1. Introduction
Defect detection is one of the important applications of optical inspection. Due to the increasing demand for factory automation, defect detection can be found in many industry sectors. Although the images from different sectors have different characteristics, the way to find defects for the images from one sector may be useful for those from the others. Ngan et al. [
1] reported the image processing methods that can be used to find defects on fabric, which usually has repeated patterned texture. They categorized the methods into the statistical approaches, the spectral approaches, the model-based approaches, the learning approaches, and the structural approaches. These approaches are also used in the semiconductor industry. Wang et al. [
2] used the statistical approach by proposing the partial information correlation coefficient (PICC) to improve the traditional normalized cross correlation coefficient (TNCCC) for defect detection. They subtracted the standard image from the inspection image to obtain the grayscale difference, calculated the PICC, and compared the PICC with a threshold. If the PICC is less than the threshold, then it indicates that a defect exists. Li et al. [
3] used the level-set method to segment the functional regions from light-emitting diode (LED) wafer images after multiple iterations and then used the median value of the average intensities to differentiate different regions for inspection. Ma et al. [
4] proposed a generic defect detection method, which analyzes the gray-level-fluctuating conditions of an image and changes the local thresholds according to the conditions. Then the thresholds can be used to segment the defects from the background by using the image difference.
Regarding the spectral approaches, Liu et al. [
5] used the spectral subtraction method based on the one-dimensional fast Fourier transform (1-D FFT) to recover the standard defect-free image from three images with defects. The defects could then be detected by comparing the images with defects to the standard image. The advantage of this method is its robustness to illumination. Bai et al. [
6] used the phase-only Fourier transform (POFT) to find the salient regions in an image, and then used the template comparison method at the regions to find defects. Unlike traditional template comparison methods, this method is not so sensitive to misalignment between the two images compared. Yeh et al. [
7] used the two-dimensional wavelet transform for defect detection by calculating the interscale ratio from the wavelet transform modulus sum (WTMS). Because the ratio of the defect is very different from that of a defect-free image, the defect can be found using an appropriate threshold for the interscale ratio. This approach is template free, so it is easy to implement.
Regarding the deep learning solutions for defect detection, Chang et al. [
8] proposed a neural network solution for defect detection on LED wafers. First, the contextual-Hopfield neural network was used to find each die on the wafer, and then they used the mask to segment the light-emitting area and p-electrode from the die. The features of these two areas were extracted. Finally, the Radial Basis Function Neural Network (RBFNN) was used to find the defects. Kyeong and Kim [
9] used convolutional neural networks (CNNs) to classify mixed-type defects in wafer bin maps (WBMs). They compared two training methods: one trained each defect type in a separate model, and then combined the results from all models. The other trained only one model with all the possible mix-type defects. They found that using the former yielded better accuracy. Their experimental results showed that the CNN outperformed the support vector machine (SVM) and the multilayer perceptron (MLP). The accuracy achieved using CNN was about 91%, compared to the accuracy of 72% using SVM, and 45% using MLP.
In addition to its application in the semiconductor-related industry, defect detection using image processing can also be found in other industries. To segment an infection location on green leaves, Singh and Misra [
10] first used the G-plane in RGB images to remove the image background. They then used a genetic algorithm to find the connected regions and used a color co-occurrence matrix to find the texture features for disease classification. Yang [
11] proposed an image analysis technique with the help of a set of evenly spaced parallel light stripes to find apple stems and calyxes. The stems and calyxes can be identified because the continuous parallel light stripes near them became unparalleled, broken, or deformed. Lai et al. [
12] adopted a similar idea by using structured light to enhance the transparent defects for easy detection on a polymeric polarizer. Lee et al. [
13] proposed to use the 2D Discrete Fourier transform and a local threshold binarization method for TFT-LCD defect inspection. The method can effectively find defects in the pad areas with patterns of varying frequencies. Liu et al. [
14] enhanced strip steel images using an enhancement operator based on mathematical morphology (EOBMM), which can reduce the effects of uneven illumination. Then, a genetic algorithm was applied to the binarization of the defect images. The method outperformed the commonly used Otsu method and Bernsen method based on the three error matrices presented in their research.
