Image Anomaly Detection Using Normal Data Only by Latent Space Resampling


Abstract
:1. Introduction
- We propose a novel method only using normal data for image anomaly detection. It effectively excludes the anomalous components in the latent space and avoids the unwanted reconstruction of the anomalous part, which achieves better detection results.
- We propose a new method for anomaly score. The high anomaly scores are concentrated in the regions where anomalies are present, which will reduce the noise introduced by the reconstruction and improve precision.
2. Related Work
2.1. Feature Extraction Based Method
2.2. Probability Based Method
2.3. Reconstruction Based Method
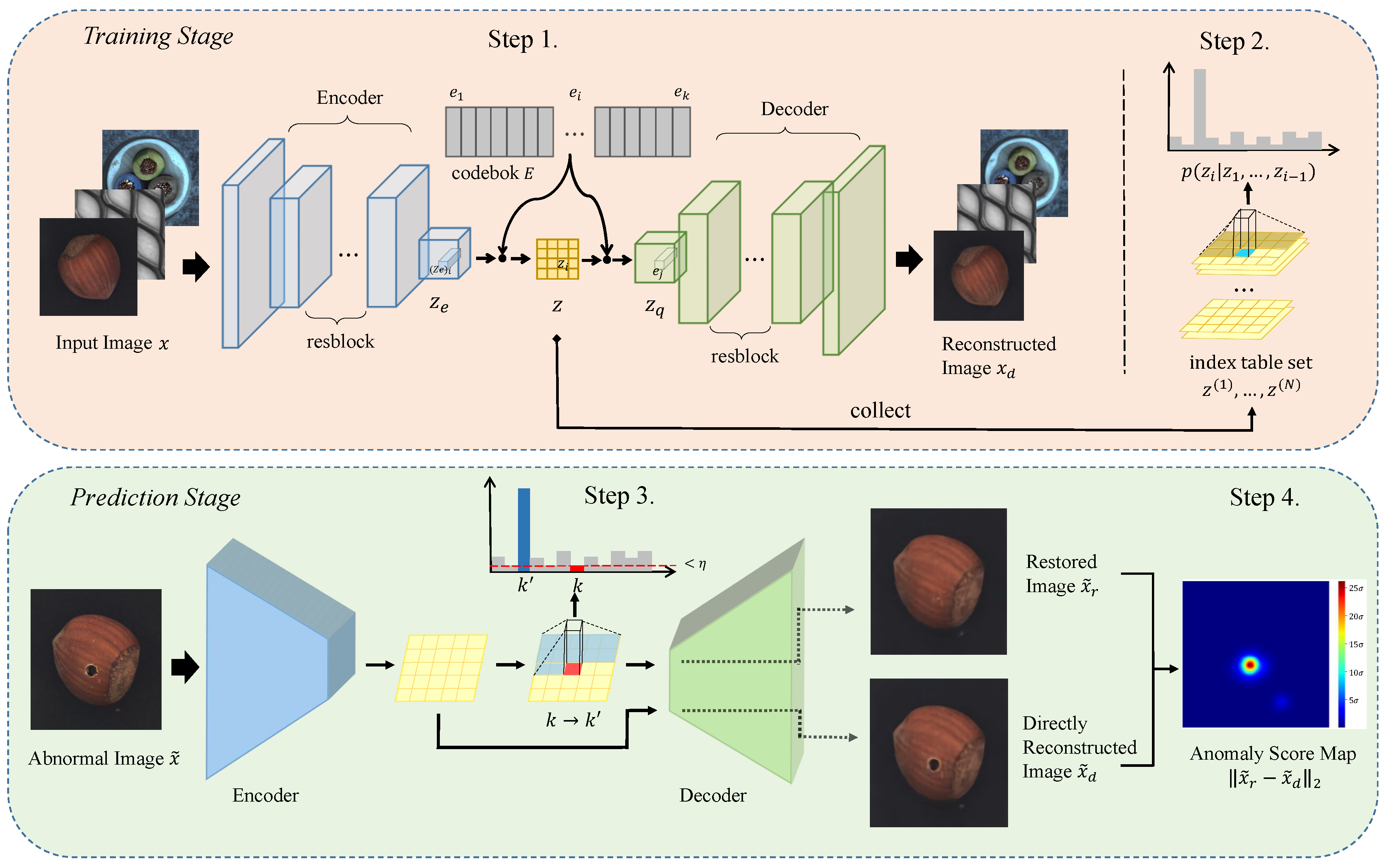
3. Method
3.1. Structuring Latent Space
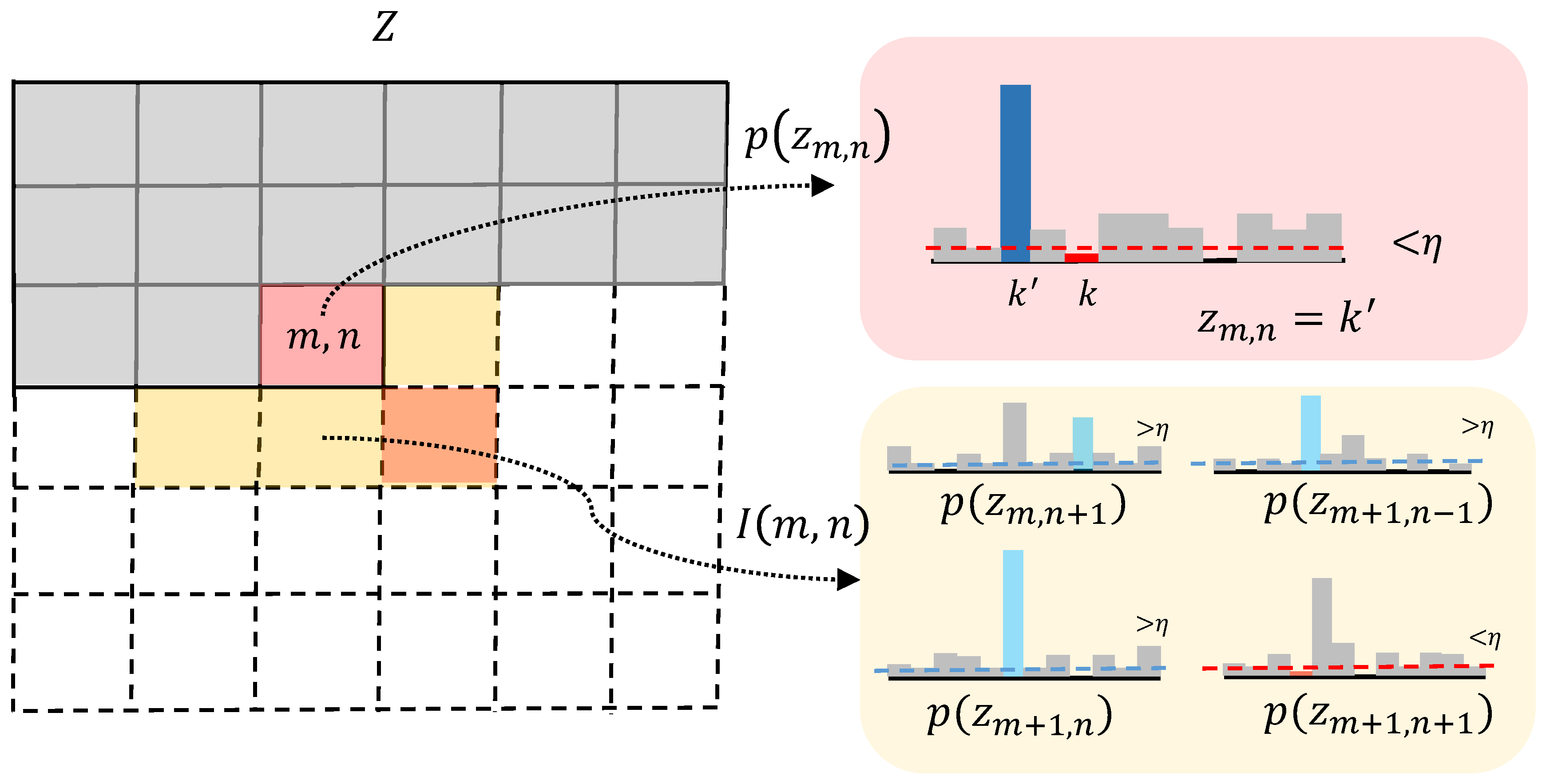
3.2. Probabilistic Modeling for Latent Space
3.3. Resampling Operation
3.4. Detection of Anomalies
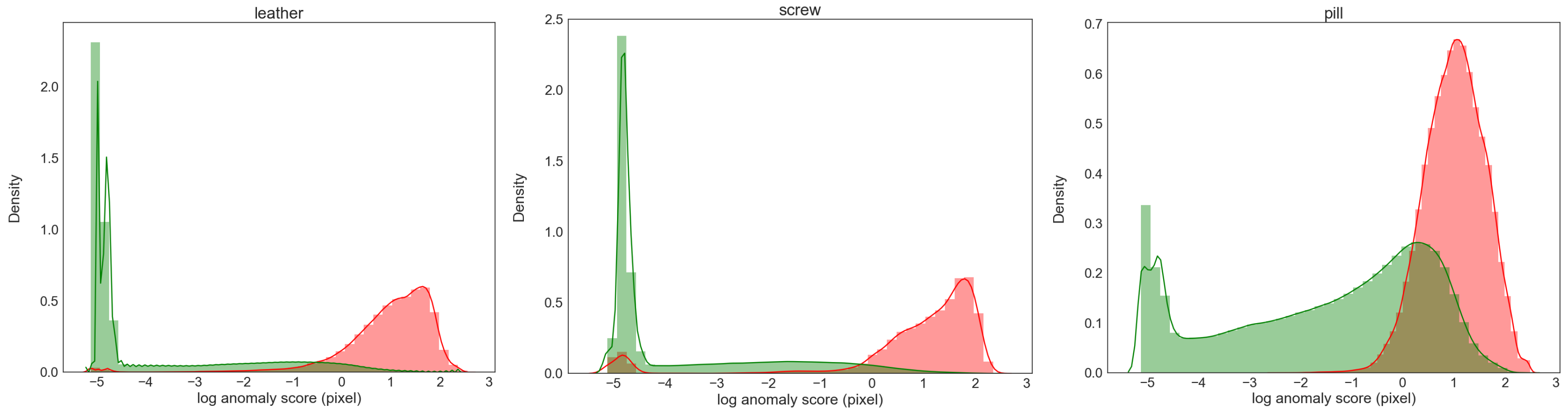
4. Experiment
4.1. Dataset
4.2. Evaluation Metric
4.3. Experimental Setup
4.3.1. Data Augmentation
