Efficient Algorithm for Providing Live Vulnerability Assessment in Corporate Network Environment


Abstract
:Featured Application
Abstract
1. Introduction
- there is no successful VM without effective communication,
- insufficient resources allocated to remediate the detected vulnerabilities, will cause vulnerability accumulation,
- fixing only “high” and “critical” vulnerabilities is not enough.
- Background—section describes foundations of this research, introduces the problems, processes and trades off that are present in vulnerability management research.
- Related Work—section presents other work related to the present topic. It is a brief description of work related vulnerability management.
- System Data Life Cycle and Analysis—section presents data life cycle and analysis of the proposed framework.
- VMC Implementation and Experiment Design—section shows an experiment design for conducted research.
- Results—section starts the discussion about the results illustrating the advantages of the proposed VMC system, shows a summary of the presented work.
- Conclusions—section gives the summary, starts critical discussion about the presented solution, and introduces fields for further research.
2. Background
- Base
- Temporal
- Environmental
3. Related Work
4. System Data Life Cycle and Analysis
4.1. Knowledge Collector Module
4.2. Asset Collector Module
4.3. Vulnerability Collector Module
4.4. Processing Module
- d
- the number of data processed by one processing module
- t
- the number of available processing modules
- v
- the number of vulnerabilities that are not fixed or removed
5. VMC Implementation and Experiment Design
- VMC processing module
- PostgreSQL database—storing VMC configurations
- MariaDB database—storing CMDB information
- Ralph—CMDB administration panel
- Rabbitmq—queue system used for communication between VMC modules
- Redis—in-memory base used for partial calculations storage and mutex support in VMC modules
- VMC monitor—the monitoring of tasks performed by VMC
- VMC admin panel—module for VMC management
- —prioritization for the initial state,
- —CIA value change for 10% of assets,
- —CIA value change for 20% of assets,
- —CIA value change for 30% of assets,