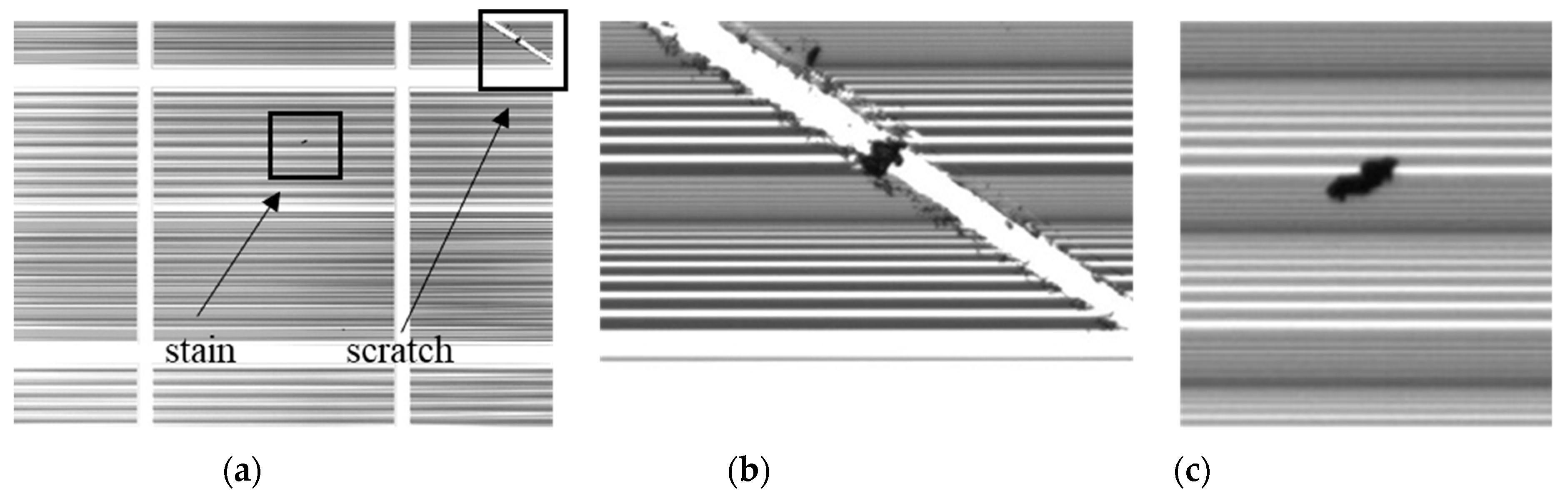
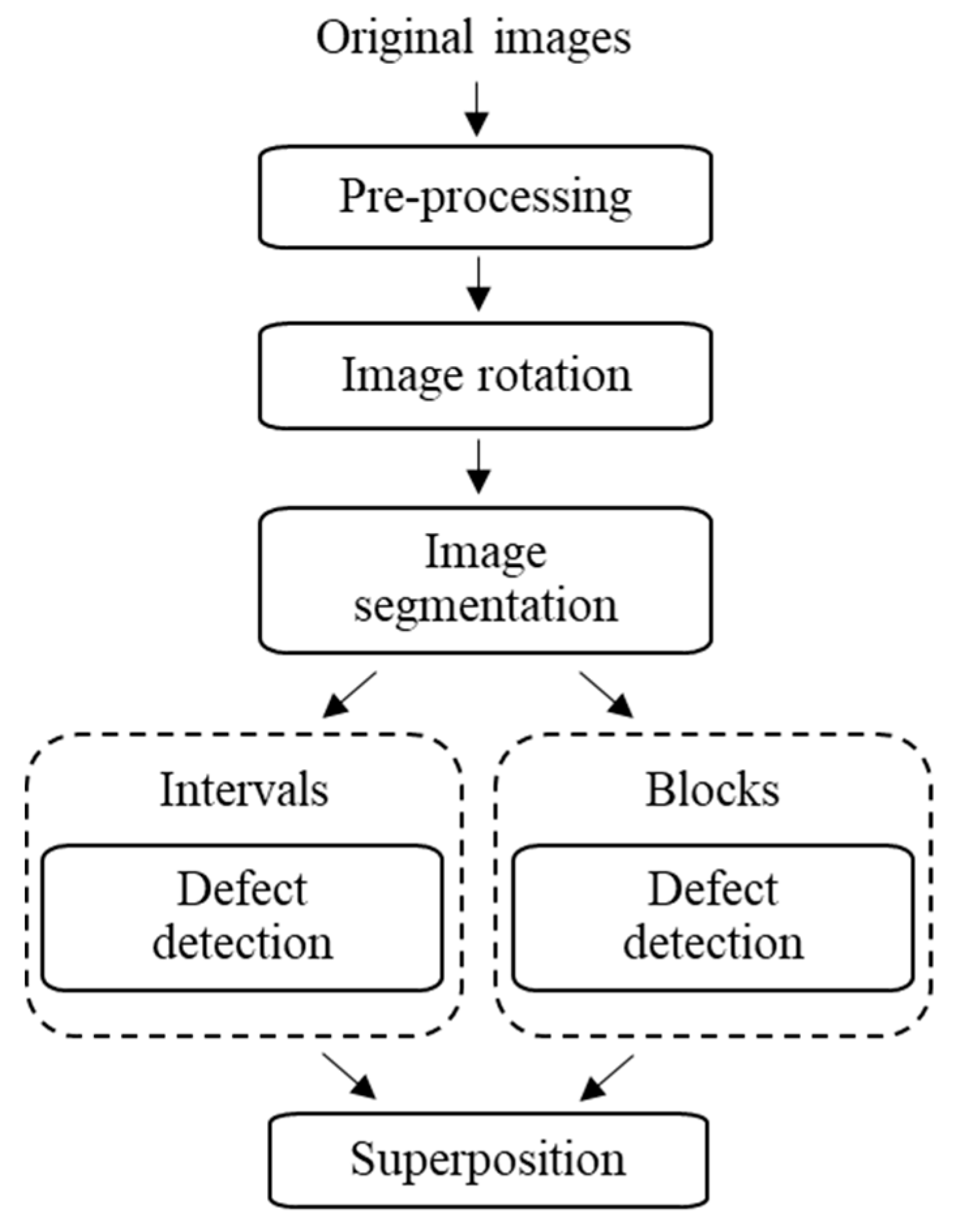
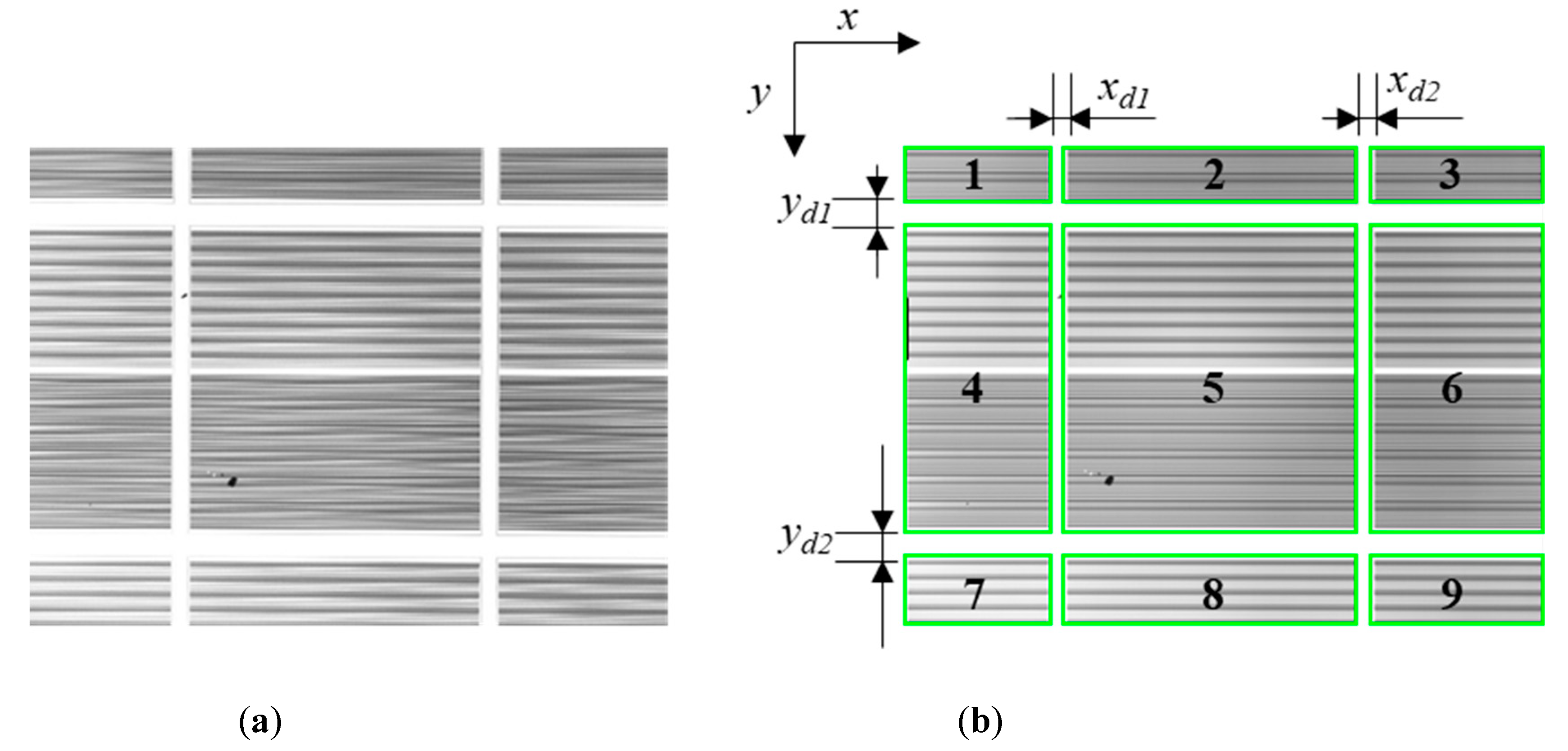
Based on the discussion above, and to the best of the authors’ knowledge, little consideration has been given to detect imaging defects in the background of striped blocks. In this study, defects in images from a semiconductor manufacturing company had to be detected. The defects, including scratches and stains, exist in the images with the background of striped blocks. Therefore, the purpose of this study was to develop an image-processing algorithm for effectively detecting defects in such images. The proposed algorithm may also be used in some other applications, such as defect detection using the structured light of stripe patterns.
3. Results and Discussion
Due to the limited number of actual defect images, the algorithm was evaluated based on 20 actual images and 65 synthesized images. The synthesized images were constructed using the segmented defects from the actual images, and the defects were randomly rotated and placed at various locations in defect-free images to synthesize the defect images. At most, two defects were included in each of the synthesized images.
Figure 18 illustrates two examples of the results obtained using the proposed algorithm. The scratches and stains were all identified and marked in
Figure 18a,b, respectively. The processing time for an image was approximately 6.9 s.
Tasi and Rivera Molina [
16] used the false negative rate (
FNR) and the false positive rate (
FPR) to determine two thresholds.
FNR and
FPR are defined in Equation (1) and Equation (2) as follows:
where False Negative (
FN) is the number of instances in which there is a defect but the proposed algorithm fails to identify it; True Positive (
TP) is the number of instances in which there is a defect and the proposed algorithm correctly finds it; False Positive (
FP) is the number of instances in which there are no defects but the proposed algorithm incorrectly determines that there is one; and True Negative (
TN) is the number of instances in which there are no defects and the proposed algorithm correctly determines that there are none.
