Boosting Face Recognition under Drastic Views Using a Pose AutoAugment Manner


Abstract
:1. Introduction
- i
- An enhanced face recognition framework is proposed to identify pose-invariant representations of faces under drastic poses. The proposed framework trains a pose-invariant CNN model, and extract identifiable features of drastic pose view for face recognition.
- ii
- A novel face augmentation method, which is composed of pose auto-augment and background appending, is proposed to increase pose variations for each subject.
- iii
- Experiments on Bosphorus and CASIA-3D FaceV1 databases demonstrate state-of-the-art performance for face recognition under drastic poses.
2. Related Work
3. Proposed Methods
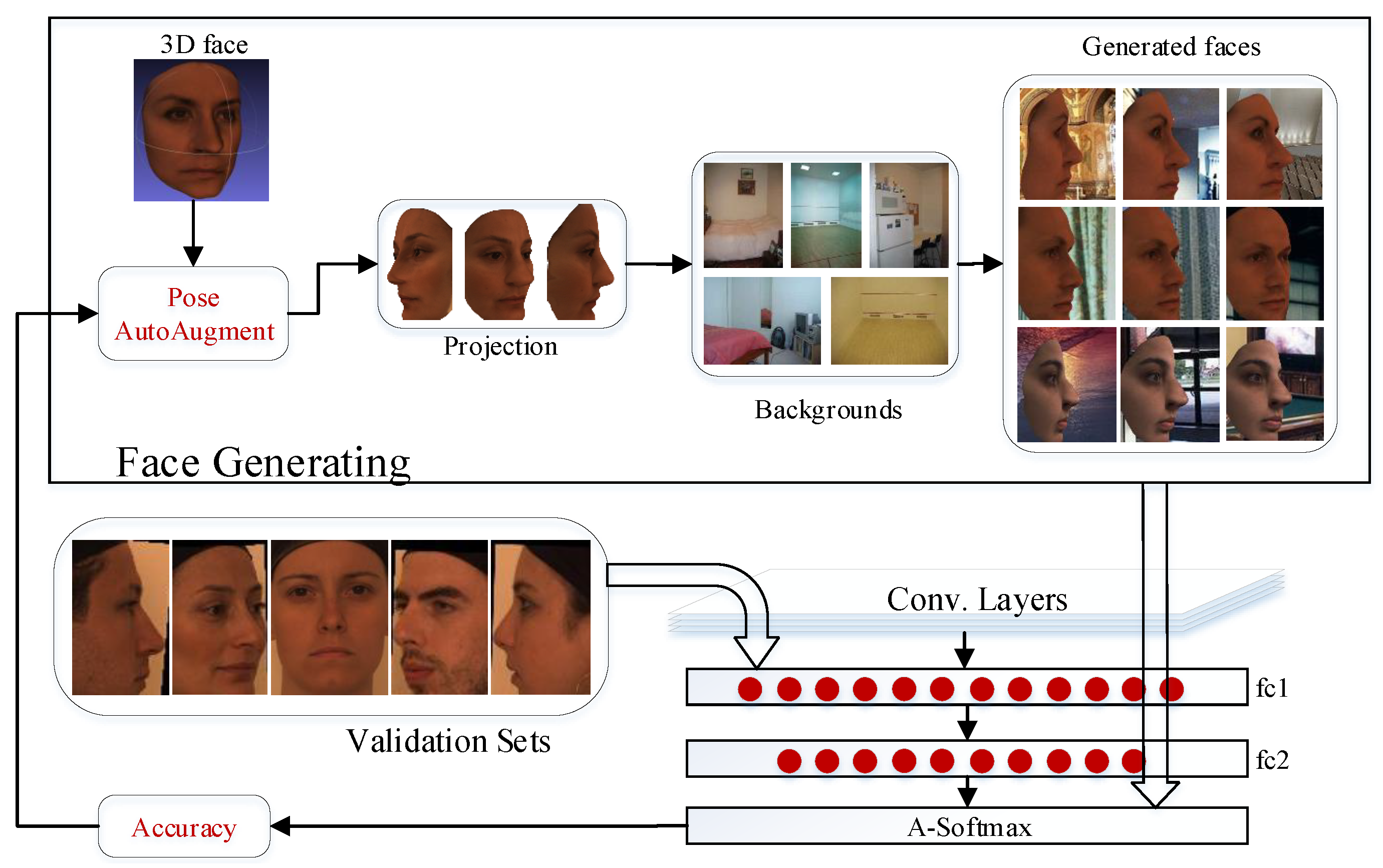
3.1. Face Augmentation
3.2. Face Recognition
3.2.1. CNN Training
3.2.2. Face Matching
4. Experiments
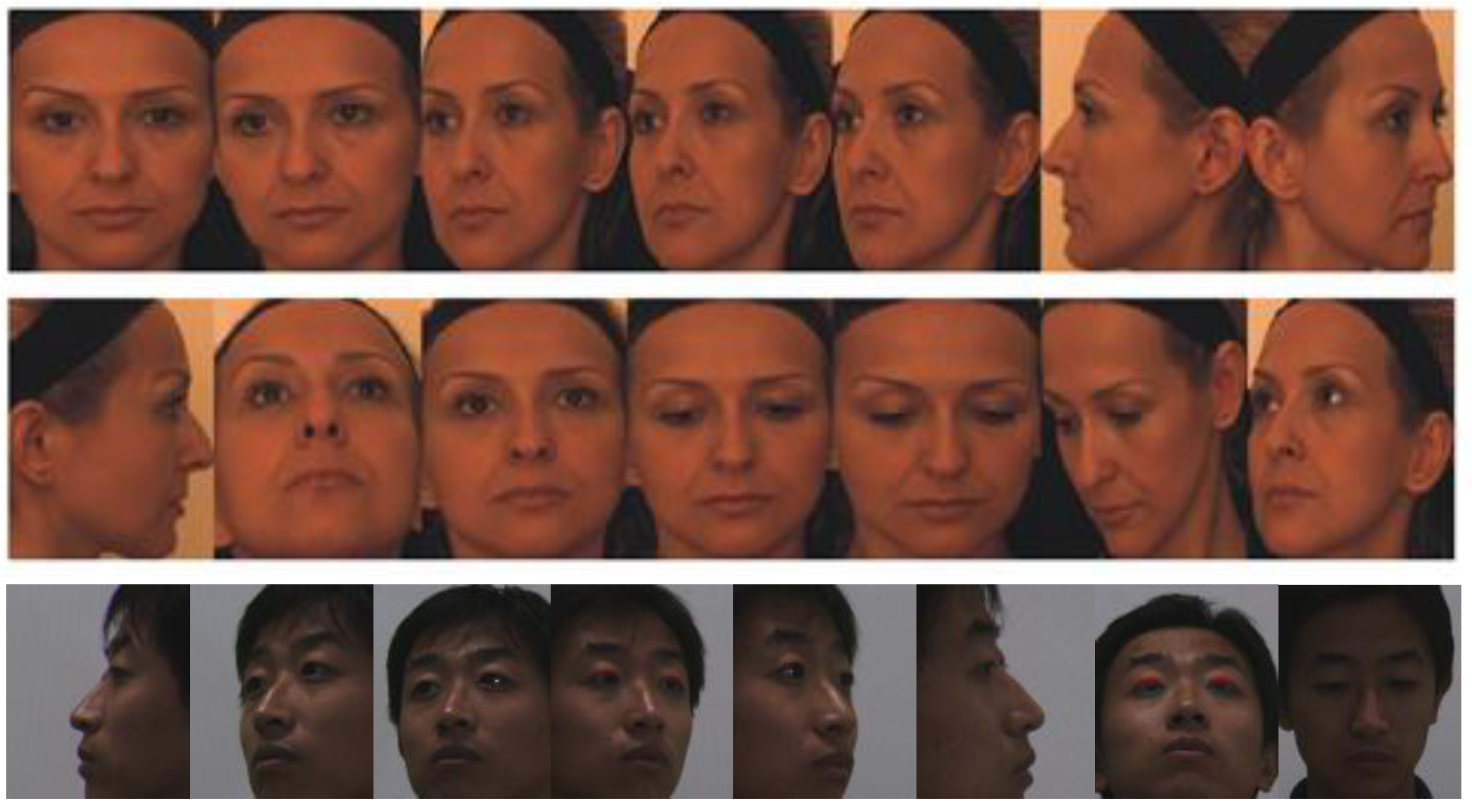
4.1. Datasets
4.2. Evaluate the Components in Face Augmentation
4.3. Evaluate the Face Recognition under Pose Variations
4.4. Comparison with State-of-the-Art
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar]
- Simonyan, K.; Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Fisher Vector Faces in the Wild. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013; pp. 8.1–8.11. [Google Scholar]
- Ding, C.; Choi, J.; Tao, D.; Davis, L.S. Multi-directional multi-level dual-cross patterns for robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 518–531. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Sparsifying Neural Network Connections for Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4856–4864. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Multi-view perceptron: A deep model for learning face identity and view representations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 217–225. [Google Scholar]
- Yim, J.; Jung, H.; Yoo, B.; Choi, C.; Park, D.; Kim, J. Rotating your face using multi-task deep neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 676–684. [Google Scholar]
- Masi, I.; Tran, A.Â.; Hassner, T.; Leksut, J.T.; Medioni, G. Do we really need to collect millions of faces for effective face recognition? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 579–596. [Google Scholar]