4.3.2. Network Setup
4.3.3. Hyperparameter Setup
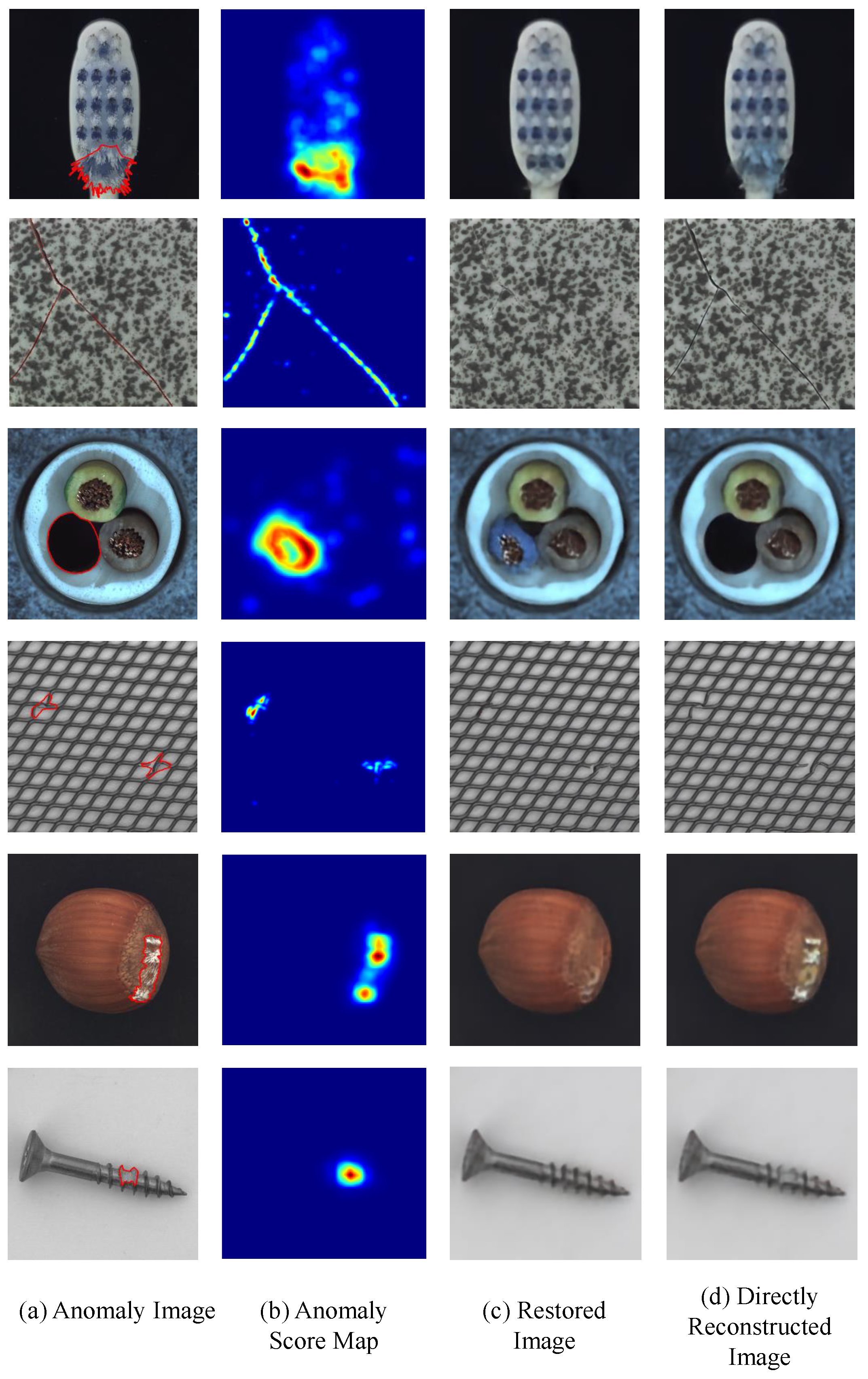
4.4. Comparison Results
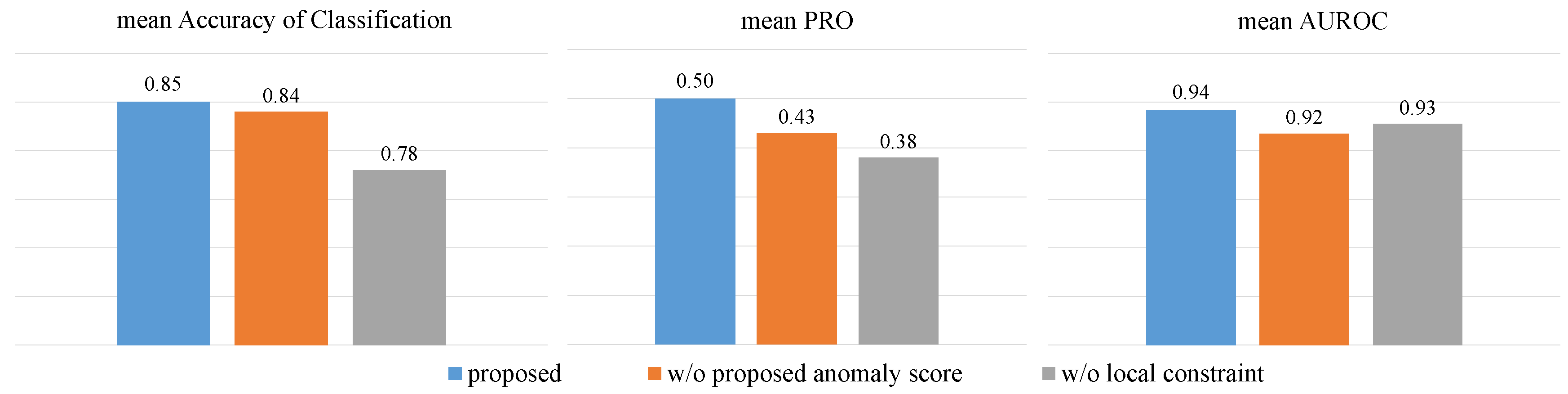
4.5. Ablation Experiment
5. Conclusions
- Using VQ-VAE to construct a discrete latent space. Then, the latent space distribution of the normal image is modeled using PixelSNAIL.
