1. Introduction
As cities are getting smarter, and as the spread of intelligent surveillance technologies is gaining popularity within developed countries, making urban transport secure and efficient plays a key role in the safety of individuals as well as in affecting traffic flow, which, in turn, may negatively impact businesses within a city [
1].
Unlike video cameras, the operation of short-range microwave radars is not much affected by the presence of adverse weather conditions. This fact makes them ideal, in addition to classical closed-circuit television (CCTV) systems [
2], for operating round-the-clock automatic surveillance in an urban environment. Radars [
3,
4,
5] can be used for vehicle and pedestrian classification by relying on feature extraction from the range and Doppler profiles of each target. The data collected by radar measurements can be used as input to machine learning (ML) algorithms for classification. However, the hardware should be low cost and lightweight while providing good performance. Therefore, for this application, we have chosen a Raspberry Pi [
6,
7,
8], a small portable edge computing device, which is a very effective platform for real-world scenarios as well as for educational and research purposes. Raspberry Pi is ideal for edge computing applications, where the node or embedded device possesses high processing capabilities and is required to have enough storage space to avoid cloud access. With the large number of wireless sensor nodes that are used over a wide range of applications, from wearable sensors to image processing and surveillance, along with the integration of artificial intelligence and machine learning in their decision making, they are required to be as smart as possible to avoid cloud access and reduce network traffic. Urban classification may not have cloud access and requires low latency, so it is the ideal example where both training and testing need to be applied on an edge computing node.
The main goal of the present work is the porting of the state-of-the-art machine learning package Rulex [
9] onto the Raspberry Pi computational platform. The dependencies were compiled to produce output binary files that are compatible with the target platforms, the first being the Windows 32 Bit client and the second being the Raspberry Pi server, which is where the Rulex engine runs.
The remainder of this paper is organized as follows:
Section 2 presents a review on pedestrian–vehicle classification,
Section 3 introduces the porting of Rulex on the Raspberry Pi, and
Section 4 describes the adopted machine learning architecture. Further, forecast results obtained with the present implementation are presented in
Section 5. Finally, we draw some conclusions in
Section 6.
2. Pedestrian–Vehicle Classification Review
Radar systems can be used for detecting and classifying different targets, such as pedestrians and vehicles [
3,
4,
5]. Indeed, such systems produce, through a proper antenna, an electromagnetic wave that propagates to the objects eventually located in the inspected scenario. The targets interact with the impinging radiation employing the well-known scattering mechanism, generating a scattered field that partly returns to the radar receiver. Specifically, the reflected waves contain information about the characteristics of the objects that generated them.
The setup considered in the present paper includes a “Distance2Go” radar demo board developed by Infineon technologies, which is able to produce range-Doppler maps by performing a double fast Fourier transform (FFT) on the raw data measured using a frequency-modulated continuous wave (FMCW) scheme [
5,
10]. Such maps are characterized by a peak in correspondence to the frequency shift due to the propagation delay and to the Doppler effect (which is always present when dealing with moving targets). With proper processing, the main information related to the range and radial speed of the objects can then be easily obtained.
From these measurements, it is possible to derive features to be used for machine learning classification. Specifically, the machine learning features used for training are the extension of the range and velocity profiles, as well as the standard deviation, mean, and variance for the same variables, in addition to the radar cross-section and the estimated target velocity [
5]. However, in vehicle classification, there is the problem of vehicles moving crosswise (i.e., along a direction perpendicular to the radar axis), which can be mistaken for pedestrians [
11]. Indeed, longitudinal moving vehicles (i.e., traveling along the direction of the radar axis) have a large range profile and a point-shape velocity profile on the range-Doppler diagram. The opposite is true for pedestrians, due to multiple velocities caused by the movement of limbs. As for crosswise moving vehicles, their range profile is comparable to the range profile of pedestrians and their velocity profile may approach that of longitudinal moving vehicles. Consequently, we need to compute both transverse and longitudinal velocities, and with such additional features, we attempt to avoid misclassification. Another feature is the radar cross-section (RCS), which is the equivalent scattering surface of the target seen by the radar and is related to the amount of power that is reflected by the object [
12,
13].