- —10% of assets marked as DELETED,
- —20% of assets marked as DELETED,
- —30% of assets marked as DELETED,
- —the increase of new vulnerabilities by 10%,
- —the increase of new vulnerabilities by 20%,
- —the increase of new vulnerabilities by 30%,
- —10% of vulnerabilities marked as FIXED (fixing the vulnerability),
- —20% of vulnerabilities marked as FIXED (fixing the vulnerability),
- —30% of vulnerabilities marked as FIXED (fixing the vulnerability).
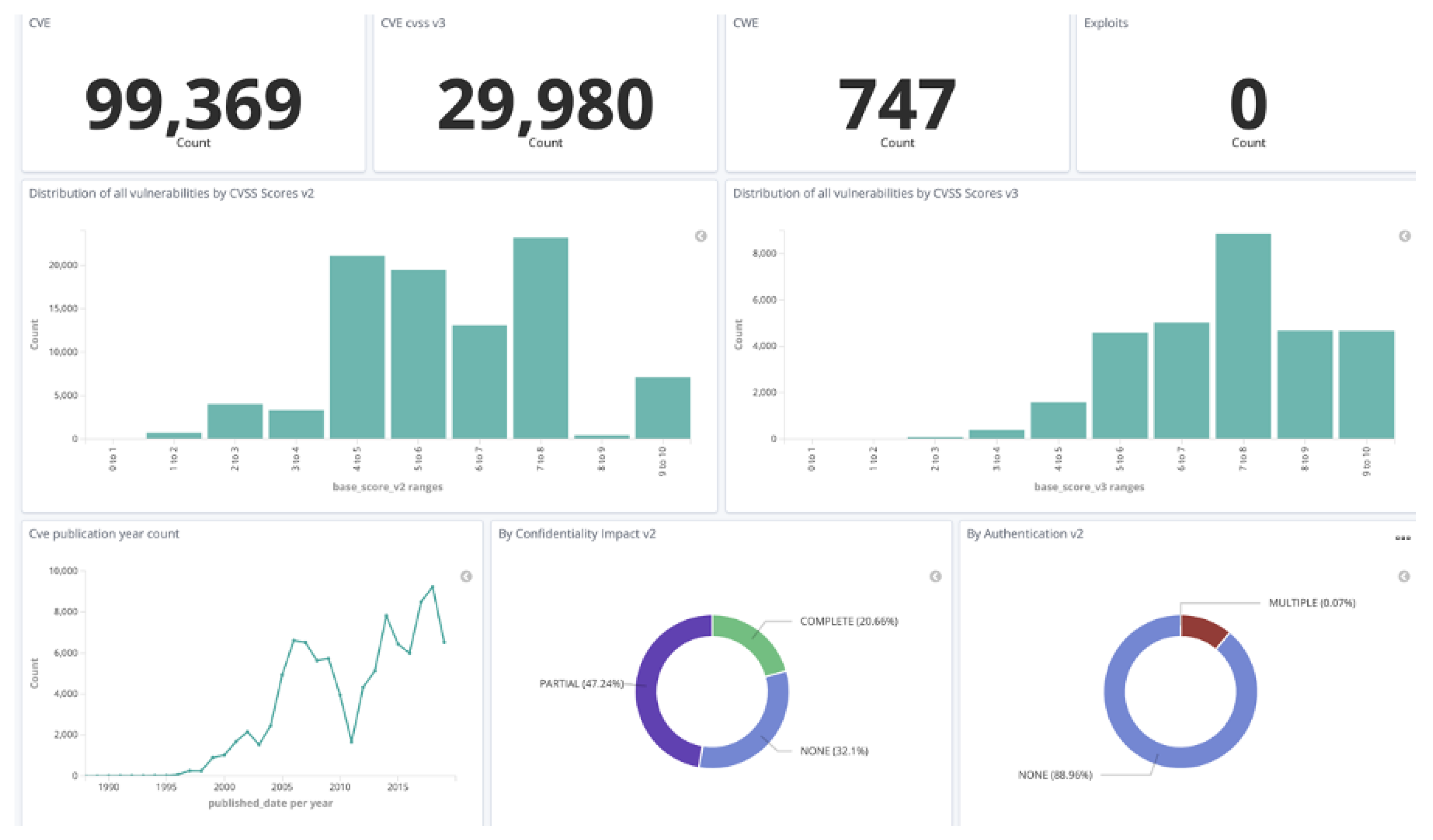
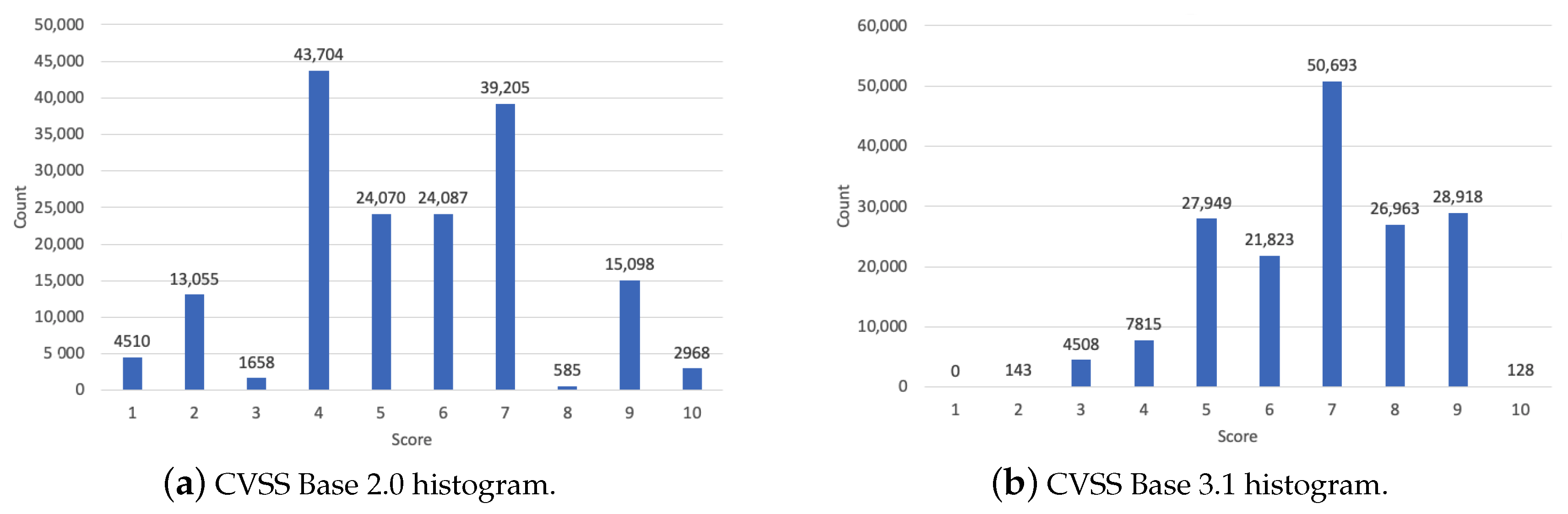
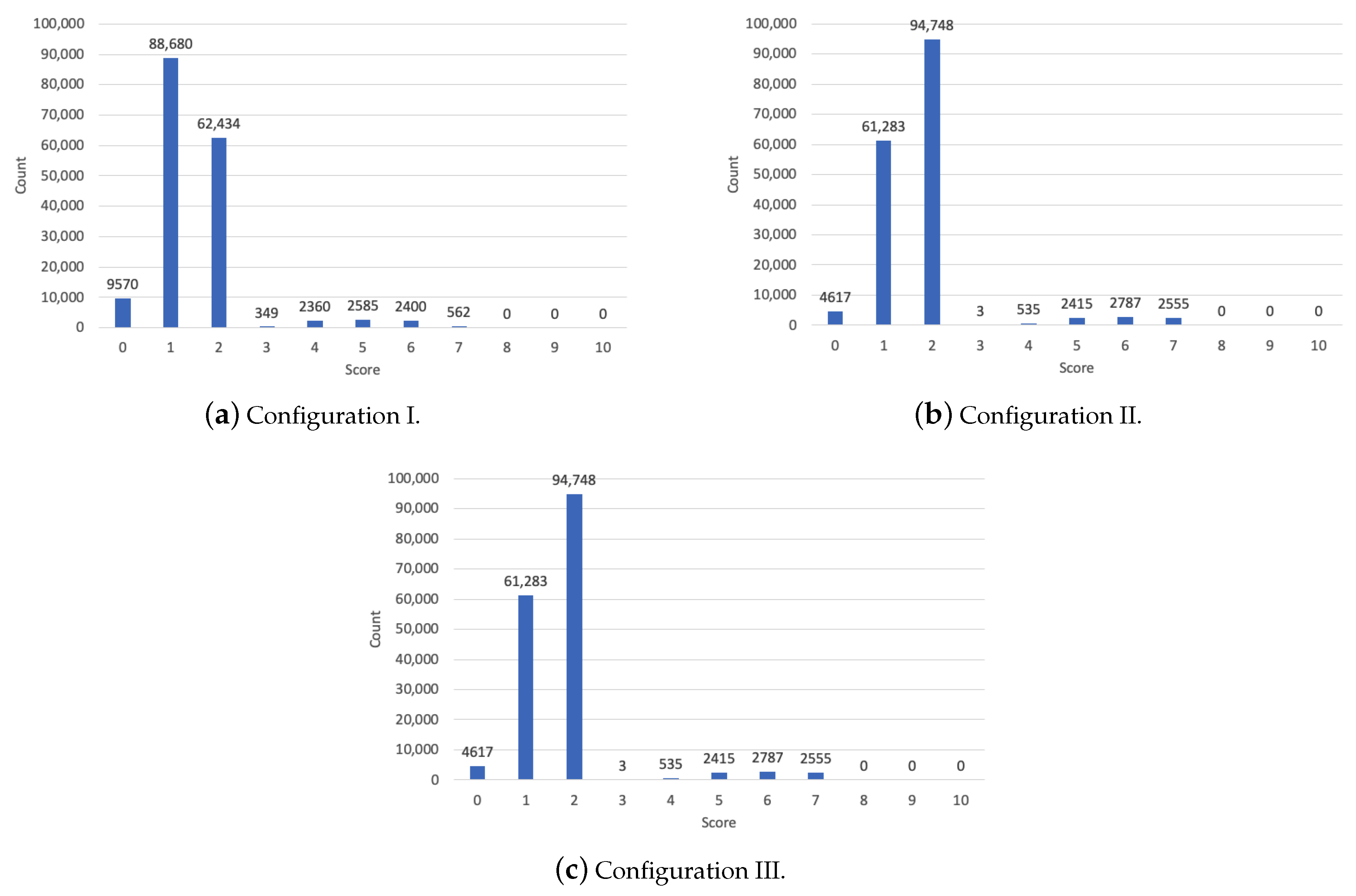
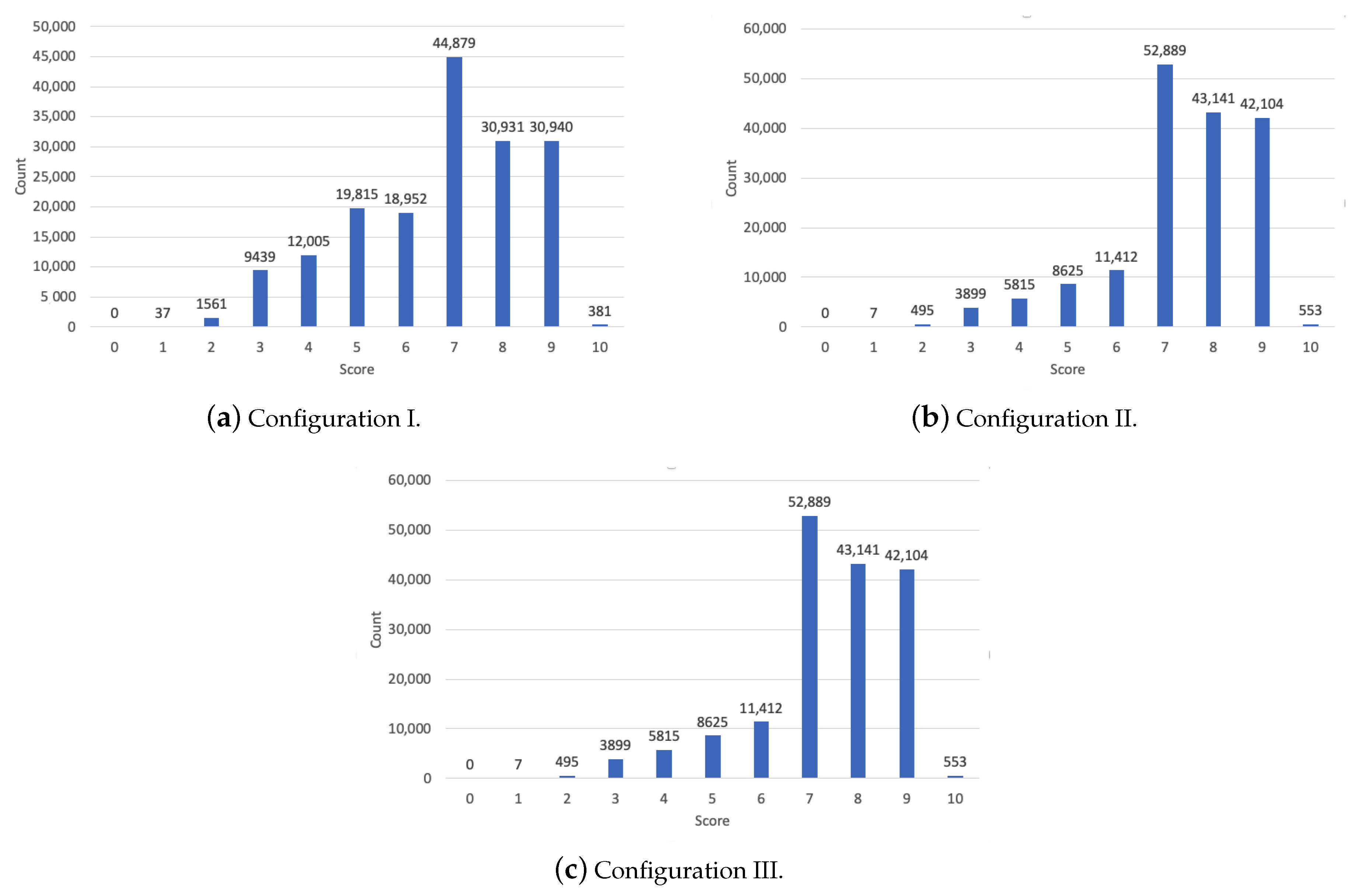
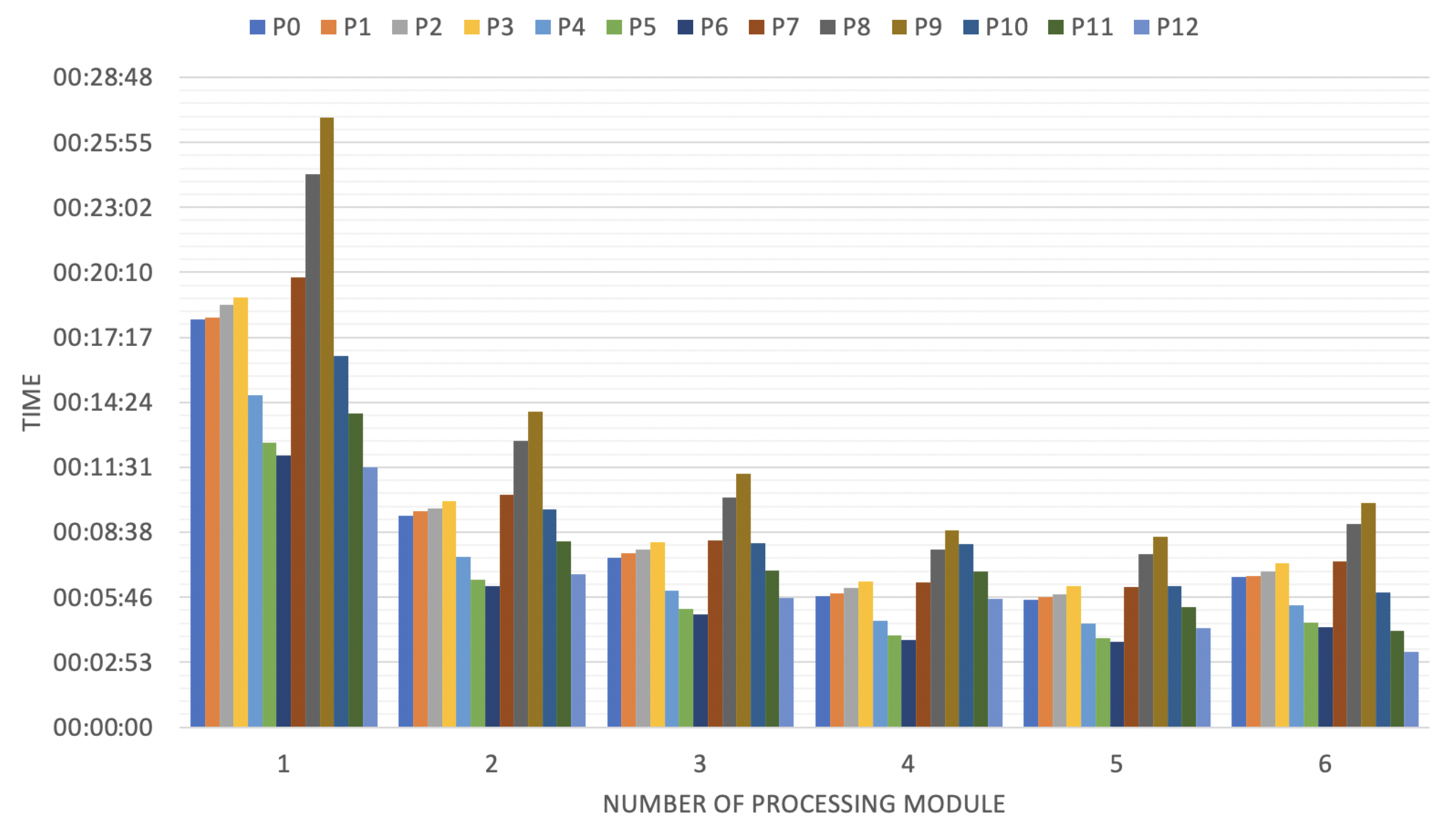
6. Results
7. Conclusions
- calculating CVSS Environmental vector component, reducing thereby the workload for stakeholders,
- fully scalable implementation, thus enabling processing large amounts of data in corporate environments [31],
- creating the dynamic metrics adjusted to corporate requirements.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CIA | Confidentiality, Integrity and Accessibility |
| CMDB | Configuration Management Database |