- Masi, I.; Chang, F.J.; Choi, J.; Harel, S.; Kim, J.; Kim, K.; Leksut, J.; Rawls, S.; Wu, Y.; Hassner, T.; et al. Learning Pose-Aware Models for Pose-Invariant Face Recognition in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 412, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Kakadiaris, I.A.; Toderici, G.; Evangelopoulos, G.; Passalis, G.; Chu, D.; Zhao, X.; Shah, S.K.; Theoharis, T. 3D-2D face recognition with pose and illumination normalization. Comput. Vis. Image Underst. 2017, 154, 137–151. [Google Scholar] [CrossRef]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Towards large-pose face frontalization in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4010–4019. [Google Scholar]
- Masi, I.; Hassner, T.; Tran, A.T.; Medioni, G. Rapid synthesis of massive face sets for improved face recognition. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 604–611. [Google Scholar]
- Chang, F.J.; Tran, A.T.; Hassner, T.; Masi, I.; Nevatia, R.; Medioni, G. FacePoseNet: Making a case for landmark-free face alignment. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1599–1608. [Google Scholar]
- Crispell, D.; Biris, O.; Crosswhite, N.; Byrne, J.; Mundy, J.L. Dataset Augmentation for Pose and Lighting Invariant Face Recognition. arXiv 2017, arXiv:1704.04326. [Google Scholar]
- Kortylewski, A.; Egger, B.; Schneider, A.; Gerig, T.; Forster, A.; Vetter, T. Empirically Analyzing the Effect of Dataset Biases on Deep Face Recognition Systems. arXiv 2017, arXiv:1712.01619. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Yuan, X.; Park, I.K. Face De-Occlusion Using 3D Morphable Model and Generative Adversarial Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 10061–10070. [Google Scholar] [CrossRef] [Green Version]
- Sawant, M.M.; Bhurchandi, K.M. Age invariant face recognition: A survey on facial aging databases, techniques and effect of aging. Artif. Intell. Rev. 2019, 52, 981–1008. [Google Scholar] [CrossRef]
- Ding, C.; Tao, D. A Comprehensive Survey on Pose-Invariant Face Recognition. ACM Trans. Intell. Syst. Technol. 2016, 7, 37:1–37:42. [Google Scholar] [CrossRef]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Nevatia, R.; Binford, T.O. Description and recognition of curved objects. Artif. Intell. 1977, 8, 77–98. [Google Scholar] [CrossRef]
