5.1. Selection of Decision Variables in the Evaluation Process
To assess the effectiveness of lean maintenance tools, the factors influencing the dependent variable were identified. In the research on the assessment of the effectiveness of lean maintenance tools, one dependent variable and 19 explanatory variables (predictors) were determined. In the conducted research, one dependent variable was assumed: the average value of the OEE indicator.
Due to the large variety (combination) of response options, three additional indicators were introduced in the surveyed enterprises: maintenance strategy indicator (MSI), number of preventive activities (NPA), and number of TPM activities (NTPMA) indicator. The NPA number is the number of actions to prevent unplanned downtime, calculated as the total value of actions carried out simultaneously by the enterprise. During the survey (data collection) process, the company could choose several activities from the following:
Implementation of autonomous service (by the operator).
Implementation of preventive maintenance.
Forecasting activities based on the condition of machines (e.g., vibration analysis).
Additional operator training.
Additional training of maintenance service employees.
Equipping the maintenance services with specialized instruments (e.g., for measuring vibrations, for measuring the noise level).
Exchange of machines for new ones.
Modernization of machines.
Increasing the number of employees of maintenance services.
Outsourcing some maintenance activities to external companies.
Depending on how many activities are carried out by the enterprise at the same time, the indicator may range from 1 to 10. In addition, during the survey (data collection) process, the company could choose several activities implemented as part of the implementation of the TPM method, recommended in the literature on the subject, from the following:
Training of selected employees.
Training of all employees.
Implementation in a selected pilot area (position, line, etc.).
TPM workshops in the selected pilot area (stand, line, etc.).
Assessment of machines in terms of meeting health and safety requirements.
Assessment of the technical condition of machines.
Identification of non-conformities on machines.
Development of the inspection schedule.
Development of a renovation schedule.
Development of the scope of preventive service (for maintenance services).
Development of the scope of autonomous service (for the operator).
Depending on the value obtained, the indicator had four levels: low, medium, high and very high (
Table 3).
The last index developed is the MSI index. With this indicator, it is possible to determine what technical infrastructure management strategy is applied by the enterprise. During the study (data collection), the company could choose several activities defining the realized activities implemented under the corrective maintenance (CM), preventive maintenance (PM), and condition-based maintenance (CBM) strategies. In order to define the index for possible variants of answers, numerical values ranging from 1 to 7 were introduced (
Table 4). The lowest value was given to the action implemented in accordance with the CM strategy as the least effective strategy. However, the highest efficiency (value 7) was adopted for the operation: continuous monitoring of the condition of all machines (e.g., noise, vibrations, temperature) (CBM).
The value of MSI indicator is calculated as the sum of the value of activities by the number of implemented activities (4).
The MSI indicator may take values from 1 to 7. Value 1 means mainly the CM strategy, value 3.5—PM strategy, value 7—CBM strategy. When the value of the ratio is <3.5, it means the implementation of a mixed strategy, mainly CM–PM; when >3.5, it means the implementation of mainly a mixed strategy PM–CBM. At the same time, when closer to the value of 3.5, PM is the prevailing strategy. In order to ensure the adequacy of the adopted indicator, the variants of the strategy implemented by the examined enterprises were analyzed. For individual values of the indicator, implemented strategy variants (sequence of implemented actions) were assigned. The distribution of variants of the implemented strategies (distribution close to the normal distribution) allows us to confirm the validity of the adopted indicator (
Table 5).
The Statistica Data Miner system was used to conduct the analyzes. This system enables the preparation of data in the form of a training and test set, intuitive guidance through the model building and fitting procedure, and a clear visualization of test results.
5.2. Decision Trees in the Assessment of the Effectiveness of Lean Maintenance
Due to qualitative nature of the dependent variables, classification decision trees with the use of the classification and regression trees (CART) algorithm were used.