In the rest of this work, we will refer to data obtained with the system described in [
5] that have been made available to us courtesy of the authors.
3. Porting Rulex to Raspberry Pi
Rulex is a machine learning software that supports various machine learning algorithms that can be easily applied in a user-friendly environment [
9]. The Rulex Graphical User Interface (GUI) provides a means of importing training data and manipulating them before applying machine learning algorithms. The main proprietary algorithm for Rulex is the logic learning machine (LLM) [
14,
15] which implements explainable AI. LLM was the main algorithm used for most of the classifications, where a tree-based structure, which combines vehicle classes to achieve more accurate results, was adopted. Then, these new combined classes are split recursively until all vehicles have been classified in their respective sub-classes.
The Raspberry Pi is a credit card-sized personal computer, which can perform application-specific tasks as well as performing general-purpose everyday computing, where it can connect to most personal computer (PC) input/output hardware. The Raspberry Pi has multiple digital input/output pins which can be used in embedded system applications such as motor control, serial communications, liquid-crystal display (LCD), and interfacing with a practically infinite variety of sensors.
Nowadays, IoT devices are becoming more intelligent because they support artificial intelligence software and algorithms, so in this work, we have deployed Rulex to operate on the Raspberry Pi which is one of the most popular IoT hardware platforms. In order to port a software package from one platform to another, all of its internal and external dependencies should be compiled on the target platform. After compilation with a specific tool, binaries or executables are generated, which are a formatted version of the code to be linked to succeeding layers of the source code. Furthermore, before porting software from 64 Bits to 32 Bits, all of its dependencies should be compiled in 32 Bits. Visual Studio may be used to compile the libraries and code when porting to Windows 32 Bits. However, when porting to Linux, we used CMake [
16,
17], which is a cross-platform application for generating executables or libraries.
Rulex external libraries were ported to 32 Bits as the first step before compiling the entire code. We ported the source code on Windows 32 Bits which is the interface and Raspbian 32 Bits which is where the engine runs. During porting, one of the issues we faced was the incompatibility of some datatypes with 32-Bit hardware and software, so they were either changed or cast into a compatible datatype. Another issue is the inability to generate a larger number of threads, so we developed two software tests, where one was written in Python and the other in C/C++ as an attempt to find out what was the maximum number of threads that could be generated. Moreover, the source code was modified accordingly to optimize the maximum number of threads.
After compiling locally on Windows 32 Bits, we proceeded to remotely compile the source code. Rulex was also debugged remotely and made compatible with both operating systems by using various macros and correctly setting variable types.
5. Results and Discussion
The dataset collected by the data acquisition system described consists of 120 rows equally distributed into 4 classes with 30 patterns for every class. The features consist of the mean, variance, and standard deviation of the range and Doppler profiles, along with their reflectivity and the estimated velocity of the target.
In order to maximize forecast accuracy, we have applied multiple tree-based sub-class arrangements to simulate using Rulex as a client/server setup [
20].