- During anomaly detection, the discrete latent code out of the normal distribution is resampled by PixelSNAIL. After this resampling, the index table is reconstructed to a restored image by the decoder. The greater the distance between the restored image and the image reconstructed directly using VQ-VAE, the more likely the region is anomalous.
- The method is evaluated on the industrial inspection dataset MVTec AD that contains 10 objects and five textures with 73 various anomalies. The results show that the proposed method achieves better performance compared to other methods.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ehret, T.; Davy, A.; Morel, J.M.; Delbracio, M. Image Anomalies: A Review and Synthesis of Detection Methods. J. Math. Imaging Vis. 2019, 61, 710–743. [Google Scholar] [CrossRef] [Green Version]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.v.d. Deep Learning for Anomaly Detection: A Review. arXiv 2020, arXiv:2007.02500. [Google Scholar]
- Markou, M.; Singh, S. Novelty detection: A review—Part 1: Statistical approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Bennamoun, M.; Bodnarova, A. Automatic visual inspection and flaw detection in textile materials: Past, present and future. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 14 October 1998. [Google Scholar] [CrossRef]
- Voorhees, H. Finding Texture Boundaries in Images; Technical Report; Computer Science and Artificial Intelligence Lab (CSAIL): Cambridge, MA, USA, 1987. [Google Scholar]
- Amet, A.L.; Ertuzun, A.; Erçil, A. Texture defect detection using subband domain co-occurrence matrices. In Proceedings of the IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Tucson, AZ, USA, 5–7 April 1998; pp. 205–210. [Google Scholar] [CrossRef]
- Zimmerer, D.; Kohl, S.A.; Petersen, J.; Isensee, F.; Maier-Hein, K.H. Context-encoding variational autoencoder for unsupervised anomaly detection. arXiv 2018, arXiv:1812.05941. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP), SCITEPRESS, Prague, Czech, 25–27 February 2019. [Google Scholar] [CrossRef]
- Baur, C.; Wiestler, B.; Albarqouni, S.; Navab, N. Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images; International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2018; pp. 161–169. [Google Scholar] [CrossRef] [Green Version]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 500–501. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6306–6315. [Google Scholar]
- Chen, X.; Mishra, N.; Rohaninejad, M.; Abbeel, P. Pixelsnail: An improved autoregressive generative model. In Proceedings of the International Conference on Machine Learning (ICML), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-Based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Liu, Y.H.; Lin, S.H.; Hsueh, Y.L.; Lee, M.J. Automatic target defect identification for TFT-LCD array process inspection using kernel FCM-based fuzzy SVDD ensemble. Expert Syst. Appl. 2009, 36, 1978–1998. [Google Scholar] [CrossRef]
