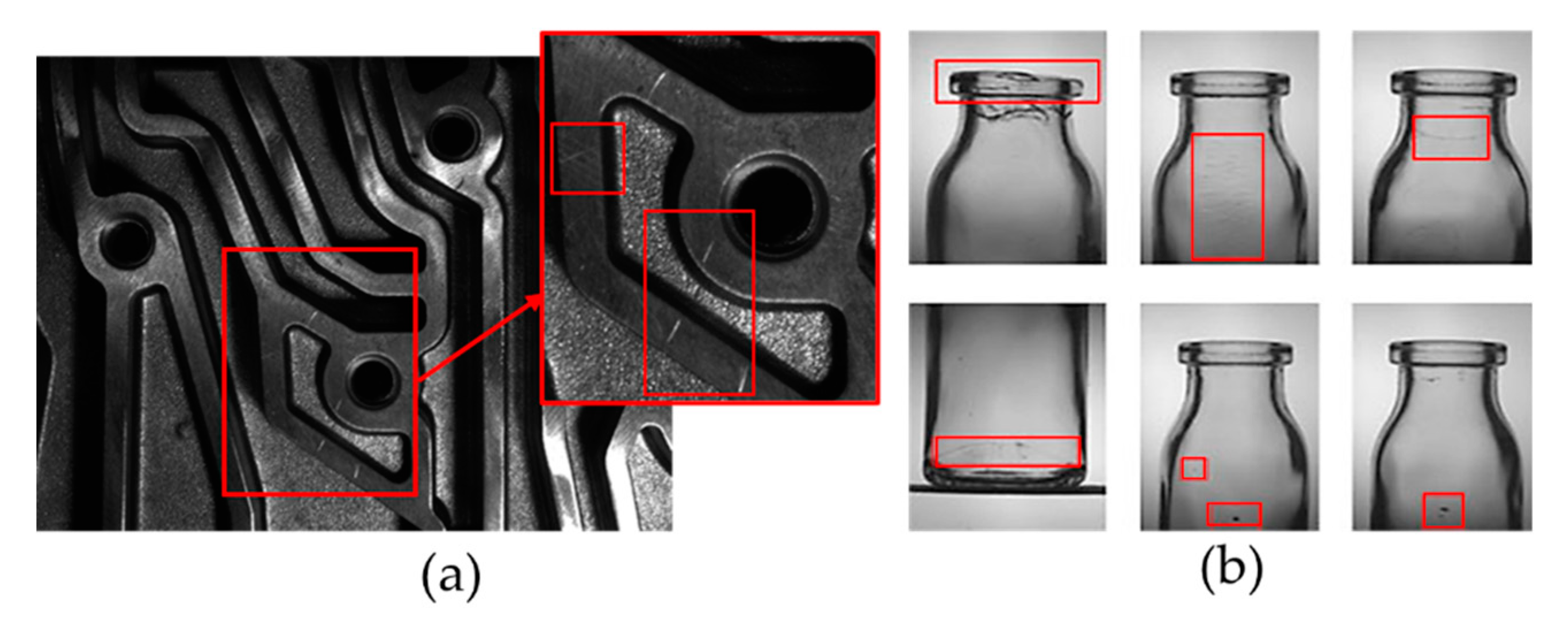
4.3.1. Experiment Description
4.3.2. Test Datasets Composition
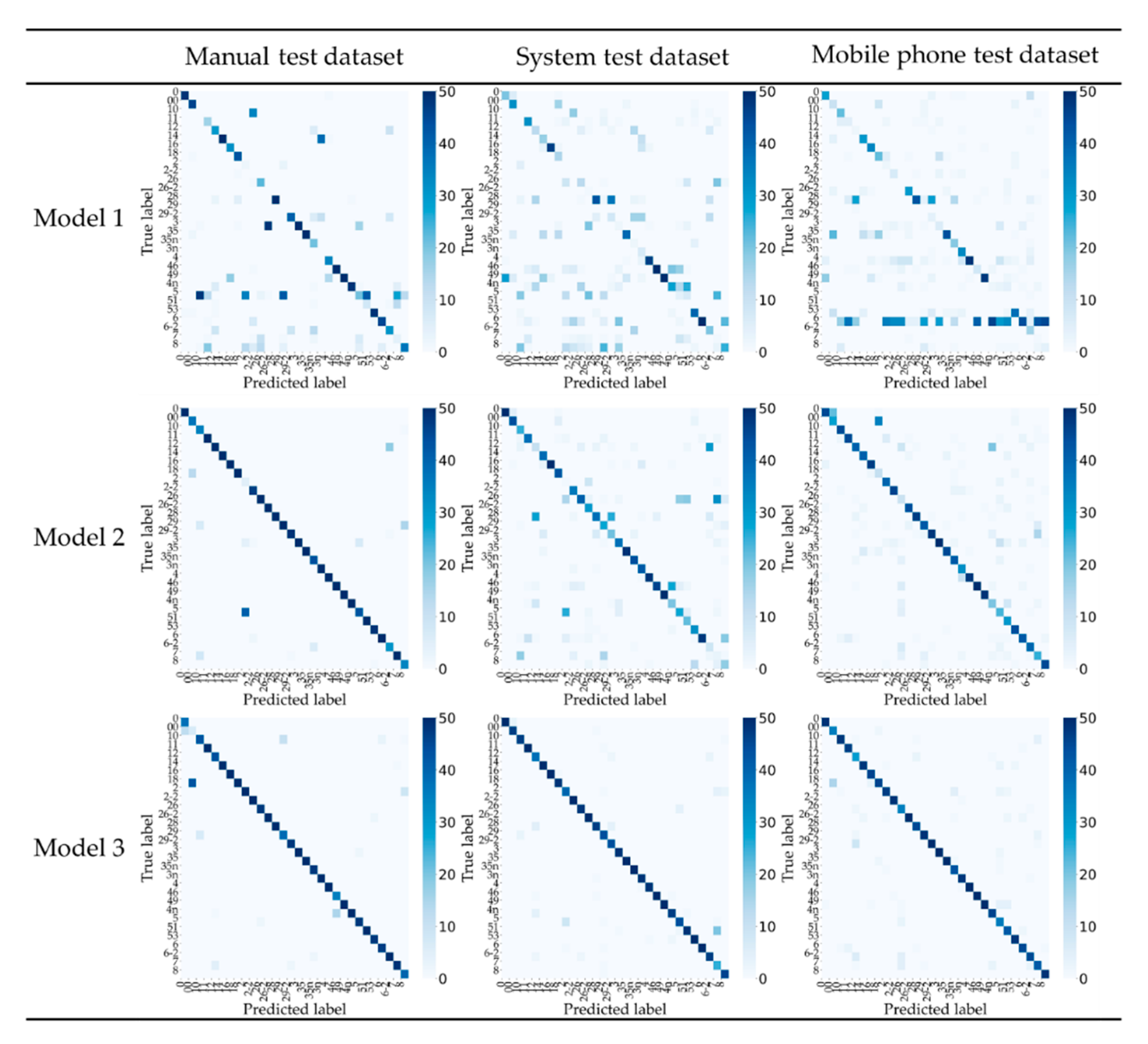
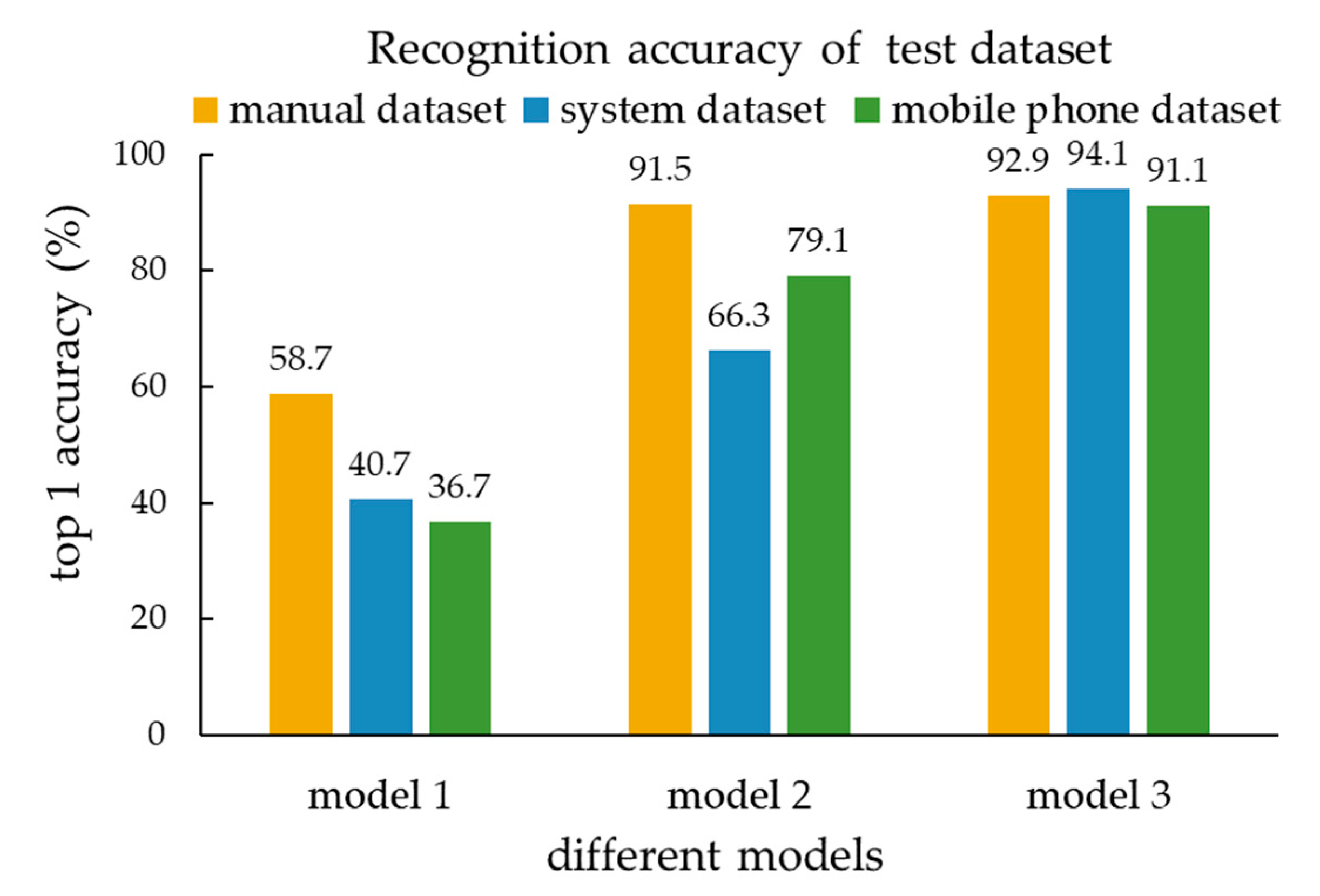
4.3.3. Result Analysis
5. Conclusions
- (1)
- A multi-degree of freedom automatic image acquisition system for deep learning was built to simulate the actual image acquisition situation. In this system, the multi-directional light source was arranged for random lighting, and the multi-degree of freedom motion axis was designed to carry out random motion of the object;
- (2)
- In the process of image acquisition, rich and diverse data can be obtained in a short time; this work calculated the camera position and optimized the random acquisition path. The system can collect 500 images (a class of fabric) in only 9 min;
- (3)
- A deep learning model was used to verify the type of obtained datasets by different methods. The results showed that the recognition accuracy of images collected by the system for different scenes was more than 91%. The construction of the system further promotes the application of deep learning in industrial production.