Not all surveyed enterprises used the same solutions, methods, and tools, therefore the main criterion for selecting this method was its insensitivity to the occurrence of atypical observations, which are believed to come from a different population, and the possibility of its effective use in datasets characterized by numerous shortcomings in independent variables. Additionally, the following advantages of CART classification trees determined the choice of the method:
Taking into account non-monotonic dependencies through successive divisions with respect to the same variable;
Simple interpretation of results in comparison with other methods;
Suitability for tasks, where the a priori knowledge of which variables are related and how they are uncertain and intuitive;
Non-parametric and non-linear;
Estimating and ranking the importance of individual predictors (input variables) in the process of shaping the value of the dependent variable;
Very useful for classification issues.
The CART tree for a dependent variable—a mean value of the OEE indicator—was designed for 24 enterprises out of the studied group of enterprises, which had analyzed this indicator and implemented the TPM method. The following explanatory variables (predictors) were assumed: enterprise size, production type, industry, ownership type, capital, company condition, machine type, 5S implementation, 5S activities, SMED implementation, way of supervision, maintenance strategy, actions undertaken to prevent unplanned downtimes (number of prevent actions—NPA), machine classification, spare parts classification, actions within TPM implementation (NTPMA indicator), and mean time to repair. The following were assumed while creating the tree: equal costs of the incorrect classification, Gini coefficient, stop rule, and a minimum size criterion in the divided node n ≥ 2, which will allow for a detailed analysis of a tree structure and for 10-fold cross validation as a quality measure. A tree consisting of 12 divided nodes and 13 end nodes was chosen for the analysis. In order to assess the quality of the chosen tree, its validation for a new dataset was conducted. Thirteen decision rules may be defined for the created tree, which has 13 end nodes. The chosen decision rules, for which the highest values of OEE were reached (over 85% and for the range 70 to 85%) with the use of additional lean maintenance methods and tools, were presented below. Decision rules established on the basis of the decision tree are:
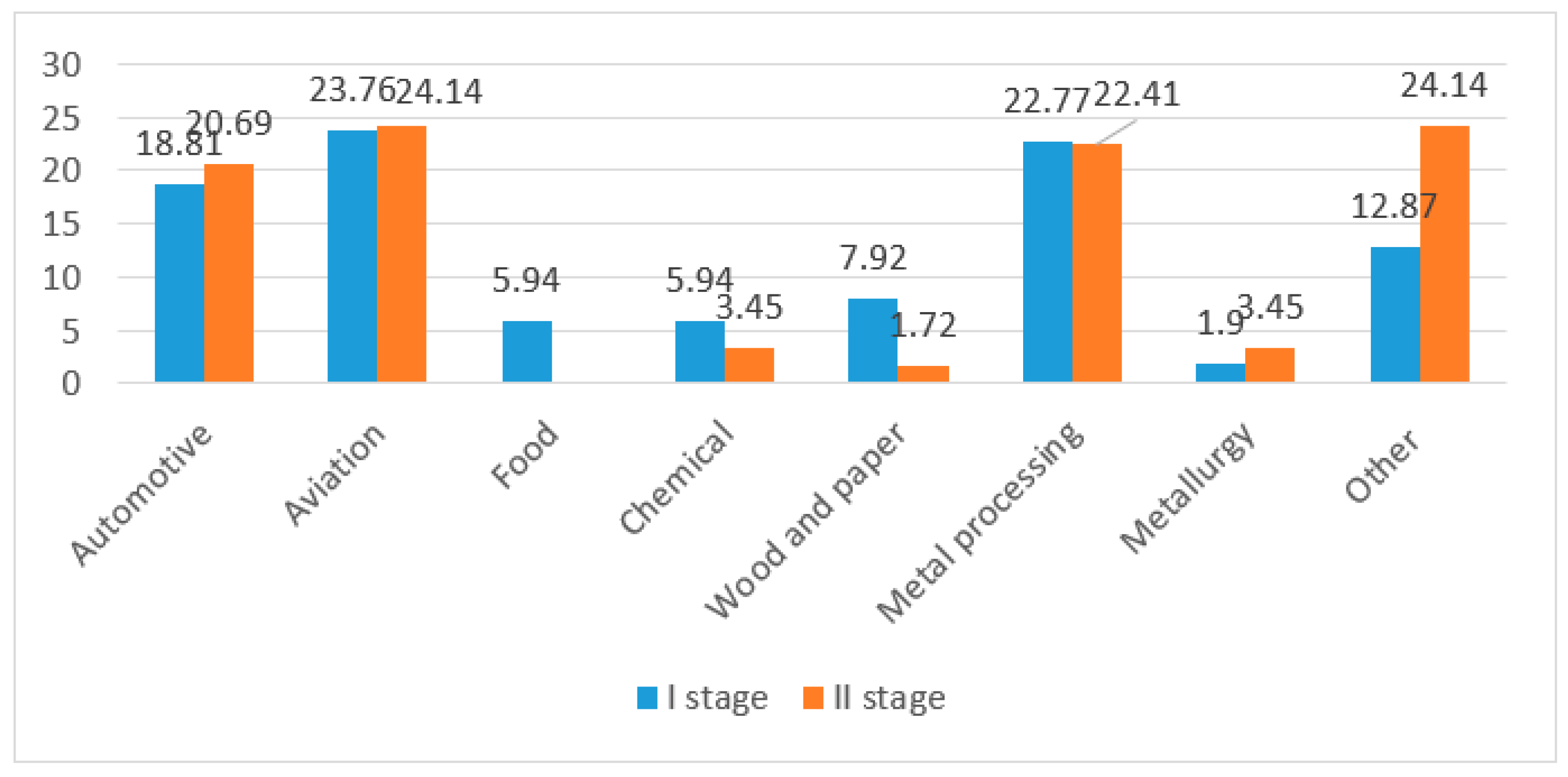
If an enterprise represents metal processing, aviation, or paper and wood industry, does not run partial supervision by outsourcing, and possesses an MSI indicator at the level of ≠4,5 and realizes machine classification, then it reaches an average value of the OEE indicator of over 85% (node 12).