- Tout, K.; Cogranne, R.; Retraint, F. Fully automatic detection of anomalies on wheels surface using an adaptive accurate model and hypothesis testing theory. In Proceedings of the European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016. [Google Scholar] [CrossRef]
- Mao, T.; Ren, L.; Yuan, F.; Li, C.; Zhang, L.; Zhang, M.; Chen, Y. Defect Recognition Method Based on HOG and SVM for Drone Inspection Images of Power Transmission Line. In Proceedings of the International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Shenzhen, China, 9–11 May 2019. [Google Scholar] [CrossRef]
- Liu, K.; Wang, H.; Chen, H.; Qu, E.; Tian, Y.; Sun, H. Steel Surface Defect Detection Using a New Haar–Weibull-Variance Model in Unsupervised Manner. IEEE Trans. Instrum. Meas. 2017, 66, 2585–2596. [Google Scholar] [CrossRef]
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly detection in nanofibrous materials by cnn-based self-similarity. Sensors 2018, 18, 209. [Google Scholar] [CrossRef] [Green Version]
- Ruff, L.; Görnitz, N.; Deecke, L.; Siddiqui, S.; Vandermeulen, R.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the International Conference on Machine Learning (ICML), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Du, B.; Zhang, L. Random-Selection-Based Anomaly Detector for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1578–1589. [Google Scholar] [CrossRef]
- Xie, X.; Mirmehdi, M. TEXEMS: Texture Exemplars for Defect Detection on Random Textured Surfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1454–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ozdemir, S.; Ercil, A. Markov random fields and Karhunen-Loeve transforms for defect inspection of textile products. In Proceedings of the IEEE Conference on Emerging Technologies and Factory Automation, (ETFA), Kauai, HI, USA, 18–21 November 1996. [Google Scholar] [CrossRef]
- Böttger, T.; Ulrich, M. Real-time texture error detection on textured surfaces with compressed sensing. Pattern Recognit. Image Anal. 2016, 26, 88–94. [Google Scholar] [CrossRef]
- Candès, E.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef] [Green Version]
- Richter, J.; Streitferdt, D. Deep Learning Based Fault Correction in 3D Measurements of Printed Circuit Boards. In Proceedings of the IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), UBC, Vancouver, BC, Canada, 1–3 November 2018. [Google Scholar] [CrossRef]
- Van den Oord, A.; Kalchbrenner, N.; Espeholt, L.; Vinyals, O.; Graves, A. Conditional image generation with pixelcnn decoders. In Proceedings of the Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Shafaei, A.; Schmidt, M.; Little, J.J. A less biased evaluation of out-of-distribution sample detectors. arXiv 2018, arXiv:1809.04729. [Google Scholar]
- Bruckstein, A.M.; Donoho, D.L.; Elad, M. From Sparse Solutions of Systems of Equations to Sparse Modeling of Signals and Images. SIAM 2009, 51, 34–81. [Google Scholar] [CrossRef] [Green Version]
- Boracchi, G.; Carrera, D.; Wohlberg, B. Novelty detection in images by sparse representations. In Proceedings of the IEEE Symposium on Intelligent Embedded Systems (IES), Orlando, FL, USA, 9–12 December 2014. [Google Scholar] [CrossRef]