| CVE | Common Vulnerabilities and Exposures |
| CVSS | Common Vulnerability Scoring System |
| DCIM | Data Center Infrastructure Management |
| ID | Identification |
| IDS | Intrusion Detection System |
| IoT | Internet of Things |
| IPS | Intrusion Prevention system |
| IT | Information Technology |
| K8S | Kubernetes cluster |
| NVD | National Vulnerabilities Database |
| OVM | Ontology for Vulnerability Management |
| P | Proposed Test cased |
| SOC | Security Operations Center |
| TD | Target Distribution |
| US | United States |
| VA | Vulnerability Assessment |
| VLAN | Virtual Local-Area Network |
| VM | Vulnerability Management |
| VMC | Vulnerability Management Centre |
References
- SkyboxR Research Lab. Vulnerability and Threat Trends; Technical Report. 2020. Available online: https://lp.skyboxsecurity.com/rs/440-MPQ-510/images/Skybox_Report_2020-VT_Trends.pdf (accessed on 15 October 2020).
- Yang, H.; Park, S.; Yim, K.; Lee, M. Better Not to Use Vulnerability’s Reference for Exploitability Prediction. Appl. Sci. 2020, 10, 2555. [Google Scholar] [CrossRef] [Green Version]
- Gartner Research. A Guidance Framework for Developing and Implementing Vulnerability Management. Available online: https://www.gartner.com/en/documents/3747620 (accessed on 15 October 2020).
- Rochford, O.; Threat-Centric, T. Vulnerability Remediation Prioritization. J. Abbr. 2008, 10, 142–149. [Google Scholar]
- Haldar, K.; Mishra, B.K. Mathematical model on vulnerability characterization and its impact on network epidemics. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 379–382. [Google Scholar] [CrossRef]
- F-Secure. Vulnerability Management Tool. Available online: https://www.f-secure.com/us-en/business/ solutions/vulnerability-management/radar (accessed on 15 October 2020).
- Qualys. Vulnerability Management Tool. Available online: https://www.qualys.com /apps/vulnerability-management/ (accessed on 15 October 2020).
- Rapid7. Vulnerability Management Tool. Available online: https://www.rapid7.com/products/nexpose/ (accessed on 15 October 2020).
- Tenable. Vulnerability Management Tool. Available online: https://www.tenable.com/products/tenable-io (accessed on 15 October 2020).
