1. Introduction
The scene is an important information which can be used as a metadata in image and video search or recommendation systems. This scene information can provide more detailed situation information with time duration and character who appears in image and video contents.
While humans naturally perceive the scene they are located, it is a challenging work for machines to recognize it. If the machines could understand the scene they are looking, this technology can be used for robots to navigate, or searching a scene in video data. The main purpose of scene classification is to classify name of scenes of given images.
In the early days, scene or place classification was carried out through traditional methods such as Scale-Invariant Feature Transformation (SIFT) [
1], Speed-Up Robust Features (SURF) [
2], and Bag of Words (BoW) [
3]. In recent years, deep learning with the convolutional neural networks (CNNs) has been widely used for image classification ever since AlexNet [
4] won the ImageNet Large Scale Visual Recognition Competition (ILSVRC) in 2012.
There have been several approaches to classify scenes and dplaces. One approach is using classification method such as
k-nearest neighbor (KNN) classifier and other is based on the convolutional neural networks (CNNs). Chowanda et al. [
5] proposed a new dataset for image classification and experimented with their dataset with CNNs such as VGG, GoogLeNet to classify Indonesian regions. Raja et al. [
6] proposed a method of classifying indoor and outdoor by using KNN classifier. Viswanathan et al. [
7] suggested an object-based approach. However, their methods could classify only indoor scenes such as kitchen, bathroom, and so forth. Yiyi et al. [
8] also proposed an object-based classification method combining CNN and semantic segmentation model and classified five indoor scenes. Zheng et al. [
9] suggested a method for aerial scene classification by using pre-trained CNN and multi-scale pooling. Liu et al. [
10] proposed a Siamese CNN for remote sensing scene classification, which combined the identification and verification models of CNNs. Pires et al. [
11] analyzed a CNN model for aerial scene classification by transfer learning. These methods were focused on verifying the aerial scene.
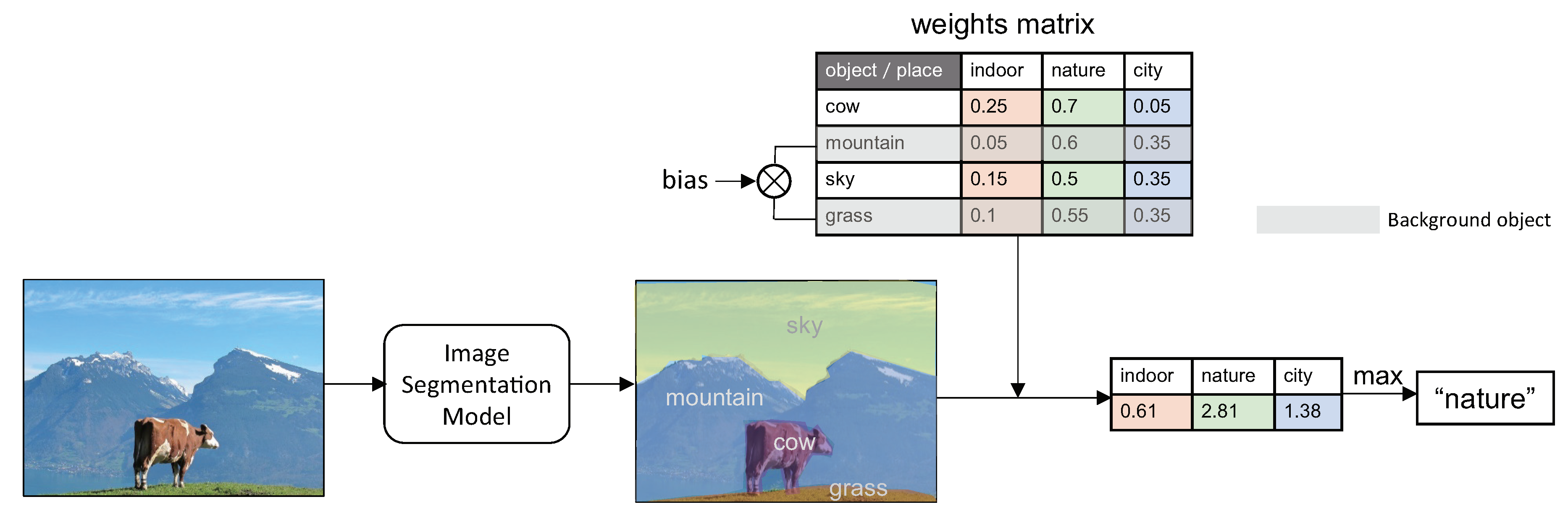
In this paper, we propose a method for classifying a scene and place image into one of three major scene categories: indoor, city, and nature which is different from the previous works in that we classify outdoor as well. There are many objects in the scene and place. It means that we are able to classify the scene by utilizing the information of the existing objects. Also, when humans see a scene or place, they recognize the scene or place based on objects, especially background objects. If there are mountains and the sky in the scene, they would perceive it as a natural scene, and if the scene is full of buildings, they would consider it as an urban scene. If there are ceiling and walls, they would recognize it as an indoor environment.