By fixing one threshold, Tasi and Rivera Molina [
16] tested in which case the other threshold could reach the lowest
FNR and
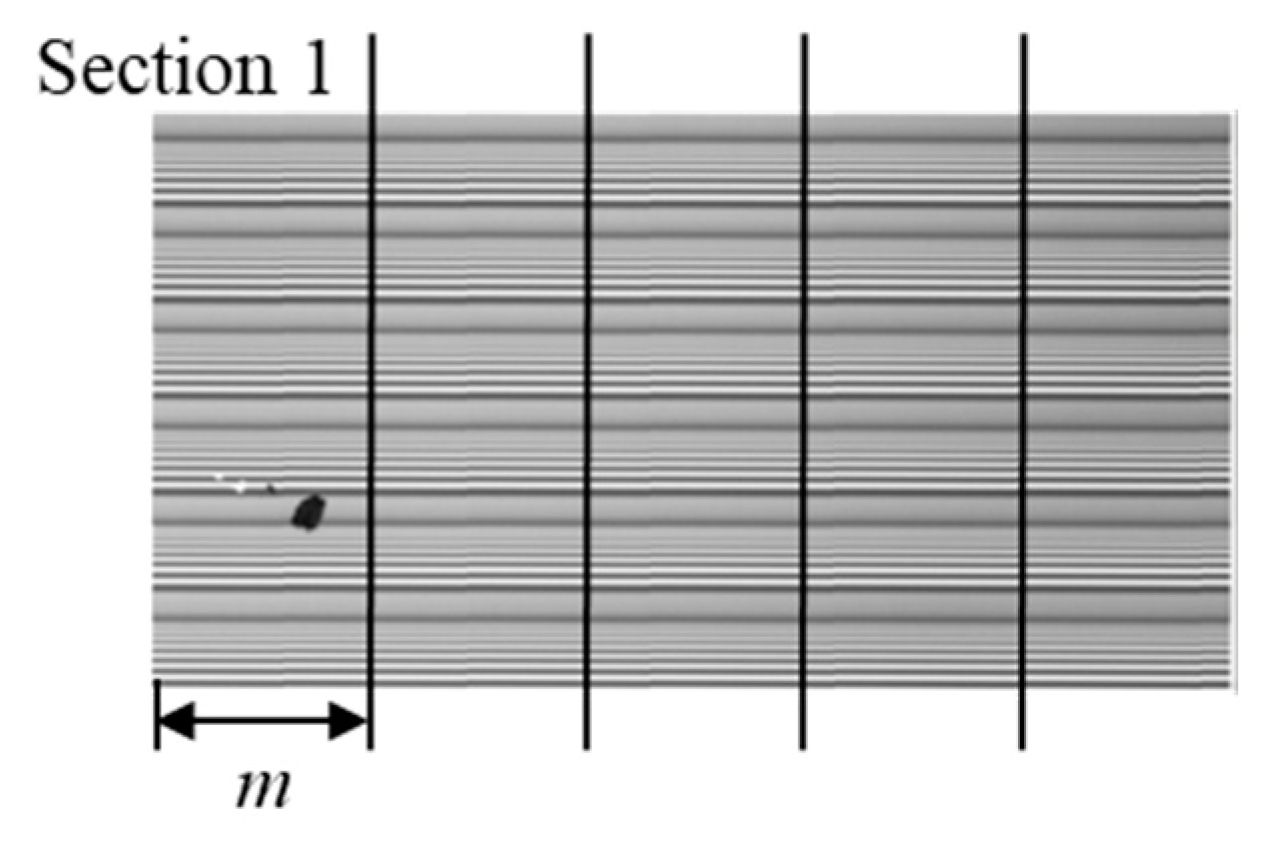
FPR. This study used a similar process to determine two critical parameters: section width,
m, and block binarization threshold,
Tr.
A total of 30 actual images, which were not from the 85 test images, were used to determine the two parameters, m and Tr so that FNR and FPR were as small as possible. Here, this study adopted the root sum square (RSS) of FNR and FPR as the objective to be minimized.
First, this study set
Tr to be 15 and found the
RSS of
FNR and
FPR for
m ranging from 200 to 450, in increments of 50. The results are shown in
Table 1. It can be seen that when
m = 300, the
RSS had its minimum value of 0.281. Besides, the
RSS varied little when
m was in the range. In other words,
FNR and
FPR are not sensitive to
m. Next, this study used
m = 300 and found the
RSS of
FNR and
FPR for
Tr, ranging from 5 to 35, in increments of 5. As shown in
Table 2, when
Tr = 20, the
RSS was at its minimum, so
Tr = 20 was used in the proposed algorithm.
Finally, the binarization threshold (
Tw) was determined. When
Tw ranged from 185 to 215 with an increment of 5, the
RSS was at its minimum when
Tw = 190, as shown in
Table 3, so
Tw was set to 190 in this research.
After the three critical parameters were determined, the performance of the algorithm was evaluated with 20 actual images and 65 synthesized images based on
TPR,
FPR, and Accuracy (
ACC).