- VMC: A Scalable, Open Source and Free Vulnerability Management Platform. Available online: https://github.com/DSecureMe/vmc (accessed on 11 May 2020).
- El Arass, M.; Souissi, N. Data Lifecycle: From Big Data to SmartData. In Proceedings of the 2018 IEEE 5th International Congress on Information Science and Technology (CiSt), Marrakech, Morocco, 21–27 October 2018; pp. 80–87. [Google Scholar] [CrossRef]
- Lenk, A.; Bonorden, L.; Hellmanns, A.; Roedder, N.; Jaehnichen, S. Towards a taxonomy of standards in smart data. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 1749–1754. [Google Scholar]
- Mann, D.E.; Christey, S.M. Towards a common enumeration of vulnerabilities. In Proceedings of the 2nd Workshop on Research with Security Vulnerability Databases, West Lafayette, Indiana, 21–22 January 1999. [Google Scholar]
- Common Vulnerability Scoring System. Available online: http://www.first.org/cvss (accessed on 24 April 2020).
- Ruohonen, J. A look at the time delays in CVSS vulnerability scoring. Appl. Comput. Inform. 2019, 15, 129. [Google Scholar] [CrossRef]
- Morrison, P.J.; Pandita, R.; Xiao, X.; Chillarege, R.; Williams, L. Are vulnerabilities discovered and resolved like other defects? Empir. Softw. Eng. 2018, 23, 1383–1384. [Google Scholar] [CrossRef]
- Martin, R.A. Managing vulnerabilities in networked systems. Computer 2001, 34, 32–38. [Google Scholar] [CrossRef] [Green Version]
- Fall, D.; Kadobayashi, Y. The Common Vulnerability Scoring System vs. Rock Star Vulnerabilities: Why the Discrepancy? In Proceedings of the 5th International Conference on Information Systems Security and Privacy—Volume 1: ICISSP, Prague, Czech Republic, 23–25 February 2019; pp. 405–411. [Google Scholar]
- Mell, P.M. An Overview of Issues in Testing Intrusion Detection Systems. NIST Internal Report 7007. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/IR/nistir7007.pdf (accessed on 24 April 2020).
- Kaya, K. A Study of Vulnerabilities and Weaknesses in Connected Cars. Bachelor’s Thesis, KTH, School of Electrical Engineering and Computer Science (EECS), Stockholm, Sweden, 2019. [Google Scholar]
- U.S. Food and Drug Administration. S. Food and Drug Administration. Postmarket Management of Cybersecurity in Medical Devices: Guidance for Industry and Food and Drug Administration Staff; U.S. Food and Drug Administration: Silver Spring, MD, USA, 2016.
- Wang, W.; Gupta, A.; Niu, N. Mining Security Requirements from Common Vulnerabilities and Exposures for Agile Projects. In Proceedings of the 2018 IEEE 1st International Workshop on Quality Requirements in Agile Projects (QuaRAP), Banff, AB, Canada, 21 August 2018; pp. 6–9. [Google Scholar]
- IBM X-Force Threat Intelligence. Available online: https://www.ibm.com/security/xforce (accessed on 15 October 2020).
- Symantec Security Center. Available online: https://www.broadcom.com/support/security-center (accessed on 15 October 2020).
- Microsoft Security Response Center. Available online: https://www.microsoft.com/en-us/msrc?rtc=1 (accessed on 15 October 2020).
- Redhat Product Security Center. Available online: https://access.redhat.com/security (accessed on 15 October 2020).
- Mozilla Foundation Security Advisories. Available online: https://www.mozilla.org/en-US/security/advisories/ (accessed on 15 October 2020).
- Secunia Research. Available online: http://secunia.com/advisories/historic/ (accessed on 15 October 2020).
- Liu, Q.; Zhang, Y.; Kong, Y.; Wu, Q. Improving VRSS-based vulnerability prioritization using analytic hierarchy process. J. Syst. Softw. 2012, 85, 1699–1708. [Google Scholar] [CrossRef]
- Google. Severity Guidelines for Security Issues. Available online: http://dev.chromium.org/developers/severity-guidelines (accessed on 15 October 2020).
- Mell, K.P.; Scarfone, S.; Romanosky, T. Common Vulnerability Scoring System. IEEE Secur. Privacy. J. Abbr. 2006, 4, 456–461. [Google Scholar] [CrossRef]
- Common Vulnerability Scoring System v3.1: Specification Document. Available online: https://www.first.org/cvss/v3.1/specification-document (accessed on 7 May 2020).
- Common Vulnerability Scoring System v2.0: Specification Document. Available online: https://www.first.org/cvss/v2/guide (accessed on 7 May 2020).