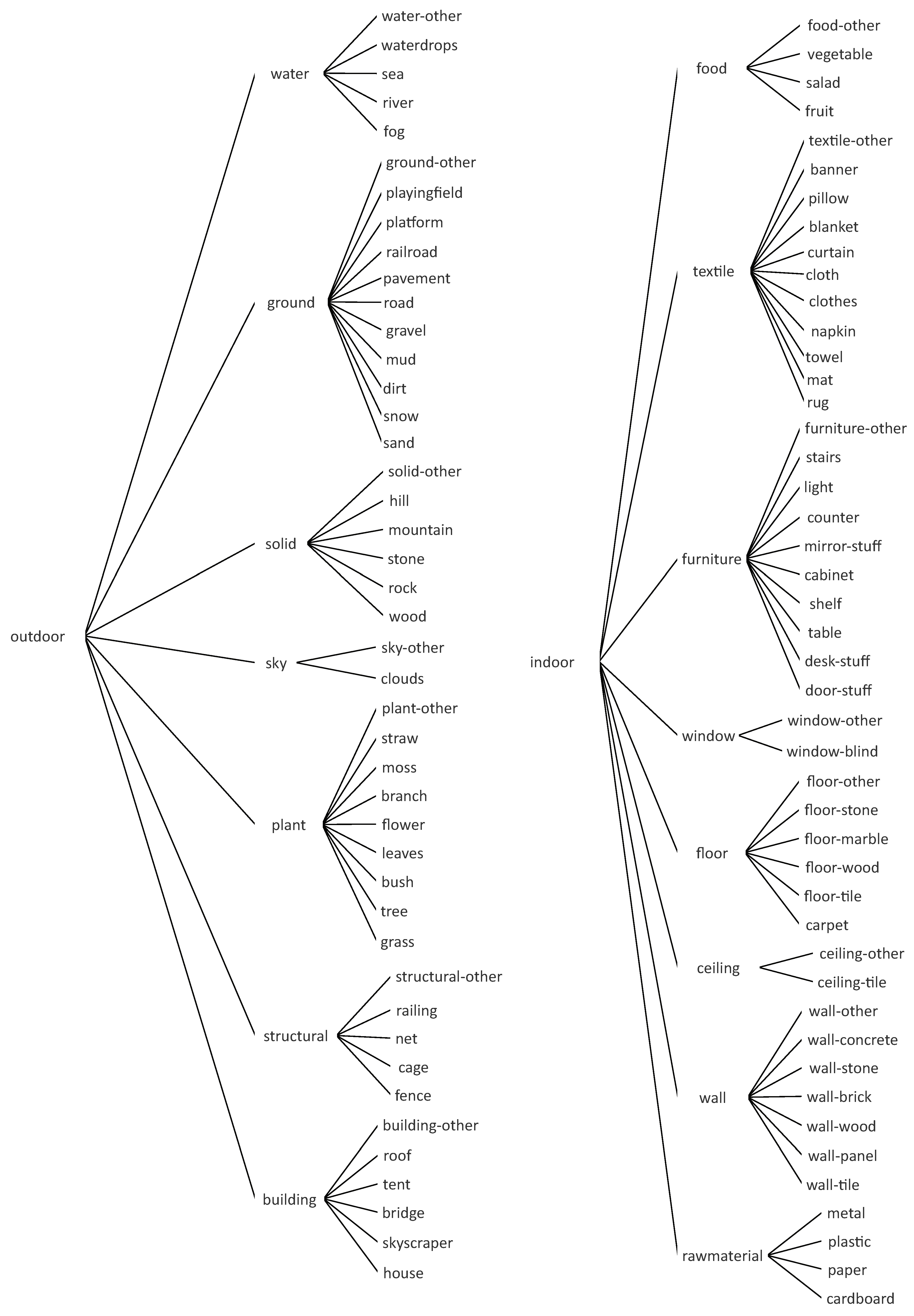
In order to classify a scene or place image based on this human perception process, we first conduct object segmentation using the image segmentation model pre-trained with MS COCO-stuff dataset [
12]. While MS COCO dataset [
13] is for object detection, MS COCO-stuff dataset is for segmentation. In this paper, we used DeepLab v2 [
14] model which is semantic segmentation model and can be trained with the background (stuff) objects. MS COCO-stuff dataset contains 171 kinds of object classes which are suitable for our solution. To classify an image, we construct a weight matrix of each object classes so that we can give more weight to objects that are more dominant on determining a scene. Finally, we classify the scene by combining the weight matrix and detected objects in the scene or place.
