Development of Adaptive Formative Assessment System Using Computerized Adaptive Testing and Dynamic Bayesian Networks

Abstract
:1. Introduction
2. Research Objectives
3. Materials and Methods
3.1. Materials
3.2. Calibartion and Construction of the Item Bank for a Simulation Study and an Application Study
3.3. A Simulation Study
3.4. An Application Study
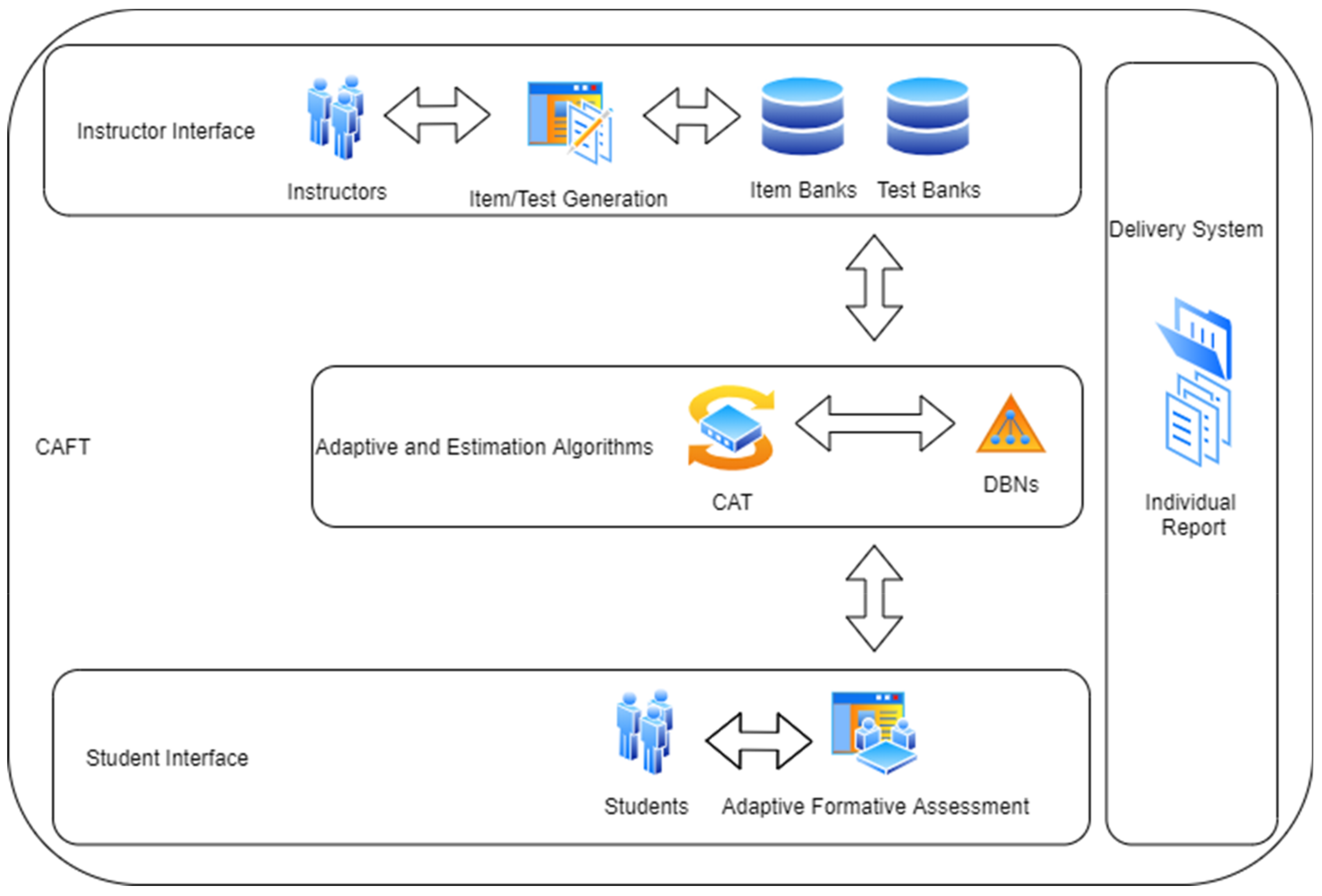
3.5. Methodology
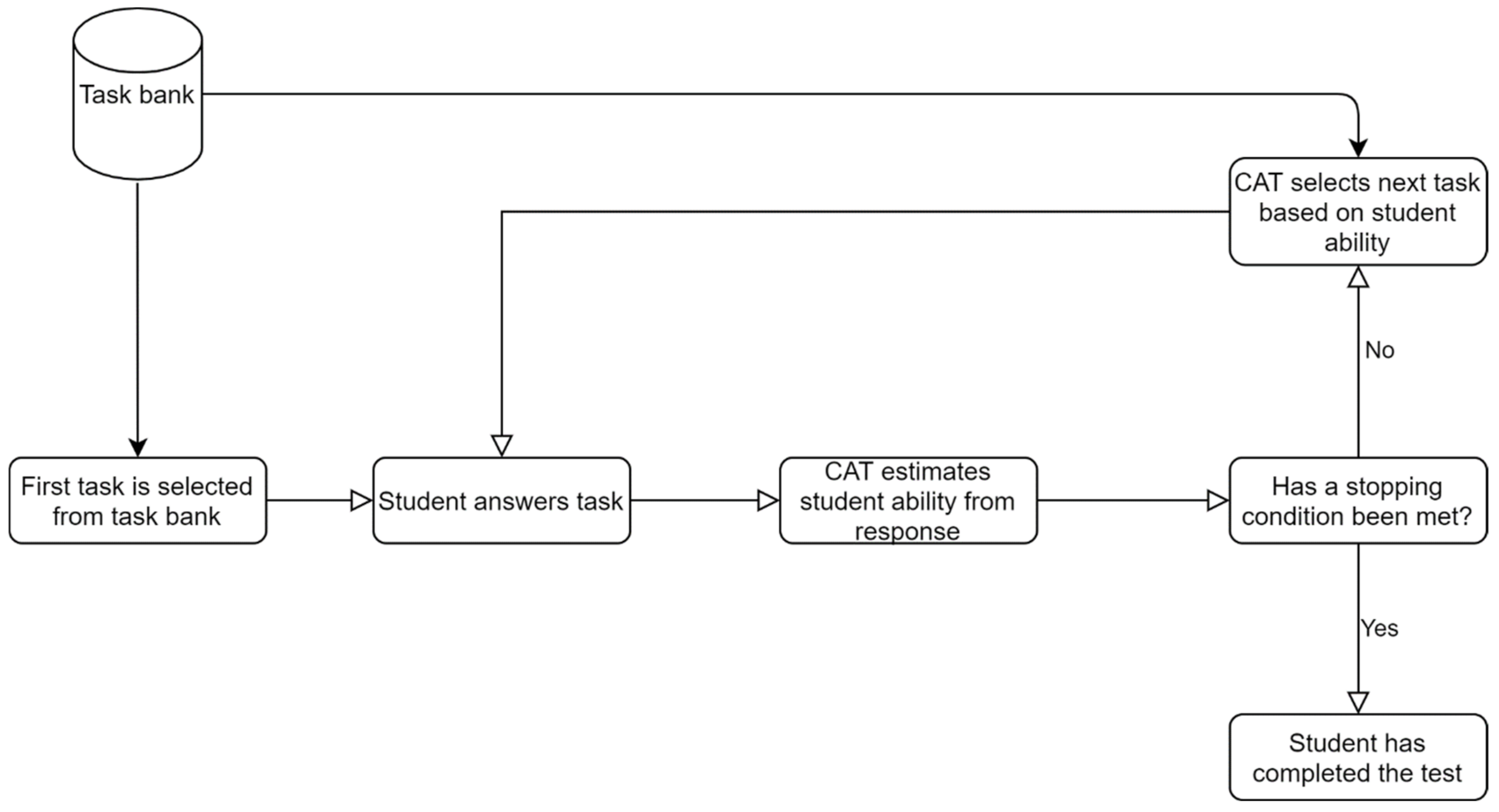
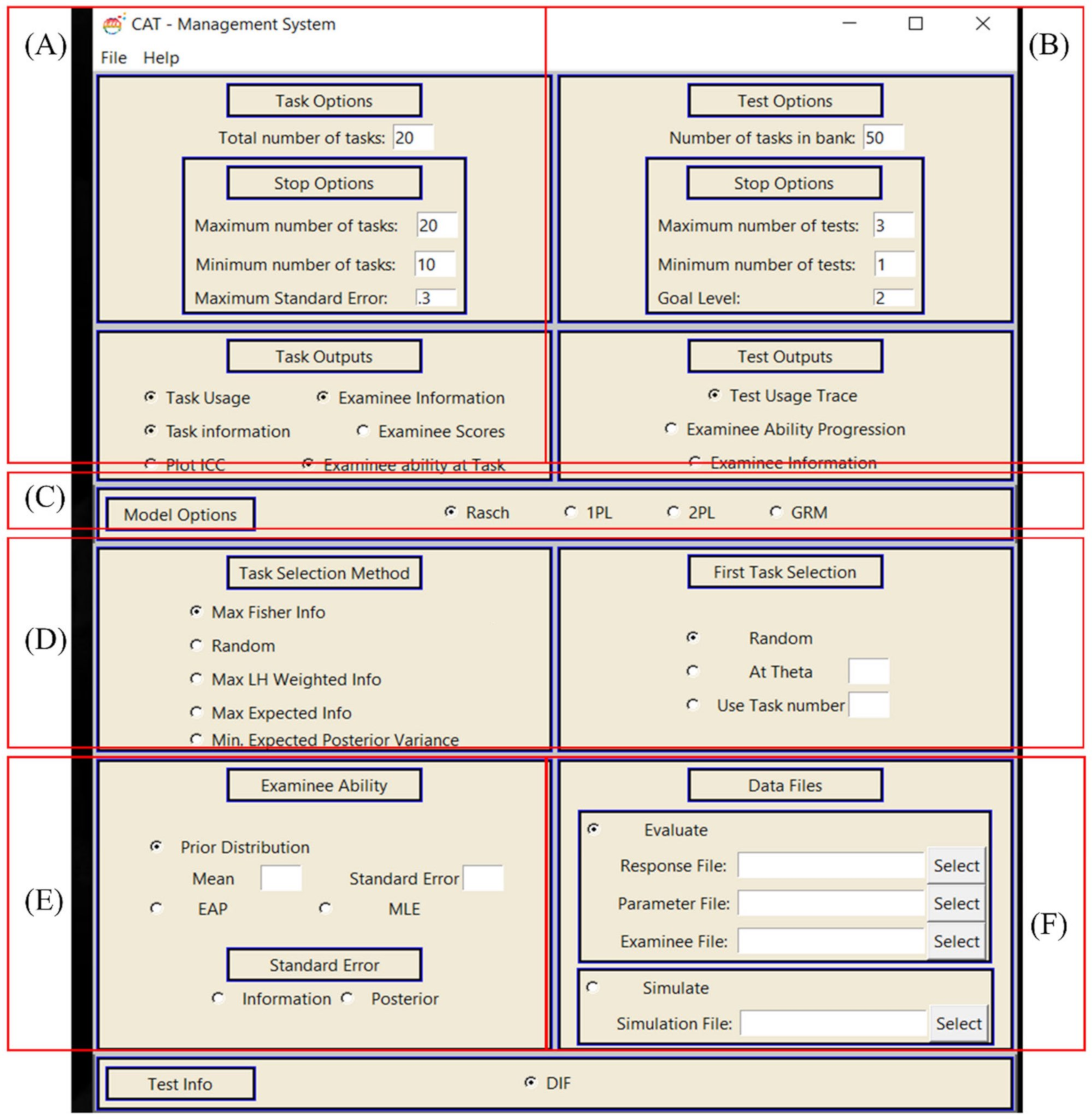
3.5.1. Statistical Functions of the CAFT Software
3.5.2. Dynamic Bayesian Network for Diagnostic Learning Progression under the Adaptive Formative Assessment System
- Initial probability matrix of the hidden state at the first time point, P(X1);
- Transition probability matrix, P(Xt| X1:t − 1);
- Conditional probability matrix, P(Yt| Xt).
- Smoothing: The process of monitoring states at previous time t − 1 given evidence at time t;
- Filtering: The process of monitoring states at time t given evidence at time t;
- Prediction: The process of monitoring states at future time t + 1 given evidence at time t.