TPR is defined as:
and
ACC is defined as:
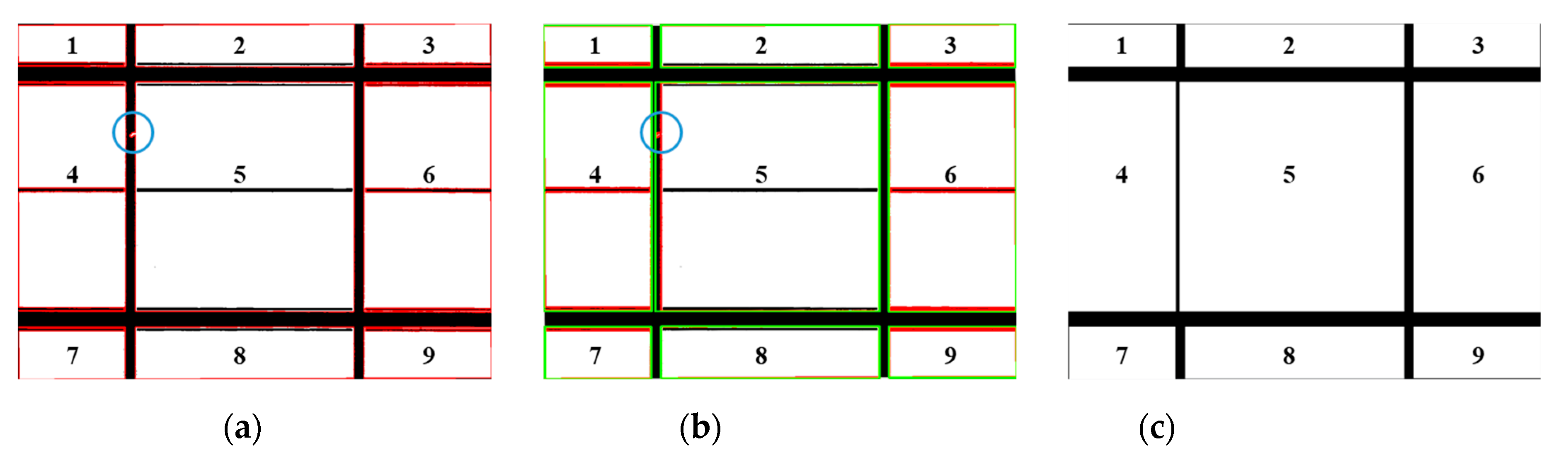
The evaluation criteria were based on the bounding box and its center, as shown in
Figure 19. The red bounding box is the correct position, and the blue or yellow bounding boxes are the results obtained by the proposed algorithm. If the position of the center was off the correct position, it was considered a failed defect detection. If the found bounding box was not completely consistent with the red bounding box, but the center of both boxes matched well, it was considered correct. There were 126 defects in the 85 images. Positive was defined as a defective region; negative was defined as a defect-free region. For defect detection, the number of defect regions could be counted, but not the number of defect-free regions. To make the subsequent calculation possible, this study assumed that there were as many defect-free regions as defect regions, which was equal to 126. The results achieved using the algorithm are listed in
Table 4. The
TP value was 119, which meant that the proposed algorithm correctly detected 119 of 126 defects. The remaining seven defects that could not be detected were the
FN cases. The
FP value was 0, which meant that the proposed algorithm had sufficient robustness for noises that it did not generate any false positives. Using Equations (2) and (3), the
FPR was 0%, and the
TPR was 94.4%. Using Equation (4) yielded an accuracy of 97.2% [
17].
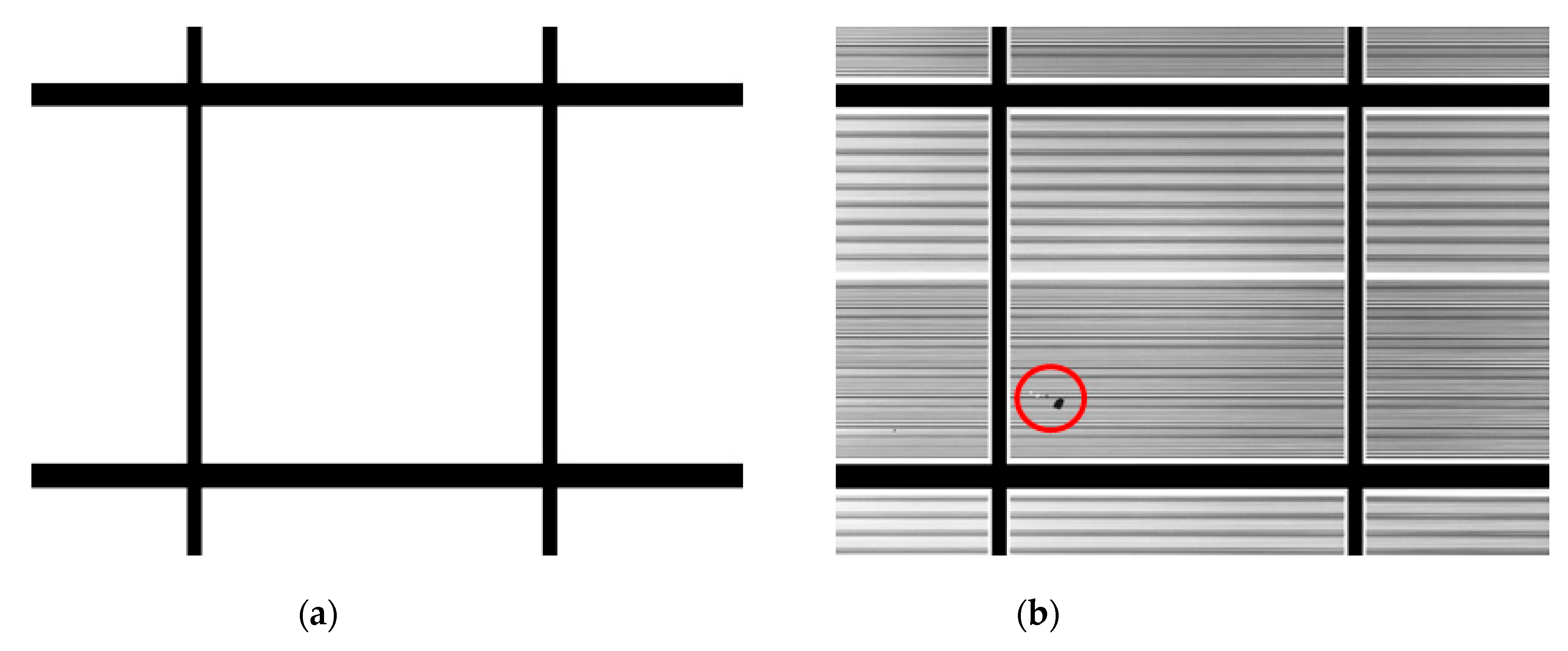
This study analyzed the seven defects that were not detected by the proposed algorithm. The seven defects occurred in six images. These defects were all scratches. From the enlarged views shown in
Figure 20, it can be seen that only the black portions of the scratches were detected, while their white portions were not. This failure was because the grayscale values of the white portions were close to the grayscale values of the background. Therefore, the proposed algorithm may fail to detect scratches whose grayscale values are too close to those of the background.