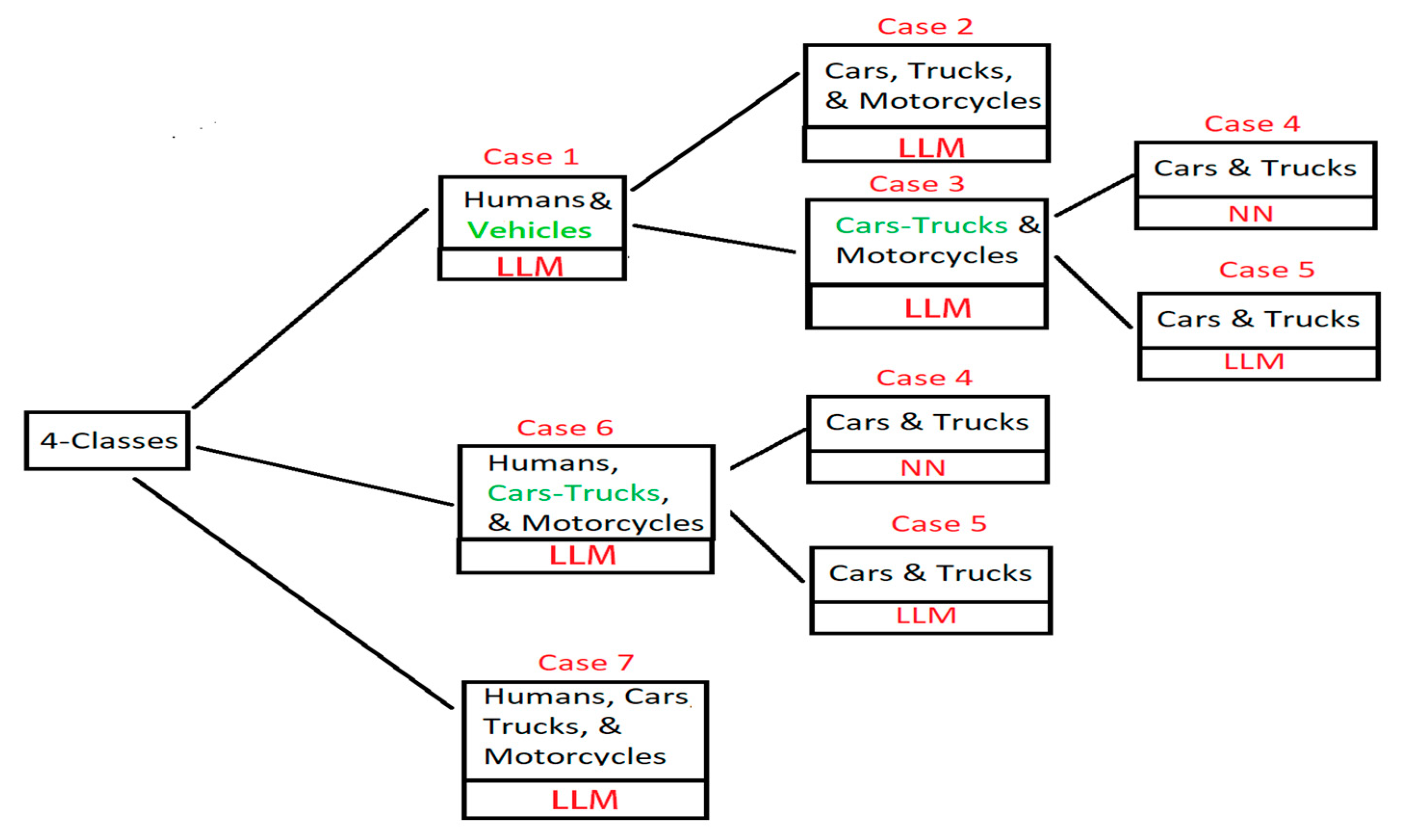
As stated earlier, multiple cascaded simulations were applied with a varying number of classes as well as a cascaded order. Thus, a summary of all the applied forecasts is presented in
Figure 2 and described in detail in this section. In
Figure 2, the red labels stand for the cases and machine learning algorithms used in that particular simulation, and the green labels represent classes that will be split into sub-classes in the upcoming simulation.
In Case 1, we split the data into two classes: humans, and vehicles where LLM was used. The accuracy is shown in
Table 1.
In Case 1, the machine learning algorithm used is LLM for classification. However, in Case 2, we only consider vehicle sub-classes. The simulation was applied using LLM where the prediction accuracies are found in
Table 2.
In Case 3, we apply a forecast using LLM for vehicle classes by splitting the data into two classes as shown in
Table 3. In Cases 4 and 5, the cars/trucks class has been split into two sub-classes, cars and trucks. In Case 4, we use neural networks, whereas LLM has been used in Case 5. The results of these can be found in
Table 4 and
Table 5, respectively.