- Trevor, J. Enterprise Vulnerability Management; ISACA Journal 2017. Available online: https://www.isaca.org/resources/isaca-journal/issues/2017/volume-2/enterprise-vulnerability-management (accessed on 8 May 2020).
- Nyanchama, M. Enterprise Vulnerability Management and Its Role in Information Security Management. Inf. Syst. Secur. 2005, 14, 29–56. [Google Scholar] [CrossRef]
- Skaggs, B.; Blackburn, B.; Manes, G.; Shenoi, S. Network vulnerability analysis. In Proceedings of the 2002 45th Midwest Symposium on Circuits and Systems, Tulsa, OK, USA, 4–7 August 2002; p. III-493. [Google Scholar]
- Farris, K.A.; Shah, A.; Cybenko, G.; Ganesan, R.; Jajodia, S. Vulcon: A System for Vulnerability Prioritization, Mitigation, and Management. ACM Trans. Priv. Secur. 2018, 21, 1–28. [Google Scholar] [CrossRef] [Green Version]
- NIST. Guide for Conducting Risk Assessments; NIST Special Publication 800-30 Revision 1; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012; p. 1.
- Walkowski, M.; Biskup, M.; Szewczyk, A.; Oko, J.; Sujecki, S. Container Based Analysis Tool for Vulnerability Prioritization in Cyber Security Systems. In Proceedings of the 2019 21st International Conference on Transparent Optical Networks (ICTON), Angers, France, 9–13 July 2019; pp. 1–4. [Google Scholar]
- Barrett, M.P. Framework for Improving Critical Infrastructure Cybersecurity; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018.
- Allodi, L. Risk-Based Vulnerability Management Exploiting the Economic Nature of the Attacker to Build Sound and Measurable Vulnerability Mitigation Strategies. Ph.D. Thesis, University of Trento, Trento, Italy, 2015; p. 8. [Google Scholar]
- Fruhwirth, C.; Mannisto, T. Improving CVSS-based vulnerability prioritization and response with context information. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Lake Buena Vista, FL, USA, 15–16 October 2009; pp. 535–544. [Google Scholar]
- Ali, A.; Zavarsky, P.; Lindskog, D.; Ruhl, R. A software application to analyze the effects of temporal and environmental metrics on overall CVSS v2 score. In Proceedings of the 2011 World Congress on Internet Security (WorldCIS-2011), London, UK, 21–23 February 2011; pp. 109–113. [Google Scholar]
- Chen, Y. Stakeholder Value Driven Threat Modeling for Off The Shelf Based Systems. In Proceedings of the International Conference on Software Engineering, Washington, DC, USA, 6–8 November 2007; pp. 91–92. [Google Scholar]
- Eschelbeck, G. The Laws of Vulnerabilities: Which security vulnerabilities really matter? Inf. Secur. Tech. Rep. 2005, 10, 213–219. [Google Scholar] [CrossRef]
- Lai, Y.; Hsia, P. Using the vulnerability information of computer systems to improve the network security. Comput. Commun. 2007, 30, 2032–2047. [Google Scholar] [CrossRef]
- Rieke, R. Modelling and Analysing Network Security Policies in a Given Vulnerability Setting. In Proceedings of the Critical Information Infrastructures Security, Samos Island, Greece, 31 August–1 September 2006; pp. 67–78. [Google Scholar]
- Gartner Peer Insights ‘Voice of the Customer’: Vulnerability Assessment. Available online: https://www.gartner.com/doc/reprints?id=1-1Z87ZU8K&ct=200611&st=sb (accessed on 15 October 2020).
- Yadav, G.; Paul, K. PatchRank: Ordering updates for SCADA systems. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 110–117. [Google Scholar]
- Miura-Ko, R.A.; Bambos, N. SecureRank: A Risk-Based Vulnerability Management Scheme for Computing Infrastructures. In Proceedings of the 2007 IEEE International Conference on Communications, Glasgow, UK, 24–28 June 2007; pp. 1455–1460. [Google Scholar]
- Chen, H.; Liu, J.; Liu, R.; Park, N.; Subrahmanian, V. VEST: A System for Vulnerability Exploit Scoring & Timing. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 6503–6505. [Google Scholar]
- El Arass, M.; Tikito, I.; Souissi, N. Data lifecycles analysis: Towards intelligent cycle. In Proceedings of the 2017 Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 17–19 April 2017. [Google Scholar]
- El Alaoui, I.; Youssef, G. Network Security Strategies in Big Data Context. Procedia Comput. Sci. 2020, 175, 730–736. [Google Scholar] [CrossRef]
- Docker Home Page. Available online: http://www.docker.com (accessed on 24 April 2020).