4. Comparison to Other Study
Here we used the deep learning method to detect defects and compare the results with those obtained by using the proposed method in the paper. The deep learning model was Faster R-CNN with ResNet-101, and the pre-trained model was on the MS COCO dataset. The number of images used for training and validation, the learning rates, and the total training steps are listed in
Table 5. Due to the limited number of the images we have, we synthesized the images for training and validation with 128 different defects on 18 different defect-free images. We arbitrarily chose a defect and put it at a location on one of the 18 defect-free images to obtain a synthesized image. By using different combinations of the defect, the defect-free image, and defect location, we synthesized about 40,000 images in total. Among them, 30,159 images were used for training and 7500 images for validation. The validation accuracy was greater than 99%.
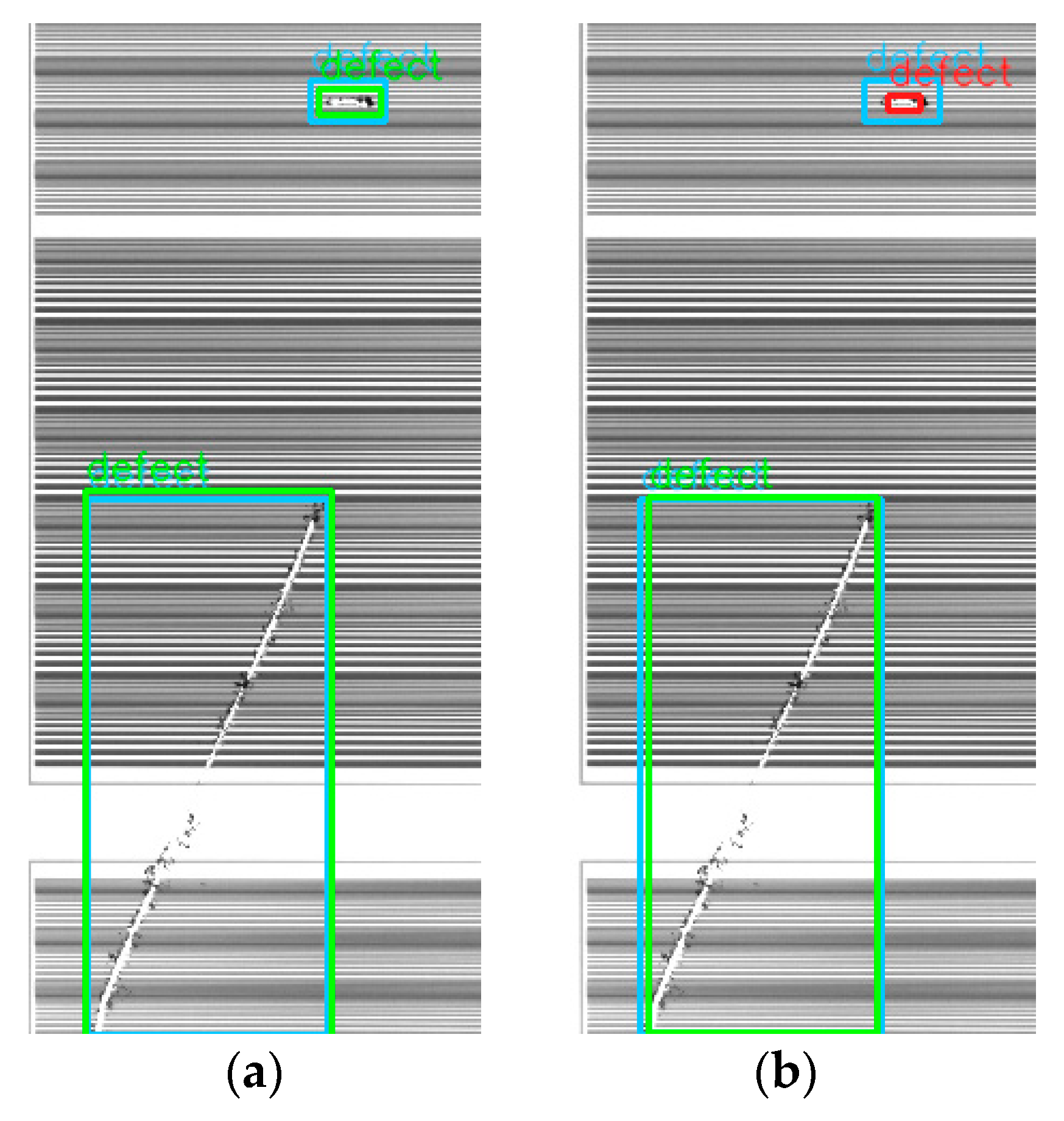
After obtaining the trained model, we applied both methods to 83 images with defects and used 0.5 as the intersection over union (IOU) threshold. The average precision (AP) for the proposed method was 0.91, and that for the deep learning method was 0.74. One image with the defect detection results is shown in
Figure 21. From the figure, we can see that the defect detection by using the proposed method can correctly find the bounding boxes of the two defects in the image, but the deep learning method failed to find one. For other images, the deep learning method even missed some defects. The training dataset may cause the deep learning results with lower AP. Although we used about 30,000 images for training, the amount and the variety may not be enough to yield high AP. From the observation of the deep learning results, most of the poor predictions are related to missing defects and imprecise bounding boxes. The method proposed in this paper finds defects using the image difference, which is more robust to find the defects.