4. Results
4.1. Item Bank Evalutioan
4.2. Simluation Study
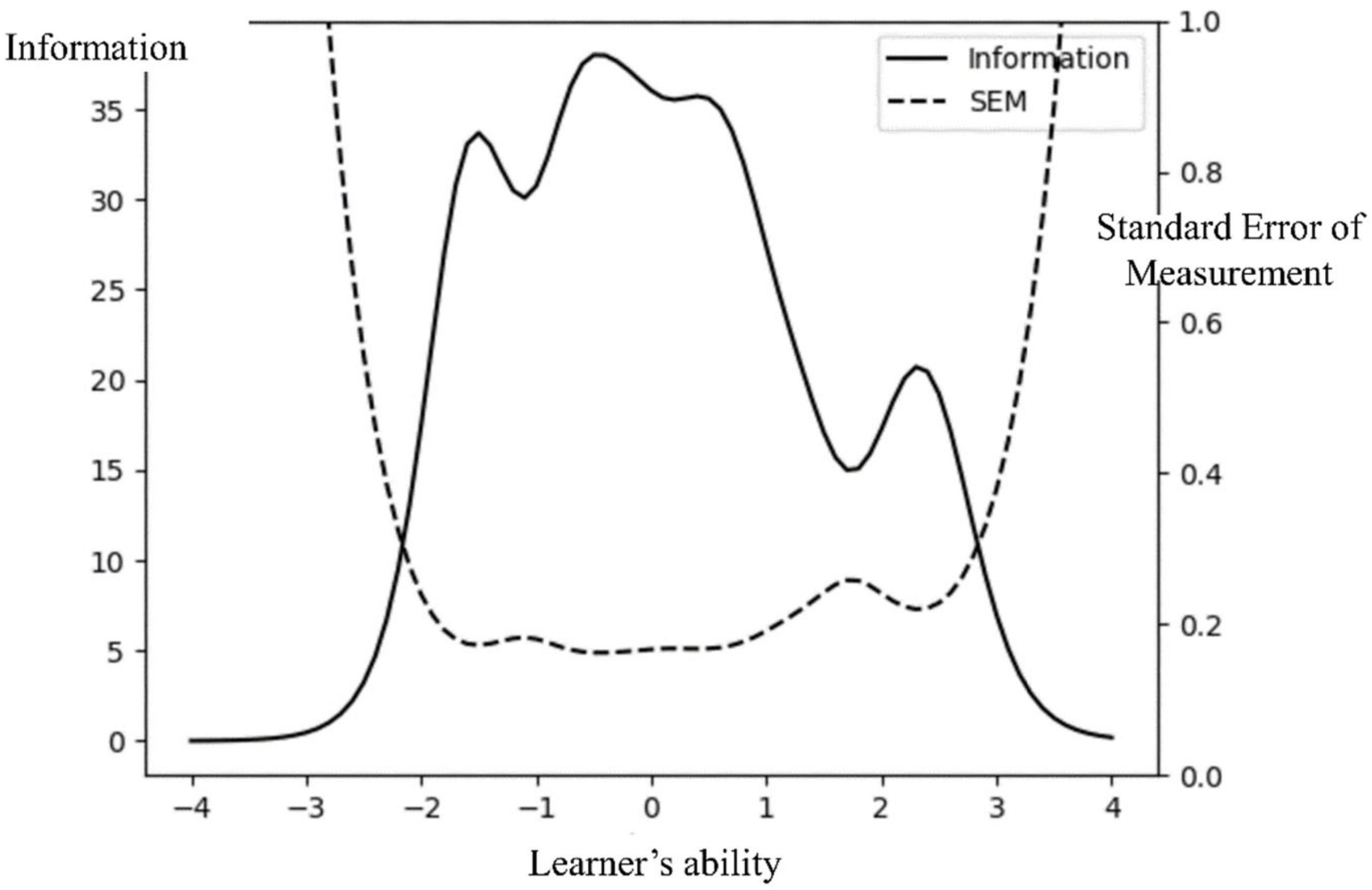
4.2.1. Validity and Efficiency Measures
4.2.2. Reliability Measures and Number of Items Used
4.3. Real Data Study
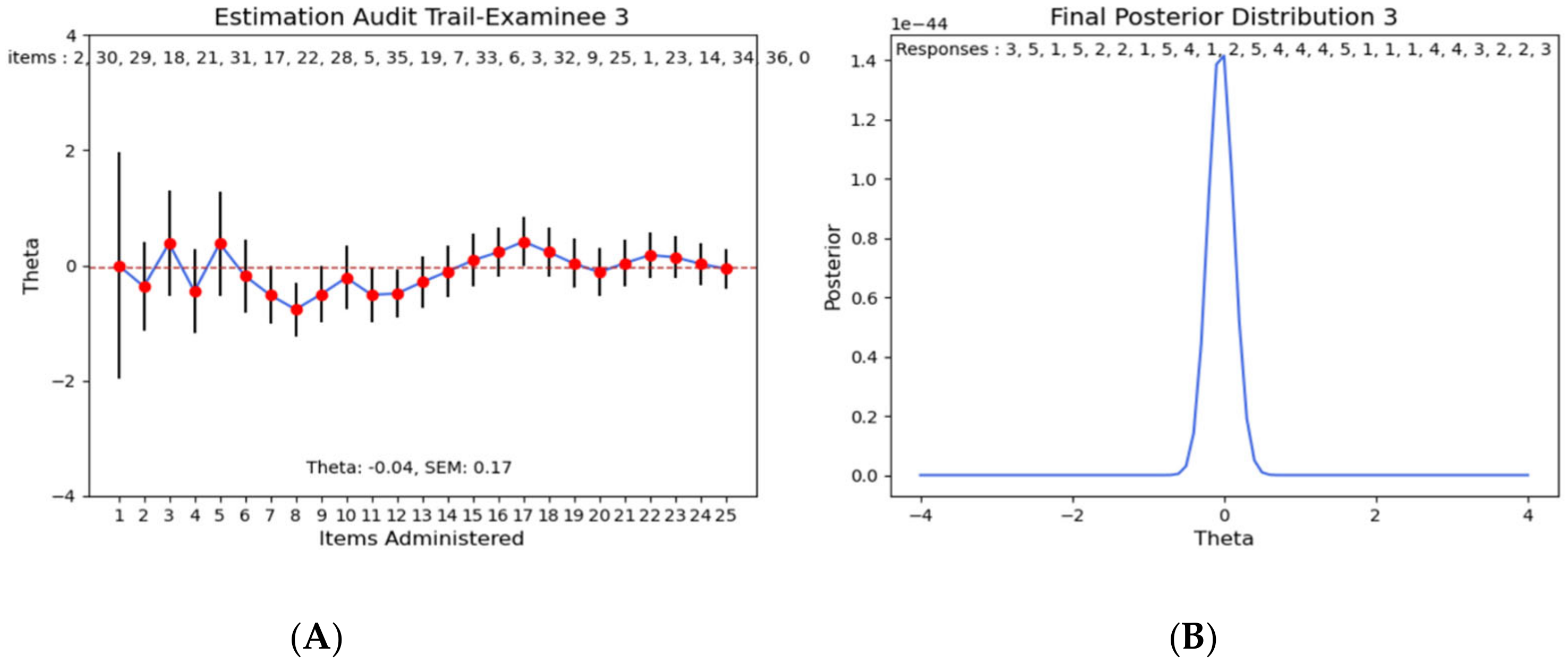
4.3.1. CAT Process in Application Study
4.3.2. Validity Measures Using Real Data
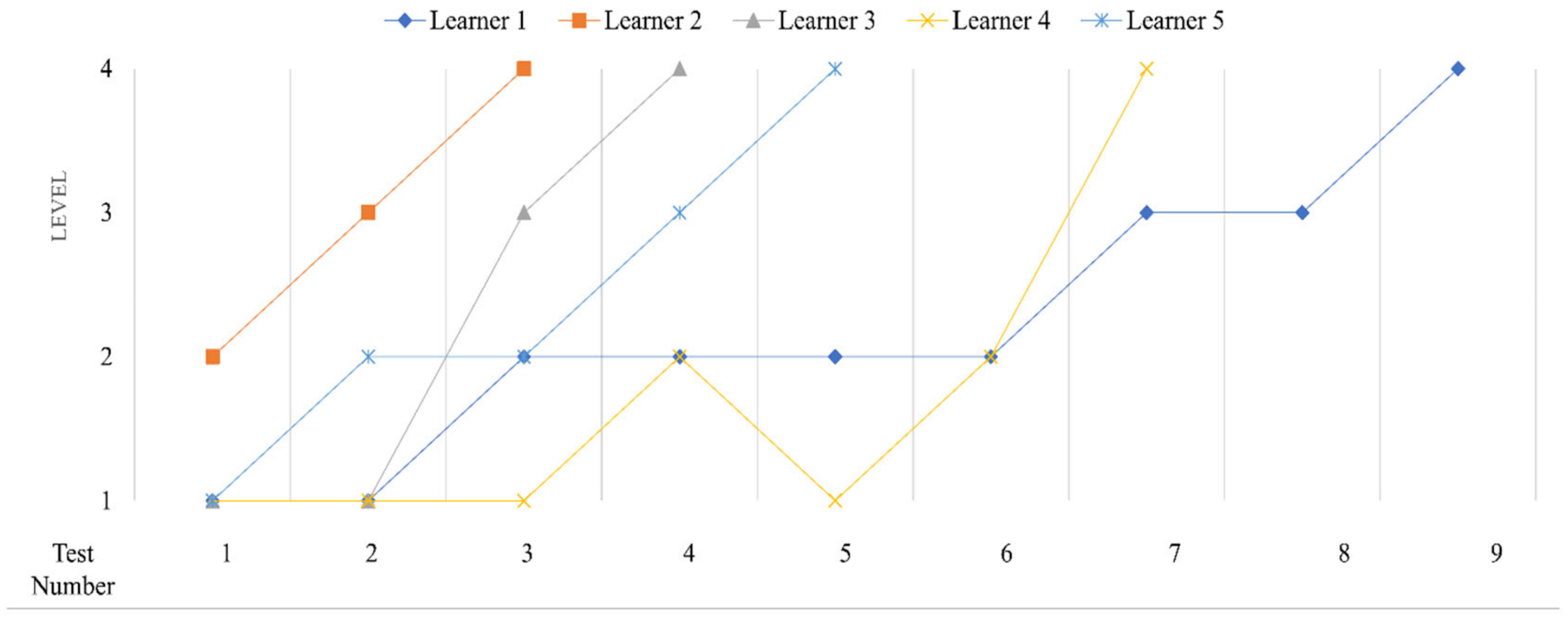
4.4. Estimation of Individual Learning Progression Using DBNs
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tiago, M.F.; Paula, F.L. Towards Next Generation Teaching, Learning, and Context-Aware Applications for Higher Education: A Review on Blockchain, IoT, Fog and Edge Computing Enabled Smart Campuses and Universities. Appl. Sci. 2019, 9, 4479. [Google Scholar]
- Alberto, R.F.; Rafael, M.C.; Faraón, L.L. Computational Characterization of Activities and Learners in a Learning System. Appl. Sci. 2020, 10, 2208. [Google Scholar]
- Conejo, R.; Guzmán, E.; Millán, E.; Trella, M.; Pérez-De-La-Cruz, J.L.; Ríos, A. SIETTE: A web-based tool for adaptive testing. Int. Artifi. Intelli. Educ. 2004, 14, 29–61. [Google Scholar]