- Elasticsearch Home Page. Available online: http://www.elastic.co/elasticsearch/ (accessed on 24 April 2020).
- Kibana Home Page. Available online: http://www.elastic.co/kibana (accessed on 24 April 2020).
- National Vulnerability Database. Available online: http://nvd.nist.gov/ (accessed on 24 April 2020).
- Exploit Database. Available online: http://www.exploit-db.com/ (accessed on 24 April 2020).
- Baron, A. Configuration Mmanagement Database State Model. U.S. Patent No. 7,756,828, 13 July 2010. [Google Scholar]
- Nessus Home Page. Available online: https://www.tenable.com/products/nessus (accessed on 24 April 2020).
- OpenVas Scanner Home Page. Available online: https://www.openvas.org/ (accessed on 24 April 2020).
- A Universally Unique IDentifier (UUID). Available online: http://www.ietf.org/rfc/rfc4122.txt (accessed on 24 April 2020).
- Elasticsearch DSL. Available online: https://elasticsearch-dsl.readthedocs.io/en/latest/ (accessed on 18 May 2020).
- Microsoft Azure Free Tier. Available online: https://azure.microsoft.com/free/ (accessed on 18 May 2020).
- Azure Network Round Trip Latency Statistics. Available online: https://docs.microsoft.com/en-us/ azure/networking/azure-network-latency (accessed on 18 May 2020).
- What Is Kubernetes. Available online: https://kubernetes.io/pl/docs/concepts/overview/what-is-kubernetes (accessed on 18 May 2020).
- Peng, C.; Kim, M.; Zhang, Z.; Lei, H. VDN: Virtual machine image distribution network for cloud data centers. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 181–189. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value | Name | Value |
|---|---|---|---|
| Redhat 5 | 18.48% | IBM AIX 6 | 4.27% |
| Redhat 6 | 19.67% | IBM AIX 5 | 5.69% |
| Redhat 7 | 18.96% | IBM AIX 7 | 4.03% |
| Windows Server 2016 | 7.82% | Debian 8 | 2.13% |
| Windows Server 2019 | 8.06% | Debian 9 | 1.41% |
| Windows Server 2012 | 7.58% | Debian 10 | 1.9% |
| Name | Value | Name | Value |
|---|---|---|---|
| Redhat 5 | 6.53% | IBM AIX 6 | 0.8% |
| Redhat 6 | 27.33% | IBM AIX 5 | 1.11% |
| Redhat 7 | 26.46% | IBM AIX 7 | 1.01% |
| Windows Server 2016 | 13.11% | Debian 8 | 2.32% |
| Windows Server 2019 | 8.6% | Debian 9 | 1.8% |
| Windows Server 2012 | 10.03% | Debian 10 | 0.9% |
| Name | Low | Medium | High | N.D. |
|---|---|---|---|---|
| Confidentiality | 25.36% | 22.99% | 23.7% | 27.96% |
| Integrity | 22.99% | 25.12% | 25.12% | 26.78% |
| Availability | 23.93% | 25.83% | 30.33% | 19.90% |
| Name | Low | Medium | High |
|---|---|---|---|
| Confidentiality | 10.19% | 7.82% | 81.99% |
| Integrity | 8.29% | 10.9% | 80.81% |
| Availability | 9.25% | 10.66% | 80.09% |
| Name | Low | Medium | High | N.D. |
|---|---|---|---|---|
| Confidentiality | 76.3% | 9% | 6.88% | 7.82% |
| Integrity | 74.64% | 8.06% | 8.77% | 8.53% |
| Availability | 73.22% | 9.48% | 8.53% | 8.77% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walkowski, M.; Krakowiak, M.; Oko, J.; Sujecki, S. Efficient Algorithm for Providing Live Vulnerability Assessment in Corporate Network Environment. Appl. Sci. 2020, 10, 7926. https://doi.org/10.3390/app10217926
Walkowski M, Krakowiak M, Oko J, Sujecki S. Efficient Algorithm for Providing Live Vulnerability Assessment in Corporate Network Environment. Applied Sciences. 2020; 10(21):7926. https://doi.org/10.3390/app10217926
Chicago/Turabian StyleWalkowski, Michał, Maciej Krakowiak, Jacek Oko, and Sławomir Sujecki. 2020. "Efficient Algorithm for Providing Live Vulnerability Assessment in Corporate Network Environment" Applied Sciences 10, no. 21: 7926. https://doi.org/10.3390/app10217926
APA StyleWalkowski, M., Krakowiak, M., Oko, J., & Sujecki, S. (2020). Efficient Algorithm for Providing Live Vulnerability Assessment in Corporate Network Environment. Applied Sciences, 10(21), 7926. https://doi.org/10.3390/app10217926