- Oliver, N.M.; Rosario, B.; Pentland, A.P. A Bayesian computer vision system for modeling human interactions. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 831–843. [Google Scholar] [CrossRef] [Green Version]
- Vasilescu, M.A.O.; Terzopoulos, D. Multilinear independent components analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 547–553. [Google Scholar]
- Michels, J.; Saxena, A.; Ng, A.Y. High speed obstacle avoidance using monocular vision and reinforcement learning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 593–600. [Google Scholar]
- Li, Y.; Su, H.; Qi, C.R.; Fish, N.; Cohen-Or, D.; Guibas, L.J. Joint embeddings of shapes and images via CNN image purification. Acm Trans. Graph. 2015, 34, 234. [Google Scholar] [CrossRef]
- Guo, H.; Wang, J.; Gao, Y.; Li, J.; Lu, H. Multi-view 3D object retrieval with deep embedding network. IEEE Trans. Image Process. 2016, 25, 5526–5537. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Qi, C.R.; Li, Y.; Guibas, L.J. Render for cnn: Viewpoint estimation in images using cnns trained with rendered 3D model views. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2686–2694. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3D solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Dou, P.; Shah, S.K.; Kakadiaris, I.A. End-to-end 3D face reconstruction with deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1503–1512. [Google Scholar]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D.J. From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Ding, L.; Ding, X.; Fang, C. 2D face fitting-assisted 3D face reconstruction for pose-robust face recognition. Soft Comput. 2011, 15, 417–428. [Google Scholar] [CrossRef]
- Prabhu, U.; Heo, J.; Savvides, M. Unconstrained pose-invariant face recognition using 3D generic elastic models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1952–1961. [Google Scholar] [CrossRef]
- Moeini, A.; Faez, K.; Moeini, H. Unconstrained pose-invariant face recognition by a triplet collaborative dictionary matrix. Pattern Recognit. Lett. 2015, 68, 83–89. [Google Scholar] [CrossRef]