- McCallum, S.; Milner, M.M. The effectiveness of formative assessment: Student views and staff reflections. Assess. Eval. High. Educ. 2020, 1–16. [Google Scholar]
- Bennett, R.E. Formative assessment: A critical review. Assess. Educ. 2011, 18, 5–25. [Google Scholar] [CrossRef]
- Black, P.; Wiliam, D. Assessment and classroom learning. Assess. Educ. 1998, 5, 7–74. [Google Scholar] [CrossRef]
- Briggs, D.C.; Ruiz-Primo, M.A.; Furtak, E.; Shepard, L.; Yin, Y. Meta–analytic methodology and inferences about the efficacy of formative assessment. Educ. Meas. 2012, 31, 13–17. [Google Scholar] [CrossRef]
- Choi, Y.; Rupp, A.; Gushta, M.; Sweet, S. Modeling Learning Trajectories with Epistemic Network Analysis: An Investigation of a Novel Analytic Method for Learning Progressions in Epistemic Games; National Council on Measurement in Education: Philadelphia, PA, USA, 2020; pp. 1–39. [Google Scholar]
- Walker, D.J.; Topping, K.; Rodrigues, S. Student reflections on formative e–assessment: Expectations and perceptions. Learn. Media Technol. 2008, 33, 221–234. [Google Scholar] [CrossRef]