If an enterprise represents an industry other than metal processing, aviation, or paper and wood. possesses an MSI indicator at the level of 3.5–5.6 and NPA number > 3, and the mean time to repair is below 1 h, then it reaches a mean value of the OEE indicator within the range from 70 to 85%.
If an enterprise represents an industry other than metal processing, aviation, or paper and wood and possesses an MSI indicator at the level other than that of 3.5–5.6 and an NTPMA indicator at any level other than high, then it reaches a mean value of the OEE indicator within the range from 70 to 85%.
If an enterprise represents an industry other than metal processing, aviation, or paper and wood, possesses an MSI indicator at any level other than that of 3.5–5.6a and an NTPMA indicator at a high level, and realizes supervision on its own with the service through outsourcing, then it reaches a mean value of the OEE indicator within the range from 70 to 85%.
If an enterprise represents an industry other than metal processing, aviation, or paper and wood, possesses an MSI indicator at any level other than that of 3.5–5.6 and an NTPMA indicator at a level other than high, and realizes supervision in a way other than on its own with the service through outsourcing, then it reaches a mean value of the OEE indicator of over 85%.
In order to evaluate the generated decision-making rules, research was again carried out in 20 randomly selected enterprises. Then, an expert system was designed and made (using PC-Shell—an expert system shell from the Aitech Sphinx software), taking into account the generated decision rules. Then, the general classification ability of the generated decision rules was tested using qualitative measures. Two blocks—aspects and rules—were used to develop the knowledge base in the system. The aspect block was used to declare the decision attributes and their values. On the other hand, the explanatory variables placed in the decision tree nodes are the decision attributes. The results of system inference were represented by the result attribute (target attribute). Finally, the value of the received attribute “OEE value” is presented in a separate window. The quality analysis consisted of developing binary matrices of classifiers’ errors determined for the classes that most commonly appear in the conducted studies. In the developed binary matrices (confusion matrices) (
Table 6), the class analyzed at a particular moment was assumed as positive, while the remaining classes were treated as negative.
Table 7 and
Table 8 present confusion matrices for the classifier—the value of OEE for the two most-emerging classes: 30–50% and 70–85%.