We organize the rest of this paper as follows:
Section 2 highlights the details of the proposed classification method.
Section 3 presents the implementation of the experiment as well as the experimental results. Finally, we draw the conclusions and suggest further research directions in
Section 4.
3. Experimental Results and Discussion
In this section, we will show the results of our classification model and well-renowned classification methods using CNNs. We implemented the proposed scheme by using PyTorch deep learning framework, and used single GPU for training. We trained DeepLab v2 model with COCO-stuff dataset which contains total 164k images. As we mentioned it in
Section 2.2, the reason why we use COCO-stuff dataset is because its object classes are divided into indoor and outdoor categories.
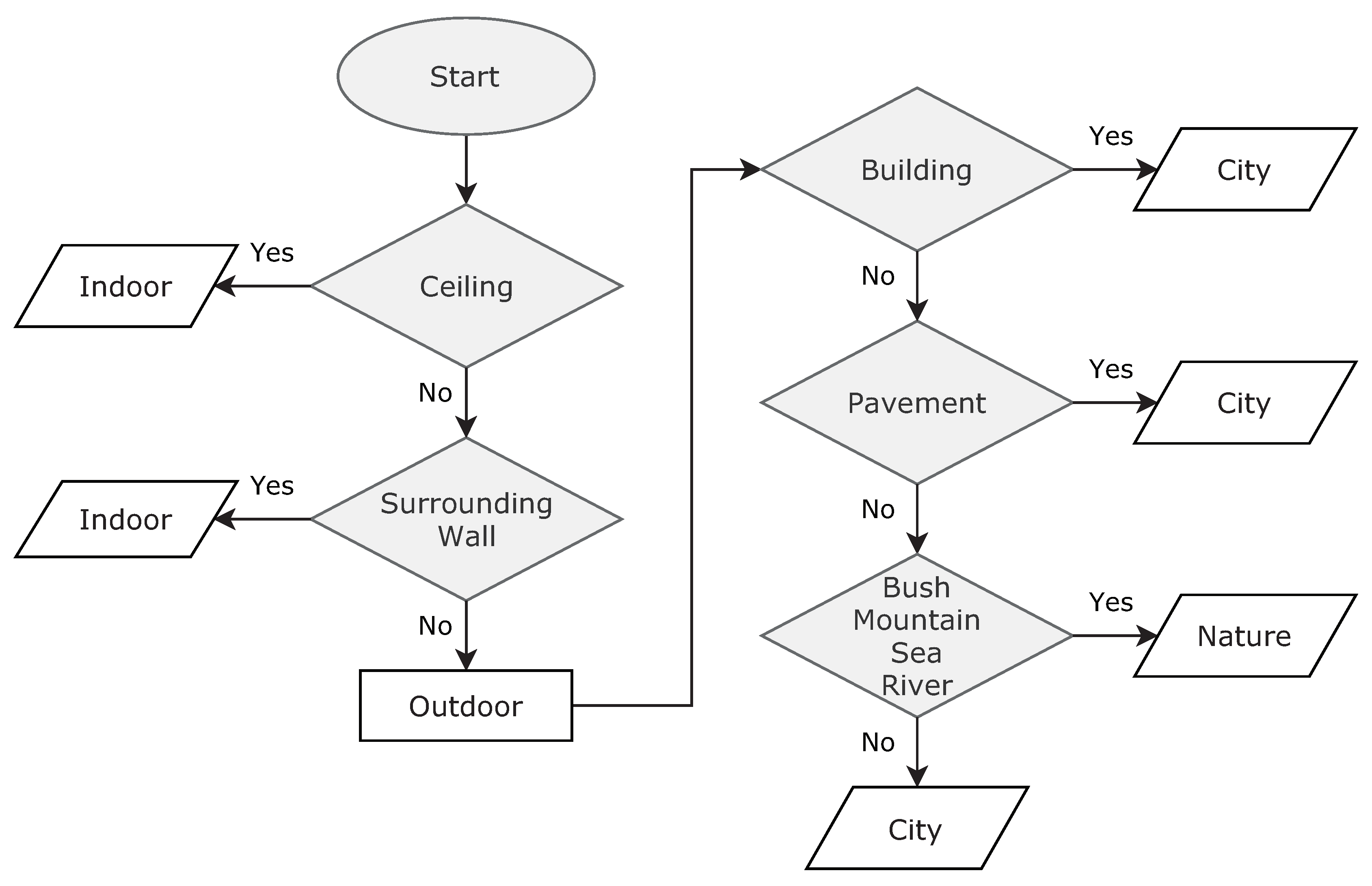
In order to compare our method with CNN based classification models, we first built a custom test dataset that consists of 500 images as shown in
Table 1. We extracted them from Korean movies, and the images were manually labeled into three scene classes (i.e., 0: indoor, 1: nature, 2: city) under certain criteria. We set some criteria according to the logic that humans more focus on the background objects rather than foreground objects. The criteria are described in
Figure 4.