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kim, K.-I.; Lee, K.M. Convolutional Neural Network-Based Gear Type Identification from Automatic Identification System Trajectory Data. Appl. Sci. 2020, 10, 4010. [Google Scholar] [CrossRef]
- Li, H.; Xu, H.; Tian, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Bridge Crack Detection Based on SSENets. Appl. Sci. 2020, 10, 4230. [Google Scholar] [CrossRef]
- Ochoa-Ruiz, G.; Angulo-Murillo, A.A.; Ochoa-Zezzatti, A.; Aguilar-Lobo, L.M.; Vega-Fernández, J.A.; Natraj, S. An Asphalt Damage Dataset and Detection System Based on RetinaNet for Road Conditions Assessment. Appl. Sci. 2020, 10, 3974. [Google Scholar] [CrossRef]
- Ruan, S.; Tang, C.; Xu, Z.; Jin, Z.; Chen, S.; Wen, H.; Liu, H.; Tang, D. Multi-Pose Face Recognition Based on Deep Learning in Unconstrained Scene. Appl. Sci. 2020, 10, 4669. [Google Scholar] [CrossRef]
- Shibata, T.; Teramoto, A.; Yamada, H.; Ohmiya, N.; Saito, K.; Fujita, H. Automated Detection and Segmentation of Early Gastric Cancer from Endoscopic Images Using Mask R-CNN. Appl. Sci. 2020, 10, 3842. [Google Scholar] [CrossRef]
- Yan, K.; Chang, L.; Andrianakis, M.; Tornari, V.; Yu, Y. Deep Learning-Based Wrapped Phase Denoising Method for Application in Digital Holographic Speckle Pattern Interferometry. Appl. Sci. 2020, 10, 4044. [Google Scholar] [CrossRef]
- Liu, S.; Yin, Y.; Ostadabbas, S. In-Bed Pose Estimation: Deep Learning with Shallow Dataset. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–12. [Google Scholar] [CrossRef]
- Berriel, R.F.; Rossi, F.S.; De Souza, A.F.; Oliveira-Santos, T. Automatic Large-Scale Data Acquisition via Crowdsourcing for Crosswalk Classification: A Deep Learning Approach. Comput. Graph. 2017, 68, 32–42. [Google Scholar] [CrossRef] [Green Version]
- Berriel, R.F.; Torres, L.T.; Cardoso, V.B.; Guidolini, R.; Oliveira-Santos, T. Heading Direction Estimation Using Deep Learning with Automatic Large-scale Data Acquisition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Geng, L.; Wen, Y.; Zhang, F.; Liu, Y. Machine Vision Detection Method for Surface Defects of Automobile Stamping Parts. Am. Sci. Res. J. Eng. Technol. Sci. ASRJETS 2019, 53, 128–144. [Google Scholar]
- Shen, W.; Pang, Q.; Fan, Y.-L.; Xu, P. Automatic Automobile Parts Recognition and Classification System Based on Machine Vision. Instrum. Tech. Sens. 2009, 9, 97–100. [Google Scholar]
- Tian-Jian, L. The Detection System of Automobile Spare Parts Based on Robot Vision. J. Jiamusi Univ. Nat. Sci. Ed. 2012, 718–722. [Google Scholar]
- Hu, G.; Huang, J.; Wang, Q.; Li, J.; Xu, Z.; Huang, X. Unsupervised fabric defect detection based on a deep convolutional generative adversarial network. Text. Res. J. 2020, 90, 247–270. [Google Scholar] [CrossRef]
- Jing, J.; Wang, Z.; Rätsch, M.; Zhang, H. Mobile-Unet: An efficient convolutional neural network for fabric defect detection. Text. Res. J. 2020, 0040517520928604. [Google Scholar] [CrossRef]
- Kumar, A. Computer-vision-based fabric defect detection: A survey. IEEE Trans. Ind. Electron. 2008, 55, 348–363. [Google Scholar] [CrossRef]
- Ngan, H.Y.; Pang, G.K.; Yung, N.H. Automated fabric defect detection—A review. Image Vis. Comput. 2011, 29, 442–458. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary Ph.D. Workshop (IIPhDW), Swinoujście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- GitHub. Available online: https://github.com/aleju/imgaug (accessed on 1 June 2020).