- Brown, L.I.; Bristol, L.; De Four-Babb, J.; Conrad, D.A. National Tests and Diagnostic Feedback: What Say Teachers in Trinidad and Tobago? J. Educ. Res. 2014, 107, 241–251. [Google Scholar] [CrossRef]
- Havnes, A.; Smith, K.; Dysthe, O.; Ludvigsen, K. Formative assessment and feedback: Making learning visible. Stud. Educ. Eval. 2012, 38, 21–27. [Google Scholar] [CrossRef]
- Schez-Sobrino, S.; Gmez-Portes, C.; Vallejo, D.; Glez-Morcillo, C.; Miguel, A.R. An Intelligent Tutoring System to Facilitate the Learning of Programming through the Usage of Dynamic Graphic Visualizations. Appl. Sci. 2020, 10, 1518. [Google Scholar] [CrossRef] [Green Version]
- Khan, R.A.; Jawaid, M. Technology Enhanced Assessment (TEA) in COVID 19 Pandemic. Pak. J. Med. Sci. 2020, 36, S108. [Google Scholar] [CrossRef] [PubMed]
- West, P.; Rutstein, D.W.; Mislevy, R.J.; Liu, J.; Choi, Y.; Levy, R.; Behrens, J.T. A Bayesian Network Approach to Modeling Learning Progressions and Task Performance. CRESST Report No 776. National Center for Research on Evaluation, Standards, and Student Testing. Available online: https://files.eric.ed.gov/fulltext/ED512650.pdf (accessed on 19 August 2010).