The sample test images are shown in
Figure 5. We used COCO-stuff validation 2017 dataset for training the CNN models, which were also used for building the weight matrix. The test images were used for measuring accuracy of the classification. We experimented various CNNs, such as VGG [
15], Inception [
16,
17], ResNet [
18], ResNeXt [
19], Wide-ResNet [
20], DenseNet [
21], and MnasNet [
22] as shown in
Table 2.
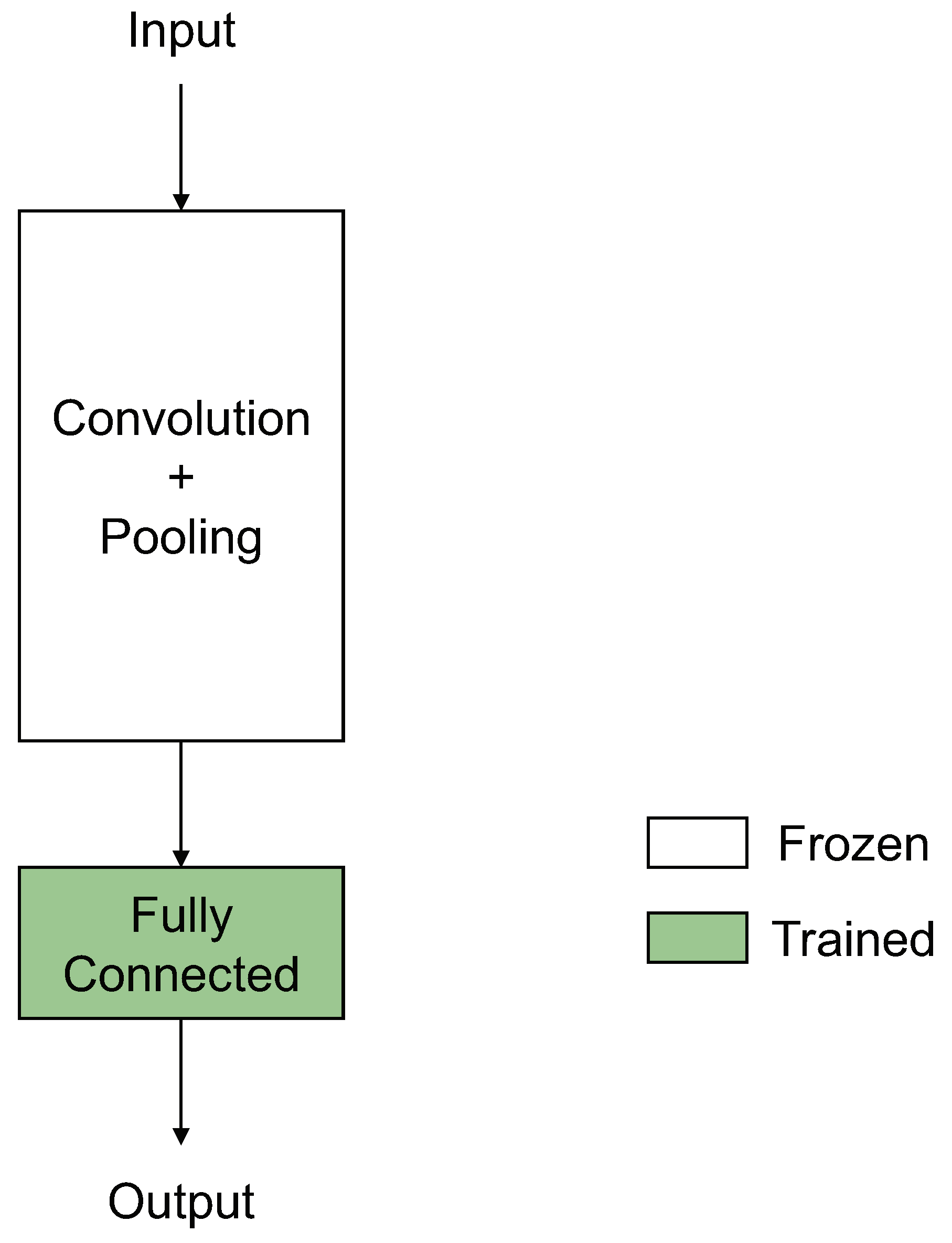
To be more specific, we trained each model by using transfer learning scheme [
23], especially Feature Extraction [
24,
25]. The basic concept of feature extraction is represented in
Figure 6. Typical CNNs have convolutional layers for extracting good features and fully connected layers to classify the feature. Feature extraction technique which trains only fully connected layers is used when there are insufficient data for training.