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. Proc. AAAI 2020, 13001–13008. [Google Scholar] [CrossRef]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Proc. Adv. Neural Inf. Proc. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Zhu, X.; Liu, Y.; Qin, Z.; Li, J. Data augmentation in emotion classification using generative adversarial networks. arXiv 2017, arXiv:1711.00648. [Google Scholar]
- Dantzig, G.; Fulkerson, R.; Johnson, S. Solution of a large-scale traveling-salesman problem. J. Oper. Res. Soc. Am. 1954, 2, 393–410. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Δx (mm) | Δy (mm) | Δz (mm) | α (°) | β (°) |
|---|---|---|---|---|---|
| 1 | −32.005 | 40.737 | −62.9 | −9.71 | 13.1875 |
| 2 | −48.803 | 59.681 | −51.652 | −15.5475 | 19.575 |
| 3 | −67.044 | 82.066 | −36.371 | −22.9025 | 27 |
| 4 | −79.439 | 89.984 | −18.315 | −29.5975 | 30.75 |
| 5 | −85.581 | 34.003 | −41.329 | −27.7375 | 11.4425 |
| 6 | −21.941 | −27.195 | −62.9 | −6.895 | −8.2525 |
| 7 | −41.033 | −48.84 | −49.987 | −13.725 | −15.425 |
| 8 | −60.088 | −43.401 | −44.696 | −20.0725 | −13.625 |
| 9 | −75.295 | −59.2 | −27.972 | −27.0875 | −19.1775 |
| 10 | −84.397 | −77.108 | −13.542 | −32.455 | −25.36 |
| 11 | 45.658 | 22.681 | −62.9 | 14.055 | 7.01 |
| 12 | 63.27 | 46.472 | −51.282 | 20.26 | 14.7425 |
| 13 | 82.88 | 62.9 | −33.966 | 28.1025 | 20.3125 |
| 14 | 90.946 | 75.48 | −24.975 | 31.85 | 24.4275 |
| 15 | −49.765 | −67.451 | −39.849 | −17.61 | −21.5625 |
| 16 | −72.113 | −41.736 | −36.371 | −24.8475 | −13.34 |
| 17 | −86.062 | −30.599 | −31.783 | −29.58 | −9.5825 |
| 18 | −67.895 | −48.396 | −35.039 | −23.82 | −15.65 |
| 19 | 99.271 | −67.044 | −12.58 | 35.41 | −22.86 |
| 20 | 77.552 | −75.036 | −25.16 | 26.8125 | −24.83 |
| Degrees | Δz (mm) | α (°) | β (°) |
|---|---|---|---|
| 1 | 15.9265 | 1.36364 | 0.355234 |
| 2 | 2.0463 | 1.231859 | 0.372423 |
| 3 | 1.7221 | 0.280749 | 0.189076 |
| 4 | 1.5537 | 0.257831 | 0.177617 |
| Index | Local Optimal | Global Optimal |
|---|---|---|
| Time-consuming | Less | More |
| Optimal path | No | Yes |
| Algorithm complexity | n | n! |
| Key Components | Model | Parameters | |
|---|---|---|---|
| Motion control | Electric guide rail | JD45P | Travel: 300 mm |
| Driver | DM442 | Two-phase stepping motor driver | |
| 8 axes motion control card | IMC408E | 8 axes | |
| Illumination control | Flat light source | HF-FX160 | DC12V, white light |
| Ring light source, | YC-DR6836WL | DC12V, white light | |
| Light source Controller | CCS PD-3012-8 | Input AC100-240V, output: DC12V, power: 25 W | |
| Single chip Microcomputer | STM32F103ZET6 | Cotex-M3 core chip |
| Datasets | Acquisition Method | Size | Time-Consuming | |
|---|---|---|---|---|
| One Class | One Image | |||
| dataset1 | Manual acquisition | 50 × 30 | 3 min | 3.6 s |
| dataset2 | Dataset1, data augmentation | 500 × 30 | - | - |
| dataset3 | System acquisition | 500 × 30 | 9 min | 1.1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Yan, N.; Yang, H.; Zhu, L.; Zheng, Z.; Yang, X.; Zhang, X. A Data Augmentation Method for Deep Learning Based on Multi-Degree of Freedom (DOF) Automatic Image Acquisition. Appl. Sci. 2020, 10, 7755. https://doi.org/10.3390/app10217755
Chen L, Yan N, Yang H, Zhu L, Zheng Z, Yang X, Zhang X. A Data Augmentation Method for Deep Learning Based on Multi-Degree of Freedom (DOF) Automatic Image Acquisition. Applied Sciences. 2020; 10(21):7755. https://doi.org/10.3390/app10217755
Chicago/Turabian StyleChen, Liangliang, Ning Yan, Hongmai Yang, Linlin Zhu, Zongwei Zheng, Xudong Yang, and Xiaodong Zhang. 2020. "A Data Augmentation Method for Deep Learning Based on Multi-Degree of Freedom (DOF) Automatic Image Acquisition" Applied Sciences 10, no. 21: 7755. https://doi.org/10.3390/app10217755
APA StyleChen, L., Yan, N., Yang, H., Zhu, L., Zheng, Z., Yang, X., & Zhang, X. (2020). A Data Augmentation Method for Deep Learning Based on Multi-Degree of Freedom (DOF) Automatic Image Acquisition. Applied Sciences, 10(21), 7755. https://doi.org/10.3390/app10217755