- Lee, H.; Choi, Y. The Influence of Human Resource Management Strategy on Learning Achievement in Online Learning Environment: The Moderated Mediating Effect of Metacognition by Extraneous Cognitive Load. J. Korean Assoc. Educ. Inf. Media 2019, 25, 853–872. [Google Scholar]
- Nagandla, K.; Sulaiha, S.; Nallia, S. Online formative assessments: Exploring their educational value. JAMP 2018, 6, 51. [Google Scholar] [PubMed]
- Han, K.T.; Simul, C.A.T. Windows software for simulating computerized adaptive test administration. Appl. Psychol. Meas. 2012, 36, 64–66. [Google Scholar] [CrossRef]
- Kingsbury, G.G.; Zara, A.R. Procedures for selecting items for computerized adaptive tests. Appl. Meas. Educ. 1989, 2, 359–375. [Google Scholar] [CrossRef]
- Han, K.T. An efficiency balanced information criterion for item selection in computerized adaptive testing. J. Educ. Meas. 2012, 49, 225–246. [Google Scholar] [CrossRef]
- Embertson, S.E.; Reise, S.P. Item Response Theory for Psychologists, 1st ed.; Psychology Press: Hove, East Sussex, UK, 2000. [Google Scholar]
- Veerkamp, W.J.; Berger, M.P. Some new item selection criteria for adaptive testing. J. Educ. Behav. Stat. 1997, 22, 203–226. [Google Scholar] [CrossRef] [Green Version]
- Han, K.T. Maximum likelihood score estimation method with fences for short-length tests and computerized adaptive tests. Appl. Psychol. Meas. 2016, 40, 289–301. [Google Scholar] [CrossRef]
- Chang, H.H.; Ying, Z.A. Global information approach to computerized adaptive testing. Appl. Psychol. Meas. 1996, 20, 213–229. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.H.; Ying, Z. A-stratified multistage computerized adaptive testing. Appl. Psychol. Meas. 1999, 23, 211–222. [Google Scholar] [CrossRef]
- Choi, Y.; Mislevy, R. Dynamic Bayesian Inference Network and hidden Markov Model for Modeling Learning Progression over Multiple Time Points. Ph.D. Thesis, University of Maryland at College Park, College Park, MD, USA, 2012. [Google Scholar]
- Revy, J. Two-Phase Updating of Student Models Based on Dynamic Belief Networks. In Intelligent Tutoring Systems: 4th International Conference ITS’98; San Antonio, TX, USA, 16–19 August 1998, Springer: Berlin/Heidelberg, Germany, 1998; pp. 274–283. [Google Scholar]
- Reye, J.A. Belief Net Backbone for Student Modeling Intelligent Tutoring System: Intelligent Tutoring Systems; Frasson, C., Gauthier, G., Lesgold, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1996; pp. 596–604. [Google Scholar]
- Yen, W.M. Scaling performance assessments: Strategies for managing local item dependence. J. Educ. Meas. 1993, 30, 187–213. [Google Scholar] [CrossRef]
- Orlando, M.; Thissen, D. Further investigation of the performance of S-X2: An item fit index for use with dichotomous item response theory models. Appl. Psychol. Meas. 2003, 27, 289–298. [Google Scholar] [CrossRef]
- Samejima, F. Estimation of Latent Ability Using a Response Pattern of Graded Scores. ETS Res. Rep. Ser. 1968, 1, i-169. [Google Scholar]
- Barrada, J.R.; Olea, J.; Ponsoda, V.; Abad, F.J. Incorporating randomness in the fisher information for improving item-exposure control in CATs. Br. J. Math. Stat. Psychol. 2008, 61, 493–513. [Google Scholar] [CrossRef]
- Bock, R.D.; Aitkin, M. Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika 1981, 46, 443–459. [Google Scholar] [CrossRef]
- Owen, R.J. A Bayesian approach to tailored testing. ETS 1969, 1969, 69–92. [Google Scholar] [CrossRef]
- Stocking, M.L.; Lewis, C. Controlling item exposure conditional on ability in computerized adaptive testing. ETS 1995, 23, 57–75. [Google Scholar] [CrossRef]
- Almond, R.G.; DiBello, L.V.; Moulder, B.; Zapata-Rivera, J.D. Modeling diagnostic assessments with Bayesian networks. J. Educ. Meas. 2007, 44, 341–359. [Google Scholar] [CrossRef]