Cases 1 to 5 were processed separately to get a glimpse of how LLM would perform with this given dataset. From the outputs generated in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, we can estimate the overall prediction accuracy for a cascaded setup. Furthermore, it should be noted that misclassified records in preceding forecasts will be treated as correctly classified in upcoming forecasts, which leads to the overall accuracy of the cascaded system being incorrectly estimated. The preceding forecasts were all performed with a 70%/30% split for training and testing data, respectively, and with all weights being set to unity.
Furthermore, we can apply multiple cascaded setups which are based on the previous forecasts. If we cascade Cases 1 and 2, the projected output is presented in
Table 6. In the case where we cascade Cases 1, 3, and 4, the projected output is provided in
Table 7.
If we cascade Cases 1, 3, and 5, we get the results shown in
Table 8. Other variations of initializing the cascaded system with LLM can be found in
Table 9, which is Case 6, where one class for humans along with two classes for vehicles is taken.
Finally, a single forecast for all four classes which is applied using LLM is presented in
Table 10, namely, Case 7, which consists of forecasting all classes in a single block. With the variation added in
Table 9 and
Table 10, we can apply two additional combinations to cascade. Thus, we can cascade Case 6 with Case 4 which employs neural networks or we can cascade it with Case 5 which uses LLM. These last two combinations include a situation where the previous prediction was not 100% accurate, so we need to take that into account when theoretically estimating the overall accuracy. When combining Case 6 with Case 4, the cars/trucks class has an accuracy of 94%, so, naturally, the neural network predictions in Case 4 will be multiplied by 0.94. The same can be said for Case 5, where the cars and trucks classes′ success rates are multiplied by the same factor.
Table 11 and
Table 12 provide the projected output forecast accuracy for the last two scenarios.
All of the preceding simulations only provide an estimation of actual results when cascading multiple engines. This is due to not considering the false-positive cases of the forecast. We took into consideration the entire dataset for each algorithm block and ignored some of the rows which were correctly classified in the abandoned class. In case two algorithms are cascaded, the first block should be followed by a Rulex data management block which will filter out the true and false positives in the abandoned class and remove them from the table. However, we still have to multiply the proceeding blocks with their parent class’s success rate to calculate the overall accuracy.
For Case 1, we split the data 70/30, with 70% used for training and 30% being used for testing. The same was applied for Case 3. However, for Case 4, with the reduced number of rows, the data were split 65/35, with 65% used for training and the remaining 35% being used for testing. The main reason for changing the split ratio in Case 4 is due to the fact the prediction is applied to half of the dataset, and we found that increasing the size of the test set can lead to higher accuracy for the given data.
As for weights, the only way to set them and optimize results is by trial and error and intuition. There is no universal method to select weights accordingly. The unity gain in the Case 1 block should already provide very good results, so there is no need to change the weights. With a unity gain, in Case 3, the cars/trucks class, which will be used in the proceeding block, should be accurate while keeping the motorcycles class forecast precise enough. A gain of 1.5 was chosen for the cars/trucks field and 1.0 for motorcycles. As for the final block, which is Case 4, both trucks and cars classes, which originate in Case 3, have an equal true positive rate of 80% in testing. Therefore, weights are left at unity.
Table 13 represents the accuracy for training and testing of Cases 1, 3, and 5, respectively, and as predicted using Rulex. All the forecasts present good results for testing. Humans were detected with a rate of 100% and vehicles overall at a rate of 96.67%. In Case 3, which is block 2, the cars/trucks class has a true positive rate of 93.75% and motorcycles at 90%. As for the cars and trucks block, which is Case 5, the success rate is 80% for both trucks and cars.
Table 14 and
Table 15 present the overall output true and false positive rates for the chosen All-LLM forecast. Humans are detected without any errors for the test dataset. The overall forecasts of the motorcycles, cars, and trucks have been calculated based on the preceding forecasts to become 90.63% for motorcycles and 77.34 for both cars and trucks.
Furthermore, the overall prediction of vehicles is 96.67%, which can be useful in practice.


 ,
, 





{kind=link}
{kind=link}