5. Conclusions
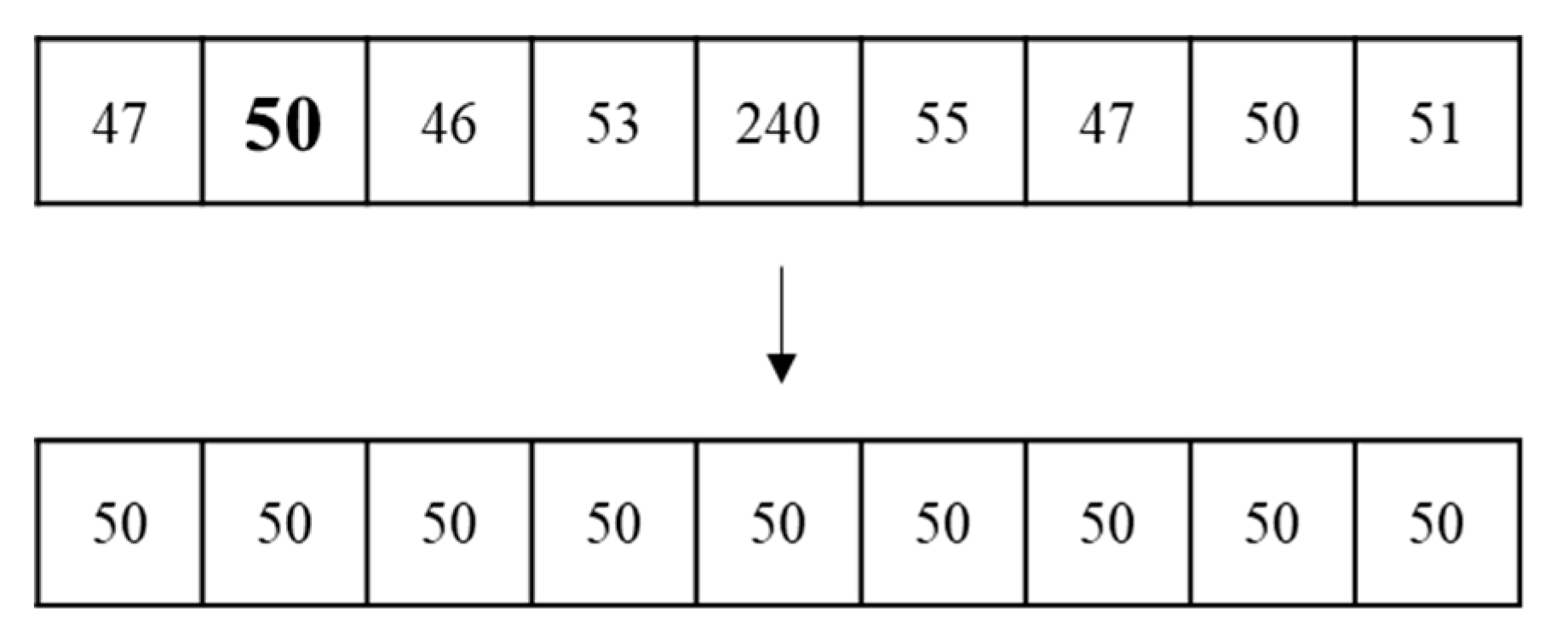
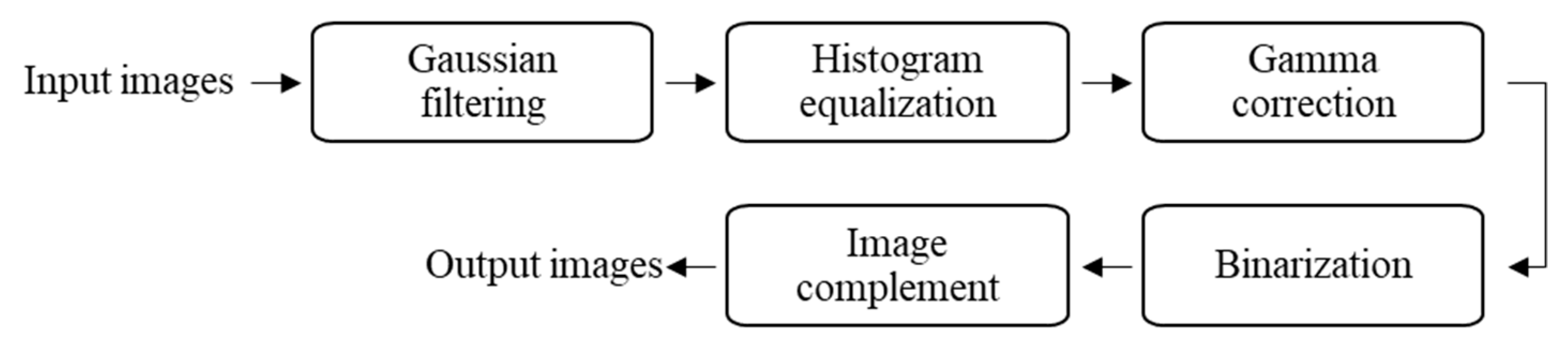
This study proposed a defect detection method for striped images using a one-dimensional median filter. After pre-processing and horizontal alignment image rotation, images were segmented into blocks and intervals. Defects were then found for the blocks and the intervals, respectively. To identify block defects, we used a one-dimensional median filter to generate standard defect-free images. The difference between the standard image and the original image was then used to find the defects. To identify interval defects, we used the image binarization to highlight the defects. Finally, the defect detection results for the blocks and intervals were superposed to obtain all the defects in the entire image. The experiment results show that the proposed method achieved an accuracy of 97.2% based on the correctness of the defect regions. The results demonstrate that the algorithm proposed in this study can effectively detect defects and correctly mark their positions. The proposed method was compared with the deep learning method, and the results show that the average precision by using the proposed method was 0.91 and that by using the deep learning method was 0.74. The proposed method has better robustness in terms of finding the correct bounding boxes for the defects.