- Nair, T.; Precup, D.; Arnold, D.L.; Arbel, T. Exploring uncertainty measures in deep networks for Multiple sclerosis lesion detection and segmentation. Med. Image Anal. 2020, 59, 101557. [Google Scholar] [CrossRef]
- Venkataramanan, S.; Peng, K.C.; Singh, R.V.; Mahalanobis, A. Attention Guided Anomaly Detection and Localization in Images. arXiv 2019, arXiv:1911.08616. [Google Scholar]
- Liu, W.; Li, R.; Zheng, M.; Karanam, S.; Wu, Z.; Bhanu, B.; Radke, R.J.; Camps, O. Towards Visually Explaining Variational Autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Haselmann, M.; Gruber, D.P.; Tabatabai, P. Anomaly Detection Using Deep Learning Based Image Completion. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1237–1242. [Google Scholar] [CrossRef] [Green Version]
- Dehaene, D.; Frigo, O.; Combrexelle, S.; Eline, P. Iterative energy-based projection on a normal data manifold for anomaly localization. arXiv 2020, arXiv:2002.03734. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar] [CrossRef] [Green Version]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-supervised Anomaly Detection via Adversarial Training. In Computer Vision–ACCV 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 622–637. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Proposed | CAVGA- [34] | [9] | [9] | AnoGAN [39] | CNNFD [21] | TI [26] | |
|---|---|---|---|---|---|---|---|---|
| Textures | Carpet | 0.71 | 0.73 | 0.67 | 0.50 | 0.49 | 0.63 | 0.59 |
| Grid | 0.91 | 0.75 | 0.69 | 0.78 | 0.51 | 0.67 | 0.50 | |
| Wood | 0.96 | 0.85 | 0.83 | 0.74 | 0.68 | 0.84 | 0.71 | |
| Leather | 0.96 | 0.71 | 0.46 | 0.44 | 0.52 | 0.67 | 0.50 | |
| Tile | 0.95 | 0.70 | 0.52 | 0.77 | 0.51 | 0.71 | 0.72 | |
| Objects | Bottle | 0.99 | 0.89 | 0.88 | 0.80 | 0.69 | 0.53 | - |
| Cable | 0.72 | 0.63 | 0.61 | 0.56 | 0.53 | 0.61 | - | |
| Capsule | 0.68 | 0.83 | 0.61 | 0.62 | 0.58 | 0.41 | - | |
| Hazelnut | 0.94 | 0.84 | 0.54 | 0.88 | 0.50 | 0.49 | - | |
| Metal Nut | 0.83 | 0.67 | 0.54 | 0.73 | 0.50 | 0.65 | - | |
| Pill | 0.68 | 0.88 | 0.60 | 0.62 | 0.62 | 0.46 | - | |
| Screw | 0.80 | 0.77 | 0.51 | 0.69 | 0.35 | 0.43 | - | |
| Toothbrush | 0.92 | 0.91 | 0.74 | 0.98 | 0.57 | 0.57 | - | |
| Transistor | 0.73 | 0.73 | 0.52 | 0.71 | 0.67 | 0.58 | - | |
| Zipper | 0.97 | 0.87 | 0.80 | 0.80 | 0.59 | 0.54 | - | |
| mean | 0.85 | 0.78 | 0.63 | 0.71 | 0.55 | 0.59 | 0.60 |
| Category | Proposed | CAVGA- [34] | VAE with Attention [35] | [9] | [9] | AnoGAN [39] | CNNFD [21] | |
|---|---|---|---|---|---|---|---|---|
| Textures | Carpet | 0.47 | 0.71 | 0.10 | 0.69 | 0.38 | 0.34 | 0.20 |
| Grid | 0.89 | 0.32 | 0.02 | 0.88 | 0.83 | 0.04 | 0.02 | |
| Wood | 0.53 | 0.56 | 0.14 | 0.36 | 0.29 | 0.14 | 0.47 | |
| Leather | 0.80 | 0.76 | 0.24 | 0.71 | 0.67 | 0.34 | 0.74 | |
| Tile | 0.36 | 0.31 | 0.23 | 0.04 | 0.23 | 0.08 | 0.14 | |
| Objects | Bottle | 0.52 | 0.30 | 0.27 | 0.15 | 0.22 | 0.05 | 0.07 |
| Cable | 0.40 | 0.37 | 0.18 | 0.01 | 0.05 | 0.01 | 0.13 | |
| Capsule | 0.31 | 0.25 | 0.11 | 0.09 | 0.11 | 0.04 | 0.00 | |
| Hazelnut | 0.54 | 0.44 | 0.44 | 0.00 | 0.41 | 0.02 | 0.00 | |
| Metal Nut | 0.36 | 0.39 | 0.49 | 0.01 | 0.26 | 0.00 | 0.13 | |