PyTorch Deep Learning Framework was used again to implement all structures for the experiment. The results of accuracy were computed after 200 iterations of training. We trained each model using cross entropy loss, and Adam optimizer with a batch size 64, learning rate 0.001. Learning rate was multiplied by 0.1 every 7 iteration.
In
Table 2, we can observe the proposed scheme outperforms the existing well-known CNNs which were trained using transfer learning. In terms of the accuracy, the proposed scheme achieved 90.8% of the accuracy.
When compared with VGG-19 (BN) [
15] and ResNeXt-101 [
19], the proposed method could improve 2.8% of the accuracy. Also, our scheme improved the performance over 13% comparing to MnasNet (0.5) [
16]. VGG-19 was tested with batch normalization (BN) and without BN. The float values with MnasNet is the depth multiplier in Reference [
22]. From this result, we can see that the proposed scheme is very reliable and better to classify the scene.
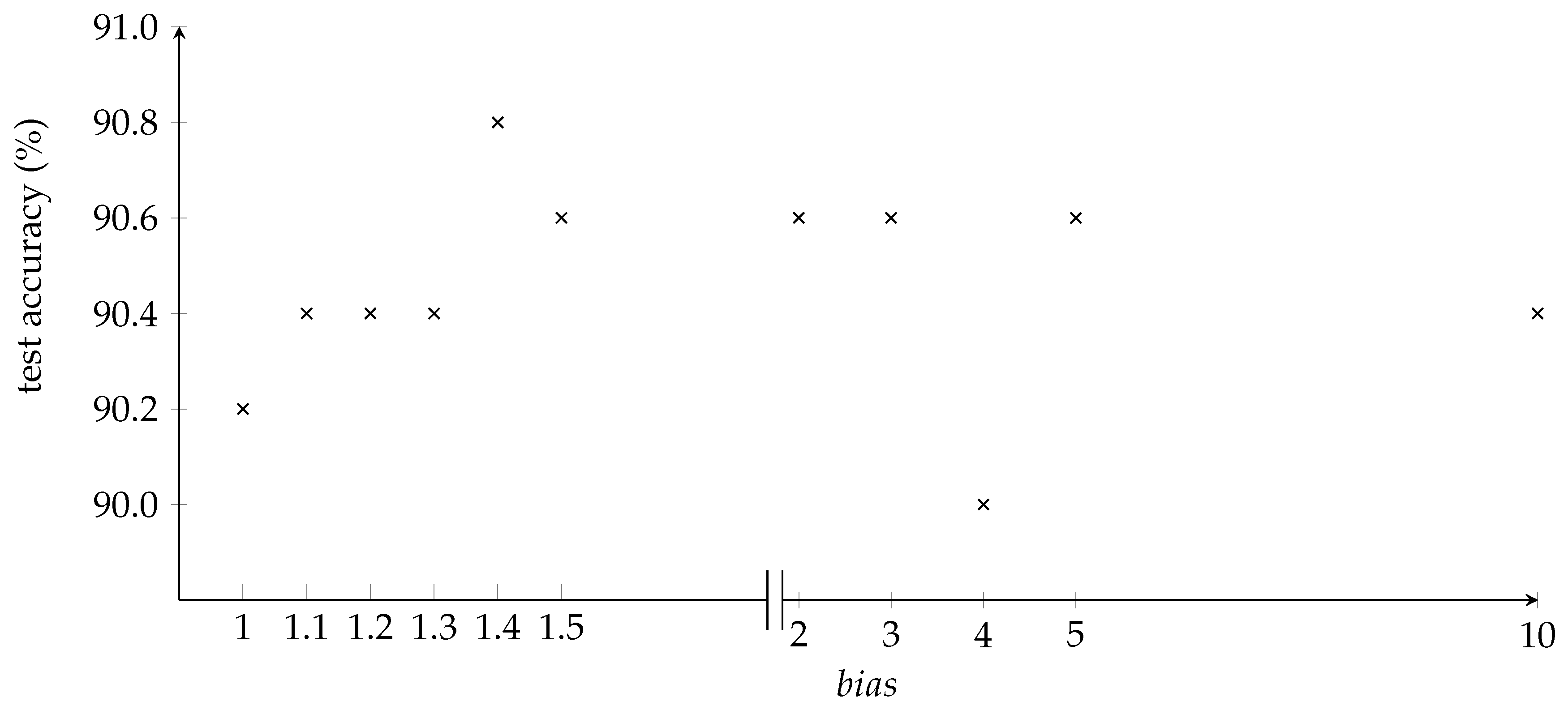
Figure 7 represents the graph of the experiment on determining optimal bias value in terms of test accuracy. It shows that the highest test accuracy when the bias is
. This value is used in the inference process when multiplying weights of background objects.
In addition, we measured test accuracy on COCO-Stuff test dataset. We adopted first 100 images of the test images and labeled the images according to the criteria in
Figure 4. We used same parameters as the previous experiment while training CNNs and building weight matrix. The result is shown in
Table 3. The result shows that the proposed method outperforms the conventional CNNs and also indicates that it achieves better performance when test images are taken in the same domain with train images.
Lastly, we experimented on indoor classes and
Table 4 shows the results. We used the subset of MITPlaces dataset [
26]. It contains categories of ’library’, ’bedroom’ and ’kitchen’ and 900 train images and 100 test images per class. As previous experiment, train images are used for building weight matrix and test images are used for measuring test accuracy in the proposed method. Classifying indoor categories must be treated differently from classifying indoor and outdoor. Since all indoor scenes have ceilings and walls, the bias value in Algorithm 2 must be given not by background objects, but by foreground objects. In this experiment, we defined foreground objects as furniture categories in