- Dou, P.; Zhang, L.; Wu, Y.; Shah, S.K.; Kakadiaris, I.A. Pose-robust face signature for multi-view face recognition. In Proceedings of the Biometrics Theory, Applications and Systems, Arlington, VA, USA, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4295–4304. [Google Scholar]
- Vasilescu, M.A.O. Multilinear projection for face recognition via canonical decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 184–191. [Google Scholar]
- Martinez-Cantin, R. BayesOpt: A Bayesian optimization library for nonlinear optimization, experimental design and bandits. J. Mach. Learn. Res. 2014, 15, 3735–3739. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Hajati, F.; Raie, A.A.; Gao, Y. 2.5D face recognition using patch geodesic moments. Pattern Recognit. 2012, 45, 969–982. [Google Scholar] [CrossRef]
- Gheisari, S.; Javadi, S.; Kashaninya, A. 3D face recognition using patch geodesic derivative pattern. Int. J. Smart Electr. Eng. 2013, 2, 127–132. [Google Scholar]
- Liang, Y.; Zhang, Y.; Zeng, X.X. Pose-invariant 3D face recognition using half face. Signal Process. Image Commun. 2017, 57, 84–90. [Google Scholar] [CrossRef]
- Moeini, A.; Moeini, H. Real-world and rapid face recognition toward pose and expression variations via feature library matrix. IEEE Trans. Inf. Forensics Secur. 2015, 10, 969–984. [Google Scholar] [CrossRef]
- Sang, G.; Li, J.; Zhao, Q. Pose-invariant face recognition via RGB-D images. Comput. Intell. Neurosci. 2016, 2016, 3563758. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Datasets | Persons | Training Set (3D Frontal Scans) | Testing Set (2D Facial Images) | Testing Set (Facial Pose) |
|---|---|---|---|---|
| Bosphorus | 105 | 105 | 1365 | 7 yaw, 4 pitch, and 2 cross rotations |
| CASIA-3D Face V1 | 122 | 122 | 976 | 6 yaw, and 2 pitch rotations. |
| Pose | L45 | R45 | L90 | R90 |
|---|---|---|---|---|
| None | 100 | 100 | 71 | 66.34 |
| cbN | 100 | 100 | 72 | 67.5 |
| cBN | 100 | 100 | 75 | 69 |
| CbN | 100 | 100 | 79 | 71.29 |
| CBN | 100 | 100 | 94 | 87.13 |
| Probe Gallery | L45-R45 | SU&SD | Up | Down | CR | L90 | R90 |
|---|---|---|---|---|---|---|---|
| Front Face | 100 | 100 | 100 | 100 | 100 | 94 | 87.13 |
| R10 | 100 | 100 | 99 | 100 | 100 | 91 | 89.11 |
| R20 | 100 | 100 | 99 | 100 | 100 | 88 | 87.13 |