| Pill | 0.24 | 0.34 | 0.18 | 0.07 | 0.25 | 0.17 | 0.00 | |
| Screw | 0.47 | 0.42 | 0.17 | 0.03 | 0.34 | 0.01 | 0.00 | |
| Toothbrush | 0.69 | 0.54 | 0.14 | 0.08 | 0.51 | 0.07 | 0.00 | |
| Transistor | 0.08 | 0.30 | 0.30 | 0.01 | 0.22 | 0.08 | 0.03 | |
| Zipper | 0.82 | 0.20 | 0.06 | 0.10 | 0.13 | 0.01 | 0.00 | |
| mean | 0.50 | 0.41 | 0.20 | 0.22 | 0.33 | 0.09 | 0.13 |
| Category | Proposed | VAE with Attention [35] | [9] | [9] | AnoGAN [39] | CNNFD [21] | |
|---|---|---|---|---|---|---|---|
| Textures | Carpet | 0.94 | 0.78 | 0.87 | 0.59 | 0.54 | 0.72 |
| Grid | 0.99 | 0.73 | 0.94 | 0.90 | 0.58 | 0.59 | |
| Wood | 0.87 | 0.77 | 0.73 | 0.73 | 0.62 | 0.91 | |
| Leather | 0.99 | 0.95 | 0.78 | 0.75 | 0.64 | 0.87 | |
| Tile | 0.88 | 0.80 | 0.59 | 0.51 | 0.50 | 0.93 | |
| Objects | Bottle | 0.95 | 0.87 | 0.93 | 0.86 | 0.86 | 0.78 |
| Cable | 0.95 | 0.90 | 0.82 | 0.86 | 0.78 | 0.79 | |
| Capsule | 0.93 | 0.74 | 0.94 | 0.88 | 0.84 | 0.84 | |
| Hazelnut | 0.95 | 0.98 | 0.97 | 0.95 | 0.87 | 0.72 | |
| Metal Nut | 0.91 | 0.94 | 0.89 | 0.86 | 0.76 | 0.82 | |
| Pill | 0.95 | 0.83 | 0.91 | 0.85 | 0.87 | 0.68 | |
| Screw | 0.96 | 0.97 | 0.96 | 0.96 | 0.80 | 0.87 | |
| Toothbrush | 0.97 | 0.94 | 0.92 | 0.93 | 0.90 | 0.77 | |
| Transistor | 0.91 | 0.93 | 0.90 | 0.86 | 0.80 | 0.66 | |
| Zipper | 0.98 | 0.78 | 0.88 | 0.77 | 0.78 | 0.76 | |
| mean | 0.94 | 0.86 | 0.87 | 0.82 | 0.74 | 0.78 |
| Category | Proposed | [9] | [9] | |
|---|---|---|---|---|
| Textures | Carpet | 0.88/0.33 | 0.87/0.08 | 0.54/0.03 |
| Grid | 0.97/0.38 | 0.90/0.02 | 0.92/0.04 | |
| Wood | 0.97/0.42 | 0.88/0.12 | 0.64/0.24 | |
| Leather | 0.98/0.42 | 0.81/0.02 | 0.76/0.32 | |
| Tile | 0.98/0.30 | 0.09/0.07 | 0.71/0.07 | |
| Objects | Bottle | 0.99/0.55 | 0.92/0.16 | 0.90/0.26 |
| Cable | 0.82/0.40 | 0.58/0.02 | 0.29/0.06 | |
| Capsule | 0.68/0.23 | 0.58/0.08 | 0.39/0.10 | |
| Hazelnut | 0.93/0.50 | 0.13/0.44 | 0.89/0.46 | |
| Metal Nut | 0.93/0.36 | 0.15/0.03 | 0.83/0.25 | |
| Pill | 0.81/0.20 | 0.43/0.09 | 0.37/0.25 | |
| Screw | 0.81/0.34 | 0.11/0.06 | 0.56/0.20 | |
| Toothbrush | 0.97/0.40 | 0.80/0.14 | 0.98/0.35 | |
| Transistor | 0.68/0.11 | 0.06/0.07 | 0.60/0.19 | |
| Zipper | 0.99/0.58 | 0.75/0.29 | 0.77/0.15 | |
| mean | 0.89/0.37 | 0.54/0.11 | 0.68/0.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zhang, D.; Guo, J.; Han, Y. Image Anomaly Detection Using Normal Data Only by Latent Space Resampling. Appl. Sci. 2020, 10, 8660. https://doi.org/10.3390/app10238660
Wang L, Zhang D, Guo J, Han Y. Image Anomaly Detection Using Normal Data Only by Latent Space Resampling. Applied Sciences. 2020; 10(23):8660. https://doi.org/10.3390/app10238660
Chicago/Turabian StyleWang, Lu, Dongkai Zhang, Jiahao Guo, and Yuexing Han. 2020. "Image Anomaly Detection Using Normal Data Only by Latent Space Resampling" Applied Sciences 10, no. 23: 8660. https://doi.org/10.3390/app10238660
APA StyleWang, L., Zhang, D., Guo, J., & Han, Y. (2020). Image Anomaly Detection Using Normal Data Only by Latent Space Resampling. Applied Sciences, 10(23), 8660. https://doi.org/10.3390/app10238660