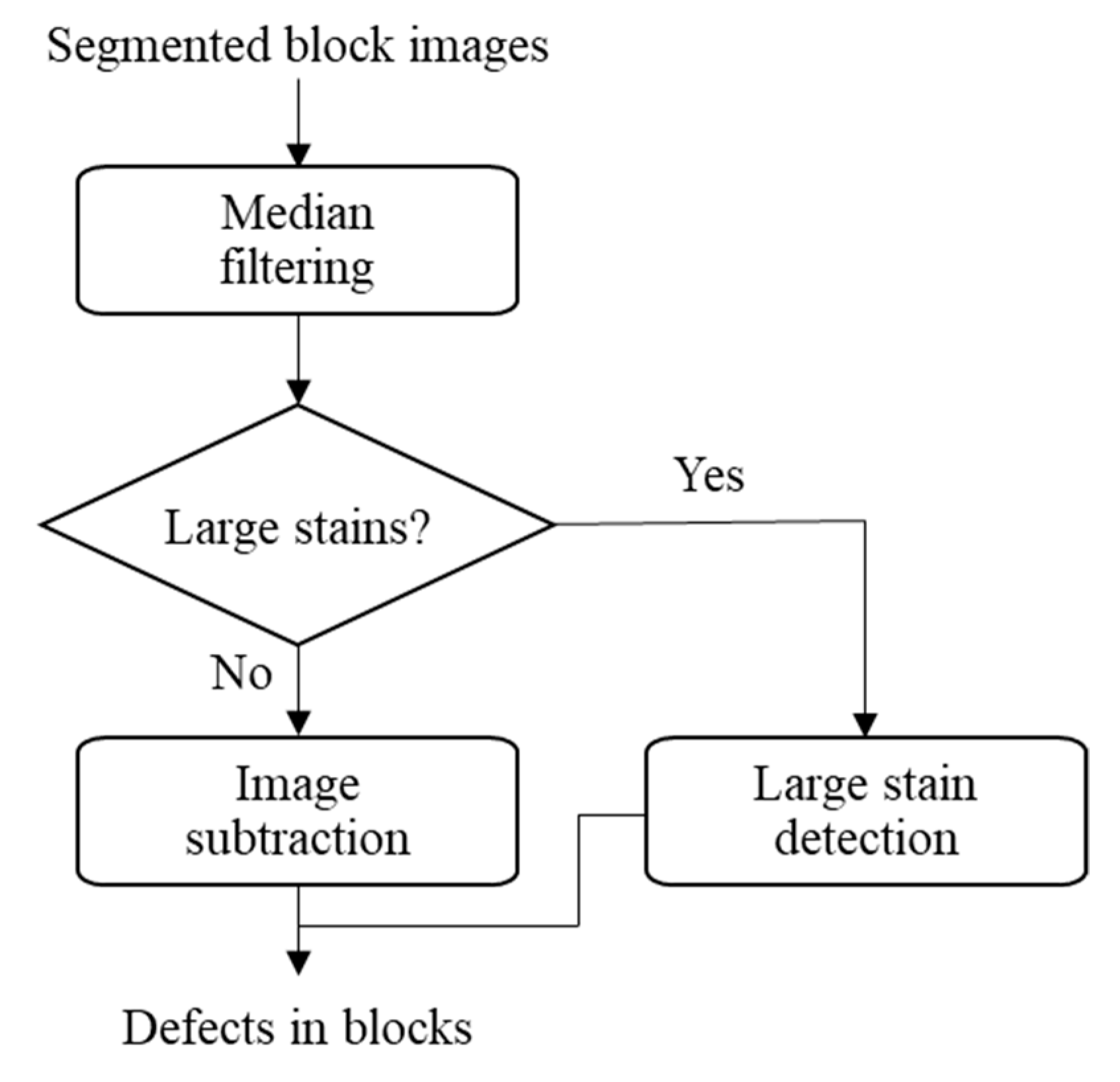
The algorithm used in this paper was developed based on the stripe characteristics of the images. If the images do not have stripes, the algorithm cannot be used. In addition, the stains need to be small (less than m/2 as discussed in the paper), which is valid for the given images. For large stains, it may not be possible to apply the median filter to recover the defect-free images. However, as long as there are some columns in a block that are not affected by the large stains, we can still use the periodic characteristics caused by the stripes along the y-direction in the stain-free columns to recover the defect-free images, which can be used to detect the large stains. However, a lot of noises will also be found. Then a particle analysis can help identify the large stains. This algorithm can be developed as a supplement to the algorithm proposed in the paper so that we can use the proposed algorithm in the paper to find the small defects and then use the supplement to find the large defects. The extension of the proposed algorithm to cover large defects and the optimization of the algorithm to reduce the processing time will be the topics for our future work.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}