- Almond, R.G.; Mislevy, R.J.; Steinberg, L.S.; Williamson, D.M.; Yan, D. Bayesian Networks in Educational Assessment; Springer: New York, NY, USA, 2015. [Google Scholar]
- Choi, Y.; Cho, Y.I. Learning Analytics Using Social Network Analysis and Bayesian Network Analysis in Sustainable Computer-Based Formative Assessment System. Sustainability 2020, 12, 7950. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Academic Press: Abingdon, VA, USA, 2013. [Google Scholar]
- Nguyen-Thin, L. A Classification of Adaptive Feedback in Educational Systems for Programming. Systems 2016, 4, 22. [Google Scholar] [CrossRef] [Green Version]
- William, V.C.; Milton, R.C.; Xavier, P.P. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Appl. Sci. 2020, 10, 5371. [Google Scholar] [CrossRef]
- Shaojie, Q.; Kan, L.; Bo, W.; Yongchao, W. Predicting Student Achievement Based on Temporal Learning Behavior in MOOCs. Appl. Sci. 2019, 9, 5539. [Google Scholar] [CrossRef] [Green Version]
- Swanson, L.; Stocking, M.L. A model and heuristic for solving very large item selection problems. Appl. Psychol. Meas. 1993, 17, 151–166. [Google Scholar] [CrossRef] [Green Version]
- Van Der Linden, W.J. A comparison of item-selection methods for adaptive tests with content constraints. J. Educ. Meas. 2005, 42, 283–302. [Google Scholar] [CrossRef]
- Nichols, P.D.; Chipman, S.F.; Brennan, R.L. Cognitively Diagnostic Assessment; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1995. [Google Scholar]
- Corcoran, T.; Mosher, F.; Rogat, A. Learning Progressions in Science: An Evidence-Based Approach to Reform; Consortium for Policy Research in Education: Philadelphia, PA, USA, 2009. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Percent (%) | Count | ||
|---|---|---|---|
| Educational Level | 1 year | 66.7 | 80 |
| 2 years | 12.5 | 15 | |
| 3 years | 12.5% | 15 | |
| 4 years | 8.3 | 10 | |
| Age | 20 | 25.0 | 30 |
| 30 | 37.5 | 45 | |
| 40 | 16.7 | 20 | |
| 50 | 20.8 | 25 | |
| Gender | Male | 40.0 | 48 |
| Female | 60.0 | 72 | |
| Job Status | Full time | 36.7 | 44 |
| Part time | 23.3 | 28 | |
| No | 40.0 | 48 |
| Stopping Rule | CBIAS | CRMSE | T |
|---|---|---|---|
| None | −0.004 | 0.114 | 1 |
| SE (theta) < 0.2 | 0.002 | 0.147 | 0.69 |
| SE (theta) < 0.3 | 0.006 | 0.217 | 0.39 |
| SE (theta) < 0.4 | 0.008 | 0.311 | 0.28 |
| Stopping Rule | Number of Items Used | Reliability | r | |
|---|---|---|---|---|
| Mean | SD | |||
| None | 40 | 0 | 0.98 | 1 |
| SE (theta) < 0.2 | 27.67 | 12.01 | 0.95 | 0.97 ** |
| SE (theta) < 0.3 | 15.80 | 8.93 | 0.92 | 0.94 ** |
| SE (theta) < 0.4 | 11.23 | 4.92 | 0.89 | 0.91 ** |
| Stopping Rule | Midterm Exam | Final Exam |
|---|---|---|
| None | 0.83 | 0.69 |
| SE (theta) < 0.3 | 0.81 | 0.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.; McClenen, C. Development of Adaptive Formative Assessment System Using Computerized Adaptive Testing and Dynamic Bayesian Networks. Appl. Sci. 2020, 10, 8196. https://doi.org/10.3390/app10228196
Choi Y, McClenen C. Development of Adaptive Formative Assessment System Using Computerized Adaptive Testing and Dynamic Bayesian Networks. Applied Sciences. 2020; 10(22):8196. https://doi.org/10.3390/app10228196
Chicago/Turabian StyleChoi, Younyoung, and Cayce McClenen. 2020. "Development of Adaptive Formative Assessment System Using Computerized Adaptive Testing and Dynamic Bayesian Networks" Applied Sciences 10, no. 22: 8196. https://doi.org/10.3390/app10228196
APA StyleChoi, Y., & McClenen, C. (2020). Development of Adaptive Formative Assessment System Using Computerized Adaptive Testing and Dynamic Bayesian Networks. Applied Sciences, 10(22), 8196. https://doi.org/10.3390/app10228196