| R30 | 100 | 100 | 98.10 | 100 | 100 | 91 | 86.14 |
| R45 | 100 | 100 | 98.10 | 100 | 100 | 93 | 88.12 |
| L45 | 100 | 100 | 97.14 | 100 | 100 | 96 | 84.16 |
| R90 | 83.05 | 82.38 | 64.76 | 77.88 | 78.57 | 78 | N/A |
| L90 | 85.14 | 87.62 | 72.38 | 77.88 | 80 | N/A | 74.26 |
| Probe Gallery | L30-R30 | L60 | R60 | L90 | R90 | Up | Down |
|---|---|---|---|---|---|---|---|
| Front Face | 100 | 100 | 100 | 93.33 | 92.62 | 100 | 100 |
| L30 | 100 | 100 | 100 | 95.90 | 93.33 | 100 | 100 |
| R30 | 99.73 | 100 | 99.18 | 95 | 91.80 | 100 | 99.18 |
| L60 | 99.72 | - | 100 | 95.90 | 94.17 | 99.18 | 99.18 |
| R60 | 99.45 | 99.18 | - | 91.80 | 95 | 96.72 | 98.36 |
| L90 | 89.88 | 92.62 | 86.89 | - | 87.50 | 87.70 | 84.43 |
| R90 | 90.16 | 87.70 | 92.62 | 87.70 | - | 88.52 | 84.43 |
| Up | 100 | 100 | 98.36 | 91.80 | 86.67 | - | 98.36 |
| Down | 99.45 | 98.36 | 99.18 | 90.16 | 90 | 97.54 | - |
| Pose Methods | R10-30 | L45 | R45 | L90 | R90 | PU | PD | CR | Average |
|---|---|---|---|---|---|---|---|---|---|
| PGM [42] | 87.1 | 38.1 | 39.0 | N/A | N/A | 79.0 | 69.5 | 49.1 | 69.1 |
| PGDP [43] | 89.2 | 37.1 | 36.2 | N/A | N/A | 91.4 | 70.0 | 50.0 | 71.4 |
| FLM+GT [45] | N/A | 99.0 | 98.8 | 83.2 | 83.0 | N/A | N/A | 95.7 | 92.0 |
| Sang et al. [46] | 99.8 | 98.1 | 97.7 | 92.3 | 91.4 | 93.0 | 92.7 | 90.1 | 93.4 |
| Liang et al. [44] | 98.4 | 93.3 | N/A | N/A | 99.5 | 94.8 | 97.2 | ||
| PAFR | 100 | 100 | 100 | 94.0 | 87.1 | 100 | 100 | 100 | 98.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, W.; Zhao, X.; Zou, J. Boosting Face Recognition under Drastic Views Using a Pose AutoAugment Manner. Appl. Sci. 2020, 10, 8940. https://doi.org/10.3390/app10248940
Gao W, Zhao X, Zou J. Boosting Face Recognition under Drastic Views Using a Pose AutoAugment Manner. Applied Sciences. 2020; 10(24):8940. https://doi.org/10.3390/app10248940
Chicago/Turabian StyleGao, Wanshun, Xi Zhao, and Jianhua Zou. 2020. "Boosting Face Recognition under Drastic Views Using a Pose AutoAugment Manner" Applied Sciences 10, no. 24: 8940. https://doi.org/10.3390/app10248940
APA StyleGao, W., Zhao, X., & Zou, J. (2020). Boosting Face Recognition under Drastic Views Using a Pose AutoAugment Manner. Applied Sciences, 10(24), 8940. https://doi.org/10.3390/app10248940