Based on the confusion matrix, numerical indicators presented in
Table 9 can be designated. In detail, these indicators have been presented and discussed, among others in the works [
51,
52,
53].
On the basis of the developed binary matrices, for each of them, the values of the twelve indicators showing the classifiers’ quality were calculated.
Table 10 presents the results for the highlighted classifier classes.
The obtained indicator values the assessment of a classification measure, e.g., of an error (Err) at the level of 0.00 and 0.15, proved high usefulness of the developed classifiers, and thereby, their possibility to be applied by manufacturing enterprises for the effective assessment of the lean maintenance methods and tools implementation.
5.3. The Theory of Rough Sets to Support the Lean Maintenance Assessment
The rough set theory is one of the fastest growing branches of data exploration. It allows for a formal approach to all phenomena related to knowledge processing, therefore it is used as a methodology in the process of knowledge discovery from data. In particular, it can be used to test the imprecision and uncertainty in the data analysis process. It enables finding the relationship between explanatory variables (conditional attributes) and explained variables (decision attributes), which facilitates supporting decision-making based on data. It is also used to reduce dimensionality, consisting of removing from the dataset those explanatory variables that do not significantly affect the explained variables. Knowledge derived from data based on the rough set theory is recorded in the form of decision rules [
55]. Details on the formal description of the rough set theory can be found, among others, at work [
56]. Often, the purpose of the decision-making system based on rough sets is to search for hidden, and therefore, implicit rules that have not worked well during the selection made by an expert (or experts) [
55,
56,
57]. Approximate sets are used to process the so-called unclear data with the use of intuitively understood inference rules. They can be used to search for hidden dependencies in input data, including decision support in the scope of cases that can be described with discrete attributes.
In this paper, the rough set theory was used to assess the degree of lean maintenance use. The same set of input data was used for the assessment as in the decision trees. Due to the presence of the so-called incomplete data, the use of rough sets improved the accuracy of the solution. Various types of algorithms were used to interfere with the rules.
The use of the rough set theory, and thus incomplete data, increased the number of analyzed enterprises from 24 included in decision trees to 34. An additional 10 analyzed enterprises were characterized by a set of variables, for which at least one variable did not have a specific value (no answer). By using decision tables in the rough set theory, it is possible to include more data when generating rules. This allows for the identification of new dependencies between the variables. To make the assessment, the rules were validated. In order to generate decision rules on the basis of the rough set theory, Rough Set Exploration System (RSES) software was used. The software was developed at the Institute of Mathematics of Warsaw University.
RSES software allows one to generate decision rules with the means of four algorithms: exhaustive algorithm, genetic algorithm, covering algorithm, and learning from examples module version 2 (LEM2). They were described in the works [
57,
58]. Furthermore, the software contains a number of other options, which, e.g., assign reductions for a given computer system. A reduct is a set of R attributes, where R ⊂ A, which allows to differentiate pairs of objects in a computer system, and at the same time, no other R proper subset possesses this property. Reductions are calculated with an exhaustive or genetic algorithm. On the basis of the assigned reductions, it is possible to create decision rules as well.
For each of decision classes, RSES software calculates three indicators, which indicate classification quality:
Accuracy—the ratio of properly classified objects of a given class to all objects belonging to this class;
Coverage—the ratio of the objects classified to a given class with decision rules to all objects belonging to this class;
True positive rate—the ratio of the properly classified objects of a given class to all objects that were classified to this class.
Accuracy and coverage are also calculated jointly for all decision classes (for the whole set of rules).
Decision rules for the described variable “an average OEE value” were generated by means of all four algorithms available in RSES. The scheme of the conducted study is shown in
Figure 7. The OEE symbol designates a decision table which contains 34 studied objects (enterprises). Each object is described by 17 explanatory variables: an enterprise size, production type, industry, ownership type, capital, actions undertaken to prevent unplanned downtimes (NPA number—MSI indicator), machine category, spare parts category, actions in the TPM implementation (NTPMA indicator), and mean time to repair. The described variable “an average OEE value” played in the study the role of a decision attribute. The remaining symbols in the scheme are described in
Table 11.