Figure 2 and determined the value to be 3 empirically. Although the results shows that 7 of CNNs outperforms our method by less than 4.6%, it shows that our method can be extendable to indoor categorization problem.
CNNs which showed the best performance tested with our custom dataset are VGG-19 (BN) and ResNeXt-101. They both showed test accuracy of 88% and the proposed method showed 90.8%.
Table 5 represents the performance of three models on each of three scene classes. VGG-19 (BN) predicted all images perfectly in indoor class and the proposed method is following. In nature class, the proposed method showed the best accuracy. When it comes to city class, ResNext-101 showed the best results. From this result, we can see that the proposed method is reliable for scene classification. Source code is available at
https://github.com/woonhahaha/place-classification.
4. Conclusions
In this work, we have proposed an efficient scene and place classification scheme using background objects and the designed weighting matrix. We designed this weighting matrix based on the open dataset which is widely used in the scene and object classifications. Also, we evaluated the proposed classification scheme which was based on semantic segmentation comparing to the existing image classification methods such as VGG [
15], Inception [
16,
17], ResNet [
18], ResNeXt [
19], Wide-ResNet [
20], DenseNet [
21], and MnasNet [
22]. The proposed scheme is the first approach of object-based classification that can classify outdoor categories as well. We have built a custom dataset of 500 images for testing which can help researchers who are dealing with scene classification. We crawled frames from Korean movies and labeled each image manually. The images were labeled as three major scene categories (i.e., indoor, nature, and city).
Experimental results showed that the proposed classification model outperformed several well-known CNNs mainly used for image classification. In the experiment, our model achieved 90.8% of verification accuracy and improved over 2.8% of the accuracy when comparing to the existing CNNs.
The Future work is to widen the scene classes to classify not just indoor (library, bedroom, kit) and outdoor (city, nature), but also more subcategories. It would be helpful for searching in videos with such semantic information.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}