While formulating the decision rules, the parameters of genetic and covering algorithms were chosen in such a way that the accuracy and coverage of the created set were equal to 1.
Table 12 includes the information on a number of rules in each of the four sets of rules. For each of the rules, a rule match is calculated. It is equal to the number of objects from the learning set and matching the forerunner of the rule.
Each of the four rule sets was used for the classification of the data from the OEE decision table. The classification was accomplished by a standard voting method. The manner of such voting is as follows: each of the generated rules determines the value of a variable described for the considered object (an enterprise). The calculated match value of particular rules is treated during the voting as an importance—the higher the match of a given rule, the more important is its vote. That is why it is more influential on a final voting result than the vote of the rule with a lower match. Eventually, the object is assigned such a value of an explanatory variable that won the weighted voting.
The result of the classification was presented in the form of a confusion matrix. The confusion matrix that includes the results of the classification accomplished by the rule set generated by an exhaustive algorithm was presented in
Figure 8. Matrix rows correspond to the real decision classes (the values of the variable described). However, matrix columns are the results of the classification that was accomplished by the generated rules. All 34 objects that are in the decision board were classified properly. It is reflected in the values located only on the main diagonal of the confusion matrix. The last three columns in the described figure show the information on the number of objects belonging to a given decision class (no. of obj.), accuracy, and coverage. The last row of the table is the true positive rate calculated for each class individually. The bottom part of the window presents the number of all studied objects and the accuracy and coverage calculated for all decision classes altogether.
Confusion matrices were also created for the classification results based on the three remaining rule sets. Each of these matrices included the same results (accuracy = 1), such as the matrix presented in
Figure 4, which indicates that there are no classification errors also for other classifications.
The assessment of the developed decision rules (decision trees and rough set theory) was carried out in the following stages: generation of a decision table and confusion matrix; development of an expert system based on the generated decision rules; use of the obtained study results to test the overall classification capacity; use of the obtained study results to test the overall classification capacity of decision-making rules using the developed expert system; and qualitative assessment of the results obtained using classification quality measures.
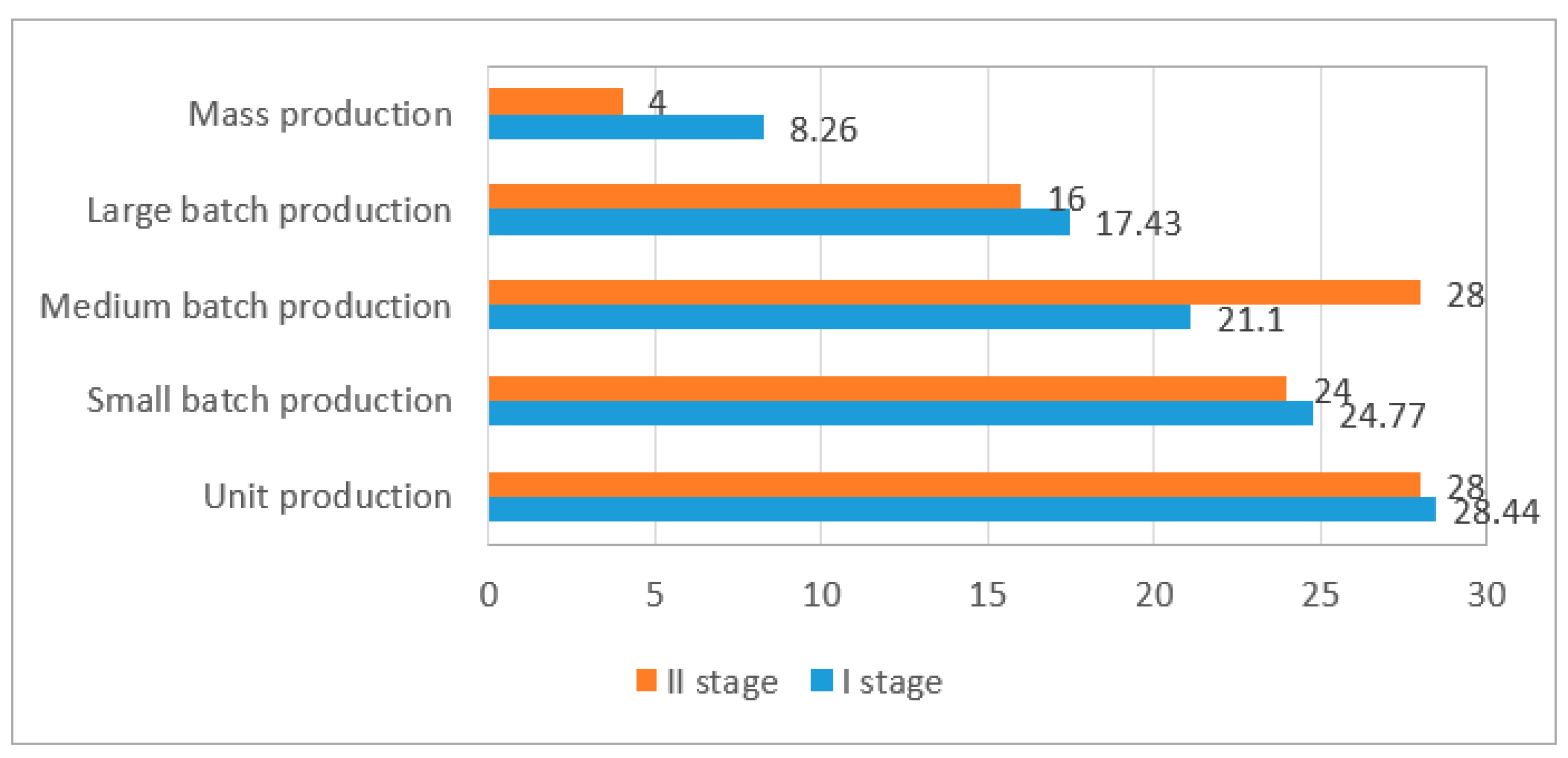
The results of the surveys from 20 companies of the Podkarpackie Voivodship were reused to validate the decision-making rules. Among the companies analyzed, the largest group included large companies (85%) from the aviation industry (50%). The majority of them were private companies (95%), with a majority of foreign capital (85%). Large-batch production (45%) dominated among the companies surveyed. On the basis of the results obtained, a decision table was created. The created decision table was introduced into the RSES system. It allowed us to create a confusion matrix for the explanatory variable “an average OEE value”. Maximum coverage calculated for all decision classes in total that equals 1 and accuracy of 0.30 for the explanatory variable “an average OEE value” were achieved using a set of rules generated by a genetic algorithm (
Figure 9).
In order to carry out the next stage of validation, an expert system was developed. The decision-making rules generated by all algorithms were implemented in the knowledge base that was created for the system needs. The knowledge base for the expert system was developed with PC-Shell software, which is part of the Aitech SPHINX integrated artificial intelligence suite and Aitech HybRex software.
In order to test the overall quality of the classifier for all algorithms, confusion matrices (
Table 13,
Table 14,
Table 15 and
Table 16) were used. These matrices were developed by comparing the results obtained by the studied companies with the result generated by the developed expert system. The classification was carried out again according to the following voting method:
The conformity of the actual class value and predicted class value was considered as a valid result;
The cases when the value of the class predicted by an expert system was one class lower than the actual class value was allowed as a valid result, e.g., the actual class is a range of 30–50% and the predicted value is 10–30%. In practice, this means that an enterprise can expect projected variables to be at a minimum level of 10–30%. However, in fact, it may be higher.
When analyzing particular confusion matrices, it should be noted that the best results for the most common classes (30–50% and 70–85%) of the accuracy value were obtained for the rules generated by an exhaustive algorithm. The accuracy value was 0.6 and 0.875, respectively. In order to accurately assess the quality of the classifiers based on binary matrices, the values of the twelve indicators were calculated for each of the matrices according to the
Table 9.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

